A problem with many stochastic machine learning algorithms is that different runs of the same algorithm on the same data return different results.
This means that when performing experiments to configure a stochastic algorithm or compare algorithms, you must collect multiple results and use the average performance to summarize the skill of the model.
This raises the question as to how many repeats of an experiment are enough to sufficiently characterize the skill of a stochastic machine learning algorithm for a given problem.
It is often recommended to use 30 or more repeats, or even 100. Some practitioners use thousands of repeats that seemingly push beyond the idea of diminishing returns.
In this tutorial, you will explore the statistical methods that you can use to estimate the right number of repeats to effectively characterize the performance of your stochastic machine learning algorithm.
Kick-start your project with my new book Statistics for Machine Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Estimate the Number of Experiment Repeats for Stochastic Machine Learning Algorithms Photo by oatsy40, some rights reserved.
Tutorial Overview
This tutorial is broken down into 4 parts. They are:
Generate Data.
Basic Analysis.
Impact of the Number of Repeats.
Calculate Standard Error.
This tutorial assumes you have a working Python 2 or 3 SciPy environment installed with NumPy, Pandas and Matplotlib.
Need help with Statistics for Machine Learning?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
1. Generate Data
The first step is to generate some data.
We will pretend that we have fit a neural network or some other stochastic algorithm to a training dataset 1000 times and collected the final RMSE score on a dataset. We will further assume that the data is normally distributed, which is a requirement for the type of analysis we will use in this tutorial.
Always check the distribution of your results; more often than not the results will be Gaussian.
We will generate a population of results to analyze. This is useful as we will know the true population mean and standard deviation, which we would not know in a real scenario.
We will use a mean score of 60 with a standard deviation of 10.
The code below generates the sample of 1000 random results and saves them to a CSV file called results.csv.
We use the seed() function to seed the random number generator to ensure that we always get the same results each time this code is run (so you get the same numbers I do). We then use the normal() function to generate Gaussian random numbers and the savetxt() function to save the array of numbers in ASCII format.
1
2
3
4
5
6
7
8
9
10
11
from numpy.random import seed
from numpy.random import normal
from numpy import savetxt
# define underlying distribution of results
mean=60
stev=10
# generate samples from ideal distribution
seed(1)
results=normal(mean,stev,1000)
# save to ASCII file
savetxt('results.csv',results)
You should now have a file called results.csv with 1000 final results from our pretend stochastic algorithm test harness.
Below are the last 10 rows from the file for context.
1
2
3
4
5
6
7
8
9
10
11
...
6.160564991742511864e+01
5.879850024371251038e+01
6.385602292344325548e+01
6.718290735754342791e+01
7.291188902850875309e+01
5.883555851728335995e+01
3.722702003339634302e+01
5.930375460544870947e+01
6.353870426882840405e+01
5.813044983467250404e+01
We will forget that we know how these fake results were generated for the time being.
2. Basic Analysis
The first step when we have a population of results is to do some basic statistical analysis and see what we have.
Three useful tools for basic analysis include:
Calculate summary statistics, such as mean, standard deviation, and percentiles.
Review the spread of the data using a box and whisker plot.
Review the distribution of the data using a histogram.
The code below performs this basic analysis. First the results.csv is loaded, summary statistics are calculated, and plots are shown.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from pandas import DataFrame
from pandas import read_csv
from numpy import mean
from numpy import std
from matplotlib import pyplot
# load results file
results=read_csv('results.csv',header=None)
# descriptive stats
print(results.describe())
# box and whisker plot
results.boxplot()
pyplot.show()
# histogram
results.hist()
pyplot.show()
Running the example first prints the summary statistics.
We can see that the average performance of the algorithm is about 60.3 units with a standard deviation of about 9.8.
If we assume the score is a minimizing score like RMSE, we can see that the worst performance was about 99.5 and the best performance was about 29.4.
1
2
3
4
5
6
7
8
count 1000.000000
mean 60.388125
std 9.814950
min 29.462356
25% 53.998396
50% 60.412926
75% 67.039989
max 99.586027
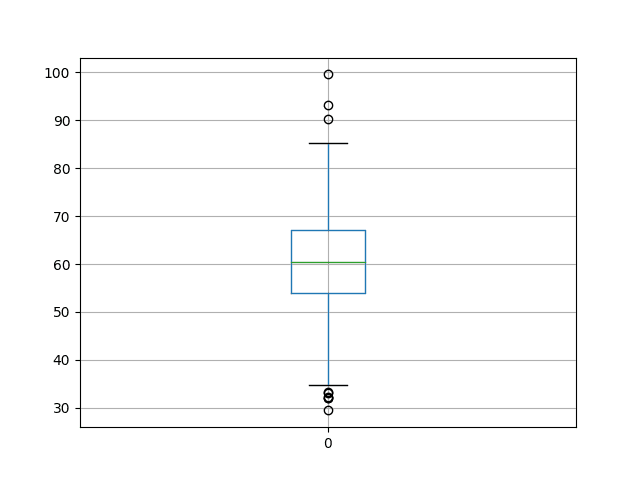
A box and whisker plot is created to summarize the spread of the data, showing the middle 50% (box), outliers (dots), and the median (green line).
We can see that the spread of the results appears reasonable even around the median.
Box and Whisker Plot of Model Skill
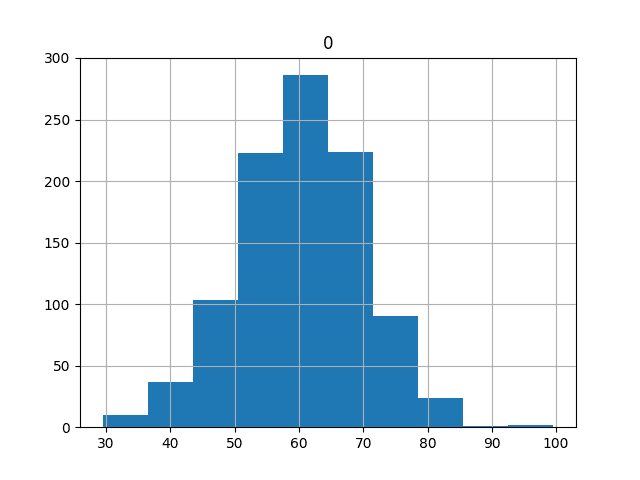
Finally, a histogram of the results is created. We can see the tell-tale bell curve shape of the Gaussian distribution, which is a good sign as it means we can use the standard statistical tools.
We do not see any obvious skew to the distribution; it seems centered around 60 or so.
Histogram of Model Skill Distribution
3. Impact of the Number of Repeats
We have a lot of results, 1000 to be exact.
This may be far more results than we need, or not enough.
How do we know?
We can get a first-cut idea by plotting the number of repeats of an experiment against the average of scores from those repeats.
We would expect that as the number of repeats of the experiment increase, the average score would quickly stabilize. It should produce a plot that is initially noisy with a long tail of stability.
The code below creates this graph.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from pandas import DataFrame
from pandas import read_csv
from numpy import mean
from matplotlib import pyplot
import numpy
# load results file
results=read_csv('results.csv',header=None)
values=results.values
# collect cumulative stats
means=list()
foriinrange(1,len(values)+1):
data=values[0:i,0]
mean_rmse=mean(data)
means.append(mean_rmse)
# line plot of cumulative values
pyplot.plot(means)
pyplot.show()
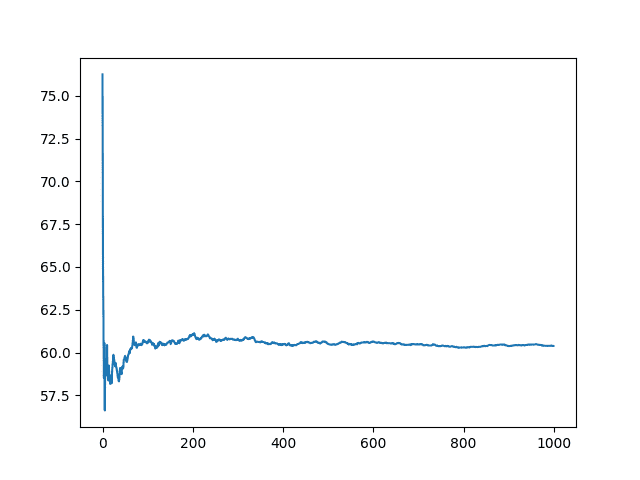
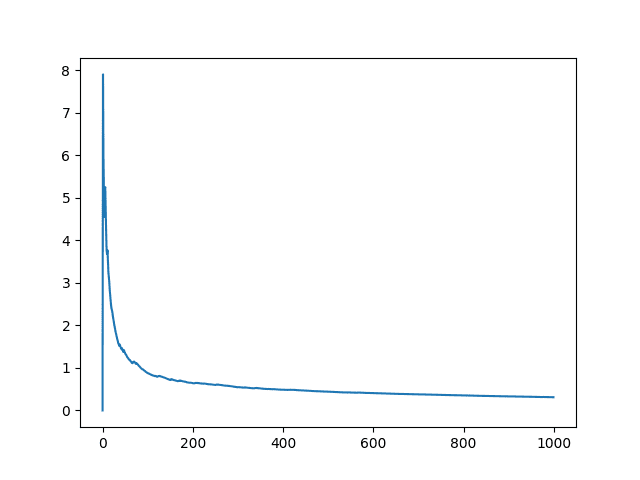
The plot indeed shows a period of noisy average results for perhaps the first 200 repeats until it becomes stable. It appears to become even more stable after perhaps 600 repeats.
Line Plot of the Number of Experiment Repeats vs Mean Model Skill
We can zoom in on this graph to the first 500 repeats to see if we can better understand what is happening.
We can also overlay the final mean score (mean from all 1000 runs) and attempt to locate a point of diminishing returns.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from pandas import DataFrame
from pandas import read_csv
from numpy import mean
from matplotlib import pyplot
import numpy
# load results file
results=read_csv('results.csv',header=None)
values=results.values
final_mean=mean(values)
# collect cumulative stats
means=list()
foriinrange(1,501):
data=values[0:i,0]
mean_rmse=mean(data)
means.append(mean_rmse)
# line plot of cumulative values
pyplot.plot(means)
pyplot.plot([final_mean forxinrange(len(means))])
pyplot.show()
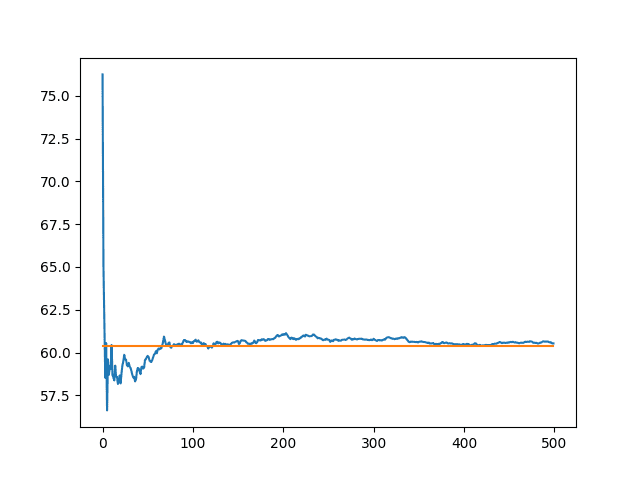
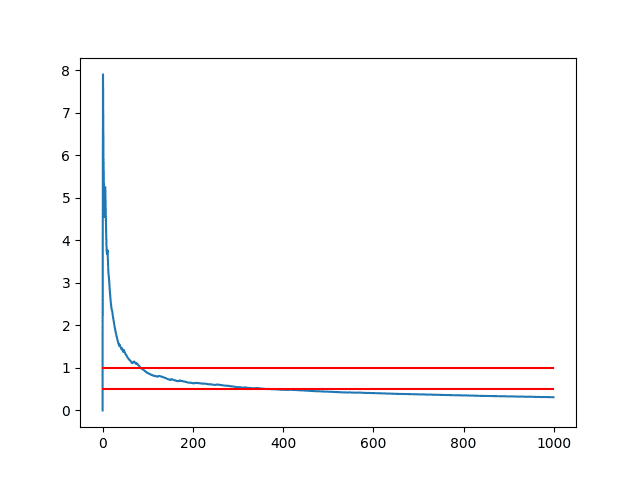
The orange line shows the mean of all 1000 runs.
We can see that 100 runs might be one good point to stop, otherwise perhaps 400 for a more refined result, but only slightly.
Line Plot of the Number of Experiment Repeats vs Mean Model Skill Truncated to 500 Repeants and Showing the Final Mean
This is a good start, but can we do better?
4. Calculate Standard Error
Standard error is a calculation of how much the “sample mean” differences from the “population mean”.
This is different from standard deviation that describes the average amount of variation of observations within a sample.
The standard error can provide an indication for a given sample size the amount of error or the spread of error that may be expected from the sample mean to the underlying and unknown population mean.
Standard error can be calculated as follows:
1
standard_error = sample_standard_deviation / sqrt(number of repeats)
That is in this context the standard deviation of the sample of model scores divided by the square root of the total number of repeats.
We would expect the standard error to decrease with the number of repeats of the experiment.
Given the results, we can calculate the standard error for the sample mean from the population mean at each number of repeats. The full code listing is provided below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from pandas import read_csv
from numpy import std
from numpy import mean
from matplotlib import pyplot
from math import sqrt
# load results file
results=read_csv('results.csv',header=None)
values=results.values
# collect cumulative stats
std_errors=list()
foriinrange(1,len(values)+1):
data=values[0:i,0]
stderr=std(data)/sqrt(len(data))
std_errors.append(stderr)
# line plot of cumulative values
pyplot.plot(std_errors)
pyplot.show()
A line plot of standard error vs the number of repeats is created.
We can see that, as expected, as the number of repeats is increased, the standard error decreases. We can also see that there will be a point of acceptable error, say one or two units.
The units for standard error are the same as the units of the model skill.
Line Plot of the Standard Error of the Sample Mean from the Population Mean
We can recreate the above graph and draw the 0.5 and 1 units as guides that can be used to find an acceptable level of error.
Again, we see the same line plot of standard error with red guidelines at a standard error of 1 and 0.5.
We can see that if a standard error of 1 was acceptable, then perhaps about 100 repeats would be sufficient. If a standard error of 0.5 was acceptable, perhaps 300-350 repeats would be sufficient.
We can see that the number of repeats quickly reaches a point of diminishing returns on standard error.
Again, remember, that standard error is a measure of how much the mean of the sample of model skill scores is wrong compared to the true underlying population of possible scores for a given model configuration given random initial conditions.
Line Plot of the Standard Error of the Sample Mean from the Population Mean With Markers
We can also use standard error as a confidence interval on the mean model skill.
For example, that the unknown population mean performance of a model has a likelihood of 95% of being between an upper and lower bound.
Note that this method is only appropriate for modest and large numbers of repeats, such as 20 or more.
The confidence interval can be defined as:
1
sample mean +/- (standard error * 1.96)
We can calculate this confidence interval and add it to the sample mean for each number of repeats as error bars.
A line plot is created showing the mean sample value for each number of repeats with error bars showing the confidence interval of each mean value capturing the unknown underlying population mean.
A read line is drawn showing the actual population mean (known only because we contrived the model skill scores at the beginning of the tutorial). As a surrogate for the population mean, you could add a line of the final sample mean after 1000 repeats or more.
The error bars obscure the line of the mean scores. We can see that the mean overestimates the population mean but the 95% confidence interval captures the population mean.
Note that a 95% confidence interval means that 95 out of 100 sample means with the interval will capture the population mean, and 5 such sample means and confidence intervals will not.
We can see that the 95% confidence interval does appear to tighten up with the increase of repeats as the standard error decreases, but there is perhaps diminishing returns beyond 500 repeats.
Line Plot of Mean Result with Standard Error Bars and Population Mean
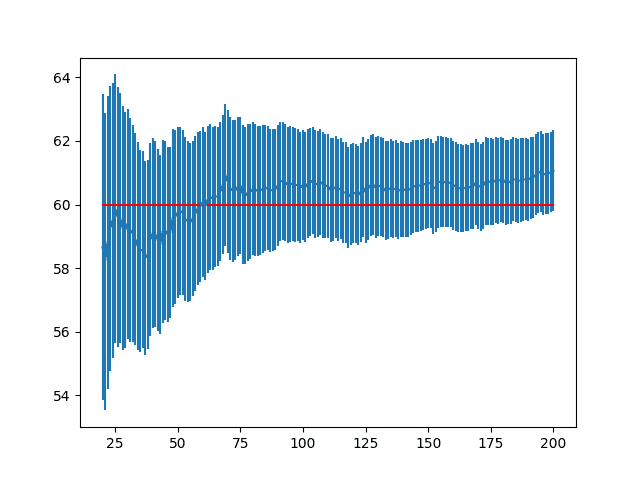
We can get a clearer idea of what is going on by zooming this graph in, highlighting repeats from 20 to 200.
In the line plot created, we can clearly see the sample mean and the symmetrical error bars around it. This plot does do a better job of showing the bias in the sample mean.
Zoomed Line Plot of Mean Result with Standard Error Bars and Population Mean
Further Reading
There are not many resources that link both the statistics required and the computational-experimental methodology used with stochastic algorithms.
Do you know of any other good related materials?
Let me know in the comments below.
Summary
In this tutorial, you discovered techniques that you can use to help choose the number of repeats that is right for evaluating stochastic machine learning algorithms.
You discovered a number of methods that you can use immediately:
A rough guess of 30, 100, or 1000 repeats.
Plot of sample mean vs number of repeats and choose based on inflection point.
Plot of standard error vs number of repeats and choose based on error threshold.
Plot of sample confidence interval vs number of repeats and choose based on spread of error.
Have you used any of these methods on your own experiments?
Share your results in the comments; I’d love to hear about them.
I wonder, how related is this technique with a cross validation?, I mean, cross validation gives many scores by training different samples from a same dataset, but in your approach you use the same dataset and “train many times the same model”. Could point out a bit about this relationship?. Thanks.
The number of CV folds is often small, e.g. 3-10. Too small for useful statistics.
You could the score from each fold as a “repeat” and repeat the whole CV process fewer times, as opposed to reporting the mean of the mean CV result (grand mean).
Could you please clarify what processes are called “repeat”? Repeating process using the same model with the same seed, or the model with the different seeds? I think it is the first one. Am I correct? Many thanks.
Thank you for your clarification. In practical, we should build an iteration loop to run the model with different seeds. However, from your code in this article, I only found one seed seed(1).
Thank you very much. If you could add this repeat process with codes into this article, it will be great for readers to use this technique in practice.
Thank Jason very much for your awesome blogs.
I wonder if I could translate your posts into my mother tongue language, Vietnamese; so many young students can understand it.
Thank you for this post. Why assume the results to be normally distributed? How do we evaluate confidence intervals if they are not normally distributed?
Jason thanks for this interesting post!. I have a question, how to choose the best model based on the number of repetitions?. I mean, according to your post, we need a number of repetitions that show the real perfomance (accuracy?) of one model, but then, how to use this number in order to get the steady model (ensembling?) that I have to consider for deployment. Thanks in advance.
Shall we repeat experiments for deep learning too? Many recents papers on CNNs, transformers, etc., seem not to mention the number of experimental runs or average results anymore so I am quite puzzled. Thanks.
Hi fresher…In our opinion yes! We agree with you that most papers do not discuss experimental runs. Given the stochastic nature of neural networks, it makes sense to establish multiple runs and consider the average performance. Additionally, many papers only show training and testing accuracy and do not provide an example of a true validation date set to understand the performance on “real world data”.










Hi Json,
For this kind of searching problem,cant we use unsupervicr learning algorithmes like k-mean clustering or apriori ?
Thnx
How might that work exactly?
of course you can run kmeans many times,to be honest, kmeans use kmeans++ to get the init centers, which algorithm is a stochastic algorithm.
How does this help to choose the number of experimental repeats?
I wonder, how related is this technique with a cross validation?, I mean, cross validation gives many scores by training different samples from a same dataset, but in your approach you use the same dataset and “train many times the same model”. Could point out a bit about this relationship?. Thanks.
Yes.
The number of CV folds is often small, e.g. 3-10. Too small for useful statistics.
You could the score from each fold as a “repeat” and repeat the whole CV process fewer times, as opposed to reporting the mean of the mean CV result (grand mean).
Does that help?
So when you say ‘grand mean’, it is like repeating a CV process many times, then calculate their means and then average those means. Am I right?
Correct.
Perfect! Thanks a lot Jason!
Could you please clarify what processes are called “repeat”? Repeating process using the same model with the same seed, or the model with the different seeds? I think it is the first one. Am I correct? Many thanks.
Goof question.
By repeat, I mean the same algorithm with the same data and different random numbers (a different seed for the random number generator).
Thank you for your clarification. In practical, we should build an iteration loop to run the model with different seeds. However, from your code in this article, I only found one seed seed(1).
You can seed the process once and use the long string of random seeds for each loop (repeat).
This is how I do it in practice.
Thank you very much. If you could add this repeat process with codes into this article, it will be great for readers to use this technique in practice.
You can see pseudocode examples here:
https://machinelearningmastery.com/evaluate-skill-deep-learning-models/
Thank Jason very much for your awesome blogs.
I wonder if I could translate your posts into my mother tongue language, Vietnamese; so many young students can understand it.
Many thanks!
No. I prefer to maintain control over my own content.
Hi Jason,
Thank you for this post. Why assume the results to be normally distributed? How do we evaluate confidence intervals if they are not normally distributed?
Regards
Great question.
I have a post scheduled that shows how to calculate empirical confidence intervals using the bootstrap that can be used if results are not Gaussian.
Hi Jason,
Is there similar tutorial based on R language?
Thank you
Xuemei
Sorry, not at this stage.
Jason thanks for this interesting post!. I have a question, how to choose the best model based on the number of repetitions?. I mean, according to your post, we need a number of repetitions that show the real perfomance (accuracy?) of one model, but then, how to use this number in order to get the steady model (ensembling?) that I have to consider for deployment. Thanks in advance.
I’d generally recommend use an ensemble of final models.
Great question, I cover it somewhat here:
https://machinelearningmastery.com/train-final-machine-learning-model/
how do we calculate the the number of repeats for classification problem (binary or multiclass)?
The same method (above) can be used regardless of the classification task.
Shall we repeat experiments for deep learning too? Many recents papers on CNNs, transformers, etc., seem not to mention the number of experimental runs or average results anymore so I am quite puzzled. Thanks.
Hi fresher…In our opinion yes! We agree with you that most papers do not discuss experimental runs. Given the stochastic nature of neural networks, it makes sense to establish multiple runs and consider the average performance. Additionally, many papers only show training and testing accuracy and do not provide an example of a true validation date set to understand the performance on “real world data”.
Thanks for the reply. We will do multiple runs in our experiments. 🙂