Overfitting is a common explanation for the poor performance of a predictive model.
An analysis of learning dynamics can help to identify whether a model has overfit the training dataset and may suggest an alternate configuration to use that could result in better predictive performance.
Performing an analysis of learning dynamics is straightforward for algorithms that learn incrementally, like neural networks, but it is less clear how we might perform the same analysis with other algorithms that do not learn incrementally, such as decision trees, k-nearest neighbors, and other general algorithms in the scikit-learn machine learning library.
In this tutorial, you will discover how to identify overfitting for machine learning models in Python.
After completing this tutorial, you will know:
- Overfitting is a possible cause of poor generalization performance of a predictive model.
- Overfitting can be analyzed for machine learning models by varying key model hyperparameters.
- Although overfitting is a useful tool for analysis, it must not be confused with model selection.
Let’s get started.

Identify Overfitting Machine Learning Models With Scikit-Learn
Photo by Bonnie Moreland, some rights reserved.
Tutorial Overview
This tutorial is divided into five parts; they are:
- What Is Overfitting
- How to Perform an Overfitting Analysis
- Example of Overfitting in Scikit-Learn
- Counterexample of Overfitting in Scikit-Learn
- Separate Overfitting Analysis From Model Selection
What Is Overfitting
Overfitting refers to an unwanted behavior of a machine learning algorithm used for predictive modeling.
It is the case where model performance on the training dataset is improved at the cost of worse performance on data not seen during training, such as a holdout test dataset or new data.
We can identify if a machine learning model has overfit by first evaluating the model on the training dataset and then evaluating the same model on a holdout test dataset.
If the performance of the model on the training dataset is significantly better than the performance on the test dataset, then the model may have overfit the training dataset.
We care about overfitting because it is a common cause for “poor generalization” of the model as measured by high “generalization error.” That is error made by the model when making predictions on new data.
This means, if our model has poor performance, maybe it is because it has overfit.
But what does it mean if a model’s performance is “significantly better” on the training set compared to the test set?
For example, it is common and perhaps normal for the model to have better performance on the training set than the test set.
As such, we can perform an analysis of the algorithm on the dataset to better expose the overfitting behavior.
How to Perform an Overfitting Analysis
An overfitting analysis is an approach for exploring how and when a specific model is overfitting on a specific dataset.
It is a tool that can help you learn more about the learning dynamics of a machine learning model.
This might be achieved by reviewing the model behavior during a single run for algorithms like neural networks that are fit on the training dataset incrementally.
A plot of the model performance on the train and test set can be calculated at each point during training and plots can be created. This plot is often called a learning curve plot, showing one curve for model performance on the training set and one curve for the test set for each increment of learning.
If you would like to learn more about learning curves for algorithms that learn incrementally, see the tutorial:
The common pattern for overfitting can be seen on learning curve plots, where model performance on the training dataset continues to improve (e.g. loss or error continues to fall or accuracy continues to rise) and performance on the test or validation set improves to a point and then begins to get worse.
If this pattern is observed, then training should stop at that point where performance gets worse on the test or validation set for algorithms that learn incrementally
This makes sense for algorithms that learn incrementally like neural networks, but what about other algorithms?
- How do you perform an overfitting analysis for machine learning algorithms in scikit-learn?
One approach for performing an overfitting analysis on algorithms that do not learn incrementally is by varying a key model hyperparameter and evaluating the model performance on the train and test sets for each configuration.
To make this clear, let’s explore a case of analyzing a model for overfitting in the next section.
Example of Overfitting in Scikit-Learn
In this section, we will look at an example of overfitting a machine learning model to a training dataset.
First, let’s define a synthetic classification dataset.
We will use the make_classification() function to define a binary (two class) classification prediction problem with 10,000 examples (rows) and 20 input features (columns).
The example below creates the dataset and summarizes the shape of the input and output components.
|
1 2 3 4 5 6 |
# synthetic classification dataset from sklearn.datasets import make_classification # define dataset X, y = make_classification(n_samples=10000, n_features=20, n_informative=5, n_redundant=15, random_state=1) # summarize the dataset print(X.shape, y.shape) |
Running the example creates the dataset and reports the shape, confirming our expectations.
|
1 |
(10000, 20) (10000,) |
Next, we need to split the dataset into train and test subsets.
We will use the train_test_split() function and split the data into 70 percent for training a model and 30 percent for evaluating it.
|
1 2 3 4 5 6 7 8 9 |
# split a dataset into train and test sets from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split # create dataset X, y = make_classification(n_samples=10000, n_features=20, n_informative=5, n_redundant=15, random_state=1) # split into train test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # summarize the shape of the train and test sets print(X_train.shape, X_test.shape, y_train.shape, y_test.shape) |
Running the example splits the dataset and we can confirm that we have 7,000 examples for training and 3,000 for evaluating a model.
|
1 |
(7000, 20) (3000, 20) (7000,) (3000,) |
Next, we can explore a machine learning model overfitting the training dataset.
We will use a decision tree via the DecisionTreeClassifier and test different tree depths with the “max_depth” argument.
Shallow decision trees (e.g. few levels) generally do not overfit but have poor performance (high bias, low variance). Whereas deep trees (e.g. many levels) generally do overfit and have good performance (low bias, high variance). A desirable tree is one that is not so shallow that it has low skill and not so deep that it overfits the training dataset.
We evaluate decision tree depths from 1 to 20.
|
1 2 3 |
... # define the tree depths to evaluate values = [i for i in range(1, 21)] |
We will enumerate each tree depth, fit a tree with a given depth on the training dataset, then evaluate the tree on both the train and test sets.
The expectation is that as the depth of the tree increases, performance on train and test will improve to a point, and as the tree gets too deep, it will begin to overfit the training dataset at the expense of worse performance on the holdout test set.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
... # evaluate a decision tree for each depth for i in values: # configure the model model = DecisionTreeClassifier(max_depth=i) # fit model on the training dataset model.fit(X_train, y_train) # evaluate on the train dataset train_yhat = model.predict(X_train) train_acc = accuracy_score(y_train, train_yhat) train_scores.append(train_acc) # evaluate on the test dataset test_yhat = model.predict(X_test) test_acc = accuracy_score(y_test, test_yhat) test_scores.append(test_acc) # summarize progress print('>%d, train: %.3f, test: %.3f' % (i, train_acc, test_acc)) |
At the end of the run, we will then plot all model accuracy scores on the train and test sets for visual comparison.
|
1 2 3 4 5 6 |
... # plot of train and test scores vs tree depth pyplot.plot(values, train_scores, '-o', label='Train') pyplot.plot(values, test_scores, '-o', label='Test') pyplot.legend() pyplot.show() |
Tying this together, the complete example of exploring different tree depths on the synthetic binary classification dataset is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# evaluate decision tree performance on train and test sets with different tree depths from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.tree import DecisionTreeClassifier from matplotlib import pyplot # create dataset X, y = make_classification(n_samples=10000, n_features=20, n_informative=5, n_redundant=15, random_state=1) # split into train test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # define lists to collect scores train_scores, test_scores = list(), list() # define the tree depths to evaluate values = [i for i in range(1, 21)] # evaluate a decision tree for each depth for i in values: # configure the model model = DecisionTreeClassifier(max_depth=i) # fit model on the training dataset model.fit(X_train, y_train) # evaluate on the train dataset train_yhat = model.predict(X_train) train_acc = accuracy_score(y_train, train_yhat) train_scores.append(train_acc) # evaluate on the test dataset test_yhat = model.predict(X_test) test_acc = accuracy_score(y_test, test_yhat) test_scores.append(test_acc) # summarize progress print('>%d, train: %.3f, test: %.3f' % (i, train_acc, test_acc)) # plot of train and test scores vs tree depth pyplot.plot(values, train_scores, '-o', label='Train') pyplot.plot(values, test_scores, '-o', label='Test') pyplot.legend() pyplot.show() |
Running the example fits and evaluates a decision tree on the train and test sets for each tree depth and reports the accuracy scores.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see a trend of increasing accuracy on the training dataset with the tree depth to a point around a depth of 19-20 levels where the tree fits the training dataset perfectly.
We can also see that the accuracy on the test set improves with tree depth until a depth of about eight or nine levels, after which accuracy begins to get worse with each increase in tree depth.
This is exactly what we would expect to see in a pattern of overfitting.
We would choose a tree depth of eight or nine before the model begins to overfit the training dataset.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
>1, train: 0.769, test: 0.761 >2, train: 0.808, test: 0.804 >3, train: 0.879, test: 0.878 >4, train: 0.902, test: 0.896 >5, train: 0.915, test: 0.903 >6, train: 0.929, test: 0.918 >7, train: 0.942, test: 0.921 >8, train: 0.951, test: 0.924 >9, train: 0.959, test: 0.926 >10, train: 0.968, test: 0.923 >11, train: 0.977, test: 0.925 >12, train: 0.983, test: 0.925 >13, train: 0.987, test: 0.926 >14, train: 0.992, test: 0.921 >15, train: 0.995, test: 0.920 >16, train: 0.997, test: 0.913 >17, train: 0.999, test: 0.918 >18, train: 0.999, test: 0.918 >19, train: 1.000, test: 0.914 >20, train: 1.000, test: 0.913 |
A figure is also created that shows line plots of the model accuracy on the train and test sets with different tree depths.
The plot clearly shows that increasing the tree depth in the early stages results in a corresponding improvement in both train and test sets.
This continues until a depth of around 10 levels, after which the model is shown to overfit the training dataset at the cost of worse performance on the holdout dataset.
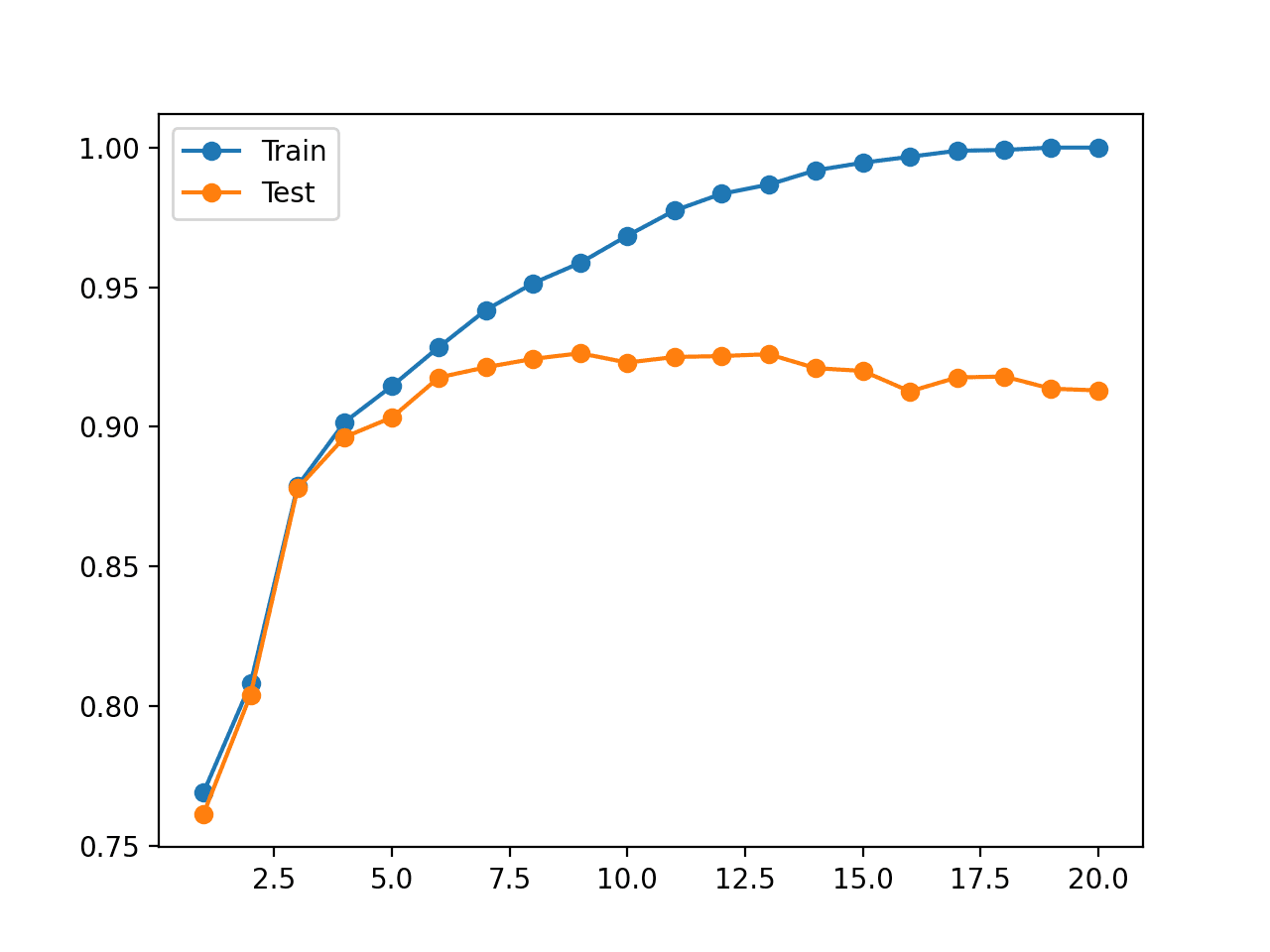
Line Plot of Decision Tree Accuracy on Train and Test Datasets for Different Tree Depths
This analysis is interesting. It shows why the model has a worse hold-out test set performance when “max_depth” is set to large values.
But it is not required.
We can just as easily choose a “max_depth” using a grid search without performing an analysis on why some values result in better performance and some result in worse performance.
In fact, in the next section, we will show where this analysis can be misleading.
Counterexample of Overfitting in Scikit-Learn
Sometimes, we may perform an analysis of machine learning model behavior and be deceived by the results.
A good example of this is varying the number of neighbors for the k-nearest neighbors algorithms, which we can implement using the KNeighborsClassifier class and configure via the “n_neighbors” argument.
Let’s forget how KNN works for the moment.
We can perform the same analysis of the KNN algorithm as we did in the previous section for the decision tree and see if our model overfits for different configuration values. In this case, we will vary the number of neighbors from 1 to 50 to get more of the effect.
The complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# evaluate knn performance on train and test sets with different numbers of neighbors from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.neighbors import KNeighborsClassifier from matplotlib import pyplot # create dataset X, y = make_classification(n_samples=10000, n_features=20, n_informative=5, n_redundant=15, random_state=1) # split into train test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # define lists to collect scores train_scores, test_scores = list(), list() # define the tree depths to evaluate values = [i for i in range(1, 51)] # evaluate a decision tree for each depth for i in values: # configure the model model = KNeighborsClassifier(n_neighbors=i) # fit model on the training dataset model.fit(X_train, y_train) # evaluate on the train dataset train_yhat = model.predict(X_train) train_acc = accuracy_score(y_train, train_yhat) train_scores.append(train_acc) # evaluate on the test dataset test_yhat = model.predict(X_test) test_acc = accuracy_score(y_test, test_yhat) test_scores.append(test_acc) # summarize progress print('>%d, train: %.3f, test: %.3f' % (i, train_acc, test_acc)) # plot of train and test scores vs number of neighbors pyplot.plot(values, train_scores, '-o', label='Train') pyplot.plot(values, test_scores, '-o', label='Test') pyplot.legend() pyplot.show() |
Running the example fits and evaluates a KNN model on the train and test sets for each number of neighbors and reports the accuracy scores.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Recall, we are looking for a pattern where performance on the test set improves and then starts to get worse, and performance on the training set continues to improve.
We do not see this pattern.
Instead, we see that accuracy on the training dataset starts at perfect accuracy and falls with almost every increase in the number of neighbors.
We also see that performance of the model on the holdout test improves to a value of about five neighbors, holds level and begins a downward trend after that.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
>1, train: 1.000, test: 0.919 >2, train: 0.965, test: 0.916 >3, train: 0.962, test: 0.932 >4, train: 0.957, test: 0.932 >5, train: 0.954, test: 0.935 >6, train: 0.953, test: 0.934 >7, train: 0.952, test: 0.932 >8, train: 0.951, test: 0.933 >9, train: 0.949, test: 0.933 >10, train: 0.950, test: 0.935 >11, train: 0.947, test: 0.934 >12, train: 0.947, test: 0.933 >13, train: 0.945, test: 0.932 >14, train: 0.945, test: 0.932 >15, train: 0.944, test: 0.932 >16, train: 0.944, test: 0.934 >17, train: 0.943, test: 0.932 >18, train: 0.943, test: 0.935 >19, train: 0.942, test: 0.933 >20, train: 0.943, test: 0.935 >21, train: 0.942, test: 0.933 >22, train: 0.943, test: 0.933 >23, train: 0.941, test: 0.932 >24, train: 0.942, test: 0.932 >25, train: 0.942, test: 0.931 >26, train: 0.941, test: 0.930 >27, train: 0.941, test: 0.932 >28, train: 0.939, test: 0.932 >29, train: 0.938, test: 0.931 >30, train: 0.938, test: 0.931 >31, train: 0.937, test: 0.931 >32, train: 0.938, test: 0.931 >33, train: 0.937, test: 0.930 >34, train: 0.938, test: 0.931 >35, train: 0.937, test: 0.930 >36, train: 0.937, test: 0.928 >37, train: 0.936, test: 0.930 >38, train: 0.937, test: 0.930 >39, train: 0.935, test: 0.929 >40, train: 0.936, test: 0.929 >41, train: 0.936, test: 0.928 >42, train: 0.936, test: 0.929 >43, train: 0.936, test: 0.930 >44, train: 0.935, test: 0.929 >45, train: 0.935, test: 0.929 >46, train: 0.934, test: 0.929 >47, train: 0.935, test: 0.929 >48, train: 0.934, test: 0.929 >49, train: 0.934, test: 0.929 >50, train: 0.934, test: 0.929 |
A figure is also created that shows line plots of the model accuracy on the train and test sets with different numbers of neighbors.
The plots make the situation clearer. It looks as though the line plot for the training set is dropping to converge with the line for the test set. Indeed, this is exactly what is happening.
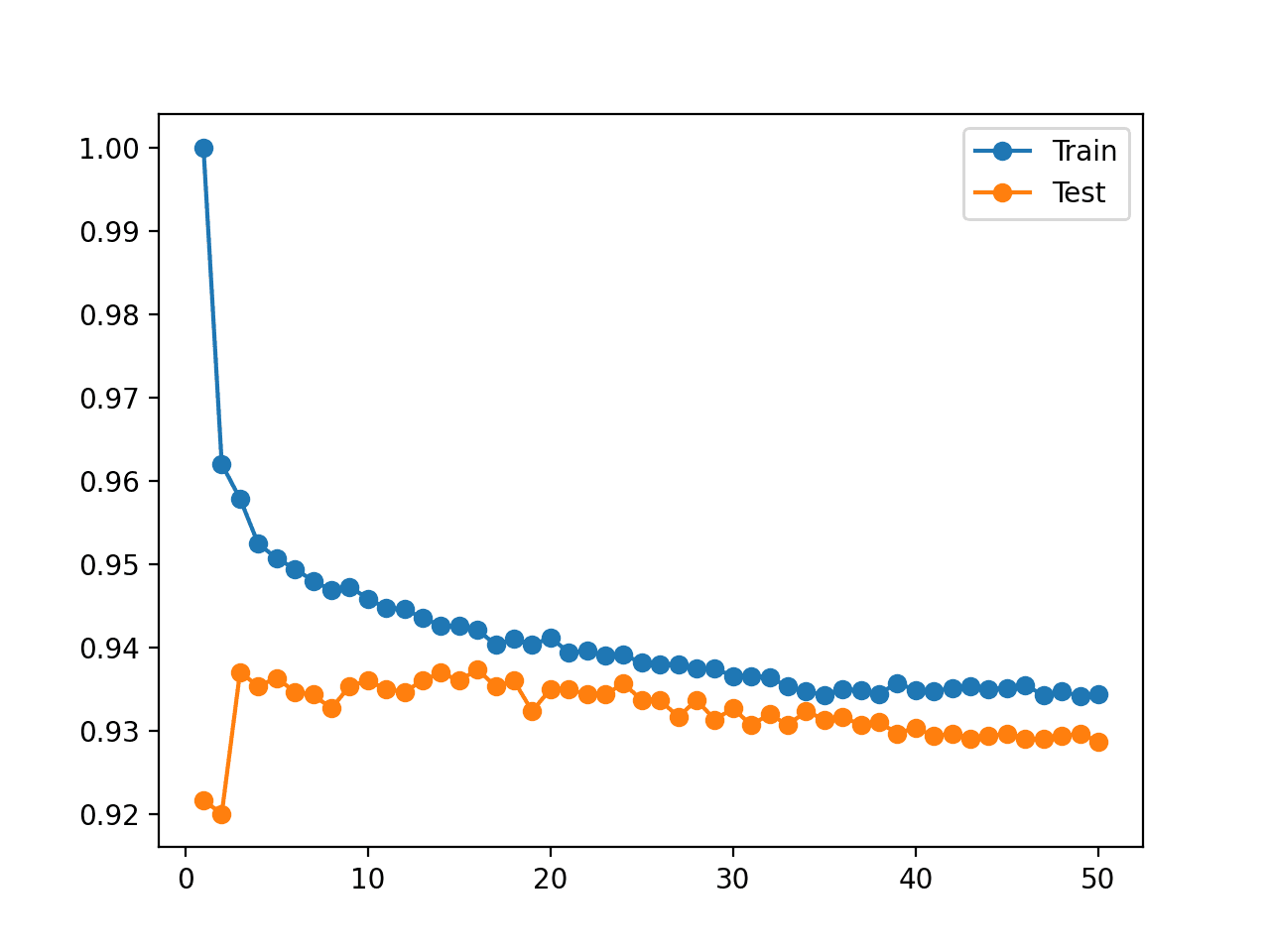
Line Plot of KNN Accuracy on Train and Test Datasets for Different Numbers of Neighbors
Now, recall how KNN works.
The “model” is really just the entire training dataset stored in an efficient data structure. Skill for the “model” on the training dataset should be 100 percent and anything less is unforgivable.
In fact, this argument holds for any machine learning algorithm and slices to the core of the confusion around overfitting for beginners.
Separate Overfitting Analysis From Model Selection
Overfitting can be an explanation for poor performance of a predictive model.
Creating learning curve plots that show the learning dynamics of a model on the train and test dataset is a helpful analysis for learning more about a model on a dataset.
But overfitting should not be confused with model selection.
We choose a predictive model or model configuration based on its out-of-sample performance. That is, its performance on new data not seen during training.
The reason we do this is that in predictive modeling, we are primarily interested in a model that makes skillful predictions. We want the model that can make the best possible predictions given the time and computational resources we have available.
This might mean we choose a model that looks like it has overfit the training dataset. In which case, an overfit analysis might be misleading.
It might also mean that the model has poor or terrible performance on the training dataset.
In general, if we cared about model performance on the training dataset in model selection, then we would expect a model to have perfect performance on the training dataset. It’s data we have available; we should not tolerate anything less.
As we saw with the KNN example above, we can achieve perfect performance on the training set by storing the training set directly and returning predictions with one neighbor at the cost of poor performance on any new data.
- Wouldn’t a model that performs well on both train and test datasets be a better model?
Maybe. But, maybe not.
This argument is based on the idea that a model that performs well on both train and test sets has a better understanding of the underlying problem.
A corollary is that a model that performs well on the test set but poor on the training set is lucky (e.g. a statistical fluke) and a model that performs well on the train set but poor on the test set is overfit.
I believe this is the sticking point for beginners that often ask how to fix overfitting for their scikit-learn machine learning model.
The worry is that a model must perform well on both train and test sets, otherwise, they are in trouble.
This is not the case.
Performance on the training set is not relevant during model selection. You must focus on the out-of-sample performance only when choosing a predictive model.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Tutorials
- How to Avoid Overfitting in Deep Learning Neural Networks
- Overfitting and Underfitting With Machine Learning Algorithms
- How to use Learning Curves to Diagnose Machine Learning Model Performance
APIs
- sklearn.datasets.make_classification API.
- sklearn.model_selection.train_test_split API.
- sklearn.tree.DecisionTreeClassifier API.
- sklearn.neighbors.KNeighborsClassifier API.
Articles
Summary
In this tutorial, you discovered how to identify overfitting for machine learning models in Python.
Specifically, you learned:
- Overfitting is a possible cause of poor generalization performance of a predictive model.
- Overfitting can be analyzed for machine learning models by varying key model hyperparameters.
- Although overfitting is a useful tool for analysis, it must not be confused with model selection.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Discover Fast Machine Learning in Python!

Develop Your Own Models in Minutes
...with just a few lines of scikit-learn code
Learn how in my new Ebook:
Machine Learning Mastery With Python
Covers self-study tutorials and end-to-end projects like:
Loading data, visualization, modeling, tuning, and much more...
Finally Bring Machine Learning To
Your Own Projects
Skip the Academics. Just Results.






Hi Jason,
a question about gradient descent. Is it for both Classifciation and Regression? Is it applicable also to machine (shallow) learning and deep learning?
Thanks,
Marco
Yes, SGD can be used for classification and regression.
Hi Jason,
is is possbile to classify sounds with machine learning or deep learning? Do you have an example?
Do you have any example of Keras functional APIs?
Thanks, Marco
Yes.
I don’t have an example, sorry.
Yes, a tutorial on the function api here:
https://machinelearningmastery.com/keras-functional-api-deep-learning/
I think there is some fishy in the sentence :
“If this pattern is observed, then training should stop at that point where performance gets worse on the training set for algorithms that learn incrementally”
of the section “How to Perform an Overfitting Analysis”
I think we should stop training when performance starts degrading on the test set and not the training set as mentioned above.
Please let me know if my understanding is wrong
Agreed. Looks like a typo. Fixed, thanks.
Your blogs is really great and very informative. I am curious and want to know that in your blogs rarely you use real world datasets. In my opinion real world datasets make more sense and provide bigger picture. Majority of bloggers will use iris dataset or some random numbers 0f 10000, how that can be correlated to real world scenario. You are PhD & i believe you can do better job.
Thanks for your feedback.
It is easier to explain and undertand an algorithm on a simple synthetic dataset. There are many projects on real datasets on the blog as well – perhaps try the blog search.
I think test error is always higher than train error. Kindly check on your graph illustrations. Remember on unforseen daat, the errors are bound to be higher. I stand to be corrected.
Hi Jason! I really liked this post. Thanks for your great work.
I agree with you 100% that performance on the training set is not relevant during model selection.
But when do you think it is very relevant? Maybe, when you´re trying to spot overfitting.
But let´s say e_test<e_train in your learning curves, would you still care and try to lower e_train
if your e_test is already good enough? Can you think of other examples when you should focus on
trying to improve e_train, when e_test is already fine? When should you care about e_train at all?
Thanks.
It’s relevant when fitting models that learn incrementally, like neural nets. See this:
https://machinelearningmastery.com/learning-curves-for-diagnosing-machine-learning-model-performance/
“Running the example splits the dataset and we can confirm that we have 70k examples for training and 30k for evaluating a model.”
You must’ve revised your code, because it’s 7k and 3k, eh?
Thanks! Fixed.
Hey Jason!
I am working on a multiclass classification problem, is it right to first do model selection, then check whether the selected model is under fitting or overfitting and then may be do feature selection or add some new features and finally do hyperparameter tuning and testing final model on test set?..What do you suggest?
Hi Asiwach…The following resource may help clarify through an example:
https://machinelearningmastery.com/multi-label-classification-with-deep-learning/
Hello! If I am considering, let’s say, 1000 models, is it possible that the model that performs the best on the test set is accidentally overfit to the test set? And I would have chosen a different model on another unseen test set?
It is possible.
Try repeated k-fold cv instead for model selection.
Thank you!
You’re welcome!
Hi Jason!
It’s often said that the golden rule of machine learning is that the test data should not influence the learning process in any way. But in the example involving a decision tree classifier, you used the test set in order to tune the max_depth hyper-parameter. Doesn’t this violate that golden rule?
Let me know if there’s something I’ve misunderstood here! Thanks!
Yes, I intentionally reuse data in some cases to keep the algorithm examples simple and easy to understand:
https://machinelearningmastery.com/faq/single-faq/why-do-you-use-the-test-dataset-as-the-validation-dataset
Very nice article, thank you! I was wondering how this would look for a DecisionTreeRegressor instead of a classification problem.
You would vary the depth of the tree.
Hello! Many thanks for this useful article. I was wondering how to evaluate overfitting and underfitting of SVM models, do you have an article that covers this?
Perhaps you can adapt the above example for your chosen model.
Hi! First, thanks for this article. Its helping me a lot!
I’m working in a model that is extremely overfitting on training dataset (near 1.0 on ROC AUC and PR AUC) and it drops a little on test set, resulting in 0,70 aprox. in both metrics. These values of PR AUC and ROC AUC in test are fine for the problem that i’m working but do i need to worry because of that high metrics on trainning? I’m using extra
trees classifier and they are very deep.
Thanks!
High metric is not a thing to worry, but the test metric being far off from training metric is. Supposedly, test metric is what we expect to see when we roll out our model for real use. Training metric only guides your training process. What we don’t want is that, we keep training and improving the training metric, but the test metric is getting worse.
Hi Jason. I created CNN model to predict cloud image and it has overfit. But I bit confuse with your statement
“Performance on the training set is not relevant during model selection. You must focus on the out-of-sample performance only when choosing a predictive model.”
Can you explain it to me? why Performance on the training set is not relevant during model selection. Does it mean we need to make test set better than training?
Hi Fikri…Some models will learn training data well but not perform well in practice. A model must be selected based upon its performance on testing and validation data.
Hi Jason,
I’ve read many of your blogs in past, and the quality of content and work you are doing via these blogs are highly appreciable.
However this blog made it pretty difficult to ready and understand and I believe that there is lack of pictorial representation for some lines you’ve written around KNN and Model selection which triggered a lot confusion for me. Even in case when I consider myself something above a beginner considering background education, skills and experience I have in data science industry
Let me know if you’re planning to incrementally improving this one blog, as I see scope of many doubts and quality interview questions to pop around these concepts
Hi Achint…Thank you for the feedback!
Great article. What effect does the size of the testing set have on the testing learning curve? I would suppose that the larger the test set, the more accurate assessment of the model’s generalisation capability you can make.
Hi Ben…You are correct. Larger datasets may help your model to generalize better if handled properly.
The following may help clarify:
https://machinelearningmastery.com/improve-model-accuracy-with-data-pre-processing/
Thanks for article. I wonder can we plot it for regression problems? And im struggling to compara regression model each other . Lets say linearregression, decisiontreeregression, randomforestregression and GradientBoostingRegressor models we tried on same dataset and decided which one is better perform but, on notebook it could really long and people tried to read it or didnt bother etc. how can we plot all of them together maybe as timeline ? I saw many example on tensorflow model training but didnt find any Sklearn or this model’s. Thanks for you reply too .
Hi Elandil2…To compare regression models performance, you may want to consider various metrics such as in the following resource:
https://machinelearningmastery.com/regression-metrics-for-machine-learning/
Hi Jason, I am using a 1D CNN where the input is a 1D waveform and output is an array of two numbers. The training accuracy is increasing after each epoch, but the validation accuracy wouldn’t move from ~0.5, no matter what I do. I tried several things such as, increasing the dataset, different architecture etc. etc. nothing works
Hi Chinthak…The following may be of interest to you:
https://machinelearningmastery.com/improve-deep-learning-performance/
https://machinelearningmastery.com/how-to-improve-deep-learning-model-robustness-by-adding-noise/
Great material, Jason!
This one is brilliant, like the all the other on your website.
Your website is like a gold mine for me.
Really helpful, enlighten the difficult concepts.
Many thanks for your generosity!
Thank you for your support and feedback! We greatly appreciate it!