Weight initialization is an important design choice when developing deep learning neural network models.
Historically, weight initialization involved using small random numbers, although over the last decade, more specific heuristics have been developed that use information, such as the type of activation function that is being used and the number of inputs to the node.
These more tailored heuristics can result in more effective training of neural network models using the stochastic gradient descent optimization algorithm.
In this tutorial, you will discover how to implement weight initialization techniques for deep learning neural networks.
After completing this tutorial, you will know:
Weight initialization is used to define the initial values for the parameters in neural network models prior to training the models on a dataset.
How to implement the xavier and normalized xavier weight initialization heuristics used for nodes that use the Sigmoid or Tanh activation functions.
How to implement the he weight initialization heuristic used for nodes that use the ReLU activation function.
Let’s get started.
Updated Feb/2020: Fixed typo in equation for normalized xavier.
Weight Initialization for Deep Learning Neural Networks Photo by Andres Alvarado, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
Weight Initialization for Neural Networks
Weight Initialization for Sigmoid and Tanh
Xavier Weight Initialization
Normalized Xavier Weight Initialization
Weight Initialization for ReLU
He Weight Initialization
Weight Initialization for Neural Networks
Weight initialization is an important consideration in the design of a neural network model.
The nodes in neural networks are composed of parameters referred to as weights used to calculate a weighted sum of the inputs.
Neural network models are fit using an optimization algorithm called stochastic gradient descent that incrementally changes the network weights to minimize a loss function, hopefully resulting in a set of weights for the mode that is capable of making useful predictions.
This optimization algorithm requires a starting point in the space of possible weight values from which to begin the optimization process. Weight initialization is a procedure to set the weights of a neural network to small random values that define the starting point for the optimization (learning or training) of the neural network model.
… training deep models is a sufficiently difficult task that most algorithms are strongly affected by the choice of initialization. The initial point can determine whether the algorithm converges at all, with some initial points being so unstable that the algorithm encounters numerical difficulties and fails altogether.
Each time, a neural network is initialized with a different set of weights, resulting in a different starting point for the optimization process, and potentially resulting in a different final set of weights with different performance characteristics.
For more on the expectation of different results each time the same algorithm is trained on the same dataset, see the tutorial:
We cannot initialize all weights to the value 0.0 as the optimization algorithm results in some asymmetry in the error gradient to begin searching effectively.
For more on why we initialize neural networks with random weights, see the tutorial:
Historically, weight initialization follows simple heuristics, such as:
Small random values in the range [-0.3, 0.3]
Small random values in the range [0, 1]
Small random values in the range [-1, 1]
These heuristics continue to work well in general.
We almost always initialize all the weights in the model to values drawn randomly from a Gaussian or uniform distribution. The choice of Gaussian or uniform distribution does not seem to matter very much, but has not been exhaustively studied. The scale of the initial distribution, however, does have a large effect on both the outcome of the optimization procedure and on the ability of the network to generalize.
Nevertheless, more tailored approaches have been developed over the last decade that have become the defacto standard given they may result in a slightly more effective optimization (model training) process.
These modern weight initialization techniques are divided based on the type of activation function used in the nodes that are being initialized, such as “Sigmoid and Tanh” and “ReLU.”
Next, let’s take a closer look at these modern weight initialization heuristics for nodes with Sigmoid and Tanh activation functions.
Weight Initialization for Sigmoid and Tanh
The current standard approach for initialization of the weights of neural network layers and nodes that use the Sigmoid or TanH activation function is called “glorot” or “xavier” initialization.
There are two versions of this weight initialization method, which we will refer to as “xavier” and “normalized xavier.”
Glorot and Bengio proposed to adopt a properly scaled uniform distribution for initialization. This is called “Xavier” initialization […] Its derivation is based on the assumption that the activations are linear. This assumption is invalid for ReLU and PReLU.
Both approaches were derived assuming that the activation function is linear, nevertheless, they have become the standard for nonlinear activation functions like Sigmoid and Tanh, but not ReLU.
Let’s take a closer look at each in turn.
Xavier Weight Initialization
The xavier initialization method is calculated as a random number with a uniform probability distribution (U) between the range -(1/sqrt(n)) and 1/sqrt(n), where n is the number of inputs to the node.
weight = U [-(1/sqrt(n)), 1/sqrt(n)]
We can implement this directly in Python.
The example below assumes 10 inputs to a node, then calculates the lower and upper bounds of the range and calculates 1,000 initial weight values that could be used for the nodes in a layer or a network that uses the sigmoid or tanh activation function.
After calculating the weights, the lower and upper bounds are printed as are the min, max, mean, and standard deviation of the generated weights.
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# example of the xavier weight initialization
from math import sqrt
from numpy import mean
from numpy.random import rand
# number of nodes in the previous layer
n=10
# calculate the range for the weights
lower,upper=-(1.0/sqrt(n)),(1.0/sqrt(n))
# generate random numbers
numbers=rand(1000)
# scale to the desired range
scaled=lower+numbers *(upper-lower)
# summarize
print(lower,upper)
print(scaled.min(),scaled.max())
print(scaled.mean(),scaled.std())
Running the example generates the weights and prints the summary statistics.
We can see that the bounds of the weight values are about -0.316 and 0.316. These bounds would become wider with fewer inputs and more narrow with more inputs.
We can see that the generated weights respect these bounds and that the mean weight value is close to zero with the standard deviation close to 0.17.
1
2
3
-0.31622776601683794 0.31622776601683794
-0.3157663248679193 0.3160839282916222
0.006806069733149146 0.17777128902976705
It can also help to see how the spread of the weights changes with the number of inputs.
For this, we can calculate the bounds on the weight initialization with different numbers of inputs from 1 to 100 and plot the result.
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
# plot of the bounds on xavier weight initialization for different numbers of inputs
from math import sqrt
from matplotlib import pyplot
# define the number of inputs from 1 to 100
values=[iforiinrange(1,101)]
# calculate the range for each number of inputs
results=[1.0/sqrt(n)forninvalues]
# create an error bar plot centered on 0 for each number of inputs
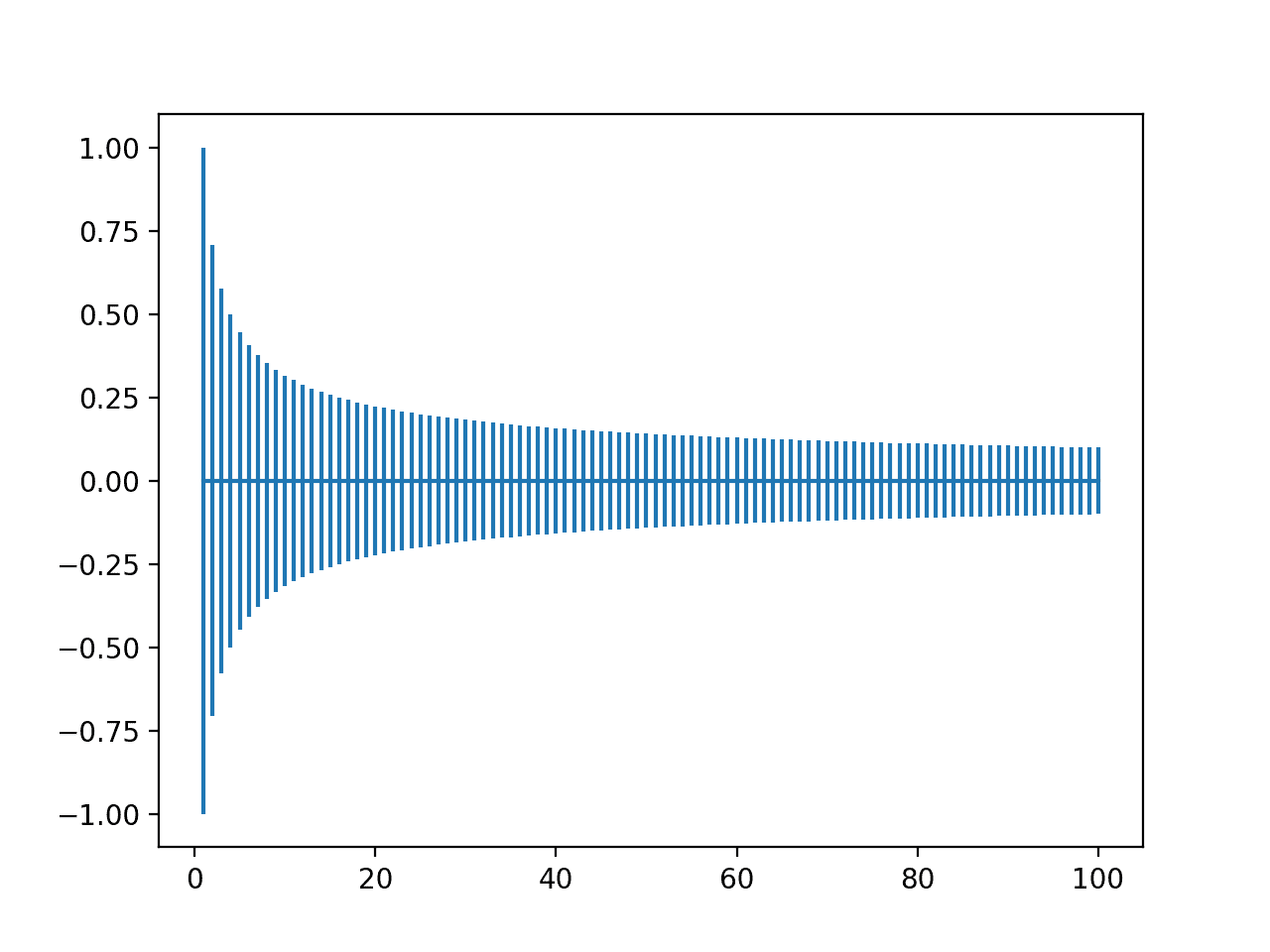
Running the example creates a plot that allows us to compare the range of weights with different numbers of input values.
We can see that with very few inputs, the range is large, such as between -1 and 1 or -0.7 to -7. We can then see that our range rapidly drops to about 20 weights to near -0.1 and 0.1, where it remains reasonably constant.
Plot of Range of Xavier Weight Initialization With Inputs From One to One Hundred
Normalized Xavier Weight Initialization
The normalized xavier initialization method is calculated as a random number with a uniform probability distribution (U) between the range -(sqrt(6)/sqrt(n + m)) and sqrt(6)/sqrt(n + m), where n us the number of inputs to the node (e.g. number of nodes in the previous layer) and m is the number of outputs from the layer (e.g. number of nodes in the current layer).
weight = U [-(sqrt(6)/sqrt(n + m)), sqrt(6)/sqrt(n + m)]
We can implement this directly in Python as we did in the previous section and summarize the statistical summary of 1,000 generated weights.
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# example of the normalized xavier weight initialization
Running the example generates the weights and prints the summary statistics.
We can see that the bounds of the weight values are about -0.447 and 0.447. These bounds would become wider with fewer inputs and more narrow with more inputs.
We can see that the generated weights respect these bounds and that the mean weight value is close to zero with the standard deviation close to 0.17.
1
2
3
-0.44721359549995787 0.44721359549995787
-0.4447861894315135 0.4463641245392874
-0.01135636099916006 0.2581340352889168
It can also help to see how the spread of the weights changes with the number of inputs.
For this, we can calculate the bounds on the weight initialization with different numbers of inputs from 1 to 100 and a fixed number of 10 outputs and plot the result.
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
# plot of the bounds of normalized xavier weight initialization for different numbers of inputs
from math import sqrt
from matplotlib import pyplot
# define the number of inputs from 1 to 100
values=[iforiinrange(1,101)]
# define the number of outputs
m=10
# calculate the range for each number of inputs
results=[1.0/sqrt(n+m)forninvalues]
# create an error bar plot centered on 0 for each number of inputs
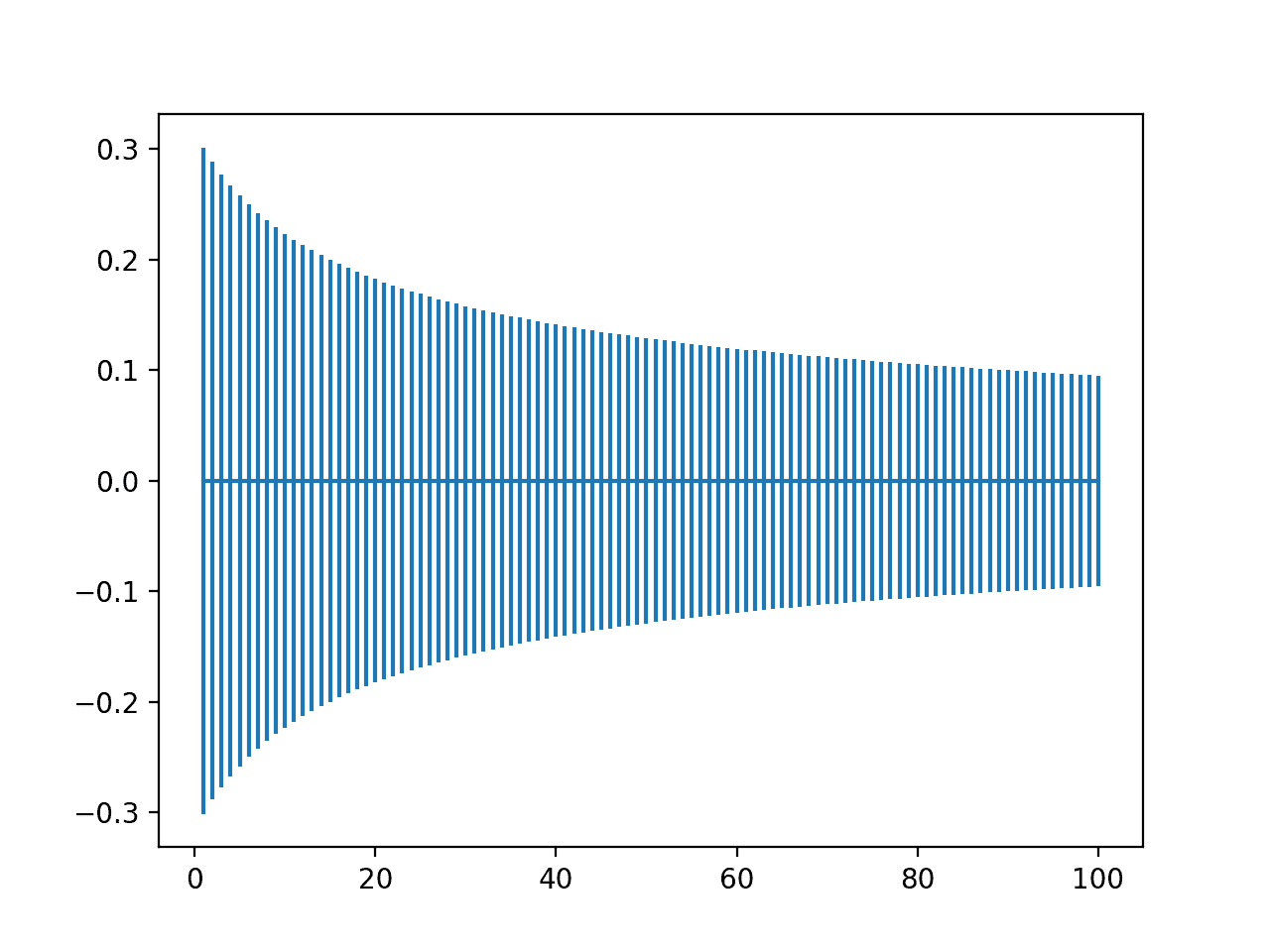
Running the example creates a plot that allows us to compare the range of weights with different numbers of input values.
We can see that the range starts wide at about -0.3 to 0.3 with few inputs and reduces to about -0.1 to 0.1 as the number of inputs increases.
Compared to the non-normalized version in the previous section, the range is initially smaller, although transitions to the compact range at a similar rate.
Plot of Range of Normalized Xavier Weight Initialization With Inputs From One to One Hundred
Weight Initialization for ReLU
The “xavier” weight initialization was found to have problems when used to initialize networks that use the rectified linear (ReLU) activation function.
As such, a modified version of the approach was developed specifically for nodes and layers that use ReLU activation, popular in the hidden layers of most multilayer Perceptron and convolutional neural network models.
The current standard approach for initialization of the weights of neural network layers and nodes that use the rectified linear (ReLU) activation function is called “he” initialization.
The he initialization method is calculated as a random number with a Gaussian probability distribution (G) with a mean of 0.0 and a standard deviation of sqrt(2/n), where n is the number of inputs to the node.
weight = G (0.0, sqrt(2/n))
We can implement this directly in Python.
The example below assumes 10 inputs to a node, then calculates the standard deviation of the Gaussian distribution and calculates 1,000 initial weight values that could be used for the nodes in a layer or a network that uses the ReLU activation function.
After calculating the weights, the calculated standard deviation is printed as are the min, max, mean, and standard deviation of the generated weights.
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# example of the he weight initialization
from math import sqrt
from numpy.random import randn
# number of nodes in the previous layer
n=10
# calculate the range for the weights
std=sqrt(2.0/n)
# generate random numbers
numbers=randn(1000)
# scale to the desired range
scaled=numbers *std
# summarize
print(std)
print(scaled.min(),scaled.max())
print(scaled.mean(),scaled.std())
Running the example generates the weights and prints the summary statistics.
We can see that the bound of the calculated standard deviation of the weights is about 0.447. This standard deviation would become larger with fewer inputs and smaller with more inputs.
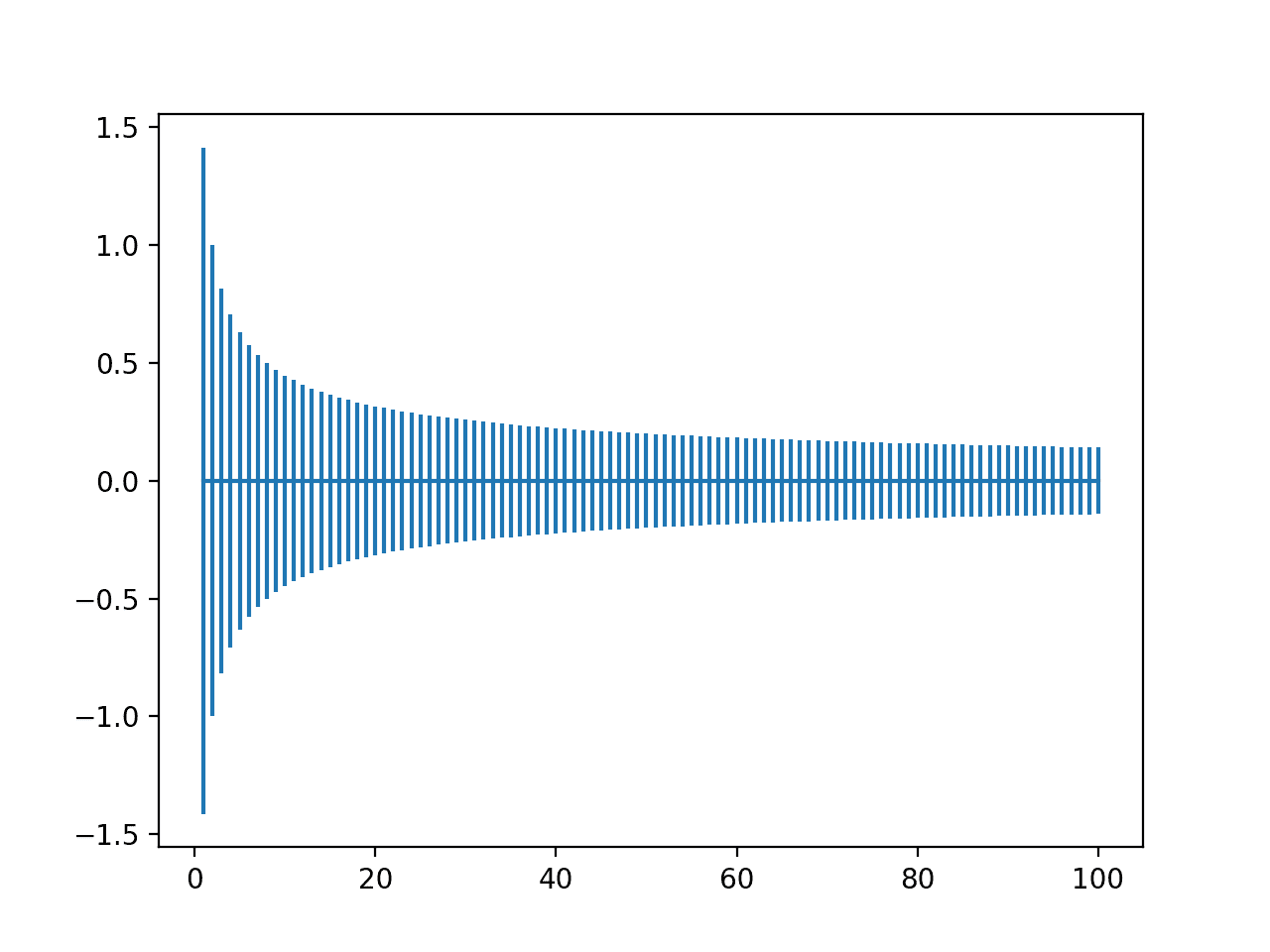
Running the example creates a plot that allows us to compare the range of weights with different numbers of input values.
We can see that with very few inputs, the range is large, near -1.5 and 1.5 or -1.0 to -1.0. We can then see that our range rapidly drops to about 20 weights to near -0.1 and 0.1, where it remains reasonably constant.
Plot of Range of He Weight Initialization With Inputs From One to One Hundred
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Excellent article! Thanks for sharing. By the way, I found some tiny error in the section:
Normalized Xavier Weight Initialization
The normalized xavier initialization method is calculated as a random number with a uniform probability distribution (U) between the range -(sqrt(6)/sqrt(n + n)) and sqrt(6)/sqrt(n + n), where n us the number of inputs to the node (e.g. number of nodes in the previous layer) and m is the number of outputs from the layer (e.g. number of nodes in the current layer).
* weight = U [-(sqrt(6)/sqrt(n + n)), sqrt(6)/sqrt(n + n)]
The second n (sqrt(n + n) -> sqrt(n + m)) should be m according to my understanding. FYI
Is there a good way to initialize weights when softmax is the activation function? I’ve been trying so hard to train a MLP with softmax as the output activation layer and input data in range of 0 to 1, and seems I have problem with weight initialization.
What is the difference between Gaussian Probability distribution and Uniform probability distribution?
Btw, I love your site it has everything we need to become expert Machine learning developers. Half the day, I am on your site only and It is really helping me to enhance my knowledge and again thanks because you provide Mathematics which is really really helpful.
Hello, I have a problem. I used a neural network and it was improved by the genetic algorithm. I used a library called Pygad. The range weights was between 9 and -9, and this is very large. When I determined the range between 1 and -1, he found the same range between 9 and -9. What is the solution?







What is a “node” in a DNN? Is it the number of channels or features in the layer?
A DNN could be any model, but let’s say you mean a multilayer perceptron (MLP).
A node in an MLP takes one or more inputs, has an activation function and has one output that may pass on to one or more nodes in the next layer.
Your explanation gives a better understanding
Thanks!
Excellent article! Thanks for sharing. By the way, I found some tiny error in the section:
Normalized Xavier Weight Initialization
The normalized xavier initialization method is calculated as a random number with a uniform probability distribution (U) between the range -(sqrt(6)/sqrt(n + n)) and sqrt(6)/sqrt(n + n), where n us the number of inputs to the node (e.g. number of nodes in the previous layer) and m is the number of outputs from the layer (e.g. number of nodes in the current layer).
* weight = U [-(sqrt(6)/sqrt(n + n)), sqrt(6)/sqrt(n + n)]
The second
n(sqrt(n + n) -> sqrt(n + m)) should bemaccording to my understanding. FYIYou’re welcome.
Thanks, looks like a typo. Fixed!
sir how we can furthur improve decision making capabilities of transfer learned alexnet with data augmentation
Here are many suggestions for improving deep learning model performance more generally:
https://machinelearningmastery.com/start-here/#better
Thank you for your explanation!
I have a few questions:
Is there a good way to initialize weights when softmax is the activation function? I’ve been trying so hard to train a MLP with softmax as the output activation layer and input data in range of 0 to 1, and seems I have problem with weight initialization.
You’re welcome.
Yes, same method as tanh and sigmoid.
What is the difference between Gaussian Probability distribution and Uniform probability distribution?
Btw, I love your site it has everything we need to become expert Machine learning developers. Half the day, I am on your site only and It is really helping me to enhance my knowledge and again thanks because you provide Mathematics which is really really helpful.
The difference is the shape. Perhaps start here:
https://machinelearningmastery.com/continuous-probability-distributions-for-machine-learning/
Thanks
You’re welcome.
Hello, I have a problem. I used a neural network and it was improved by the genetic algorithm. I used a library called Pygad. The range weights was between 9 and -9, and this is very large. When I determined the range between 1 and -1, he found the same range between 9 and -9. What is the solution?
Hello Mohammed…I cannot at the moment speak to the particular library. I did find some introductory material on it, however.
https://pygad.readthedocs.io/en/latest/
Mistake detected: “-0.7 to -7”.
I also think that “he” should be capitalized.
Thank you for the feedback Marsel!
Why has weight initialization involved small random numbers? I understand why they have to be random, but why do they have to be small?
Hi Vincente…smaller numbers are generally considered a better option to avoid “exploding” gradients:
https://machinelearningmastery.com/exploding-gradients-in-neural-networks/
I’m wondering if there is an initializer that is an all-arounder. One that works well with both relu and tanh?
Hi Jason, thank you very much for this blog and explanations. I find it very very useful!!
I have one question about the normalized Xavier weight initialization. I am not sure if I am undestanding something wrong or is a typo:
In complete example, line 8-9:
is:
# calculate the range for each number of inputs
results = [1.0 / sqrt(n + m) for n in values]
should be?:
# calculate the range for each number of inputs
results = [6.0 / sqrt(n + m) for n in values]
Thanks for your time,
Luis
Hi Luis..The following resource should clarify:
https://towardsdatascience.com/weight-initialization-in-neural-networks-a-journey-from-the-basics-to-kaiming-954fb9b47c79
thank you for the exposition
Hi Samuel…You are very welcome!
How do you implement the initial weights in a neural network training loop?
Thank you for your insights
Hi Joseph…The following resource may be of interest to you:
https://www.deeplearning.ai/ai-notes/initialization/index.html