Decision trees are a powerful prediction method and extremely popular.
They are popular because the final model is so easy to understand by practitioners and domain experts alike. The final decision tree can explain exactly why a specific prediction was made, making it very attractive for operational use.
Decision trees also provide the foundation for more advanced ensemble methods such as bagging, random forests and gradient boosting.
In this tutorial, you will discover how to implement the Classification And Regression Tree algorithm from scratch with Python.
After completing this tutorial, you will know:
- How to calculate and evaluate candidate split points in a data.
- How to arrange splits into a decision tree structure.
- How to apply the classification and regression tree algorithm to a real problem.
Kick-start your project with my new book Machine Learning Algorithms From Scratch, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
- Update Jan/2017: Changed the calculation of fold_size in cross_validation_split() to always be an integer. Fixes issues with Python 3.
- Update Feb/2017: Fixed a bug in build_tree.
- Update Aug/2017: Fixed a bug in Gini calculation, added the missing weighting of group Gini scores by group size (thanks Michael!).
- Update Aug/2018: Tested and updated to work with Python 3.6.

How To Implement The Decision Tree Algorithm From Scratch In Python
Photo by Martin Cathrae, some rights reserved.
Descriptions
This section provides a brief introduction to the Classification and Regression Tree algorithm and the Banknote dataset used in this tutorial.
Classification and Regression Trees
Classification and Regression Trees or CART for short is an acronym introduced by Leo Breiman to refer to Decision Tree algorithms that can be used for classification or regression predictive modeling problems.
We will focus on using CART for classification in this tutorial.
The representation of the CART model is a binary tree. This is the same binary tree from algorithms and data structures, nothing too fancy (each node can have zero, one or two child nodes).
A node represents a single input variable (X) and a split point on that variable, assuming the variable is numeric. The leaf nodes (also called terminal nodes) of the tree contain an output variable (y) which is used to make a prediction.
Once created, a tree can be navigated with a new row of data following each branch with the splits until a final prediction is made.
Creating a binary decision tree is actually a process of dividing up the input space. A greedy approach is used to divide the space called recursive binary splitting. This is a numerical procedure where all the values are lined up and different split points are tried and tested using a cost function.
The split with the best cost (lowest cost because we minimize cost) is selected. All input variables and all possible split points are evaluated and chosen in a greedy manner based on the cost function.
- Regression: The cost function that is minimized to choose split points is the sum squared error across all training samples that fall within the rectangle.
- Classification: The Gini cost function is used which provides an indication of how pure the nodes are, where node purity refers to how mixed the training data assigned to each node is.
Splitting continues until nodes contain a minimum number of training examples or a maximum tree depth is reached.
Banknote Dataset
The banknote dataset involves predicting whether a given banknote is authentic given a number of measures taken from a photograph.
The dataset contains 1,372 rows with 5 numeric variables. It is a classification problem with two classes (binary classification).
Below provides a list of the five variables in the dataset.
- variance of Wavelet Transformed image (continuous).
- skewness of Wavelet Transformed image (continuous).
- kurtosis of Wavelet Transformed image (continuous).
- entropy of image (continuous).
- class (integer).
Below is a sample of the first 5 rows of the dataset
|
1 2 3 4 5 6 |
3.6216,8.6661,-2.8073,-0.44699,0 4.5459,8.1674,-2.4586,-1.4621,0 3.866,-2.6383,1.9242,0.10645,0 3.4566,9.5228,-4.0112,-3.5944,0 0.32924,-4.4552,4.5718,-0.9888,0 4.3684,9.6718,-3.9606,-3.1625,0 |
Using the Zero Rule Algorithm to predict the most common class value, the baseline accuracy on the problem is about 50%.
You can learn more and download the dataset from the UCI Machine Learning Repository.
Download the dataset and place it in your current working directory with the filename data_banknote_authentication.csv.
Tutorial
This tutorial is broken down into 5 parts:
- Gini Index.
- Create Split.
- Build a Tree.
- Make a Prediction.
- Banknote Case Study.
These steps will give you the foundation that you need to implement the CART algorithm from scratch and apply it to your own predictive modeling problems.
1. Gini Index
The Gini index is the name of the cost function used to evaluate splits in the dataset.
A split in the dataset involves one input attribute and one value for that attribute. It can be used to divide training patterns into two groups of rows.
A Gini score gives an idea of how good a split is by how mixed the classes are in the two groups created by the split. A perfect separation results in a Gini score of 0, whereas the worst case split that results in 50/50 classes in each group result in a Gini score of 0.5 (for a 2 class problem).
Calculating Gini is best demonstrated with an example.
We have two groups of data with 2 rows in each group. The rows in the first group all belong to class 0 and the rows in the second group belong to class 1, so it’s a perfect split.
We first need to calculate the proportion of classes in each group.
|
1 |
proportion = count(class_value) / count(rows) |
The proportions for this example would be:
|
1 2 3 4 |
group_1_class_0 = 2 / 2 = 1 group_1_class_1 = 0 / 2 = 0 group_2_class_0 = 0 / 2 = 0 group_2_class_1 = 2 / 2 = 1 |
Gini is then calculated for each child node as follows:
|
1 2 |
gini_index = sum(proportion * (1.0 - proportion)) gini_index = 1.0 - sum(proportion * proportion) |
The Gini index for each group must then be weighted by the size of the group, relative to all of the samples in the parent, e.g. all samples that are currently being grouped. We can add this weighting to the Gini calculation for a group as follows:
|
1 |
gini_index = (1.0 - sum(proportion * proportion)) * (group_size/total_samples) |
In this example the Gini scores for each group are calculated as follows:
|
1 2 3 4 5 6 |
Gini(group_1) = (1 - (1*1 + 0*0)) * 2/4 Gini(group_1) = 0.0 * 0.5 Gini(group_1) = 0.0 Gini(group_2) = (1 - (0*0 + 1*1)) * 2/4 Gini(group_2) = 0.0 * 0.5 Gini(group_2) = 0.0 |
The scores are then added across each child node at the split point to give a final Gini score for the split point that can be compared to other candidate split points.
The Gini for this split point would then be calculated as 0.0 + 0.0 or a perfect Gini score of 0.0.
Below is a function named gini_index() the calculates the Gini index for a list of groups and a list of known class values.
You can see that there are some safety checks in there to avoid a divide by zero for an empty group.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# Calculate the Gini index for a split dataset def gini_index(groups, classes): # count all samples at split point n_instances = float(sum([len(group) for group in groups])) # sum weighted Gini index for each group gini = 0.0 for group in groups: size = float(len(group)) # avoid divide by zero if size == 0: continue score = 0.0 # score the group based on the score for each class for class_val in classes: p = [row[-1] for row in group].count(class_val) / size score += p * p # weight the group score by its relative size gini += (1.0 - score) * (size / n_instances) return gini |
We can test this function with our worked example above. We can also test it for the worst case of a 50/50 split in each group. The complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# Calculate the Gini index for a split dataset def gini_index(groups, classes): # count all samples at split point n_instances = float(sum([len(group) for group in groups])) # sum weighted Gini index for each group gini = 0.0 for group in groups: size = float(len(group)) # avoid divide by zero if size == 0: continue score = 0.0 # score the group based on the score for each class for class_val in classes: p = [row[-1] for row in group].count(class_val) / size score += p * p # weight the group score by its relative size gini += (1.0 - score) * (size / n_instances) return gini # test Gini values print(gini_index([[[1, 1], [1, 0]], [[1, 1], [1, 0]]], [0, 1])) print(gini_index([[[1, 0], [1, 0]], [[1, 1], [1, 1]]], [0, 1])) |
Running the example prints the two Gini scores, first the score for the worst case at 0.5 followed by the score for the best case at 0.0.
|
1 2 |
0.5 0.0 |
Now that we know how to evaluate the results of a split, let’s look at creating splits.
2. Create Split
A split is comprised of an attribute in the dataset and a value.
We can summarize this as the index of an attribute to split and the value by which to split rows on that attribute. This is just a useful shorthand for indexing into rows of data.
Creating a split involves three parts, the first we have already looked at which is calculating the Gini score. The remaining two parts are:
- Splitting a Dataset.
- Evaluating All Splits.
Let’s take a look at each.
2.1. Splitting a Dataset
Splitting a dataset means separating a dataset into two lists of rows given the index of an attribute and a split value for that attribute.
Once we have the two groups, we can then use our Gini score above to evaluate the cost of the split.
Splitting a dataset involves iterating over each row, checking if the attribute value is below or above the split value and assigning it to the left or right group respectively.
Below is a function named test_split() that implements this procedure.
|
1 2 3 4 5 6 7 8 9 |
# Split a dataset based on an attribute and an attribute value def test_split(index, value, dataset): left, right = list(), list() for row in dataset: if row[index] < value: left.append(row) else: right.append(row) return left, right |
Not much to it.
Note that the right group contains all rows with a value at the index above or equal to the split value.
2.2. Evaluating All Splits
With the Gini function above and the test split function we now have everything we need to evaluate splits.
Given a dataset, we must check every value on each attribute as a candidate split, evaluate the cost of the split and find the best possible split we could make.
Once the best split is found, we can use it as a node in our decision tree.
This is an exhaustive and greedy algorithm.
We will use a dictionary to represent a node in the decision tree as we can store data by name. When selecting the best split and using it as a new node for the tree we will store the index of the chosen attribute, the value of that attribute by which to split and the two groups of data split by the chosen split point.
Each group of data is its own small dataset of just those rows assigned to the left or right group by the splitting process. You can imagine how we might split each group again, recursively as we build out our decision tree.
Below is a function named get_split() that implements this procedure. You can see that it iterates over each attribute (except the class value) and then each value for that attribute, splitting and evaluating splits as it goes.
The best split is recorded and then returned after all checks are complete.
|
1 2 3 4 5 6 7 8 9 10 11 |
# Select the best split point for a dataset def get_split(dataset): class_values = list(set(row[-1] for row in dataset)) b_index, b_value, b_score, b_groups = 999, 999, 999, None for index in range(len(dataset[0])-1): for row in dataset: groups = test_split(index, row[index], dataset) gini = gini_index(groups, class_values) if gini < b_score: b_index, b_value, b_score, b_groups = index, row[index], gini, groups return {'index':b_index, 'value':b_value, 'groups':b_groups} |
We can contrive a small dataset to test out this function and our whole dataset splitting process.
|
1 2 3 4 5 6 7 8 9 10 11 |
X1 X2 Y 2.771244718 1.784783929 0 1.728571309 1.169761413 0 3.678319846 2.81281357 0 3.961043357 2.61995032 0 2.999208922 2.209014212 0 7.497545867 3.162953546 1 9.00220326 3.339047188 1 7.444542326 0.476683375 1 10.12493903 3.234550982 1 6.642287351 3.319983761 1 |
We can plot this dataset using separate colors for each class. You can see that it would not be difficult to manually pick a value of X1 (x-axis on the plot) to split this dataset.
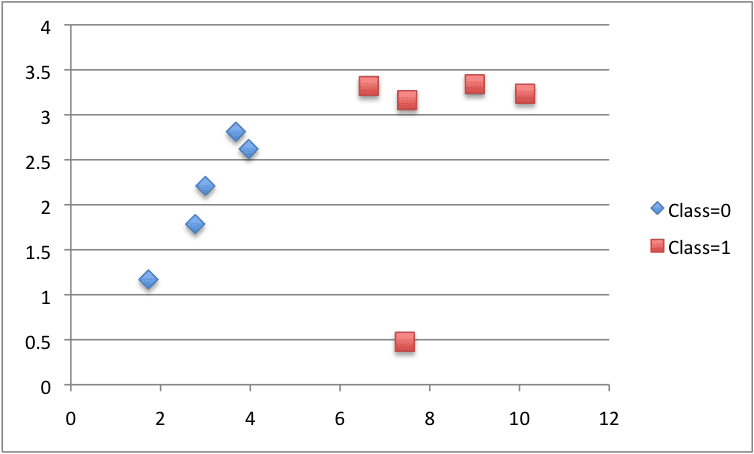
CART Contrived Dataset
The example below puts all of this together.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
# Split a dataset based on an attribute and an attribute value def test_split(index, value, dataset): left, right = list(), list() for row in dataset: if row[index] < value: left.append(row) else: right.append(row) return left, right # Calculate the Gini index for a split dataset def gini_index(groups, classes): # count all samples at split point n_instances = float(sum([len(group) for group in groups])) # sum weighted Gini index for each group gini = 0.0 for group in groups: size = float(len(group)) # avoid divide by zero if size == 0: continue score = 0.0 # score the group based on the score for each class for class_val in classes: p = [row[-1] for row in group].count(class_val) / size score += p * p # weight the group score by its relative size gini += (1.0 - score) * (size / n_instances) return gini # Select the best split point for a dataset def get_split(dataset): class_values = list(set(row[-1] for row in dataset)) b_index, b_value, b_score, b_groups = 999, 999, 999, None for index in range(len(dataset[0])-1): for row in dataset: groups = test_split(index, row[index], dataset) gini = gini_index(groups, class_values) print('X%d < %.3f Gini=%.3f' % ((index+1), row[index], gini)) if gini < b_score: b_index, b_value, b_score, b_groups = index, row[index], gini, groups return {'index':b_index, 'value':b_value, 'groups':b_groups} dataset = [[2.771244718,1.784783929,0], [1.728571309,1.169761413,0], [3.678319846,2.81281357,0], [3.961043357,2.61995032,0], [2.999208922,2.209014212,0], [7.497545867,3.162953546,1], [9.00220326,3.339047188,1], [7.444542326,0.476683375,1], [10.12493903,3.234550982,1], [6.642287351,3.319983761,1]] split = get_split(dataset) print('Split: [X%d < %.3f]' % ((split['index']+1), split['value'])) |
The get_split() function was modified to print out each split point and it’s Gini index as it was evaluated.
Running the example prints all of the Gini scores and then prints the score of best split in the dataset of X1 < 6.642 with a Gini Index of 0.0 or a perfect split.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
X1 < 2.771 Gini=0.444 X1 < 1.729 Gini=0.500 X1 < 3.678 Gini=0.286 X1 < 3.961 Gini=0.167 X1 < 2.999 Gini=0.375 X1 < 7.498 Gini=0.286 X1 < 9.002 Gini=0.375 X1 < 7.445 Gini=0.167 X1 < 10.125 Gini=0.444 X1 < 6.642 Gini=0.000 X2 < 1.785 Gini=0.500 X2 < 1.170 Gini=0.444 X2 < 2.813 Gini=0.320 X2 < 2.620 Gini=0.417 X2 < 2.209 Gini=0.476 X2 < 3.163 Gini=0.167 X2 < 3.339 Gini=0.444 X2 < 0.477 Gini=0.500 X2 < 3.235 Gini=0.286 X2 < 3.320 Gini=0.375 Split: [X1 < 6.642] |
Now that we know how to find the best split points in a dataset or list of rows, let’s see how we can use it to build out a decision tree.
3. Build a Tree
Creating the root node of the tree is easy.
We call the above get_split() function using the entire dataset.
Adding more nodes to our tree is more interesting.
Building a tree may be divided into 3 main parts:
- Terminal Nodes.
- Recursive Splitting.
- Building a Tree.
3.1. Terminal Nodes
We need to decide when to stop growing a tree.
We can do that using the depth and the number of rows that the node is responsible for in the training dataset.
- Maximum Tree Depth. This is the maximum number of nodes from the root node of the tree. Once a maximum depth of the tree is met, we must stop splitting adding new nodes. Deeper trees are more complex and are more likely to overfit the training data.
- Minimum Node Records. This is the minimum number of training patterns that a given node is responsible for. Once at or below this minimum, we must stop splitting and adding new nodes. Nodes that account for too few training patterns are expected to be too specific and are likely to overfit the training data.
These two approaches will be user-specified arguments to our tree building procedure.
There is one more condition. It is possible to choose a split in which all rows belong to one group. In this case, we will be unable to continue splitting and adding child nodes as we will have no records to split on one side or another.
Now we have some ideas of when to stop growing the tree. When we do stop growing at a given point, that node is called a terminal node and is used to make a final prediction.
This is done by taking the group of rows assigned to that node and selecting the most common class value in the group. This will be used to make predictions.
Below is a function named to_terminal() that will select a class value for a group of rows. It returns the most common output value in a list of rows.
|
1 2 3 4 |
# Create a terminal node value def to_terminal(group): outcomes = [row[-1] for row in group] return max(set(outcomes), key=outcomes.count) |
3.2. Recursive Splitting
We know how and when to create terminal nodes, now we can build our tree.
Building a decision tree involves calling the above developed get_split() function over and over again on the groups created for each node.
New nodes added to an existing node are called child nodes. A node may have zero children (a terminal node), one child (one side makes a prediction directly) or two child nodes. We will refer to the child nodes as left and right in the dictionary representation of a given node.
Once a node is created, we can create child nodes recursively on each group of data from the split by calling the same function again.
Below is a function that implements this recursive procedure. It takes a node as an argument as well as the maximum depth, minimum number of patterns in a node and the current depth of a node.
You can imagine how this might be first called passing in the root node and the depth of 1. This function is best explained in steps:
- Firstly, the two groups of data split by the node are extracted for use and deleted from the node. As we work on these groups the node no longer requires access to these data.
- Next, we check if either left or right group of rows is empty and if so we create a terminal node using what records we do have.
- We then check if we have reached our maximum depth and if so we create a terminal node.
- We then process the left child, creating a terminal node if the group of rows is too small, otherwise creating and adding the left node in a depth first fashion until the bottom of the tree is reached on this branch.
- The right side is then processed in the same manner, as we rise back up the constructed tree to the root.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# Create child splits for a node or make terminal def split(node, max_depth, min_size, depth): left, right = node['groups'] del(node['groups']) # check for a no split if not left or not right: node['left'] = node['right'] = to_terminal(left + right) return # check for max depth if depth >= max_depth: node['left'], node['right'] = to_terminal(left), to_terminal(right) return # process left child if len(left) <= min_size: node['left'] = to_terminal(left) else: node['left'] = get_split(left) split(node['left'], max_depth, min_size, depth+1) # process right child if len(right) <= min_size: node['right'] = to_terminal(right) else: node['right'] = get_split(right) split(node['right'], max_depth, min_size, depth+1) |
3.3. Building a Tree
We can now put all of the pieces together.
Building the tree involves creating the root node and calling the split() function that then calls itself recursively to build out the whole tree.
Below is the small build_tree() function that implements this procedure.
|
1 2 3 4 5 |
# Build a decision tree def build_tree(train, max_depth, min_size): root = get_split(train) split(root, max_depth, min_size, 1) return root |
We can test out this whole procedure using the small dataset we contrived above.
Below is the complete example.
Also included is a small print_tree() function that recursively prints out nodes of the decision tree with one line per node. Although not as striking as a real decision tree diagram, it gives an idea of the tree structure and decisions made throughout.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 |
# Split a dataset based on an attribute and an attribute value def test_split(index, value, dataset): left, right = list(), list() for row in dataset: if row[index] < value: left.append(row) else: right.append(row) return left, right # Calculate the Gini index for a split dataset def gini_index(groups, classes): # count all samples at split point n_instances = float(sum([len(group) for group in groups])) # sum weighted Gini index for each group gini = 0.0 for group in groups: size = float(len(group)) # avoid divide by zero if size == 0: continue score = 0.0 # score the group based on the score for each class for class_val in classes: p = [row[-1] for row in group].count(class_val) / size score += p * p # weight the group score by its relative size gini += (1.0 - score) * (size / n_instances) return gini # Select the best split point for a dataset def get_split(dataset): class_values = list(set(row[-1] for row in dataset)) b_index, b_value, b_score, b_groups = 999, 999, 999, None for index in range(len(dataset[0])-1): for row in dataset: groups = test_split(index, row[index], dataset) gini = gini_index(groups, class_values) if gini < b_score: b_index, b_value, b_score, b_groups = index, row[index], gini, groups return {'index':b_index, 'value':b_value, 'groups':b_groups} # Create a terminal node value def to_terminal(group): outcomes = [row[-1] for row in group] return max(set(outcomes), key=outcomes.count) # Create child splits for a node or make terminal def split(node, max_depth, min_size, depth): left, right = node['groups'] del(node['groups']) # check for a no split if not left or not right: node['left'] = node['right'] = to_terminal(left + right) return # check for max depth if depth >= max_depth: node['left'], node['right'] = to_terminal(left), to_terminal(right) return # process left child if len(left) <= min_size: node['left'] = to_terminal(left) else: node['left'] = get_split(left) split(node['left'], max_depth, min_size, depth+1) # process right child if len(right) <= min_size: node['right'] = to_terminal(right) else: node['right'] = get_split(right) split(node['right'], max_depth, min_size, depth+1) # Build a decision tree def build_tree(train, max_depth, min_size): root = get_split(train) split(root, max_depth, min_size, 1) return root # Print a decision tree def print_tree(node, depth=0): if isinstance(node, dict): print('%s[X%d < %.3f]' % ((depth*' ', (node['index']+1), node['value']))) print_tree(node['left'], depth+1) print_tree(node['right'], depth+1) else: print('%s[%s]' % ((depth*' ', node))) dataset = [[2.771244718,1.784783929,0], [1.728571309,1.169761413,0], [3.678319846,2.81281357,0], [3.961043357,2.61995032,0], [2.999208922,2.209014212,0], [7.497545867,3.162953546,1], [9.00220326,3.339047188,1], [7.444542326,0.476683375,1], [10.12493903,3.234550982,1], [6.642287351,3.319983761,1]] tree = build_tree(dataset, 1, 1) print_tree(tree) |
We can vary the maximum depth argument as we run this example and see the effect on the printed tree.
With a maximum depth of 1 (the second parameter in the call to the build_tree() function), we can see that the tree uses the perfect split we discovered in the previous section. This is a tree with one node, also called a decision stump.
|
1 2 3 |
[X1 < 6.642] [0] [1] |
Increasing the maximum depth to 2, we are forcing the tree to make splits even when none are required. The X1 attribute is then used again by both the left and right children of the root node to split up the already perfect mix of classes.
|
1 2 3 4 5 6 7 |
[X1 < 6.642] [X1 < 2.771] [0] [0] [X1 < 7.498] [1] [1] |
Finally, and perversely, we can force one more level of splits with a maximum depth of 3.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[X1 < 6.642] [X1 < 2.771] [0] [X1 < 2.771] [0] [0] [X1 < 7.498] [X1 < 7.445] [1] [1] [X1 < 7.498] [1] [1] |
These tests show that there is great opportunity to refine the implementation to avoid unnecessary splits. This is left as an extension.
Now that we can create a decision tree, let’s see how we can use it to make predictions on new data.
4. Make a Prediction
Making predictions with a decision tree involves navigating the tree with the specifically provided row of data.
Again, we can implement this using a recursive function, where the same prediction routine is called again with the left or the right child nodes, depending on how the split affects the provided data.
We must check if a child node is either a terminal value to be returned as the prediction, or if it is a dictionary node containing another level of the tree to be considered.
Below is the predict() function that implements this procedure. You can see how the index and value in a given node
You can see how the index and value in a given node is used to evaluate whether the row of provided data falls on the left or the right of the split.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# Make a prediction with a decision tree def predict(node, row): if row[node['index']] < node['value']: if isinstance(node['left'], dict): return predict(node['left'], row) else: return node['left'] else: if isinstance(node['right'], dict): return predict(node['right'], row) else: return node['right'] |
We can use our contrived dataset to test this function. Below is an example that uses a hard-coded decision tree with a single node that best splits the data (a decision stump).
The example makes a prediction for each row in the dataset.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# Make a prediction with a decision tree def predict(node, row): if row[node['index']] < node['value']: if isinstance(node['left'], dict): return predict(node['left'], row) else: return node['left'] else: if isinstance(node['right'], dict): return predict(node['right'], row) else: return node['right'] dataset = [[2.771244718,1.784783929,0], [1.728571309,1.169761413,0], [3.678319846,2.81281357,0], [3.961043357,2.61995032,0], [2.999208922,2.209014212,0], [7.497545867,3.162953546,1], [9.00220326,3.339047188,1], [7.444542326,0.476683375,1], [10.12493903,3.234550982,1], [6.642287351,3.319983761,1]] # predict with a stump stump = {'index': 0, 'right': 1, 'value': 6.642287351, 'left': 0} for row in dataset: prediction = predict(stump, row) print('Expected=%d, Got=%d' % (row[-1], prediction)) |
Running the example prints the correct prediction for each row, as expected.
|
1 2 3 4 5 6 7 8 9 10 |
Expected=0, Got=0 Expected=0, Got=0 Expected=0, Got=0 Expected=0, Got=0 Expected=0, Got=0 Expected=1, Got=1 Expected=1, Got=1 Expected=1, Got=1 Expected=1, Got=1 Expected=1, Got=1 |
We now know how to create a decision tree and use it to make predictions. Now, let’s apply it to a real dataset.
5. Banknote Case Study
This section applies the CART algorithm to the Bank Note dataset.
The first step is to load the dataset and convert the loaded data to numbers that we can use to calculate split points. For this we will use the helper function load_csv() to load the file and str_column_to_float() to convert string numbers to floats.
We will evaluate the algorithm using k-fold cross-validation with 5 folds. This means that 1372/5=274.4 or just over 270 records will be used in each fold. We will use the helper functions evaluate_algorithm() to evaluate the algorithm with cross-validation and accuracy_metric() to calculate the accuracy of predictions.
A new function named decision_tree() was developed to manage the application of the CART algorithm, first creating the tree from the training dataset, then using the tree to make predictions on a test dataset.
The complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 |
# CART on the Bank Note dataset from random import seed from random import randrange from csv import reader # Load a CSV file def load_csv(filename): file = open(filename, "rt") lines = reader(file) dataset = list(lines) return dataset # Convert string column to float def str_column_to_float(dataset, column): for row in dataset: row[column] = float(row[column].strip()) # Split a dataset into k folds def cross_validation_split(dataset, n_folds): dataset_split = list() dataset_copy = list(dataset) fold_size = int(len(dataset) / n_folds) for i in range(n_folds): fold = list() while len(fold) < fold_size: index = randrange(len(dataset_copy)) fold.append(dataset_copy.pop(index)) dataset_split.append(fold) return dataset_split # Calculate accuracy percentage def accuracy_metric(actual, predicted): correct = 0 for i in range(len(actual)): if actual[i] == predicted[i]: correct += 1 return correct / float(len(actual)) * 100.0 # Evaluate an algorithm using a cross validation split def evaluate_algorithm(dataset, algorithm, n_folds, *args): folds = cross_validation_split(dataset, n_folds) scores = list() for fold in folds: train_set = list(folds) train_set.remove(fold) train_set = sum(train_set, []) test_set = list() for row in fold: row_copy = list(row) test_set.append(row_copy) row_copy[-1] = None predicted = algorithm(train_set, test_set, *args) actual = [row[-1] for row in fold] accuracy = accuracy_metric(actual, predicted) scores.append(accuracy) return scores # Split a dataset based on an attribute and an attribute value def test_split(index, value, dataset): left, right = list(), list() for row in dataset: if row[index] < value: left.append(row) else: right.append(row) return left, right # Calculate the Gini index for a split dataset def gini_index(groups, classes): # count all samples at split point n_instances = float(sum([len(group) for group in groups])) # sum weighted Gini index for each group gini = 0.0 for group in groups: size = float(len(group)) # avoid divide by zero if size == 0: continue score = 0.0 # score the group based on the score for each class for class_val in classes: p = [row[-1] for row in group].count(class_val) / size score += p * p # weight the group score by its relative size gini += (1.0 - score) * (size / n_instances) return gini # Select the best split point for a dataset def get_split(dataset): class_values = list(set(row[-1] for row in dataset)) b_index, b_value, b_score, b_groups = 999, 999, 999, None for index in range(len(dataset[0])-1): for row in dataset: groups = test_split(index, row[index], dataset) gini = gini_index(groups, class_values) if gini < b_score: b_index, b_value, b_score, b_groups = index, row[index], gini, groups return {'index':b_index, 'value':b_value, 'groups':b_groups} # Create a terminal node value def to_terminal(group): outcomes = [row[-1] for row in group] return max(set(outcomes), key=outcomes.count) # Create child splits for a node or make terminal def split(node, max_depth, min_size, depth): left, right = node['groups'] del(node['groups']) # check for a no split if not left or not right: node['left'] = node['right'] = to_terminal(left + right) return # check for max depth if depth >= max_depth: node['left'], node['right'] = to_terminal(left), to_terminal(right) return # process left child if len(left) <= min_size: node['left'] = to_terminal(left) else: node['left'] = get_split(left) split(node['left'], max_depth, min_size, depth+1) # process right child if len(right) <= min_size: node['right'] = to_terminal(right) else: node['right'] = get_split(right) split(node['right'], max_depth, min_size, depth+1) # Build a decision tree def build_tree(train, max_depth, min_size): root = get_split(train) split(root, max_depth, min_size, 1) return root # Make a prediction with a decision tree def predict(node, row): if row[node['index']] < node['value']: if isinstance(node['left'], dict): return predict(node['left'], row) else: return node['left'] else: if isinstance(node['right'], dict): return predict(node['right'], row) else: return node['right'] # Classification and Regression Tree Algorithm def decision_tree(train, test, max_depth, min_size): tree = build_tree(train, max_depth, min_size) predictions = list() for row in test: prediction = predict(tree, row) predictions.append(prediction) return(predictions) # Test CART on Bank Note dataset seed(1) # load and prepare data filename = 'data_banknote_authentication.csv' dataset = load_csv(filename) # convert string attributes to integers for i in range(len(dataset[0])): str_column_to_float(dataset, i) # evaluate algorithm n_folds = 5 max_depth = 5 min_size = 10 scores = evaluate_algorithm(dataset, decision_tree, n_folds, max_depth, min_size) print('Scores: %s' % scores) print('Mean Accuracy: %.3f%%' % (sum(scores)/float(len(scores)))) |
The example uses the max tree depth of 5 layers and the minimum number of rows per node to 10. These parameters to CART were chosen with a little experimentation, but are by no means are they optimal.
Running the example prints the average classification accuracy on each fold as well as the average performance across all folds.
You can see that CART and the chosen configuration achieved a mean classification accuracy of about 97% which is dramatically better than the Zero Rule algorithm that achieved 50% accuracy.
|
1 2 |
Scores: [96.35036496350365, 97.08029197080292, 97.44525547445255, 98.17518248175182, 97.44525547445255] Mean Accuracy: 97.299% |
Extensions
This section lists extensions to this tutorial that you may wish to explore.
- Algorithm Tuning. The application of CART to the Bank Note dataset was not tuned. Experiment with different parameter values and see if you can achieve better performance.
- Cross Entropy. Another cost function for evaluating splits is cross entropy (logloss). You could implement and experiment with this alternative cost function.
- Tree Pruning. An important technique for reducing overfitting of the training dataset is to prune the trees. Investigate and implement tree pruning methods.
- Categorical Dataset. The example was designed for input data with numerical or ordinal input attributes, experiment with categorical input data and splits that may use equality instead of ranking.
- Regression. Adapt the tree for regression using a different cost function and method for creating terminal nodes.
- More Datasets. Apply the algorithm to more datasets on the UCI Machine Learning Repository.
Did you explore any of these extensions?
Share your experiences in the comments below.
Review
In this tutorial, you discovered how to implement the decision tree algorithm from scratch with Python.
Specifically, you learned:
- How to select and evaluate split points in a training dataset.
- How to recursively build a decision tree from multiple splits.
- How to apply the CART algorithm to a real world classification predictive modeling problem.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer them.
Discover How to Code Algorithms From Scratch!

No Libraries, Just Python Code.
...with step-by-step tutorials on real-world datasets
Discover how in my new Ebook:
Machine Learning Algorithms From Scratch
It covers 18 tutorials with all the code for 12 top algorithms, like:
Linear Regression, k-Nearest Neighbors, Stochastic Gradient Descent and much more...
Finally, Pull Back the Curtain on
Machine Learning Algorithms
Skip the Academics. Just Results.






Super good .. Thanks a lot for sharing
I’m glad you found it useful steve.
Hi , Could you explain what do it mean ?
[X1 < 6.642]
[X1 < 2.771]
[0]
[0]
[X1 < 7.498]
[1]
[1]
Does it mean if X1 <6.642 and X1 <2.771, it belongs to class 0, if X1 <6.642 and X1 < 7.498, it belong to class 1 ?
Thanks for your help.
Mak
Yes, [X1 < 6.642] is the root node with two child nodes, each leaf node has a classification label.
Hello, can you help me with this problem?
This project is expecting you to write two functions. The first will take the training data including the type of features and returns a decision tree best modeling the classification problem. This should not do any pruning of the tree. An optional part of the homework will require the pruning step. The second function will just apply the decision tree to a given set of data points.
You should follow the following for this homework:
1. Load the data and performa a quick analysis of what it is and what features it has. You will need to construct a vector indicating the type (values) of each of the features. In this case, you can assume that you have numeric (real or integer) and categorical values.
2. Implement the function “build_dt(X, y, attribute_types, options)”.
a. X: is the matrix of features/attributes for the training data. Each row includes a data sample.
b. y: The vector containing the class labels for each sample in the rows of X.
c. attribute_types: The vector containing (1: integer/real) or (2: categorical) indicating the type of each attributes (the columns of X).
d. options: Any options you might want to pass to your decision tree builder.
e. Returns a decision tree of the structure of your choice.
3. Implement the function “predict_dt(dt, X, options)”.
a. dt: The decision tree modeled by “build_dt” function.
b. X: is the matrix of features/attributes for the test data.
c. Returns a vector for the predicted class labels.
4. Report the performance of your implementation using an appropriate k-fold cross validation using confusion matrices on the given dataset.
[Optional] Implement the pruning strategy discussed in the class. Repeat the steps 4 above. Indicate any assumptions you might have made.
I think you should complete your own homework assignments.
If you have questions about your homework assignment, ask your teacher. That is why you’re paying them.
Hi can you help me interpret the model the I created..thanks
[X1 < 2.000]
[X10 < 0.538]
[0.0]
[1.0]
[X15 < 10.200]
[X20 < 2.700]
[X10 < 0.574]
[X6 < 14.000]
[1.0]
[X8 < 256.000]
[1.0]
[X16 < 5.700]
[X18 < 0.600]
[X2 < 82.000]
[X15 < 4.100]
[0.0]
[0.0]
[1.0]
[X4 < 112.000]
[X1 < 3.000]
[0.0]
[0.0]
[0.0]
[0.0]
[0.0]
[0.0]
[1.0]
hello, super jor let me translate this article in russian language with link on this resource?
No thanks. This is a common question that I answer here:
https://machinelearningmastery.com/faq/single-faq/can-i-translate-your-posts-books-into-another-language
Hi Jason, can you use a decision tree in place of a rules engine?
It really depends on the specifics of the application and requirements of the stakeholders.
can this code be used for a multinomial Decision tree dataset?
It can with some modification.
What modifications would you recommend?
Specifically the handling of evaluating and selecting nominal values at split points.
Thanks for detailed description and code.
I tried to run and got ‘ValueError: empty range for randrange()’ in line 26:
index = randrange(len(dataset_copy))
if replace dataset_copy to list(dataset) and run this line manually it works.
Sounds like a Python 3 issue Mike.
Replace
With:
I have updated the cross_validation_split() function in the above example to address issues with Python 3.
How about to use of euclidian distance instead of calculating for each element in the dataset?
What do you mean exactly? Are you able to elaborate?
Thank you very much
You’re welcome.
Hi Jason,
Great tutorial on CART!
The results of decision trees are quite dependent on the training vs test data. With this in mind, how do I set the amount of training vs test data in the code right now to changes in the result? From what I can see, it looks like they are being set in the evaluate_algorithm method.
//Kind regards
Sokrates
That is correct Sokrates.
The example uses k-fold cross validation to evaluate the performance of the algorithm on the dataset.
You can change the number of folds by setting the “n_folds” variable.
You can use a different resampling method, like train/test splits, see this post:
https://machinelearningmastery.com/implement-resampling-methods-scratch-python/
Nice Post. I will like to ask if i this implementation can be used for time series data with only one feature
Yes it could, but the time series data would have to be re-framed as a supervised learning problem.
See this post for more information:
https://machinelearningmastery.com/time-series-forecasting-supervised-learning/
Really helpful. Thanks a lot for sharing.
I’m glad you found the post useful vishal.
Hi Jason,
there is a minor point in your code. Specifically, in the follwing procedure:
——
# Build a decision tree
def build_tree(train, max_depth, min_size):
root = get_split(dataset)
split(root, max_depth, min_size, 1)
return root
——
I think it should be root = get_split(train), eventhough your code is still running correctly since dataset is the global variable.
Thank you for your nice posts.
I like your blog very much.
I think you’re right, nice catch!
I’ll investigate and fix up the example.
Thanks a lot Jason, really helpful
I’m glad to hear that.
Excuse me,I’m confused about the get_split function in your work.Actually, i encountered a problem that the function always returns a tree with only a depth of one even if i have two more features .As a novice,i found it a little difficult to work out the problem.So would you please answer the question for me?Just show me a direction is OK.Thanks.
Perhaps you data does not benefit from more than one spit?
Perhaps try a decision tree as part of the scikit-learn library?
I’m slowly going through your code and I’m confused about a line in your
get_split functiongroups = test_split(index, row[index], dataset)Doesn’t this only return the left group? It seems we need both groups to calculate the gini_index?
Thank you.
Hi Amit,
The get_split() function evaluates all possible split points and returns a dict of the best found split point, gini score, split data.
After playing around with the code for a bit, I realized that function returns both groups (left and right) under one variable.
In the function
splitif not left or not right:
node[‘left’] = node[‘right’] = to_terminal(left + right)
return
Why do you add (left + right)? Are you adding the two groups together into one group?
Thank you.
Yes.
Another question (line 132)
if isinstance(node[‘left’], dict):
return predict(node[‘left’], row)
isinstance is just checking if we have already created such a dictionary instance?
Thank you.
It is checking if the type of the variable is a dict.
My name is Cynthia I am very interested in machine learning and at the same time python but l am very new to coding can this book help me in coding? I am a geomatic engineer aspiring to upgrade myself into environmental engineering
It would be easier to learn to program first.
Or you can learn machine learning without any programming using Weka:
https://machinelearningmastery.com/start-here/#weka
Hello,
I’ve been trying some stuff out with this code and I thought I was understanding what was going on but when I tried it on a dataset with binary values it doesn’t seem to work and I can’t figure out why. Could you help me out please?
Thanks.
The example assumes real-valued inputs, binary or categorical inputs should be handled differently.
I don’t have an example at hand, sorry.
Hello there,
If the inputs are categorical, it this the right way to split the inputs? Instead of using less than and greater than, I use == or !=.
Thanks
Perhaps try it and see.
Hey, Hendra
Did it work for you? When I tried with my dataset the accuracy dropped to 30%.
Hi
Could you tell me how decision trees are used for predicting an unknown function when a sample dataset is given. What i mean how it is used for regression?
Good question, sorry, I don’t have an example of decision trees for regression from scratch.
How can we use weka for regression using decision trees?
Consider using the search function of this blog.
See this post:
https://machinelearningmastery.com/use-regression-machine-learning-algorithms-weka/
Great article, this is exactly what I was looking for!
I’m really glad to hear that Joe!
I am new to machine learning … successfully ran the code with the given data set
Now I want to run it for my own data set … will the algo always treat the last column as the column to classify?
thanks
Yes, that is how it was coded.
Thank you! It works beautifully
Well done!
Apologies if I am taking too much time but I tried to run this algo on the below scenario with 10 folds
#
#https://www.youtube.com/watch?v=eKD5gxPPeY0&list=PLBv09BD7ez_4temBw7vLA19p3tdQH6FYO
#
#outlook
#
#1 = sunny
#2 = overcast
#3 = rain
#
#humidity
#
#1 = high
#2 = normal
#
#wind
#
#1 = weak
#2 = strong
#
#play
#
#0 = no
#1 = yes
The tree generated does not cater to x2, x3 variables (for some reason), just generates for x1 (what am I doing wrong?) … the accuracy has dropped to 60%
[X1 < 1.000]
[1.0]
[1.0]
[X1 < 1.000]
[1.0]
[1.0]
[X1 < 1.000]
[1.0]
[1.0]
[X1 < 1.000]
[1.0]
[1.0]
[X1 < 3.000]
[X1 < 1.000]
[1.0]
[1.0]
[0.0]
[X1 < 1.000]
[1.0]
[1.0]
[X1 < 1.000]
[1.0]
[1.0]
[X1 < 1.000]
[1.0]
[1.0]
[X1 < 1.000]
[1.0]
[1.0]
[X1 < 1.000]
[1.0]
[1.0]
Scores: [100.0, 100.0, 0.0, 100.0, 0.0, 100.0, 0.0, 0.0, 100.0, 100.0]
Mean Accuracy: 60.000%
Ensure that you have loaded your data correctly.
Yes, working fine now 🙂
Would love to get my hands on a script that would print the tree in a more graphical (readable) format. The current format helps but does get confusing at times.
Thanks a lot!
This will generate a graphviz dot file that you can use to generate a .pnj, jpeg etc.
e.g:
dot -Tpng graph1.dot > graph.png
Note it generates a new file each time it is called – graph1.dot … graphN.dot
# code begin
def graph_node(f, node):
if isinstance(node, dict):
f.write(‘ %d [label=\”[X%d %d;\n’ % ((id(node), id(node[‘left’]))))
f.write(‘ %d -> %d;\n’ % ((id(node), id(node[‘right’]))))
graph_node(f, node[‘left’])
graph_node(f, node[‘right’])
else:
f.write(‘ %d [label=\”[%s]\”];\n’ % ((id(node), node)))
def graph_tree(node):
if not hasattr(graph_tree, ‘n’): graph_tree.n = 0
graph_tree.n += 1
fn = ‘graph’ + str(graph_tree.n) + ‘.dot’
f = open(fn, ‘w’)
f.write(‘digraph {\n’)
f.write(‘ node[shape=box];\n’)
graph_node(f, node)
f.write(‘}\n’)
Hello dude, Do I only need to put this codes at the end part?? You only define functions…How can I run this and on what parts of the code….Thanks
Hello Greg. Your code doesn’t work in my case. Can you correct it?
Thanks a lot for this, Dr. Brownlee!
I’m glad you found it useful.
excellent explanation
I’m glad you found it useful.
I’m implementing AdaBoost from scratch now, and I have a tough time understanding how to apply the sample weights calculated in each iteration to build the decision tree? I guess I should modify the gini index in this regard, but I’m not specifically sure how to do that. Could you shed some light? Thanks!
I offer a step-by-step example in this book:
https://machinelearningmastery.com/master-machine-learning-algorithms/
I would also recommend this book for a great explanation:
http://www-bcf.usc.edu/~gareth/ISL/
Part of the code: predicted = algorithm(train_set, test_set, *args)
TypeError: ‘int’ object is not callable
Issue: I’m getting error like this. Please help me
I’m sorry to hear that.
Ensure that you have copied all of the code without any extra white space.
hey jason
honestly dude stuff like this is no joke man.
I did BA in math and one year of MA in math
then MA in Statistical Computing and Data Mining
and then sas certifications and a lot of R and man let me tell you,
when I read your work and see how you have such a strong understanding of the unifications of all the different fields needed to be successful at applying machine learning.
you my friend, are a killer.
Thanks.
Hello Sir!!
First of all Thank You for such a great tutorial.
I would like to make a suggestion for function get_split()-
In this function instead of calculating gini index considering every value of that attribute in data set , we can just use the mean of that attribute as the split_value for test_split function.
This is just my idea please do correct me if this approach is wrong.
Thank You!!
Try it and see.
Hello Sir,
I am a student and i need to develop an algorithm for both Decision Tree and Ensemble(Preferably,Random Forest) both using python and R. i really need the book that contains everything that is,the super bundle.
Thank you so very much for the post and the tutorials. They have been really helpful.
You can grab the super bundle here:
https://machinelearningmastery.com/super-bundle/
Hello Sir,
First of all Thank You for such a great tutorial
I am new to machine learning and python as well.I’m slowly going through your code
I have a doubt in the below section
# Build a decision tree
def build_tree(train, max_depth, min_size):
root = get_split(train)
split(root, max_depth, min_size, 1)
return root
In this section the “split” function returns “none”,Then how the changes made in “split” function are reflecting in the variable “root”
To know what values are stored in “root” variable, I run the code as below
# Build a decision tree
def build_tree(train, max_depth, min_size):
root = get_split(train)
print(root) — Before calling split function
split(root, max_depth, min_size, 1)
print(root) — after calling split function
The values in both cases are different.But I’m confused how it happens
Can anybody help me out please?
Thank you.
The split function adds child nodes to the passed in root node to build the tree.
Hello sir
Thanks for this tutorial.
I guess that when sum the Gini indexes of subgroups into a total one, their corresponding group sizes should be taken into consideration, that is, I think it should be a weighted sum.
I think I have the same question. The Gini Index computed in the above examples are not weighted by the size of the partitions. Shouldn’t they be? I posted a detailed example, but it has not been excepted (yet?).
Hello Sir,
Assume we have created a model using the above algorithm.
Then if we go for prediction using this model ,will this model process on the whole training data.?
Thank you.
We do not need to evaluate the model when we want to make predictions. We fit it on all the training data then start using it.
See this post:
https://machinelearningmastery.com/train-final-machine-learning-model/
Hello Sir,
Assume I have 1 million training data,and I created and saved a model to predict whether the patient is diabetic or not ,Every thing is ok with the model and the model is deployed in client side(hospital).consider the case below
1. If a new patient come then based on some input from the patient the model will predict whether the patient is diabetic or not.
2.If another patient come then also our model will predict
my doubt is in the both case will the model process on one million training data.?
that is if 100 patient come at different time, will this model process 100 times over one million data(training data).?
Thank you
No, after you fit the model you save it. Later you load it and make a prediction.
See this post on creating a final model for making predictions:
https://machinelearningmastery.com/train-final-machine-learning-model/
Excellent, thank you for sharing!
Are there tools that allow to do this without ANY coding?
I mean drag-n-drop / right-click-options.
It is very useful to understand behind-the-scenes but much faster in many cases to use some sort of UI.
What would you recommend?
Thank you,
Michael
Yes, Weka:
https://machinelearningmastery.com/start-here/#weka
Hello,
Excellent post. It has been really helpful for me!
Is there a similar article/tutorial for the C4.5 algorithm?
Is there any implementations in R?
Thank you,
Ali.
See here for R examples:
https://machinelearningmastery.com/non-linear-classification-in-r-with-decision-trees/
dataset = list(lines)
Error: iterator should return strings, not bytes (did you open the file in text mode?)
How can i solve this issue ?
This might be a Python version issue.
Try changing the loading of the file to ‘rt’ format.
Hi jason, thanks for sharing about this algorithm,
i have a final task to use some classification model like decision tree to fill missing values in data set, is it possible ?
Thank you
Yes, see this post for ideas:
https://machinelearningmastery.com/handle-missing-data-python/
Hi Jason,
I tried running the modified version by adding labels for the data
#to add label but not part of the training
data = pd.read_csv(r’H:\Python\Tree\data_banknote_authentication.txt’, header = None )
dataset = pd.DataFrame(data)
dataset.columns = [‘var’, ‘skew’, ‘curt’, ‘ent’, ‘bin’]
so on the last step, i only ran
n_folds = 5
max_depth = 5
min_size = 10
scores = evaluate_algorithm(dataset, decision_tree, n_folds, max_depth, min_size)
print(‘Scores: %s’ % scores)
print(‘Mean Accuracy: %.3f%%’ % (sum(scores)/float(len(scores))))
and i got the error message saying
ValueError: empty range for randrange()
Could you help explain why?
Also on this section to load the CSV file
# Load a CSV file
def load_csv(filename):
file = open(filename, “rb”)
lines = reader(file)
dataset = list(lines)
return dataset
could you help explain how to add the location of the file if it’s on local drive?
Thank you very much,
What changes would you suggest i should make to solve the following problem:
A premium payer wants to improve the medical care using Machine Learning. They want to predict next events of Diagnosis, Procedure or Treatment that is going to be happen to patients. They’ve provided with patient journey information coded using ICD9.
You have to predict the next 10 events reported by patient in order of occurrence in 2014.
Data Description
There are three files given to download: train.csv, test.csv and sample_submission.csv
The train data consists of patients information from Jan 2011 to Dec 2013. The test data consists of Patient IDs for the year 2014.
Variable Description
ID Patient ID
Date Period of Diagnosis
Event Event ID (ICD9 Format) – Target Variable
Sounds like homework.
If not, I recommend this process for working through new predictive modeling problems:
https://machinelearningmastery.com/start-here/#process
Jason,
Thanks for this wonderful example. I rewrote your code, exactly as you wrote it, but cannot replicate your scores and mean accuracy. I get the following:
Scores: [28.467153284671532, 37.591240875912405, 76.64233576642336, 68.97810218978103, 70.43795620437956]
Mean Accuracy: 56.42335766423357
As another run, I changed nFolds to be 7, maxDepth to be 4 and minSize to be 4 and got:
Scores: [40.30612244897959, 38.775510204081634, 37.755102040816325, 71.42857142857143, 70.91836734693877, 70.91836734693877, 69.89795918367348]
Mean Accuracy: 57.142857142857146
I have tried all types of combinations for nFolds, minSize and maxDepth, and even tried stopping randomizing the selection of data instances into Folds. However, my scores do not change, and my mean accuracy has never exceeded 60%, and in fact consistently is in the 55%+ range. Strangely, my first two scores are low and then they increase, though not to 80%. I am at my wits end, why I cannot replicate your high (80%+) scores/accuracy.
Any ideas on what might be happening? Thanks for taking the time to read my comment and again thanks for the wonderful illustration.
Ikib
That is odd.
Perhaps a copy-paste error somewhere? That would be my best guess.
Hi Jason
It’s not usefull splitting on groups with size 1 (as you do now with groups size 0) and you can make them directly terminal.
BR
Thanks Jason for a very well put together tutorial!
Read through all the replies here to see if someone had asked the question I had. I think the question Xinglong Li asked on June 24, 2017 is the same one I have, but it wasn’t answered so I’ll rephrase:
Isn’t the calculation of the Gini Index suppose to be weighted by the count in each group?
For example, in the table just above section “3. Build a Tree”, on line 15, the output lists:
X2 < 2.209 Gini=0.934
When I compute this by hand, I get this exact value if I do NOT weight the calculation by the size of the partitions. When I do this calculation the way I think it's supposed to be done (weighting by partition size), I get Gini=0.4762. This is how I compute this value:
1) Start with the test data sorted by X1 so we can easily do the split (expressed in csv format):
X1,X2,Y
7.444542326,0.476683375,1
1.728571309,1.169761413,0
2.771244718,1.784783929,0
— group 1 above this line, group 2 below this line —
2.999208922,2.209014212,0
3.961043357,2.61995032,0
3.678319846,2.81281357,0
7.497545867,3.162953546,1
10.12493903,3.234550982,1
6.642287351,3.319983761,1
9.00220326,3.339047188,1
2) Compute the proportions (computing to 9 places, displaying 4):
P(1, 0) = group 1 (above line), class 0 = 0.6667
P(1, 1) = group 1 (above line), class 1 = 0.3333
P(2, 0) = group 2 (below line), class 0 = 0.4286
P(2, 1) = group 2 (below line), class 1 = 0.5714
3) Compute Gini Score WITHOUT weighting (computing to 9 places, displaying 4):
Gini Score =
[P(1, 0) x (1 – P(1, 0))] +
[P(1, 1) x (1 – P(1, 1))] +
[P(2, 0) x (1 – P(2, 0))] +
[P(2, 1) x (1 – P(2, 1))] =
0.2222 + 0.2222 + 0.2449 + 0.2449 = 0.934 (just what you got)
4) Compute Gini Score WITH weighting (computing to 9 places, displaying 4):
[(3/10) x (0.2222 + 0.2222)] + [(7/10) x (0.2449 + 0.2449)] = 0.4762
Could you explain why you don't weight by partition size when you compute your Gini Index?
Thanks!
Hi Michael, I believe the counts are weighted.
See “proportion” both in the description of the algorithm and the code calculation of gini for each class group.
See “an introduction to statistical learning with applications in r” pages 311 onwards for the equations.
Does that help?
Hi Jason, Thanks for the reply. After reading and re-reading pages 311 and 312 several times, it seems to me that equation (8.6) in the ISL (love this book BTW, but in this rare case, it is lacking some important details) should really have a subscript m on the G because it is computing the Gini score for a particular region. Notice that in this equation: 1) the summation is over K (the total number of classes) and 2) the mk subscript on p hat. These imply that both the proportion (p hat sub mk) and G are with respect to a particular region m.
Eqn. (8.6) in the ISL is correct, but it’s not the final quanitity that should be used for determining the quality of the split. There is an additional step (not described in the ISL) which needs to be done: weighting the Gini scores by the size of the proposed split regions as shown in this example:
https://www.researchgate.net/post/How_to_compute_impurity_using_Gini_Index
I think the gini_index function should look something like what is shown below. This version gives me the values I expect and is consistent with how the gini score of a split is computed in the above example:
Thoughts?
Sorry about the loss of indentation in the code… Seems like the webapp parses these out before posting.
I added some pre tags for you.
I’ll take a look, thanks for sharing.
Thanks for your eyeballs. The original code I proposed works, but it has some unnecessary stuff in it. This is a cleaner (less lines) implementation (hopefully the pre tags I insert work…):
Thanks. Added to my trello to review.
Update: Yes, you are 100% correct. Thank you so much for pointing this out and helping me see the fault Michael! I really appreciate it!
I did some homework on the calculation (checked some textbooks and read sklearns source) and wrote a new version of the gini calculation function from scratch. I then update the tutorial.
I think it’s good now, but shout if you see anything off.
Hi Jason,In your code:
print(gini_index([[[1, 1], [1, 0]], [[1, 1], [1, 0]]], [0, 1]))
how should i interpret the number of ZEROES and ONES(distribution of classes in group)?I am new to this..
Great question!
No, each array is a pattern, the final value in each array is a class value. The final array are the valid classes.
I did not notice any difference in the split point and prediction when I used both the old and revised gini codes
how to apply this for discrete value ?
Do you recommend this decision tree model for binary file based data?
I do not recommend an algorithm. I recommend testing a suite of algorithms to see what works best.
See this post:
https://machinelearningmastery.com/a-data-driven-approach-to-machine-learning/
Good Day sir!
I would like to ask why does my code run around 30-46 minutes to get the mean accuracy? I am running about 24100 rows of data with 3 columns. Is it normally this slow? Thank you very much!
Yes, because this is just a demonstration.
For a more efficient implementation, use the implementation is scikit-learn.
For more on why you should only code machine learning algorithms from scratch for learning, see this post:
https://machinelearningmastery.com/dont-implement-machine-learning-algorithms/
Can you leave an example with a larger hard-coded decision tree, with 2 or even 3 stages?
I can’t seem to get the syntax right to work with larger decision trees.
Thanks for the suggestion. Note that the code can develop such a tree.
Yeah I just found that out myself, might be better to not even give the example and let us think for some time.
I would like to ask if there is a way to store the already learned decision tree? so that when the predict function is called for one test data only, it can be run at a much faster speed. Thank you very much!
Hey Maria, you could save it to a .txt file and then read it back in for the prediction. I did it that way and it works flawlessly!
oh okay. I will save the result for build_tree to a text file? Thank you very much for this information! 😀
Great tip Jarich.
Yes, I would recommend using the sklearn library then save the fit model using pickle.
I have examples of this on my blog, use the search.
Jason : Thank you for a great artcile. Can u provide me the code for generating the tree. I have got scores and accuracy and would like to view the decision tree. Please provide the code related to generating tree
i would need to code using graphviz
Thanks for the suggestion.
I would like to know if this tree can also handle multiple classification aside from 0 or 1? for example I need to classify if it is 1,2,3,4,5 Thank you very much!
It could be extended to multiple classes. I do not have an example sorry.
I can’t get started.
I use Python 3.5 on Spyder 3.0.0.
Your code doesn’t read the dataset and an error comes out:
Error: iterator should return strings, not bytes (did you open the file in text mode?)
I’m a beginner in both Python and ML.
Can you help?
Thank you, Leo
The code was developed for Python 2.7. I will update it for Python 3 in the future.
Perhaps start with Weka where no programming is required:
https://machinelearningmastery.com/start-here/#weka
Hello, I am a beginner and I have the same problem, too. Why are codes different for Python 2 and 3? Shall I save the file as text or csv if I am using your codes? What should I do now? Thank you
Python 2 and 3 are different programming language. The example is intended for Python2 and requires modification to work with Python3.
I will make those changes in coming months.
I have a dataset with titles on both axes (will post example below) and they have 1’s and 0’s signifying if the characteristic is present or not. Where would you suggest I start with altering your code in order to fit this dataset? Right now I am getting an error with the converting string to float function.
white blue tall
ch1 0 1 1
ch2 1 0 0
ch3 1 0 1
I’m not sure I understand your problem, sorry.
Perhaps this process will help you define and work through your problem end to end:
https://machinelearningmastery.com/start-here/#process
This is great!
May I know do you plan to introduce cost-complexity pruning for CART?
Many thanks!
Not at this stage. Perhaps you could post some links?
Hello sir, i was trying to use your code on my data, but i find a problem which said ValueError: invalid literal for float(): 1;0.766126609;45;2;0.802982129;9120;13;0;6;0;2 . How could i fix this?
Hello Sir,
Thanks for the tutorial. It is quite clear and concise. However, how best can you advise on altering it to suit the following data set:
my_data=[[‘slashdot’,’USA’,’yes’,18,’None’], [‘google’,’France’,’yes’,23,’Premium’], [‘digg’,’USA’,’yes’,24,’Basic’], [‘kiwitobes’,’France’,’yes’,23,’Basic’], [‘google’,’UK’,’no’,21,’Premium’], [‘(direct)’,’New Zealand’,’no’,12,’None’], [‘(direct)’,’UK’,’no’,21,’Basic’], [‘google’,’USA’,’no’,24,’Premium’], [‘slashdot’,’France’,’yes’,19,’None’], [‘digg’,’USA’,’no’,18,’None’], [‘google’,’UK’,’no’,18,’None’], [‘kiwitobes’,’UK’,’no’,19,’None’], [‘digg’,’New Zealand’,’yes’,12,’Basic’], [‘slashdot’,’UK’,’no’,21,’None’], [‘google’,’UK’,’yes’,18,’Basic’], [‘kiwitobes’,’France’,’yes’,19,’Basic’]
This tutorial is advanced.
Perhaps you would be better suited starting with Weka:
https://machinelearningmastery.com/start-here/#weka
Or scikit-learn library in Python:
https://machinelearningmastery.com/start-here/#python
Jason,
Thanks so much for this code. I was able to adapt for my application but can you suggest how to plot the tree diagram in place of the build tree code?
Thanks
John
Sorry John, I don’t have code to plot the tree.
Hey Jason,
Thank you very much for this tutorial. It has been extremely helpful in my understanding of decision trees. I have one point of inquiry which requires clarification. In the ‘def split (node, max_depth, min_size, depth)’ method I can see that you recursively split the left nodes until the max depth or min size condition is met. When you perform the split you add 1 to the current depth to but once you move to the next if statement to process the first right child/partition there is no function that resets the depth.
Is this because in a recursive function you are saving new depth values for every iteration? Meaning unique depth values are saved at each recursion?
Depth is passed down each line of the recursion.
Also how is the return of build tree read?
i.e.:
in:
tree = build_tree(dataset, 10, 1)
print tree
out:
{‘index’: 0, ‘right’: {‘index’: 0, ‘right’: {‘index’: 0, ‘right’: 1, ‘value’: 7.497545867, ‘left’: 1}, ‘value’: 7.497545867, ‘left’: {‘index’: 0, ‘right’: 1, ‘value’: 7.444542326, ‘left’: 1}}, ‘value’: 6.642287351, ‘left’: {‘index’: 0, ‘right’: {‘index’: 0, ‘right’: 0, ‘value’: 2.771244718, ‘left’: 0}, ‘value’: 2.771244718, ‘left’: 0}}
Each node had has references to left and right nodes.
Hey,
I have a dataset with numerical and categorical values, so I modified some of the code in load_csv and main to convert categorical values to numerical:
#load_csv
def load_csv(filename):
#file = open(filename, “r”)
headers = [“location”,”w”,”final_margin”,”shot_number”,”period”,”game_clock”,”shot_clock”,”dribbles”,”touch_time”,
“shot_dist”,”pts_type”,”close_def_dist”,”target”]
df = pd.read_csv(filename, header=None, names=headers, na_values=”?”)
cleanup_nums = {“location”: {“H”: 1, “A”: 0},
“w”: {“W”: 1, “L”: 0},
“target”: {“made”: 1, “missed”: 0}}
df.replace(cleanup_nums, inplace=True)
df.head()
obj_df=list(df.values.flatten())
return obj_df
#main:
# Test CART on Basketball dataset
seed(1)
# load and prepare data
filename=’data/basketball.train.csv’
dataset = load_csv(filename)
i=0
new_list=[]
while i<len(dataset):
new_list.append(dataset[i:i+13])
i+=13
n_folds = 5
max_depth = 5
min_size = 10
scores = evaluate_algorithm(new_list, decision_tree, n_folds, max_depth, min_size)
print('Scores: %s' % scores)
print('Mean Accuracy: %.3f%%' % (sum(scores)/float(len(scores))))
The program is still working for your dataset, but when i try to run it on my own, the program freezes in the listcomp in the line p = [row[-1] for row in group].count(class_val) / size, in the method gini_index.
Do you have any idea how i can break this infinite loop?
Thanks
Perhaps get it working with sklearn first and better understand your data:
https://machinelearningmastery.com/start-here/#python
Thanks it helps!
You’re welcome.
I don’t get this part row [-1] for row in group. please explain what’s happening here
You can learn more about Python array indexing in this post:
https://machinelearningmastery.com/index-slice-reshape-numpy-arrays-machine-learning-python/
Just thanks <3
You’re welcome.
Really helpful, thanks a lot !
Thanks, I’m glad to hear that.
Easy to understand, no need of any background knowledge. Excellent Article
Thanks,
Great tutorial,can you help me using entropy criteria for splitting rather than gini index. Any example for that. I tried but not working for me
Sorry, I don’t have an example.
Hi Nandit,
I tried out Jason’s algorithm along with Entropy as cost function. Might be able to help you.
@Kevin Sequeira
Hi Kevin,
I tried using entropy – information gain criteria in Jason’s algorithm, but it’s not working for me. Please, can you provide an example of its implementation?
Hello Sir,
Is it possible to visualize the above tree? is it possible implement using Graphviz? Can you please provide an example to visualize the above decision tree?
Sure you can. Sorry, I don’t have an example.
Perhaps you can use a third-part CART library with viz builtin, such as R or Weka.
Hi. Check this out:
https://github.com/Aarhi/MLAlgorithms/blob/main/DecisionTreeImplementationVisualization.py
I have implemented decision trees from scratch and visualized it using Decision Trees.
Well done, thanks for sharing!
Hi –
I notice that
to_terminalis basically the Zero Rule algorithm. Is that just a coincidence (i.e. it might just be the least stupid thing to do with small data sets)? Or is there a deeper idea here that when you cut down the tree to whatever minimum data size you choose, you might want to apply some other predictive algorithm to the remaining subset (sort of using a decision tree to prefilter inputs to some other method)?(If it’s just a coincidence, then I guess I’m guilty of over-fitting… 🙂 )
Thanks.
Just a coincidence, well done on noting it!
Im having trouble trying to classify the iris.csv dataset, how would you suggest modifying the code to to load in the attributes and a non numeric class?
Load the data as a mixed numpy array, then covert the strings to integers via a label encoding.
I have many examples on the blog.
I am having loading dataset it says the following error ” iterator should return strings, not bytes (did you open the file in text mode?”
Are you able to confirm that you are using Python 2.7?
A typo under the subheading Banknote Dataset…
{The dataset contains 1,372 with 5 numeric variables.} should be
{The dataset contains 1,372 rows with 5 numeric variables.}
Thanks, fixed.
outcomes = [row[-1] for row in group]
what does this code snippet does.?
for Regression tree, to_terminal(group) function should return mean of target attribute values, but I am getting group varible having all NaN values.
Please suggest any alternatives
Collects all the output values.
Perhaps this post will help you understand lists and array indexing in Python:
https://machinelearningmastery.com/index-slice-reshape-numpy-arrays-machine-learning-python/
The example was written for Python 2.7, confirm you are using this version.
Thanks, This is extremely useful.
We are trying to make a decision based on the attributes found in a WebElemnt on a WebPage for generating dynamic test cases.
for example, we want to feed some properties like type = “text” and name =”email” etc… and then come to a decision that its a text filed and generate test cases applicable for textfield. An example of what we want to read properties from
Any pointers, how to begin ? Any help would be appreciated. Basically how to start preparing the training dataset for links, images and other element types..
Perhaps this post will help define the inputs and outputs to the model:
https://machinelearningmastery.com/how-to-define-your-machine-learning-problem/
Hi Jason,
I must be blind. Once an attribute is used in a split, I don’t see you remove it from the next recursive split/branching.
Thanks!
It can be reused if it can add value, but note the subset of data at the next level down will be different – e.g. having been split.
Hello Jason,
Thanks for the great tutorial.
I am a bit confused by the definition of gini index.
gini_index = sum(proportion * (1.0 – proportion)) is just 2*p*q where p is the proportion of one class in the group and q is the proportion of the other, i.e.
gini_index = sum(proportion * (1.0 – proportion)) == 2p*(1-p)
Correct?
What makes you say that?
Nice tutorial sir. I really enjoy going through you work sir. It has helped me to understand what is happening under the hood better. How can someone plot the logloss for this tutorial?
Thanks.
How would a plot of logloss work for a decision tree exactly? As it is being constructed? It might not be appropriate.
Hi Jason,
thanks for your tutorial, i want to translate your essay to Chinese not for business just for share.
Can i?
If i can, there are something i should notice?
Please do not translate and republish my content.
OK, thanks for your reply.
I’d recommend that for the recursive split explanation, you may add a note regarding Python creating a separate copy of the ‘node’ dictionary on each recursive call. It is not trivially known to people without extensive programming experience and can confuse them if they try to evaluate the expressions manually for the small ‘dataset’. Thanks otherwise for such a great article.
Thanks for the suggestion.
Welcome. I ran through the whole recursive code for the small dataset manually myself just to get a hang of the flow. Used a different variable name for ‘node’s at each depth level. Here’s the code, incase it is helpful to anyone:
root = get_split(dataset)
max_depth = 3
min_size = 1
depth = 1
node = root.copy()
left, right = node[‘groups’]
del(node[‘groups’])
node[‘left’] = l1 = get_split(left)
depth = depth + 1
l1left, l1right = l1[‘groups’]
del(l1[‘groups’])
len(l1left) <= min_size
l1['left'] = to_terminal(l1left)
l1['right'] = l1r2 = get_split(l1right)
depth = depth + 1
l1r2left, l1r2right = l1r2['groups']
del(l1r2['groups'])
not l1r2left or not l1r2right
l1r2['left'] = l1r2['right'] = to_terminal(l1r2left + l1r2right)
depth = depth – 1
node['right'] = r1 = get_split(right)
r1left, r1right = r1['groups']
del(r1['groups'])
r1['left'] = r1l2 = get_split(r1left)
depth = depth + 1
r1l2left, r1l2right = r1l2['groups']
del(r1l2['groups'])
r1l2['left'], r1l2['right'] = to_terminal(r1l2left), to_terminal(r1l2right)
depth = depth – 1
r1['right'] = r1r2 = get_split(r1right)
depth = depth + 1
r1r2left, r1r2right = r1r2['groups']
del(r1r2['groups'])
not r1r2left or not r1r2right
r1r2['left'] = r1r2['right'] = to_terminal(r1r2left + r1r2right)
Nice work!
What does the number after each X mean? (X1, X2, etc) In the print_tree function it stands for node[‘index’]. Is this the gini-index?
Why do only two indexes appear around your example-data?
I tried some other dataset and this is the result:
[X4 < 23.570]
[X1 < 1143.631]
[X1 < 1096.228]
[X1 < 905.490]
[X1 < 714.853]
[X1 < 524.248]
[0]
[0]
[0]
[0]
[0]
[X1 < 1143.631]
[0]
[0]
[X1 < 1373.940]
[X1 < 1292.075]
[X1 < 1276.251]
[X1 < 1141.360]
[X1 < 912.083]
[1]
[1]
[1]
[1]
[1]
[X1 < 1373.940]
[1]
[1]
Xn is the variable number, the floating point value number after is the observation of that variable chosen to be the split point.
Another question:
How exactly do you have to modify your python-code to solve an n-dimensional problem with a decision tree?
Wouldn’t this be a good update for this page here? 🙂
I would be more than happy and thankful.
Anyway, thank you so much for your work here.
The code is to teach you how the algorithm works.
To solve real problems, I recommend using the sklearn library. I have many examples, search the blog.
Really nice writeup ! Can I know what these “groups” are exactly ? I know they’re 3d arrays having 2 groups of data but what do they hold ? Thanks !
Thanks. Which groups?
I was referring to the “groups” of data but I understood what they were after I read the code. Thank you for your time !
No problem.
Hello,
I am working on decision tree classifier. Could you please share the coding of SLIQ – decission tree classifier in python language?
What is SLIQ?
Hello,
SLIQ is a Decision Tree classifier for Data Mining. I am sending you the file of SLIQ. Please check it and if possible please share its coding in Python.
http://sci2s.ugr.es/keel/pdf/algorithm/congreso/SLIQ.pdf
Thank you, sir.
Thanks. Sorry, I don’t know anything about it.
I highly recommend publishing this code here on github since it makes contributing very easy. I would then suggest a simple pruning-function. And you already suggest other improvements/features in your text. Plus: you as the owner get more inisghts and numbers concerning clones/usages etc. What do you think?
Thanks for the suggestion, but I prefer to not have my code on github.
Why?
Because I control this blog and all aspects of the experience, I have zero control over github, it is someone else’s platform.
I write code tutorials, I don’t just dump source code online. Context is critical.
Also sell books, which allows me to keep writing more tutorials.
thanks alot!!
it really helps!!!
your book and your books are wonderful as well
I am a beginner of ML and I sort of have a language problem in reading those material , but not that difficult.
Q1:I wonder how to corectly use your book and your site tutorial and have a good combination of them?
Q2:there are 63 pages in your tutorial ,are they sorted by the random? or each of your blog is ordered ,eg. the blog right after this article is ,so next one is more advanced in the level of decision trees?last,what I wanna ask is that should I read the matiarial one by one if I wanna learning systematicly about ML or I just read your book ,after read it I look back on this site ?
The blog is not very ordered. You can use the search feature.
For more help on a specific topic, I recommend getting a book or using a guide here:
https://machinelearningmastery.com/start-here/
Hi, train_set.remove(fold) line would raise an error.
ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
I solve this problem by refer to this note.
https://stackoverflow.com/questions/3157374/how-do-you-remove-a-numpy-array-from-a-list-of-numpy-arrays
removearray(train_set,fold)
Hope this can help others.
The code was written for Python 2.7. Are you using this version of Python?
Hi Jason!
First of all, wonderful article and thank you very much for writing it. I wanted to ask you regarding training a perceptron decision tree, where as you might know, each node is a perceptron. Now to build such a tree, ideally I should be training each node separately and depending on the output (say if its a binary classification problem with y = 0 or 1), I would split the dataset into two child nodes, provided the impurity is greater than threshold.
Since the split at each node depends on the weights used for the perceptron, the entire tree structure also depends on the weights. Thus, during training I would be constantly changing the tree structure (which might be computationally intensive). Or should I train each perceptron separately starting from the root and do the same for the subsequent nodes?
Thanks!
Sorry, I don’t have an example of such an algorithm.
Sir I have to implement decision tree and linear svc from scratch on a data set of comments (string) fetched from twitter the csd will contain comments under the hashtags student refugee and trip ….
Perhaps use a library like scikit-learn, it will be much easier!
Sir I have implement this decision tree,but i want to visualize the tree,how can i do that?
by using sklearn i can use pydotplus.graph_from_dot_data,but i don’t know how to do it by using this tutorial
Sorry, I don’t have an example of plotting a decision tree.
How can i connect mysql database to get dataset
I don’t see why not.
Did u get code
Sir ,
I am doing project that will take images as data and will process it such that has to take a decision “Yes” or “No”……….suppose i give a data image as blue sky image…..it has to print yes only if its blue….else no…..this is to be done by Machine Learning …..Can you please help me telling a code for that….or any source ……please help me out
Sounds like a big project.
Perhaps look into the use of CNN models and perhaps making use of pre-trained models. Also try this tutorial:
https://machinelearningmastery.com/develop-a-deep-learning-caption-generation-model-in-python/
Hi Jason, This is a great article which you have posted. Really helped me a lot.
By any chance do you have links of the extension of this tutorial – Cross-Entropy and Tree Pruning?
Thank you so much!
I don’t, sorry.
Thank for your article. It is really helpful to my assignment. In your case, “class” has been generated; either 0 or 1. How would you generate class if you haven’t done so? Any references on generating “class”. Thanks for your detailed explanation.
This is our goal. To train a model on data where we have the class, then use the trained model to make a prediction on data where we don’t have the class.
I recommend starting here:
https://machinelearningmastery.com/machine-learning-in-python-step-by-step/
I’m in a situation where i need to have a custom splitting function that splits on the basis of difference in rate (churn rates for different demographic groups) into two nodes, one with low difference and other with higher difference.
I worked out that function, but my issue now lies in splitting.If i have 3M rows of data, then i will have to calculate my metric 3M-1 times: for every combination of rows. is there a more efficient way to choose splits to evaluate?
Any thoughts would be appreciable. Thanks,
This question sounds specific to your dataset, I’m not sure I can answer it sensibly sorry.
In the n x m dataset :The get_split(dataset) function above is calculating gini index for n-1 possible combinations of row-values for that column, before selecting the best split. Which means m x (n-1) evaluations of gini_index().
I was able bring down these gini evaluations to #of-unique-row-values in that column, but still is is pretty low.Is there a way to make it more efficient. I don’t know how sklearn or rpart do i so quickly.
I expect there is, I would recommend using an implementation from a robust library such as sklearn. This code is for learning how the algorithm works, not for operational use.
Hi Jason, Great tutorial!! I ran your code on the small dataset and then replicated this process manually in Excel to gain a deeper understanding. Finally, I tried using the same data in sklearn but could not get the same results. What is sklearn in DecisionTreeClassifier doing differently/additionally from your code? Thanks!!!
The sklearn library will be doing many more things to ensure that the results are robust and that the implementations use best practices. These differences add up to give slightly different resulting trees.
Hi. Can anyone help me what is “algorithm” in “predicted = algorithm(train_set, test_set, *args)” line? Thanks a lot.
It is executing the algorithm function name passed in as an argument.
If this is challenging for you, perhaps start with sklearn:
https://machinelearningmastery.com/start-here/#python
Hi Jason,
I built a CART model for my case study in my project using the similar code. But when run it, it throws error p=[row[-1] for row in group].count(class_val)/size ;invalid index to scalar variable.
Due to inter conversion of the dataset many times throughout the code,group finally becomes a list instead of a nd array, so row in group becomes a scalar variable for which we are trying to access [-1] index,resulting in that error.But how to fix it i am not able to figure out. Can you help me here ?
Ensure your data was loaded as you expect.
Hi Jason,
I’m building a tree based on your code but I get stuck when I try to visualize the tree. Can you show me how to do that?? Thanks
I show how to visualize with a simple ascii output.
Hi Jason! Thank you for the great tutorial.
I have a question regarding decision trees. Can I use label encoder for nominal categorical variables? I found a variety of answers for this question on the web by nothing unequivocal.
You can, but no need with decision trees.
I also recommend using sklearn’s implementation.
Excellent explanation! Very helpful
Thank you so much 🙂
I’m glad it helped.
Hello,
thanks a lot for the nice explanation.
I am wondering if I am able to add somewhere in the code an overall constraint regarding the test data.
For example, depending on to which group an instance is assigned, it has a specific value for a parameter. For all the test data the sum of these parameters have to equal something.
Is this somehow possible?
Sorry, Id on’t follow, perhaps you can elaborate what you mean?
Hey Dr. Brownlee,
Thankful for your tutorial!
Some comments: I needed to change rb to rt, and I removed the string to float function for my dataset of >400000 obs (since they were already float). I know you didn’t design this for such a large dataset, but it’s just for fun for now! If my calculations are correct, this will take my machine ~ 200 minutes.
Just fyi, it’s still working with Python 3.7 🙂
Best,
Thanks.
Hello, is there a way to modify this for a large dataset? Wouldn’t want to wait for so long.
Thank you
Yes, I would encourage you to use the faster implementation in sklearn, this post is just for learning about the algorithm.
Hi Jason thanks for your material, in decision tree after every split we should remove the splitter column but your code is not doing that could you provide some sample code for the same
No, we do not remove the column used in the split in this algorithm.
Thank you . It was super helpful in understanding the algorithm
Thanks, I’m glad it helped.
Very nice Jason! Really clear explanation and well-written code. I really appreciate you putting out this content for free!
Thanks. I hope that it helps.
Hi Jason,
Firstly I must say this website is an absolute life-saver when it comes to learning ML without any prior experience – amazing job creating and maintaining these articles!
I am a 3rd year student and I was given my Final year individual project to do which is implementing ML onto an affordable embedded system to recognise human activities – in my case walking and running to start with – the project is mainly proof-of-concept. Until I found this post I was very stuck but when I did I ran it on my collected data (from an on-board accelerometer) which I labeled and got a staggering 93-96% accuracy on my PC.
The microcontroller I am using runs MicroPython – I am using the LoPy by Pycom if you are curious – hence it is fairly straightforward to adapt it to run on it with a very small modified dataset. However I am new to ML and still learning python and I was wondering given the example above what would you suggest I should try to attempt to have a labelled dataset for training and an unlabelled dataset for testing, could that be done easily?
I tried examining your cross-validation function and it seems to need labels to work properly (I looked at your post about it – https://machinelearningmastery.com/implement-resampling-methods-scratch-python/). Correct me if I’m wrong of course. Do you have any suggestions? Thank you again for what you are doing here!
Thanks.
Well done!
An unlabelled dataset means you are not testing, it means you are making a prediction on new data. No resampling is possible.
anybody have the CART algorithm as step by step description.??? Please help me…….
Try this:
https://machinelearningmastery.com/classification-and-regression-trees-for-machine-learning/
Man, I can only say you are solid gold. You really “help developers (like you) get results”.
Awesome tutorial and unlike many others, practical and usable out of the box.
My most sincere thank you.
Thanks, I’m happy it helps!
Hey Jason I know ML in C++ is not something you teavh but I am trying to implement decision tree in C++ can you help me by providing some code in C++..?
Sorry, I don’t have the capacity to write some cpp for you.
Thanks a lot ! I am new to algorithms. and your blog me helped me a lot to understand and more than that in implementation. Thanks again 🙂
I’m happy to hear that!
Thanks man. This gives me a light to implement c45 algorithm
I’m happy it helped.
There is one thing which I find a bit odd:
In the “gini_index” you have the
p=[row[-1] for row in groups].count(label)
which just counts how many time the label appears as the last value of your feature vector (I assume each row in group is a feature vector – please correct me if Im wrong) – I dont see how that is usefull ?
The group is scored based on the ratio of each class. More purity (less mixing) is better.
Yes, I found the same thing. For example, if you pass the following to the gini function, you get the same result:
gini_index([[[10, 1], [‘c’,’b’, 0]], [[‘e’, 1], [1, 0]]], [0, 1]))
You get the same result. In other words, the first element in each list does not matter. So what exactly does this data represent?
Exactly. Same doubt here. The
gini_indexfunction seems to accept multidimensional data, but then the computation is done only with regard on the last dimension of the data, a bit puzzling…I’ve been thinking about refining the implementation to avoid unnecessary splits as suggested in the article.
Looks like the get_split function is testing every single value from a column. In the situation where all the labels are already the same but the predictors are different, if it had tested unique (sorted) values only, the smallest value in each column would be tested and set as the best gini score, and all of the rows would be allocated to the right side due to test_split checking for <, and the "if not left or not right:" check in the split function would terminate it due to an empty left side.
Assuming i don't do the unique + sort before checking for split points, another idea i have is to add the best gini score to the node dictionary too, and add another terminating condition of "if node['gini'] == 0: node['left'], node['right'] = to_terminal(left), to_terminal(right)".
Comparing the 2 strategies above, the gini check (2nd) strategy would allow the tree to terminate 1 level earlier than the "empty left side" check. However, doing unique+sort would cut down a lot of computation if the dataset has many duplicate values in it's columns, such as label encoded values from categorical data.(which usually repeat).
Any other ideas of how it can be cut shorter?/reduced computation?
I've been thinking about pruning too. What are the considerations/functions i may need to edit/variables to track?
Yes, I would encourage you to look at the implementation in sklearn, it is much faster by design.
Thanks for the post, code, and all the follow ups! I also was wondering about avoiding some of the unnecessary splits at the bottom of the tree. In case others are curious, one short addition to the code would be to add
if len(class_values) == 1: return to_terminal(dataset)
as the second line of get_split, and then
if not isinstance(node, dict): return
at the beginning of split.
It looks like this avoids unnecessary splitting in the example given and in some other datasets.
Thanks again!
Nice one!
I want to implement c4.5 from scratch in python. Any links for this ?
I do not, sorry.
I did some modification to deal with categorical variables,
I ran the program on another dataset (Loan Prediction) and it worked fine with about 79% accuracy.
Well done!
Hi Jason,
Thanks for producing such a great resource!
When evaluating all possible splits, how should you proceed if the impurity measure returns multiple local minimums (assuming this is possible?). So if for instance, multiple features contain a Gini index of zero, or if a feature were to contain equivalent minimum Gini indices at different split points?
Should you test all possible combinations of splits?
Also, as in the example, what’s reason for not applying a condition which terminates the node if pure?
It should (and may, I don’t recall). Great comment!
If all splits are even (same score), then a random spit can be chosen.
Yes, we test all splits as part of the algorithm.
Hi, can I use some of your code for a personal project? I am trying to implement a slightly different decision tree.
This is a common question that I answer here:
https://machinelearningmastery.com/faq/single-faq/can-i-use-your-code-in-my-own-project
Hi Jason,
I found this example super helpful. And most of the time when we want to build decision trees, we need to define our own questions, and use these questions to create and build a decision tree. Now, you have essentially created your own functions to do the job.
In your experience, do you find that most often than not, you need to build your own decision tree from scratch and not use models such as XGBoost, Sklearn etc to do the underlying work? I guess I am also asking would you be able to do what you did using an open-source library like sklean or XGBoost or other boosted open-source tools? Would a scientist be able to ask their own questions and provide their own split values using open-source tools, or do you need to construct your own decision tree, prediction mechanism and accuracy calculation functions or can this be created using open-source tools? Hope you can understand what I am getting at.
BTW – if you answered this previously, please excuse me.
I have read many of your posts, such as https://machinelearningmastery.com/visualize-gradient-boosting-decision-trees-xgboost-python/
and thought this was the most interesting as you built it from scratch.
Thanks, I’m happy to hear that.
No, I very rarely write code from scratch – it’s too easy to introduce bugs and write slow code. I use libs because they are tested and are fast.
Yes, I recommend using open source libs in nearly all cases.
“A perfect separation results in a Gini score of 0, whereas the worst case split that results in 50/50 classes in each group result in a Gini score of 0.5 (for a 2 class problem).” wait don’t you think this is wrong, 0.5 means perfect seperation.
No, in this case it means a worst case where the classes are mixed in each group.
The code line:
file = open(filename, “rb”)
is incompatible with the data file , it should be instead:
file = open(filename, “rt”)
Thanks, fixed.
Hi Jason, I’m not very familiar with the Gini index, so please ignore me if I am wrong. But according to the book ‘Elements of Statistical Learning’, the definition of Gini index is
gini = 1-sum(p_k * (1-p_k))
This one also seems to me to be more intuitive to understand.
However, your implementation uses
gini = (1-sum(p_k **2)) * sum(p_k **2)
I understand that loss functions can take many form as long as they have the same extreme point. I can see that they actually yield the same result for k = 2, I can’t prove mathematically that they will be equivalent at all the time. May I know if this is just another way to use Gini index? Many thanks.
This might help:
https://en.wikipedia.org/wiki/Gini_coefficient
Thanks for the response. But I think maybe you mean Gini impurity defined within https://en.wikipedia.org/wiki/Decision_tree_learning#Gini_impurity? The link you provided is actually an economical term.
Yes, sorry, too quick off the search-copy-paste.
Thanks Jason, I also realized that I was so stupid as those two are completely equivalent if we just expand the formulas and rearrange…Thanks for the post, it’s the best tutorial I’ve ever seen.
Thanks.
I’m so happy that it helped you on your project!
That’s an excellent tutorial. Thanks for writing this up. Very useful to see an implementation from scratch to understand all of the issues involved
Thanks, I’m happy it’s useful!
Hi Jason,
Thanks for the awesome tutorial.
I have a challenging problem:
I need to implement an “interactive Decision Tree” whereby the user decides which features to split on rather than using gini index.
For example, in the banknote_authentication dataset, I need to allow the user to give the order of nodes to put in the tree e.g. skewness as the root node, kurtosis next, followed by variance, and then entropy of image.
How can I tweak the code to allow for that?
Many thanks
Sounds like you need to build an interface. e.g. engineering, not machine learning.
TypeError: ‘list’ object cannot be interpreted as an integer
Hi Jason thanks for you code, while i running and learning the codes .
this error comes out, can you please help me ?
Sorry to hear that, see this:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Hello.
I’ve tried to analyze your code and I have a doubt about cross_validation.
If I have k folds, it’s normal that your code produces k different trees?
What if I have a training set (that can be divided in k folds) but a different test set? In which tree there is the prediction phase? Thanks so much.
Correct.
If you want to use a train/test set, you will need to prepare a different test harness to evaluate your model.
Hi, thanks for this tutorial.
I implemented this code myself, using information entropy (#explanation of information entropy here: https://victorzhou.com/blog/information-gain/) instead of the Gini score. Here are the only functions I changed/added from the code above, but it is kind of an ignorant implementation, assuming it is a 2D dataset (+class)
Thanks for sharing.
Me again, thanks again for this tutorial. I have one problem, and it’s that specifying a max_depth that is too large breaks the code. I imported my own dataset, and when I specify a max_depth of 2,3,4 it works, but when I go to max_depth=5, I get this error.
It seems that “node[‘groups’]” is “None”, and I can’t figure out where that is happening. Maybe there should be a way to catch this error? I think the code is supposed terminate before it breaks like this, but it’s not working.
I’m not sure offhand, sorry. Perhaps running through a debugger?
It did take some debugging, but I figured it out. I used an extra “if/else” statement to check for the NoneType. I also checked if it was NoneType using “is None” instead of “if not”, because for some reason “if not” wasn’t working
Well done.
Hey Jason, great tutorial!
I wanna know is their any other scratch algorithm to implement classification tree?
I searched a long time and just found this CART approach and the random forest approach.
Is there any other classofocation approach?
Thanks for your sharing!
Thanks!
Yes, I have a few. Perhaps start here:
https://machinelearningmastery.com/start-here/#code_algorithms
How are you handling cases when all the rows have the same label, here also we should stop splitting. Is the split function handling it by checking: whether the left is empty or right is empty?
Left or right will be empty if and only if the splitting value is maximum or minimum of an explanatory variable. When does it happen?
Yes. Gini will show perfect separation.
Hi, I think this code have a minor problem in detect which index of data such (x0,x1,x2) are importent selectable. in default case it select x1 and did not change if x0 is selectable index.
tnx
I’m sorry to hear that you are having trouble, perhaps this will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
your means i get mistake or your means i can announce your website code problem in this case?
I don’t believe there is a problem with the implementation.
Hi Jason! Thanks for yout great tutorial.
But I wanna know do you have any tutorials on implementing regression tree based on this model? Besides, do you have any code for tree pruning?
Thanks a lot!
Hi Jason! Thanks for yout great tutorial.
But I wanna know do you have any tutorials on implementing regression tree based on this model? Besides, do you have any code for tree pruning?
Thanks a lot!
Not at this stage.
Hey Jason,
Thank you for posting this model. Instead of classification, how would you recommend using this technique (regression) to predict housing prices, based on types and lot size, for example?
Perhaps use a standard implementation here:
https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeRegressor.html
Thanks for this Jason, my interest centers around unplugging the Gini function and plugging in a different cost function which unless I am missing something should not have any repercussions. With horse racing data it would be interesting to see if evaluating splits based on profitability would improve a model over Gini which is seeking out accuracy
Sounds great!
Is this algorithm easily amendable to predict probabilities ?
It can predict probabilities, but they will need to be calibrated:
https://machinelearningmastery.com/calibrated-classification-model-in-scikit-learn/
I meant from scratch, not using sklearn libraries
Yes, you can adapt it, again you will need to then calibrate the predicted probabilities.
Sorry, I don’t have a worked example, I recommend checking a good review paper or textbook on the topic.
Thank you for that great tutorial. Exist an extension for the calculation of the feature importance based on your dict-structure of the tree?
This will help you with feature importance:
https://machinelearningmastery.com/calculate-feature-importance-with-python/
I have seen this article too and use the sklearn-library. The next step is to go depper and extend your decision tree classificator.
Yes, extending the decision tree implementation is a good next step. Sorry, I don’t have the capacity to guide you.
HI Jason
As i feel that, it is not gini index but it is gini impurity. Gini index term comes under economics.
Thanks.
Hello are you from Nirma Uni.
No, I am from Melbourne, Australia.
Excellent tutorial, thank you for creating Machine Learning Mastery.
Could you please help me understand one point?
“New nodes added to an existing node are called child nodes. A node may have zero children (a terminal node), one child (one side makes a prediction directly) or two child nodes.”
I don’t see how one child is possible. If there is no split to be done, shouldn’t the node be terminal?
I’m also adding this for other people that may have the same question I had (please correct me if I’m wrong). In this part:
“The scores are then added across each child node at the split point to give a final Gini score for the split point that can be compared to other candidate split points.”
The reason for this to be a regular addition instead of a weighted addition is because the weighing of imbalanced classes was already considered in the calculation of the Gini indexes. Scikit-learn, for instance, calculates Gini indexes as sum(p*(1-p)) and considers weights later.
Thanks.
Good question, yes, it sounds like a terminal node. You might want to set it up so that it makes a “no prediction” on one side of the split.
Very useful and informative article. I appreciate to author for providing such an useful article specially related to Gini Index.
Thanks!
Hey, Jason.
Thank you for this article! Could you tell me how or help me with your code, to get the decision rules from the tree built? I mean, I wish to explicitly print the IF-THEN rules for the tree.
Sorry, I don’t have an example of this.
I compared accuracy results of your code with with sklearn, there’s a huge difference. this code gives 97% accuracy whereas sklearn returns 57% accuracy. can you explain the reason?
Thanks
Perhaps the methods were compared on different data or different samples of the same data?
Perhaps the there was a bug or typo in your sklearn code?
Perhaps there is was a bug or typo in your copy of the above code?
Perhaps you need to tune the sklearn implementation?
Perhaps the above implementation is already tuned?
Hi Jason,
Great and very easy explanations of all the topics…
You’re welcome.
hi Jason is , it possible to explain me this bit
Gini(group_1) = 0.0 * 0.5
Yes, I recommend reading the section on “Gini Index”.
Hi jason, sorry this two bit. I am slightly confused. We only got two groups and aren’t we suppose to find two gini impurity from each group. But I here we worked out three gini impurity from each group and how we got below numbers. could you please clarify this for me. thank you
Gini(group_1) = 0.0 * 0.5
Gini(group_1) = 0.0
Yes, we are working through the calculation – calculating the terms.
i need this code with java language can you help?
No.
I need to develop an algorithm for Aspect based Sentiment Analysis. But I dont want to use any deep learning method. How to customize a standard classification algo so that it can be used in ABSA.
Perhaps use a bag of words representation and test a suite of standard ML algorithms.
size = float(len(group)) on [[[1, 1], [1, 0]], [[1, 1], [1, 0]]], [0, 1]
gives the number sets on each side of groups and not instances which is the number needed for the Gini.
what am I missing?
Hello, Thank you so much for such a great article.
I think your print_tree function needs a slight modification as it seems that you have only considered the left child nodes that are less than the split value in the formatted print ([X%d < %.3f]) and, that's why after running the code for your mentioned example, we get the following result:
[X1 < 6.642]
[X1 < 2.771]
[0]
[0]
[X1 7.498] for class [1] not “<"
def print_tree(node, depth=0):
if isinstance(node, dict):
print('%s[X%d < %.3f]' % ((depth*' ', (node['index']+1), node['value'])))
print_tree(node['left'], depth+1)
print_tree(node['right'], depth+1)
You’re correct. As quoted, “Although not as striking as a real decision tree diagram, it gives an idea of the tree structure and decisions made throughout.” That function is just for illustration.
Could you help explain how step 5, “as we rise back up the constructed tree to the root.” work? I cannot see how the backup to the root work in the code. Thanks
No, that piece of code does not back to the root. What this sentence means is that from the root to the leaves, we consistently define what is left and right node. If the check is true then left, if false then right, or vice versa. What you must not do is sometimes, the check is true to go left but sometimes go right.
Hi Andrian, Thanks for your reply. I tried to reproduce your code and have one more question:
The following dictionary is generated through your first recursion of the split function.
‘index’: 0, ‘value’: 6.642287351, ‘groups’: ([[2.771244718, 1.784783929, 0], [1.728571309, 1.169761413, 0], [3.678319846, 2.81281357, 0], [3.961043357, 2.61995032, 0], [2.999208922, 2.209014212, 0]], [[7.497545867, 3.162953546, 1], [9.00220326, 3.339047188, 1], [7.444542326, 0.476683375, 1], [10.12493903, 3.234550982, 1], [6.642287351, 3.319983761, 1]])
I think after this step, all nodes are pure(left group all have label 0 while right group all have label of 1). Could you let me know why you keep splitting the tree after the first step?
You should continue the split if your desired tree depth is not reached yet.
Hi Jason, This is my loss function and to_ Terminal used for regression, but when I use them to predict house prices in Boston, the effect is not very good. Can you help me?
I think your second “for row in group” is wrong.
How should I correct it?
the “temp = avg-x” line is repeatedly overwriting “temp” without using it in the loop. Is that what you want to do?
thank you , that‘s my fault. The loss should be in the loop
Clear and easy to understand.
Thank you for this article.
For the extension* (At the end of extension 3)
Requirement :- To stop the further splitting of nodes if
1). current_depth min_size
2). The groups are pure (only a single unique class in each of the two groups.
# changing the split() function {refer ‘—>’ marker for new lines added}:-
def split(node, max_depth, min_size, depth):
left, right = node[‘groups’]
del(node[‘groups’])
# check for a no split
if not left or not right:
node[‘left’] = node[‘right’] = to_terminal(left + right)
return
# check for max depth
if depth >= max_depth:
node[‘left’], node[‘right’] = to_terminal(left), to_terminal(right)
return
# process left child
if len(left) if (len(set([row[-1] for row in left])) == 1):
—> node[‘left’] = to_terminal(left)
—> else:
node[‘left’] = get_split(left)
split(node[‘left’], max_depth, min_size, depth+1)
# process right child
if len(right) if (len(set([row[-1] for row in right])) == 1):
—> node[‘right’] = to_terminal(right)
—> else:
node[‘right’] = get_split(right)
split(node[‘right’], max_depth, min_size, depth+1)
Hi, first of all, this is an excellent post. I want to implement decision trees from scratch as well. I need a detailed source, but not a off-the-shelf implementation like this source. where can I find a detailed source about decision trees? So far ive looked at books on deep learning(e.g. the one from Goodfellow) but they dont go into implementation details.
Hi Onat…The following is a great starting point:
https://www.hackerearth.com/practice/machine-learning/machine-learning-algorithms/ml-decision-tree/tutorial/
As always Jason your website pops up when I’m looking for the python implementation of a complicated subject. After reading the code now and understanding more of what this implementation but it also creates more questions.
How to select and evaluate split points in a training dataset = This part makes sense in that it will provide statistical feedback to evaluate and then return a data split recommendation while training a model?
How to recursively build a decision tree from multiple splits. = This part is less clear, in your other post-https://machinelearningmastery.com/use-classification-machine-learning-algorithms-weka/ you definitively show a decision tree. For this post Decision Tree I’m not understanding how it builds a tree. On page 10 of your Statistical Methods for Machine Learning book (which is incredible) you briefly mention decision trees but while you mention
decision9 times in the book this post has more detail so I thought to ask.How to apply the CART algorithm to a real-world classification predictive modeling problem. = This mostly makes sense, I’ll need to play with it more but you saved me a ton of time. When I get closer I’d like to buy the associated ML book, which of your books is most relevant to decision science or decision trees? https://machinelearningmastery.com/products/
Nice website and example!
A question that hit me: shouldn’t it be
def to_terminal_(group):
outcomes = [row[-1] for row in group]
return max(outcomes, key=outcomes.count)
instead of
def to_terminal_(group):
outcomes = [row[-1] for row in group]
return max(set(outcomes), key=outcomes.count)
I would have say that using
set(outcomes)instead ofoutcomeas first argument ofmaxwould screw the result. Am I correct or did I miss something?Hi, first thank you so much for the explanation!
While I understood the decision trees, I had no idea
how to actually implement them. This is the best explanation
I found 🙂
I do have one question about how to tree is build.
While I understand the split function, I don’t understand what it returns,
or how it could change the root?
could anyone maybe explain?:)
Hi Myrthe…The following resource should add clarity:
https://www.analyticsvidhya.com/blog/2020/06/4-ways-split-decision-tree/#:~:text=Steps%20to%20split%20a%20decision%20tree%20using%20Information%20Gain%3A,entropy%20or%20highest%20information%20gain
Hi Jason
What is the notion of groups meaning? How do you relate input feature attributes to this notion of groups? It is confusing. Kindly help with this!!
Hi Tarun…The following resource may be of interest:
https://scikit-learn.org/stable/modules/tree.html