Deep learning neural networks are a flexible class of machine learning algorithms that perform well on a wide range of problems.
Neural networks are trained using the backpropagation of error algorithm that involves calculating errors made by the model on the training dataset and updating the model weights in proportion to those errors. The limitation of this method of training is that examples from each class are treated the same, which for imbalanced datasets means that the model is adapted a lot more for one class than another.
The backpropagation algorithm can be updated to weigh misclassification errors in proportion to the importance of the class, referred to as weighted neural networks or cost-sensitive neural networks. This has the effect of allowing the model to pay more attention to examples from the minority class than the majority class in datasets with a severely skewed class distribution.
In this tutorial, you will discover weighted neural networks for imbalanced classification.
After completing this tutorial, you will know:
How the standard neural network algorithm does not support imbalanced classification.
How the neural network training algorithm can be modified to weight misclassification errors in proportion to class importance.
How to configure class weight for neural networks and evaluate the effect on model performance.
Kick-start your project with my new book Imbalanced Classification with Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
How to Develop a Cost-Sensitive Neural Network for Imbalanced Classification Photo by Bernard Spragg. NZ, some rights reserved.
Tutorial Overview
This tutorial is divided into four parts; they are:
Imbalanced Classification Dataset
Neural Network Model in Keras
Deep Learning for Imbalanced Classification
Weighted Neural Network With Keras
Imbalanced Classification Dataset
Before we dive into the modification of neural networks for imbalanced classification, let’s first define an imbalanced classification dataset.
We can use the make_classification() function to define a synthetic imbalanced two-class classification dataset. We will generate 10,000 examples with an approximate 1:100 minority to majority class ratio.
Once generated, we can summarize the class distribution to confirm that the dataset was created as we expected.
1
2
3
4
...
# summarize class distribution
counter=Counter(y)
print(counter)
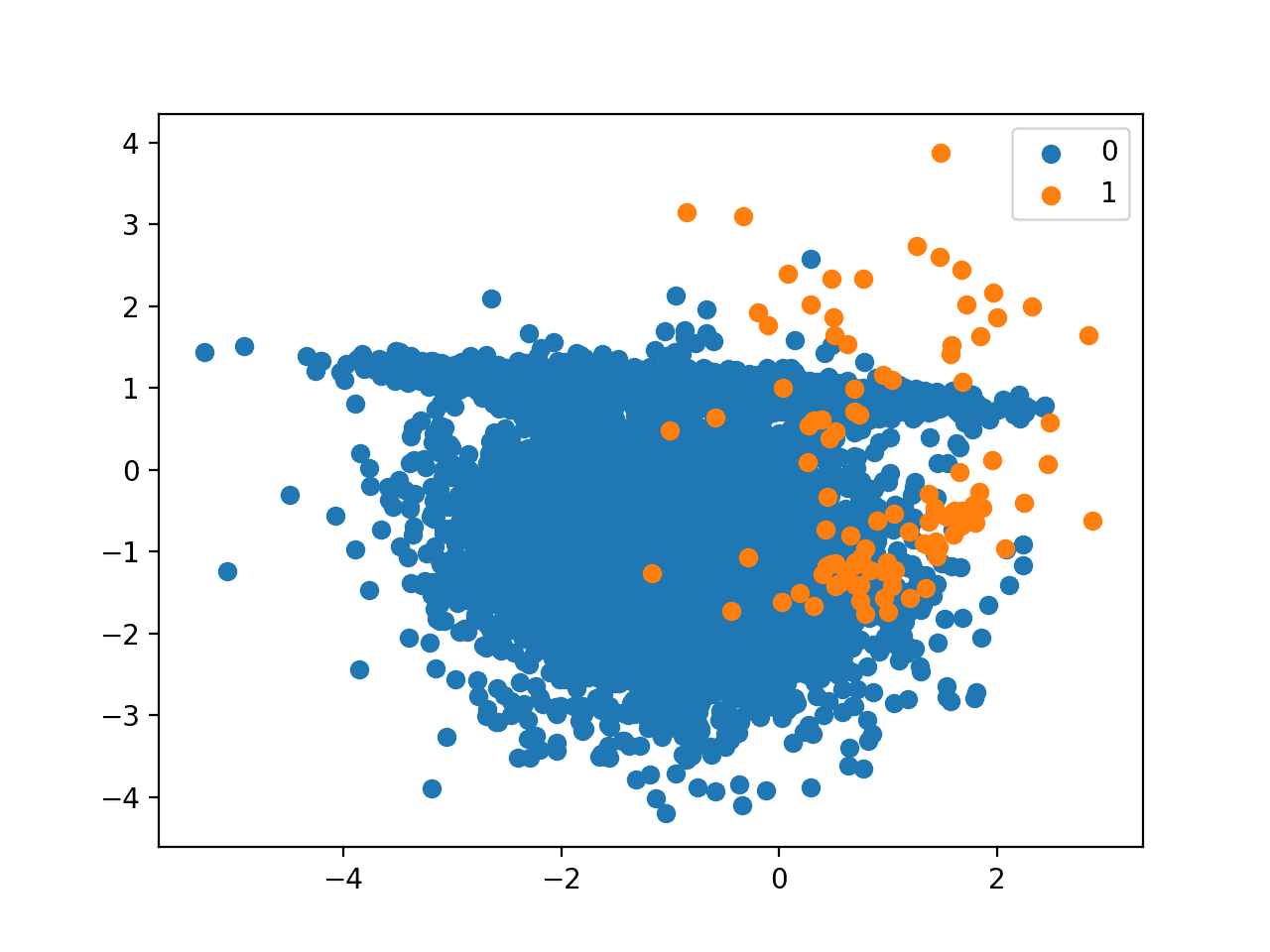
Finally, we can create a scatter plot of the examples and color them by class label to help understand the challenge of classifying examples from this dataset.
Running the example first creates the dataset and summarizes the class distribution.
We can see that the dataset has an approximate 1:100 class distribution with a little less than 10,000 examples in the majority class and 100 in the minority class.
1
Counter({0: 9900, 1: 100})
Next, a scatter plot of the dataset is created showing the large mass of examples for the majority class (blue) and a small number of examples for the minority class (orange), with some modest class overlap.
Scatter Plot of Binary Classification Dataset with 1 to 100 Class Imbalance
Want to Get Started With Imbalance Classification?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Neural Network Model in Keras
Next, we can fit a standard neural network model on the dataset.
First, we can define a function to create the synthetic dataset and split it into separate train and test datasets with 5,000 examples in each.
A Multilayer Perceptron neural network can be defined using the Keras deep learning library. We will define a neural network that expects two input variables, has one hidden layer with 10 nodes, then an output layer that predicts the class label.
We will use the popular ReLU activation function in the hidden layer and the sigmoid activation function in the output layer to ensure predictions are probabilities in the range [0,1]. The model will be fit using stochastic gradient descent with the default learning rate and optimized according to cross-entropy loss.
The network architecture and hyperparameters are not optimized to the problem; instead, the network provides a basis for comparison when the training algorithm is later modified to handle the skewed class distribution.
The define_model() function below defines and returns the model, taking the number of input variables to the network as an argument.
Running the example evaluates the neural network model on the imbalanced dataset and reports the ROC AUC.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, the model achieves a ROC AUC of about 0.949. This suggests that the model has some skill as compared to the naive classifier that has a ROC AUC of 0.5.
1
ROC AUC: 0.949
This provides a baseline for comparison for any modifications performed to the standard neural network training algorithm.
Deep Learning for Imbalanced Classification
Neural network models are commonly trained using the backpropagation of error algorithm.
This involves using the current state of the model to make predictions for training set examples, calculating the error for the predictions, then updating the model weights using the error, and assigning credit for the error to different nodes and layers backward from the output layer back through to the input layer.
Given the balanced focus on misclassification errors, most standard neural network algorithms are not well suited to datasets with a severely skewed class distribution.
Most of the existing deep learning algorithms do not take the data imbalance problem into consideration. As a result, these algorithms can perform well on the balanced data sets while their performance cannot be guaranteed on imbalanced data sets.
This training procedure can be modified so that some examples have more or less error than others.
The misclassification costs can also be taken in account by changing the error function that is being minimized. Instead of minimizing the squared error, the backpropagation learning procedure should minimize the misclassification costs.
The simplest way to implement this is to use a fixed weighting of error scores for examples based on their class where the prediction error is increased for examples in a more important class and decreased or left unchanged for those examples in a less important class.
… cost sensitive learning methods solve data imbalance problem based on the consideration of the cost associated with misclassifying samples. In particular, it assigns different cost values for the misclassification of the samples.
A large error weighting can be applied to those examples in the minority class as they are often more important in an imbalanced classification problem than examples from the majority class.
Large Weight: Assigned to examples from the minority class.
Small Weight: Assigned to examples from the majority class.
This modification to the neural network training algorithm is referred to as a Weighted Neural Network or Cost-Sensitive Neural Network.
Typically, careful attention is required when defining the costs or “weightings” to use for cost-sensitive learning. However, for imbalanced classification where only misclassification is the focus, the weighting can use the inverse of the class distribution observed in the training dataset.
Weighted Neural Network With Keras
The Keras Python deep learning library provides support class weighting.
The fit() function that is used to train Keras neural network models takes an argument called class_weight. This argument allows you to define a dictionary that maps class integer values to the importance to apply to each class.
This function is used to train each different type of neural network, including Multilayer Perceptrons, Convolutional Neural Networks, and Recurrent Neural Networks, therefore the class weighting capability is available to all of those network types.
For example, a 1 to 1 weighting for each class 0 and 1 can be defined as follows:
The class weighing can be defined multiple ways; for example:
Domain expertise, determined by talking to subject matter experts.
Tuning, determined by a hyperparameter search such as a grid search.
Heuristic, specified using a general best practice.
A best practice for using the class weighting is to use the inverse of the class distribution present in the training dataset.
For example, the class distribution of the test dataset is a 1:100 ratio for the minority class to the majority class. The invert of this ratio could be used with 1 for the majority class and 100 for the minority class, for example:
Fractions that represent the same ratio do not have the same effect. For example, using 0.01 and 0.99 for the majority and minority classes respectively may result in worse performance than using 1 and 100 (it does in this case).
The reason is that the error for examples drawn from both the majority class and the minority class is reduced. Further, the reduction in error from the majority class is dramatically scaled down to very small numbers that may have limited or only a very minor effect on model weights.
As such integers are recommended to represent the class weightings, such as 1 for no change and 100 for misclassification errors for class 1 having 100-times more impact or penalty than misclassification errors for class 0.
We can evaluate the neural network algorithm with a class weighting using the same evaluation procedure defined in the previous section.
We would expect the class-weighted version of the neural network to perform better than the version of the training algorithm without any class weighting.
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# class weighted neural network on an imbalanced classification dataset
Running the example prepares the synthetic imbalanced classification dataset, then evaluates the class-weighted version of the neural network training algorithm.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
The ROC AUC score is reported, in this case showing a better score than the unweighted version of the training algorithm, or about 0.973 as compared to about 0.949.
1
ROC AUC: 0.973
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
It provides self-study tutorials and end-to-end projects on: Performance Metrics, Undersampling Methods, SMOTE, Threshold Moving, Probability Calibration, Cost-Sensitive Algorithms
and much more...
Bring Imbalanced Classification Methods to Your Machine Learning Projects
For product classification from customer queries, in case I have a 50k rows of pre-labelled dataset with two columns, one is customer queries, one has 50 classes ( 50 labels of products)
I will use this dataset as the training dataset. what is the parameters I need to put in :
# define the first hidden layer and visible layer
model.add(Dense(10, input_dim=n_input, activation=’relu’, kernel_initializer=’he_uniform’))
# define output layer
model.add(Dense(1, activation=’sigmoid’))
My dataset also happens multi-label problems. For example, customer querry ” T-shirt with short hand” is labelled in both class A and B
So in this case , Could you recommend me some solutions
Hello Jason,
I’ve heard about meta-model in Machine Learning as ‘concatenation’ of two o more models together.
Is it used and when is it possible to use? Is it possible in sklearn and/ or keras?
What are pros/ cons?
Do you have an example?
Thanks
Hi, great article. How do you modify these for multiclass problem? I am having trouble with the loss function and the final layers I have 7 classes and do not know if I have to proceed with only one neuron in the final layer or seven. It is also an imbalance class problem.
in the function define_model what is the most important parameter which indicates we have to do with imbalance data. I mean the exact same function we use for balance dataset.
def define_model(n_input):
# define model
model = Sequential()
# define first hidden layer and visible layer
model.add(Dense(10, input_dim=n_input, activation=’relu’, kernel_initializer=’he_uniform’))
# define output layer
model.add(Dense(1, activation=’sigmoid’))
# define loss and optimizer
model.compile(loss=’binary_crossentropy’, optimizer=’sgd’)
return model
I mean which parameter on the above code tells that we have to do with imbalanced data?
As I understood to set up the class_weight argument on keras (.fit) method, for imbalanced dataset set, it is a weight to set up strongest penalty on minority (vs majority) class loss or error to force better fit learning on minority dataset class loss or error, due to the fact that the code see less time the minority class datasets.
Intuitively I think I can reproduce exactly the same learning effect but just copying the minority dataset as many time as majority class dataset (I mean repeating same minority dataset class a certain amount to get the same amount of majority class)? or are different approach being better the class_weight approach ?
You can achieve a similar result using oversampling, but it is a slightly different mechanism, – e.g. weight penalty on each batch update (stochastic composition) vs the composition of the training set.
1. While training DL model for imabance classification and using class weightings what should be prefered performance meteric to monitor ?(During model.compile)
2. In the same case during EarlyStopping calllback what should be the desiered performance parameters?(i.e EarlyStopping(monitor=??? , mode=???)
Thank you for your tutorial! I’ve never seen a detailed tutorial explaining about imbalanced data like this tutorial.
But, I have a problem deal with imbalanced data using class weight.
I am using keras and my dataset’s ratio is 10:1. So, i set weights = {0:1, 1:10}
but its performance wasn’t improved. I confirmed accuracy, precision, recall, f1score.
but these metrics even were worsen.
Was it possible? and do you have any idea for the reason?
Could you give me what I should do for enhancing the performance?
Hi, I’m currently doing some research for my internship and your article is really helpful. There’s just one part of it that isn’t clear to me. Could you explain again why weighting 1-100 is better than 0.01-1 ?
Thanks
I tried for my own dataset, and this method simply gives all sorts of values while calculating the ROC AUC. I’m concerned this is way too much stochastic, and I can’t use it as a validation metric.
Through a Google search on a topic related to Machine Learning, I found your Blog.
I would like to congratulate you for the work and ask for a tip.
I’m starting a Master’s degree and I’m participating in a group where the elaboration of work was chosen, which should develop a classifier that after the samples are classified incorrectly, using a first classifier, he is able to identify and classify them correctly.
I have been researching a lot, but I confess that I am having trouble finding any article that I can use as a basis to carry out the development.
If u have any tips I appreciate
Carlos Reis
Thank you for the tutorial. I am working on a project where my input tensor is a unbalanced binary matrix (m x n x 1). When I tried to use class weight in fit_generator, I am getting the following error: “ValueError: class_weight not supported for 3+ dimensional targets.” It would be very helpful if you have any tips. In my case there are at most [ minimum(m, n)] number of 1’s and the rest are 0s.
Hi Jason, I wonder if it is possible to train a neural network regression with weighted samples in R? If so, could you please recommend some related R packages? Thanks!
Hi Jason, I wonder if you could recommend some python packages for doing weighted neural network regression (not for time series)? Currently, my dataset has explicit heteroscedasticity issues. One of the best way to deal with it is to use weighted regression.








The following package implementated 85 of SMOTE variants:
https://github.com/analyticalmindsltd/smote_variants
tested against 40 benchmark database. Probably this is the best source to look for the optimal oversampler.
Thanks for sharing.
For product classification from customer queries, in case I have a 50k rows of pre-labelled dataset with two columns, one is customer queries, one has 50 classes ( 50 labels of products)
I will use this dataset as the training dataset. what is the parameters I need to put in :
# define the first hidden layer and visible layer
model.add(Dense(10, input_dim=n_input, activation=’relu’, kernel_initializer=’he_uniform’))
# define output layer
model.add(Dense(1, activation=’sigmoid’))
My dataset also happens multi-label problems. For example, customer querry ” T-shirt with short hand” is labelled in both class A and B
So in this case , Could you recommend me some solutions
Thank you very much
The multi-label example here might give you ideas:
https://machinelearningmastery.com/how-to-develop-a-convolutional-neural-network-to-classify-satellite-photos-of-the-amazon-rainforest/
Still model results in trained behavior.. still #AI needs to evolve
What do you mean exactly?
Hello Jason,
I’ve heard about meta-model in Machine Learning as ‘concatenation’ of two o more models together.
Is it used and when is it possible to use? Is it possible in sklearn and/ or keras?
What are pros/ cons?
Do you have an example?
Thanks
Not quite.
You combine multiple models with an average or similar.
You concatenate multiple input models into a broader model, e.g. text and static data, or time series and static data. I have many examples, but perhaps start with the basics here:
https://machinelearningmastery.com/keras-functional-api-deep-learning/
Hi, great article. How do you modify these for multiclass problem? I am having trouble with the loss function and the final layers I have 7 classes and do not know if I have to proceed with only one neuron in the final layer or seven. It is also an imbalance class problem.
Thanks in advance
Thanks.
Offhand, I don’t think Keras support cost-sensitive learning for multi-class classification.
Hi Jason, thanks for your frank answer! Kind regards.
You’re welcome.
Hi Jason, Is there any good practices / tricks for imbalance text classification task?
Great question.
Hmm, off hand I’d suggest carefully selecting the metric, weighted models, explore threshold moving and calibration.
Hi Jason,
in the function define_model what is the most important parameter which indicates we have to do with imbalance data. I mean the exact same function we use for balance dataset.
Sorry, I don’t understand your question.
Perhaps you can rephrase it?
def define_model(n_input):
# define model
model = Sequential()
# define first hidden layer and visible layer
model.add(Dense(10, input_dim=n_input, activation=’relu’, kernel_initializer=’he_uniform’))
# define output layer
model.add(Dense(1, activation=’sigmoid’))
# define loss and optimizer
model.compile(loss=’binary_crossentropy’, optimizer=’sgd’)
return model
I mean which parameter on the above code tells that we have to do with imbalanced data?
None.
or would you defined your model in the same way if you’ve had balanced data?
You can set the “class_weight” argument for imbalanced data.
That is the point of this tutorial. Perhaps re-read it?
oh ok,,,i understood …..the only parameter that helps to classify more accurately imbalanced data is class_weight….on fit part…..is that right?
In this tutorial, yes.
Hi Jason,
thank you for your marvelous tutorial !
As I understood to set up the class_weight argument on keras (.fit) method, for imbalanced dataset set, it is a weight to set up strongest penalty on minority (vs majority) class loss or error to force better fit learning on minority dataset class loss or error, due to the fact that the code see less time the minority class datasets.
Intuitively I think I can reproduce exactly the same learning effect but just copying the minority dataset as many time as majority class dataset (I mean repeating same minority dataset class a certain amount to get the same amount of majority class)? or are different approach being better the class_weight approach ?
thanks
You’re welcome.
You can achieve a similar result using oversampling, but it is a slightly different mechanism, – e.g. weight penalty on each batch update (stochastic composition) vs the composition of the training set.
Hi Jason,
Thanks for your brilliant post. I hope I can use this technique for text classification, too.
What happened if I use the train_test_split method from sklearn to define train and test datasets?
You’re welcome!
Perhaps try and see if it is appropriate for your dataset.
Hi Jason, Please shed some light on this:
1. While training DL model for imabance classification and using class weightings what should be prefered performance meteric to monitor ?(During model.compile)
2. In the same case during EarlyStopping calllback what should be the desiered performance parameters?(i.e EarlyStopping(monitor=??? , mode=???)
Choose a metric that makes sense for your project:
https://machinelearningmastery.com/tour-of-evaluation-metrics-for-imbalanced-classification/
Early stopping should probably use loss, not a metric.
Thank you for your tutorial! I’ve never seen a detailed tutorial explaining about imbalanced data like this tutorial.
But, I have a problem deal with imbalanced data using class weight.
I am using keras and my dataset’s ratio is 10:1. So, i set weights = {0:1, 1:10}
but its performance wasn’t improved. I confirmed accuracy, precision, recall, f1score.
but these metrics even were worsen.
Was it possible? and do you have any idea for the reason?
Could you give me what I should do for enhancing the performance?
Thanks!
Perhaps try other approaches:
https://machinelearningmastery.com/framework-for-imbalanced-classification-projects/
As per tutorial, Assigning class weight sort of balances the dataset. So, can we rely on evaluating final model on accuracy itself?
Yes, choose a metric you trust:
https://machinelearningmastery.com/tour-of-evaluation-metrics-for-imbalanced-classification/
Hi, I’m currently doing some research for my internship and your article is really helpful. There’s just one part of it that isn’t clear to me. Could you explain again why weighting 1-100 is better than 0.01-1 ?
Thanks
It may offer more of a penalty to the model during learning.
I tried for my own dataset, and this method simply gives all sorts of values while calculating the ROC AUC. I’m concerned this is way too much stochastic, and I can’t use it as a validation metric.
Perhaps you can collect more training data to reduce the variance of your model?
Perhaps you can ensemble a suite of final models together to reduce the variance in predictions?
Hi Jason
It’s all right ??
Through a Google search on a topic related to Machine Learning, I found your Blog.
I would like to congratulate you for the work and ask for a tip.
I’m starting a Master’s degree and I’m participating in a group where the elaboration of work was chosen, which should develop a classifier that after the samples are classified incorrectly, using a first classifier, he is able to identify and classify them correctly.
I have been researching a lot, but I confess that I am having trouble finding any article that I can use as a basis to carry out the development.
If u have any tips I appreciate
Carlos Reis
Thanks!
Sounds like a great project. Sounds like a stacking model to me:
https://machinelearningmastery.com/?s=stacking&post_type=post&submit=Search
Thank you for the tip
You’re welcome.
Hi Jason,
Thank you for the tutorial. I am working on a project where my input tensor is a unbalanced binary matrix (m x n x 1). When I tried to use class weight in fit_generator, I am getting the following error: “ValueError:
class_weightnot supported for 3+ dimensional targets.” It would be very helpful if you have any tips. In my case there are at most [ minimum(m, n)] number of 1’s and the rest are 0s.Thank you for your time.
Regards,
Sutanu
Yes, I believe class weight only supports 2d targets, e.g. classification.
Hi Jason, I wonder if it is possible to train a neural network regression with weighted samples in R? If so, could you please recommend some related R packages? Thanks!
Hi Bob…If this is an application related to time-series…Sorry, I do not have material on time series forecasting in R.
I do have a book on time series in Python.
There are already some great books on time series forecast in R, for example, see this post:
Top Books on Time Series Forecasting With R
https://machinelearningmastery.com/books-on-time-series-forecasting-with-r/
Hi Jason, I wonder if you could recommend some python packages for doing weighted neural network regression (not for time series)? Currently, my dataset has explicit heteroscedasticity issues. One of the best way to deal with it is to use weighted regression.
Hi Leon,
Hopefully the following will be of interest:
https://machinelearningmastery.com/deep-learning-models-for-multi-output-regression/
How cost-sensitive method improve the training process of neural network?
Hi Ifran…The following resource presents a study of the benefits to the training process especially for deep learning models.
https://arxiv.org/pdf/1508.03422