The problem of predictive modeling is to create models that have good performance making predictions on new unseen data.
Therefore it is critically important to use robust techniques to train and evaluate your models on your available training data. The more reliable the estimate of the performance on your model, the further you can push the performance and be confident it will translate to the operational use of your model.
In this post you will discover the various different ways that you can estimate the performance of your machine learning models in Weka.
After reading this post you will know:
How to evaluate your model using the training dataset.
How to evaluate your model using a random train and test split.
How to evaluate your model using k-fold cross validation.
Kick-start your project with my new book Machine Learning Mastery With Weka, including step-by-step tutorials and clear screenshots for all examples.
Let’s get started.
How To Estimate The Performance of Machine Learning Algorithms in Weka Photo by Will Fisher, some rights reserved.
Model Evaluation Techniques
There are a number of model evaluation techniques that you can choose from, and the Weka machine learning workbench offers four of them, as follows:
Training Dataset
Prepare your model on the entire training dataset, then evaluate the model on the same dataset. This is generally problematic not least because a perfect algorithm could game this evaluation technique by simply memorizing (storing) all training patterns and achieve a perfect score, which would be misleading.
Supplied Test Set
Split your dataset manually using another program. Prepare your model on the entire training dataset and use the separate test set to evaluate the performance of the model. This is a good approach if you have a large dataset (many tens of thousands of instances).
Percentage Split
Randomly split your dataset into a training and a testing partitions each time you evaluate a model. This can give you a very quick estimate of performance and like using a supplied test set, is preferable only when you have a large dataset.
Cross Validation
Split the dataset into k-partitions or folds. Train a model on all of the partitions except one that is held out as the test set, then repeat this process creating k-different models and give each fold a chance of being held out as the test set. Then calculate the average performance of all k models. This is the gold standard for evaluating model performance, but has the cost of creating many more models.
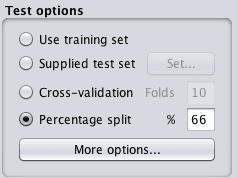
You can see these techniques in the Weka Explorer on the “Classify” tab after you have loaded a dataset.
Weka Algorithm Evaluation Test Options
Which Test Option to Use
Given that there are four different test options to choose from, which one should you use?
Each test option has a time and place, summarized as follows:
Training Dataset: Only to be used when you have all of the data and you are interested in creating a descriptive rather than a predictive model. Because you have all of the data, you do not need to make new predictions. You are interested in creating a model to better understand the problem.
Supplied Test Set: When the data is very large, e.g. millions of records and you do not need all of it to train a model. Also useful when the test set has been defined by a third party.
Percentage Split: Excellent to use to get a quick idea of the performance of a model. Not to be used to make decisions, unless you have a very large dataset and are confident (e.g. you have tested) that the splits sufficiently describe the problem. A common split value is 66% to 34% for train and test sets respectively.
Cross Validation: The default. To be used when you are unsure. Generally provides a more accurate estimate of the performance than the other techniques. Not to be used when you have a very large data. Common values for k are 5 and 10, depending on the size of the dataset.
If in doubt, use k-fold cross validation where k is set to 10.
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
What About The Final Model
Test options are concerned with estimating the performance of a model on unseen data.
This is an important concept to internalize. The goal of predictive modeling is to create a model that performs best in a situation that we do not fully understand, the future with new unknown data. We must use these powerful statistical techniques to best estimate the performance of the model in this situation.
That being said, once we have chosen a model, it must be finalized. None of these test options are used for this purpose.
The model must be trained on the entire training dataset and saved. This topic of model finalization is beyond the scope of this post.
Just note, that the performance of the finalized model does not need to be calculated, it is estimated using the test option techniques discussed above.
Performance Summary
The performance summary is provided in Weka when you evaluate a model.
In the “Classify” tab after you have evaluated an algorithm by clicking the “Start” button, the results are presented in the “Classifier output” pane.
This pane includes a lot of information, including:
The run information such as the algorithm and its configuration, the dataset and its properties as well as the test option
The details of the constructed model, if any.
The summary of the performance including a host of different measures.
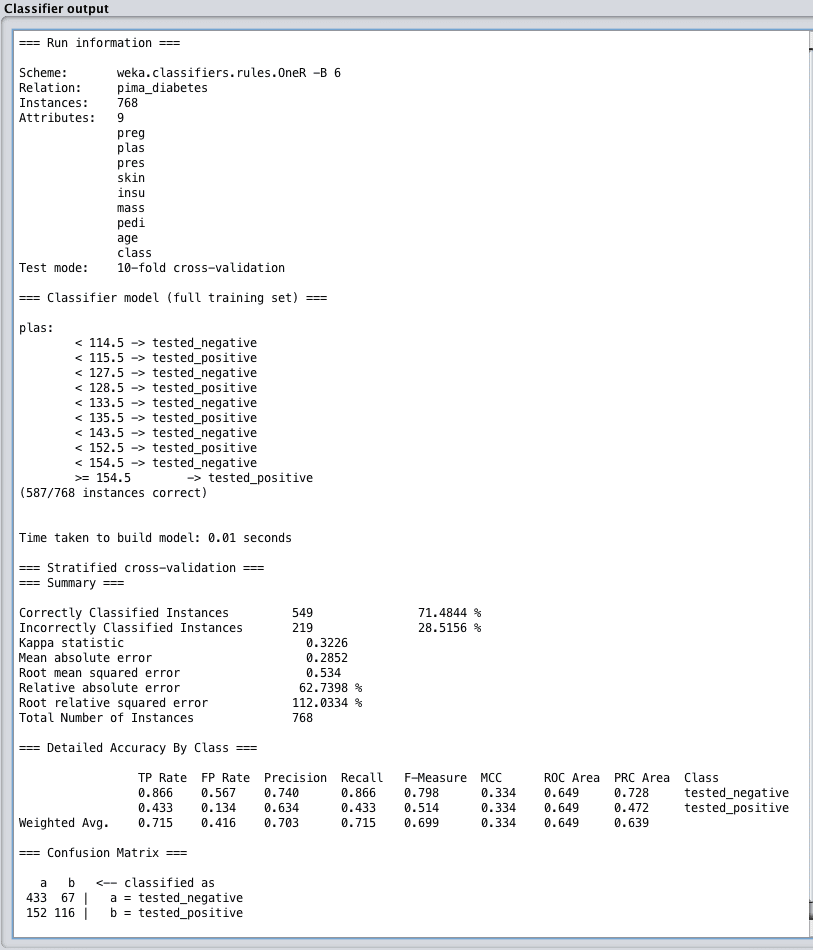
Classification Performance Summary
When evaluating a machine learning algorithm on a classification problem, you are given a vast amount of performance information to digest.
This is because classification may be the most studied type of predictive modeling problem and there are so many different ways to think about the performance of classification algorithms.
There are three things to note in the performance summary for classification algorithms:
Classification accuracy. This the ratio of the number of correct predictions out of all predictions made, often presented as a percentage where 100% is the best an algorithm can achieve. If your data has unbalanced classes, you may want to look into the Kappa metric which presents the same information taking the class balance into account.
Accuracy by class. Take note of the true-positive and false-positive rates for the predictions for each class which can be instructive of the class breakdown for the problem is uneven or there are more than two classes. This can help you interpret the results if predicting one class is more important than predicting another.
Confusion matrix. A table showing the number of predictions for each class compared to the number of instances that actually belong to each class. This is very useful to get an overview of the types of mistakes the algorithm made.
Weka Classification Performance Summary
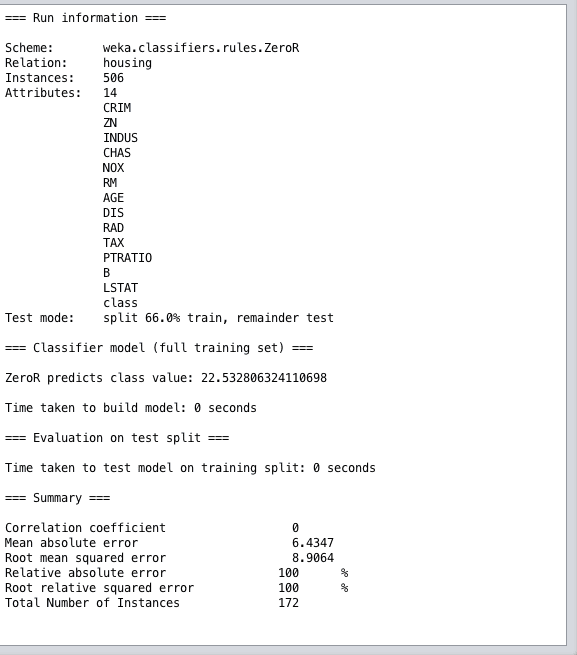
Regression Performance Summary
When evaluating a machine learning algorithm on a regression problem, you are given a number of different performance measures to review.
Of note the performance summary for regression algorithms are two things:
Correlation Coefficient. This is how well the predictions are correlated or change with the actual output value. A value of 0 is the worst and a value of 1 is a perfectly correlated set of predictions.
Root Mean Squared Error. This is the average amount of error made on the test set in the units of the output variable. This measure helps you get an idea on the amount a given prediction may be wrong on average.
Weka Regression Performance Summary
Summary
In this post you discovered how to estimate the performance of your machine learning models on unseen data in Weka.
Specifically, you learned:
About the importance of estimating the performance of machine learning models on unseen data as the core problem in predictive modeling.
About the 4 different test options and when to use each, paying specific attention to train and test splits and k-fold cross validation.
About the performance summary for classification and regression problems and to which metrics to pay attention.
Do you have any questions about estimating model performance in Weka or about this post? Ask your questions in the comments and I will do my best to answer them.
Hi Jason,
I am a little confused on the using cross-validation for testing. Is it that we split original dataset into training and test subsets. Then we use cross-validation on training subset for model selection and use test subset for cross validation to estimate the performance of chosen model?
Generally, when exploring different models, using cross validation to evaluate the performance of your model is sufficient.
For additional robustness, it is a good idea to first split your dataset into training and validation datasets, cross validate on the training dataset and once finalized evaluate the dataset on the standalone validation as a last check for overfitting.
i want to evaluate my proposed algorithm by cross validation by classification.i am dividing the data into two parts. test data is unlabeled data and training data is labelled data.then apply 10 folds cross validation on data by regression test and predict the labeled data from test data by training data.i have calculated MSe(mean of square error) and accuracy rate by confusion matrix. but still i am confused how i can evaluate my proposed algorithm by these results?
Hi Jason,
I have a doubt in calculating prediction accuracy. Generally, for classification, we will get the accuracy in weka but for regression how to calculate accuracy? Kindly help
Say, I have 1000 data, I split it into 80% (training dataset) 20% (test dataset). Then I will use the training dataset to perform 10-fold validations where internally it will further split the training dataset into 10% (8% from 1000) validation data and 90% (72% from 1000) training data and rotate each fold and based on generated accuracy I will select my model (model selection). Once model is selected, I will test it with the held-out 20% test data (20% from 1000).
Is the approach correct, as based on some literature this is what I understand? Hence, the terms training, validation and test data.
Another question:
From what I understand to calculate accuracy of k-fold, the formula is:
K-fold accuracy = Total accuracy of individual k-fold / k = Average of total accuracy of individual k-fold
However, can I apply per-class accuracy to calculate accuracy of each k-fold?
Such that, say if my data having 6 different classes, the formula will be:
Accuracy of individual class = Correct prediction of class / Total data
Accuracy of individual k-fold = Total of individual class accuracy / 6 = Average of total of individual class accuracy (in each fold)
K-fold accuracy = Total accuracy of individual k-fold / k
where accuracy of each class is derived from Confusion Matrix.
I’m working on more than 254 000 dataset and when I run the code. Python takes ages to execute and still no result. Is that a normal thing ? please advise.
Thanks a lot
Hello i want to ask something, if i got data about the percentage of attribute such as percentage of air according to specific location city a, city b. that is oxygen carbon dioxide, monoxide and so on what kind of technique and algorithm that suitable for this kind of data
How to choose a finalized regression model? For example, if I use RMSE as the measure and I have two models A and B. If RMSE(A, train)RMSE(B, test), then which model do you prefer? A or B?
If i use supplied test the accuracy of the classifier will be reduced. Before that I use cross validation for a singe arff file i get the acuuracy as 92% but in case of supplied test set the accuracy will be onle 82%. I don’t know whether it is correct or not.Is it correct.Please guide me.
Generally, cross validation is a more accurate estimate of performance, where as a train/test evaluation is optimistic unless the test set is very large.
Hi Jason, m actively following your blogs. I didn’t find a blog about how to calculate the training and testing time of an algorithm lets say RNN. Can you guide me plz how to calculate the testing time of an algorithm ? Looking forward to your reply.
How to find which algorithm is best for particular result? If i use decision tree and naive bayes which wll best among two how to check by using classifie output
I have thousands datset csv files especially related to network packets so if I use percentage split and fill the value 50 percent does weaka automatically train my data for 50 percent training and 50 percent testing ? Can we apply cross validation ?
Hi Jason, is it normal to get accuracy lower than 50% when using a percentage split of 66%? I am using about 40 datasets which all differ in the number of attributes and instances and most of them have been of accuracy 75%+, just wondered why the values are so much lower and if it’s okay for them to be lower.
Can I use only Cross validation without train test because a perfect algorithm could game this evaluation technique thank you very much and I am using (XGBoost) Ensemble
I split the whole dataset into 80/20%. 80% for cross-validation and the rest 20% for the final test for model evaluation. So, could you please help me out with how to test the model on test (unseen) data after trained it on k fold cross-validation in WEKA?. Like how we can save the model or the model will be saved after training in WEKA and later we can evaluate the model by supplying the rest 20% in the supplied test?.
One approach would be to use all data with k-fold cross-validation.
Another approach would be to first split the data, save the train and test sets as separate files, then load them into Weka as a train set and a test set.
Hi Jason
I want to perform 10 folds cross validation manually using weka. I should use SMOTE technique for training folds and let the test fold to stay original and repeat this process for 10 times. how can I do this using weka?








Hi Jason,
I am a little confused on the using cross-validation for testing. Is it that we split original dataset into training and test subsets. Then we use cross-validation on training subset for model selection and use test subset for cross validation to estimate the performance of chosen model?
Thanks
Generally, when exploring different models, using cross validation to evaluate the performance of your model is sufficient.
For additional robustness, it is a good idea to first split your dataset into training and validation datasets, cross validate on the training dataset and once finalized evaluate the dataset on the standalone validation as a last check for overfitting.
Thank you very much!
You’re welcome.
Hi Jason,
i want to evaluate my proposed algorithm by cross validation by classification.i am dividing the data into two parts. test data is unlabeled data and training data is labelled data.then apply 10 folds cross validation on data by regression test and predict the labeled data from test data by training data.i have calculated MSe(mean of square error) and accuracy rate by confusion matrix. but still i am confused how i can evaluate my proposed algorithm by these results?
Hi Jason,
I have a doubt in calculating prediction accuracy. Generally, for classification, we will get the accuracy in weka but for regression how to calculate accuracy? Kindly help
You cannot calculate accuracy in regression. There are no classes.
You must use another measure like RMSE or MAE or similar.
But still, there is a way to evaluate the algorithm. Not sure but I think same as in clustring.
Yes, by evaluating the error of the predictions (e.g. mean squared error or similar).
Hi Jason
you said that we couldn’t calculate accuracy in regression, but i need that…
No, we calculate error.
Hi again
How to calculate error????
Error = Prediction – Expected
Mean Absolute Error that WEKA give us in classifier output, is it error?? what about RMSE??
MAE and RMSE do not make sense for classification (e.g. class labels), unless they are reporting on the error in predicted probabilities.
Hi Jason,
Say, I have 1000 data, I split it into 80% (training dataset) 20% (test dataset). Then I will use the training dataset to perform 10-fold validations where internally it will further split the training dataset into 10% (8% from 1000) validation data and 90% (72% from 1000) training data and rotate each fold and based on generated accuracy I will select my model (model selection). Once model is selected, I will test it with the held-out 20% test data (20% from 1000).
Is the approach correct, as based on some literature this is what I understand? Hence, the terms training, validation and test data.
Another question:
From what I understand to calculate accuracy of k-fold, the formula is:
K-fold accuracy = Total accuracy of individual k-fold / k = Average of total accuracy of individual k-fold
However, can I apply per-class accuracy to calculate accuracy of each k-fold?
Such that, say if my data having 6 different classes, the formula will be:
Accuracy of individual class = Correct prediction of class / Total data
Accuracy of individual k-fold = Total of individual class accuracy / 6 = Average of total of individual class accuracy (in each fold)
K-fold accuracy = Total accuracy of individual k-fold / k
where accuracy of each class is derived from Confusion Matrix.
I’m working on more than 254 000 dataset and when I run the code. Python takes ages to execute and still no result. Is that a normal thing ? please advise.
Thanks a lot
Perhaps, it really depends on the dataset and on your hardware.
Perhaps try working with a smaller sample of your data?
Hello i want to ask something, if i got data about the percentage of attribute such as percentage of air according to specific location city a, city b. that is oxygen carbon dioxide, monoxide and so on what kind of technique and algorithm that suitable for this kind of data
See this post:
https://machinelearningmastery.com/a-data-driven-approach-to-machine-learning/
Hey Jason,
What should i use from Training data, supplied test and cross-validation upon the soybean.arff file in default datasets of weka?
Plase help
Weka will split the data for you automatically.
How to choose a finalized regression model? For example, if I use RMSE as the measure and I have two models A and B. If RMSE(A, train)RMSE(B, test), then which model do you prefer? A or B?
Perhaps the one with the lowest RMSE and smallest standard deviation.
Really helpful! Big thanks.
Thanks, I’m happy to hear that.
If i use supplied test the accuracy of the classifier will be reduced. Before that I use cross validation for a singe arff file i get the acuuracy as 92% but in case of supplied test set the accuracy will be onle 82%. I don’t know whether it is correct or not.Is it correct.Please guide me.
It really depends on the dataset.
Generally, cross validation is a more accurate estimate of performance, where as a train/test evaluation is optimistic unless the test set is very large.
Hai… I want to find a clustering accuracy for 1000 dataset can i use purity or that?and my incorrected instances are high…What i do for that?
Sorry, I don’t have any tutorials on clustering.
How to give test data set in weka? only by use of supplied test set, is there any other way to give test data set?
You can also use an automatic split of the data or an automatic cross-validation of the data.
Hi Jason, m actively following your blogs. I didn’t find a blog about how to calculate the training and testing time of an algorithm lets say RNN. Can you guide me plz how to calculate the testing time of an algorithm ? Looking forward to your reply.
What do you mean by train and test “time”, do you mean the number of epochs?
If so, set it to a very large number and use early stopping to end the training process:
https://machinelearningmastery.com/how-to-stop-training-deep-neural-networks-at-the-right-time-using-early-stopping/
How to find which algorithm is best for particular result? If i use decision tree and naive bayes which wll best among two how to check by using classifie output
Excellent question, this may help:
https://machinelearningmastery.com/faq/single-faq/what-algorithm-config-should-i-use
I have thousands datset csv files especially related to network packets so if I use percentage split and fill the value 50 percent does weaka automatically train my data for 50 percent training and 50 percent testing ? Can we apply cross validation ?
I believe when using Weka, you may have to have all data in a single file or in a train/test file first.
Hello…what is the meaning if i have a complex decision tree but has high accuracy?
What is your concern exactly?
Hi Jason, is it normal to get accuracy lower than 50% when using a percentage split of 66%? I am using about 40 datasets which all differ in the number of attributes and instances and most of them have been of accuracy 75%+, just wondered why the values are so much lower and if it’s okay for them to be lower.
It really depends on the dataset and the choice of models.
Perhaps compare results to zero-rule to see if the result is skillful on the same split of data?
HI Jason, How can I get the percentage of correctly classified instances for each class?
– I’m trying to find for the given classifier, which class is correctly classified better when compared to the rest.
Accuracy is a global measure for all classes.
Instead, you might want to look at the precision and recall for each class, this can help you understand the meaning:
https://machinelearningmastery.com/framework-for-imbalanced-classification-projects/
Hi Jason
I want to ask about the error measures : MMRE (Magnitude mean for relative error) and PRED(30) (Percentage Relative error deviation)
where I can found on WEKA or how can I add to it ??
Thanks in advance
I’m not sure sorry. You may have to write custom code.
Can I use only Cross validation without train test because a perfect algorithm could game this evaluation technique thank you very much and I am using (XGBoost) Ensemble
You can use a train/test split or k-fold cross-validation, no need to use both.
Hi Jason,
I split the whole dataset into 80/20%. 80% for cross-validation and the rest 20% for the final test for model evaluation. So, could you please help me out with how to test the model on test (unseen) data after trained it on k fold cross-validation in WEKA?. Like how we can save the model or the model will be saved after training in WEKA and later we can evaluate the model by supplying the rest 20% in the supplied test?.
Thank you
Ali
One approach would be to use all data with k-fold cross-validation.
Another approach would be to first split the data, save the train and test sets as separate files, then load them into Weka as a train set and a test set.
Hi Jason
I want to perform 10 folds cross validation manually using weka. I should use SMOTE technique for training folds and let the test fold to stay original and repeat this process for 10 times. how can I do this using weka?
Hi Farzin…You may find the following of interest:
https://experienceweka.wordpress.com/