
Bidirectional LSTMs are an extension of traditional LSTMs that can improve model performance on sequence classification problems.
In problems where all timesteps of the input sequence are available, Bidirectional LSTMs train two instead of one LSTMs on the input sequence. The first on the input sequence as-is and the second on a reversed copy of the input sequence. This can provide additional context to the network and result in faster and even fuller learning on the problem.
In this tutorial, you will discover how to develop Bidirectional LSTMs for sequence classification in Python with the Keras deep learning library.
After completing this tutorial, you will know:
- How to develop a small contrived and configurable sequence classification problem.
- How to develop an LSTM and Bidirectional LSTM for sequence classification.
- How to compare the performance of the merge mode used in Bidirectional LSTMs.
Kick-start your project with my new book Long Short-Term Memory Networks With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
- Update Jan/2020: Updated API for Keras 2.3 and TensorFlow 2.0.

How to Develop a Bidirectional LSTM For Sequence Classification in Python with Keras
Photo by Cristiano Medeiros Dalbem, some rights reserved.
Overview
This tutorial is divided into 6 parts; they are:
- Bidirectional LSTMs
- Sequence Classification Problem
- LSTM For Sequence Classification
- Bidirectional LSTM For Sequence Classification
- Compare LSTM to Bidirectional LSTM
- Comparing Bidirectional LSTM Merge Modes
Environment
This tutorial assumes you have a Python SciPy environment installed. You can use either Python 2 or 3 with this example.
This tutorial assumes you have Keras (v2.0.4+) installed with either the TensorFlow (v1.1.0+) or Theano (v0.9+) backend.
This tutorial also assumes you have scikit-learn, Pandas, NumPy, and Matplotlib installed.
If you need help setting up your Python environment, see this post:
Need help with LSTMs for Sequence Prediction?
Take my free 7-day email course and discover 6 different LSTM architectures (with code).
Click to sign-up and also get a free PDF Ebook version of the course.
Bidirectional LSTMs
The idea of Bidirectional Recurrent Neural Networks (RNNs) is straightforward.
It involves duplicating the first recurrent layer in the network so that there are now two layers side-by-side, then providing the input sequence as-is as input to the first layer and providing a reversed copy of the input sequence to the second.
To overcome the limitations of a regular RNN […] we propose a bidirectional recurrent neural network (BRNN) that can be trained using all available input information in the past and future of a specific time frame.
…
The idea is to split the state neurons of a regular RNN in a part that is responsible for the positive time direction (forward states) and a part for the negative time direction (backward states)
— Mike Schuster and Kuldip K. Paliwal, Bidirectional Recurrent Neural Networks, 1997
This approach has been used to great effect with Long Short-Term Memory (LSTM) Recurrent Neural Networks.
The use of providing the sequence bi-directionally was initially justified in the domain of speech recognition because there is evidence that the context of the whole utterance is used to interpret what is being said rather than a linear interpretation.
… relying on knowledge of the future seems at first sight to violate causality. How can we base our understanding of what we’ve heard on something that hasn’t been said yet? However, human listeners do exactly that. Sounds, words, and even whole sentences that at first mean nothing are found to make sense in the light of future context. What we must remember is the distinction between tasks that are truly online – requiring an output after every input – and those where outputs are only needed at the end of some input segment.
— Alex Graves and Jurgen Schmidhuber, Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures, 2005
The use of bidirectional LSTMs may not make sense for all sequence prediction problems, but can offer some benefit in terms of better results to those domains where it is appropriate.
We have found that bidirectional networks are significantly more effective than unidirectional ones…
— Alex Graves and Jurgen Schmidhuber, Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures, 2005
To be clear, timesteps in the input sequence are still processed one at a time, it is just the network steps through the input sequence in both directions at the same time.
Bidirectional LSTMs in Keras
Bidirectional LSTMs are supported in Keras via the Bidirectional layer wrapper.
This wrapper takes a recurrent layer (e.g. the first LSTM layer) as an argument.
It also allows you to specify the merge mode, that is how the forward and backward outputs should be combined before being passed on to the next layer. The options are:
- ‘sum‘: The outputs are added together.
- ‘mul‘: The outputs are multiplied together.
- ‘concat‘: The outputs are concatenated together (the default), providing double the number of outputs to the next layer.
- ‘ave‘: The average of the outputs is taken.
The default mode is to concatenate, and this is the method often used in studies of bidirectional LSTMs.
Sequence Classification Problem
We will define a simple sequence classification problem to explore bidirectional LSTMs.
The problem is defined as a sequence of random values between 0 and 1. This sequence is taken as input for the problem with each number provided one per timestep.
A binary label (0 or 1) is associated with each input. The output values are all 0. Once the cumulative sum of the input values in the sequence exceeds a threshold, then the output value flips from 0 to 1.
A threshold of 1/4 the sequence length is used.
For example, below is a sequence of 10 input timesteps (X):
|
1 |
0.63144003 0.29414551 0.91587952 0.95189228 0.32195638 0.60742236 0.83895793 0.18023048 0.84762691 0.29165514 |
The corresponding classification output (y) would be:
|
1 |
0 0 0 1 1 1 1 1 1 1 |
We can implement this in Python.
The first step is to generate a sequence of random values. We can use the random() function from the random module.
|
1 2 |
# create a sequence of random numbers in [0,1] X = array([random() for _ in range(10)]) |
We can define the threshold as one-quarter the length of the input sequence.
|
1 2 |
# calculate cut-off value to change class values limit = 10/4.0 |
The cumulative sum of the input sequence can be calculated using the cumsum() NumPy function. This function returns a sequence of cumulative sum values, e.g.:
|
1 |
pos1, pos1+pos2, pos1+pos2+pos3, ... |
We can then calculate the output sequence as whether each cumulative sum value exceeded the threshold.
|
1 2 |
# determine the class outcome for each item in cumulative sequence y = array([0 if x < limit else 1 for x in cumsum(X)]) |
The function below, named get_sequence(), draws all of this together, taking as input the length of the sequence, and returns the X and y components of a new problem case.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from random import random from numpy import array from numpy import cumsum # create a sequence classification instance def get_sequence(n_timesteps): # create a sequence of random numbers in [0,1] X = array([random() for _ in range(n_timesteps)]) # calculate cut-off value to change class values limit = n_timesteps/4.0 # determine the class outcome for each item in cumulative sequence y = array([0 if x < limit else 1 for x in cumsum(X)]) return X, y |
We can test this function with a new 10 timestep sequence as follows:
|
1 2 3 |
X, y = get_sequence(10) print(X) print(y) |
Running the example first prints the generated input sequence followed by the matching output sequence.
|
1 2 3 |
[ 0.22228819 0.26882207 0.069623 0.91477783 0.02095862 0.71322527 0.90159654 0.65000306 0.88845226 0.4037031 ] [0 0 0 0 0 0 1 1 1 1] |
LSTM For Sequence Classification
We can start off by developing a traditional LSTM for the sequence classification problem.
Firstly, we must update the get_sequence() function to reshape the input and output sequences to be 3-dimensional to meet the expectations of the LSTM. The expected structure has the dimensions [samples, timesteps, features].
The classification problem has 1 sample (e.g. one sequence), a configurable number of timesteps, and one feature per timestep.
Therefore, we can reshape the sequences as follows.
|
1 2 3 |
# reshape input and output data to be suitable for LSTMs X = X.reshape(1, n_timesteps, 1) y = y.reshape(1, n_timesteps, 1) |
The updated get_sequence() function is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# create a sequence classification instance def get_sequence(n_timesteps): # create a sequence of random numbers in [0,1] X = array([random() for _ in range(n_timesteps)]) # calculate cut-off value to change class values limit = n_timesteps/4.0 # determine the class outcome for each item in cumulative sequence y = array([0 if x < limit else 1 for x in cumsum(X)]) # reshape input and output data to be suitable for LSTMs X = X.reshape(1, n_timesteps, 1) y = y.reshape(1, n_timesteps, 1) return X, y |
We will define the sequences as having 10 timesteps.
Next, we can define an LSTM for the problem. The input layer will have 10 timesteps with 1 feature a piece, input_shape=(10, 1).
The first hidden layer will have 20 memory units and the output layer will be a fully connected layer that outputs one value per timestep. A sigmoid activation function is used on the output to predict the binary value.
A TimeDistributed wrapper layer is used around the output layer so that one value per timestep can be predicted given the full sequence provided as input. This requires that the LSTM hidden layer returns a sequence of values (one per timestep) rather than a single value for the whole input sequence.
Finally, because this is a binary classification problem, the binary log loss (binary_crossentropy in Keras) is used. The efficient ADAM optimization algorithm is used to find the weights and the accuracy metric is calculated and reported each epoch.
|
1 2 3 4 5 |
# define LSTM model = Sequential() model.add(LSTM(20, input_shape=(10, 1), return_sequences=True)) model.add(TimeDistributed(Dense(1, activation='sigmoid'))) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) |
The LSTM will be trained for 1,000 epochs. A new random input sequence will be generated each epoch for the network to be fit on. This ensures that the model does not memorize a single sequence and instead can generalize a solution to solve all possible random input sequences for this problem.
|
1 2 3 4 5 6 |
# train LSTM for epoch in range(1000): # generate new random sequence X,y = get_sequence(n_timesteps) # fit model for one epoch on this sequence model.fit(X, y, epochs=1, batch_size=1, verbose=2) |
Once trained, the network will be evaluated on yet another random sequence. The predictions will be then compared to the expected output sequence to provide a concrete example of the skill of the system.
|
1 2 3 4 5 |
# evaluate LSTM X,y = get_sequence(n_timesteps) yhat = model.predict_classes(X, verbose=0) for i in range(n_timesteps): print('Expected:', y[0, i], 'Predicted', yhat[0, i]) |
The complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
from random import random from numpy import array from numpy import cumsum from keras.models import Sequential from keras.layers import LSTM from keras.layers import Dense from keras.layers import TimeDistributed # create a sequence classification instance def get_sequence(n_timesteps): # create a sequence of random numbers in [0,1] X = array([random() for _ in range(n_timesteps)]) # calculate cut-off value to change class values limit = n_timesteps/4.0 # determine the class outcome for each item in cumulative sequence y = array([0 if x < limit else 1 for x in cumsum(X)]) # reshape input and output data to be suitable for LSTMs X = X.reshape(1, n_timesteps, 1) y = y.reshape(1, n_timesteps, 1) return X, y # define problem properties n_timesteps = 10 # define LSTM model = Sequential() model.add(LSTM(20, input_shape=(n_timesteps, 1), return_sequences=True)) model.add(TimeDistributed(Dense(1, activation='sigmoid'))) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # train LSTM for epoch in range(1000): # generate new random sequence X,y = get_sequence(n_timesteps) # fit model for one epoch on this sequence model.fit(X, y, epochs=1, batch_size=1, verbose=2) # evaluate LSTM X,y = get_sequence(n_timesteps) yhat = model.predict_classes(X, verbose=0) for i in range(n_timesteps): print('Expected:', y[0, i], 'Predicted', yhat[0, i]) |
Running the example prints the log loss and classification accuracy on the random sequences each epoch.
This provides a clear idea of how well the model has generalized a solution to the sequence classification problem.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
We can see that the model does well, achieving a final accuracy that hovers around 90% and 100% accurate. Not perfect, but good for our purposes.
The predictions for a new random sequence are compared to the expected values, showing a mostly correct result with a single error.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
... Epoch 1/1 0s - loss: 0.2039 - acc: 0.9000 Epoch 1/1 0s - loss: 0.2985 - acc: 0.9000 Epoch 1/1 0s - loss: 0.1219 - acc: 1.0000 Epoch 1/1 0s - loss: 0.2031 - acc: 0.9000 Epoch 1/1 0s - loss: 0.1698 - acc: 0.9000 Expected: [0] Predicted [0] Expected: [0] Predicted [0] Expected: [0] Predicted [0] Expected: [0] Predicted [0] Expected: [0] Predicted [0] Expected: [0] Predicted [1] Expected: [1] Predicted [1] Expected: [1] Predicted [1] Expected: [1] Predicted [1] Expected: [1] Predicted [1] |
Bidirectional LSTM For Sequence Classification
Now that we know how to develop an LSTM for the sequence classification problem, we can extend the example to demonstrate a Bidirectional LSTM.
We can do this by wrapping the LSTM hidden layer with a Bidirectional layer, as follows:
|
1 |
model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=(n_timesteps, 1))) |
This will create two copies of the hidden layer, one fit in the input sequences as-is and one on a reversed copy of the input sequence. By default, the output values from these LSTMs will be concatenated.
That means that instead of the TimeDistributed layer receiving 10 timesteps of 20 outputs, it will now receive 10 timesteps of 40 (20 units + 20 units) outputs.
The complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
from random import random from numpy import array from numpy import cumsum from keras.models import Sequential from keras.layers import LSTM from keras.layers import Dense from keras.layers import TimeDistributed from keras.layers import Bidirectional # create a sequence classification instance def get_sequence(n_timesteps): # create a sequence of random numbers in [0,1] X = array([random() for _ in range(n_timesteps)]) # calculate cut-off value to change class values limit = n_timesteps/4.0 # determine the class outcome for each item in cumulative sequence y = array([0 if x < limit else 1 for x in cumsum(X)]) # reshape input and output data to be suitable for LSTMs X = X.reshape(1, n_timesteps, 1) y = y.reshape(1, n_timesteps, 1) return X, y # define problem properties n_timesteps = 10 # define LSTM model = Sequential() model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=(n_timesteps, 1))) model.add(TimeDistributed(Dense(1, activation='sigmoid'))) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # train LSTM for epoch in range(1000): # generate new random sequence X,y = get_sequence(n_timesteps) # fit model for one epoch on this sequence model.fit(X, y, epochs=1, batch_size=1, verbose=2) # evaluate LSTM X,y = get_sequence(n_timesteps) yhat = model.predict_classes(X, verbose=0) for i in range(n_timesteps): print('Expected:', y[0, i], 'Predicted', yhat[0, i]) |
Running the example, we see a similar output as in the previous example.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
The use of bidirectional LSTMs have the effect of allowing the LSTM to learn the problem faster.
This is not apparent from looking at the skill of the model at the end of the run, but instead, the skill of the model over time.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
... Epoch 1/1 0s - loss: 0.0967 - acc: 0.9000 Epoch 1/1 0s - loss: 0.0865 - acc: 1.0000 Epoch 1/1 0s - loss: 0.0905 - acc: 0.9000 Epoch 1/1 0s - loss: 0.2460 - acc: 0.9000 Epoch 1/1 0s - loss: 0.1458 - acc: 0.9000 Expected: [0] Predicted [0] Expected: [0] Predicted [0] Expected: [0] Predicted [0] Expected: [0] Predicted [0] Expected: [0] Predicted [0] Expected: [1] Predicted [1] Expected: [1] Predicted [1] Expected: [1] Predicted [1] Expected: [1] Predicted [1] Expected: [1] Predicted [1] |
Compare LSTM to Bidirectional LSTM
In this example, we will compare the performance of traditional LSTMs to a Bidirectional LSTM over time while the models are being trained.
We will adjust the experiment so that the models are only trained for 250 epochs. This is so that we can get a clear idea of how learning unfolds for each model and how the learning behavior differs with bidirectional LSTMs.
We will compare three different models; specifically:
- LSTM (as-is)
- LSTM with reversed input sequences (e.g. you can do this by setting the “go_backwards” argument to he LSTM layer to “True”)
- Bidirectional LSTM
This comparison will help to show that bidirectional LSTMs can in fact add something more than simply reversing the input sequence.
We will define a function to create and return an LSTM with either forward or backward input sequences, as follows:
|
1 2 3 4 5 6 |
def get_lstm_model(n_timesteps, backwards): model = Sequential() model.add(LSTM(20, input_shape=(n_timesteps, 1), return_sequences=True, go_backwards=backwards)) model.add(TimeDistributed(Dense(1, activation='sigmoid'))) model.compile(loss='binary_crossentropy', optimizer='adam') return model |
We can develop a similar function for bidirectional LSTMs where the merge mode can be specified as an argument. The default of concatenation can be specified by setting the merge mode to the value ‘concat’.
|
1 2 3 4 5 6 |
def get_bi_lstm_model(n_timesteps, mode): model = Sequential() model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=(n_timesteps, 1), merge_mode=mode)) model.add(TimeDistributed(Dense(1, activation='sigmoid'))) model.compile(loss='binary_crossentropy', optimizer='adam') return model |
Finally, we define a function to fit a model and retrieve and store the loss each training epoch, then return a list of the collected loss values after the model is fit. This is so that we can graph the log loss from each model configuration and compare them.
|
1 2 3 4 5 6 7 8 9 |
def train_model(model, n_timesteps): loss = list() for _ in range(250): # generate new random sequence X,y = get_sequence(n_timesteps) # fit model for one epoch on this sequence hist = model.fit(X, y, epochs=1, batch_size=1, verbose=0) loss.append(hist.history['loss'][0]) return loss |
Putting this all together, the complete example is listed below.
First a traditional LSTM is created and fit and the log loss values plot. This is repeated with an LSTM with reversed input sequences and finally an LSTM with a concatenated merge.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
from random import random from numpy import array from numpy import cumsum from matplotlib import pyplot from pandas import DataFrame from keras.models import Sequential from keras.layers import LSTM from keras.layers import Dense from keras.layers import TimeDistributed from keras.layers import Bidirectional # create a sequence classification instance def get_sequence(n_timesteps): # create a sequence of random numbers in [0,1] X = array([random() for _ in range(n_timesteps)]) # calculate cut-off value to change class values limit = n_timesteps/4.0 # determine the class outcome for each item in cumulative sequence y = array([0 if x < limit else 1 for x in cumsum(X)]) # reshape input and output data to be suitable for LSTMs X = X.reshape(1, n_timesteps, 1) y = y.reshape(1, n_timesteps, 1) return X, y def get_lstm_model(n_timesteps, backwards): model = Sequential() model.add(LSTM(20, input_shape=(n_timesteps, 1), return_sequences=True, go_backwards=backwards)) model.add(TimeDistributed(Dense(1, activation='sigmoid'))) model.compile(loss='binary_crossentropy', optimizer='adam') return model def get_bi_lstm_model(n_timesteps, mode): model = Sequential() model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=(n_timesteps, 1), merge_mode=mode)) model.add(TimeDistributed(Dense(1, activation='sigmoid'))) model.compile(loss='binary_crossentropy', optimizer='adam') return model def train_model(model, n_timesteps): loss = list() for _ in range(250): # generate new random sequence X,y = get_sequence(n_timesteps) # fit model for one epoch on this sequence hist = model.fit(X, y, epochs=1, batch_size=1, verbose=0) loss.append(hist.history['loss'][0]) return loss n_timesteps = 10 results = DataFrame() # lstm forwards model = get_lstm_model(n_timesteps, False) results['lstm_forw'] = train_model(model, n_timesteps) # lstm backwards model = get_lstm_model(n_timesteps, True) results['lstm_back'] = train_model(model, n_timesteps) # bidirectional concat model = get_bi_lstm_model(n_timesteps, 'concat') results['bilstm_con'] = train_model(model, n_timesteps) # line plot of results results.plot() pyplot.show() |
Running the example creates a line plot.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
We can see that the LSTM forward (blue) and LSTM backward (orange) show similar log loss over the 250 training epochs.
We can see that the Bidirectional LSTM log loss is different (green), going down sooner to a lower value and generally staying lower than the other two configurations.
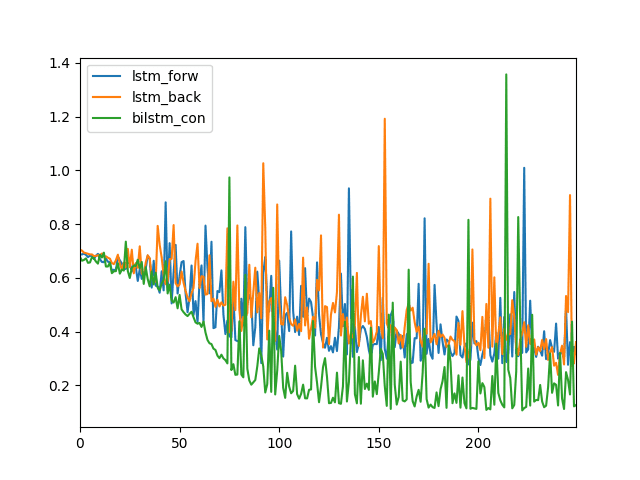
Line Plot of Log Loss for an LSTM, Reversed LSTM and a Bidirectional LSTM
Comparing Bidirectional LSTM Merge Modes
There a 4 different merge modes that can be used to combine the outcomes of the Bidirectional LSTM layers.
They are concatenation (default), multiplication, average, and sum.
We can compare the behavior of different merge modes by updating the example from the previous section as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
n_timesteps = 10 results = DataFrame() # sum merge model = get_bi_lstm_model(n_timesteps, 'sum') results['bilstm_sum'] = train_model(model, n_timesteps) # mul merge model = get_bi_lstm_model(n_timesteps, 'mul') results['bilstm_mul'] = train_model(model, n_timesteps) # avg merge model = get_bi_lstm_model(n_timesteps, 'ave') results['bilstm_ave'] = train_model(model, n_timesteps) # concat merge model = get_bi_lstm_model(n_timesteps, 'concat') results['bilstm_con'] = train_model(model, n_timesteps) # line plot of results results.plot() pyplot.show() |
Running the example will create a line plot comparing the log loss of each merge mode.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
The different merge modes result in different model performance, and this will vary depending on your specific sequence prediction problem.
In this case, we can see that perhaps a sum (blue) and concatenation (red) merge mode may result in better performance, or at least lower log loss.
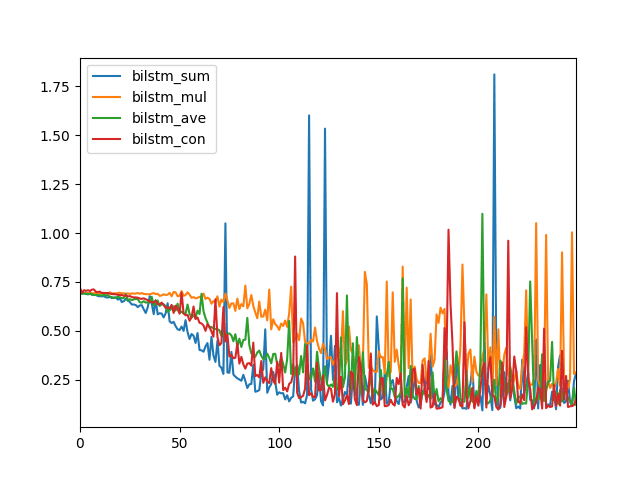
Line Plot to Compare Merge Modes for Bidirectional LSTMs
Summary
In this tutorial, you discovered how to develop Bidirectional LSTMs for sequence classification in Python with Keras.
Specifically, you learned:
- How to develop a contrived sequence classification problem.
- How to develop an LSTM and Bidirectional LSTM for sequence classification.
- How to compare merge modes for Bidirectional LSTMs for sequence classification.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop LSTMs for Sequence Prediction Today!

Develop Your Own LSTM models in Minutes
...with just a few lines of python code
Discover how in my new Ebook:
Long Short-Term Memory Networks with Python
It provides self-study tutorials on topics like:
CNN LSTMs, Encoder-Decoder LSTMs, generative models, data preparation, making predictions and much more...
Finally Bring LSTM Recurrent Neural Networks to
Your Sequence Predictions Projects
Skip the Academics. Just Results.






Great post! Do you think bidirectional LSTMs can be used for time series prediciton problems?
Yes, the question is, can they lift performance on your problem. Try it and see.
Thanks,is there a torch based implementation case?Looking forward to receiving the latest learning website!
This might help as a starting point:
https://machinelearningmastery.com/pytorch-tutorial-develop-deep-learning-models/
Greatest ,thank you
I’m glad it helped!
hi Jason,
In fact, I usually need to use multi thread ( multi worker) for load model Keras for improve performance for my system. But when I use multi thread to work with model Keras, its so error with graph, so I used multi process instead. I wana ask you have another solution for multi worker with Keras? Hope you can understand what i say.
Thank you.
Yes, I would recommend using GPUs on AWS:
https://machinelearningmastery.com/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/
Thanks, Jason, such a great post !
You’re welcome Yitzhak.
hi Jason, thanks greatly for your work. I’ve read probably 50 of your blog articles!
I’m still struggling to understand how to reshape lagged data for LSTM and would greatly appreciate your help.
I’m working on sequence classification on time-series data over multiple days. I’ve lagged the data together (2D) and created differential features using code very similar to yours, and generated multiple look forward and look backward features over a window of about +5 and -4:
# frame a sequence as a supervised learning problem
def timeseries_to_supervised(data, lag=1):
df = DataFrame(data)
columns = [df.shift(i) for i in range(1, lag+1)]
columns.append(df)
df = concat(columns, axis=1)
return df
I’ve gotten decent results with Conv1D residual networks on my dataset, but my experiments with LSTM are total failures.
I reshape the data for Conv1D like so:
X = X.reshape(X.shape[0], X.shape[1], 1)Is this same data shape appropriate for LSTM or Bidirectional LSTM? I think it needs to be different, but I cannot figure out how despite hours of searching.
Thanks for your assistance if any!
By the way, my question is not a prediction task – it’s multi class classification: looking at a particular day’s data in combination with surrounding lagged/diff’d day’s data and saying it is one of 10 different types of events.
Great. Sequence classification.
One day might be one sequence and be comprised of lots of time steps for lots of features.
Thanks John!
Are you working on a sequence classification problem or sequence regression problem? Do you want to classify a whole sequence or predict the next value in the sequence? This will determine the type of LSTM you want.
The input to LSTMs is 3d with the form [samples, time steps, features].
Samples are sequences.
Time steps are lag obs.
Features are things measured at each time step.
Does that help?
Hello Jason,
Thank you for this blog .
i want to use a 2D LSTM (the same as gridlstm or multi diagonal LSTM) after CNN,the input is image with 3D RGB (W * H * D)
does the keras develop GridLSTM or multi-directional LSTM.
i saw the tensorflow develop the GridLSTM.can link it into keras?
Thank you.
You can use a CNN as a front-end model for LSTM.
Sorry, I’ve not heard of “grid lstm” or “multi-directional lstm”.
Nice post, Jason! I have two questions:
1.- May Bidirectional() work in a regression model without TimeDistributed() wrapper?
2.- May I have two Bidirectional() layers, or the model would be a far too complex?
3.- Does Bidirectional() requires more input data to train?
Thank you in advance! 🙂
Hi Marianico,
1. sure.
2. you can if you want, try it.
3. it may, test this assumption.
Thank you so much Mr Jason!
You’re welcome.
very nice post, Jason. I am working on a CNN+LSTM problem atm. This post is really helpful.
By the way, do you have some experience of CNN + LSTM for sequence classification. The inputs are frames of medical scans over time.
We are experiencing a quick overfitting (95% accuracy after 5 epochs).
What is the best practice to slow down the overfitting?
Yes, I have a small example in my book.
Consider dropout and other forms of regularization. Also try larger batch sizes.
Let me know how you go.
Hi Jason! First of all congratulations on your work, I have been learning a lot through your posts.
Regarding this topic: I am handling a problem where I have time series with different size, and I want to binary classify each fixed-size window of each time series.
I know that n_timesteps should be the fixed-size of the window, but then I will have a different number of samples for each time series. A solution might be defining a fixed sample size and add “zero” windows to smaller time series, but I would like to know if there are other options. Do you have any suggestion to overcome this problem?
Thanks in advance!
Hi Ed, yes, use zero padding and a mask to ignore zero values.
If you know you need to make a prediction every n steps, consider splitting each group of n steps into separate samples of length n. It will make modeling so much easier.
Let me know how you go.
Hello Jason,
I have a question on how to output each timestep of a sequence using LSTM. My problem is 0-1 classification. All I want to do is for one sample (a sequence) to output many labels (corresponding to this sequence). My data are all 3D, including labels and input. But the output I got is wrong. All of them (predicted labels) were 0.
Here is my code:
###
model = Sequential()
model.add(Masking(mask_value= 0,input_shape=(maxlen,feature_dim)))
model.add (LSTM(int(topos[0]), activation=act, kernel_initializer=’normal’, return_sequences=True))
model.add(TimeDistributed(Dense(1, activation=’sigmoid’)))
model.compile(loss=’binary_crossentropy’, optimizer=opt, metrics=[‘accuracy’])
model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, callbacks=[tensorboard], validation_data=(x_val,y_val), shuffle=True, initial_epoch=0)
###
Is this right? Thank you so much.
Perhaps you need a larger model, more training, more data, etc…
Here are some ideas:
https://machinelearningmastery.com/improve-deep-learning-performance/
very good post,I am trying to try it.
Thanks.
Hi Jason
Are we feeding one sequence value[i.e sequence[i]] at each time step into the LSTM? If this is true, does this sequence[i] go through all the memory units in the LSTM? Or does it progressively go through each memory unit as timesteps are incremented?
Thanks
Each input is passed through all units in the layer at the same time.
Great post, Jason. I learn best from examples. I bought a series of your books and feel like I have learned more from them then actual courses and am very satisfied with them.
Thanks Jacob, I write to help people and it is great to hear that it is helping!
Hi Jason
I’m looking into predicting a cosine series based on input sine series
I tried redefining the get_sequence as follows:
in the main i changed the loss function to use MSE as ‘binary_crossentropy’ to my understanding produces a 0/1 loss and I’m looking at a continues function use case
model.compile(loss=’mean_squared_error’, optimizer=’adam’, metrics=[‘acc’])
Alas the model doesn’t converge and results in binary like results.
Expected: [ 0.55061242] Predicted [1]
Any suggestions ?
BR
Ami
Full modified code:
===============
I have a long list of general ideas here:
https://machinelearningmastery.com/improve-deep-learning-performance/
Thanks for the awesome article. Wondering if you have one for Bidirectional LSTMs in language translation? Curious as I have seen some use the Bidirectional in both encoder and decoder, and some in just the encoder.
This may help you to get started:
https://machinelearningmastery.com/develop-bidirectional-lstm-sequence-classification-python-keras/
we dont need to modify anything ….just put bidirectional layer…that’t it ….is there anything we have to modify in different problems like [Neural machine translation]…
Not really.
how to add attention layer in decoder…..that thing also one line of code i think…
See these posts:
https://machinelearningmastery.com/?s=attention&submit=Search
Jason,
Is bidirectional lstm and bidirectional rnn one and the same?
A bidirectional LSTM is a bidirectional RNN. A bidirectional GRU is also a bidirectional RNN.
Hello Jason,
thanks for a very clear and informative post.
My data consists of many time-series of different lengths, which may be very different and grow quite large – from minutes to more than an hour of 1 Hz samples.
Is there a way, therefore, not to specify n_timesteps in the definition of the model, as it doesn’t really need it then, but only when fitting or predicting?
I really wouldn’t want to arbitrarily cut my sequences or pad them with a lot of unnecessary “zeros”.
By the way, I’m trying to detect rather rare occurrences of some event(s) along the sequence; hopefully a sigmoid predicted probability with an appropriate threshold would do the trick.
Thanks,
Ehud.
You can pad with zeros and use a Mask to ignore the zero values.
I have many examples on the blog.
sir, can bidirectional lstm be used for sequence or time series forecasting?
Perhaps, try it and see.
Do you need the full data sequence at test time, or can it be run on each input online?
Another way of asking this is: is Bidirectional LSTM just a modification at training time, or does it limit you to having the full sequence for classification?
Thanks!
It depends what the model expects to receive as input in order to make a prediction.
Thank you Jason. It’s great for me as a beginner of LSTM. Thank you so much.
My RQ is about grammatical error detection, eg. people who are good at maths has more chances to succeed. How to detect “has” in this sentence is wrong? This problem is quite different from the example you give.
My proposal is that: first find the verb “has” by a postagger, then vectorize the left context “people who are good at maths” and train lstm, then vectorize the right context backwords “more chances to succeed ” and train lstm. Finally, predcit the word “has” as 0 or 1. Is this a bi-lstm?
If it is, we have so many sentences with different length and the input size is changable, how to deal with this prob? Especially, samples are the total sentences, and what are the timesteps and features?
Sounds like a fun project.
For variable length input sequences, I would recommend zero-padding and using a masking input layer to ignore the zero inputs.
More info here:
https://machinelearningmastery.com/data-preparation-variable-length-input-sequences-sequence-prediction/
When you train a model with the go_backwards flag set on the LSTM layer, is the prediction reversed when you make a prediction on the model? Or does the prediction come out forwards?
It comes out normally.
Think of the time series as a sequence used to predict the next step. We have the whole sequence in memory, so we can read it forward or backward or even in a stateless (time independent) way – all in order to predict the next step.
Does that help?
Good stuff it clearly explains how to use bidirectional lstm. Hope this code works with the current version of tensorflow and keras as of the time of this writing
You’re welcome.
My code works fine. I keep all tutorials updated, when issues are pointed out.
why is it when doing model.add(TimeDistributed(Dense(2, activation=’sigmoid’)) doesn’t work.. Please explain
What is the problem?
Perhaps post your code and error to stackoverflow?
Oops..sorry. Have reasoned it out. Thanks though for the tutorial.
Glad to hear it.
sir ,
I am working on an RNN that can tell word beginning and ending.
Let me explain.
For training, I have wav file containing a sentence (say I am a person) and a group of words. I also have information which says that word ‘I’ appear in interval [20-30], am in [50-70] , ‘a’ in [85-90] and ‘person’ in [115-165] timsteps.
Now I want RNN to find word position in unknown sentence.
It does not have to tell what the word is , just the beginning and end of it.
So number of classes will be atleast three because a timestep can be classified as word_beginning,word_end,something_else.
Something_else may indicate silence zone or time inside a word.
So far , I have considered of splitting wav file into sequence of overlapping windows.
mfcc allows – successive 25 ms windows with overlap of 15ms by default so we can get 13 or 26 mfcc coefficients at each time step.
it is not a binary classification problem as there are multiple classes involved.
Need your thoughts on this .
Thanks for listening.
Sounds like a great problem and a good start.
I expect a lot of model tuning will be required.
Let me know how you go.
sir , i need your expert opinion on this.
Currently i am casting it into binary classification.
Simply the data is split into middle (=frames inside a spoken word)and ending(=frames at word boundary)
I am hoping that silence between two words will be learnt as class ‘ending’.
But it is not working.
It seems that the neural network is classifying everything as ‘middle’ . Though I have given 38k samples of both classes in training folder.
I think , I am doing something basic wrong here.
here is the code
[code]
import math
import os
import random
from python_speech_features import mfcc
import scipy.io.wavfile as wav
import numpy as np
import tensorflow as tf
from scipy import stats
import re
WORD_LIST=[‘middle’,’ending’]
TEST_WORD_LIST=[‘middle’,’ending’]
MAX_STEPS=11
BATCH_SIZE=500
EPOCH=5000
INTERVAL=1
test_input=[]
train_input=[]
train_output=[]
test_output=[]
deviation_list=[]
def create_test_data(word):
index = WORD_LIST.index(word) if word in WORD_LIST else -1
files = os.listdir(‘/home/lxuser/test_data/’+word)
length_of_folder=len(files)
interval=INTERVAL
j=0
for i in range(int(length_of_folder/interval)):
filecount=int(math.floor(j))
(test_rate,test_sig) = wav.read(‘/home/lxuser/test_data/’+word+’/’+files[filecount])
test_mfcc_feat = mfcc(test_sig,test_rate,numcep=26)
sth=test_mfcc_feat.shape[0]
test_padded_array=np.pad(test_mfcc_feat,[(MAX_STEPS-sth,0),(0,0)],’constant’)
test_input.append(test_padded_array)
temp_list = [0]*2
temp_list[index]=1
test_output.append(temp_list)
if(word==’middle’):
deviation_list.append(-1)
else:
value=int(re.search(r’\d+’,files[filecount]).group())
deviation_list.append(value)
j=j+interval
if(j>length_of_folder-1):
j=0
def make_train_data(word):
int_class = WORD_LIST.index(word) if word in WORD_LIST else -1
files = os.listdir(‘/home/lxuser/train_dic/’+word)
length_of_folder=len(files)
interval=INTERVAL
random.shuffle(files)
j=0
for i in range(int(length_of_folder/interval)):
(train_rate,train_sig) = wav.read(‘/home/lxuser/train_dic/’+word+’/’+files[int(math.floor(j))])
# print(word,files[int(math.floor(j))],’in training’)
train_mfcc_feat = mfcc(train_sig,train_rate,numcep=26)
train_test_mfcc_feat=train_mfcc_feat
sth=train_mfcc_feat.shape[0]
train_padded_array=np.pad(train_mfcc_feat,[(MAX_STEPS-sth,0),(0,0)],’constant’)
train_input.append(train_padded_array)
temp_list = [0]*2
temp_list[int_class]=1
train_output.append(temp_list)
j=j+interval
if(j>length_of_folder-1):
j=0
def shuffletrain():
rng_state = np.random.get_state()
np.random.shuffle(train_input)
np.random.set_state(rng_state)
np.random.shuffle(train_output)
if __name__== “__main__”:
for i in WORD_LIST:
make_train_data(i)
for i in TEST_WORD_LIST:
create_test_data(i)
shuffletrain()
print “test and training data loaded”
data = tf.placeholder(tf.float32, [None, MAX_STEPS,26]) #Number of examples, number of input, dimension of each input
target = tf.placeholder(tf.float32, [None, 2])
num_hidden = 128
cell = tf.nn.rnn_cell.LSTMCell(num_hidden,state_is_tuple=True)
val, _ = tf.nn.dynamic_rnn(cell, data, dtype=tf.float32)
val = tf.transpose(val, [1, 0, 2])
last = tf.gather(val, int(val.get_shape()[0]) – 1)
weight = tf.Variable(tf.truncated_normal([num_hidden, int(target.get_shape()[1])]))
bias = tf.Variable(tf.constant(0.1, shape=[target.get_shape()[1]]))
prediction = tf.nn.softmax(tf.matmul(last, weight) + bias)
cross_entropy = -tf.reduce_sum(target * tf.log(tf.clip_by_value(prediction,1e-10,1.0)))
optimizer = tf.train.AdamOptimizer()
minimize = optimizer.minimize(cross_entropy)
mistakes = tf.not_equal(tf.argmax(target, 1), tf.argmax(prediction, 1))
error = tf.reduce_mean(tf.cast(mistakes, tf.float32))
if True:
print(‘starting fresh model’)
init_op = tf.initialize_all_variables()
saver = tf.train.Saver()
sess = tf.Session()
sess.run(init_op)
#saver.restore(sess, “./1840frames-example-two-class-ten-from-each-model-2870.ckpt”)
incorrect = sess.run(error,{data: train_input, target: train_output})
print(‘Train error with now {:3.9f}%’.format(100 * incorrect))
incorrect = sess.run(error,{data: test_input, target: test_output})
print(‘test error with now {:3.9f}%’.format(100 * incorrect))
batch_size = BATCH_SIZE
no_of_batches = int(len(train_input)) / batch_size
for i in range(1000000):
print “Epoch “,str(i)
ptr = 0
for j in range(no_of_batches):
inp, out = train_input[ptr:ptr+batch_size], train_output[ptr:ptr+batch_size]
ptr+=batch_size
sess.run(minimize,{data: inp, target: out})
if((i!=0)and(i%10==0)):
true_count=0
false_count=0
deviation=0
for test_count in range(len(test_output)):
test_result_i=sess.run(prediction,{data:[test_input[test_count]]})
guess_class=np.argmax(test_result_i)
true_class=np.argmax(test_output[test_count])
print(‘true class guess class’,true_class,guess_class)
if(guess_class==true_class):
true_count+=1
if(true_class==1):
true_position=deviation_list[test_count]
predicted_position=920
deviation+=np.absolute(true_position-predicted_position)
#print(‘truepos’,true_position,’deviation so far’,deviation)
else:
false_count+=1
print(‘true_count’,true_count,’false_count’,false_count,’deviation’,deviation)
incorrect = sess.run(error,{data: train_input, target: train_output})
print(‘Epoch {:2d} train error {:3.1f}%’.format(i , 100 * incorrect))
incorrect = sess.run(error,{data: test_input, target: test_output})
print(‘Epoch {:2d} test error {:3.1f}%’.format(i , 100 * incorrect))
save_path = saver.save(sess, “./1840frames-example-true-two-class-ten-from-each-model-%d.ckpt” % i)
print(“Model saved in path: %s” % save_path)
sess.close()
[/code]
I am sure – you will point my mistake quickly .
Here I am loading data for each class from wav files in corresponding folder.
Deviation is simply for stats of result.
You can ignore that.
If my code is not understandable, please let me know.
Here neural network makes decision from 11 time steps each having 26 values.
Is hidden=128 okay ?
Thanks.
Here are some general ideas to try:
https://machinelearningmastery.com/improve-deep-learning-performance/
it seems to be memorising input so that train error falls to 0% quickly but in test it classifies everything as class zero .
thanks for listening.
Sounds like overfitting.
i want the network to understand that if it encounters data containing silence in any part then it should call it class 1 no matter even if all the other data suggests class 0 .
Sorry for frequent replies.
Thanks.
Perhaps brainstorm different ways of framing this as a supervised learning problem first:
https://machinelearningmastery.com/how-to-define-your-machine-learning-problem/
Thank you Jason, great post. What do you think about Bi-Directional LSTM models for sentiment analysis, like classify labels as positive, negative and neutral? There are a lot of research papers that use simple LSTM models for this, but there are barley no for BiLSTM models (mainly speech recognition). So is it not really worth it for this task?
Not really needed, see this post:
https://machinelearningmastery.com/best-practices-document-classification-deep-learning/
Nevertheless, run some experiments and try bidirectional. Experiments are cheap.
Hi Jason!
Thanks for the post.
Does a bidirectional LSTM requires the whole series as input or only sequences?
series input: x[t] with t=[0..n] a complete measurement/simulation.
sequences input: x[t] with t=[0..10], [10..20], …[n-10, n], seq_length = 10.
In the second option, it can be used for online prediction tasks, where future inputs are unknown.
LSTMs and Bidirectional LSTMs both that a single sample as input, which might be the sequence or a subsequence, depending on your prediction problem.
Incredible work Jason!
– especially love the test LSTM vanilla vs. LSTM reversed vs. LSTM bidirectional.
– even 1 year later I see nobody covering this (Andrew Ng, Advanced NLP Udemy, Udacity NLP).
– your post made me just re-re-re-re-read your LSTM book
Franco
PS: interesting idea from Francois Chollet for NLP: 1D-CNN + LSTM Bidirectional for text classification where word order matters (otherwise no LSTM needed).
Thanks!
Yes, I am currently writing about 1D cnns myself, they are very effective.
Also, I have a ton on them already, start here:
https://machinelearningmastery.com/develop-word-embedding-model-predicting-movie-review-sentiment/
And here:
https://machinelearningmastery.com/develop-n-gram-multichannel-convolutional-neural-network-sentiment-analysis/
And here:
https://machinelearningmastery.com/best-practices-document-classification-deep-learning/
Hi Jason,
Thank you your tutorial.
Could you please explain why the number of memory units is larger than the number of time steps. I suppose that they should be identical, because each input connects to each memory unit (https://colah.github.io/posts/2015-08-Understanding-LSTMs/)
Best
Time steps and the number of units in the first hidden layer of the network are unrelated.
Hi Jason,
Thank for your quick reply.
I suppose that an input at timestep t, i.e. x(t), connects to a memory unit U(t). If the input sample contains N timesteps, N memory units are required correspondingly.
U(0) -> U(1) -> … -> U(N-1)
^ ^ ^
x(0) -> x(1) -> … -> x(N-1)
In your code, the number of units is 20, while the number of timesteps is 10. In this case, how do x connects to U?
Best,
Each time step is processed one at a time by the model.
Each unit in the first hidden layer receives one time step of data at a time.
Hi Jason, thanks for the great explanation! My question:
It appears to me that the Backwards running RNN has no chance to solve the problem at all, or am I missing something? Only the forward running RNN sees the numbers and has a chance to figure out when the limit is exceeded. So why does the bidirectional RNN perform better than forward running RNN?
The bidir model looks at the data twice, forwards and backwards (two perspectives) and gets more of a chance to interpret it.
I think it’s strange that nobody else has brought up this issue or answered it properly for 4 years.
The actual answer to your question is basically that because of the way the sequences are generated the LSTM has about the same chance to find the correct solution going from right to left as going from left to right. This baffled me at first when I looked at the plot comparing the three models (forward, backward and bi), but it’s quite trivial really, just a matter of basic probability theory.
Since the elements of the sequences are taken from a uniform distribution in the range [0.0,1.0), this means that the expected value of each element of the sequence is 0.5, and the expected value of the sum of the elements of a 10-element sequence will be 5. The threshold to switch from 0 to 1 was set to 10 / 4 = 2.5, so it follows that the switch from 0 to 1 (or from 1 to 0 if you’re going backward) will be made on average just after the 5th time step (5 * 0.5 = 2.5) regardless of whether you are going forward or backward.
There is only one plausible explanation for the fact that the LSTM going backward performs just as well as the forward LSTM: the forward LSTM has no idea that it’s supposed to add up the values and make the switch when the sum goes above 2.5. What it learns, just like the backward LSTM, is rather to make the switch after the 5th time step. Since this is where the switch in fact occurs most of the time due to the uniform distribution, both LSTMs guess the correct solution most of the time. However, the huge oscillations in the log loss show that when a sequence of very small or very large numbers happens to be generated, then the strategy followed by the LSTMs of switching right in the middle will fail.
It follows that it should be evident from the comparative plot when the LSTM models go beyond predicting all 0s up to element 5 and all 1s after it. That this happens would be shown by the fact that the LSTM forward plot clearly drops below the LSTM back plot and starts to oscillate less, i.e. its predictions become more consistent and less guesswork. If you let the training run much longer, this trend starts to show clearly after around 1000 epochs, then the log loss of the forward LSTM reaches that of the bidirectional LSTM (as to be expected) eventually, after 3000 epochs or so, and slowly becomes maybe even marginally better than it. Meanwhile the backward LSTM shows no improvement whatsoever after around 1000 epochs, which means that it has learned the probability-based guessing strategy by then perfectly, and no further improvement is possible by looking at the sequence from right to left.
Hi Jason, thanks a lot for the great article.
I have general question regarding Bidirectional networks and predictions:
Assume I have a game with obstacles at every 3-5 seconds and where depending on the first 30 seconds of the player playing, I have to predict whether the user crashes in an obstacle _i in the next 5 seconds.
I generate a lot of features at each obstacle, one of them being “did the user crash in the last obstacle”.
I now applied Bidirectional LSTM, and get a near 100% performance.
Am I correct that using BiLSTM in this scenario is some sort of “cheating”, because by also using the features of the future, I basically know whether he crashed into this obstacle _i because I can look at the feature “did the user crash into the last obstacle” right after this obstacle _i!
I should therefore not use Bidirectional Networks but rather stick to LSTM/RNNs.
I would greatly appreciate your help,
Bastian
It really depends on how you are framing the problem.
Hi Bastian,
I struggle with a similar problem, also trying to predict with a bidirectional LSTM and getting nearly 100% accuracy on training, but nonsense output on prediction. I too came to the conclusion that a bidirectional LSTM cannot be used that way. The example Jason gives here is somewhat misleading into that direction…
Best, Constanze
Sounds like overfitting of the training data.
What clues might I look for to determine if over-fitting is happening?
Thanks!
Performance on the train set is good and performance on the test set is bad.
Hi Jason, I want to ask how to set the initial state of Bidirectional RNN in Keras?The below is my code and the ‘initial_state’ is set in the third Bidirectional RNN:
encoder_input = ks.layers.Input(shape=(85,))
decoder_input = ks.layers.Input(shape=(85,))
encoder_inputs = Embedding(lenpinyin, 64, input_length=85, mask_zero=True)(encoder_input)
encoder = Bidirectional(LSTM(400, return_sequences=True), merge_mode=’concat’)(encoder_inputs)
encoder_outputs, forward_h, forward_c, backward_h, backward_c = Bidirectional(LSTM(400, return_sequences=True, return_state=True), merge_mode=’concat’)(encoder)
decoder_inputs = Embedding(lentext, 64, input_length=85, mask_zero=True)(decoder_input)
decoder = Bidirectional(LSTM(400, return_sequences=True), merge_mode=’concat’)(decoder_inputs, initial_state=[forward_h, forward_c, backward_h, backward_c])
decoder_outputs, _, _, _, _ = Bidirectional(LSTM(400, return_sequences=True, return_state=True), merge_mode=’concat’)(decoder)
decoder_outputs = TimeDistributed(Dense(lentext, activation=”softmax”))(decoder_outputs)
I have an example here that might help:
https://machinelearningmastery.com/develop-encoder-decoder-model-sequence-sequence-prediction-keras/
Hi Jason,
I am struggling with a particular concept for sequence classification. Suppose I have a list of customer feedback sentences and want to use unsupervised training to group them by their nature (a customer complaint about a certain feature vs. question they ask vs. a general comment, etc.). I basically want to detect whatever their natural groupings might be.
All these models seem to talk about prediction along the timesteps of a sequence, but how does prediction lead to a meaningful grouping (classification) of a sentence? In other words, how do you go from predicting the next word in a sentence to discovering the sentence groups and determining that this sentence belongs to this group vs. another?
Thanks very much!
Sorry, I generally don’t have material on unsupervised methods.
If you can get experts to label thousands of examples, you could then use a supervised learning method.
Hi jason,
You are a godsend in lstms. Really appreciate it and been learning lots.
From looking at the code, can i confirm this is a multi step prediction of the same length as input sequence?
Is the time distributed layer the trick here?
I have been trying to find multi step predictions and i know you have a blog post that does it using stateful = True but i cant seem to use bidrectional with it and limited by batch size needing to be a multiple of training size. Same goes for prediction.
Any explanation would be deeply appreciated.
I recommend this tutorial:
https://machinelearningmastery.com/multi-step-time-series-forecasting-long-short-term-memory-networks-python/
You can simply change the first hidden layer to be a Bidirectional LSTM.
Hi, Jason Thanks for your great article.
I noticed that every epoch you train with new sample. is this necessary?
1) can we train with all data inside each epoch?
2) or at each epoch , I should select only a single sample of my data to fit and this implies that the number of samples=no. of epochs?
You can train the model with the same dataset on each epoch, the chosen problem was just a demonstration.
Hi Jason, I have a question. Normally all inputs fed to BiLSTM are of shape [batch_size, time_steps, input_size]. I am working on a problem of Automatic Essay Grading in which there’s an extra dimension which is number of sentences in each essay. So in my case, a typical batch after embedding using word2vec, is of shape [2,16,25,300]. Here there are 2 essays in each batch (batch_size=2), each essay has 16 sentences, each sentence is 25 words long(time_step=25) and I’m using word2vec of 300 dimensions(input_size=300). So clearly I need to loop this batch over dimension 16 somehow. I have tried for a long time but I haven’t been able to find a way to do it. For example, if you make a loop over tf.nn.bidirectional_dynamic_rnn(), it’ll give error in second iteration saying that tf.nn.bidirectional_dynamic_rnn() kernel already exists. Can you please tell me if there’s any other way to do it? Thanks a lot in advance.
Perhaps you can combine the sentences from one document into a single sequence of words?
No I can’t do that because I have to feed the data on sentence level. Is there any other way?
You could use an autoencoder for the entire document.
You could make a forecast per sentence.
I’ll try that. Meanwhile, can we use tf.map_fn() somehow here? Like we take transpose of the batch and make it [16,2,25,300] and then use above function to send it to the bidirectional lstm. I am not really sure how would I do it though.
I have not done this, perhaps experiment and see what you can come up with.
I think the answer to my problem is pretty simple but I’m getting confused somewhere. If you get some time please do look at my code(https://codeshare.io/5NNB0r). It’s a simple 10 line code so won’t take much of your time. I also tried tf.map_fn() but so far no success. Thanks.
I’m eager to help, but I don’t have the capacity to review code. I get 100s of similar requests via email each day.
Hi Jason, I understand and thank you very much for all your help. You’ll also be glad to know that I managed to get that code working. I used tf.map_fn() to map whole batch to bilstm_layers. Thanks again.
Well done!
Hi Jason and Thank you for another cool post.
I was wondering if you had any good advice for using CNN-biLSTM to recognize action in videos. I’m trying to feed the flow extracted from sequences of 10 frames but the results are disappointing. One concern I have is the (Shuffle = True). I read it’s better to keep it this way but since my sequence is in order I cannot afford to shuffle when reading the input frames/flow. Also, when I try to finetune a CNN with my data the classfication accuracy is low (which is normal since it’s based on frames only) so I wonder if the accuracy matters or if I should just train on my data (regardless of the final accuracy), remove the top layer and use it in my CNN-LSTM ?
Any tips or tutorial on this matter will be super appreciated. Thanks a lot !!
This post will help as a first step:
https://machinelearningmastery.com/cnn-long-short-term-memory-networks/
I have a fuller example in my LSTM book:
https://machinelearningmastery.com/lstms-with-python/
Hi, I am designing a bird sound recognition tool for a University project. It is extracting features using the MFCC feature extraction method, but now I am struggling with the classification part. I have tried Back propagation neural networks but have not had success. Do you think recurrent networks, being good at classifying time series, would be a better solution? There are many repetitive patterns in the extracted features of the bird sounds.
I would recommend trying many different framings of the problem, many different preparations of the data and many different modeling algorithms in order to _discover_ what works best for your specific problem.
This process may help:
https://machinelearningmastery.com/start-here/#process
Excellent post! It helped me to complete the Sequence Model course on Coursera! I was stuck for an hour at the last assignment, could not figure out the Bidirectional LSTM, came to your tutorial and it all made it clear for me. Thank you Jason!
I’m happy that it helped!
Hi, is your code example fit for a multiclass multi label opinion mining classification problem ?
And is it possible to give to the NN a w2v matrix as an input ?
Thanks
The above example is binary classification.
I have examples of multi-class classification. I don’t have examples of multi-label classification at this stage.
Hi Jason,
Good article. I have a question in your above example.
Since Y is (logically) determined by cumsum of the proceeding numbers (e.g. X1, X2, X3 ==> Y3), how can a reverse of LSTM can predict (or benifit) the Y3 from later of the time steps (e.g. X4, X5, X6….), since they are irrelevant from the reverse order?
But from your above lost plot, it shows it does help.
Note: I understand in speech recognition, this concept really helps.
Thanks & Regards,
M.
The bidirectional layer doubles the capacity of the input and by processing the sequence forwards and backwards, it gives more opportunity for model to extract the serial correlation in the observations.
This is phenomenal, but I get a bit confused (my python is quite weak) as I’m following this along with other tutorials and most people tend to do something like “xyz = model.fit(trainx, trainy, batch_size=batch_size, epochs=iterations, verbose=1, validation_data=(testx, testy),”
which is not the case here.
I works great but I cannot find figure out any way to run diagnostics on it (since I can’t seem to connect it to tensorboard without “model.fit(…).” I also would love to be able to make a confusion matrix and a dataframe with actuals and predicted but every guide I’ve found on that seens to require I use the format “model.fit()”
The fit() function returns the model.
The predict() function returns predictions that you can then compare to true values, calculate performance and confusion matrices.
Great Post! But i am interested to learn to build MDLSTM with CNN which can be helpful for the handwritten paragraph recognition without pre-segmentation. It is hard to train and build? Could you kind with me explaining how to build such model and train it in keras.
Sorry, I’m not familiar with “MDLSTM”.
Hi Jason, thanks for the useful post, I was wondering if it’s possible to stack the Bidirectional LSTM (multiple layers) ? If yes, how? Cheers.
Yes, the same as if you were stacking LSTMs.
Like this?
I tried the below but error went like crazy large to million.
model = Sequential()
model.add(Bidirectional(LSTM(50, activation=’relu’, return_sequences=True), input_shape=(n_steps, n_features)))
model.add(Bidirectional(LSTM(50, activation=’relu’)))
model.add(Dense(1))
model.compile(optimizer=’adam’, loss=’mse’)
Perhaps the model requires tuning for your problem?
I see, so there’s no problem with the structure of the codes? Or the model?
Looks fine from a glance, but I don’t have the capacity to run or debug your posted code.
Try this code with number of epoch=300 and n_steps =50, may be in this way your code do work fine
Hi! Great post! I have a sequence classification problem, where the length of the input sequence may vary! I read your article on preparation of variable length sequences, but the problem is if I truncate long sequences, I will not be able to classify those values. (The values lost from the truncation). Is there a solution for this problem?
Perhaps try zero padding and add a Masking layer to the input.
Masking layer should do! Thanks a lot!
Do you have a suggestion for dealing with very long sequences after masking for classification? ie minibatching…
This may help:
https://machinelearningmastery.com/handle-long-sequences-long-short-term-memory-recurrent-neural-networks/
Hi Jason! Great post, as always. I just have one question here. I am working on a sequence multiclass classification problem, unlike in the above post, there is only one output for one sequence (instead of one per input in the sequence). What changes I am required to do to make this work?
Perhaps this will help:
https://machinelearningmastery.com/faq/single-faq/how-do-i-prepare-my-data-for-an-lstm
Thanks, Jason, I will check this out.
Thanks.
Hi Dr Jason, please i need help with the Bidirectional LSTM implementation. i applied it to chord_lstm_training.py and polyphonic_lstm_training.py in the JAMBOT Music Theory Aware Chord Based Generation of Polyphonic Music with LSTMs project. but it gives an error message ” If a RNN is stateful, it needs to know its batch size. Specify the batch size of your input tensors:” please help . the website to the project is https://github.com/brunnergino/JamBot.git
Sorry, I am not familiar with that code, perhaps contact the author?
Hi Jason,
I thank you very much for your tutorials, they are very interesting and very explanatory,
my question is: can we use the LSTM for the prediction of a categorical variable V for several time steps ie for t, t + 1, t + 2 ….,? if yes how to do it?
thank you for your reply
Yes, this is a time series classification.
You can get started here:
https://machinelearningmastery.com/start-here/#deep_learning_time_series
Hi
I need to build an LSTM for sequence classification when we have more than two classes (the classes are integer values (0,1,2,3).
Unlike your example I have built the whole train set once not one by one
My question is that what activation function should I choose in the output layer with the TimeDistributed wrapper
When I use Softmax in the output layer and and sparse_categorical_crossentropy loss for complaining the model ,I GET THIS ERROR:
Received a label value of 3 which is outside the valid range of [0,1)
If you use sparse categorical loss, then the model must have n output nodes (one for each class) and the target y variable must have 1 variable with n values.
Does that help?
Yes. Thanks a lot. One more question: in my problem, input is time series data and output is a sequence of classes corresponding to each point at the input.
and I am using window method to create each input and output sequence, but the problem is that the data is highly imbalanced, Can I use LSTM with some considerations about class weights or I should use oversampling or under sampling methods to make the data balanced?
Thank you for your reply.
Good question. I’m not familiar with rebalancing techniques for time series, sorry.
There might be class weightings for LSTMs, I have not used them before.
Thank you .
I just found out that we can set sample_weight parameter in the fit function equal to an array of weights (corresponding to the class weights) and set the sample_weight_mode to ‘temporal’ as a parameter of the compile method.
Nice work.
Hi Aida, I am trying to do a LSTM with 4 classes too. Is it possible to share your code? I can’t get mine to work. Sorry and thank you!
How about using Bidirectional LSTMs for seq2seq models? Possible?
Thanks a lot for the blog!
Yes.
Thanks a lot, Jason for the nice post. I have one question can we use this model to identify the entities in medical documents such as condition, drug names, etc?
I read on a research paper about the combined approach of CRF and BLSTM but actually, need help to build the model or maybe you can direct me somewhere. I managed to extract the entities from the document with the CRF but not sure how to embed BLSTM. Any help much appreciated.
If you are working with text data, perhaps start here:
https://machinelearningmastery.com/start-here/#nlp
Dear Jason,
Can we use Bidirectional LSTM model for program language modeling to generate code predictions or suggestions? Is there any benefit of it?
Perhaps try it on your dataset and compare to other methods?
Adam optimizer (learning_rate = 0.001), batch size 128. LSTMs have
hidden dimension 100, 4 layers, and are bidirectional.
I want to code the previous specification of LSTM but I do not know, how I could do that because some of the parameters such as number of layer is not obvious where should I put it?
Good question, this will help with the general number of layers and number of nodes/units:
https://machinelearningmastery.com/faq/single-faq/how-many-layers-and-nodes-do-i-need-in-my-neural-network
Hi Jason,
I have defined a 3DCNN like this for feature extraction from my video dataset:
model = Sequential()
model.add(
TimeDistributed(
MobileNetV2(weights=’imagenet’,include_top=False),
input_shape=sample_shape
)
)
model.add(
TimeDistributed(
GlobalAveragePooling2D()
)
)
Now I need to append a bidirectional LSTM to it as the next layer ??
model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=( ?)))
Not sure how to define the input shape, since it is the output of 3DCNN pooling layer
Sorry, I don’t have examples of a 3dcnn, I recommend experimenting.
Hi Jason,
I am a new research student in the deep learning area. During my study, I browsed a lot of your tutorials. I really appreciate your clear and understandable summary. It’s very helpful for me. I just want to say thank you, thank you for your dedication. Now I’m going to start my research in earnest.
Cheers,
Angela
Thanks Angela, I’m happy that my tutorials are helpful to you!
Hi Jason, thanks for this great tutorial!
Would this approach work with a multivariate time series? (I.e. with several time series that we group together and wish to classify together.)
I’ve tried it but I’m unsure on the way to deal with this layer:
model.add(TimeDistributed(Dense(1, activation=’sigmoid’)))
The best way to deal with this seems to be to simply set return_sequences=False on the last LSTM, but I’m curious is there is another approach?
Apologies if you dealt with this in another blog post, I could not find it.
Best regards,
Yes, perhaps try adapting one of the examples listed in this tutorial to use the bidirectional layer:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
Hi Jason,
thanks for great sharing!
I am confusing, In merge output of Bidirectinal, modes = “concat” mean that many outputs concatenates together in pair or just last forward and backwards concatenated each other.
The output of the layer is concatenated, so the output of a forward and backward pass.
Hi Jason,
thanks for great sharing!
What is the purpose of using TimeDistributed wrapper with bidirectional LSTM (in the given example) ?
Will there be any advantage of using it..if we intend to have single output using multiple inputs ?
This will help you understand the role of the time distributed wrapper:
https://machinelearningmastery.com/timedistributed-layer-for-long-short-term-memory-networks-in-python/
Is there a glitch in Bidirectional keras wrapper when masking padded inputs that it doesn’t compute masks in one of the directions?
I have not seen this problem, perhaps test to confirm and raise an issue with the project?
I tested with different versions of tensorflow and keras imported from tf:
tf version :2.1.0
tf.keras: 2.2.4-tf
padding wasn’t masked in the BiDirectional wrapper althought specifying mask_value=0 in embed layer before:
print([layer.supports_masking for layer in model.layers])
>[True, False, True]
However,
tf version :2.3.1
tf.keras version: 2.4.0
padding is masked with these version:
print([layer.supports_masking for layer in model.layers])
[True, True, True]
I think tf updated something recently in this maybe.
Thanks for sharing.
My pleasure, thanks for your articles!
Thanks for sharing. I have a question, please answer me.
How can I implement a BiLSTM with 256 cell? LSTM layer does not have cell argument.
The nodes/units is the cell.
Quick question – I have an online marketing 3d dataset (household * day * online advertisements) and from this dataset, we train for each household — so a 2d Matrix with a row for each day and column for each potential advertisement. I was just wondering how the bidirectional functionality would work.
A simple reverse of the matrix would change the exposed column, and advertisement that the household would be exposed to, so we should be reversing the matrix along the time series axis (dim=1 ).
Is this the correct thought process behind this, and how would you do this?
If you can apply an LSTM, then you can apply a bidirectional LSTM, not much difference in terms of input data.
Thanks for sharing. I have a question, please answer me.
I’m working on a database that is in the frequency domain. In fact, for each sample I have a univariate time series and 11 classes.
The length of each time series is very different. for Minimum class 12,000 and maximum length 56,000 for some class.
For the implement overlapping window, I’m a little confused, please help me.
Perhaps you can pad all sequences to the same length then use a masking layer to ignore the padded values.
This may help you understand sliding windows:
https://machinelearningmastery.com/time-series-forecasting-supervised-learning/
the problem with BiDirectional LSTMs and masking seems to be that by reading that data backwards, masking is once in the front (where it should be) and once in the back (where it shouldn’t). Therefore I’m getting weird results.
Perhaps use a custom model with one input for each sequence forward and backward, then provide the data in two different ways, once to each input head of the model.
I am doing Parts of speech tagging using deep learning(BLSTM).I got struggled on padding and masking on BLSTM layer.only works for LSTM.
Great!
Sorry , i got an error
:
“C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\python.exe” D:/PythonProject/HAR/Paper/mlmLSTM.py
2021-06-04 13:22:20.708270: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cudart64_110.dll’; dlerror: cudart64_110.dll not found
2021-06-04 13:22:20.708691: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
2021-06-04 13:22:22.730407: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library nvcuda.dll
2021-06-04 13:22:23.660035: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1733] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce MX330 computeCapability: 6.1
coreClock: 1.594GHz coreCount: 3 deviceMemorySize: 2.00GiB deviceMemoryBandwidth: 52.21GiB/s
2021-06-04 13:22:23.660883: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cudart64_110.dll’; dlerror: cudart64_110.dll not found
2021-06-04 13:22:23.661620: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cublas64_11.dll’; dlerror: cublas64_11.dll not found
2021-06-04 13:22:23.662249: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cublasLt64_11.dll’; dlerror: cublasLt64_11.dll not found
2021-06-04 13:22:23.665837: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library cufft64_10.dll
2021-06-04 13:22:23.666999: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library curand64_10.dll
2021-06-04 13:22:23.667668: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cusolver64_11.dll’; dlerror: cusolver64_11.dll not found
2021-06-04 13:22:23.668345: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cusparse64_11.dll’; dlerror: cusparse64_11.dll not found
2021-06-04 13:22:23.669000: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cudnn64_8.dll’; dlerror: cudnn64_8.dll not found
2021-06-04 13:22:23.669171: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1766] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices…
2021-06-04 13:22:23.669965: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2021-06-04 13:22:23.670861: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1258] Device interconnect StreamExecutor with strength 1 edge matrix:
2021-06-04 13:22:23.671169: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1264]
Traceback (most recent call last):
File “D:\PythonProject\HAR\Paper\mlmLSTM.py”, line 27, in
model.add(Bidirectional(LSTM(20, return_sequences=True), input_shape=(n_timesteps, 1)))
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\training\tracking\base.py”, line 522, in _method_wrapper
result = method(self, *args, **kwargs)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\engine\sequential.py”, line 208, in add
layer(x)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\layers\wrappers.py”, line 581, in __call__
return super(Bidirectional, self).__call__(inputs, **kwargs)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\engine\base_layer.py”, line 945, in __call__
return self._functional_construction_call(inputs, args, kwargs,
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\engine\base_layer.py”, line 1083, in _functional_construction_call
outputs = self._keras_tensor_symbolic_call(
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\engine\base_layer.py”, line 816, in _keras_tensor_symbolic_call
return self._infer_output_signature(inputs, args, kwargs, input_masks)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\engine\base_layer.py”, line 856, in _infer_output_signature
outputs = call_fn(inputs, *args, **kwargs)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\layers\wrappers.py”, line 694, in call
y = self.forward_layer(forward_inputs,
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\layers\recurrent.py”, line 660, in __call__
return super(RNN, self).__call__(inputs, **kwargs)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\engine\base_layer.py”, line 1006, in __call__
outputs = call_fn(inputs, *args, **kwargs)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\layers\recurrent_v2.py”, line 1139, in call
inputs, initial_state, _ = self._process_inputs(inputs, initial_state, None)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\layers\recurrent.py”, line 860, in _process_inputs
initial_state = self.get_initial_state(inputs)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\layers\recurrent.py”, line 642, in get_initial_state
init_state = get_initial_state_fn(
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\layers\recurrent.py”, line 2508, in get_initial_state
return list(_generate_zero_filled_state_for_cell(
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\layers\recurrent.py”, line 2990, in _generate_zero_filled_state_for_cell
return _generate_zero_filled_state(batch_size, cell.state_size, dtype)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\layers\recurrent.py”, line 3006, in _generate_zero_filled_state
return tf.nest.map_structure(create_zeros, state_size)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\util\nest.py”, line 867, in map_structure
structure[0], [func(*x) for x in entries],
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\util\nest.py”, line 867, in
structure[0], [func(*x) for x in entries],
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\layers\recurrent.py”, line 3003, in create_zeros
return tf.zeros(init_state_size, dtype=dtype)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\util\dispatch.py”, line 206, in wrapper
return target(*args, **kwargs)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\ops\array_ops.py”, line 2911, in wrapped
tensor = fun(*args, **kwargs)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\ops\array_ops.py”, line 2960, in zeros
output = _constant_if_small(zero, shape, dtype, name)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\ops\array_ops.py”, line 2896, in _constant_if_small
if np.prod(shape) < 1000:
File "”, line 5, in prod
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\numpy\core\fromnumeric.py”, line 3051, in prod
return _wrapreduction(a, np.multiply, ‘prod’, axis, dtype, out,
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\numpy\core\fromnumeric.py”, line 86, in _wrapreduction
return ufunc.reduce(obj, axis, dtype, out, **passkwargs)
File “C:\Users\Xxx xxx\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\framework\ops.py”, line 867, in __array__
raise NotImplementedError(
NotImplementedError: Cannot convert a symbolic Tensor (bidirectional/forward_lstm/strided_slice:0) to a numpy array. This error may indicate that you’re trying to pass a Tensor to a NumPy call, which is not supported
Process finished with exit code 1
Please help me
Sorry to hear that, perhaps some of these suggestions will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Hi , i want to ask , now i got this error:
2021-06-04 13:51:55.949744: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cudart64_110.dll’; dlerror: cudart64_110.dll not found
2021-06-04 13:51:55.949948: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.
2021-06-04 13:51:58.240879: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library nvcuda.dll
2021-06-04 13:51:59.179144: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1733] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce MX330 computeCapability: 6.1
coreClock: 1.594GHz coreCount: 3 deviceMemorySize: 2.00GiB deviceMemoryBandwidth: 52.21GiB/s
2021-06-04 13:51:59.180019: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cudart64_110.dll’; dlerror: cudart64_110.dll not found
2021-06-04 13:51:59.181090: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cublas64_11.dll’; dlerror: cublas64_11.dll not found
2021-06-04 13:51:59.182227: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cublasLt64_11.dll’; dlerror: cublasLt64_11.dll not found
2021-06-04 13:51:59.211775: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library cufft64_10.dll
2021-06-04 13:51:59.217816: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library curand64_10.dll
2021-06-04 13:51:59.218823: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cusolver64_11.dll’; dlerror: cusolver64_11.dll not found
2021-06-04 13:51:59.220086: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cusparse64_11.dll’; dlerror: cusparse64_11.dll not found
2021-06-04 13:51:59.221200: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library ‘cudnn64_8.dll’; dlerror: cudnn64_8.dll not found
2021-06-04 13:51:59.221417: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1766] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices…
2021-06-04 13:51:59.222714: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2021-06-04 13:51:59.223413: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1258] Device interconnect StreamExecutor with strength 1 edge matrix:
2021-06-04 13:51:59.223733: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1264]
2021-06-04 13:52:00.392622: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:176] None of the MLIR Optimization Passes are enabled (registered 2)
1/1 – 17s – loss: 0.7083 – accuracy: 0.4000
1/1 – 0s – loss: 0.6992 – accuracy: 0.4000
…………………………………………………………….
1/1 – 0s – loss: 0.1665 – accuracy: 0.9000
1/1 – 0s – loss: 0.1543 – accuracy: 0.9000
C:\Users\Zainal Arifien\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\engine\sequential.py:450: UserWarning:
model.predict_classes()is deprecated and will be removed after 2021-01-01. Please use instead:*np.argmax(model.predict(x), axis=-1), if your model does multi-class classification (e.g. if it uses asoftmaxlast-layer activation).*(model.predict(x) > 0.5).astype("int32"), if your model does binary classification (e.g. if it uses asigmoidlast-layer activation).warnings.warn(‘
model.predict_classes()is deprecated and ‘Expected: [0] Predicted [0]
Expected: [0] Predicted [0]
Expected: [0] Predicted [0]
Expected: [0] Predicted [0]
Expected: [1] Predicted [0]
Expected: [1] Predicted [1]
Expected: [1] Predicted [1]
Expected: [1] Predicted [1]
Expected: [1] Predicted [1]
Expected: [1] Predicted [1]
Process finished with exit code 0
Perhaps there is a problem with your tensorflow installation? Perhaps try reinstalling?
Great post! I am serching for examples about using Bi-LSTM to predict Remaining Useful Life (RUL), more specifically, using C-MAPSS dataset. Is it possible to adapt this code to do this? Do you have any other example about RUL using Bi-LSTM? Thanks a lot in advance!
Hi Carlos…While I cannot speak to your specific project/application, I am confident that our material will serve you well in terms of getting starting with the essential machine learning concepts.
Are you looking for sample code for a specific machine learning method?
Perhaps I have a tutorial with sample code on the blog. Search the blog:
Search Machine Learning Mastery
If I do not have an example on the blog, I cannot give you an idea of where to get code off-hand.
Nevertheless, I have some ideas here:
Perhaps find a paper on the method via Google Scholar and email the author?
Perhaps search on GitHub?
Perhaps search on Google?
Perhaps search on StackOverflow or CrossValidated?
Perhaps you can find an example in a book, use Google Book Search?
Hi Dr Jason, I need help with the Bidirectional LSTM implementation please.
– Does the “forward path” means the same as “regular lstm”? what is difference between only “forward path” and “regular lstm”?
– Does merge forward and backward layers means the same as Bidirectional-lstm ? if “yes” then why in base
paper ” Bidirectional Recurrent Neural Networks/ IEEE TRANSACTIONS ON SIGNAL PROCESSING, VOL. 45, NO. 11, NOVEMBER 1997″ “merge” means different with bidirectional-lstm?
Thank you for your reply
Hi star…The following resource may add clarity:
https://analyticsindiamag.com/complete-guide-to-bidirectional-lstm-with-python-codes/#:~:text=In%20bidirectional%2C%20our%20input%20flows,future%20and%20the%20past%20information.