Ensemble algorithms are a powerful class of machine learning algorithm that combine the predictions from multiple models.
A benefit of using Weka for applied machine learning is that makes available so many different ensemble machine learning algorithms.
In this post you will discover the how to use ensemble machine learning algorithms in Weka.
After reading this post you will know:
- About 5 top ensemble machine learning algorithms.
- How to use top ensemble algorithms in Weka.
- About key configuration parameters for ensemble algorithms in Weka.
Kick-start your project with my new book Machine Learning Mastery With Weka, including step-by-step tutorials and clear screenshots for all examples.
Let’s get started.

How to Use Ensemble Machine Learning Algorithms in Weka
Photo by LEONARDO DASILVA, some rights reserved.
Ensemble Algorithms Overview
We are going to take a tour of 5 top ensemble machine learning algorithms in Weka.
Each algorithm that we cover will be briefly described in terms of how it works, key algorithm parameters will be highlighted and the algorithm will be demonstrated in the Weka Explorer interface.
The 5 algorithms that we will review are:
- Bagging
- Random Forest
- AdaBoost
- Voting
- Stacking
These are 5 algorithms that you can try on your problem in order to lift performance.
A standard machine learning classification problem will be used to demonstrate each algorithm.
Specifically, the Ionosphere binary classification problem. This is a good dataset to demonstrate classification algorithms because the input variables are numeric and all have the same scale the problem only has two classes to discriminate.
Each instance describes the properties of radar returns from the atmosphere and the task is to predict whether or not there is structure in the ionosphere or not. There are 34 numerical input variables of generally the same scale. You can learn more about this dataset on the UCI Machine Learning Repository. Top results are in the order of 98% accuracy.
Start the Weka Explorer:
- Open the Weka GUI Chooser.
- Click the “Explorer” button to open the Weka Explorer.
- Load the Ionosphere dataset from the data/ionosphere.arff file
- Click “Classify” to open the Classify tab.
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
Bootstrap Aggregation (Bagging)
Bootstrap Aggregation or Bagging for short is an ensemble algorithm that can be used for classification or regression.
Bootstrap is a statistical estimation technique where a statistical quantity like a mean is estimated from multiple random samples of your data (with replacement). It is a useful technique when you have a limited amount of data and you are interested in a more robust estimate of a statistical quantity.
This sample principle can be used with machine learning models. Multiple random samples of your training data are drawn with replacement and used to train multiple different machine learning models. Each model is then used to make a prediction and the results are averaged to give a more robust prediction.
It is a technique that is best used with models that have a low bias and a high variance, meaning that the predictions they make are highly dependent on the specific data from which they were trained. The most used algorithm for bagging that fits this requirement of high variance are decision trees.
Choose the bagging algorithm:
- Click the “Choose” button and select “Bagging” under the “meta” group.
- Click on the name of the algorithm to review the algorithm configuration.
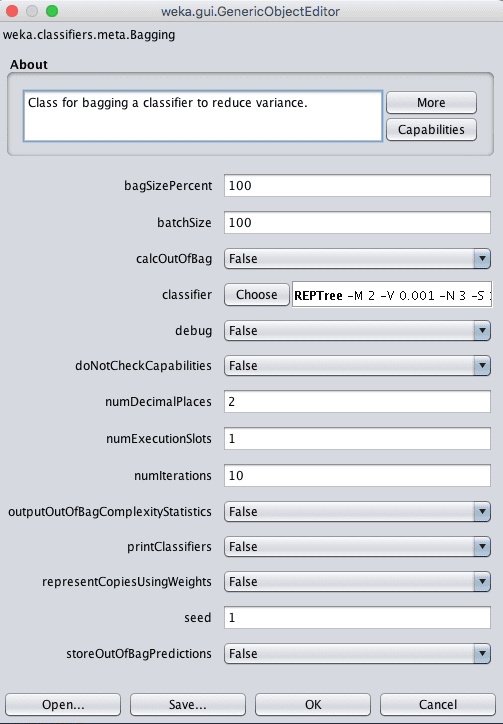
Weka Configuration for the Bagging Algorithm
A key configuration parameter in bagging is the type of model being bagged. The default is the REPTree which is the Weka implementation of a standard decision tree, also called a Classification and Regression Tree or CART for short. This is specified in the classifier parameter.
The size of each random sample is specified in the bagSizePercent, which is a size as a percentage of the raw training dataset. The default is 100% which will create a new random sample the same size as the training dataset, but will have a different composition.
This is because the random sample is drawn with replacement, which means that each time an instance is randomly drawn from the training dataset and added to the sample, it is also added back into the training dataset (replaced) meaning that it can be chosen again and added twice or more times to the sample.
Finally, the number of bags (and number of classifiers) can be specified in the numIterations parameter. The default is 10, although it is common to use values in the hundreds or thousands. Continue to increase the value of numIterations until you no longer see an improvement in the model, or you run out of memory.
- Click “OK” to close the algorithm configuration.
- Click the “Start” button to run the algorithm on the Ionosphere dataset.
You can see that with the default configuration that bagging achieves an accuracy of 91%.
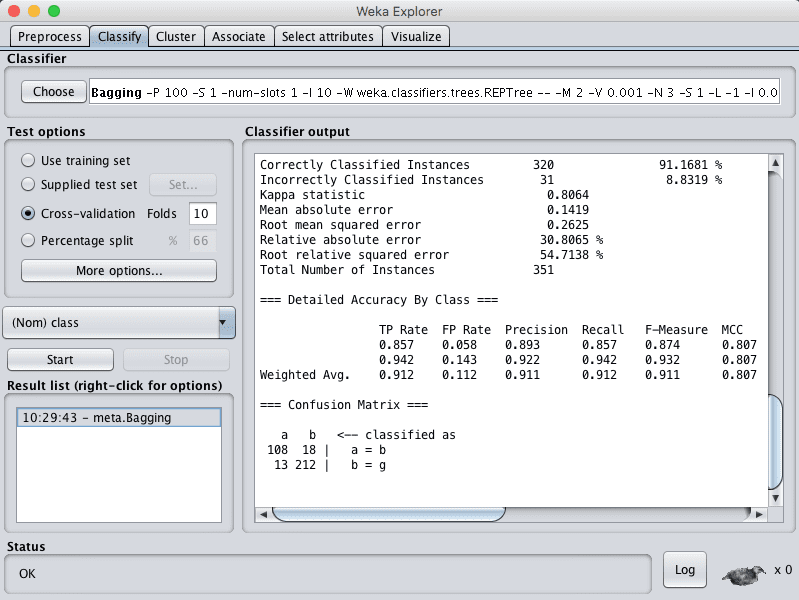
Weka Classification Results for the Bagging Algorithm
Random Forest
Random Forest is an extension of bagging for decision trees that can be used for classification or regression.
A down side of bagged decision trees is that decision trees are constructed using a greedy algorithm that selects the best split point at each step in the tree building process. As such, the resulting trees end up looking very similar which reduces the variance of the predictions from all the bags which in turn hurts the robustness of the predictions made.
Random Forest is an improvement upon bagged decision trees that disrupts the greedy splitting algorithm during tree creation so that split points can only be selected from a random subset of the input attributes. This simple change can have a big effect decreasing the similarity between the bagged trees and in turn the resulting predictions.
Choose the random forest algorithm:
- Click the “Choose” button and select “RandomForest” under the “trees” group.
- Click on the name of the algorithm to review the algorithm configuration.
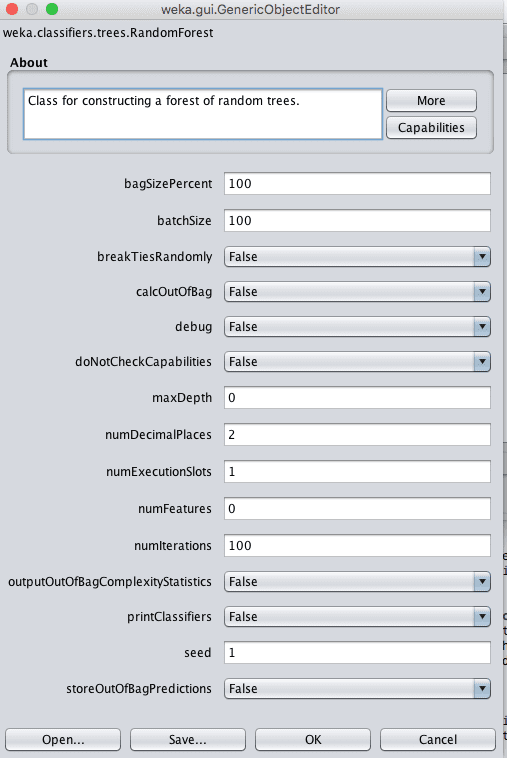
Weka Configuration for the Random Forest Algorithm
In addition to the parameters listed above for bagging, a key parameter for random forest is the number of attributes to consider in each split point. In Weka this can be controlled by the numFeatures attribute, which by default is set to 0, which selects the value automatically based on a rule of thumb.
- Click “OK” to close the algorithm configuration.
- Click the “Start” button to run the algorithm on the Ionosphere dataset.
You can see that with the default configuration that random forests achieves an accuracy of 92%.

Weka Classification Results for the Random Forest Algorithm
AdaBoost
AdaBoost is an ensemble machine learning algorithm for classification problems.
It is part of a group of ensemble methods called boosting, that add new machine learning models in a series where subsequent models attempt to fix the prediction errors made by prior models. AdaBoost was the first successful implementation of this type of model.
Adaboost was designed to use short decision tree models, each with a single decision point. Such short trees are often referred to as decision stumps.
The first model is constructed as per normal. Each instance in the training dataset is weighted and the weights are updated based on the overall accuracy of the model and whether an instance was classified correctly or not. Subsequent models are trained and added until a minimum accuracy is achieved or no further improvements are possible. Each model is weighted based on its skill and these weights are used when combining the predictions from all of the models on new data.
Choose the AdaBoost algorithm:
- Click the “Choose” button and select “AdaBoostM1” under the “meta” group.
- Click on the name of the algorithm to review the algorithm configuration.
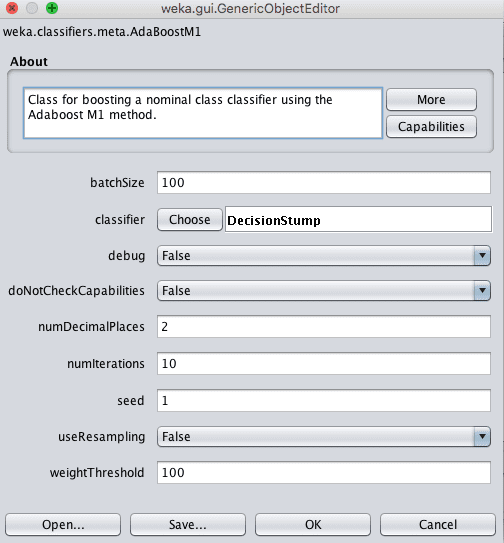
Weka Configuration for the AdaBoost Algorithm
The weak learner within the AdaBoost model can be specified by the classifier parameter.
The default is the decision stump algorithm, but other algorithms can be used. a key parameter in addition to the weak learner is the number of models to create and add in series. This can be specified in the numIterations parameter and defaults to 10.
- Click “OK” to close the algorithm configuration.
- Click the “Start” button to run the algorithm on the Ionosphere dataset.
You can see that with the default configuration that AdaBoost achieves an accuracy of 90%.
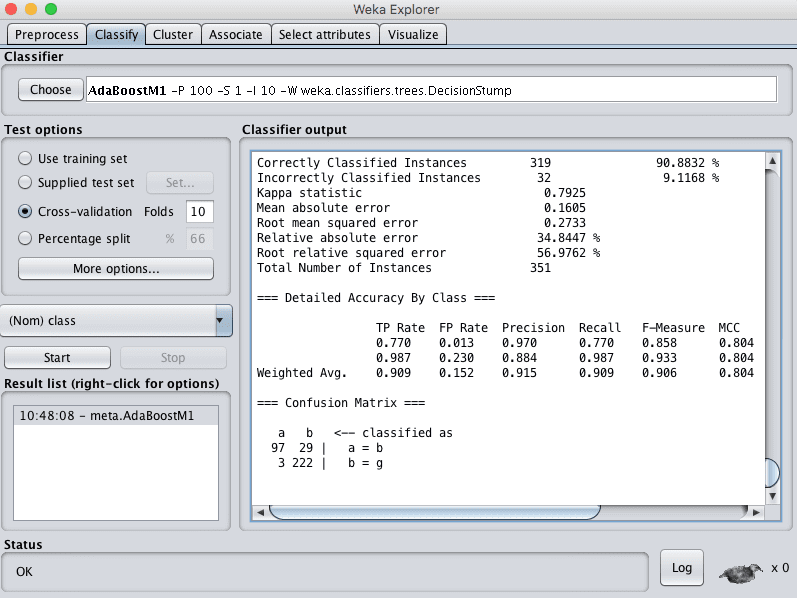
Weka Classification Results for the AdaBoost Algorithm
Voting
Voting is perhaps the simplest ensemble algorithm, and is often very effective. It can be used for classification or regression problems.
Voting works by creating two or more sub-models. Each sub-model makes predictions which are combined in some way, such as by taking the mean or the mode of the predictions, allowing each sub-model to vote on what the outcome should be.
Choose the Vote algorithm:
- Click the “Choose” button and select “Vote” under the “meta” group.
- Click on the name of the algorithm to review the algorithm configuration.
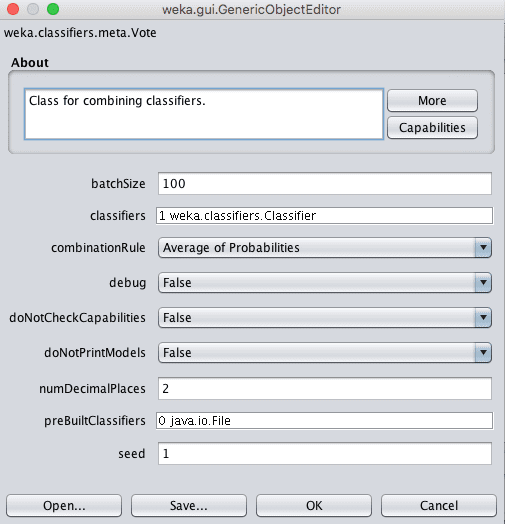
Weka Configuration for the Voting Ensemble Algorithm
The key parameter of a Vote ensemble is the selection of sub-models.
Models can be specified in Weka in the classifier parameter. Clicking this parameter lets you add a number of classifiers.
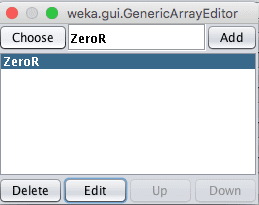
Weka Algorithm Selection for the Voting Ensemble Algorithm
Clicking the “Edit” button with a classifier selected lets you configure the details of that classifier. An objective in selecting sub-models is to select models that make quite different predictions (uncorrelated predictions). As such, it is a good rule of thumb to select very different model types, such as trees, instance based methods, functions and so on.
Another key parameter to configure for voting is how the predictions of the sub models are combined. This is controlled by the combinationRule parameter which is set to take the average of the probabilities by default.
- Click “OK” to close the algorithm configuration.
- Click the “Start” button to run the algorithm on the Ionosphere dataset.
You can see that with the default configuration that Vote achieves an accuracy of 64%.
Obviously, this technique achieved poor results because only the ZeroR sub-model was selected. Try selecting a collection of 5-to-10 different sub models.
Stacked Generalization (Stacking)
Stacked Generalization or Stacking for short is a simple extension to Voting ensembles that can be used for classification and regression problems.
In addition to selecting multiple sub-models, stacking allows you to specify another model to learn how to best combine the predictions from the sub-models. Because a meta model is used to best combine the predictions of sub-models, this technique is sometimes called blending, as in blending predictions together.
Choose the Stacking algorithm:
- Click the “Choose” button and select “Stacking” under the “meta” group.
- Click on the name of the algorithm to review the algorithm configuration.
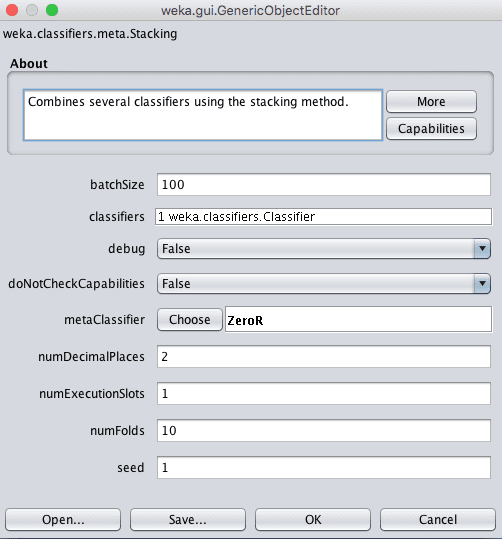
Weka Configuration for the Stacking Ensemble Algorithm
As with the Vote classifier, you can specify the sub-models in the classifiers parameter.
The model that will be trained to learn how to best combine the predictions from the sub model can be specified in the metaClassifier parameter, which is set to ZeroR (majority vote or mean) by default. It is common to use a linear algorithm like linear regression or logistic regression for regression and classification type problems respectively. This is to achieve an output that is a simple linear combination of the predictions of the sub models.
- Click “OK” to close the algorithm configuration.
- Click the “Start” button to run the algorithm on the Ionosphere dataset.
You can see that with the default configuration that Stacking achieves an accuracy of 64%.
Again, the same as voting, Stacking achieved poor results because only the ZeroR sub-model was selected. Try selecting a collection of 5-to-10 different sub models and a good model to combine the predictions.
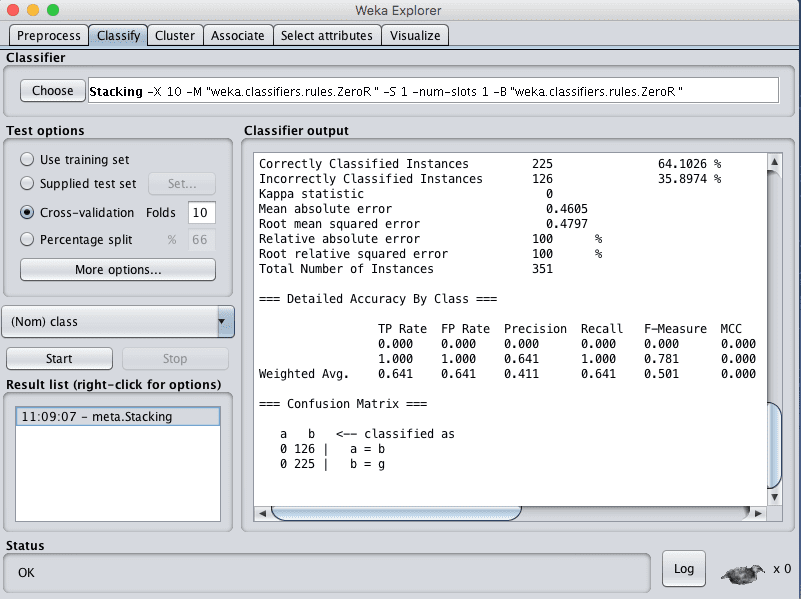
Weka Classification Results for the Stacking Ensemble Algorithm
Summary
In this post you discovered how to use ensemble machine learning algorithms in Weka.
Specifically you learned:
- About 5 ensemble machine learning algorithms that you can use on your problem.
- How to use ensemble machine learning algorithms in Weka.
- About the key configuration parameters for ensemble machine learning algorithms in Weka.
Do you have any questions about ensemble machine learning algorithms in Weka or about this post? Ask your questions in the comments and I will do my best to answer.
Discover Machine Learning Without The Code!

Develop Your Own Models in Minutes
...with just a few a few clicks
Discover how in my new Ebook:
Machine Learning Mastery With Weka
Covers self-study tutorials and end-to-end projects like:
Loading data, visualization, build models, tuning, and much more...
Finally Bring The Machine Learning To Your Own Projects
Skip the Academics. Just Results.






Hi Jason,
I noticed that when I used stacking to combine series of classifiers, there was a significant amount of difference in the ROC of the classifiers used when the meta and base learners were interchanged. For instance, when I used Naïve Bayes as a base learner and J48 as the meta learner, ROC of 0.805 was recorded but when I used J48 as the base learner and Naive Bayes as the meta learner, ROC of 0.926 was recoreded. This similar pattern was noticed for some other algorithms used. Could you please shed more light into the most likely reasons for this occurrence?
Thanks
Interesting finding, I don’t know off hand Seun.
Alright Jason. Thanks
Hi Jason,
I am new to Weka and trying to use random forest to train a regression model. I have three questions as below.
1) Cross-validation:
I am using 10-fold cross-validation but I wonder whether the data is shuffled before divided into 10 folds. Specifically, why is the performance statistic always same for the same algorithm?
Furthermore, what is the final model trained by cross-validation? As I see the performance statistic is averaged by 10 models, but how is the final model derived?
2) Random Forest
I am using the default parameters and 10-fold cross-validation, same question as 1), why the performance is always the same? I thought random forest would randomly select the instances as training set, and also select a random subset of the input attributes for each tree. But the training performance is always the same every time I perform random forest on my dataset.
Thanks.
Hi Lebron,
k-fold cross validation does split the data into k random groups, fits the model on k-1 groups and evaluates on the left out group, then repeats for all groups. Weka uses the same random seed so that each time you run, you get the same groups.
This is why you are getting the same result each time.
Learn more about cross validation in Weka here:
https://machinelearningmastery.com/estimate-performance-machine-learning-algorithms-weka/
Thanks for the information
Hello, all is going fine here and ofcourse every one is sharing data, that’s actually fine, keep up writing.
Great!
hi Mr jason
I used a combination of algorithms to predict the number of defects
I want to use the weighted average method to combine algorithms. Is the mean weighted method in veka implemented? How?
Please Guide me
You could take the mean of the predictions directly or you could use a new model to learn how to best combine the predictions.
Hi Jason;
I used Random Forest and I want to know why there is misclassifying in some testing data. Is there some specific way to know that.
There will always be prediction errors given noise in the data and a mismatch between the model and the true (but unknown) underlying mapping between inputs and outputs.
We use skill scores to get an idea of how well a model performs on average when making predictions on new data.
What effect twill the bag size have on the accuracy ?
Good question, larger models may be more expressive to a point of diminishing returns. It will really depend on the problem.
Very useful tutorial…if I am using vote and I want to select two classifiers, how can I choose the best compining list of classifiers which can achieve the best accuracy and performance ??
And how really can we improve the accuracy of the model if i am using randomforest for example?
Good question. Generally, you want to pick models that have uncorrelated predictions (uncorrelated prediction errors).
This can be challenging to analyze, so perhaps use experimentation and test many different combinations.
How can I visualize a tree by using meta classifier AdaBoost implement decision stump ..is there any package that can draw the tree from output
Not that I am aware.
How can I view the out-of-bag error rate for random forest?
Good question, perhaps Weka does not support that out of the box. I’m not sure.
Hi Jason,
Thanks for the continued support in the field of data mining. Well, I have been trying to create ensemble outlier detection model but have not succeed in coming up with one that out perform Random forest. I have even tried including RF in the ensemble together with other algorithms but none seem to out smart RF. I have even tried to to fine tune the parameters but all in vain.
Some of the ensemble include
(i) RF+KNN
(ii) KNN + Adaboost with RF as the weak classifier
(iii) RF + realbost with KNN as the weak classifier
I have varied the combination including use of Vote.
Have you ever created an Ensemble outlier detector that out perform RF
Kindly suggest for me some of the algorithm I can try to ensemble
regards,
Dalton
I have not.
This post might give you more ideas to explore:
https://machinelearningmastery.com/machine-learning-performance-improvement-cheat-sheet/
hi Jason,
thanks for your effort
i used adaboostm1 using weka
wit resullt i recieve that:
AdaBoostM1: no boosting possible, ONE CLASSIFIER USED !
what indicate of this?
i need to make boosting what to do or justify?
Change the configuration of the algorithm to use more than one classifier.
Can we use WEKA for ensemble feature selection?
What is ensemble feature selection?
Hi dears Dr., I used weka 6.8.2 and try to generate trees using Random forest using printclassifiers number of iteration 50 and then it generate number of trees with different number of tree size so how can identify the best size of tree to generate rules using the tree please help me ASAP?
I recommend testing a suite of different configurations to see what works best for your problem.
sure, before staring using Random Forest (RF), I tested using Auto-Weka application, so that RF is the best classifiers for the datasets, however, when generated tree using RF it display more than 2, 3,… etc. so which one is the best tree is that the middle one, the last one or the first one? how can I choose the best one for my paper? or what you suggest me to this kind tree generating challenges?
I don’t understand sorry. Perhaps you can provide more context?
Hi Mr jason , I’m a PhD student and my research field is the educational data mining, and I want to do a comparative study between many classifiers including the decision tree. I’ve never used weka software, and I want to use the J48 and the CART, the J48 already exits beyond the classifiers proposed by weka, but I couldn’t notice that the CART exists. can please tell me how I can run the CART algorithm using the software weka.
Yes, it is called REPTree I believe.
Hi ! Jason hope you are fine! i am student of MS computer science, my research work is improve accuracy in heart diseases prediction using optimized hybrid approach. please kindly brief me about how to use hybrid approach and from where i get Data set.
A hybrid approach might mean combining existing algorithms.
You can search for datasets here:
https://machinelearningmastery.com/faq/single-faq/where-can-i-get-a-dataset-on-___
Hi there
I have two questions.
1- I want to add new algorithm in weka for classifire for example genetic.
How can I do that?
2- My dataset is about water consumption and with weka I peredict water consumption for 1 month. I use linier regression, RandomTree, RandomForest. I want to improve accuracy.
Which algorithm is good for my goal?
Sorry, I don’t have tutorials on writing code for new algorithms in Weka.
I have suggestions for improving accuracy here:
https://machinelearningmastery.com/machine-learning-performance-improvement-cheat-sheet/
What’s up, everything is going perfectly here and ofcourse
every one is sharing information, that’s in fact fine, keep up writing.
Thanks.
I am trying to compare three methods to use on a data for prediction and Random Forest has the highest coefficient compared to RET, and M5P. The result box never showed any other information besides the summary. Where can i view the model for Random Forest for predictions?
You can save the model, is that what you mean?
Here’s how:
https://machinelearningmastery.com/save-machine-learning-model-make-predictions-weka/
Hello Sir. Thank you so much for the explanation about ensemble algorithms. I wanted to ask, if we combine two algorithms, say, Multilayer Perceptron and IBk, by stacking, how will we calculate the time complexity of the resulting technique?
Not sure off hand.
Hello Sir. I made three tests for 62 attributes, for the 1st test I have 90% as recognition rate, for the 2nd I have 92% and for the 3rd I have 88%. I want to make a voting method to take benefit of the results of the 3 tests to finally have only one result. knowing that the size of the different bases of the three tests differs from one to another.
Sounds good, perhaps try it?
Hello Sir, I used weka to random forest regression . but i don’t know how to this in weka., can you help me to implement random forest regression in weka .