Caption generation is the challenging artificial intelligence problem of generating a human-readable textual description given a photograph.
It requires both image understanding from the domain of computer vision and a language model from the field of natural language processing.
It is important to consider and test multiple ways to frame a given predictive modeling problem and there are indeed many ways to frame the problem of generating captions for photographs.
In this tutorial, you will discover 3 ways that you could frame caption generating and how to develop a model for each.
The three caption generation models we will look at are:
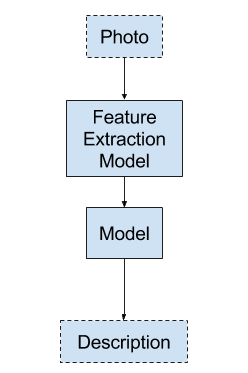
Model 1: Generate the Whole Sequence
Model 2: Generate Word from Word
Model 3: Generate Word from Sequence
We will also review some best practices to consider when preparing data and developing caption generation models in general.
The first approach involves generating the entire textual description for the photo given a photograph.
Input: Photograph
Output: Complete textual description.
This is a one-to-many sequence prediction model that generates the entire output in a one-shot manner.
Model 1 – Generate the Whole Sequence
This model puts a heavy burden on the language model to generate the right words in the right order.
The photograph passes through a feature extraction model such as a model pre-trained on the ImageNet dataset.
A one hot encoding is used for the output sequence, allowing the model to predict the probability distribution of each word in the sequence over the entire vocabulary.
All sequences are padded to the same length. This means that the model is forced to generate multiple “no word” time steps in the output sequence.
Testing this method, I found that a very large language model is required and even then it is hard to get past the model generating the NLP equivalent of persistence, e.g. generating the same word repeated for the entire sequence length as the output.
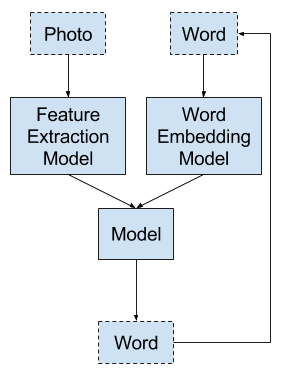
Model 2: Generate Word from Word
This is a different approach where the LSTM generates a prediction of one word given a photograph and one word as input.
Input 1: Photograph.
Input 2: Previously generated word, or start of sequence token.
Output: Next word in sequence.
This is a one-to-one sequence prediction model that generates the textual description via recursive calls to the model.
Model 2 – Generate Word From Word
The one word input is either a token to indicate the start of the sequence in the case of the first time the model is called, or is the word generated from the previous time the model was called.
The photograph passes through a feature extraction model such as a model pre-trained on the ImageNet dataset. The input word is integer encoded and passes through a word embedding.
The output word is one hot encoded to allow the model to predict the probabilities of words over the whole vocabulary.
The recursive word generation process is repeated until an end of sequence token is generated.
Testing this method, I found that the model does generate some good n-gram sequences, but gets caught in a loop repeating the same sequences of words for long descriptions. There is insufficient memory in the model to remember what has been generated previously.
Need help with Deep Learning for Text Data?
Take my free 7-day email crash course now (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
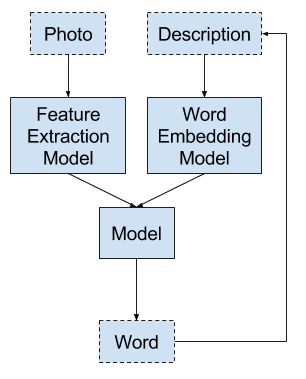
Model 3: Generate Word from Sequence
Given a photograph and a sequence of words already generated for the photograph as input, predict the next word in the description.
Input 1: Photograph.
Input 2: Previously generated sequences of words, or start of sequence token.
Output: Next word in sequence.
This is a many-to-one sequence prediction model that generates a textual description via recursive calls to the model.
Model 3 – Generate Word From Sequence
It is a generalization of the above Model 2 where the input sequence of words gives the model a context for generating the next word in the sequence.
The photograph passes through a feature extraction model such as a model pre-trained on the ImageNet dataset. The photograph may be provided each time step with the sequence, or once at the beginning, which may be the preferred approach.
The input sequence is padded to a fixed-length and integer encoded to pass through a word embedding.
The output word is one hot encoded to allow the model to predict the probabilities of words over the whole vocabulary.
The recursive word generation process is repeated until an end of sequence token is generated.
This appears to be the preferred model described in papers on the topic and might be the best structure we have for this type of problem for now.
Testing this method, I have found that the model does readily generate readable descriptions, the quality of which is often refined by larger models trained for longer. Key to the skill of this model is the masking of padded input sequences. Without masking, the resulting generated sequences of words are terrible, e.g. the end of sequence token is repeated over and over.
Modeling Best Practices
This section lists some general tips when developing caption generation models.
Pre-trained Photo Feature Extraction Model. Use a photo feature extraction model pre-trained on a large dataset like ImageNet. This is called transfer learning. The Oxford Vision Geometry Group (VGG) models that won the ImageNet competition in 2014 are a good start.
Pre-trained Word Embedding Model. Use a pre-trained word embedding model with vectors either trained on average large corpus or trained on your specific text data.
Fine Tune Pre-trained Models. Explore making the pre-trained models trainable in your model to see if they can be dialed-in for your specific problem and result in a slight lift in skill.
Pre-Processing Text. Pre-process textual descriptions to reduce the vocabulary of words to generate, and in turn, the size of the model.
Preprocessing Photos. Pre-process photos for the photo feature extraction model, and even pre-extract features so the full feature extraction model is not required when training your model.
Padding Text. Pad input sequences to a fixed length; this is in fact a requirement of vectorizing your input for deep learning libraries.
Masking Padding. Use masking on the embedding layer to ignore “no word” time steps, often a zero value when words are integer encoded.
Attention. Use attention on the input sequence when generating the output word in order to both achieve better performance and understand where the model is “looking” when each word is being generated.
Evaluation. Evaluate the model using standard text translation metrics like BLEU and compare generated descriptions against multiple references image captions.
Do you have your own best practices for developing robust captioning models?
Let me know in the comments below.
Further Reading
This section provides more resources on the topic if you are looking go deeper.
In this tutorial, you discovered 3 sequence prediction models that can be used to address the problem of generating human readable textual descriptions for photographs.
Have you experimented with any of these models?
Share your experiences in the comments below.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Hi Jason, will you provide an example code of Model 2? I’m wondering how to provide the visual feature only the first time and then a sequence of words/values
Ok, so you provide both visual and textual concatenated. But the first time you mask the sequence of words. And from the second time you mask the visual feature. Is that right?
So you put all zeros in lieu of the visual feature starting from the second time? I mean, you should provide the image only at time 1, together with a special START word. Then, starting from time 2, you provide all zeros instead of the visual features and the previous predicted word.







Thanks a lot Jason. You highlight masking. What exactly is that. Have you covered that before?
Yes, see this post:
https://machinelearningmastery.com/handle-missing-timesteps-sequence-prediction-problems-python/
Hi Jason, will you provide an example code of Model 2? I’m wondering how to provide the visual feature only the first time and then a sequence of words/values
I have an example of Model 3 in the book, which can be adapted to be model 2.
Model 3 is the easiest to train and has better skill in my experience.
Great! I don t understand if you use Masking to provide the visual feature online the first time or Afflect the initial state?
We would mask the sequence of padded words.
Ok, so you provide both visual and textual concatenated. But the first time you mask the sequence of words. And from the second time you mask the visual feature. Is that right?
No, the image is only provided once, the words – the description generated so far – is padded to the maximum length.
So you put all zeros in lieu of the visual feature starting from the second time? I mean, you should provide the image only at time 1, together with a special START word. Then, starting from time 2, you provide all zeros instead of the visual features and the previous predicted word.
No, the network has two input channels, one for the image and one for a sequence of words generated so far.
Mmm…sorry, but it is still not clear to me how you provide the image only once.
Perhaps try running this example and see for yourself:
https://machinelearningmastery.com/develop-a-deep-learning-caption-generation-model-in-python/