Resampling methods are designed to add or remove examples from the training dataset in order to change the class distribution.
Once the class distributions are more balanced, the suite of standard machine learning classification algorithms can be fit successfully on the transformed datasets.
Oversampling methods duplicate or create new synthetic examples in the minority class, whereas undersampling methods delete or merge examples in the majority class. Both types of resampling can be effective when used in isolation, although can be more effective when both types of methods are used together.
In this tutorial, you will discover how to combine oversampling and undersampling techniques for imbalanced classification.
After completing this tutorial, you will know:
How to define a sequence of oversampling and undersampling methods to be applied to a training dataset or when evaluating a classifier model.
How to manually combine oversampling and undersampling methods for imbalanced classification.
How to use pre-defined and well-performing combinations of resampling methods for imbalanced classification.
Kick-start your project with my new book Imbalanced Classification with Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Updated Jan/2021: Updated links for API documentation.
Combine Oversampling and Undersampling for Imbalanced Classification Photo by Radek Kucharski, some rights reserved.
Tutorial Overview
This tutorial is divided into four parts; they are:
Binary Test Problem and Decision Tree Model
Imbalanced-Learn Library
Manually Combine Over- and Undersampling Methods
Manually Combine Random Oversampling and Undersampling
Manually Combine SMOTE and Random Undersampling
Use Predefined Combinations of Resampling Methods
Combination of SMOTE and Tomek Links Undersampling
Combination of SMOTE and Edited Nearest Neighbors Undersampling
Binary Test Problem and Decision Tree Model
Before we dive into combinations of oversampling and undersampling methods, let’s define a synthetic dataset and model.
We can define a synthetic binary classification dataset using the make_classification() function from the scikit-learn library.
For example, we can create 10,000 examples with two input variables and a 1:100 class distribution as follows:
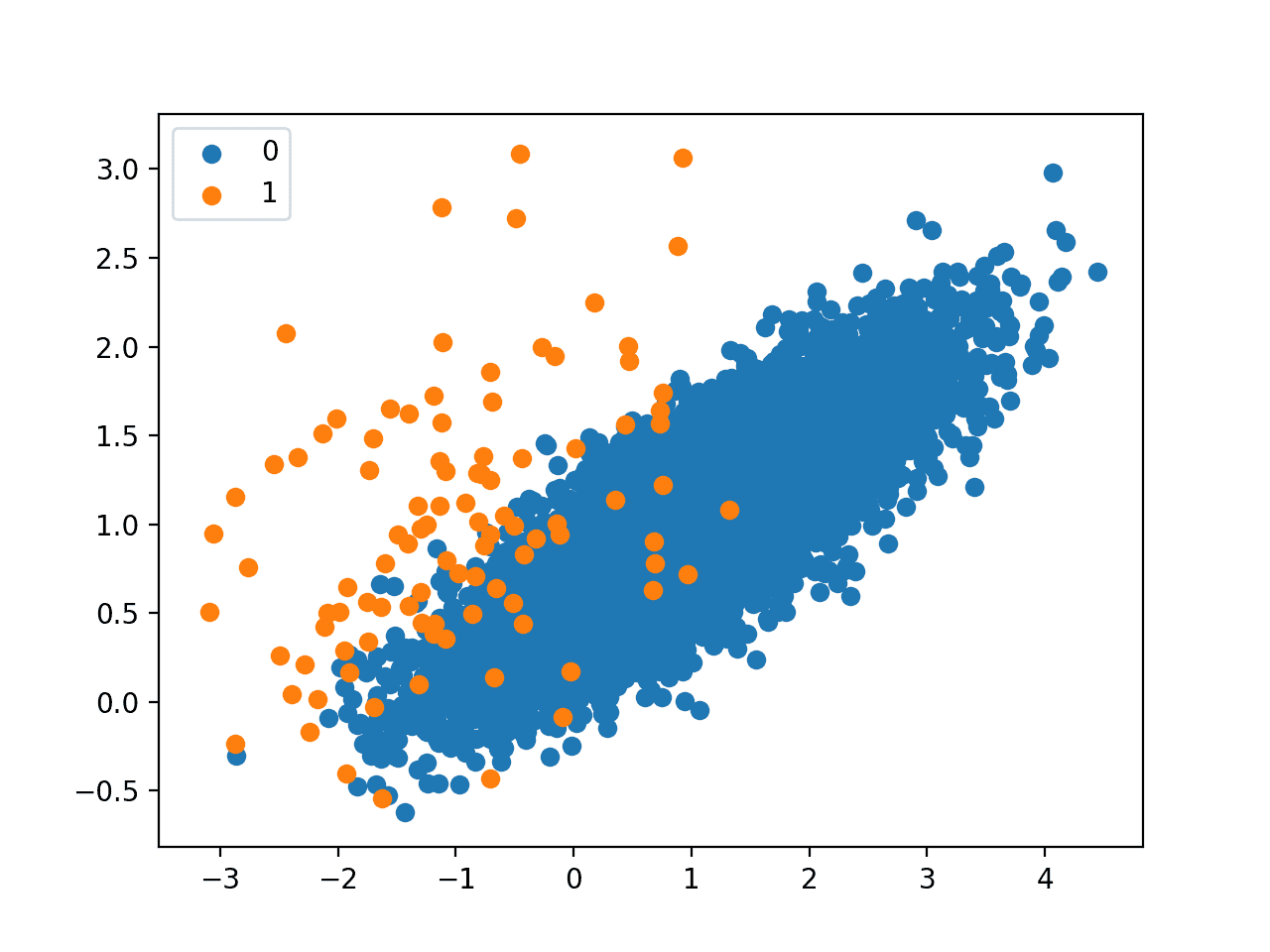
We can then create a scatter plot of the dataset via the scatter() Matplotlib function to understand the spatial relationship of the examples in each class and their imbalance.
Running the example first summarizes the class distribution, showing an approximate 1:100 class distribution with about 10,000 examples with class 0 and 100 with class 1.
1
Counter({0: 9900, 1: 100})
Next, a scatter plot is created showing all of the examples in the dataset. We can see a large mass of examples for class 0 (blue) and a small number of examples for class 1 (orange).
We can also see that the classes overlap with some examples from class 1 clearly within the part of the feature space that belongs to class 0.
Scatter Plot of Imbalanced Classification Dataset
We can fit a DecisionTreeClassifier model on this dataset. It is a good model to test because it is sensitive to the class distribution in the training dataset.
The ROC area under curve (AUC) measure can be used to estimate the performance of the model. It can be optimistic for severely imbalanced datasets, although it does correctly show relative improvements in model performance.
Running the example reports the average ROC AUC for the decision tree on the dataset over three repeats of 10-fold cross-validation (e.g. average over 30 different model evaluations).
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this example, you can see that the model achieved a ROC AUC of about 0.76. This provides a baseline on this dataset, which we can use to compare different combinations of over and under sampling methods on the training dataset.
1
Mean ROC AUC: 0.762
Now that we have a test problem, model, and test harness, let’s look at manual combinations of oversampling and undersampling methods.
Want to Get Started With Imbalance Classification?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Imbalanced-Learn Library
In these examples, we will use the implementations provided by the imbalanced-learn Python library, which can be installed via pip as follows:
1
sudo pip install imbalanced-learn
You can confirm that the installation was successful by printing the version of the installed library:
1
2
3
# check version number
import imblearn
print(imblearn.__version__)
Running the example will print the version number of the installed library; for example:
1
0.5.0
Manually Combine Over- and Undersampling Methods
The imbalanced-learn Python library provides a range of resampling techniques, as well as a Pipeline class that can be used to create a combined sequence of resampling methods to apply to a dataset.
We can use the Pipeline to construct a sequence of oversampling and undersampling techniques to apply to a dataset. For example:
1
2
3
4
5
# define resampling
over=...
under=...
# define pipeline
pipeline=Pipeline(steps=[('o',over),('u',under)])
This pipeline first applies an oversampling technique to a dataset, then applies undersampling to the output of the oversampling transform before returning the final outcome. It allows transforms to be stacked or applied in sequence on a dataset.
The pipeline can then be used to transform a dataset; for example:
Alternately, a model can be added as the last step in the pipeline.
This allows the pipeline to be treated as a model. When it is fit on a training dataset, the transforms are first applied to the training dataset, then the transformed dataset is provided to the model so that it can develop a fit.
Recall that the resampling is only applied to the training dataset, not the test dataset.
When used in k-fold cross-validation, the entire sequence of transforms and fit is applied on each training dataset comprised of cross-validation folds. This is important as both the transforms and fit are performed without knowledge of the holdout set, which avoids data leakage. For example:
Now that we know how to manually combine resampling methods, let’s look at two examples.
Manually Combine Random Oversampling and Undersampling
A good starting point for combining resampling techniques is to start with random or naive methods.
Although they are simple, and often ineffective when applied in isolation, they can be effective when combined.
Random oversampling involves randomly duplicating examples in the minority class, whereas random undersampling involves randomly deleting examples from the majority class.
As these two transforms are performed on separate classes, the order in which they are applied to the training dataset does not matter.
The example below defines a pipeline that first oversamples the minority class to 10 percent of the majority class, under samples the majority class to 50 percent more than the minority class, and then fits a decision tree model.
Running the example evaluates the system of transforms and the model and summarizes the performance as the mean ROC AUC.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see a modest lift in ROC AUC performance from 0.76 with no transforms to about 0.81 with random over- and undersampling.
1
Mean ROC AUC: 0.814
Manually Combine SMOTE and Random Undersampling
We are not limited to using random resampling methods.
Perhaps the most popular oversampling method is the Synthetic Minority Oversampling Technique, or SMOTE for short.
SMOTE works by selecting examples that are close in the feature space, drawing a line between the examples in the feature space and drawing a new sample as a point along that line.
The authors of the technique recommend using SMOTE on the minority class, followed by an undersampling technique on the majority class.
The combination of SMOTE and under-sampling performs better than plain under-sampling.
We can combine SMOTE with RandomUnderSampler. Again, the order in which these procedures are applied does not matter as they are performed on different subsets of the training dataset.
The pipeline below implements this combination, first applying SMOTE to bring the minority class distribution to 10 percent of the majority class, then using RandomUnderSampler to bring the majority class down to 50 percent more than the minority class before fitting a DecisionTreeClassifier.
1
2
3
4
5
6
7
...
# define model
model=DecisionTreeClassifier()
# define pipeline
over=SMOTE(sampling_strategy=0.1)
under=RandomUnderSampler(sampling_strategy=0.5)
steps=[('o',over),('u',under),('m',model)]
The example below evaluates this combination on our imbalanced binary classification problem.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# combination of SMOTE and random undersampling for imbalanced classification
from numpy import mean
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.tree import DecisionTreeClassifier
from imblearn.pipeline import Pipeline
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import RandomUnderSampler
Running the example evaluates the system of transforms and the model and summarizes the performance as the mean ROC AUC.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see another list in ROC AUC performance from about 0.81 to about 0.83.
1
Mean ROC AUC: 0.833
Use Predefined Combinations of Resampling Methods
There are combinations of oversampling and undersampling methods that have proven effective and together may be considered resampling techniques.
Two examples are the combination of SMOTE with Tomek Links undersampling and SMOTE with Edited Nearest Neighbors undersampling.
The imbalanced-learn Python library provides implementations for both of these combinations directly. Let’s take a closer look at each in turn.
Combination of SMOTE and Tomek Links Undersampling
SMOTE is an oversampling method that synthesizes new plausible examples in the minority class.
Tomek Links refers to a method for identifying pairs of nearest neighbors in a dataset that have different classes. Removing one or both of the examples in these pairs (such as the examples in the majority class) has the effect of making the decision boundary in the training dataset less noisy or ambiguous.
Specifically, first the SMOTE method is applied to oversample the minority class to a balanced distribution, then examples in Tomek Links from the majority classes are identified and removed.
In this work, only majority class examples that participate of a Tomek link were removed, since minority class examples were considered too rare to be discarded. […] In our work, as minority class examples were artificially created and the data sets are currently balanced, then both majority and minority class examples that form a Tomek link, are removed.
The SMOTE configuration can be set via the “smote” argument and takes a configured SMOTE instance. The Tomek Links configuration can be set via the “tomek” argument and takes a configured TomekLinks object.
… we propose applying Tomek links to the over-sampled training set as a data cleaning method. Thus, instead of removing only the majority class examples that form Tomek links, examples from both classes are removed.
Alternately, we can configure the combination to only remove links from the majority class as described in the 2003 paper by specifying the “tomek” argument with an instance of TomekLinks with the “sampling_strategy” argument set to only undersample the ‘majority‘ class; for example:
Running the example evaluates the system of transforms and the model and summarizes the performance as the mean ROC AUC.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, it seems that this combined resampling strategy does not offer a benefit for this model on this dataset.
1
Mean ROC AUC: 0.815
Combination of SMOTE and Edited Nearest Neighbors Undersampling
SMOTE may be the most popular oversampling technique and can be combined with many different undersampling techniques.
Another very popular undersampling method is the Edited Nearest Neighbors, or ENN, rule. This rule involves using k=3 nearest neighbors to locate those examples in a dataset that are misclassified and that are then removed. It can be applied to all classes or just those examples in the majority class.
Regarding this final combination, the authors comment that ENN is more aggressive at downsampling the majority class than Tomek Links, providing more in-depth cleaning. They apply the method, removing examples from both the majority and minority classes.
… ENN is used to remove examples from both classes. Thus, any example that is misclassified by its three nearest neighbors is removed from the training set.
This can be implemented via the SMOTEENN class in the imbalanced-learn library.
1
2
3
...
# define resampling
resample=SMOTEENN()
The SMOTE configuration can be set as a SMOTE object via the “smote” argument, and the ENN configuration can be set via the EditedNearestNeighbours object via the “enn” argument. SMOTE defaults to balancing the distribution, followed by ENN that by default removes misclassified examples from all classes.
We could change the ENN to only remove examples from the majority class by setting the “enn” argument to an EditedNearestNeighbours instance with sampling_strategy argument set to ‘majority‘.
Running the example evaluates the system of transforms and the model and summarizes the performance as the mean ROC AUC.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we see a further lift in performance over SMOTE with the random undersampling method from about 0.81 to about 0.85.
1
Mean ROC AUC: 0.856
This result highlights that editing the oversampled minority class may also be an important consideration that could easily be overlooked.
This was the same finding in the 2004 paper where the authors discover that SMOTE with Tomek Links and SMOTE with ENN perform well across a range of datasets.
Our results show that the over-sampling methods in general, and Smote + Tomek and Smote + ENN (two of the methods proposed in this work) in particular for data sets with few positive (minority) examples, provided very good results in practice.
It provides self-study tutorials and end-to-end projects on: Performance Metrics, Undersampling Methods, SMOTE, Threshold Moving, Probability Calibration, Cost-Sensitive Algorithms
and much more...
Bring Imbalanced Classification Methods to Your Machine Learning Projects
Thanks for your answer, I get it now, this is just a random synthetic dataset without any particular pattern to learn, so random sampling is the method that best preserves the distribution. If the dataset had non-random patterns with some noise added then some of the resampling techniques may help to sharpen the class boundaries and help the classifier to learn the patterns.
You mentioned the undersampling and oversampling apply to training data set only, not the validation and testing sets. In the cross validation pipeline, does the python package ignore the sampling procedure in validation set? See below
##############################################
# combination of random oversampling and undersampling for imbalanced classification
from numpy import mean
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.tree import DecisionTreeClassifier
from imblearn.pipeline import Pipeline
from imblearn.over_sampling import RandomOverSampler
from imblearn.under_sampling import RandomUnderSampler
# generate dataset
X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1)
# define model
model = DecisionTreeClassifier()
# define resampling
over = RandomOverSampler(sampling_strategy=0.1)
under = RandomUnderSampler(sampling_strategy=0.5)
# define pipeline
pipeline = Pipeline(steps=[(‘o’, over), (‘u’, under), (‘m’, model)])
# define evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# evaluate model
scores = cross_val_score(pipeline, X, y, scoring=’roc_auc’, cv=cv, n_jobs=-1)
# summarize performance
print(‘Mean ROC AUC: %.3f’ % mean(scores))
good work!
As SMOTE is useful in the case where we have imbalanced dataset….
If we have balanced data equally, e.g, 10 samples for each class and we want to increase them synthetically upto 20 sample for each class.
Is there any method in machine learning which can be use to oversample the balanced dataset?
Sorry Jason please correct me if I am wrong.
I read in various papers that SMOTE can be only use in that case when we imbalanced dataset?
Is it a fair to use SMOTE for small balanced data?
Group positives and negative classes together when calculating a metric or sampling the data. You need to tell the algorithms what are the “positive” cases.
Thank you very much!
Let’s assume I have 3 classes. I’ll have 3 combinations now (i.e) class_1 as positive cases and class_2,class_3 as negative cases, so on and so forth.
Is my understanding correct?
I have an imbalanced medical dataset with 245 minor class, 760 major class, and the data of categorical type. It resulted in bad classification performances. I would like to improve the classification and use the feature selection.
So I used chi2 then applied an EditedNearestNeighbours, I have obtained very good improvement.
Now, I wonder, is it true if I use the EditedNearestNeighbours before the feature selection?
Your last example uses pipelines to implement SMOTEEN(), but when I run the code, it gives me TypeError: All intermediate steps should be transformers and implement fit and transform or be the string ‘passthrough’ ‘SMOTEENN()’ (type ) doesn’t
Hello sir,
Here you have used
model = DecisionTreeClassifier()
# define pipeline
over = SMOTE(sampling_strategy=0.1)
under = RandomUnderSampler(sampling_strategy=0.5)
steps = [(‘o’, over), (‘u’, under), (‘m’, model)]
pipeline = Pipeline(steps=steps)
# define evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) and then
scores = cross_val_score(pipeline, X, y, scoring=’roc_auc’, cv=cv, n_jobs=-1)
But if I want to apply RandomUnderSampler, RepeatedStratifiedFold on training dataset and model decision tree then how to apply ?
Good stuff here. If you wanted to use these over/under sampling techniques in a pipeline that you fit with GridsearchCV, ideas on how to keep the over/under sampling techniques from being applied when testing the performance on a test/generalization dataset? Given that GridsearchCV is going to fit a estimator/pipeline to the whole training dataset and then when we apply predict or score for that estimator/pipeline to the holdout test set, it will apply the same transformations in the pipeline to the test set.
I don’t believe you want to over/under sample the holdout/test set though, correct? I was understanding from your blog that you want to train the model on the oversampled/undersampled training set, but test against a dataset that has a normal distribution of classes. Because that is what the model will be working with in operation.
Very interesting article. Is it possible to do the combined oversampling and undersampling (eg: SMOTE+ Random Undersampling) in R? If yes, can you please make article on how to do the hybrid sampling in R. Really appreciate it.
Thank you.
“Recall that the resampling is only applied to the training dataset, not the test dataset.”
Why do we not balance the test data and only balance the train data?
If we have balanced the train data and not the test data, do we need to evaluate the model on metrics designed for imbalanced datasets such as G-mean, ROAUC etc. as our test data is still not balanced and we have few instances of minority class in the test data.








Excellent overview of resampling technique. Thanks!
I also tried just plain under = RandomUnderSampler(sampling_strategy=0.5)
and I got the best score:
Mean ROC AUC: 0.864
So it looks like you always need to try many things to see what works best on your dataset.
Do you want have any comment on why random undersampliing seem to work works best in this dataset?
Regards
Nice work!
No, the dataset is just for demonstration purposes – e.g. to show how to use the method, we’re not trying to get the best results.
Thanks for your answer, I get it now, this is just a random synthetic dataset without any particular pattern to learn, so random sampling is the method that best preserves the distribution. If the dataset had non-random patterns with some noise added then some of the resampling techniques may help to sharpen the class boundaries and help the classifier to learn the patterns.
Hi Jason,
You mentioned the undersampling and oversampling apply to training data set only, not the validation and testing sets. In the cross validation pipeline, does the python package ignore the sampling procedure in validation set? See below
##############################################
# combination of random oversampling and undersampling for imbalanced classification
from numpy import mean
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.tree import DecisionTreeClassifier
from imblearn.pipeline import Pipeline
from imblearn.over_sampling import RandomOverSampler
from imblearn.under_sampling import RandomUnderSampler
# generate dataset
X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1)
# define model
model = DecisionTreeClassifier()
# define resampling
over = RandomOverSampler(sampling_strategy=0.1)
under = RandomUnderSampler(sampling_strategy=0.5)
# define pipeline
pipeline = Pipeline(steps=[(‘o’, over), (‘u’, under), (‘m’, model)])
# define evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
# evaluate model
scores = cross_val_score(pipeline, X, y, scoring=’roc_auc’, cv=cv, n_jobs=-1)
# summarize performance
print(‘Mean ROC AUC: %.3f’ % mean(scores))
Yes.
good work!
As SMOTE is useful in the case where we have imbalanced dataset….
If we have balanced data equally, e.g, 10 samples for each class and we want to increase them synthetically upto 20 sample for each class.
Is there any method in machine learning which can be use to oversample the balanced dataset?
SMOTE can be useful, but not always, and sometimes other methods perform much better. Depends on the dataset.
Yes, you can force an oversampling method to create more synthetic samples. See the API documentation.
Sorry Jason please correct me if I am wrong.
I read in various papers that SMOTE can be only use in that case when we imbalanced dataset?
Is it a fair to use SMOTE for small balanced data?
Not really. Perhaps try it and see if it improves skill on your dataset.
Thank you for your work, it’s great!
I do have a few questions, though,
Is it preferable or not to scale up the data before using these techniques?
To what extent do they generate noise?
Thank you in advance,
Marine
It is a good idea to scale the data prior to sampling as often a knn model is used as part of the sampling process.
I have a couple of questions:
1. How do we calibrate the probabilities for these combinations of sampling. There are 2 methods mentioned for undersampling and oversampling separately: http://www.data-mining-blog.com/tips-and-tutorials/overrepresentation-oversampling/ and https://www3.nd.edu/~dial/publications/dalpozzolo2015calibrating.pdf
2. Do we threshold differently to identify classes
Calibration is performed with a validation set without data sampling.
Thresholding is performed after calibration.
Thanks! I am assuming the same calibration methods (isotonic/sigmoid) deal with the bias from sampling?
The bias in the data would have been corrected via data sampling prior to fitting the model.
How do I use Smote with calibratedclassifiercv…..given I dont have a validation data?
You can use a portion of your training set as a validation set.
Hello Jason,
What should I do to accomodate multiple classes from the dataset?
Group positives and negative classes together when calculating a metric or sampling the data. You need to tell the algorithms what are the “positive” cases.
Thank you very much!
Let’s assume I have 3 classes. I’ll have 3 combinations now (i.e) class_1 as positive cases and class_2,class_3 as negative cases, so on and so forth.
Is my understanding correct?
Not quite, it would be something like
Positive Classes: 0, 1
Negative Classes: 2
For one model/evaluation metric.
Hi Jason
Thank you for your great work
I have an imbalanced medical dataset with 245 minor class, 760 major class, and the data of categorical type. It resulted in bad classification performances. I would like to improve the classification and use the feature selection.
So I used chi2 then applied an EditedNearestNeighbours, I have obtained very good improvement.
Now, I wonder, is it true if I use the EditedNearestNeighbours before the feature selection?
Feature selection might be better as a first step.
I recommend testing a suite of approaches in order to discover what works best, see this:
https://machinelearningmastery.com/framework-for-imbalanced-classification-projects/
Your last example uses pipelines to implement SMOTEEN(), but when I run the code, it gives me TypeError: All intermediate steps should be transformers and implement fit and transform or be the string ‘passthrough’ ‘SMOTEENN()’ (type ) doesn’t
I have found my mistake. I used sklearn piplines. One more question, can I standardize data after resampling?
Happy to hear it.
Yes, try it and see if it makes a difference before or after the sampling.
Make sure you are using the Pipeline class from the imbalanced-learn project, e.g. ensure you copy all of the code from the complete code listing.
“…then using RandomUnderSampler to bring the minority class down to 50 percent more than the minority class before fitting a DecisionTreeClassifier.”
I think you meant to say,
“…then using RandomUnderSampler to bring the majority class down to 50 percent more than the minority class before fitting a DecisionTreeClassifier.”
Thanks! Fixed.
Hi.
I wrote the following code, but in the end all the binary values became continuous.
thank you for your help…
from imblearn.pipeline import Pipeline
pipeline1 = Pipeline([(‘impute’, SimpleImputer()),(‘scaler’,MinMaxScaler()), (‘balance’, SMOTE())])
SMOTE assumes inputs are continuous, for categorical inputs or mixed inputs you must use SMOTENC:
https://imbalanced-learn.readthedocs.io/en/stable/generated/imblearn.over_sampling.SMOTENC.html
Jason,
What’s your take on TF-IDF Vectorizer?
Should someone use TF_IDF on whole corpus then train, test split or
train test split and then do tf_vectorizer.fit_transform(train) and tf_vectorizer.transform(test).
So Q is: TF-IDF first on whole data then train test split or train test split and then TF_IDF?
See this tutorial:
https://machinelearningmastery.com/prepare-text-data-machine-learning-scikit-learn/
This doesn’t answer the Q I asked. Should we to TF-IDF before train test split or after that.
And if after should it only be on train data then
TFIDF like other transforms should be fit on training data, then applied to train and test datasets.
You can learn about the proper procedure/order for applying data preparation methods to avoid data leakage here:
https://machinelearningmastery.com/data-preparation-without-data-leakage/
Hi, Jason!
Wonderful article!
Just one question:
Should PCA be applied before or after a resampling technique (smote, random undersampling, random oversampling…) ?
Thank you in advance!
Thanks.
Good question, perhaps experiment with both approaches and see what works best for your data and model.
One of the best tutorial I’ve read. Thanks !
Thanks!
Hello sir,
Here you have used
model = DecisionTreeClassifier()
# define pipeline
over = SMOTE(sampling_strategy=0.1)
under = RandomUnderSampler(sampling_strategy=0.5)
steps = [(‘o’, over), (‘u’, under), (‘m’, model)]
pipeline = Pipeline(steps=steps)
# define evaluation procedure
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) and then
scores = cross_val_score(pipeline, X, y, scoring=’roc_auc’, cv=cv, n_jobs=-1)
But if I want to apply RandomUnderSampler, RepeatedStratifiedFold on training dataset and model decision tree then how to apply ?
The above example does exactly this.
Perhaps I don’t understand the problem you’re having?
Yes thank you , in cross validation we do same thing.
Jason,
Good stuff here. If you wanted to use these over/under sampling techniques in a pipeline that you fit with GridsearchCV, ideas on how to keep the over/under sampling techniques from being applied when testing the performance on a test/generalization dataset? Given that GridsearchCV is going to fit a estimator/pipeline to the whole training dataset and then when we apply predict or score for that estimator/pipeline to the holdout test set, it will apply the same transformations in the pipeline to the test set.
Thanks
Jeff
Yes, the pipeline will ensure the methods are only ever fit on the internal training set and applied on the internal test.
That is the major benefit of using a pipeline.
I don’t believe you want to over/under sample the holdout/test set though, correct? I was understanding from your blog that you want to train the model on the oversampled/undersampled training set, but test against a dataset that has a normal distribution of classes. Because that is what the model will be working with in operation.
Thanks
Jeff
Yes, over/under sampling is not applied to test/hold out data. Pipelines are aware of this.
If you fit/apply pipelines manually you must take this into account.
In one of the lines its written -“SMOTE is an oversampling method that synthesizes new plausible examples in the majority class.”
Correct me if I am wrong, should it not be minority class?
As per the documentation in microsoft
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/smote#:~:text=SMOTE%20stands%20for%20Synthetic%20Minority,dataset%20in%20a%20balanced%20way.&text=SMOTE%20takes%20the%20entire%20dataset,of%20only%20the%20minority%20cases.
it is given as-
“The module works by generating new instances from existing minority cases that you supply as input. This implementation of SMOTE does not change the number of majority cases.”
Yes, the minority class, it’s a typo. Fixed.
Learn more about smote here:
https://machinelearningmastery.com/smote-oversampling-for-imbalanced-classification/
Hi Jason!
Very interesting article. Is it possible to do the combined oversampling and undersampling (eg: SMOTE+ Random Undersampling) in R? If yes, can you please make article on how to do the hybrid sampling in R. Really appreciate it.
Thank you.
Hello…Thank you for the recommendation! It will be considered for content going forward.
Hi, I had a confusion regarding this statement.
“Recall that the resampling is only applied to the training dataset, not the test dataset.”
Why do we not balance the test data and only balance the train data?
If we have balanced the train data and not the test data, do we need to evaluate the model on metrics designed for imbalanced datasets such as G-mean, ROAUC etc. as our test data is still not balanced and we have few instances of minority class in the test data.
Hi Zaa…The following resource my be of interest to you:
https://towardsdatascience.com/the-complete-guide-to-resampling-methods-and-regularization-in-python-5037f4f8ae23