A key part of data preparation is creating transforms of the dataset such as rescaled attribute values and attributes decomposed into their constituent parts, all with the intention of exposing more and useful structure to the modeling algorithms.
An important suite of methods to employ when preparing the dataset are automatic feature selection algorithms. In this post you will discover feature selection, the benefits of simple feature selection and how to make best use of these algorithms in Weka on your dataset.
Kick-start your project with my new book Machine Learning Mastery With Weka, including step-by-step tutorials and clear screenshots for all examples.
Let’s get started.
Carefully choose features in your dataset Photo by Gabe Photos, some rights reserved
Not All Attributes Are Equal
Whether you select and gather sample data yourself or whether it is provided to you by domain experts, the selection of attributes is critically important. It is important because it can mean the difference between successfully and meaningfully modeling the problem and not.
Misleading
Including redundant attributes can be misleading to modeling algorithms. Instance-based methods such as k-nearest neighbor use small neighborhoods in the attribute space to determine classification and regression predictions. These predictions can be greatly skewed by redundant attributes.
Overfitting
Keeping irrelevant attributes in your dataset can result in overfitting. Decision tree algorithms like C4.5 seek to make optimal spits in attribute values. Those attributes that are more correlated with the prediction are split on first. Deeper in the tree less relevant and irrelevant attributes are used to make prediction decisions that may only be beneficial by chance in the training dataset. This overfitting of the training data can negatively affect the modeling power of the method and cripple the predictive accuracy.
It is important to remove redundant and irrelevant attributes from your dataset before evaluating algorithms. This task should be tackled in the Prepare Data step of the applied machine learning process.
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
Feature Selection
Feature Selection or attribute selection is a process by which you automatically search for the best subset of attributes in your dataset. The notion of “best” is relative to the problem you are trying to solve, but typically means highest accuracy.
A useful way to think about the problem of selecting attributes is a state-space search. The search space is discrete and consists of all possible combinations of attributes you could choose from the dataset. The objective is to navigate through the search space and locate the best or a good enough combination that improves performance over selecting all attributes.
Three key benefits of performing feature selection on your data are:
Reduces Overfitting: Less redundant data means less opportunity to make decisions based on noise.
Improves Accuracy: Less misleading data means modeling accuracy improves.
Reduces Training Time: Less data means that algorithms train faster.
Attribute Selection in Weka
Weka provides an attribute selection tool. The process is separated into two parts:
Attribute Evaluator: Method by which attribute subsets are assessed.
Search Method: Method by which the space of possible subsets is searched.
Attribute Evaluator
The Attribute Evaluator is the method by which a subset of attributes are assessed. For example, they may be assessed by building a model and evaluating the accuracy of the model.
Some examples of attribute evaluation methods are:
CfsSubsetEval: Values subsets that correlate highly with the class value and low correlation with each other.
ClassifierSubsetEval: Assesses subsets using a predictive algorithm and another dataset that you specify.
WrapperSubsetEval: Assess subsets using a classifier that you specify and n-fold cross validation.
Search Method
The Search Method is the is the structured way in which the search space of possible attribute subsets is navigated based on the subset evaluation. Baseline methods include Random Search and Exhaustive Search, although graph search algorithms are popular such as Best First Search.
Some examples of attribute evaluation methods are:
Exhaustive: Tests all combinations of attributes.
BestFirst: Uses a best-first search strategy to navigate attribute subsets.
GreedyStepWise: Uses a forward (additive) or backward (subtractive) step-wise strategy to navigate attribute subsets.
How to Use Attribute Selection in Weka
In this section I want to share with you three clever ways of using attribute selection in Weka.
1. Explore Attribute Selection
When you are just stating out with attribute selection I recommend playing with a few of the methods in the Weka Explorer.
Load your dataset and click the “Select attributes” tab. Try out different Attribute Evaluators and Search Methods on your dataset and review the results in the output window.
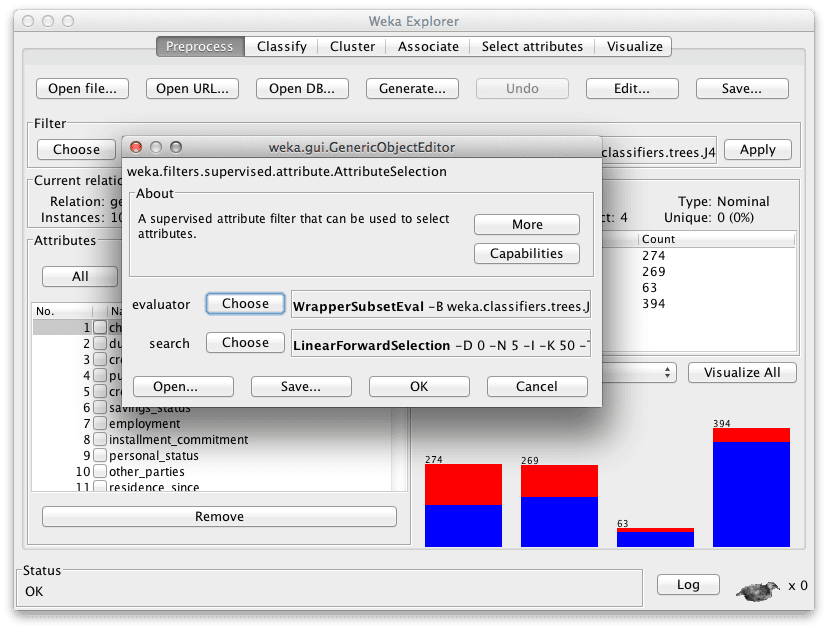
Feature Selection Methods in the Weka Explorer
The idea is to get a feeling and build up an intuition for 1) how many and 2) which attributes are selected for your problem. You could use this information going forward into either or both of the next steps.
2. Prepare Data with Attribute Selection
The next step would be to use attribute selection as part of your data preparation step.
There is a filter you can use when preprocessing your dataset that will run an attribute selection scheme then trim your dataset to only the selected attributes. The filter is called “AttributeSelection” under the Unsupervised Attribute filters.
Creating Transforms of a Dataset using Feature Selection methods in Weka
You can then save the dataset for use in experiments when spot checking algorithms.
3. Run Algorithms with Attribute Selection
Finally, there is one more clever way you can incorporate attribute selection and that is to incorporate it with the algorithm directly.
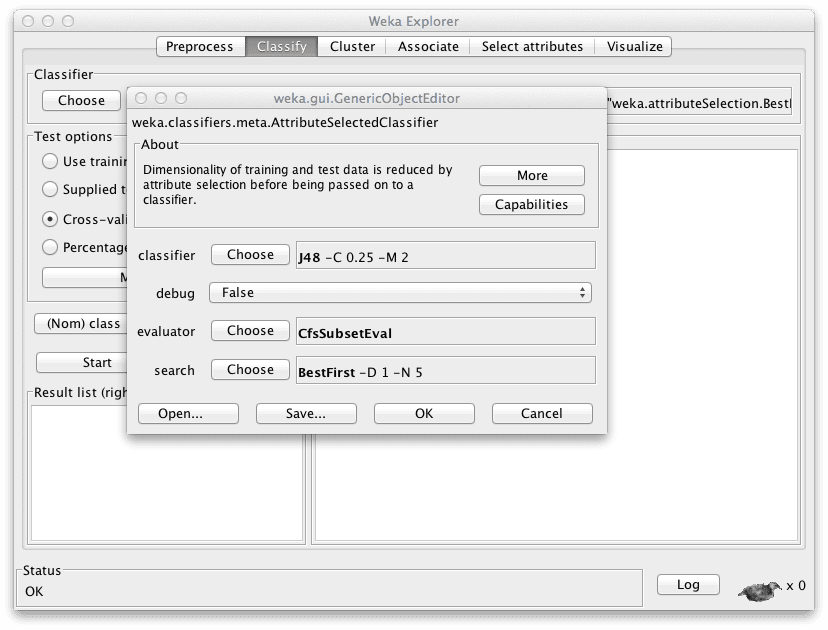
There is a meta algorithm you can run and include in experiments that selects attributes running the algorithm. The algorithm is called “AttributeSelectedClassifier” under the “meta” group of algorithms. You can configure this algorithm to use your algorithm of choice as well as the Attribute Evaluator and Search Method of your choosing.
Coupling a Classifier and Attribute Selection in a Meta Algorithm in Weka
You can include multiple versions of this meta algorithm configured with different variations and configurations of the attribute selection scheme and see how they compare to each other.
Summary
In this post you discovered feature selection as a suite of methods that can increase model accuracy, decrease model training time and reduce overfitting.
You also discovered that feature selection methods are built into Weka and you learned three clever ways for using feature selection methods on your dataset in Weka, namely by exploring, preparing data and in coupling it with your algorithm in a meta classifier.
If you are looking for the next step, I recommend the book Feature Extraction: Foundations and Applications. It is a collection of articles by academics covering a range of issues on and realted to feature selection. It’s pricy but well worth it because of the difference the methods it can make on solving your problem.
For an updated perspective on feature selection with Weka see the post:
Thanks a lot for the tips! I read somewhere that you could not do attribute selection using GUI; your post really made my day.
There’s a small thing that I noticed. In my version of Weka 3.7.1.1 the filter that we need to use (attribute selector) comes under supervised, not the Unsupervised category as you posted.
After the feature selection, the accuracies of the models I tested got decreased. Usually, as I believe, accuracy should be improved.
When it comes to Naive Bayes, the accuracy got reduced in big manner. From 45% to 36%.
Can that be something wrong with the dataset I use? My dataset is a small one with 5 categories and 30 instances in each category.
Attribute selection helps you weed out attributes that are hurting your accuracy because they are misleading in some way (Jason’s article covers what that means pretty well). If you only have 5 attributes, then your models will likely need all of them. Attribute selection helps when you have lots of attributes (I would say at least a few dozen, in general, but it depends on the data and the model) or you think that some of your attributes might be causing problems.
After applying feature selection and viewing the rank sequence which was used to get rid of an attribute with the lowest rank, I applied both the Naives Bayes and J48 classifier and for both cases, my accuracy reduced from what it was initially before removing the least ranked attribute.
Any ideas on why this might be so??
Thanks.
How can I decide which attribute selection algorithms I should use to enhance the accuracy of the model. I do have more than 1000 features and I am gonna use the model to classify apps into good or malicious based on binary features?
I have dataset with 62 attribute and 300 record
I apply feature selection tell me selected attribute 41.
I remove these attribute.
I use random forest knn baysian network neural network and svm.
But some classifier accuracy enhance result and other not . Some classifier accuracy decreased. Than original accuracy with 62
Idimensions. Why? I have another pca in preprocces . What different
Hi DR. Jason,
I am interested to use Machine Learning into a User Interfaces Adaptation System. The purpose is to predict the system reaction toward the context of use variations. My dataset consists of 14 attributes (nominal, numeric and binary). The 14th attribute representing the class is nominal and consiists of 12 actions that can be performed by the systems. THe other attributes refers to the context parameters. I tested several Weka algorithms but I cannot decide which one feets more with my problem. My question is how to choose the more suitable algorithms in order to make prediction ? Can Feature Selection help me in this case ?
Thanks
Perhaps you can create many copies of your data, one leave it as is, another try converting all features to numeric, another all to categorical and so on and evaluate algorithms on each view of the problem to see if anything floats to the surface.
Thanks for your quick response. I found another tutorial that you have published at this adress “https://machinelearningmastery.com/save-machine-learning-model-make-predictions-weka/”. I really helped me a lot. So, I used logistic regression algorithm to make prediction. It gives me best results compared to others algorithms.
Training step :
Correctly Classified Instances 216 86.747 %
Incorrectly Classified Instances 33 13.253 %
Kappa statistic 0.83
Mean absolute error 0.0232
Root mean squared error 0.1076
Relative absolute error 17.7309 %
Root relative squared error 42.2221 %
Total Number of Instances 249
Test step :
Correctly Classified Instances 8 66.6667 %
Incorrectly Classified Instances 4 33.3333 %
Kappa statistic 0.6066
Mean absolute error 0.0463
Root mean squared error 0.1525
Total Number of Instances 12
I just now want if these results are satisfactory to adaopt this solution. I need it in my thesisPHD. If not, what can i do to improve the prediction capability ?
I didn’t understand what do you mean exactly by defining “good” as a score relative to the ZeroR algorithm but I will read the post and try to understand.
Thank you again.
Hi Jason, Thanks for the tuto.
I’m working on an IDS, and first i want to do feature selection.When performed with CFS and IG it works well. But with a wrapper no matter what it is, it’s taking so much time. I know should take more time comparing to filter-based since we use an ML algo., but this is taking more than the normal, maybe 1 day and still not giving any result. At first, it was a RAM problem but i fixed it. Then i thought it’s a CPU problem, but when checking the CPU i see just 35% of it that is used. I’m wondering what could be the issue here….
Thanks
Hey I have a question regarding the definition of training time? What all does the training time include for Neural Networks? Does it only include the time taken to run the code for best network architecture (hidden layers and neurons) or does it also include the time taken to determine the best architecture i.e. k fold Cross validation and other steps?
sir i need your help i want to use filters method for features selection to diagnose thyroid disease. please suggusset goofd algortrims???like JMIM ,permutation ,limma,impurity and sym.uncert please tell meh that are good for daignose disease and what classification can i use for best accuracy??????








 for Feature Selection in Python")
what is Discrete method used in Weka software
which version of Weka is this ?
I used Weka version 3.6.10 on OS X when creating this post.
Hi there,
Thanks a lot for the tips! I read somewhere that you could not do attribute selection using GUI; your post really made my day.
There’s a small thing that I noticed. In my version of Weka 3.7.1.1 the filter that we need to use (attribute selector) comes under supervised, not the Unsupervised category as you posted.
After the feature selection, the accuracies of the models I tested got decreased. Usually, as I believe, accuracy should be improved.
When it comes to Naive Bayes, the accuracy got reduced in big manner. From 45% to 36%.
Can that be something wrong with the dataset I use? My dataset is a small one with 5 categories and 30 instances in each category.
Attribute selection helps you weed out attributes that are hurting your accuracy because they are misleading in some way (Jason’s article covers what that means pretty well). If you only have 5 attributes, then your models will likely need all of them. Attribute selection helps when you have lots of attributes (I would say at least a few dozen, in general, but it depends on the data and the model) or you think that some of your attributes might be causing problems.
After applying feature selection and viewing the rank sequence which was used to get rid of an attribute with the lowest rank, I applied both the Naives Bayes and J48 classifier and for both cases, my accuracy reduced from what it was initially before removing the least ranked attribute.
Any ideas on why this might be so??
Thanks.
How can I decide which attribute selection algorithms I should use to enhance the accuracy of the model. I do have more than 1000 features and I am gonna use the model to classify apps into good or malicious based on binary features?
I have dataset with 62 attribute and 300 record
I apply feature selection tell me selected attribute 41.
I remove these attribute.
I use random forest knn baysian network neural network and svm.
But some classifier accuracy enhance result and other not . Some classifier accuracy decreased. Than original accuracy with 62
Idimensions. Why? I have another pca in preprocces . What different
Feature selection methods are heuristics, they are just an idea of what might work well, not a guarantee.
I would suggest building models from many different “views” of your data, then combine predictions in an ensemble. Results are often much better.
Hi, Dr. Jason Brownlee iam intrested in learning machine learning without codeing can you help me Iam from INDIA
Yes, start here:
https://machinelearningmastery.com/start-here/#weka
Hi, Dr. Jason.
I am a bit new in Data Mining. I am into predictive modeling.
May I just as ask how can I determine the training time / processing time in building classifier? and what tool can i use?
Thanks.
What do you mean exactly? The wall clock time to train a model?
If so, often you can do this by writing code alongside the training of your model.
Hi DR. Jason,
I am interested to use Machine Learning into a User Interfaces Adaptation System. The purpose is to predict the system reaction toward the context of use variations. My dataset consists of 14 attributes (nominal, numeric and binary). The 14th attribute representing the class is nominal and consiists of 12 actions that can be performed by the systems. THe other attributes refers to the context parameters. I tested several Weka algorithms but I cannot decide which one feets more with my problem. My question is how to choose the more suitable algorithms in order to make prediction ? Can Feature Selection help me in this case ?
Thanks
Perhaps you can create many copies of your data, one leave it as is, another try converting all features to numeric, another all to categorical and so on and evaluate algorithms on each view of the problem to see if anything floats to the surface.
Thanks for your quick response. I found another tutorial that you have published at this adress “https://machinelearningmastery.com/save-machine-learning-model-make-predictions-weka/”. I really helped me a lot. So, I used logistic regression algorithm to make prediction. It gives me best results compared to others algorithms.
Training step :
Correctly Classified Instances 216 86.747 %
Incorrectly Classified Instances 33 13.253 %
Kappa statistic 0.83
Mean absolute error 0.0232
Root mean squared error 0.1076
Relative absolute error 17.7309 %
Root relative squared error 42.2221 %
Total Number of Instances 249
Test step :
Correctly Classified Instances 8 66.6667 %
Incorrectly Classified Instances 4 33.3333 %
Kappa statistic 0.6066
Mean absolute error 0.0463
Root mean squared error 0.1525
Total Number of Instances 12
I just now want if these results are satisfactory to adaopt this solution. I need it in my thesisPHD. If not, what can i do to improve the prediction capability ?
Thanks a lot
One other question please. Is the Logistic Regression sitable for a Multiclass classification problem ? (my class have 12 possible nominal values)
Generally no. Logistic regression is for binary classification.
“Good” is really defined by your domain. Perhaps you can define good as a score relative to the ZeroR algorithm?
This post lists all of my best ideas for lifting model skill:
https://machinelearningmastery.com/machine-learning-performance-improvement-cheat-sheet/
I didn’t understand what do you mean exactly by defining “good” as a score relative to the ZeroR algorithm but I will read the post and try to understand.
Thank you again.
I meant that the baseline skill for all models to out-perform will be the score of the ZeroR algorithm.
Hi Jason, Thanks for the tuto.
I’m working on an IDS, and first i want to do feature selection.When performed with CFS and IG it works well. But with a wrapper no matter what it is, it’s taking so much time. I know should take more time comparing to filter-based since we use an ML algo., but this is taking more than the normal, maybe 1 day and still not giving any result. At first, it was a RAM problem but i fixed it. Then i thought it’s a CPU problem, but when checking the CPU i see just 35% of it that is used. I’m wondering what could be the issue here….
Thanks
Perhaps you could use a smaller sample of your data for feature selection?
Thanks for the tutorial. It seems that Weka has really helped you in your machine learning journey. I’ll give it a try.
It has. I started with it back in the early 2000s, before eventually moving on to R and Python.
Hey I have a question regarding the definition of training time? What all does the training time include for Neural Networks? Does it only include the time taken to run the code for best network architecture (hidden layers and neurons) or does it also include the time taken to determine the best architecture i.e. k fold Cross validation and other steps?
Training time means the execution of the training epochs. From random initial model to trained model.
Hi dear Jason Brownlee, Is there any concept of rough set theory in Weka?
Not that I’m aware.
sir i need your help i want to use filters method for features selection to diagnose thyroid disease. please suggusset goofd algortrims???like JMIM ,permutation ,limma,impurity and sym.uncert please tell meh that are good for daignose disease and what classification can i use for best accuracy??????
Good question, I recommend following this process:
https://machinelearningmastery.com/start-here/#process