How to Handle the Intractability of Applied Machine Learning.
Applied machine learning is challenging.
You must make many decisions where there is no known “right answer” for your specific problem, such as:
What framing of the problem to use?
What input and output data to use?
What learning algorithm to use?
What algorithm configuration to use?
This is challenging for beginners that expect that you can calculate or be told what data to use or how to best configure an algorithm.
In this post, you will discover the intractable nature of designing learning systems and how to deal with it.
After reading this post, you will know:
How to develop a clear definition of your learning problem for yourself and others.
The 4 decision points you must consider when designing a learning system for your problem.
The 3 strategies that you can use to specifically address the intractable problem of designing learning systems in practice.
Let’s get started.
Overview
This post is divided into 6 sections inspired by chapter 1 of Tom Mitchell’s excellent 1997 book Machine Learning; they are:
Well-Posed Learning Problems
Choose the Training Data
Choose the Target Function
Choose a Representation of the Target Function
Choose a Learning Algorithm
How to Design Learning Systems
Well-Posed Learning Problems
We can define a general learning task in the field of applied machine learning as a program that learns from experience on some task against a specific performance measure.
Tom Mitchell in his 1997 book Machine Learning states this clearly as:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
We take this as a general definition for the types of learning tasks that we may be interested in for applied machine learning such as predictive modeling. Tom lists a few examples to make this clear, such as:
Learning to recognize spoken words.
Learning to drive an autonomous vehicle.
Learning to classify new astronomical structures.
Learning to play world-class backgammon.
We can use the above definition to define our own predictive modeling problem. Once defined, the task becomes that of designing a learning system to address it.
Designing a learning system, i.e. an application of machine learning, involves four design choices:
Choosing the training data.
Choosing the target function.
Choosing the representation.
Choosing the learning algorithm.
There might be a best set of choices that you can make for a given problem given infinite resources, but we don’t have infinite time, compute resources, and knowledge about the domain or learning systems.
Therefore, although we can prepare a well-posed description of a learning problem, designing the best possible learning system is intractable.
The best we can do is use knowledge, skill, and available resources to work through the design choices.
Let’s look at each of these design choices in more detail.
Choose the Training Data
You must choose the data your learning system will use as experience from which to learn.
This is the data from past observations.
The type of training experience available can have a significant impact on success or failure of the learner.
It is rarely well formatted and ready to use; often you must collect the data you need (or think you might need) for the learning problem.
This may mean:
Scraping documents.
Querying databases.
Processing files.
Collating disparate sources
Consolidating entities.
You need to get all of the data together and into a normalized form such that one observation represents one entity for which an outcome is available.
Choose the Target Function
Next, you must choose the framing of the learning problem.
Machine learning is really a problem of learning a mapping function (f) from inputs (X) to outputs (y).
1
y = f(X)
This function can then be used on new data in the future in order to predict the most likely output.
The goal of the learning system is to prepare a function that best maps inputs to outputs given the resources available. The underlying function that actually exists is unknown. If we knew the form of this function, we could use it directly and we would not need machine learning to learn it.
More generally, this is a problem called function approximation. The result will be an approximation, meaning that it will have error. We will do our best to minimize this error, but some error will always exist given noise in the data.
… we have reduced the learning task in this case to the problem of discovering an operational description of the ideal target function V. It may be very difficult in general to learn such an operational form of V perfectly. In fact, we often expect learning algorithms to acquire only some approximation to the target function, and for this reason the process of learning the target function is often called function approximation.
This step is about selecting exactly what data to use as input to the function, e.g. the input features or input variables and what exactly will be predicted, e.g. the output variable.
Often, I refer to this as the framing of your learning problem. Choosing the inputs and outputs essentially chooses the nature of the target function we will seek to approximate.
Choose a Representation of the Target Function
Next, you must choose the representation you wish to use for the mapping function.
Think of this as the type of final model you wish to have that you can then use to make predictions. You must choose the form of this model, the data structure if you’d like.
Now that we have specified the ideal target function V, we must choose a representation that the learning program will use to describe the function Vprime that it will learn.
Perhaps your project requires a decision tree that is easy to understand and explain to stakeholders.
Perhaps your stakeholders prefer a linear model that the stats guys can easily interpret.
Perhaps your stakeholders don’t care about anything other than model performance so all model representations are up for grabs.
The choice of representation will impose constraints on the types of learning algorithms that you can use to learn the mapping function.
Choose a Learning Algorithm
Finally, you must choose the learning algorithm that will take the input and output data and learn a model of your preferred representation.
If there were few constraints on the choice of representation, as is often the case, then you may be able to evaluate a suite of different algorithms and representations.
If there were strong constraints on the choice of function representation, e.g. a weighted sum linear model or a decision tree, then the choice of algorithms will be limited to those that that can operate on the specific representations.
The choice of algorithm may impose its own constraints, such as specific data preparation transforms like data normalization.
How to Design Learning Systems
Developing a learning system is challenging.
No one can tell you the best answer to each decision along the way; the best answer is unknown for your specific learning problem.
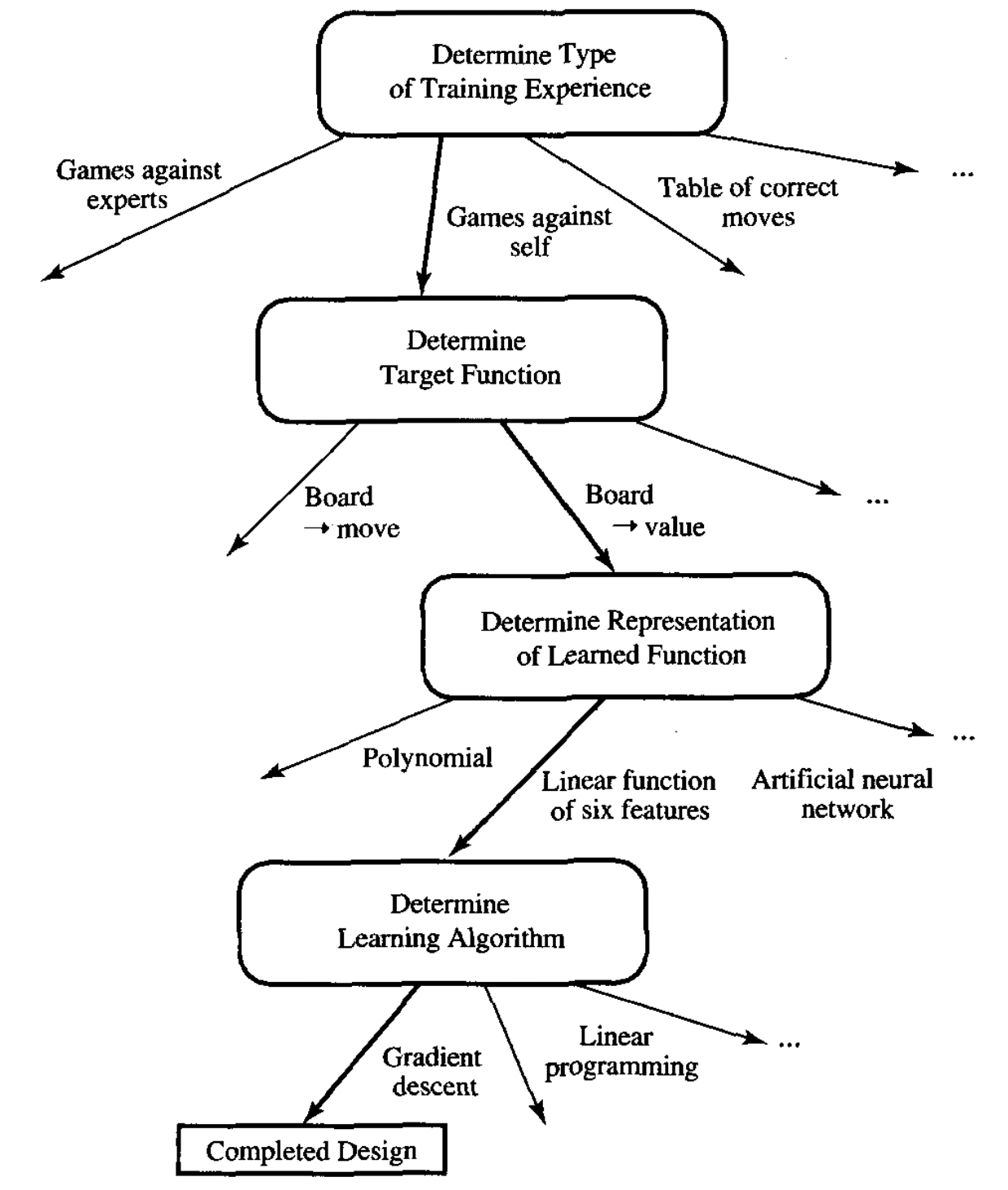
Mitchell helps to clarify this with a depiction of the choices made in designing a learning system for playing checkers.
The depiction of Choices in Designing a Checker-Playing Learning System. Taken from “Machine Learning”, 1997.
The choices act as points of constraint on the design process. Mitchell goes on to say:
These design choices have constrained the learning task in a number of ways. We have restricted the type of knowledge that can be acquired to a single linear evaluation function. Furthermore, we have constrained this evaluation function to depend on only the six specific board features provided. If the true target function V can indeed be represented by a linear combination of these particular features, then our program has a good chance to learn it. If not, then the best we can hope for is that it will learn a good approximation, since a program can certainly never learn anything that it cannot at least represent.
I like this passage as it really drives home both the importance of these constraints to simplify the problem, and the risk of making choices that limit or prevent the system from learning the problem sufficiently.
Generally, you cannot analytically calculate the answer to these choices, e.g. what data to use, what algorithm to use, or what algorithm configuration to use.
Nevertheless, all is not lost; here are 3 tactics that you can use in practice:
Copy. Look to the literature or experts for learning systems on problems the same or similar to your problem and copy the design of the learning system. It is very likely you are not the first to work on a problem of a given type. At the very worst, the copied design provides a starting point for your own design.
Search. List available options at each decision point and empirically evaluate each to see what works best on your specific data. This may be the most robust and most practiced approach in applied machine learning.
Design. After completing many projects via the Copy and Search methods above, you will develop an intuition for how to design machine learning systems.
Developing learning systems is not a science; it is engineering.
Developing new machine learning algorithms and describing how and why they work is a science, and this is often not required when developing a learning system.
Developing a learning system is a lot like developing software. You must combine (1) copies of past designed that work, (2) prototypes that show promising results, and (3) design experience when developing a new system in order to get the best results.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Could you kindly provide any example from your own experience? Not only the resulting design but also your thought process and how you came about the resulting design?
Quantitative tutorials (projects encapsulated within a full code) plus reflexive and qualitative ideas, to understand what going on behind those algorithms, such this one, It is a great combination from your side, in order to get the mission of “providing to each of one of us with the tools and necessary concepts to get Artificial Intelligence paradigms and be skilful practitioners






Awesome article!
Thanks!
nice post!
Thanks.
Could you kindly provide any example from your own experience? Not only the resulting design but also your thought process and how you came about the resulting design?
Thanks for the suggestion.
Many of my longer blog posts would be a good starting point.
Top article. Thanks.
You’re welcome.
thks Jason!.
Quantitative tutorials (projects encapsulated within a full code) plus reflexive and qualitative ideas, to understand what going on behind those algorithms, such this one, It is a great combination from your side, in order to get the mission of “providing to each of one of us with the tools and necessary concepts to get Artificial Intelligence paradigms and be skilful practitioners
Thanks.
It’s a very friendly explanation!
Thanks Alex.