The Support Vector Machine algorithm is effective for balanced classification, although it does not perform well on imbalanced datasets.
The SVM algorithm finds a hyperplane decision boundary that best splits the examples into two classes. The split is made soft through the use of a margin that allows some points to be misclassified. By default, this margin favors the majority class on imbalanced datasets, although it can be updated to take the importance of each class into account and dramatically improve the performance of the algorithm on datasets with skewed class distributions.
This modification of SVM that weighs the margin proportional to the class importance is often referred to as weighted SVM, or cost-sensitive SVM.
In this tutorial, you will discover weighted support vector machines for imbalanced classification.
After completing this tutorial, you will know:
How the standard support vector machine algorithm is limited for imbalanced classification.
How the support vector machine algorithm can be modified to weight the margin penalty proportional to class importance during training.
How to configure class weight for the SVM and how to grid search different class weight configurations.
Kick-start your project with my new book Imbalanced Classification with Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
How to Implement Weighted Support Vector Machines for Imbalanced Classification Photo by Bas Leenders, some rights reserved.
Tutorial Overview
This tutorial is divided into four parts; they are:
Imbalanced Classification Dataset
SVM for Imbalanced Classification
Weighted SVM With Scikit-Learn
Grid Search Weighted SVM
Imbalanced Classification Dataset
Before we dive into the modification of SVM for imbalanced classification, let’s first define an imbalanced classification dataset.
We can use the make_classification() function to define a synthetic imbalanced two-class classification dataset. We will generate 10,000 examples with an approximate 1:100 minority to majority class ratio.
Once generated, we can summarize the class distribution to confirm that the dataset was created as we expected.
1
2
3
4
...
# summarize class distribution
counter=Counter(y)
print(counter)
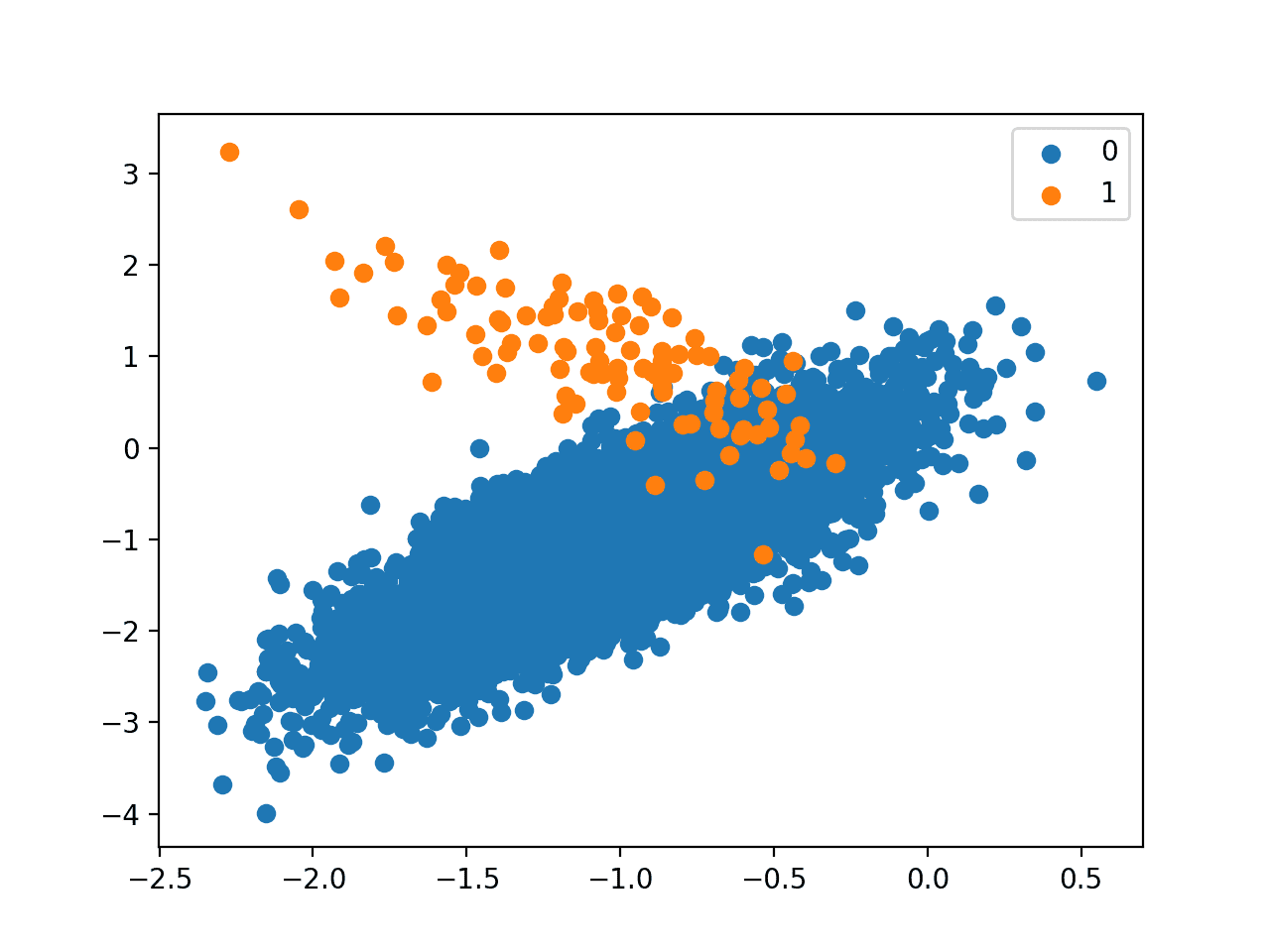
Finally, we can create a scatter plot of the examples and color them by class label to help understand the challenge of classifying examples from this dataset.
Running the example first creates the dataset and summarizes the class distribution.
We can see that the dataset has an approximate 1:100 class distribution with a little less than 10,000 examples in the majority class and 100 in the minority class.
1
Counter({0: 9900, 1: 100})
Next, a scatter plot of the dataset is created showing the large mass of examples for the majority class (blue) and a small number of examples for the minority class (orange), with some modest class overlap.
Scatter Plot of Binary Classification Dataset With 1 to 100 Class Imbalance
Next, we can fit a standard SVM model on the dataset.
An SVM can be defined using the SVC class in the scikit-learn library.
1
2
3
...
# define model
model=SVC(gamma='scale')
We will use repeated cross-validation to evaluate the model, with three repeats of 10-fold cross-validation. The mode performance will be reported using the mean ROC area under curve (ROC AUC) averaged over repeats and all folds.
Running the example evaluates the standard SVM model on the imbalanced dataset and reports the mean ROC AUC.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
We can see that the model has skill, achieving a ROC AUC above 0.5, in this case achieving a mean score of 0.804.
1
Mean ROC AUC: 0.804
This provides a baseline for comparison for any modifications performed to the standard SVM algorithm.
Want to Get Started With Imbalance Classification?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
SVM for Imbalanced Classification
Support Vector Machines, or SVMs for short, are an effective nonlinear machine learning algorithm.
The SVM training algorithm seeks a line or hyperplane that best separates the classes. The hyperplane is defined by a margin that maximizes the distance between the decision boundary and the closest examples from each of the two classes.
Loosely speaking, the margin is the distance between the classification boundary and the closest training set point.
The data may be transformed using a kernel to allow linear hyperplanes to be defined to separate the classes in a transformed feature space that corresponds to a nonlinear class boundary in the original feature space. Common kernel transforms include a linear, polynomial, and radial basis function transform. This transformation of data is referred to as the “kernel trick.”
Typically, the classes are not separable, even with data transforms. As such, the margin is softened to allow some points to appear on the wrong side of the decision boundary. This softening of the margin is controlled by a regularization hyperparameter referred to as the soft-margin parameter, lambda, or capital-C (“C“).
… where C stands for the regularization parameter that controls the trade-off between maximizing the separation margin between classes and minimizing the number of misclassified instances.
A value of C indicates a hard margin and no tolerance for violations of the margin. Small positive values allow some violation, whereas large integer values, such as 1, 10, and 100 allow for a much softer margin.
… [C] determines the number and severity of the violations to the margin (and to the hyperplane) that we will tolerate. We can think of C as a budget for the amount that the margin can be violated by the n observations.
Although effective, SVMs perform poorly when there is a severe skew in the class distribution. As such, there are many extensions to the algorithm in order to make them more effective on imbalanced datasets.
Although SVMs often produce effective solutions for balanced datasets, they are sensitive to the imbalance in the datasets and produce suboptimal models.
The C parameter is used as a penalty during the fit of the model, specifically the finding of the decision boundary. By default, each class has the same weighting, which means that the softness of the margin is symmetrical.
Given that there are significantly more examples in the majority class than the minority class, it means that the soft margin and, in turn, the decision boundary will favor the majority class.
… [the] learning algorithm will favor the majority class, as concentrating on it will lead to a better trade-off between classification error and margin maximization. This will come at the expense of minority class, especially when the imbalance ratio is high, as then ignoring the minority class will lead to better optimization results.
Perhaps the simplest and most common extension to SVM for imbalanced classification is to weight the C value in proportion to the importance of each class.
To accommodate these factors in SVMs an instance-level weighted modification was proposed. […] Values of weights may be given depending on the imbalance ratio between classes or individual instance complexity factors.
Specifically, each example in the training dataset has its own penalty term (C value) used in the calculation for the margin when fitting the SVM model. The value of an example’s C-value can be calculated as a weighting of the global C-value, where the weight is defined proportional to the class distribution.
C_i = weight_i * C
A larger weighting can be used for the minority class, allowing the margin to be softer, whereas a smaller weighting can be used for the majority class, forcing the margin to be harder and preventing misclassified examples.
Small Weight: Smaller C value, larger penalty for misclassified examples.
Larger Weight: Larger C value, smaller penalty for misclassified examples.
This has the effect of encouraging the margin to contain the majority class with less flexibility, but allow the minority class to be flexible with misclassification of majority class examples onto the minority class side if needed.
That is, the modified SVM algorithm would not tend to skew the separating hyperplane toward the minority class examples to reduce the total misclassifications, as the minority class examples are now assigned with a higher misclassification cost.
This modification of SVM may be referred to as Weighted Support Vector Machine (SVM), or more generally, Class-Weighted SVM, Instance-Weighted SVM, or Cost-Sensitive SVM.
The basic idea is to assign different weights to different data points such that the WSVM training algorithm learns the decision surface according to the relative importance of data points in the training data set.
The scikit-learn Python machine learning library provides an implementation of the SVM algorithm that supports class weighting.
The LinearSVC and SVC classes provide the class_weight argument that can be specified as a model hyperparameter. The class_weight is a dictionary that defines each class label (e.g. 0 and 1) and the weighting to apply to the C value in the calculation of the soft margin.
For example, a 1 to 1 weighting for each class 0 and 1 can be defined as follows:
1
2
3
4
...
# define model
weights={0:1.0,1:1.0}
model=SVC(gamma='scale',class_weight=weights)
The class weighing can be defined multiple ways; for example:
Domain expertise, determined by talking to subject matter experts.
Tuning, determined by a hyperparameter search such as a grid search.
Heuristic, specified using a general best practice.
A best practice for using the class weighting is to use the inverse of the class distribution present in the training dataset.
For example, the class distribution of the test dataset is a 1:100 ratio for the minority class to the majority class. The invert of this ratio could be used with 1 for the majority class and 100 for the minority class; for example:
1
2
3
4
...
# define model
weights={0:1.0,1:100.0}
model=SVC(gamma='scale',class_weight=weights)
We might also define the same ratio using fractions and achieve the same result; for example:
1
2
3
4
...
# define model
weights={0:0.01,1:1.0}
model=SVC(gamma='scale',class_weight=weights)
This heuristic is available directly by setting the class_weight to ‘balanced.’ For example:
1
2
3
...
# define model
model=SVC(gamma='scale',class_weight='balanced')
We can evaluate the SVM algorithm with a class weighting using the same evaluation procedure defined in the previous section.
We would expect the class-weighted version of SVM to perform better than the standard version of the SVM without any class weighting.
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# svm with class weight on an imbalanced classification dataset
from numpy import mean
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
Running the example prepares the synthetic imbalanced classification dataset, then evaluates the class-weighted version of the SVM algorithm using repeated cross-validation.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
The mean ROC AUC score is reported, in this case, showing a better score than the unweighted version of the SVM algorithm, 0.964 as compared to 0.804.
1
Mean ROC AUC: 0.964
Grid Search Weighted SVM
Using a class weighting that is the inverse ratio of the training data is just a heuristic.
It is possible that better performance can be achieved with a different class weighting, and this too will depend on the choice of performance metric used to evaluate the model.
In this section, we will grid search a range of different class weightings for weighted SVM and discover which results in the best ROC AUC score.
We will try the following weightings for class 0 and 1:
Class 0: 100, Class 1: 1
Class 0: 10, Class 1: 1
Class 0: 1, Class 1: 1
Class 0: 1, Class 1: 10
Class 0: 1, Class 1: 100
These can be defined as grid search parameters for the GridSearchCV class as follows:
print("Best: %f using %s"%(grid_result.best_score_,grid_result.best_params_))
# report all configurations
means=grid_result.cv_results_['mean_test_score']
stds=grid_result.cv_results_['std_test_score']
params=grid_result.cv_results_['params']
formean,stdev,param inzip(means,stds,params):
print("%f (%f) with: %r"%(mean,stdev,param))
Running the example evaluates each class weighting using repeated k-fold cross-validation and reports the best configuration and the associated mean ROC AUC score.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the 1:100 majority to minority class weighting achieved the best mean ROC score. This matches the configuration for the general heuristic.
It might be interesting to explore even more severe class weightings to see their effect on the mean ROC AUC score.
1
2
3
4
5
6
Best: 0.966189 using {'class_weight': {0: 1, 1: 100}}
It provides self-study tutorials and end-to-end projects on: Performance Metrics, Undersampling Methods, SMOTE, Threshold Moving, Probability Calibration, Cost-Sensitive Algorithms
and much more...
Bring Imbalanced Classification Methods to Your Machine Learning Projects
In case I have imbalanced text classification case that is customer searches are classified into 50 classes of products.
So in this case do I need to set the weight for all 50 classes ? or I can focus on classes with the most and the least samples
In the case of class_weight dictionary for SVM with Scikit-learn i get differents results depending on the fractions i use. For example, if i have a positive class which is four times more frequent than the negative class, there is a difference in defining the class weights in the following ways:
class_weight = {1: 0.25, 0: 1} and
class_weight = {1: 1, 0: 4}.
According to your article, there should not be any difference right?
Hi, I have a question regarding the definition of the dictionary class_weight for SVM using Scikit-Learn. I am working on an imbalanced binary classification problem where the positive class has 4 times the frequency of the negative class. I noticed that the results are differents if i define the dictionary in the following ways:
I guess the difference is due to the fact that the weights multiplies the missclassification penalty C, and there is a substantial difference in multiplying C by 4, or dividing it by 4.
“A value of C indicates a hard margin and no tolerance for violations of the margin. Small positive values allow some violation, whereas large integer values, such as 1, 10, and 100 allow for a much softer margin.”
Doesn’t a large C value allow for a harder margin instead of a softer one? because as far as I know, the higher is the value of C, the less tolerant it becomes for mis-classifications.
I don’t understand why the scoring function is “roc_auc” if in the link ROC area under curve (ROC AUC) it is said that
“ROC curves are appropriate when the observations are balanced between each class, whereas precision-recall curves are appropriate for imbalanced datasets.”
shouldn’t we be using “average_precision” instead, which reads as Compute average precision (AP) from prediction scores AP summarizes a precision-recall curve
Hi Jason, I ran the similar code in one of my projects where I vary the class weights.
There my weighted class contribution were 0.2 for positive class and 99.8 for negative class. So I have taken weights as [‘balanced’, {0:100,1:1}, {0:10,1:1}, {0:1,1:1}, {0:1,1:10}, {0:1,1:100}, {0:0.173, 1:99.826}] in my grid search and as expected the best score was at {0:0.173, 1:99.826} with 97.2 roc score but for training it was 95. So I am saying should I run grid search without doing cross validation and fit it on training sets and test sets to compare scores for all values to get the best combinations ? Or is there any other way ? Because scores shouldn’t misfit on neither training nor testing. What would you suggest me ?
I recommend designing a test harness that best captures how you expect to use the final model. I then recommend using that test harness to evaluate and select a candidate model, including grid searching.
My recommendation is to use repeated stratified k-fold cross-validation with maybe 3+ repeats and 10 folds and use a pipeline for all transforms and the model. But you can use anything you wish.
I need imbalanced high dimensional medical datasets with samples more than features
I ask your advice
Which is the most dataset used in research that can I used to apply my idea and compare with others
Please I need the source of data
Thanks for the post . What’s the difference between “repeated stratified k-fold cross-validation ” Vs “stratified k-fold cross-validation ” , other than the repeated operation ? Any observed benefit for the former ?
Thanks !
I tried to use SVM to handle a multiclassification with the imbalanced dataset.
My dataset includes three classes, A, B, and C with a proportion of 72%, 13%, and 15%.
I tried to use class_weight=’balanced’, and output the probabilities of each class.
The cohen’s kappa score was considered as the evaluation metric.
My supervisor told me that I can set the different weights to A, B, C after getting the output probalities. and multiple these weights with the corresponding class, after that assign the class with the highest probability as output class. For example, the output probabilities of A, B, C are [0.90, 0.03, 0.07], the corresponding weights are [1, 5.5, 4.8], the corresponding multiple results are [0.90,0.16,0.34], so class A was selected as the output class.
My question is that Can I do such a thing that assigns weights for A, B, C after model training?
I feel a little sense of cheating.
Thanks!
Perhaps you can tune the weightings as part of a k-fold cross-validation test harness, e.g. treat it like hyperparameter tuning with a validation dataset.
Do you mean that I can do this process during validation that multiple the weights with the output of probabilities of the validation set to get an optimization result, and then feed the selected weights to the test set, then using argmax function to get the final output class?
I really appreciate your sharing!
I constructed a stacking classifier by referring to your related post.
And tuning the weights during the validation as your suggestion.
It has better results than using a stacking classifier alone.
Besides, you give me the confidence to trust my idea.



")




In case I have imbalanced text classification case that is customer searches are classified into 50 classes of products.
So in this case do I need to set the weight for all 50 classes ? or I can focus on classes with the most and the least samples
Great question!
It depends on the goals of your project.
Weighing the most important classes is a great start, then see if you can do better with more refined weighting.
In the case of class_weight dictionary for SVM with Scikit-learn i get differents results depending on the fractions i use. For example, if i have a positive class which is four times more frequent than the negative class, there is a difference in defining the class weights in the following ways:
class_weight = {1: 0.25, 0: 1} and
class_weight = {1: 1, 0: 4}.
According to your article, there should not be any difference right?
Different fractions will impact the model by definition.
Whole numbers vs fractions will have more or less weight when fitting the model.
Hi, I have a question regarding the definition of the dictionary class_weight for SVM using Scikit-Learn. I am working on an imbalanced binary classification problem where the positive class has 4 times the frequency of the negative class. I noticed that the results are differents if i define the dictionary in the following ways:
class_weight = {1: 1/4, 0: 1}
class_weight = {1: 1, 0: 4}
I guess the difference is due to the fact that the weights multiplies the missclassification penalty C, and there is a substantial difference in multiplying C by 4, or dividing it by 4.
I kindly await your answer,
thanks
Yes, exactly.
Try both approaches and use the model with the best performance.
“A value of C indicates a hard margin and no tolerance for violations of the margin. Small positive values allow some violation, whereas large integer values, such as 1, 10, and 100 allow for a much softer margin.”
Doesn’t a large C value allow for a harder margin instead of a softer one? because as far as I know, the higher is the value of C, the less tolerant it becomes for mis-classifications.
Yes, a hard margin – as written. Perhaps re-read the sentence?
“A larger weighting can be used for the minority class, allowing the margin to be softer, ”
I think softer should be changed to harder.
A larger value tends to have a harder margin. This leads to a boundary in favor of the minority class.
Thank you for your feedback Ahmad!
I don’t understand why the scoring function is “roc_auc” if in the link ROC area under curve (ROC AUC) it is said that
“ROC curves are appropriate when the observations are balanced between each class, whereas precision-recall curves are appropriate for imbalanced datasets.”
shouldn’t we be using “average_precision” instead, which reads as Compute average precision (AP) from prediction scores AP summarizes a precision-recall curve
Good question, perhaps this will help understand the score and when to use it:
https://machinelearningmastery.com/tour-of-evaluation-metrics-for-imbalanced-classification/
Thanks Jason for the detailed explanation and all supported links for deeper understanding.
Our goal shouldn’t be to reduce false negatives. Shouldn’t you have focused on recall based approach ?
Perhaps, choosing a performance metric is an important step:
https://machinelearningmastery.com/framework-for-imbalanced-classification-projects/
And there is one more thing. Shall I do feature scaling before tuning the models ? And if yes, then how shall we decide about the type of scaling ?
Scaling would be performed as part of the modeling pipeline.
Hi Jason, I ran the similar code in one of my projects where I vary the class weights.
There my weighted class contribution were 0.2 for positive class and 99.8 for negative class. So I have taken weights as [‘balanced’, {0:100,1:1}, {0:10,1:1}, {0:1,1:1}, {0:1,1:10}, {0:1,1:100}, {0:0.173, 1:99.826}] in my grid search and as expected the best score was at {0:0.173, 1:99.826} with 97.2 roc score but for training it was 95. So I am saying should I run grid search without doing cross validation and fit it on training sets and test sets to compare scores for all values to get the best combinations ? Or is there any other way ? Because scores shouldn’t misfit on neither training nor testing. What would you suggest me ?
I recommend designing a test harness that best captures how you expect to use the final model. I then recommend using that test harness to evaluate and select a candidate model, including grid searching.
My recommendation is to use repeated stratified k-fold cross-validation with maybe 3+ repeats and 10 folds and use a pipeline for all transforms and the model. But you can use anything you wish.
Hi Jason
Thanks for your great article
I need imbalanced high dimensional medical datasets with samples more than features
I ask your advice
Which is the most dataset used in research that can I used to apply my idea and compare with others
Please I need the source of data
Thanks in advance
You’re welcome!
Here are some ideas for test datasets you could use:
https://machinelearningmastery.com/standard-machine-learning-datasets-for-imbalanced-classification/
Hello Jason .
Thanks for the post . What’s the difference between “repeated stratified k-fold cross-validation ” Vs “stratified k-fold cross-validation ” , other than the repeated operation ? Any observed benefit for the former ?
Thanks !
No other difference.
Hi Jason,
I tried to use SVM to handle a multiclassification with the imbalanced dataset.
My dataset includes three classes, A, B, and C with a proportion of 72%, 13%, and 15%.
I tried to use class_weight=’balanced’, and output the probabilities of each class.
The cohen’s kappa score was considered as the evaluation metric.
My supervisor told me that I can set the different weights to A, B, C after getting the output probalities. and multiple these weights with the corresponding class, after that assign the class with the highest probability as output class. For example, the output probabilities of A, B, C are [0.90, 0.03, 0.07], the corresponding weights are [1, 5.5, 4.8], the corresponding multiple results are [0.90,0.16,0.34], so class A was selected as the output class.
My question is that Can I do such a thing that assigns weights for A, B, C after model training?
I feel a little sense of cheating.
Thanks!
Perhaps you can tune the weightings as part of a k-fold cross-validation test harness, e.g. treat it like hyperparameter tuning with a validation dataset.
Dear Janson,
Thank you!
I’m sorry for replying so later!
Do you mean that I can do this process during validation that multiple the weights with the output of probabilities of the validation set to get an optimization result, and then feed the selected weights to the test set, then using argmax function to get the final output class?
Am I right?
Perhaps try it and see.
Dear Jason,
I really appreciate your sharing!
I constructed a stacking classifier by referring to your related post.
And tuning the weights during the validation as your suggestion.
It has better results than using a stacking classifier alone.
Besides, you give me the confidence to trust my idea.
Thank you very much!
Well done!
Thank you, Jason!
I guess I can refer to this post.
https://machinelearningmastery.com/probability-calibration-for-imbalanced-classification/?unapproved=612041&moderation-hash=58c27e99d9d98e4253854b259b1fc73f#comment-612041.