Some prediction problems require predicting both numeric values and a class label for the same input.
A simple approach is to develop both regression and classification predictive models on the same data and use the models sequentially.
An alternative and often more effective approach is to develop a single neural network model that can predict both a numeric and class label value from the same input. This is called a multi-output model and can be relatively easy to develop and evaluate using modern deep learning libraries such as Keras and TensorFlow.
In this tutorial, you will discover how to develop a neural network for combined regression and classification predictions.
After completing this tutorial, you will know:
Some prediction problems require predicting both numeric and class label values for each input example.
How to develop separate regression and classification models for problems that require multiple outputs.
How to develop and evaluate a neural network model capable of making simultaneous regression and classification predictions.
Let’s get started.
Develop Neural Network for Combined Classification and Regression Photo by Sang Trinh, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
Single Model for Regression and Classification
Separate Regression and Classification Models
Abalone Dataset
Regression Model
Classification Model
Combined Regression and Classification Models
Single Model for Regression and Classification
It is common to develop a deep learning neural network model for a regression or classification problem, but on some predictive modeling tasks, we may want to develop a single model that can make both regression and classification predictions.
Regression refers to predictive modeling problems that involve predicting a numeric value given an input.
Classification refers to predictive modeling problems that involve predicting a class label or probability of class labels for a given input.
For more on the difference between classification and regression, see the tutorial:
There may be some problems where we want to predict both a numerical value and a classification value.
One approach to solving this problem is to develop a separate model for each prediction that is required.
The problem with this approach is that the predictions made by the separate models may diverge.
An alternate approach that can be used when using neural network models is to develop a single model capable of making separate predictions for a numeric and class output for the same input.
This is called a multi-output neural network model.
The benefit of this type of model is that we have a single model to develop and maintain instead of two models and that training and updating the model on both output types at the same time may offer more consistency in the predictions between the two output types.
We will develop a multi-output neural network model capable of making regression and classification predictions at the same time.
First, let’s select a dataset where this requirement makes sense and start by developing separate models for both regression and classification predictions.
Separate Regression and Classification Models
In this section, we will start by selecting a real dataset where we may want regression and classification predictions at the same time, then develop separate models for each type of prediction.
Abalone Dataset
We will use the “abalone” dataset.
Determining the age of an abalone is a time-consuming task and it is desirable to determine the age from physical details alone.
This is a dataset that describes the physical details of abalone and requires predicting the number of rings of the abalone, which is a proxy for the age of the creature.
Running the example first downloads and summarizes the shape of the dataset.
We can see that there are 4,177 examples (rows) that we can use to train and evaluate a model and 9 features (columns) including the target variable.
We can see that all input variables are numeric except the first, which is a string value.
To keep data preparation simple, we will drop the first column from our models and focus on modeling the numeric input values.
1
2
3
4
5
6
7
(4177, 9)
0 1 2 3 4 5 6 7 8
0 M 0.455 0.365 0.095 0.5140 0.2245 0.1010 0.150 15
1 M 0.350 0.265 0.090 0.2255 0.0995 0.0485 0.070 7
2 F 0.530 0.420 0.135 0.6770 0.2565 0.1415 0.210 9
3 M 0.440 0.365 0.125 0.5160 0.2155 0.1140 0.155 10
4 I 0.330 0.255 0.080 0.2050 0.0895 0.0395 0.055 7
We can use the data as the basis for developing separate regression and classification Multilayer Perceptron (MLP) neural network models.
Note: we are not trying to develop an optimal model for this dataset; instead we are demonstrating a specific technique: developing a model that can make both regression and classification predictions.
Regression Model
In this section, we will develop a regression MLP model for the abalone dataset.
First, we must separate the columns into input and output elements and drop the first column that contains string values.
We will also force all loaded columns to have a float type (expected by neural network models) and record the number of input features, which will need to be known by the model later.
1
2
3
4
5
...
# split into input (X) and output (y) variables
X,y=dataset[:,1:-1],dataset[:,-1]
X,y=X.astype('float'),y.astype('float')
n_features=X.shape[1]
Next, we can split the dataset into a train and test dataset.
We will use a 67% random sample to train the model and the remaining 33% to evaluate the model.
The model will have two hidden layers, the first with 20 nodes and the second with 10 nodes, both using ReLU activation and “he normal” weight initialization (a good practice). The number of layers and nodes were chosen arbitrarily.
The output layer will have a single node for predicting a numeric value and a linear activation function.
Running the example will prepare the dataset, fit the model, and report an estimate of model error.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the model achieved an error of about 1.5 (rings).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
...
Epoch 145/150
88/88 - 0s - loss: 4.6130
Epoch 146/150
88/88 - 0s - loss: 4.6182
Epoch 147/150
88/88 - 0s - loss: 4.6277
Epoch 148/150
88/88 - 0s - loss: 4.6437
Epoch 149/150
88/88 - 0s - loss: 4.6166
Epoch 150/150
88/88 - 0s - loss: 4.6132
MAE: 1.554
So far so good.
Next, let’s look at developing a similar model for classification.
Classification Model
The abalone dataset can be framed as a classification problem where each “ring” integer is taken as a separate class label.
The example and model are much the same as the above example for regression, with a few important changes.
This requires first assigning a separate integer for each “ring” value, starting at 0 and ending at the total number of “classes” minus one.
We can also record the total number of classes as the total number of unique encoded class values, which will be needed by the model later.
1
2
3
4
...
# encode strings to integer
y=LabelEncoder().fit_transform(y)
n_class=len(unique(y))
After splitting the data into train and test sets as before, we can define the model and change the number of outputs from the model to equal the number of classes and use the softmax activation function, common for multi-class classification.
Given we have encoded class labels as integer values, we can fit the model by minimizing the sparse categorical cross-entropy loss function, appropriate for multi-class classification tasks with integer encoded class labels.
After the model is fit on the training dataset as before, we can evaluate the performance of the model by calculating the classification accuracy on the hold-out test set.
1
2
3
4
5
6
...
# evaluate on test set
yhat=model.predict(X_test)
yhat=argmax(yhat,axis=-1).astype('int')
acc=accuracy_score(y_test,yhat)
print('Accuracy: %.3f'%acc)
Tying this all together, the complete example of an MLP neural network for the abalone dataset framed as a classification problem is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# classification mlp model for the abalone dataset
from numpy import unique
from numpy import argmax
from pandas import read_csv
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
Running the example will prepare the dataset, fit the model, and report an estimate of model error.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the model achieved an accuracy of about 27%.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
...
Epoch 145/150
88/88 - 0s - loss: 1.9271
Epoch 146/150
88/88 - 0s - loss: 1.9265
Epoch 147/150
88/88 - 0s - loss: 1.9265
Epoch 148/150
88/88 - 0s - loss: 1.9271
Epoch 149/150
88/88 - 0s - loss: 1.9262
Epoch 150/150
88/88 - 0s - loss: 1.9260
Accuracy: 0.274
So far so good.
Next, let’s look at developing a combined model capable of both regression and classification predictions.
Combined Regression and Classification Models
In this section, we can develop a single MLP neural network model that can make both regression and classification predictions for a single input.
This is called a multi-output model and can be developed using the functional Keras API.
For more on this functional API, which can be tricky for beginners, see the tutorials:
We can prepare the dataset as we did before for classification, although we should save the encoded target variable with a separate name to differentiate it from the raw target variable values.
1
2
3
4
...
# encode strings to integer
y_class=LabelEncoder().fit_transform(y)
n_class=len(unique(y_class))
We can then split the input, raw output, and encoded output variables into train and test sets.
Given the two output layers, we can compile the model with two loss functions, mean squared error loss for the first (regression) output layer and sparse categorical cross-entropy for the second (classification) output layer.
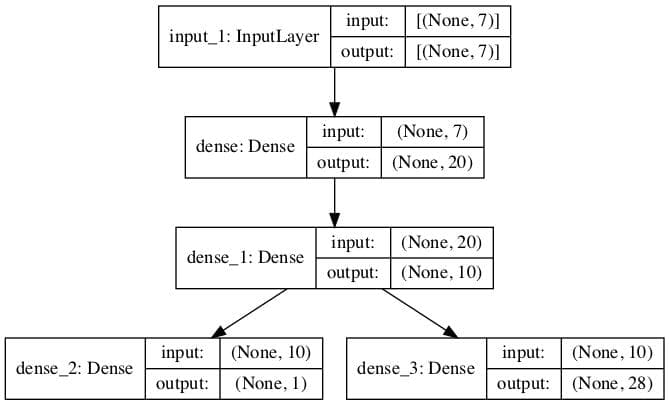
We can also create a plot of the model for reference.
This requires that pydot and pygraphviz are installed. If this is a problem, you can comment out this line and the import statement for the plot_model() function.
The fit model can then make a regression and classification prediction for each example in the hold-out test set.
1
2
3
...
# make predictions on test set
yhat1,yhat2=model.predict(X_test)
The first array can be used to evaluate the regression predictions via mean absolute error.
1
2
3
4
...
# calculate error for regression model
error=mean_absolute_error(y_test,yhat1)
print('MAE: %.3f'%error)
The second array can be used to evaluate the classification predictions via classification accuracy.
1
2
3
4
5
...
# evaluate accuracy for classification model
yhat2=argmax(yhat2,axis=-1).astype('int')
acc=accuracy_score(y_test_class,yhat2)
print('Accuracy: %.3f'%acc)
And that’s it.
Tying this together, the complete example of training and evaluating a multi-output model for combiner regression and classification predictions on the abalone dataset is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
# mlp for combined regression and classification predictions on the abalone dataset
from numpy import unique
from numpy import argmax
from pandas import read_csv
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
Running the example will prepare the dataset, fit the model, and report an estimate of model error.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
A plot of the multi-output model is created, clearly showing the regression (left) and classification (right) output layers connected to the second hidden layer of the model.
Plot of the Multi-Output Model for Combine Regression and Classification Predictions
In this case, we can see that the model achieved both a reasonable error of about 1.495 (rings) and a similar accuracy as before of about 25.6%.
Hi Jason,
Would it be possible to use the Sequential method for the “Combined Regression and Classification Models” ? (Like in the Regression and Classification Model examples).
y_values could be a numpy array array([y, y_class ])
The unit of last Dense layer would be equal to 2.
But in that case, what would be the activation of this last layer ?
And what would be the loss attribute in the compile function ?
Very interesting tutorial !. Specially to get familiar with API Model Keras. Thank you.
Anyway, I think both problems are better analyzed in a separate way.
I share my code experiment.
– It was simply to use the own model.evaluate () method to get out the metrics. “mae” for regression part of the full model and ‘accuracy’ for the classification part.
Previously I have to add, at the compilation model method, the ‘metrics’ argument equal to [‘mae’, ‘accuracy´].
The only confusing thing is when you get the output of model.evaluate() you have all cross combinations for ‘mae’ and ‘accuracy’, even for the opposite layer of classifier and regressor.
So I decided to put names on the outputs layers (at model creation) to get a better identification of the right ones!
I think the code needs a little revision:
1) The name should be dataframe instead of dataset
2) We should use iloc to access the dataframe in index format
>>> X, y = dataframe.iloc[:, 1:-1], dataframe.iloc[:, -1]
>>> X, y = X.astype(‘float’), y.astype(‘float’)
>>> n_features = X.shape[1]
Hello Jason, Your blogs are great. This is what exactly I was looking for. This works great but I need a slight modification can you please suggest me the best solution.
I have a classification and regression problem for the image dataset. My regression is dependent on the classification, i.e. for example: If Class=1, then Regression prediction should be = 0. How will I force my ML model to predict zero when Class=1 without building different classification model.
I have a scenario where i need to forecast a single sequence of time series values first based on the last 10 sequences and based on the forecasted value sequence i need to check under which class label that single sequence falls out of 7 classes.
Thank you for the insightful article on combined regression and classification neural network model. I had few queries from my side concerning the model.
1. Does the model capture the dependency between the two output variables or do we assume they are independent of each other?
2. In the given example, it seems that the same output variable is being classified and same output variable is used for regression. Can we use two different output variables, one for regression and other for classification and run the model ?
The model should not assume (1) but it will learn it. Remember, the network model is non-linear. The dependency in that case is not as trivial as linear dependency. For (2), I don’t see that is the same. Note that there are y and y_class, which the latter is a transformed result of the former.
Thank you for your response. In the model I am working on, I have 2 different variables dependent on each other and are outputs. One variable is numeric and other variable is categorical. The rest of the variables are inputs.
I tried running the combined model and found that the regression aspect of the model was working well returning almost the same outputs as compared to a neural network model that does only regression (The second categorical output variable that I mentioned earlier was input to this model).
However, when it comes to classification, I am getting very low numbers (of the order 10^-5) instead of class labels(6 classes). Any insights from your side would help. Otherwise, can we connect on LinkedIn or email?
When I tried to run the code given on this page as it is, the regression part is giving good predictions. But the classification part is giving predictions of the order of 10^-5 or even lower. The loss function values for both regression and classification were exactly the same values which are shown in this web page. Is there anything else I need to do for the classification part?
Thanks for your insights Adrian. The code is working fine now.
For general insight, could you elaborate a bit on how the model predicts 2 output variables. Let us say we have inputs x1….x7 & output variables y1 and y2. For predicting y1, does the model take x1…x7 as input or does the model take x1…x7 including y2 as input. Similarly how does it do for y2 ?
Can I use this technique to predict on data across multiple quarters (time-series). If yes, in what way can I modify it ?
Usually we will not have y1 and y2 in the input, because if you call it the output, that means we should not know it beforehand. But for time-series, you may include the lagged version of y1 and y2. For example, predicting GDP of next quarter, you may use the GDP of this quarter, stock market performance, unemployment rate of today, etc.
My question is related with the Loss, is there a problem if you are combining differents functions to calculate it?
To calculate the weights of the NN, how can be affected if you are ussing different losses at the same time? or simply the NN will adjust the weights onto minimizes the general output error?
You can define your own loss function but you use one loss function to train the neural network (or otherwise, gradient descent won’t work). You can make use of a different loss function to keep track on the performance of partially-trained network, e.g., in the validation steps.
If you are to train a model, there should only be one loss function for the training. This is the loss that training will try to minimize. For validation, however, you can use many different functions.
This is a very important nuance omitted from the solution. The quick and dirty approach is to transform the regression targets, so you are at least in the same ballpark when combining the losses, another dirty approach might be to rescale the losses in the model. compile call. A bit better approach would be to use callbacks and update the weights with every epoch. At the moment, I am looking further into this.
Hi Ngoc-Tuan Do…Weights and bias are adjusted during training via backgpropagation utilizing a form of gradient descent for optimization. The following may be of interest to you:
In the above example, you can do one regression, one classification, but got multiple outputs in a similar way.
(The labels to classify are biased (in many cases), but in the case of multiple outputs, how do you stratified sampling?
Hi Jason,
I have a question about the classification part – we obtain at the end Accuracy: 0.256. Isn’t it too low and how we can improve it? If I understand this article right it is approach to combine the two models which does not improve the accuracy but rather sparing one pass.
First of all, thank you very much for your work! you have already helped a lot me with all your tutorials.
In regard to the two output layers (Regression and Classification) and the keras functional API:
can i somehow combine that with the ImageDataGenerator?
It seems that
iterator_train = datagen.flow(
x = x_train,
y = [y_train_reg, y_train_class],
batch_size=batch_size,
seed = datagen_seed
)
So i have build a network with two outputlayers. One outputlayer has 3 Neurons with relu activation and mse as loss for regression and the second outputlayer has 1 Neuron for classificaiton (loss is binary_crossentropy).
thats how the end of the network looks like
x = keras.layers.Dense(256, activation=”relu”)(x)
x = keras.layers.Dropout(0.5)(x)
out_reg = keras.layers.Dense(3, activation=last_layer_activation_function_reg)(x)
out_clas = keras.layers.Dense(1, activation=last_layer_activation_function_clas)(x)
building the model works fine, also training it without the ImageDataGenerator works as well.
The Error arises when I try to train the model with a generator with two label vecotors y_train_reg and y_train_clas (ImageDataGenerator from Keras)
datagen = ImageDataGenerator(
horizontal_flip=horizontal_flip,
vertical_flip=vertical_flip,
rotation_range=rotation_angle,
#brightness_range=brightness_range,
zoom_range=zoom_range,
shear_range=shear_range
)
iterator_train = datagen.flow(
x = x_train,
y = [y_train_reg, y_train_class], <————————————– HERE
batch_size=batch_size,
seed = datagen_seed
)
Error Message:
iterator_train = datagen.flow(
File "C:\Users\Anwender\AppData\Local\Programs\Python\Python38\lib\site-packages\keras\preprocessing\image.py", line 884, in flow
return NumpyArrayIterator(
File "C:\Users\Anwender\AppData\Local\Programs\Python\Python38\lib\site-packages\keras\preprocessing\image.py", line 463, in __init__
super(NumpyArrayIterator, self).__init__(
File "C:\Users\Anwender\AppData\Local\Programs\Python\Python38\lib\site-packages\keras_preprocessing\image\numpy_array_iterator.py", line 89, in __init__
(np.asarray(x).shape, np.asarray(y).shape))
File "C:\Users\Anwender\AppData\Local\Programs\Python\Python38\lib\site-packages\numpy\core\_asarray.py", line 83, in asarray
return array(a, dtype, copy=False, order=order)
ValueError: could not broadcast input array from shape (5449,3) into shape (5449)
Hi James,
thanks for your work. Is it possible to add a predefined weight to tell the model, which output layer is more important? (In the sense of an optimisation task).
Hi. In my case, I’ve got two different target variables. One is binary (classification) and the other is continuous (regression). In defining my X and y, do I need to do something like this:
X = df.drop(columns=[‘y_1’, ‘y_2’], axis=1)?
y_clas = df[‘y_1’]
y_reg = df[‘y_2’]?
And if this is the case, how and where do I feed these into the networks?
Hi Wonder…Yes, you’re on the right track with your approach to defining your feature matrix (X) and target variables (y) for your binary classification and regression tasks.
1. **Defining X and y:**
– X: Your feature matrix typically consists of all the predictor variables/features you’ll use to make predictions.
– y_clas: This would be your binary classification target variable.
– y_reg: This would be your continuous regression target variable.
So, your code snippet would look like this: python
X = df.drop(columns=['y_1', 'y_2'], axis=1)
y_clas = df['y_1']
y_reg = df['y_2']
2. **Training the Models:**
– For the binary classification task, you would train a classifier (e.g., logistic regression, decision tree, neural network) using X and y_clas.
– For the regression task, you would train a regression model (e.g., linear regression, random forest regression, neural network) using X and y_reg.
Here’s a simplified example of how you might train a neural network for each task using Python’s TensorFlow and Keras:
python
# Binary Classification Model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# Define and compile the model
model_clas = Sequential()
model_clas.add(Dense(64, activation='relu', input_shape=(X.shape[1],)))
model_clas.add(Dense(1, activation='sigmoid')) # Assuming binary classification
model_clas.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
model_clas.fit(X, y_clas, epochs=10, batch_size=32, validation_split=0.2)
# Regression Model
# Define and compile the model
model_reg = Sequential()
model_reg.add(Dense(64, activation='relu', input_shape=(X.shape[1],)))
model_reg.add(Dense(1)) # Output layer for regression
model_reg.compile(optimizer='adam', loss='mean_squared_error')
# Train the model
model_reg.fit(X, y_reg, epochs=10, batch_size=32, validation_split=0.2)
In these examples, X is the feature matrix containing all your predictor variables except the target variables y_1 and y_2. y_clas is used for training the binary classification model, and y_reg is used for training the regression model.
Make sure to adjust the architecture, activation functions, loss functions, and other hyperparameters based on the specifics of your problem and data.
Hello,
Can anyone help me understand why when I run the code in Jupyter labs the epoch output data line doesn’t separate the output layer losses like
Epoch 145/150
88/88 – 0s – loss: 6.5707 – dense_2_loss: 4.5396 – dense_3_loss: 2.0311
It just spits out
Epoch 145/150
88/88 – 0s – loss: 6.5707
Hi struggling…Yes, the method you’re referring to can indeed be called multitasking. In the context of neural networks, multitasking refers to training a single model to perform multiple tasks simultaneously. These tasks can be of different types, such as classification and regression.
For example, in a multitasking neural network, you might have one output layer dedicated to classification (e.g., predicting a class label) and another output layer dedicated to regression (e.g., predicting a continuous value). The model learns shared representations in the earlier layers and then branches out to handle the specific tasks, allowing it to leverage commonalities between the tasks while still being specialized in each one.
Multitasking can be beneficial as it often leads to better generalization, especially when the tasks are related. The model can learn from the combined signals of both tasks, potentially improving its performance on each individual task compared to training separate models for classification and regression.

")



")

Hi, Are there examples from healthcare where neural networks can solve the problem of both regression and classification?
Sure. You can search scholar.google.com
hi jason
can you explain one example of classification model with microarray gene expression dataset
Thanks for the suggestion.
Hi Jason,
this model can be performed on data with multi-outputs?
Thanks
Perhaps this would be a more appropriate model:
https://machinelearningmastery.com/multi-output-regression-models-with-python/
Thanks,
I will check.
You’re welcome.
Hi Jason,
Would it be possible to use the Sequential method for the “Combined Regression and Classification Models” ? (Like in the Regression and Classification Model examples).
y_values could be a numpy array array([y, y_class ])
The unit of last Dense layer would be equal to 2.
But in that case, what would be the activation of this last layer ?
And what would be the loss attribute in the compile function ?
Thank you very much
I don’t see why not.
You may have to make large changes to the model.
Hi Jason,
Very interesting tutorial !. Specially to get familiar with API Model Keras. Thank you.
Anyway, I think both problems are better analyzed in a separate way.
I share my code experiment.
– It was simply to use the own model.evaluate () method to get out the metrics. “mae” for regression part of the full model and ‘accuracy’ for the classification part.
Previously I have to add, at the compilation model method, the ‘metrics’ argument equal to [‘mae’, ‘accuracy´].
The only confusing thing is when you get the output of model.evaluate() you have all cross combinations for ‘mae’ and ‘accuracy’, even for the opposite layer of classifier and regressor.
So I decided to put names on the outputs layers (at model creation) to get a better identification of the right ones!
Thanks.
Hmmm, perhaps evaluate() is not a good tool for such a complex model.
I think the code needs a little revision:
1) The name should be
dataframeinstead ofdataset2) We should use
ilocto access thedataframein index format>>> X, y = dataframe.iloc[:, 1:-1], dataframe.iloc[:, -1]
>>> X, y = X.astype(‘float’), y.astype(‘float’)
>>> n_features = X.shape[1]
I prefer to work with numpy arrays directly.
Hello Jason, Your blogs are great. This is what exactly I was looking for. This works great but I need a slight modification can you please suggest me the best solution.
I have a classification and regression problem for the image dataset. My regression is dependent on the classification, i.e. for example: If Class=1, then Regression prediction should be = 0. How will I force my ML model to predict zero when Class=1 without building different classification model.
Thank you so much.
Thanks!
Perhaps you can chain the models sequentially, perhaps manually.
Thanks Jason, Is it possible to train both models together if it is sequentially chained?
Hi Jason,
I have a scenario where i need to forecast a single sequence of time series values first based on the last 10 sequences and based on the forecasted value sequence i need to check under which class label that single sequence falls out of 7 classes.
Thanks
I recommend testing a suite of models in order to discover what works well or best for your dataset.
Can you please provide me an example or a brief explanation on what you meant by suit of models ?
Thanks
Sorry, I mean many different model types or configurations.
Thanks got it 😉
Hi Jason,
Thank you for the insightful article on combined regression and classification neural network model. I had few queries from my side concerning the model.
1. Does the model capture the dependency between the two output variables or do we assume they are independent of each other?
2. In the given example, it seems that the same output variable is being classified and same output variable is used for regression. Can we use two different output variables, one for regression and other for classification and run the model ?
The model should not assume (1) but it will learn it. Remember, the network model is non-linear. The dependency in that case is not as trivial as linear dependency. For (2), I don’t see that is the same. Note that there are y and y_class, which the latter is a transformed result of the former.
Hi Adrian,
Thank you for your response. In the model I am working on, I have 2 different variables dependent on each other and are outputs. One variable is numeric and other variable is categorical. The rest of the variables are inputs.
I tried running the combined model and found that the regression aspect of the model was working well returning almost the same outputs as compared to a neural network model that does only regression (The second categorical output variable that I mentioned earlier was input to this model).
However, when it comes to classification, I am getting very low numbers (of the order 10^-5) instead of class labels(6 classes). Any insights from your side would help. Otherwise, can we connect on LinkedIn or email?
When I tried to run the code given on this page as it is, the regression part is giving good predictions. But the classification part is giving predictions of the order of 10^-5 or even lower. The loss function values for both regression and classification were exactly the same values which are shown in this web page. Is there anything else I need to do for the classification part?
It is not my case. You can try add these two lines at the end after you print the accuracy to compare the output side by side:
import pandas as pd
print(pd.DataFrame({“y”:y_test.ravel(), “yhat”:yhat1.ravel(), “y_cls”: y_test_class.ravel(), “yhat_cls”:yhat2.ravel()}))
Thanks for your insights Adrian. The code is working fine now.
For general insight, could you elaborate a bit on how the model predicts 2 output variables. Let us say we have inputs x1….x7 & output variables y1 and y2. For predicting y1, does the model take x1…x7 as input or does the model take x1…x7 including y2 as input. Similarly how does it do for y2 ?
Can I use this technique to predict on data across multiple quarters (time-series). If yes, in what way can I modify it ?
Usually we will not have y1 and y2 in the input, because if you call it the output, that means we should not know it beforehand. But for time-series, you may include the lagged version of y1 and y2. For example, predicting GDP of next quarter, you may use the GDP of this quarter, stock market performance, unemployment rate of today, etc.
Hello Jason, thanks for your example.
My question is related with the Loss, is there a problem if you are combining differents functions to calculate it?
To calculate the weights of the NN, how can be affected if you are ussing different losses at the same time? or simply the NN will adjust the weights onto minimizes the general output error?
You can define your own loss function but you use one loss function to train the neural network (or otherwise, gradient descent won’t work). You can make use of a different loss function to keep track on the performance of partially-trained network, e.g., in the validation steps.
If you are to train a model, there should only be one loss function for the training. This is the loss that training will try to minimize. For validation, however, you can use many different functions.
This is a very important nuance omitted from the solution. The quick and dirty approach is to transform the regression targets, so you are at least in the same ballpark when combining the losses, another dirty approach might be to rescale the losses in the
model. compilecall. A bit better approach would be to use callbacks and update the weights with every epoch. At the moment, I am looking further into this.Thank you for very interesting post. Could you please explain how the dense layer (hidden1 layer) weights are updated in the training phase?
Hi Ngoc-Tuan Do…Weights and bias are adjusted during training via backgpropagation utilizing a form of gradient descent for optimization. The following may be of interest to you:
https://machinelearningmastery.com/a-gentle-introduction-to-the-challenge-of-training-deep-learning-neural-network-models/
In the above example, you can do one regression, one classification, but got multiple outputs in a similar way.
(The labels to classify are biased (in many cases), but in the case of multiple outputs, how do you stratified sampling?
Hi Jason,
I have a question about the classification part – we obtain at the end Accuracy: 0.256. Isn’t it too low and how we can improve it? If I understand this article right it is approach to combine the two models which does not improve the accuracy but rather sparing one pass.
Hi Anthony…The tutorial was meant to be an example of how to approach the technique, however the models were not optimized.
Hey James!
First of all, thank you very much for your work! you have already helped a lot me with all your tutorials.
In regard to the two output layers (Regression and Classification) and the keras functional API:
can i somehow combine that with the ImageDataGenerator?
It seems that
iterator_train = datagen.flow(
x = x_train,
y = [y_train_reg, y_train_class],
batch_size=batch_size,
seed = datagen_seed
)
does not work :/
thanks!
Hi Marian…Thank you for the feedback and support! Please clarify or describe how your model “does not work”. This will enable us to better assist you.
Sure!
So i have build a network with two outputlayers. One outputlayer has 3 Neurons with relu activation and mse as loss for regression and the second outputlayer has 1 Neuron for classificaiton (loss is binary_crossentropy).
thats how the end of the network looks like
x = keras.layers.Dense(256, activation=”relu”)(x)
x = keras.layers.Dropout(0.5)(x)
out_reg = keras.layers.Dense(3, activation=last_layer_activation_function_reg)(x)
out_clas = keras.layers.Dense(1, activation=last_layer_activation_function_clas)(x)
building the model works fine, also training it without the ImageDataGenerator works as well.
The Error arises when I try to train the model with a generator with two label vecotors y_train_reg and y_train_clas (ImageDataGenerator from Keras)
# image augmentation
horizontal_flip = True
vertical_flip = True
rotation_angle = 5
brightness_range = None
zoom_range = [1.0, 1.5]
shear_range = 0.2
datagen = ImageDataGenerator(
horizontal_flip=horizontal_flip,
vertical_flip=vertical_flip,
rotation_range=rotation_angle,
#brightness_range=brightness_range,
zoom_range=zoom_range,
shear_range=shear_range
)
iterator_train = datagen.flow(
x = x_train,
y = [y_train_reg, y_train_class], <————————————– HERE
batch_size=batch_size,
seed = datagen_seed
)
Error Message:
iterator_train = datagen.flow(
File "C:\Users\Anwender\AppData\Local\Programs\Python\Python38\lib\site-packages\keras\preprocessing\image.py", line 884, in flow
return NumpyArrayIterator(
File "C:\Users\Anwender\AppData\Local\Programs\Python\Python38\lib\site-packages\keras\preprocessing\image.py", line 463, in __init__
super(NumpyArrayIterator, self).__init__(
File "C:\Users\Anwender\AppData\Local\Programs\Python\Python38\lib\site-packages\keras_preprocessing\image\numpy_array_iterator.py", line 89, in __init__
(np.asarray(x).shape, np.asarray(y).shape))
File "C:\Users\Anwender\AppData\Local\Programs\Python\Python38\lib\site-packages\numpy\core\_asarray.py", line 83, in asarray
return array(a, dtype, copy=False, order=order)
ValueError: could not broadcast input array from shape (5449,3) into shape (5449)
can you explain one example of classification model with microarray gene expression dataset
Thank you for the suggestion! The following is a complete listing of the our current content.
https://machinelearningmastery.com/start-here/
hi Jamesh,
thank you very much for your work, can you help me to understand , how can I combine 2 classifier and 1 regression. I want three outputs
Hi Hari…The following resource is a great starting point for your query:
https://machinelearningmastery.com/ensemble-machine-learning-with-python-7-day-mini-course/
Hi James,
could you please write about how to optimize these models for better results?
Hi Saeideh…You may find the following resource of interest:
https://machinelearningmastery.com/combined-algorithm-selection-and-hyperparameter-optimization/
Hi James,
thanks for your work. Is it possible to add a predefined weight to tell the model, which output layer is more important? (In the sense of an optimisation task).
Hi Stefan…You are very welcome! The following resource may be of interest:
https://machinelearningmastery.com/weight-initialization-for-deep-learning-neural-networks/
Hi. In my case, I’ve got two different target variables. One is binary (classification) and the other is continuous (regression). In defining my X and y, do I need to do something like this:
X = df.drop(columns=[‘y_1’, ‘y_2’], axis=1)?
y_clas = df[‘y_1’]
y_reg = df[‘y_2’]?
And if this is the case, how and where do I feed these into the networks?
Hi Wonder…Yes, you’re on the right track with your approach to defining your feature matrix (X) and target variables (y) for your binary classification and regression tasks.
1. **Defining X and y:**
–
X: Your feature matrix typically consists of all the predictor variables/features you’ll use to make predictions.–
y_clas: This would be your binary classification target variable.–
y_reg: This would be your continuous regression target variable.So, your code snippet would look like this:
python
X = df.drop(columns=['y_1', 'y_2'], axis=1)
y_clas = df['y_1']
y_reg = df['y_2']
2. **Training the Models:**
– For the binary classification task, you would train a classifier (e.g., logistic regression, decision tree, neural network) using
Xandy_clas.– For the regression task, you would train a regression model (e.g., linear regression, random forest regression, neural network) using
Xandy_reg.Here’s a simplified example of how you might train a neural network for each task using Python’s TensorFlow and Keras:
python# Binary Classification Model
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# Define and compile the model
model_clas = Sequential()
model_clas.add(Dense(64, activation='relu', input_shape=(X.shape[1],)))
model_clas.add(Dense(1, activation='sigmoid')) # Assuming binary classification
model_clas.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
model_clas.fit(X, y_clas, epochs=10, batch_size=32, validation_split=0.2)
# Regression Model
# Define and compile the model
model_reg = Sequential()
model_reg.add(Dense(64, activation='relu', input_shape=(X.shape[1],)))
model_reg.add(Dense(1)) # Output layer for regression
model_reg.compile(optimizer='adam', loss='mean_squared_error')
# Train the model
model_reg.fit(X, y_reg, epochs=10, batch_size=32, validation_split=0.2)
In these examples,
Xis the feature matrix containing all your predictor variables except the target variablesy_1andy_2.y_clasis used for training the binary classification model, andy_regis used for training the regression model.Make sure to adjust the architecture, activation functions, loss functions, and other hyperparameters based on the specifics of your problem and data.
Hello,
Can anyone help me understand why when I run the code in Jupyter labs the epoch output data line doesn’t separate the output layer losses like
Epoch 145/150
88/88 – 0s – loss: 6.5707 – dense_2_loss: 4.5396 – dense_3_loss: 2.0311
It just spits out
Epoch 145/150
88/88 – 0s – loss: 6.5707
Hi Jordan…Have you tried your code in Google Colab? Just curious if you experience any difference.
Hello, can this method be called multitasking?
Hi struggling…Yes, the method you’re referring to can indeed be called multitasking. In the context of neural networks, multitasking refers to training a single model to perform multiple tasks simultaneously. These tasks can be of different types, such as classification and regression.
For example, in a multitasking neural network, you might have one output layer dedicated to classification (e.g., predicting a class label) and another output layer dedicated to regression (e.g., predicting a continuous value). The model learns shared representations in the earlier layers and then branches out to handle the specific tasks, allowing it to leverage commonalities between the tasks while still being specialized in each one.
Multitasking can be beneficial as it often leads to better generalization, especially when the tasks are related. The model can learn from the combined signals of both tasks, potentially improving its performance on each individual task compared to training separate models for classification and regression.
Okay, I understand. Thank you for your reply