A big benefit of using the Weka platform is the large number of supported machine learning algorithms.
The more algorithms that you can try on your problem the more you will learn about your problem and likely closer you will get to discovering the one or few algorithms that perform best.
In this post you will discover the machine learning algorithms supported by Weka.
After reading this post you will know:
The different types of machine learning algorithms supported and key algorithms to try in Weka.
How algorithms can be configured in Weka and how to save and load good algorithm configurations.
How to learn more about the machine learning algorithms supported by Weka.
Kick-start your project with my new book Machine Learning Mastery With Weka, including step-by-step tutorials and clear screenshots for all examples.
Let’s get started.
How to Use Machine Learning Algorithms in Weka Photo by Eugeniy Golovko, some rights reserved.
Weka Machine Learning Algorithms
Weka has a lot of machine learning algorithms. This is great, it is one of the large benefits of using Weka as a platform for machine learning.
A down side is that it can be a little overwhelming to know which algorithms to use, and when. Also, the algorithms have names that may not be familiar to you, even if you know them in other contexts.
In this section we will start off by looking at some well known algorithms supported by Weka. What we will learn in this post applies to the machine learning algorithms used across the Weka platform, but the Explorer is the best place to learn more about the algorithms as they are all available in one easy place.
Open the Weka GUI Chooser.
Click the “Explorer” button to open the Weka explorer.
Open a dataset, such as the Pima Indians dataset from the data/diabetes.arff file in your Weka installation.
Click “Classify” to open the Classify tab.
The classify tab of the Explorer is where you can learn about the various different algorithms and explore predictive modeling.
You can choose a machine learning algorithm by clicking the “Choose” button.
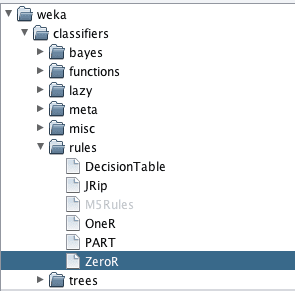
Weka Choose a Machine Learning Algorithms
Clicking on the “Choose” button presents you with a list of machine learning algorithms to choose from. They are divided into a number of main groups:
bayes: Algorithms that use Bayes Theorem in some core way, like Naive Bayes.
function: Algorithms that estimate a function, like Linear Regression.
lazy: Algorithms that use lazy learning, like k-Nearest Neighbors.
meta: Algorithms that use or combine multiple algorithms, like Ensembles.
misc: Implementations that do not neatly fit into the other groups, like running a saved model.
rules: Algorithms that use rules, like One Rule.
trees: Algorithms that use decision trees, like Random Forest.
The tab is called “Classify” and the algorithms are listed under an overarching group called “Classifiers”. Nevertheless, Weka supports both classification (predict a category) and regression (predict a numeric value) predictive modeling problems.
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
The type of problem you are working with is defined by the variable you wish to predict. On the “Classify” tab this is selected below the test options. By default, Weka selects the last attribute in your dataset. If the attribute is nominal, then Weka assumes you are working on a classification problem. If the attribute is numeric, Weka assumes you are working on a regression problem.
Weka Choose an Output Attribute to Predict
This is important, because the type of problem that you are working on determines what algorithms that you can work with. For example, if you are working on a classification problem, you cannot use regression algorithms like Linear Regression. On the other hand, if you are working on a regression problem, you cannot use classification algorithms like Logistic Regression.
Note if you are confused by the word “regression”, that is OK. It is confusing. Regression is a historical word from statistics. It used to mean making a model for a numerical output (to regress). It now means both the name of some algorithms and to predict a numerical value.
Weka will gray-out algorithms that are not supported by your chosen problem. Many machine learning algorithms can be used for both classification and regression. So you will have access to a large suite of algorithms regardless of your chosen problem.
Weka Algorithms Unavailable For Some Problem Types
Which Algorithm To Use
Generally, when working on a machine learning problem you cannot know which algorithm will be the best for your problem beforehand.
If you had enough information to know which algorithm would achieve the best performance, you probably would not be doing applied machine learning. You would be doing something else like statistics.
The solution therefore is to try a suite of algorithms on your problem and see what works best. Try a handful of powerful algorithms, then double down on the 1-to-3 algorithms that perform the best. They will given you an idea of the general type of algorithms that perform well or learning strategies that may be better than average at picking out the hidden structure in your data.
Some of the machine learning algorithms in Weka have non-standard names. You may already know the names of some machine learning algorithms, but feel confused by the names of the algorithms in Weka.
Below is a list of 10 top machine learning algorithms you should consider trying on your problem, including both their standard name and the name used in Weka.
Linear Machine Learning Algorithms
Linear algorithms assume that the predicted attribute is a linear combination of the input attributes.
Linear Regression: function.LinearRegression
Logistic Regression: function.Logistic
Nonlinear Machine Learning Algorithms
Nonlinear algorithms do not make strong assumptions about the relationship between the input attributes and the output attribute being predicted.
Naive Bayes: bayes.NaiveBayes
Decision Tree (specifically the C4.5 variety): trees.J48
k-Nearest Neighbors (also called KNN: lazy.IBk
Support Vector Machines (also called SVM): functions.SMO
Neural Network: functions.MultilayerPerceptron
Ensemble Machine Learning Algorithms
Ensemble methods combine the predictions from multiple models in order to make more robust predictions.
Random Forest: trees.RandomForest
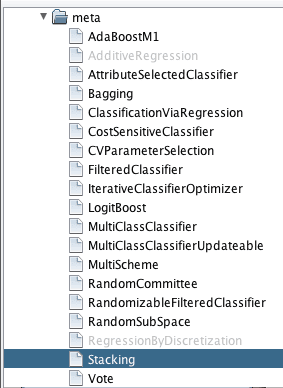
Bootstrap Aggregation (also called Bagging): meta.Bagging
Stacked Generalization (also called Stacking or Blending): meta.Stacking
Weka has an extensive array of ensemble methods, perhaps one of the largest available across all of the popular machine learning frameworks.
If you are looking for an area to specialize in using Weka, a source of true power in the platform besides ease of use, I would point to the support for ensemble techniques.
Machine Learning Algorithm Configuration
Once you have chosen a machine learning algorithm, you can configure it.
Configuration is optional, but highly recommended. Weka cleverly chooses sensible defaults for each machine learning algorithm meaning that you can select an algorithm and start using it immediately without knowing much about it.
To get the best results from an algorithm, you should configure it to behave ideally for your problem.
How do you configure an algorithm for your problem?
Again, this is another open question and not knowable beforehand. Given algorithms do have heuristics that can guide you but they are not a silver bullet. The true answer is to systematically test a suite of standard configurations for a given algorithm on your problem.
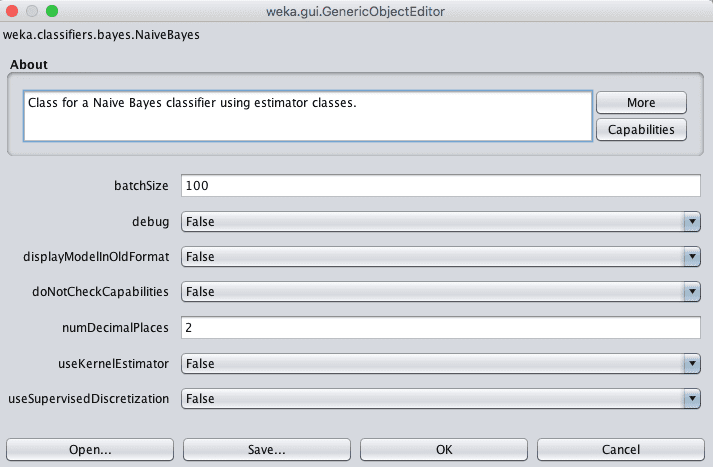
You can configure a machine learning algorithm in Weka by clicking on it’s name after you have selected it. This will launch a window that displays all of the configuration details for the algorithm.
Weka Configure a Machine Learning Algorithms
You can learn more about the meaning of each configuration option by hovering your mouse over each option which will display a tooltip describing the configuration option.
Some options give you a limited set of values to choose from, other take integer or real valued numbers. Try both experimentation and research in order to come up with 3-to-5 standard configurations of an algorithm to try on your problem.
A pro-tip that you can use is to save your standard algorithm configurations to a file. Click the “Save” button at the bottom of the algorithm configuration. Enter a filename that clearly labels the algorithm name and the type of configuration you are saving. You can load an algorithm configuration later in the Weka Explorer, the Experimenter and elsewhere in Weka. This is most valuable when you settle on a suite of standard algorithm configurations that you want reuse on problem to problem.
You can adopt and use the configuration for the algorithm by clicking the “OK” button on the algorithm configuration window.
Get More Information on Algorithms
Weka provides more information about each support machine learning algorithm.
On the algorithm configuration window, you will notice two buttons to learn more about the algorithm.
More Information
Clicking the “More” button will show a window that summarizes the implementation of the algorithm and all of the algorithms configuration properties.
Weka More Information About an Algorithm
This is useful to get a fuller idea of how the algorithm works and how to configure it. It also often includes references to books or papers from which the implementation of the algorithm was based. These can be good resources to track down and review in order to get a better idea for how to get the most from a given algorithm.
Reading up on how to better configure an algorithm is not something to do as a beginner because it can feel a little overwhelming, but it is a pro tip that will help you learn more and faster later on when you have more experience with applied machine learning.
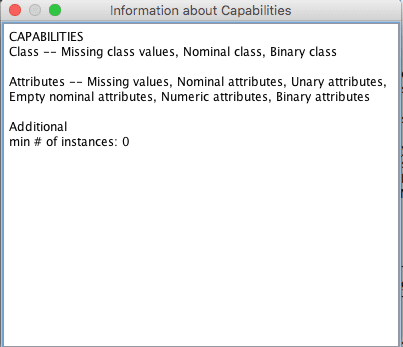
Algorithm Capabilities
Clicking on the “Capabilities” button will provide you with a snapshot of the capabilities of the algorithm.
Weka Capabilities for an Algorithm
Most importantly, this is useful to get an idea of how the algorithm handles missing data and any other important expectations it may have on your problem.
Reviewing this information can give you ideas on how to create new and different views on your data in order to lift performance for one or more algorithms.
Summary
In this post you discovered the support for machine learning algorithms in the Weka machine learning workbench.
Specifically, you learned:
That Weka has a large selection of machine learning algorithms to choose from for classification and regression problems.
That you can easily configure each machine learning algorithm and save and load a set of standard configurations.
That you can dive deeper into the details of a given algorithm and even discover the source from which it was based in order to learn how to get the best performance.
Do you have any questions about machine learning algorithms in Weka or about this post? Ask your questions in the comments and I will do my best to answer.
Hi Jason,
Many thanks for sharing this information.
Please, I am interested AI. I have background in Operations Research and IT, and I have been in computing application over some years.
I wan to to get in touch with for professional advice
Sir, Please can i develop or write my algorithms to implement in WEKA instead of using the ones that comes with the WEKA software? Also is it possible to modify the algorithms that are inbuilt in WEKA?
Is there a way we can find out how the algorithms work such as find accuracy. When do they know when to stop? Is their deep documentation on all the algorithms?
In general, we specify a stopping condition to end training, such as a fixed number of iterations or a change in improvement to model skill on the training or validation dataset.
For web service security, I am building intrusion detection system using machine learning for which I need data set. So I have no idea where to get that from !!
If you were to generalise as to which algorithms in Weka best reflect the notion of each tribe of AI, would it depend mostly on the state of the data being passed in? Are there algorithms that are quite obviously part of one tribe or another. e.g. naiveBayes is obviously used by the Bayesian tribe…?
hello sir i want to develop or modify existing algorithm based on neural network sir so can i code it in java n can i run it in weka if yes can u tgell me the procedure .and i also confuse to select atool whether to go for weka or to use python.plz suggest me sir.
Thank you for the information you’ve shared it has helped me a lot with my preliminary research into machine learning algorithms. I’m going to use weka in a project at University, I’ll be analysing network traffic of all kinds, light and heavy normal use to light and heavy malicious use. Analysing the differences from all datasets to deduce common tendencies to try outline where potential IDS can learn from it.
Are there any recommendations to which algorithms may be best suited towards my research?
Hi Jason, Thank you for your excellent work. Can I get a bit more interpretation on the results part. for example, how the algorithm looks like if I have a below node.










Thank you
You’re welcome.
why only algorithms like j48,rep tree,random tree are used in weather prediction in weka
You can use whatever algorithms you wish.
Hi Jason,
Many thanks for sharing this information.
Please, I am interested AI. I have background in Operations Research and IT, and I have been in computing application over some years.
I wan to to get in touch with for professional advice
A good place to get started might be here:
https://machinelearningmastery.com/start-here/#getstarted
Sir, Please can i develop or write my algorithms to implement in WEKA instead of using the ones that comes with the WEKA software? Also is it possible to modify the algorithms that are inbuilt in WEKA?
Yes, you can implement your own algorithms in Weka and modify existing ones.
Sorry, I don’t have tutorials to show how to do that.
Is there a way we can find out how the algorithms work such as find accuracy. When do they know when to stop? Is their deep documentation on all the algorithms?
Great question!
In general, we specify a stopping condition to end training, such as a fixed number of iterations or a change in improvement to model skill on the training or validation dataset.
hi Jason
will Bayes.BayesNet fall under NonLinear Machine learning algorithm?…similar to NaiveBayes which is a Nonlinear algorithm?
It is linear.
Hi Jason,
I am working on web services security project(REST based) , how do I will get the data set to work upon for machine learning training.
Not sure I follow, are you asking how to use Weka via REST? I have no idea.
For web service security, I am building intrusion detection system using machine learning for which I need data set. So I have no idea where to get that from !!
No sorry, perhaps try some google searches?
You may can get from data.world big ml or kaggle
If you were to generalise as to which algorithms in Weka best reflect the notion of each tribe of AI, would it depend mostly on the state of the data being passed in? Are there algorithms that are quite obviously part of one tribe or another. e.g. naiveBayes is obviously used by the Bayesian tribe…?
Thanks in advance
Yes, Weka’s organization of algorithms is good that way.
I have installed WEKA but i cant see any dataset to open. Unable to proceed
I show how to download the datasets separately here:
https://machinelearningmastery.com/download-install-weka-machine-learning-workbench/
I have a difficulty of feeding the data of three server CPU and memory utilization to train and predict. would you please help me how I do it.
Thanks
Perhaps this framework will help:
https://machinelearningmastery.com/how-to-define-your-machine-learning-problem/
how can i use AAAlgo algorithm in weka
What is “AAAlgo”?
hello sir i want to develop or modify existing algorithm based on neural network sir so can i code it in java n can i run it in weka if yes can u tgell me the procedure .and i also confuse to select atool whether to go for weka or to use python.plz suggest me sir.
Sorry, I don’t have tutorials on this topic.
Hello
Thank you for the information you’ve shared it has helped me a lot with my preliminary research into machine learning algorithms. I’m going to use weka in a project at University, I’ll be analysing network traffic of all kinds, light and heavy normal use to light and heavy malicious use. Analysing the differences from all datasets to deduce common tendencies to try outline where potential IDS can learn from it.
Are there any recommendations to which algorithms may be best suited towards my research?
Thank you for your time.
You’re welcome.
Yes, perhaps follow this process:
https://machinelearningmastery.com/start-here/#process
hi,
How to use graphical models such as CRF and HMM with your tool
I don’t have tutorials on these methods but I ope to write about them in the future.
Hi Jason,
Can we load our own data set or only use the datasets already in Weka.?
Further, does it have data cleaning capabilities?
Appreciate your response and thanks for all your insightful articles.
Regars
Yes, you can load your own dataset:
https://machinelearningmastery.com/load-csv-machine-learning-data-weka/
Yes, weka offers data transforms for data cleaning, perhaps start here:
https://machinelearningmastery.com/start-here/#weka
Hi Jason, Thank you for your excellent work. Can I get a bit more interpretation on the results part. for example, how the algorithm looks like if I have a below node.
Sigmoid Node 1
Inputs Weights
Threshold -6.9928483131703745
Attrib Temp 5.821816668231223
Attrib pH 1.5059966471679669
Attrib Konduktivitet 1.9145713932268624
Attrib Turbiditet -4.70465564011304
Attrib UV245 -0.7809926826308812
Sorry, I don’t quite related this to the post. Can you elaborate?