Classification accuracy is a metric that summarizes the performance of a classification model as the number of correct predictions divided by the total number of predictions.
It is easy to calculate and intuitive to understand, making it the most common metric used for evaluating classifier models. This intuition breaks down when the distribution of examples to classes is severely skewed.
Intuitions developed by practitioners on balanced datasets, such as 99 percent representing a skillful model, can be incorrect and dangerously misleading on imbalanced classification predictive modeling problems.
In this tutorial, you will discover the failure of classification accuracy for imbalanced classification problems.
After completing this tutorial, you will know:
Accuracy and error rate are the de facto standard metrics for summarizing the performance of classification models.
Classification accuracy fails on classification problems with a skewed class distribution because of the intuitions developed by practitioners on datasets with an equal class distribution.
Intuition for the failure of accuracy for skewed class distributions with a worked example.
Kick-start your project with my new book Imbalanced Classification with Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Updated Jan/2020: Updated for changes in scikit-learn v0.22 API.
Classification Accuracy Is Misleading for Skewed Class Distributions Photo by Esqui-Ando con Tònho, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
What Is Classification Accuracy?
Accuracy Fails for Imbalanced Classification
Example of Accuracy for Imbalanced Classification
What Is Classification Accuracy?
Classification predictive modeling involves predicting a class label given examples in a problem domain.
The most common metric used to evaluate the performance of a classification predictive model is classification accuracy. Typically, the accuracy of a predictive model is good (above 90% accuracy), therefore it is also very common to summarize the performance of a model in terms of the error rate of the model.
Accuracy and its complement error rate are the most frequently used metrics for estimating the performance of learning systems in classification problems.
Classification accuracy involves first using a classification model to make a prediction for each example in a test dataset. The predictions are then compared to the known labels for those examples in the test set. Accuracy is then calculated as the proportion of examples in the test set that were predicted correctly, divided by all predictions that were made on the test set.
Accuracy = Correct Predictions / Total Predictions
Conversely, the error rate can be calculated as the total number of incorrect predictions made on the test set divided by all predictions made on the test set.
Error Rate = Incorrect Predictions / Total Predictions
The accuracy and error rate are complements of each other, meaning that we can always calculate one from the other. For example:
Accuracy = 1 – Error Rate
Error Rate = 1 – Accuracy
Another valuable way to think about accuracy is in terms of the confusion matrix.
A confusion matrix is a summary of the predictions made by a classification model organized into a table by class. Each row of the table indicates the actual class and each column represents the predicted class. A value in the cell is a count of the number of predictions made for a class that are actually for a given class. The cells on the diagonal represent correct predictions, where a predicted and expected class align.
The most straightforward way to evaluate the performance of classifiers is based on the confusion matrix analysis. […] From such a matrix it is possible to extract a number of widely used metrics for measuring the performance of learning systems, such as Error Rate […] and Accuracy …
The confusion matrix provides more insight into not only the accuracy of a predictive model, but also which classes are being predicted correctly, which incorrectly, and what type of errors are being made.
The simplest confusion matrix is for a two-class classification problem, with negative (class 0) and positive (class 1) classes.
In this type of confusion matrix, each cell in the table has a specific and well-understood name, summarized as follows:
1
2
3
| Positive Prediction | Negative Prediction
Positive Class | True Positive (TP) | False Negative (FN)
Negative Class | False Positive (FP) | True Negative (TN)
The classification accuracy can be calculated from this confusion matrix as the sum of correct cells in the table (true positives and true negatives) divided by all cells in the table.
Accuracy = (TP + TN) / (TP + FN + FP + TN)
Similarly, the error rate can also be calculated from the confusion matrix as the sum of incorrect cells of the table (false positives and false negatives) divided by all cells of the table.
Error Rate = (FP + FN) / (TP + FN + FP + TN)
Now that we are familiar with classification accuracy and its complement error rate, let’s discover why they might be a bad idea to use for imbalanced classification problems.
Want to Get Started With Imbalance Classification?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Accuracy Fails for Imbalanced Classification
Classification accuracy is the most-used metric for evaluating classification models.
The reason for its wide use is because it is easy to calculate, easy to interpret, and is a single number to summarize the model’s capability.
As such, it is natural to use it on imbalanced classification problems, where the distribution of examples in the training dataset across the classes is not equal.
This is the most common mistake made by beginners to imbalanced classification.
When the class distribution is slightly skewed, accuracy can still be a useful metric. When the skew in the class distributions are severe, accuracy can become an unreliable measure of model performance.
The reason for this unreliability is centered around the average machine learning practitioner and the intuitions for classification accuracy.
Typically, classification predictive modeling is practiced with small datasets where the class distribution is equal or very close to equal. Therefore, most practitioners develop an intuition that large accuracy score (or conversely small error rate scores) are good, and values above 90 percent are great.
Achieving 90 percent classification accuracy, or even 99 percent classification accuracy, may be trivial on an imbalanced classification problem.
This means that intuitions for classification accuracy developed on balanced class distributions will be applied and will be wrong, misleading the practitioner into thinking that a model has good or even excellent performance when it, in fact, does not.
Accuracy Paradox
Consider the case of an imbalanced dataset with a 1:100 class imbalance.
In this problem, each example of the minority class (class 1) will have a corresponding 100 examples for the majority class (class 0).
In problems of this type, the majority class represents “normal” and the minority class represents “abnormal,” such as a fault, a diagnosis, or a fraud. Good performance on the minority class will be preferred over good performance on both classes.
Considering a user preference bias towards the minority (positive) class examples, accuracy is not suitable because the impact of the least represented, but more important examples, is reduced when compared to that of the majority class.
On this problem, a model that predicts the majority class (class 0) for all examples in the test set will have a classification accuracy of 99 percent, mirroring the distribution of major and minor examples expected in the test set on average.
Many machine learning models are designed around the assumption of balanced class distribution, and often learn simple rules (explicit or otherwise) like always predict the majority class, causing them to achieve an accuracy of 99 percent, although in practice performing no better than an unskilled majority class classifier.
A beginner will see the performance of a sophisticated model achieving 99 percent on an imbalanced dataset of this type and believe their work is done, when in fact, they have been misled.
This situation is so common that it has a name, referred to as the “accuracy paradox.”
… in the framework of imbalanced data-sets, accuracy is no longer a proper measure, since it does not distinguish between the numbers of correctly classified examples of different classes. Hence, it may lead to erroneous conclusions …
Strictly speaking, accuracy does report a correct result; it is only the practitioner’s intuition of high accuracy scores that is the point of failure. Instead of correcting faulty intuitions, it is common to use alternative metrics to summarize model performance for imbalanced classification problems.
Now that we are familiar with the idea that classification can be misleading, let’s look at a worked example.
Example of Accuracy for Imbalanced Classification
Although the explanation of why accuracy is a bad idea for imbalanced classification has been given, it is still an abstract idea.
We can make the failure of accuracy concrete with a worked example, and attempt to counter any intuitions for accuracy on balanced class distributions that you may have developed, or more likely dissuade the use of accuracy for imbalanced datasets.
First, we can define a synthetic dataset with a 1:100 class distribution.
The make_blobs() scikit-learn function will always create synthetic datasets with an equal class distribution.
Nevertheless, we can use this function to create synthetic classification datasets with arbitrary class distributions with a few extra lines of code. A class distribution can be defined as a dictionary where the key is the class value (e.g. 0 or 1) and the value is the number of randomly generated examples to include in the dataset.
The function below, named get_dataset(), will take a class distribution and return a synthetic dataset with that class distribution.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# create a dataset with a given class distribution
def get_dataset(proportions):
# determine the number of classes
n_classes=len(proportions)
# determine the number of examples to generate for each class
The function can take any number of classes, although we will use it for simple binary classification problems.
Next, we can take the code from the previous section for creating a scatter plot for a created dataset and place it in a helper function. Below is the plot_dataset() function that will plot the dataset and show a legend to indicate the mapping of colors to class labels.
1
2
3
4
5
6
7
8
9
10
11
12
13
# scatter plot of dataset, different color for each class
print('Class 0: %.3f%%, Class 1: %.3f%%'%(major,minor))
# plot dataset
plot_dataset(X,y)
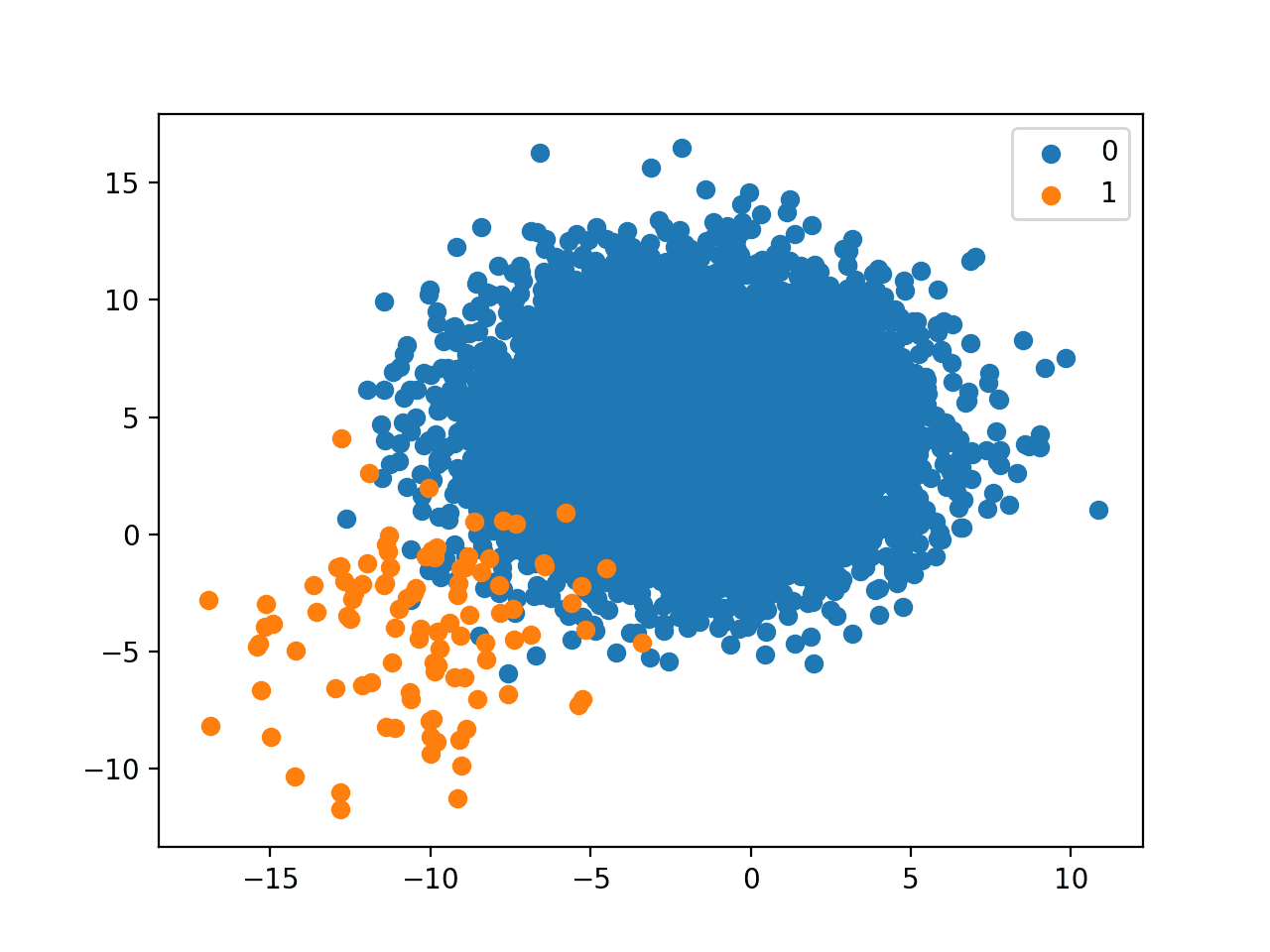
Running the example first creates the dataset and prints the class distribution.
We can see that a little over 99 percent of the examples in the dataset belong to the majority class, and a little less than 1 percent belong to the minority class.
1
Class 0: 99.010%, Class 1: 0.990%
A plot of the dataset is created and we can see that there are many more examples for each class and a helpful legend to indicate the mapping of plot colors to class labels.
Scatter Plot of Binary Classification Dataset With 1 to 100 Class Distribution
Next, we can fit a naive classifier model that always predicts the majority class.
We can achieve this using the DummyClassifier from scikit-learn and use the ‘most_frequent‘ strategy that will always predict the class label that is most observed in the training dataset.
1
2
3
...
# define model
model=DummyClassifier(strategy='most_frequent')
We can then evaluate this model on the training dataset using repeated k-fold cross-validation. It is important that we use stratified cross-validation to ensure that each split of the dataset has the same class distribution as the training dataset. This can be achieved using the RepeatedStratifiedKFold class.
The evaluate_model() function below implements this and returns a list of scores for each evaluation of the model.
1
2
3
4
5
6
7
8
# evaluate a model using repeated k-fold cross-validation
def evaluate_model(X,y,metric):
# define model
model=DummyClassifier(strategy='most_frequent')
# evaluate a model with repeated stratified k fold cv
We can then evaluate the model and calculate the mean of the scores across each evaluation.
We would expect that the naive classifier would achieve a classification accuracy of about 99 percent, which we know because that is the distribution of the majority class in the training dataset.
1
2
3
4
5
...
# evaluate model
scores=evaluate_model(X,y,'accuracy')
# report score
print('Accuracy: %.3f%%'%(mean(scores)*100))
Tying this all together, the complete example of evaluating a naive classifier on the synthetic dataset with a 1:100 class distribution is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# evaluate a majority class classifier on an 1:100 imbalanced dataset
from numpy import mean
from numpy import hstack
from numpy import vstack
from numpy import where
from sklearn.datasets import make_blobs
from sklearn.dummy import DummyClassifier
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
# create a dataset with a given class distribution
def get_dataset(proportions):
# determine the number of classes
n_classes=len(proportions)
# determine the number of examples to generate for each class
print('Class 0: %.3f%%, Class 1: %.3f%%'%(major,minor))
# evaluate model
scores=evaluate_model(X,y,'accuracy')
# report score
print('Accuracy: %.3f%%'%(mean(scores)*100))
Running the example first reports the class distribution of the training dataset again.
Then the model is evaluated and the mean accuracy is reported. We can see that as expected, the performance of the naive classifier matches the class distribution exactly.
Normally, achieving 99 percent classification accuracy would be cause for celebration. Although, as we have seen, because the class distribution is imbalanced, 99 percent is actually the lowest acceptable accuracy for this dataset and the starting point from which more sophisticated models must improve.
1
2
Class 0: 99.010%, Class 1: 0.990%
Accuracy: 99.010%
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
In this tutorial, you discovered the failure of classification accuracy for imbalanced classification problems.
Specifically, you learned:
Accuracy and error rate are the de facto standard metrics for summarizing the performance of classification models.
Classification accuracy fails on classification problems with a skewed class distribution because of the intuitions developed by practitioners on datasets with an equal class distribution.
Intuition for the failure of accuracy for skewed class distributions with a worked example.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
It provides self-study tutorials and end-to-end projects on: Performance Metrics, Undersampling Methods, SMOTE, Threshold Moving, Probability Calibration, Cost-Sensitive Algorithms
and much more...
Bring Imbalanced Classification Methods to Your Machine Learning Projects
nice explanation of the problem. request a “solution”: what to do when the training set has a signigicant imbalance on the predicted variable by definition (eg. fraud detection)…
Hello Jason,
happy New Year!
In a previous post about how to classify Machine Learning and Deep Learning algorithms you said that if I use Scikit-Learn it is Machine Learning and if I use Keras it is Deep Learning.
So is it correct to say:
a classification problem (e.g. IRIS) using Scikit-Learn is Machine Learning?
a classification problem (e.g. IRIS) using Keras is Deep Learning?
Thanks,
Marco
In the third code snippet under the section ‘Example of Accuracy for Imbalanced Classification’, you talk about using a class ratio of 1:100 “with 1,000 examples for the minority class and 10,000 examples for the majority class”. However, this gives a 1:10 class ratio. The resulting printout should is then incorrect, as well as the plot…
Sorry this might sound like a stupid qn. Whats the purpose of using a dummy classifier?
Am i right to say that we can achieve the same results as the original by also using a dummy classifier? Therefore the accuracy in the original results are flawed?
That is a great post! I wonder with what kind of ratio we would regard the case as imbalanced data? Because you are using an extreme case with 1:100. How about 40:60, or 30:70? Should we use other metric instead as well? Thank you!
Thank you for your answers Jason! Then does it mean that the metric “Accuracy” has very limited use, because in the real world, it is very rare case that we have exact 50%:50% control-case dataset. Is it right?
Hi Jason,
Thanks for your post! I have a question… I have an imbalance dataset and what I did was that I solved the class imbalance problem with upsampling the minority class in my train dataset and THEN train my data on the upsampled train dataset… My question is: Should I also deal with class imbalance in the test dataset? or should I only run the model on the test dataset…
I have a feeling that I shouldn’t change anything in the test dataset but am wondering if imbalance test dataset would affect the accuracy as well…
Some context: I’m using a simple logistic regression
When the text says “We can see that a little over 90 percent of the examples in the dataset belong to the majority class, and a little less than 1 percent belong to the minority class.”, did the author mean “a little over 99 percent” instead?
Will Increasing the number of classes will affect the accuracy of classification? for example, classifying data into three classes, two different classes related to a specific domain, and one different class related to another domain, knowing that the research field discusses two classes with the one domain.
If I have multiclass dataset with around 150 labels, each will have varied number of samples. The total number of samples will go around 10000 approx. Some labels may have 400 samples, some will have even less than 10 samples. No doubt, the accuracy obtained using individual classifier (using different classifiers) or using voting classifier is goes beyond 99%. As per your article, this obtained accuracy is not a proper measure in such situation of varied number samples per label. What methodology or measure you suggest in this case. Second, how can I obtain accuracy of individual label in that situation. Will appreciate your response with code.








nice explanation of the problem. request a “solution”: what to do when the training set has a signigicant imbalance on the predicted variable by definition (eg. fraud detection)…
There are many things to try, such as:
– data sampling
– customized algorithms
– cost sensitive algorithms
– one class algorithms
– threshold moving
– probability calibration
– …
I will provide a framework on the topic soon.
Hello Jason,
happy New Year!
In a previous post about how to classify Machine Learning and Deep Learning algorithms you said that if I use Scikit-Learn it is Machine Learning and if I use Keras it is Deep Learning.
So is it correct to say:
a classification problem (e.g. IRIS) using Scikit-Learn is Machine Learning?
a classification problem (e.g. IRIS) using Keras is Deep Learning?
Thanks,
Marco
Sure.
Thanks for the great post, Jason.
In the third code snippet under the section ‘Example of Accuracy for Imbalanced Classification’, you talk about using a class ratio of 1:100 “with 1,000 examples for the minority class and 10,000 examples for the majority class”. However, this gives a 1:10 class ratio. The resulting printout should is then incorrect, as well as the plot…
Thanks, fixed!
Sorry this might sound like a stupid qn. Whats the purpose of using a dummy classifier?
Am i right to say that we can achieve the same results as the original by also using a dummy classifier? Therefore the accuracy in the original results are flawed?
Thanks
Excellent question!
A dummy classifier establishes a baseline in performance for a given dataset:
https://machinelearningmastery.com/how-to-develop-and-evaluate-naive-classifier-strategies-using-probability/
If a model cannot perform better than a dummy classifier (a naive model), then it does not “have skill” on the dataset.
Thanks Jason for the reply! Appreciate it. Anyway I really love your page and your content. Thanks for doing what you do!
Thanks for your support!
what are the metrics works best for a multi-label imbalance problem?
The same metrics for binary classification tasks can be used for the same purposes.
Hi Jason,
That is a great post! I wonder with what kind of ratio we would regard the case as imbalanced data? Because you are using an extreme case with 1:100. How about 40:60, or 30:70? Should we use other metric instead as well? Thank you!
Thanks.
Yes, most likely. This framework will help you choose a metric:
https://machinelearningmastery.com/tour-of-evaluation-metrics-for-imbalanced-classification/
Thank you for your answers Jason! Then does it mean that the metric “Accuracy” has very limited use, because in the real world, it is very rare case that we have exact 50%:50% control-case dataset. Is it right?
Yes!
Thanks Jason. Excellent post.
Thanks!
Typically, classification predictive modeling is practiced with small datasets where the class distribution is equal or very close to “equal”. Typo?
How so?
Hi Jason,
Thanks for your post! I have a question… I have an imbalance dataset and what I did was that I solved the class imbalance problem with upsampling the minority class in my train dataset and THEN train my data on the upsampled train dataset… My question is: Should I also deal with class imbalance in the test dataset? or should I only run the model on the test dataset…
I have a feeling that I shouldn’t change anything in the test dataset but am wondering if imbalance test dataset would affect the accuracy as well…
Some context: I’m using a simple logistic regression
Thank you again
No, you must not change the balance of the test dataset.
When the text says “We can see that a little over 90 percent of the examples in the dataset belong to the majority class, and a little less than 1 percent belong to the minority class.”, did the author mean “a little over 99 percent” instead?
Yes, thanks. Fixed.
Hi Jason, thanks for the excellent post, I think the ratio should be:
# define the class distribution 1:100
proportions = {0:10000, 1:100}
Cheers
Thanks.
Will Increasing the number of classes will affect the accuracy of classification? for example, classifying data into three classes, two different classes related to a specific domain, and one different class related to another domain, knowing that the research field discusses two classes with the one domain.
Yes, surely. You should see accuracy dropped. Getting more options means a random guess will less likely be right.
If I have multiclass dataset with around 150 labels, each will have varied number of samples. The total number of samples will go around 10000 approx. Some labels may have 400 samples, some will have even less than 10 samples. No doubt, the accuracy obtained using individual classifier (using different classifiers) or using voting classifier is goes beyond 99%. As per your article, this obtained accuracy is not a proper measure in such situation of varied number samples per label. What methodology or measure you suggest in this case. Second, how can I obtain accuracy of individual label in that situation. Will appreciate your response with code.
Hi Vijay…The following may be of interest to you:
https://machinelearningmastery.com/model-prediction-versus-interpretation-in-machine-learning/