Ensemble learning is a general meta approach to machine learning that seeks better predictive performance by combining the predictions from multiple models.
Although there are a seemingly unlimited number of ensembles that you can develop for your predictive modeling problem, there are three methods that dominate the field of ensemble learning. So much so, that rather than algorithms per se, each is a field of study that has spawned many more specialized methods.
The three main classes of ensemble learning methods are bagging, stacking, and boosting, and it is important to both have a detailed understanding of each method and to consider them on your predictive modeling project.
But, before that, you need a gentle introduction to these approaches and the key ideas behind each method prior to layering on math and code.
In this tutorial, you will discover the three standard ensemble learning techniques for machine learning.
After completing this tutorial, you will know:
Bagging involves fitting many decision trees on different samples of the same dataset and averaging the predictions.
Stacking involves fitting many different models types on the same data and using another model to learn how to best combine the predictions.
Boosting involves adding ensemble members sequentially that correct the predictions made by prior models and outputs a weighted average of the predictions.
Kick-start your project with my new book Ensemble Learning Algorithms With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
A Gentle Introduction to Ensemble Learning Algorithms Photo by Rajiv Bhuttan, some rights reserved.
Tutorial Overview
This tutorial is divided into four parts; they are:
Standard Ensemble Learning Strategies
Bagging Ensemble Learning
Stacking Ensemble Learning
Boosting Ensemble Learning
Standard Ensemble Learning Strategies
Ensemble learning refers to algorithms that combine the predictions from two or more models.
Although there is nearly an unlimited number of ways that this can be achieved, there are perhaps three classes of ensemble learning techniques that are most commonly discussed and used in practice. Their popularity is due in large part to their ease of implementation and success on a wide range of predictive modeling problems.
A rich collection of ensemble-based classifiers have been developed over the last several years. However, many of these are some variation of the select few well- established algorithms whose capabilities have also been extensively tested and widely reported.
Given their wide use, we can refer to them as “standard” ensemble learning strategies; they are:
Bagging.
Stacking.
Boosting.
There is an algorithm that describes each approach, although more importantly, the success of each approach has spawned a myriad of extensions and related techniques. As such, it is more useful to describe each as a class of techniques or standard approaches to ensemble learning.
Rather than dive into the specifics of each method, it is useful to step through, summarize, and contrast each approach. It is also important to remember that although discussion and use of these methods are pervasive, these three methods alone do not define the extent of ensemble learning.
Next, let’s take a closer look at bagging.
Bagging Ensemble Learning
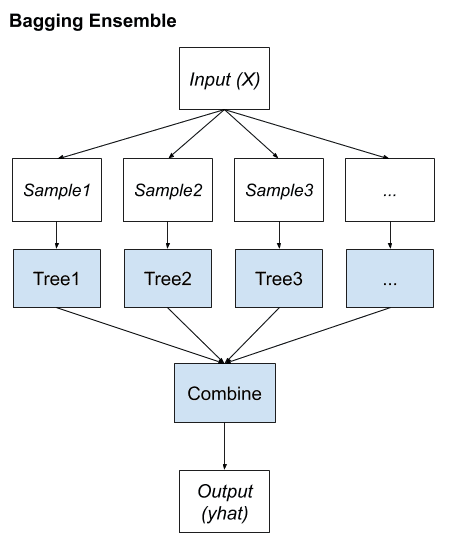
Bootstrap aggregation, or bagging for short, is an ensemble learning method that seeks a diverse group of ensemble members by varying the training data.
The name Bagging came from the abbreviation of Bootstrap AGGregatING. As the name implies, the two key ingredients of Bagging are bootstrap and aggregation.
This typically involves using a single machine learning algorithm, almost always an unpruned decision tree, and training each model on a different sample of the same training dataset. The predictions made by the ensemble members are then combined using simple statistics, such as voting or averaging.
The diversity in the ensemble is ensured by the variations within the bootstrapped replicas on which each classifier is trained, as well as by using a relatively weak classifier whose decision boundaries measurably vary with respect to relatively small perturbations in the training data.
Key to the method is the manner in which each sample of the dataset is prepared to train ensemble members. Each model gets its own unique sample of the dataset.
Examples (rows) are drawn from the dataset at random, although with replacement.
Bagging adopts the bootstrap distribution for generating different base learners. In other words, it applies bootstrap sampling to obtain the data subsets for training the base learners.
Replacement means that if a row is selected, it is returned to the training dataset for potential re-selection in the same training dataset. This means that a row of data may be selected zero, one, or multiple times for a given training dataset.
This is called a bootstrap sample. It is a technique often used in statistics with small datasets to estimate the statistical value of a data sample. By preparing multiple different bootstrap samples and estimating a statistical quantity and calculating the mean of the estimates, a better overall estimate of the desired quantity can be achieved than simply estimating from the dataset directly.
In the same manner, multiple different training datasets can be prepared, used to estimate a predictive model, and make predictions. Averaging the predictions across the models typically results in better predictions than a single model fit on the training dataset directly.
We can summarize the key elements of bagging as follows:
Bootstrap samples of the training dataset.
Unpruned decision trees fit on each sample.
Simple voting or averaging of predictions.
In summary, the contribution of bagging is in the varying of the training data used to fit each ensemble member, which, in turn, results in skillful but different models.
Bagging Ensemble
It is a general approach and easily extended. For example, more changes to the training dataset can be introduced, the algorithm fit on the training data can be replaced, and the mechanism used to combine predictions can be modified.
Many popular ensemble algorithms are based on this approach, including:
Bagged Decision Trees (canonical bagging)
Random Forest
Extra Trees
Next, let’s take a closer look at stacking.
Want to Get Started With Ensemble Learning?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Stacking Ensemble Learning
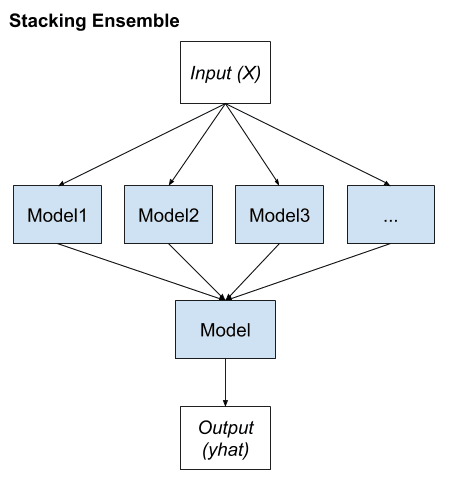
Stacked Generalization, or stacking for short, is an ensemble method that seeks a diverse group of members by varying the model types fit on the training data and using a model to combine predictions.
Stacking is a general procedure where a learner is trained to combine the individual learners. Here, the individual learners are called the first-level learners, while the combiner is called the second-level learner, or meta-learner.
Stacking has its own nomenclature where ensemble members are referred to as level-0 models and the model that is used to combine the predictions is referred to as a level-1 model.
The two-level hierarchy of models is the most common approach, although more layers of models can be used. For example, instead of a single level-1 model, we might have 3 or 5 level-1 models and a single level-2 model that combines the predictions of level-1 models in order to make a prediction.
Stacking is probably the most-popular meta-learning technique. By using a meta-learner, this method tries to induce which classifiers are reliable and which are not.
Any machine learning model can be used to aggregate the predictions, although it is common to use a linear model, such as linear regression for regression and logistic regression for binary classification. This encourages the complexity of the model to reside at the lower-level ensemble member models and simple models to learn how to harness the variety of predictions made.
Using trainable combiners, it is possible to determine which classifiers are likely to be successful in which part of the feature space and combine them accordingly.
We can summarize the key elements of stacking as follows:
Unchanged training dataset.
Different machine learning algorithms for each ensemble member.
Machine learning model to learn how to best combine predictions.
Diversity comes from the different machine learning models used as ensemble members.
As such, it is desirable to use a suite of models that are learned or constructed in very different ways, ensuring that they make different assumptions and, in turn, have less correlated prediction errors.
Stacking Ensemble
Many popular ensemble algorithms are based on this approach, including:
Stacked Models (canonical stacking)
Blending
Super Ensemble
Next, let’s take a closer look at boosting.
Boosting Ensemble Learning
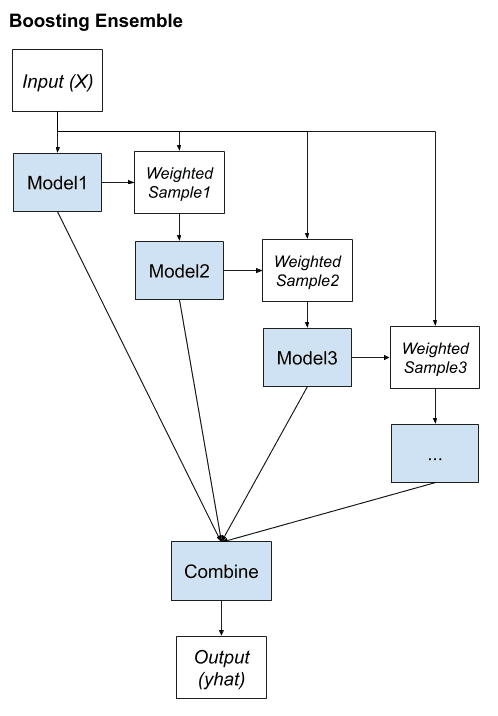
Boosting is an ensemble method that seeks to change the training data to focus attention on examples that previous fit models on the training dataset have gotten wrong.
In boosting, […] the training dataset for each subsequent classifier increasingly focuses on instances misclassified by previously generated classifiers.
The key property of boosting ensembles is the idea of correcting prediction errors. The models are fit and added to the ensemble sequentially such that the second model attempts to correct the predictions of the first model, the third corrects the second model, and so on.
This typically involves the use of very simple decision trees that only make a single or a few decisions, referred to in boosting as weak learners. The predictions of the weak learners are combined using simple voting or averaging, although the contributions are weighed proportional to their performance or capability. The objective is to develop a so-called “strong-learner” from many purpose-built “weak-learners.”
… an iterative approach for generating a strong classifier, one that is capable of achieving arbitrarily low training error, from an ensemble of weak classifiers, each of which can barely do better than random guessing.
Typically, the training dataset is left unchanged and instead, the learning algorithm is modified to pay more or less attention to specific examples (rows of data) based on whether they have been predicted correctly or incorrectly by previously added ensemble members. For example, the rows of data can be weighed to indicate the amount of focus a learning algorithm must give while learning the model.
We can summarize the key elements of boosting as follows:
Bias training data toward those examples that are hard to predict.
Iteratively add ensemble members to correct predictions of prior models.
Combine predictions using a weighted average of models.
The idea of combining many weak learners into strong learners was first proposed theoretically and many algorithms were proposed with little success. It was not until the Adaptive Boosting (AdaBoost) algorithm was developed that boosting was demonstrated as an effective ensemble method.
The term boosting refers to a family of algorithms that are able to convert weak learners to strong learners.
Since AdaBoost, many boosting methods have been developed and some, like stochastic gradient boosting, may be among the most effective techniques for classification and regression on tabular (structured) data.
Boosting Ensemble
To summarize, many popular ensemble algorithms are based on this approach, including:
AdaBoost (canonical boosting)
Gradient Boosting Machines
Stochastic Gradient Boosting (XGBoost and similar)
This completes our tour of the standard ensemble learning techniques.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
In this tutorial, you discovered the three standard ensemble learning techniques for machine learning.
Specifically, you learned:
Bagging involves fitting many decision trees on different samples of the same dataset and averaging the predictions.
Stacking involves fitting many different models types on the same data and using another model to learn how to best combine the predictions.
Boosting involves adding ensemble members sequentially that correct the predictions made by prior models and outputs a weighted average of the predictions.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Hi, Thanks for the explanation of each method. It was very helpful. I am a bit confused about weighted samples in boosting ensemble learning. Wouldn’t giving weights to features based on their importance introduce noise to the system? It is like changing the training data.
Thanks.
Great explanation as usual.. All methods talk about weak ensemble members. What about making having an ensemble learning of weak and strong algorithms. For instance, for a problem of image classification, a decision tree (weak) model to learn from meta data of the images and a CNN (strong) model to learn from the image dataset itself. Do you think these two could work together to give better results? And how do you thing this could be implemented?
I think you can try that. For implementation, I believe the existing ensemble library can be used, or otherwise you can write your own function for ensemble.
what is the best approach in bagging or boosting?
bagging is better or boosting is better please tell me from exam point of view? which technique is better?
Hi Najum-ul-Saher…Thank you for your questions! While I cannot speak to your exam questions, I am most able to help you with specific questions regarding our materials and code listings.
weighted ensemble and weighted avg ensemble are not the same thing right? im little confused. i made a ensemble model combining 3 different cnn models, each multiplied by optimized weights that i fine-tuned by doing a grid search of weights. Then i sum the whole thing(model1*w1+model2*w2…) and made the final ensemble model, not doing any averaging,, is this a dumb idea? ahaha ,,i wanted some models to contribute differently from the others.






")

Sir, can you show the code for same in R?
Perhaps this will help:
https://machinelearningmastery.com/machine-learning-ensembles-with-r/
Hi, Thanks for the explanation of each method. It was very helpful. I am a bit confused about weighted samples in boosting ensemble learning. Wouldn’t giving weights to features based on their importance introduce noise to the system? It is like changing the training data.
Thanks.
Yes, but instead of the noise, we are more concerned about the accuracy to the rare cases when there are imbalanced samples.
Great explanation as usual.. All methods talk about weak ensemble members. What about making having an ensemble learning of weak and strong algorithms. For instance, for a problem of image classification, a decision tree (weak) model to learn from meta data of the images and a CNN (strong) model to learn from the image dataset itself. Do you think these two could work together to give better results? And how do you thing this could be implemented?
Thanks
I think you can try that. For implementation, I believe the existing ensemble library can be used, or otherwise you can write your own function for ensemble.
what is the best approach in bagging or boosting?
bagging is better or boosting is better please tell me from exam point of view? which technique is better?
Hi Najum-ul-Saher…Thank you for your questions! While I cannot speak to your exam questions, I am most able to help you with specific questions regarding our materials and code listings.
Thank you very much for this tutorial.
All the content is helpfull for me.
Many thanks again.
You are very welcome Julius! We appreciate the support and feedback!
Hello,
Which of these ensemble methods has majority voting?
Hi gndkup…You may find the following of interest:
https://machinelearningmastery.com/voting-ensembles-with-python/#:~:text=A%20voting%20ensemble%20(or%20a,model%20used%20in%20the%20ensemble.
Please how can I use the ensemble learning in R. Code needed please. Thanks
Hi Arowona…Our content is primarily devoted to Python. The following resource is however available for R:
https://machinelearningmastery.com/machine-learning-with-r/
Hello thank you for the explanation.
In what class do Model Averaging and Classifier Voting fall into?
I’m quite puzzled as they are mentioned in other sites as ensemble strategies/methods but always out of the 3 categories you explained.
Thanx
Hi Noor…You are very welcome! We consider them ensemble learning algorithms.
The following is a great starting point for this topic:
https://machinelearningmastery.com/voting-ensembles-with-python/
weighted ensemble and weighted avg ensemble are not the same thing right? im little confused. i made a ensemble model combining 3 different cnn models, each multiplied by optimized weights that i fine-tuned by doing a grid search of weights. Then i sum the whole thing(model1*w1+model2*w2…) and made the final ensemble model, not doing any averaging,, is this a dumb idea? ahaha ,,i wanted some models to contribute differently from the others.