Given the rise of smart electricity meters and the wide adoption of electricity generation technology like solar panels, there is a wealth of electricity usage data available.
This data represents a multivariate time series of power-related variables that in turn could be used to model and even forecast future electricity consumption.
Machine learning algorithms predict a single value and cannot be used directly for multi-step forecasting. Two strategies that can be used to make multi-step forecasts with machine learning algorithms are the recursive and the direct methods.
In this tutorial, you will discover how to develop recursive and direct multi-step forecasting models with machine learning algorithms.
After completing this tutorial, you will know:
How to develop a framework for evaluating linear, nonlinear, and ensemble machine learning algorithms for multi-step time series forecasting.
How to evaluate machine learning algorithms using a recursive multi-step time series forecasting strategy.
How to evaluate machine learning algorithms using a direct per-day and per-lead time multi-step time series forecasting strategy.
Kick-start your project with my new book Deep Learning for Time Series Forecasting, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Multi-step Time Series Forecasting with Machine Learning Models for Household Electricity Consumption Photo by Sean McMenemy, some rights reserved.
Tutorial Overview
This tutorial is divided into five parts; they are:
Problem Description
Load and Prepare Dataset
Model Evaluation
Recursive Multi-Step Forecasting
Direct Multi-Step Forecasting
Problem Description
The ‘Household Power Consumption‘ dataset is a multivariate time series dataset that describes the electricity consumption for a single household over four years.
The data was collected between December 2006 and November 2010 and observations of power consumption within the household were collected every minute.
It is a multivariate series comprised of seven variables (besides the date and time); they are:
global_active_power: The total active power consumed by the household (kilowatts).
global_reactive_power: The total reactive power consumed by the household (kilowatts).
voltage: Average voltage (volts).
global_intensity: Average current intensity (amps).
sub_metering_1: Active energy for kitchen (watt-hours of active energy).
sub_metering_2: Active energy for laundry (watt-hours of active energy).
sub_metering_3: Active energy for climate control systems (watt-hours of active energy).
Active and reactive energy refer to the technical details of alternative current.
A fourth sub-metering variable can be created by subtracting the sum of three defined sub-metering variables from the total active energy as follows:
Download the dataset and unzip it into your current working directory. You will now have the file “household_power_consumption.txt” that is about 127 megabytes in size and contains all of the observations.
We can use the read_csv() function to load the data and combine the first two columns into a single date-time column that we can use as an index.
Next, we can mark all missing values indicated with a ‘?‘ character with a NaN value, which is a float.
This will allow us to work with the data as one array of floating point values rather than mixed types (less efficient.)
1
2
3
4
# mark all missing values
dataset.replace('?',nan,inplace=True)
# make dataset numeric
dataset=dataset.astype('float32')
We also need to fill in the missing values now that they have been marked.
A very simple approach would be to copy the observation from the same time the day before. We can implement this in a function named fill_missing() that will take the NumPy array of the data and copy values from exactly 24 hours ago.
1
2
3
4
5
6
7
# fill missing values with a value at the same time one day ago
def fill_missing(values):
one_day=60*24
forrow inrange(values.shape[0]):
forcol inrange(values.shape[1]):
ifisnan(values[row,col]):
values[row,col]=values[row-one_day,col]
We can apply this function directly to the data within the DataFrame.
1
2
# fill missing
fill_missing(dataset.values)
Now we can create a new column that contains the remainder of the sub-metering, using the calculation from the previous section.
1
2
3
# add a column for for the remainder of sub metering
We can now save the cleaned-up version of the dataset to a new file; in this case we will just change the file extension to .csv and save the dataset as ‘household_power_consumption.csv‘.
1
2
# save updated dataset
dataset.to_csv('household_power_consumption.csv')
Tying all of this together, the complete example of loading, cleaning-up, and saving the dataset is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# load and clean-up data
from numpy import nan
from numpy import isnan
from pandas import read_csv
from pandas import to_numeric
# fill missing values with a value at the same time one day ago
Running the example creates the new file ‘household_power_consumption.csv‘ that we can use as the starting point for our modeling project.
Need help with Deep Learning for Time Series?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Model Evaluation
In this section, we will consider how we can develop and evaluate predictive models for the household power dataset.
This section is divided into four parts; they are:
Problem Framing
Evaluation Metric
Train and Test Sets
Walk-Forward Validation
Problem Framing
There are many ways to harness and explore the household power consumption dataset.
In this tutorial, we will use the data to explore a very specific question; that is:
Given recent power consumption, what is the expected power consumption for the week ahead?
This requires that a predictive model forecast the total active power for each day over the next seven days.
Technically, this framing of the problem is referred to as a multi-step time series forecasting problem, given the multiple forecast steps. A model that makes use of multiple input variables may be referred to as a multivariate multi-step time series forecasting model.
A model of this type could be helpful within the household in planning expenditures. It could also be helpful on the supply side for planning electricity demand for a specific household.
This framing of the dataset also suggests that it would be useful to downsample the per-minute observations of power consumption to daily totals. This is not required, but makes sense, given that we are interested in total power per day.
We can achieve this easily using the resample() function on the pandas DataFrame. Calling this function with the argument ‘D‘ allows the loaded data indexed by date-time to be grouped by day (see all offset aliases). We can then calculate the sum of all observations for each day and create a new dataset of daily power consumption data for each of the eight variables.
Running the example creates a new daily total power consumption dataset and saves the result into a separate file named ‘household_power_consumption_days.csv‘.
We can use this as the dataset for fitting and evaluating predictive models for the chosen framing of the problem.
Evaluation Metric
A forecast will be comprised of seven values, one for each day of the week ahead.
It is common with multi-step forecasting problems to evaluate each forecasted time step separately. This is helpful for a few reasons:
To comment on the skill at a specific lead time (e.g. +1 day vs +3 days).
To contrast models based on their skills at different lead times (e.g. models good at +1 day vs models good at days +5).
The units of the total power are kilowatts and it would be useful to have an error metric that was also in the same units. Both Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE) fit this bill, although RMSE is more commonly used and will be adopted in this tutorial. Unlike MAE, RMSE is more punishing of forecast errors.
The performance metric for this problem will be the RMSE for each lead time from day 1 to day 7.
As a short-cut, it may be useful to summarize the performance of a model using a single score in order to aide in model selection.
One possible score that could be used would be the RMSE across all forecast days.
The function evaluate_forecasts() below will implement this behavior and return the performance of a model based on multiple seven-day forecasts.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# evaluate one or more weekly forecasts against expected values
Running the function will first return the overall RMSE regardless of day, then an array of RMSE scores for each day.
Train and Test Sets
We will use the first three years of data for training predictive models and the final year for evaluating models.
The data in a given dataset will be divided into standard weeks. These are weeks that begin on a Sunday and end on a Saturday.
This is a realistic and useful way for using the chosen framing of the model, where the power consumption for the week ahead can be predicted. It is also helpful with modeling, where models can be used to predict a specific day (e.g. Wednesday) or the entire sequence.
We will split the data into standard weeks, working backwards from the test dataset.
The final year of the data is in 2010 and the first Sunday for 2010 was January 3rd. The data ends in mid November 2010 and the closest final Saturday in the data is November 20th. This gives 46 weeks of test data.
The first and last rows of daily data for the test dataset are provided below for confirmation.
The function split_dataset() below splits the daily data into train and test sets and organizes each into standard weeks.
Specific row offsets are used to split the data using knowledge of the dataset. The split datasets are then organized into weekly data using the NumPy split() function.
1
2
3
4
5
6
7
8
# split a univariate dataset into train/test sets
def split_dataset(data):
# split into standard weeks
train,test=data[1:-328],data[-328:-6]
# restructure into windows of weekly data
train=array(split(train,len(train)/7))
test=array(split(test,len(test)/7))
returntrain,test
We can test this function out by loading the daily dataset and printing the first and last rows of data from both the train and test sets to confirm they match the expectations above.
Running the example shows that indeed the train dataset has 159 weeks of data, whereas the test dataset has 46 weeks.
We can see that the total active power for the train and test dataset for the first and last rows match the data for the specific dates that we defined as the bounds on the standard weeks for each set.
1
2
3
4
(159, 7, 8)
3390.46 1309.2679999999998
(46, 7, 8)
2083.4539999999984 2197.006000000004
Walk-Forward Validation
Models will be evaluated using a scheme called walk-forward validation.
This is where a model is required to make a one week prediction, then the actual data for that week is made available to the model so that it can be used as the basis for making a prediction on the subsequent week. This is both realistic for how the model may be used in practice and beneficial to the models, allowing them to make use of the best available data.
We can demonstrate this below with separation of input data and output/predicted data.
1
2
3
4
5
Input, Predict
[Week1] Week2
[Week1 + Week2] Week3
[Week1 + Week2 + Week3] Week4
...
The walk-forward validation approach to evaluating predictive models on this dataset is provided in a function below, named evaluate_model().
A scikit-learn model object is provided as an argument to the function, along with the train and test datasets. An additional argument n_input is provided that is used to define the number of prior observations that the model will use as input in order to make a prediction.
The specifics of how a scikit-learn model is fit and makes predictions is covered in later sections.
The forecasts made by the model are then evaluated against the test dataset using the previously defined evaluate_forecasts() function.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# evaluate a single model
def evaluate_model(model,train,test,n_input):
# history is a list of weekly data
history=[xforxintrain]
# walk-forward validation over each week
predictions=list()
foriinrange(len(test)):
# predict the week
yhat_sequence=...
# store the predictions
predictions.append(yhat_sequence)
# get real observation and add to history for predicting the next week
Once we have the evaluation for a model we can summarize the performance.
The function below, named summarize_scores(), will display the performance of a model as a single line for easy comparison with other models.
1
2
3
4
# summarize scores
def summarize_scores(name,score,scores):
s_scores=', '.join(['%.1f'%sforsinscores])
print('%s: [%.3f] %s'%(name,score,s_scores))
We now have all of the elements to begin evaluating predictive models on the dataset.
Recursive Multi-Step Forecasting
Most predictive modeling algorithms will take some number of observations as input and predict a single output value.
As such, they cannot be used directly to make a multi-step time series forecast.
This applies to most linear, nonlinear, and ensemble machine learning algorithms.
One approach where machine learning algorithms can be used to make a multi-step time series forecast is to use them recursively.
This involves making a prediction for one time step, taking the prediction, and feeding it into the model as an input in order to predict the subsequent time step. This process is repeated until the desired number of steps have been forecasted.
For example:
1
2
3
4
5
6
7
8
9
10
X=[x1,x2,x3]
y1=model.predict(X)
X=[x2,x3,y1]
y2=model.predict(X)
X=[x3,y1,y2]
y3=model.predict(X)
...
In this section, we will develop a test harness for fitting and evaluating machine learning algorithms provided in scikit-learn using a recursive model for multi-step forecasting.
The first step is to convert the prepared training data in window format into a single univariate series.
The to_series() function below will convert a list of weekly multivariate data into a single univariate series of daily total power consumed.
1
2
3
4
5
6
7
# convert windows of weekly multivariate data into a series of total power
def to_series(data):
# extract just the total power from each week
series=[week[:,0]forweek indata]
# flatten into a single series
series=array(series).flatten()
returnseries
Next, the sequence of daily power needs to be transformed into inputs and outputs suitable for fitting a supervised learning problem.
The prediction will be some function of the total power consumed on prior days. We can choose the number of prior days to use as inputs, such as one or two weeks. There will always be a single output: the total power consumed on the next day.
The model will be fit on the true observations from prior time steps. We need to iterate through the sequence of daily power consumed and split it into inputs and outputs. This is called a sliding window data representation.
The to_supervised() function below implements this behavior.
It takes a list of weekly data as input as well as the number of prior days to use as inputs for each sample that is created.
The first step is to convert the history into a single data series. The series is then enumerated, creating one input and output pair per time step. This framing of the problem will allow a model to learn to predict any day of the week given the observations of prior days. The function returns the inputs (X) and outputs (y) ready for training a model.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# convert history into inputs and outputs
def to_supervised(history,n_input):
# convert history to a univariate series
data=to_series(history)
X,y=list(),list()
ix_start=0
# step over the entire history one time step at a time
foriinrange(len(data)):
# define the end of the input sequence
ix_end=ix_start+n_input
# ensure we have enough data for this instance
ifix_end<len(data):
X.append(data[ix_start:ix_end])
y.append(data[ix_end])
# move along one time step
ix_start+=1
returnarray(X),array(y)
The scikit-learn library allows a model to be used as part of a pipeline. This allows data transforms to be applied automatically prior to fitting the model. More importantly, the transforms are prepared in the correct way, where they are prepared or fit on the training data and applied on the test data. This prevents data leakage when evaluating models.
We can use this capability when in evaluating models by creating a pipeline prior to fitting each model on the training dataset. We will both standardize and normalize the data prior to using the model.
The make_pipeline() function below implements this behavior, returning a Pipeline that can be used just like a model, e.g. it can be fit and it can make predictions.
The standardization and normalization operations are performed per column. In the to_supervised() function, we have essentially split one column of data (total power) into multiple columns, e.g. seven for seven days of input observations. This means that each of the seven columns in the input data will have a different mean and standard deviation for standardization and a different min and max for normalization.
Given that we used a sliding window, almost all values will appear in each column, therefore, this is not likely an issue. But it is important to note that it would be more rigorous to scale the data as a single column prior to splitting it into inputs and outputs.
1
2
3
4
5
6
7
8
9
10
11
12
# create a feature preparation pipeline for a model
def make_pipeline(model):
steps=list()
# standardization
steps.append(('standardize',StandardScaler()))
# normalization
steps.append(('normalize',MinMaxScaler()))
# the model
steps.append(('model',model))
# create pipeline
pipeline=Pipeline(steps=steps)
returnpipeline
We can tie these elements together into a function called sklearn_predict(), listed below.
The function takes a scikit-learn model object, the training data, called history, and a specified number of prior days to use as inputs. It transforms the training data into inputs and outputs, wraps the model in a pipeline, fits it, and uses it to make a prediction.
The model will use the last row from the training dataset as input in order to make the prediction.
The forecast() function will use the model to make a recursive multi-step forecast.
The recursive forecast involves iterating over each of the seven days required of the multi-step forecast.
The input data to the model is taken as the last few observations of the input_data list. This list is seeded with all of the observations from the last row of the training data, and as we make predictions with the model, they are added to the end of this list. Therefore, we can take the last n_input observations from this list in order to achieve the effect of providing prior outputs as inputs.
The model is used to make a prediction for the prepared input data and the output is added both to the list for the actual output sequence that we will return and the list of input data from which we will draw observations as input for the model on the next iteration.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# make a recursive multi-step forecast
def forecast(model,input_x,n_input):
yhat_sequence=list()
input_data=[xforxininput_x]
forjinrange(7):
# prepare the input data
X=array(input_data[-n_input:]).reshape(1,n_input)
# make a one-step forecast
yhat=model.predict(X)[0]
# add to the result
yhat_sequence.append(yhat)
# add the prediction to the input
input_data.append(yhat)
returnyhat_sequence
We now have all of the elements to fit and evaluate scikit-learn models using a recursive multi-step forecasting strategy.
We can update the evaluate_model() function defined in the previous section to call the sklearn_predict() function. The updated function is listed below.
An important final function is the get_models() that defines a dictionary of scikit-learn model objects mapped to a shorthand name we can use for reporting.
We will start-off by evaluating a suite of linear algorithms. We would expect that these would perform similar to an autoregression model (e.g. AR(7) if seven days of inputs were used).
The get_models() function with ten linear models is defined below.
This is a spot check where we are interested in the general performance of a diverse range of algorithms rather than optimizing any given algorithm.
Running the example evaluates the ten linear algorithms and summarizes the results.
As each of the algorithms is evaluated and the performance is reported with a one-line summary, including the overall RMSE as well as the per-time step RMSE.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
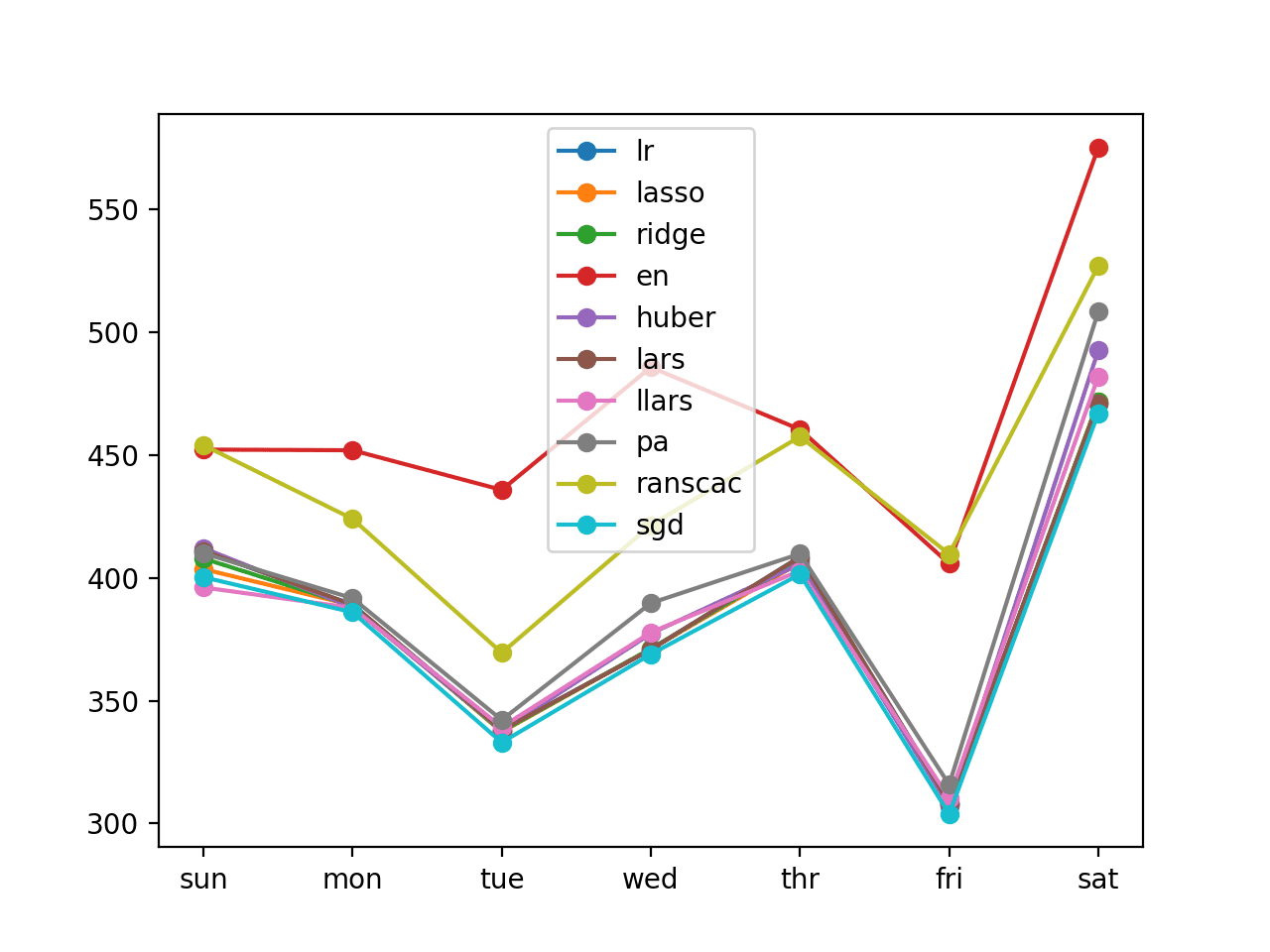
We can see that most of the evaluated models performed well, below 400 kilowatts in error over the whole week, with perhaps the Stochastic Gradient Descent (SGD) regressor performing the best with an overall RMSE of about 383.
A line plot of the daily RMSE for each of the 10 classifiers is also created.
We can see that all but two of the methods cluster together with equally well performing results across the seven day forecasts.
Line Plot of Recursive Multi-step Forecasts With Linear Algorithms
Better results may be achieved by tuning the hyperparameters of some of the better performing algorithms. Further, it may be interesting to update the example to test a suite of nonlinear and ensemble algorithms.
An interesting experiment may be to evaluate the performance of one or a few of the better performing algorithms with more or fewer prior days as input.
Direct Multi-Step Forecasting
An alternate to the recursive strategy for multi-step forecasting is to use a different model for each of the days to be forecasted.
This is called a direct multi-step forecasting strategy.
Because we are interested in forecasting seven days, this would require preparing seven different models, each specialized for forecasting a different day.
There are two approaches to training such a model:
Predict Day. Models can be prepared to predict a specific day of the standard week, e.g. Monday.
Predict Lead Time. Models can be prepared to predict a specific lead time, e.g. day 1.
Predicting a day will be more specific, but will mean that less of the training data can be used for each model. Predicting a lead time makes use of more of the training data, but requires the model to generalize across the different days of the week.
We will explore both approaches in this section.
Direct Day Approach
First, we must update the to_supervised() function to prepare the data, such as the prior week of observations, used as input and an observation from a specific day in the following week used as the output.
The updated to_supervised() function that implements this behavior is listed below. It takes an argument output_ix that defines the day [0,6] in the following week to use as the output.
1
2
3
4
5
6
7
8
# convert history into inputs and outputs
def to_supervised(history,output_ix):
X,y=list(),list()
# step over the entire history one time step at a time
foriinrange(len(history)-1):
X.append(history[i][:,0])
y.append(history[i+1][output_ix,0])
returnarray(X),array(y)
This function can be called seven times, once for each of the seven models required.
Next, we can update the sklearn_predict() function to create a new dataset and a new model for each day in the one-week forecast.
The body of the function is mostly unchanged, only it is used within a loop over each day in the output sequence, where the index of the day “i” is passed to the call to to_supervised() in order to prepare a specific dataset for training a model to predict that day.
The function no longer takes an n_input argument, as we have fixed the input to be the seven days of the prior week.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# fit a model and make a forecast
def sklearn_predict(model,history):
yhat_sequence=list()
# fit a model for each forecast day
foriinrange(7):
# prepare data
train_x,train_y=to_supervised(history,i)
# make pipeline
pipeline=make_pipeline(model)
# fit the model
pipeline.fit(train_x,train_y)
# forecast
x_input=array(train_x[-1,:]).reshape(1,7)
yhat=pipeline.predict(x_input)[0]
# store
yhat_sequence.append(yhat)
returnyhat_sequence
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
# direct multi-step forecast by day
from math import sqrt
from numpy import split
from numpy import array
from pandas import read_csv
from sklearn.metrics import mean_squared_error
from matplotlib import pyplot
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import HuberRegressor
from sklearn.linear_model import Lars
from sklearn.linear_model import LassoLars
from sklearn.linear_model import PassiveAggressiveRegressor
from sklearn.linear_model import RANSACRegressor
from sklearn.linear_model import SGDRegressor
# split a univariate dataset into train/test sets
def split_dataset(data):
# split into standard weeks
train,test=data[1:-328],data[-328:-6]
# restructure into windows of weekly data
train=array(split(train,len(train)/7))
test=array(split(test,len(test)/7))
returntrain,test
# evaluate one or more weekly forecasts against expected values
Running the example first summarizes the performance of each model.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
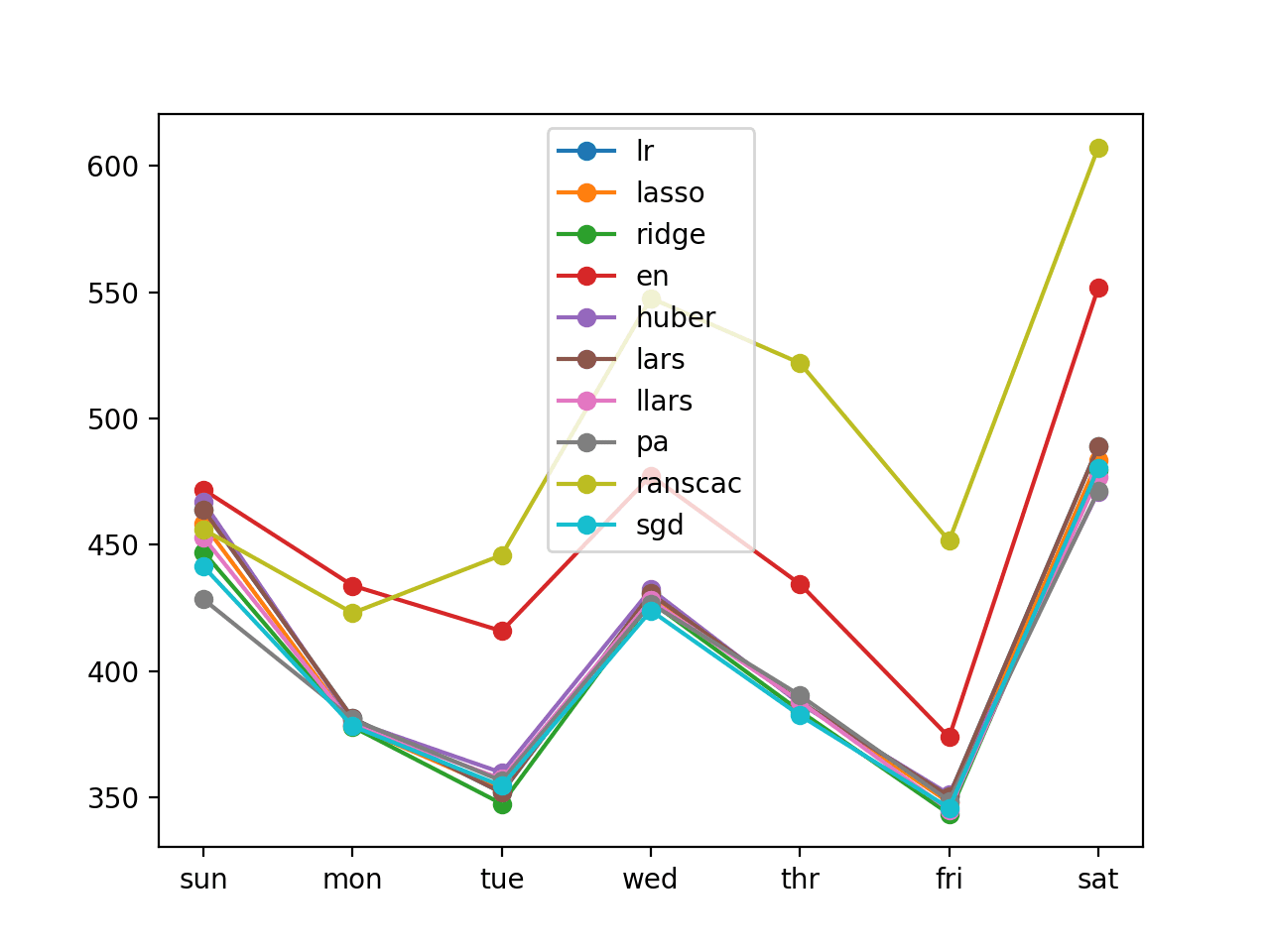
We can see that the performance is slightly worse than the recursive model on this problem.
A line plot of the per-day RMSE scores for each model is also created, showing a similar grouping of models as was seen with the recursive model.
Line Plot of Direct Per-Day Multi-step Forecasts With Linear Algorithms
Direct Lead Time Approach
The direct lead time approach is the same, except that the to_supervised() makes use of more of the training dataset.
The function is the same as it was defined in the recursive model example, except it takes an additional output_ix argument to define the day in the following week to use as the output.
The updated to_supervised() function for the direct per-lead time strategy is listed below.
Unlike the per-day strategy, this version of the function does support variable sized inputs (not just seven days), allowing you to experiment if you like.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# convert history into inputs and outputs
def to_supervised(history,n_input,output_ix):
# convert history to a univariate series
data=to_series(history)
X,y=list(),list()
ix_start=0
# step over the entire history one time step at a time
foriinrange(len(data)):
# define the end of the input sequence
ix_end=ix_start+n_input
ix_output=ix_end+output_ix
# ensure we have enough data for this instance
ifix_output<len(data):
X.append(data[ix_start:ix_end])
y.append(data[ix_output])
# move along one time step
ix_start+=1
returnarray(X),array(y)
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
# direct multi-step forecast by lead time
from math import sqrt
from numpy import split
from numpy import array
from pandas import read_csv
from sklearn.metrics import mean_squared_error
from matplotlib import pyplot
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridge
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import HuberRegressor
from sklearn.linear_model import Lars
from sklearn.linear_model import LassoLars
from sklearn.linear_model import PassiveAggressiveRegressor
from sklearn.linear_model import RANSACRegressor
from sklearn.linear_model import SGDRegressor
# split a univariate dataset into train/test sets
def split_dataset(data):
# split into standard weeks
train,test=data[1:-328],data[-328:-6]
# restructure into windows of weekly data
train=array(split(train,len(train)/7))
test=array(split(test,len(test)/7))
returntrain,test
# evaluate one or more weekly forecasts against expected values
Running the example summarizes the overall and per-day RMSE for each of the evaluated linear models.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
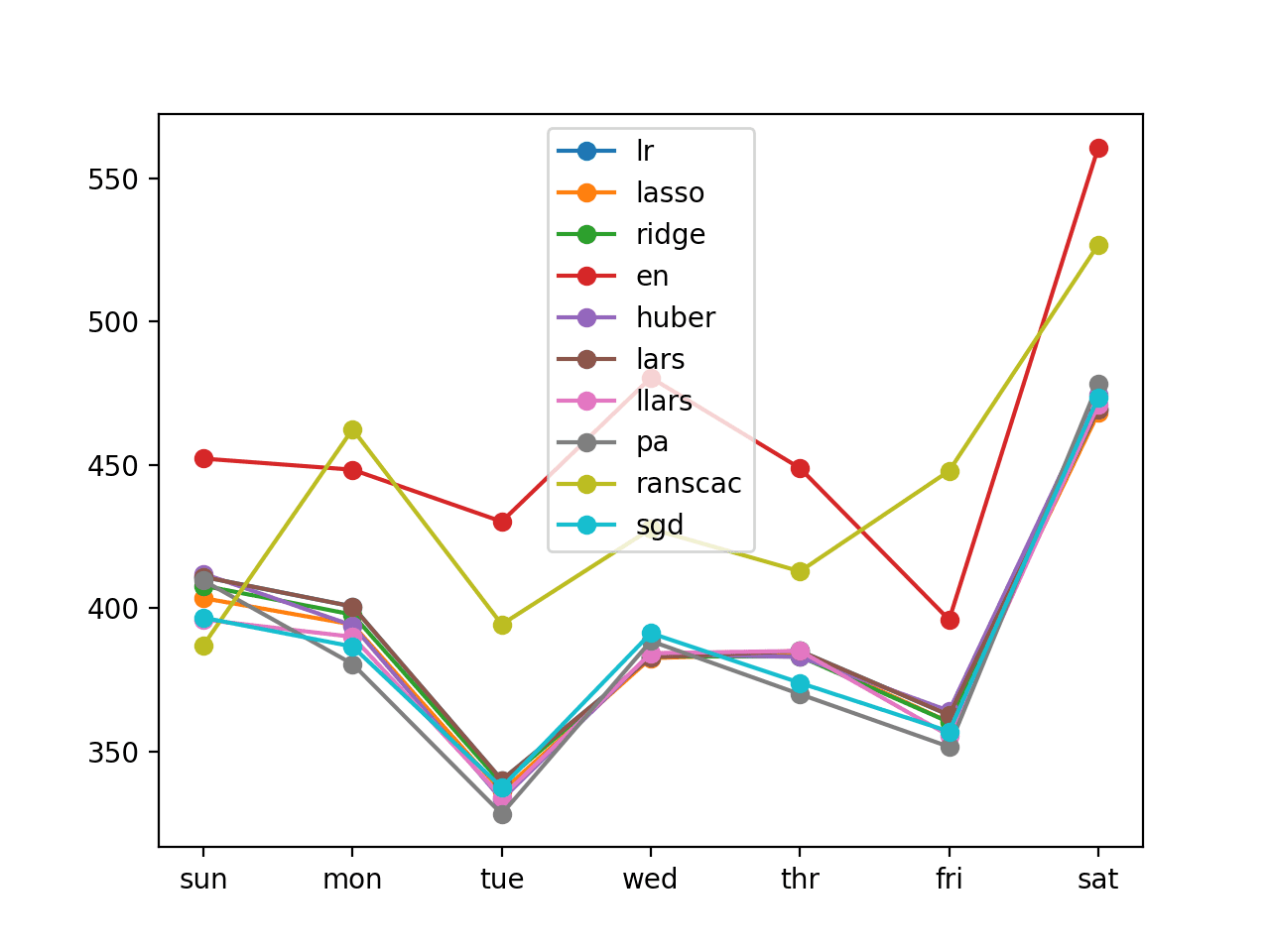
We can see that generally the per-lead time approach resulted in better performance than the per-day version. This is likely because the approach made more of the training data available to the model.
A line plot of the per-day RMSE scores was again created.
Line Plot of Direct Per-Lead Time Multi-step Forecasts With Linear Algorithms
It may be interesting to explore a blending of the per-day and per-time step approaches to modeling the problem.
It may also be interesting to see if increasing the number of prior days used as input for the per-lead time improves performance, e.g. using two weeks of data instead of one week.
Extensions
This section lists some ideas for extending the tutorial that you may wish to explore.
Tune Models. Select one well-performing model and tune the model hyperparameters in order to further improve performance.
Tune Data Preparation. All data was standardized and normalized prior to fitting each model; explore whether these methods are necessary and whether more or different combinations of data scaling methods can result in better performance.
Explore Input Size. The input size was limited to seven days of prior observations; explore more and fewer days of observations as input and their impact on model performance.
Nonlinear Algorithms. Explore a suite of nonlinear and ensemble machine learning algorithms to see if they can lift performance, such as SVM and Random Forest.
Multivariate Direct Models. Develop direct models that make use of all input variables for the prior week, not just the total daily power consumed. This will require flattening the 2D arrays of seven days of eight variables into 1D vectors.
If you explore any of these extensions, I’d love to know.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Hi Jason, thanks for the excellent and informative article. How would we observe the (46) predicted values for each day?
Also, the objective was to answer the question: “Given recent power consumption, what is the expected power consumption for the week ahead?”
Therefore, how would we from these models create a 7 day future forecast?
I can only see the RSME values for each model, when I think it would also be beneficial to see the predicted values. For example, it is possible that the SGD model doesn’t capture the trend as well as another model, despite the fact it has the lowest overall RSME.
How would I go about using one of these models for future forecasting? Is this simply an extension of the script, or would we have to create a separate piece of code elsewhere?
Adding in: print predictions under the line: predictions = array(predictions), in the evaluate_model code does give me the predicted values, but as there are so many predictions the output is messy. Is there a way to obtain the average predicted value for each week?
Apologies for flooding you with replies. Inserting: print(sum(predictions)/len(test)) under the predictions = array(predictions) line does the job. However I am still unsure how future forecasting is achieved.
model = SGDRegressor(max_iter=1000, tol=1e-3)
model.fit(X_train, Y_train)
Y_new = model.predict(X_new)
# show the inputs and predicted outputs
for i in range(len(X_new)):
print(“X_train=%s, Predicted=%s” % (X_new[i], Y_new[i]))
I cannot work out what to define X_new as? Let’s say, I would like the predictions for the next 3 days (11/27/2010,11/28/2010 and 11/29/2010)? Also, would I need to drop the datetime column from Y_train?
The make predictions article linked is for Regression. Surely it could not be used for Time Series future forecasting, as we do not know any of the future values for any of the features?
thanks for the great posts – I’m new to Python and ML and I have pretty much learned all I know by working through your examples.
In regards to this one, I tried 3 non-linear sklearn models (RandomForestReg, SVR, ExtraTreesReg) with similar results (RSME ~400), hence non of them better than SGD.
I have been wondering if you have done an example for Multi-step multi-variate time-series forecasting where a forecast of the input variables is available.
E.g. 10-day weather forecast (Wind, Rain, Temp, etc.) is available and model should predict how many people go to the movies 😉 – or something like that.
If you didn’t already do such an example it would be great if you would consider doing one.
Thanks for your blog, it helps a lot for my research.
Here is a question for this blog def get_models() function. Can I use my own constructed LSTM model for this? Because I want to compare the results of different models with the actual value.
Thanks!
thanks a lot of your amazing tutorials. I got a question if I want to use these machine learning models but with multivariate input.
I modified the code to be able to fit the different variables by reshaping the arrays. However,
def forecast(model, input_x, n_input, n_features):
yhat_sequence = list()
input_data = [x for x in input_x]
for j in range(7):
# prepare the input data
X = array(input_data[-n_input:]).reshape(1, n_input*n_features)
# make a one-step forecast
yhat = model.predict(X)
# add to the result
yhat_sequence.append(yhat[0])
# add the prediction to the input
input_data.append(yhat)
return yhat_sequence
There is something that I dont understand because after calling model.predict(X), X is (7,7) reshaped array, I now get an array of 7 values and store the the first one ‘yhat[0]’ as we want to predict the global consumption of energy.
But then after updating input_data and during the 2nd loop my new X is only an array (7,). but my list input_data contains the new vector added. Hard for me to understand.
Do you know where the problem could come from ? Seems like the new array created for X contains all 7 arrays of the observations.
Thank you for an impressive tutorial. I was reading an article titled “Short-Term Residential Load Forecasting Based on Resident Behaviour Learning”, where the authors converted the current reading(collected every minute) into Ampere hour for every 30 minutes.
My question is if we have the current reading (every minute) then how we will convert it into Ampere hour for every 30 minutes.
I contacted the authors of the article but I didn’t hear from them.
I would really appreciate your help in this regard.
In the paper, authors used the following sentence, “We convert the current reading into Ampere hour for every 30 minutes to mimic commonly available smart meter data.”
To apply the Multivariate Direct Models. you said that it will require flattening the 2D arrays of seven days of eight variables into 1D vectors. does this mean:
I tried and I didn’t find any example of Multivariate Direct Models. The reason why I am in doubt is that for each time step and each single model when fitting the model, model.fit(train_x, train_y) I get (7*n_features) coefficients in model.coef_ (for lm for example) and I should get only just 7 coefs (1 for each time step) isn’t it? Thank you!
My training data has the following shape: (100, 3, 11), and obviously its multivariate. You have said that in this case, we must flatten the 2D array to 1D, is it correct if we do this:
train_x = train_x.reshape((train_x.shape[0], train_x.shape[1]*train_x.shape[2])) prior to fitting the model ??
But then if we do this, the data will have the shape: (100, 33), however the number of features is only 11.
I tried endlessly to search for examples online but unfortunately I found None.
Why do i get a different values even when I copied all of the code exactly? Furthermore I notice the difference between my ranscac value and yours is quite significant. Can you please explain to me why the value is off? Thanks!
Thanks for the useful article. I also bought your time-series bundle.
I am trying to wrap my head around an extension of this model:
Suppose we have the following data sets available:
1) The hourly electricity consumption of 1000 households over one year,
2) The per kWh price for each of these households which changed from being a fixed per kWh price to a time-based price which changes during the day from the first six months to the next six-month period,
3) Demographics and appliance numbers for each household,
4) Hourly temperature during the year the electricity consumption is measured.
We want to predict the hourly consumption of a household for the next month under a new time-based pricing scheme, given the hourly electricity consumption data, demographics, appliance numbers for the household over one year under fixed pricing.
Do you have any suggestions into how to go about solving this problem? Could you suggest any resources which might be helpful?
Yes, I recommend exploring multiple different framings of the problem in order to discover what works well/best for your specific dataset.
Perhaps try modeling per customer/per customer groups/and across all customers and evaluate how models perform, to confirm assumptions that modeling across customers improves skill?
Perhaps try linear vs nonlinear methods to prove that complex methods add skill?
Perhaps try univariate vs multivariate data to confirm additional data improves skill?
my data is multivariate (columns = Date, consumption building1, consumption building2, consumption building2 )
I want to predict the weekly consumption of each building and then compare in one graph.
how can I change this function to predict each variable and then compare?
def to_series(data):
# extract just the total power from each week
series = [week[:, 0] for week in data]
# flatten into a single series
series = array(series).flatten()
return series
Dr Brownlee, first of all thanks for all your work you published. I started from 0 and now i can understand what is a Time Series Forecasting and how to handle it ( more or less 🙂 ).
2 questions:
1) when you call the pipeline, you force the dataset in “make_pipeline(model)” to standardization and normalization. Is that correct use both, or i can choose just one of them?
2)when you get back the prediction values and RMSE, are they rescaled as original dataset or you don’t use the inverse_trasform and they are in scaled shape?
I have tried invert transform form the prediction made in scikit_predict functions(I am using this code for 30 days multi step instead of 7 days). Is there piece of code or a function which i can use to invert the forecasted predictions.
Hello Jason, thanks for the reply, are there any tutorials that handle multivariate multi-step time series forecasting using the linear models you used in this post ?
I realize that here, we did not split the test data into the regular: X_test & y_test, but rather, we were passing to model.predict() the last window from X_train. Can we split the test data into X_test & y_test, and do model.predict(X_test) ? or is this method not appropriate for this kind of problems ?
In the Extensions section of this post, you talked about developing Multivariate Direct models. One cannot develop a Multivariate Recursive model right ?
I was actually trying to develop the multivariate recursive, but in the forecast() function of the recursive, we do at the end input_data.append(yhat), but yhat is a single variable and input_data is multivariate and it does not expect a single value, is that true ? is there a way to come around this ?
Thanks in advance Jason, your tutorials are one of a kind and very helpful.
Hello again Jason, sorry for asking too many questions,
When our data is univariate, should we consider doing any kind of normalization/standardization to the data and then inverse normalization/standardization after forecasting? Or it doesn’t matter since the data is univariate and we have only one column?
i am having a time series dataset with 3 inputs and a single output for 6 months(jan to june) at a interval of 30 seconds each,
is there any way to forecast for the july and august month?
i am a student and i am thinking of taking some of your courses..
Can i find in your courses an introduction about multi-step forecasting household consumption using SVR/ SVM or LS-SVM???
Here, since the number of previous time steps to take is equal to the number of time steps ahead to forecast, you split both train and test using the same number (which is 7):
1
2
3
4
5
6
7
def split_dataset(data):
# split into standard weeks
train,test=data[1:-328],data[-328:-6]
# restructure into windows of weekly data
train=array(split(train,len(train)/7))
test=array(split(test,len(test)/7))
returntrain,test
but if they are different (not both 7), how should we do it (i.e. for example, if we want to take two previous weeks to predict one week ahead) ???
Hi Jason, thanks for your great tutorial. I’m currently doing a time series project for my studies so i have been reading a lot of your stuf regarding that topic. However, I did not find a tutorial that contains information about the problem I am currently facing.
To summarise my problem:
The task is to predict the sales volume of ten products.
For this I have a dataset with sales figures for one year. The dataset therefore has 365 lines (one for each day).
Furthermore it has a number of features like:
– Is public holiday: Indicates whether the respective day is a public holiday.
– Temperature: Indicates the temperature on the corresponding day.
– etc.
In addition, the dataset has one column for each of the ten products with the corresponding sales volume of the day. So I’m looking for a model that gives me an output vector. In addition, the model should be able to predict several days into the future (multi-step).
So far i could not find a tutorial that brings all that together. Do you have a recommendation for one of you Tutorials that fits best to my Problem?
Hi, Jason.
II’m getting a lot of help through your blog. I’m really appreciate it.
I have a question for recursive model.
Could I use recursive methodology to LSTM?
In the above article, you used the statistical methodology (ex.lasso, ridge)
Can we use it to LSTM?
HI Jason
i have a scenario with 365 datapoints (1 per day) for past year and need to predict the value for next 365 days. Can you please throw some light on what the X and Y could be. Can we use a rolling time window, if so what would be the length
Atul
why do you need to retrain the model (see below) every time you append a new test time step to the initial history? can’t we just train the model only in the first place (only on the initial history)?
Thanks
# evaluate a single model
def evaluate_model(model, train, test, n_input):
# history is a list of weekly data
history = [x for x in train]
# walk-forward validation over each week
predictions = list()
for i in range(len(test)):
# predict the week
yhat_sequence = sklearn_predict(model, history, n_input)
# store the predictions
predictions.append(yhat_sequence)
# get real observation and add to history for predicting the next week
history.append(test[i, :])
predictions = array(predictions)
# evaluate predictions days for each week
score, scores = evaluate_forecasts(test[:, :, 0], predictions)
return score, scores
# split a univariate dataset into train/test sets
def split_dataset(data):
# split into standard weeks
train, test = data[1:-328], data[-328:-6]
# restructure into windows of weekly data
train = array(split(train, len(train)/7))
test = array(split(test, len(test)/7))
return train, test
Jason, kindly help me, I don’t understand how you splitted your data. What figure is the -328 and which one is the -1 and -6. I will be grateful if you explain to me. Thanks for your great job
I am still not cleared. Can you tell me how you calculated for the -328. Or Supposing I’m using
Training set which starts from 16 April 2017 sunday to 30 September 2017 Saturday making 24 weeks for training and 1 october 2017 sunday to 2 December 2017 Saturday making 9 weeks for testing. Can you please tell me the number to use for the splitting. It keeps giving me errors. Please i’m not too strong in this field but your tutorial is really making me a pro. Kindly explain to me like a newbie. Thanks
Alright, I’ve tried to specify mine too but it keeps giving me:
‘array split does not result in an equal division’)
ValueError: array split does not result in an equal division.
Can you please help me specify my data.
The data starts from 15th April 2017 and ends in 5th December 2017. I want to use 24 weeks for the training and 9 weeks for testing.
And since I am using standard weeks which start from sunday, I started from the 16th of April 2017 to 31st October which was Saturday. And the test starts from 1st October to 2nd December which is the last Saturday. I’ve tried several ways but it keeps giving error. I will be so grateful if you assist me. Thanks
However I don’t know much about python & R. but I’m willing to learn.
I wanted to build a model which can predict how much % of sales forecast can be actually achieved given the % of forecast sales that has been realised till date.
For example, if I have a forecast of 10000 units for the whole month and its 10th day of the month, and only 2000 (20% of 10000) units have been sold, I want a model that can predict, how much % of the forecast I can achieve at the end of the month.
I have 3 years of daily demand data of around 500 odd SKUs.
Can you help me out to build a model?
I also want to tell the model about certain holidays that keeps on changing by a fortnight or so every year, so that the model has that kind of dynamic capability.
Perhaps you can frame it as a forecast of the expected total sales for the month given sales over the last n days, then covert predictions to percentages?
you are using only the first column “global_active_power” for training and evaluation right? So why are you creating an additional “column sub_metering_4” when it is not used anyway?
hi,
thanks for sharing beautiful excercise. I was trying to apply the same on my use case.
where i have to predict for next 72 hours data and I have hourly level data.
so first I am trying to do it for 24 hours. for that I have taken n_input as 24, in order to predict for next 24 hours. m i going in the right direction?
Also How much time will it take to run all the 10 models?
I tried but it kept on running for more than an hour so i stopped in between, worrying that might be doing something wrong..
Also one question- I have to do future forecasting for more than one variable. 6 columns to be specific.- have to do time series for next 72 hours for 6 columns. So can it be done for multivariate ?
Thank you very much for the great resources & examples. In using these resources, I have built a model from scratch (thanks to you!) but think I need some help.
My objective is similar to the one described above, using historical data to predict “today’s” output. I am trying to predict how long specific flights will be based on numerical weather factors.
Up until this point, I have been feeding in my dataset & manually making the training set ALL data from inception to T-1 & the test set becomes the data rows that have today’s date. This is somewhat accurate but I wish to have my model start in the middle of my data and “walk forward” up until today.
There is a small wrinkle, the flights being tracked & predicted each day changes. Is it possible to create a walk forward multi step prediction model when the data you’re predicting changes each day?
For instance, let’s say we’re tracking just 10 total planes. Planes 1, 3, &9 are flying today, I would want the model to go back in time to the mid point, and predict the times for 1 3 & 9 based off of their historical performance. Does this make sense? The specific factors for each flight do not change, just the planes that are flying that specific day change.
Thanks for this informative tutorial. Could you help me where can I found a tutorial that has all the steps to ( check seasonality, trend ..etc. and apply ( training, validation and testing ) split into the data. then fitting the model and do the forecast for time-series dataset, please?
Can you please explain what is the exact meaning of the lines calculating overall RMSE? I mean the following par
s = 0
for row in range(actual.shape[0]):
for col in range(actual.shape[1]):
s += (actual[row, col] – predicted[row, col])**2
score = sqrt(s / (actual.shape[0] * actual.shape[1]))
Regards,
Karolina
Hi, can we use direct approach for ARIMA model?
If yes, is there any tutorial for the same?
If not, how can I train an ARIMA model to do 4-step prediction?
I have used direct approach for ML models, MLP and LSTM. In that case, we reorganize the data from ‘series’ to ‘supervised’ format. So it’s straightforward on how to train and test ML models.
For ARIMA, however, we give entire series as training set and use predict fucntion to get one or more out-of-sample predictions.
So, here’s my question, direct method requires us to train multi mudels for different time steps, so how can I organize data for different models?
Hello sir,
Great work and thanks for sharing. I am getting completely confused when I am trying to use multivariate input to a single model to make recursive predictions. Any help on that would be appreciated.
Let’s say I have 8 input features (x variable), and 1 output prediction (y variable), I am planning to use this 1 prediction in a recursive fashion to predict next 6 values, in the way you mentioned I will be shifting my input 1 step to include my current prediction to make next prediction right? But what if I want to recursively forecast this way?
Input features (8 values)——————————————————–>predict (1st value)
Input features (8 values) + predict (1st value)——————————–>predict (2nd value)
Input features (8 values) + predict (1st value) + predict (2nd value)——->predict (3rd value)
I probably have misunderstooded the “recursive multistep” concept. In the code you shared with us (def evaluate_model(train, test) ==> # get real observation and add to history for predicting the next week) wasn’t it supposed to use yhat PLUS somehow-I-don’t-know-how predicted inputs for predicting next week yhat?
In real data out-of-sample predictions, how would we perform recursive multistep predictions? Can you point a direction for custom code to use the predicted output as an input on subsequent forecasts?
I have a question : how should we proceed if we want to include some explanatory variables (like temperature,price of energy…) in addition to the 7 lags in order to predict the total active power for the next 7 days ?
Thank you very much, I’ve just read the two articles, I’ll use them.
In fact, I was trying to predict the demand for energy over the next 24 hours and I have variables such as the energy produced by different sources at each hour, the price of energy at each hour, as well as the climatic variables (temperature, wind speed, pressure, precipitation…) at each hour. With your articles, I now have a rough idea of how to do this, but there are still uncertainties about for example how many delays I should use.
Hi Jason! I am currently implementing the recursive multi-step forecasting technique on multivariate data. It has given me extremely good results, so thank you!
However, I have a fear about overfitting. How can I tell if my model is overfit or not?
If you have poor performance on hold out data – maybe your overfitting. You can then investigate/diagnose the model with learning curves (which can be hard to do for time series data with walk-forward validation).
Just focus on optimizing out of sample performance.
Also in investigating the code, I am a bit confused since we fit on train_x and then we predict using train_x[-1, :]. Doesn’t that mean we are predicting on data that we already fitted the model on?
I have another question then – is there a need to detrend/deseasonalize the data before setting it up as a machine learning problem? I ask this because it seems like we are adding the correlations back in by changing the features to lagged features.
you have explained well, but from coding standards point of view, you have written in a verybad way. Its very difficult to understand which method calling which method. you must atleast make sure atleast you consume all methods from one main method in a sequential manner
Hi,
Hope you are doing well. How can we change the prediction from weekly to daily?
I tried to make the dataset with the hourly consumptions, and divide it into the 24 datapoints frames.
Is it okay to compute RMSE across all multi-step forecasted values? That is, assuming you want to make h+5 forecast periods, you compute RMSE for each h forecast and take average RMSE across all forecasts (each RMSE per forecast horizon). If so, could you please direct me to papers or resources that dealt with the said approach?
It should be OK mathematically (I believe you know how to implement such function) but I don’t think it make sense because the prediction into the future are less and less accurate. Hence you’re like combining different things into one metric.
Hi Jason,
I just purchased your book, and started working on univariate multi-step lstm for the power usage dataset. I am trying to adjust your code to my task. I have 48 months sequence of target variable values (with 6 features). I need to predict last 12 target values based on 36 months training set. How should I reshape my input data? I believe, I should use n_input=36, n_out=12, and n_features=6. Alternative variant: n_input=12. Please, suggest.
Hi Jason, thank you so much for this tutorial, it is extremely helpful to an ML beginner such as myself.
As a power engineer I have just one remark – while aggregating initial data by day you added up all of the active power values in kW, which makes no physical sense. We could either calculate average active power value over each day, or calculate total energy consumed in kWh during each minute (active power [kW] / 60), which then could be aggregated by day, giving us the actual total power consumed each day.
I actually did similar model comparison to yours by creating ‘Total consumption [kWh]’ column in the daily dataset and validated all the models on how good they were in predicting household’s daily electricity demand. These are my results:








How do you handle seasonality in the time series when using machine learning?
You can calculate a seasonal difference or let the model learn the relationship.
When model use recursive forecasting strategy, I think the history should use
” history.append(yhat)”
would you explan why using:” history.append(test[i, :])” in your model?
I explain the different strategies and when to use them here:
https://machinelearningmastery.com/multi-step-time-series-forecasting/
Hi Jason, thanks for the excellent and informative article. How would we observe the (46) predicted values for each day?
Also, the objective was to answer the question: “Given recent power consumption, what is the expected power consumption for the week ahead?”
Therefore, how would we from these models create a 7 day future forecast?
You can choose a model and configuration, train a final model and start using it to make forecasts.
Perhaps I don’t follow, what problem are you having exactly?
I can only see the RSME values for each model, when I think it would also be beneficial to see the predicted values. For example, it is possible that the SGD model doesn’t capture the trend as well as another model, despite the fact it has the lowest overall RSME.
How would I go about using one of these models for future forecasting? Is this simply an extension of the script, or would we have to create a separate piece of code elsewhere?
You can make a prediction by calling model.predict()
In fact, I show how and give a function to do it.
Which part is challenging? I’ll do my best to help.
I have tried the following into a cell after we have plotted all the models:
for model in models.items():
model.predict(test)
But it comes back with the error: AttributeError: ‘tuple’ object has no attribute ‘predict’.
I do not know where I would insert model.predict(), as every “section” kind of relies on the “section” above it. Likewise with the future forecasting.
I recommend fitting a new final model on all available data and using it to make a prediction.
More here:
https://machinelearningmastery.com/make-predictions-scikit-learn/
Adding in: print predictions under the line: predictions = array(predictions), in the evaluate_model code does give me the predicted values, but as there are so many predictions the output is messy. Is there a way to obtain the average predicted value for each week?
Apologies for flooding you with replies. Inserting: print(sum(predictions)/len(test)) under the predictions = array(predictions) line does the job. However I am still unsure how future forecasting is achieved.
Hi Jason,
Really cool and interesting content we have here! Congrats on the great job you are doing!
Do you have any reference about what you mentioned “Multivariate Direct Models”?
Many Thanks
Yes, I have examples of direct models here:
https://machinelearningmastery.com/multi-step-time-series-forecasting-with-machine-learning-models-for-household-electricity-consumption/
Thanks for the advice Jason. I am almost there…
from sklearn.linear_model import SGDRegressor
from pandas import read_csv
df = read_csv(‘household_power_consumption_days.csv’, header=0, infer_datetime_format=True, parse_dates=[‘datetime’], index_col=[‘datetime’])
X_train = df.drop([‘Global_active_power’],axis=1)
Y_train = df[‘Global_active_power’]
model = SGDRegressor(max_iter=1000, tol=1e-3)
model.fit(X_train, Y_train)
Y_new = model.predict(X_new)
# show the inputs and predicted outputs
for i in range(len(X_new)):
print(“X_train=%s, Predicted=%s” % (X_new[i], Y_new[i]))
I cannot work out what to define X_new as? Let’s say, I would like the predictions for the next 3 days (11/27/2010,11/28/2010 and 11/29/2010)? Also, would I need to drop the datetime column from Y_train?
The make predictions article linked is for Regression. Surely it could not be used for Time Series future forecasting, as we do not know any of the future values for any of the features?
Xnew is any input data required to make a prediction.
I explain exactly how to make a prediction here:
https://machinelearningmastery.com/faq/single-faq/how-do-i-make-predictions
But we may have no input data to set as X_new. Future forecasts rely solely on the present data.
You must frame your problem in such a way that the data you do have can be used to make a prediction.
Hi Jason,
thanks for the great posts – I’m new to Python and ML and I have pretty much learned all I know by working through your examples.
In regards to this one, I tried 3 non-linear sklearn models (RandomForestReg, SVR, ExtraTreesReg) with similar results (RSME ~400), hence non of them better than SGD.
I have been wondering if you have done an example for Multi-step multi-variate time-series forecasting where a forecast of the input variables is available.
E.g. 10-day weather forecast (Wind, Rain, Temp, etc.) is available and model should predict how many people go to the movies 😉 – or something like that.
If you didn’t already do such an example it would be great if you would consider doing one.
I have some examples in the deep learning for time series book I believe.
Also, checkout the ‘air pollution’ examples here:
https://machinelearningmastery.com/start-here/#deep_learning_time_series
hanks for the great posts .i got the error of
Traceback (most recent call last):
File “”, line 159, in
models = get_models()
File “”, line 70, in get_models
models[‘pa’] = PassiveAggressiveRegressor(max_iter=1000, tol=1e-3)
TypeError: __init__() got an unexpected keyword argument ‘max_iter’
Therefore, what should i do?
I have some suggestions here:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Thanks for your blog, it helps a lot for my research.
Here is a question for this blog def get_models() function. Can I use my own constructed LSTM model for this? Because I want to compare the results of different models with the actual value.
Thanks!
It might be better to develop a separate framework for evaluating LSTMs.
I have tons of examples on the blog. Start here:
https://machinelearningmastery.com/start-here/#deep_learning_time_series
Hello Jason,
thanks a lot of your amazing tutorials. I got a question if I want to use these machine learning models but with multivariate input.
I modified the code to be able to fit the different variables by reshaping the arrays. However,
def forecast(model, input_x, n_input, n_features):
yhat_sequence = list()
input_data = [x for x in input_x]
for j in range(7):
# prepare the input data
X = array(input_data[-n_input:]).reshape(1, n_input*n_features)
# make a one-step forecast
yhat = model.predict(X)
# add to the result
yhat_sequence.append(yhat[0])
# add the prediction to the input
input_data.append(yhat)
return yhat_sequence
There is something that I dont understand because after calling model.predict(X), X is (7,7) reshaped array, I now get an array of 7 values and store the the first one ‘yhat[0]’ as we want to predict the global consumption of energy.
But then after updating input_data and during the 2nd loop my new X is only an array (7,). but my list input_data contains the new vector added. Hard for me to understand.
Do you know where the problem could come from ? Seems like the new array created for X contains all 7 arrays of the observations.
Thanks for your help.
Perhaps this tutorial will help you to get started:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-time-series-forecasting/
Hey Jason,
Thank you for an impressive tutorial. I was reading an article titled “Short-Term Residential Load Forecasting Based on Resident Behaviour Learning”, where the authors converted the current reading(collected every minute) into Ampere hour for every 30 minutes.
My question is if we have the current reading (every minute) then how we will convert it into Ampere hour for every 30 minutes.
I contacted the authors of the article but I didn’t hear from them.
I would really appreciate your help in this regard.
Here is a link to the article https://ieeexplore.ieee.org/document/7887751
Perhaps they resampled the observations?
In the paper, authors used the following sentence, “We convert the current reading into Ampere hour for every 30 minutes to mimic commonly available smart meter data.”
What you conclude from this statement.
Thanks.
Not sure off the cuff, perhaps contact the authors?
To apply the Multivariate Direct Models. you said that it will require flattening the 2D arrays of seven days of eight variables into 1D vectors. does this mean:
train_x = train_x.reshape((train_x.shape[0],train_x.shape[1]*train_x.shape[2]))
Do you have an example where you applied Multivariate Direct Models?
Thank you!
Yes, I believe that is correct.
I’m not sure if I have exampels no the blog, maybe. Try a search.
I tried and I didn’t find any example of Multivariate Direct Models. The reason why I am in doubt is that for each time step and each single model when fitting the model, model.fit(train_x, train_y) I get (7*n_features) coefficients in model.coef_ (for lm for example) and I should get only just 7 coefs (1 for each time step) isn’t it? Thank you!
You will have one input for each time series at each time step.
If you have 7 days of input and 3 time series, that is 21 inputs that need 21 coefficients in a linear model.
Hello Jason,
My training data has the following shape: (100, 3, 11), and obviously its multivariate. You have said that in this case, we must flatten the 2D array to 1D, is it correct if we do this:
train_x = train_x.reshape((train_x.shape[0], train_x.shape[1]*train_x.shape[2])) prior to fitting the model ??
But then if we do this, the data will have the shape: (100, 33), however the number of features is only 11.
I tried endlessly to search for examples online but unfortunately I found None.
Thanks in advance.
Yes, because each time step has 11 features and there are 3 time steps, there for 3*11 is 33.
Hi Jason,
I tried to follow your tutorial on Direct Lead Time Approach but I get a different values:
Defined 10 models
lr: [410.927] 463.8, 381.4, 351.9, 430.7, 387.8, 350.4, 488.8
lasso: [408.440] 458.4, 378.5, 352.9, 429.5, 388.0, 348.0, 483.5
ridge: [403.875] 447.1, 377.9, 347.5, 427.4, 384.1, 343.4, 479.7
en: [454.263] 471.8, 433.8, 415.8, 477.4, 434.4, 373.8, 551.8
huber: [409.500] 466.8, 380.2, 359.8, 432.4, 387.0, 351.3, 470.9
lars: [410.927] 463.8, 381.4, 351.9, 430.7, 387.8, 350.4, 488.8
llars: [406.490] 453.0, 378.8, 357.3, 428.1, 388.0, 345.0, 476.9
pa: [403.339] 437.0, 379.9, 364.0, 427.4, 391.8, 350.9, 460.1
ranscac: [491.196] 588.3, 454.6, 403.1, 522.8, 443.4, 403.7, 583.7
sgd: [403.982] 450.3, 377.0, 347.6, 427.8, 381.1, 345.6, 478.5
Why do i get a different values even when I copied all of the code exactly? Furthermore I notice the difference between my ranscac value and yours is quite significant. Can you please explain to me why the value is off? Thanks!
This is to be expected, I explain more here:
https://machinelearningmastery.com/faq/single-faq/why-do-i-get-different-results-each-time-i-run-the-code
Hi Jason, I am new to this so excuse the dumb question. What is a directory? Where do I write all the code you provide here? Thanks
You can copy the code into a text file and save it as a new file with a .py extension:
https://machinelearningmastery.com/faq/single-faq/how-do-i-copy-code-from-a-tutorial
You can then open the command prompt and run the script:
https://machinelearningmastery.com/faq/single-faq/how-do-i-run-a-script-from-the-command-line
The current working directory is the directory where you saved the file.
I hope that helps.
Hi Jason,
Thanks for the useful article. I also bought your time-series bundle.
I am trying to wrap my head around an extension of this model:
Suppose we have the following data sets available:
1) The hourly electricity consumption of 1000 households over one year,
2) The per kWh price for each of these households which changed from being a fixed per kWh price to a time-based price which changes during the day from the first six months to the next six-month period,
3) Demographics and appliance numbers for each household,
4) Hourly temperature during the year the electricity consumption is measured.
We want to predict the hourly consumption of a household for the next month under a new time-based pricing scheme, given the hourly electricity consumption data, demographics, appliance numbers for the household over one year under fixed pricing.
Do you have any suggestions into how to go about solving this problem? Could you suggest any resources which might be helpful?
Yes, I recommend exploring multiple different framings of the problem in order to discover what works well/best for your specific dataset.
Perhaps try modeling per customer/per customer groups/and across all customers and evaluate how models perform, to confirm assumptions that modeling across customers improves skill?
Perhaps try linear vs nonlinear methods to prove that complex methods add skill?
Perhaps try univariate vs multivariate data to confirm additional data improves skill?
Does that help?
Yes, I will start with per-customer linear model with univariate data and go from there. Thanks!
Sounds good!
Hi Jason,
Thanks for this tutorial.
my data is multivariate (columns = Date, consumption building1, consumption building2, consumption building2 )
I want to predict the weekly consumption of each building and then compare in one graph.
how can I change this function to predict each variable and then compare?
def to_series(data):
# extract just the total power from each week
series = [week[:, 0] for week in data]
# flatten into a single series
series = array(series).flatten()
return series
thanks
Kind Regards
I’m eager to help, but I don’t have the capacity to write code for you.
ok, thanks for the reply
The function name is wrong, it`s different from the complete example.
The forecasts made by the model are then evaluated against the test dataset using the previously defined evaluate_forecasts() function.
What do you mean exactly?
Can you please elaborate?
Dr Brownlee, first of all thanks for all your work you published. I started from 0 and now i can understand what is a Time Series Forecasting and how to handle it ( more or less 🙂 ).
2 questions:
1) when you call the pipeline, you force the dataset in “make_pipeline(model)” to standardization and normalization. Is that correct use both, or i can choose just one of them?
2)when you get back the prediction values and RMSE, are they rescaled as original dataset or you don’t use the inverse_trasform and they are in scaled shape?
Thank you in advance.
Typically just one scaling is required.
In general, I recommend inverting the transform to get back to original units.
Hi Jason, Thanks for Sharing this article.
I am still trying to figure out the answers to the above questions asked by Salvatore.
It looks like both Standardization and Normalization is used in your code.Why do we use both the process?
Second things, are the RMSE value generated in Standardized form they are back to original form
Yes, we standardize to a unit gaussian, then normalzie the values to [0,1].
Try modeling with and without and compare performance.
Yes, the forecasts are scaled, and the scaling must be inverted to return to the original units.
Hi Jason, Thanks for the quick response.
I have tried invert transform form the prediction made in scikit_predict functions(I am using this code for 30 days multi step instead of 7 days). Is there piece of code or a function which i can use to invert the forecasted predictions.
Thanks in advance.
Yes, I give an example in this post:
https://machinelearningmastery.com/machine-learning-data-transforms-for-time-series-forecasting/
Hi Jason,
Can we use these same models (Linear Regression, Lasso, Ridge, etc.) in order to make a one-shot multi-step prediction ?
Perhaps if they were used in a direct mode, e.g. one model per series, or you wrote custom code to achieve the desired result.
Hello Jason, thanks for the reply, are there any tutorials that handle multivariate multi-step time series forecasting using the linear models you used in this post ?
Not linear models, but I do show how with an MLP, CNN and LSTM:
https://machinelearningmastery.com/start-here/#deep_learning_time_series
Hello Jason,
I realize that here, we did not split the test data into the regular: X_test & y_test, but rather, we were passing to model.predict() the last window from X_train. Can we split the test data into X_test & y_test, and do model.predict(X_test) ? or is this method not appropriate for this kind of problems ?
Yes, you can fit the model and use it for making predictions beyond the end of the dataset.
model.predict() with the last set of observations as input.
Hello Jason,
In the Extensions section of this post, you talked about developing Multivariate Direct models. One cannot develop a Multivariate Recursive model right ?
I was actually trying to develop the multivariate recursive, but in the forecast() function of the recursive, we do at the end input_data.append(yhat), but yhat is a single variable and input_data is multivariate and it does not expect a single value, is that true ? is there a way to come around this ?
Thanks in advance Jason, your tutorials are one of a kind and very helpful.
You could, but the model must predict all features for each time step.
Hello again Jason, sorry for asking too many questions,
When our data is univariate, should we consider doing any kind of normalization/standardization to the data and then inverse normalization/standardization after forecasting? Or it doesn’t matter since the data is univariate and we have only one column?
Yes, it can help.
Hi Jason,
i am having a time series dataset with 3 inputs and a single output for 6 months(jan to june) at a interval of 30 seconds each,
is there any way to forecast for the july and august month?
Yes, perhaps start here:
https://machinelearningmastery.com/how-to-develop-a-skilful-time-series-forecasting-model/
Hey Jason,
i am a student and i am thinking of taking some of your courses..
Can i find in your courses an introduction about multi-step forecasting household consumption using SVR/ SVM or LS-SVM???
I don’t have examples of time series forecasting using SVM, sorry.
what about ANN?
Yes, I have a tutorial on this, use the search box for “MLP”.
Hello Jason,
Do you have a tutorial about single step forecasting ?
Yes, many, perhaps start here:
https://machinelearningmastery.com/start-here/#deep_learning_time_series
Hi Jason,
Here, since the number of previous time steps to take is equal to the number of time steps ahead to forecast, you split both train and test using the same number (which is 7):
but if they are different (not both 7), how should we do it (i.e. for example, if we want to take two previous weeks to predict one week ahead) ???
Good question.
You would have to write your own modified function for preparing the data.
Hi Jason, thanks for your great tutorial. I’m currently doing a time series project for my studies so i have been reading a lot of your stuf regarding that topic. However, I did not find a tutorial that contains information about the problem I am currently facing.
To summarise my problem:
The task is to predict the sales volume of ten products.
For this I have a dataset with sales figures for one year. The dataset therefore has 365 lines (one for each day).
Furthermore it has a number of features like:
– Is public holiday: Indicates whether the respective day is a public holiday.
– Temperature: Indicates the temperature on the corresponding day.
– etc.
In addition, the dataset has one column for each of the ten products with the corresponding sales volume of the day. So I’m looking for a model that gives me an output vector. In addition, the model should be able to predict several days into the future (multi-step).
So far i could not find a tutorial that brings all that together. Do you have a recommendation for one of you Tutorials that fits best to my Problem?
You can try modeling each product separeatly or all products together.
You could try modeling the sales as a univariate problem or with all variates.
I would also encourage you to try classical linear time series methods as well as machine learning and deep learning methods.
This framework will help:
https://machinelearningmastery.com/how-to-develop-a-skilful-time-series-forecasting-model/
Get started with simple time series here:
https://machinelearningmastery.com/start-here/#timeseries
Get started with advanced time series here:
https://machinelearningmastery.com/start-here/#deep_learning_time_series
Does that help?
Hi, Jason.
II’m getting a lot of help through your blog. I’m really appreciate it.
I have a question for recursive model.
Could I use recursive methodology to LSTM?
In the above article, you used the statistical methodology (ex.lasso, ridge)
Can we use it to LSTM?
Thank you
I don’t see why not.
HI Jason
i have a scenario with 365 datapoints (1 per day) for past year and need to predict the value for next 365 days. Can you please throw some light on what the X and Y could be. Can we use a rolling time window, if so what would be the length
Atul
Perhaps try a linear model like an ARIMA or SARIMA:
https://machinelearningmastery.com/how-to-grid-search-sarima-model-hyperparameters-for-time-series-forecasting-in-python/
Hi Jason,
why do you need to retrain the model (see below) every time you append a new test time step to the initial history? can’t we just train the model only in the first place (only on the initial history)?
Thanks
# evaluate a single model
def evaluate_model(model, train, test, n_input):
# history is a list of weekly data
history = [x for x in train]
# walk-forward validation over each week
predictions = list()
for i in range(len(test)):
# predict the week
yhat_sequence = sklearn_predict(model, history, n_input)
# store the predictions
predictions.append(yhat_sequence)
# get real observation and add to history for predicting the next week
history.append(test[i, :])
predictions = array(predictions)
# evaluate predictions days for each week
score, scores = evaluate_forecasts(test[:, :, 0], predictions)
return score, scores
It is not required, it is the model evaluation scheme I chose to use.
Use the approach you believe is more appropriate for your problem.
# split a univariate dataset into train/test sets
def split_dataset(data):
# split into standard weeks
train, test = data[1:-328], data[-328:-6]
# restructure into windows of weekly data
train = array(split(train, len(train)/7))
test = array(split(test, len(test)/7))
return train, test
Jason, kindly help me, I don’t understand how you splitted your data. What figure is the -328 and which one is the -1 and -6. I will be grateful if you explain to me. Thanks for your great job
We clip off days so we are working with full weeks.
Then we use about the last 46 weeks as test data and the rest for train.
I am still not cleared. Can you tell me how you calculated for the -328. Or Supposing I’m using
Training set which starts from 16 April 2017 sunday to 30 September 2017 Saturday making 24 weeks for training and 1 october 2017 sunday to 2 December 2017 Saturday making 9 weeks for testing. Can you please tell me the number to use for the splitting. It keeps giving me errors. Please i’m not too strong in this field but your tutorial is really making me a pro. Kindly explain to me like a newbie. Thanks
However, the whole dataset starts from 15th April 2017 and ends at 5th Decemeber 2017.
I did not calculate it. I looked at the data and specified it precisely.
The split was somewhat arbitrary. You can choose to split your own data any way you wish.
Alright, I’ve tried to specify mine too but it keeps giving me:
‘array split does not result in an equal division’)
ValueError: array split does not result in an equal division.
Can you please help me specify my data.
The data starts from 15th April 2017 and ends in 5th December 2017. I want to use 24 weeks for the training and 9 weeks for testing.
And since I am using standard weeks which start from sunday, I started from the 16th of April 2017 to 31st October which was Saturday. And the test starts from 1st October to 2nd December which is the last Saturday. I’ve tried several ways but it keeps giving error. I will be so grateful if you assist me. Thanks
Perhaps experiment with your data and allocate one week at a time until you find the cause of the fault?
Hey Jason!
Its an excellent step by step post.
However I don’t know much about python & R. but I’m willing to learn.
I wanted to build a model which can predict how much % of sales forecast can be actually achieved given the % of forecast sales that has been realised till date.
For example, if I have a forecast of 10000 units for the whole month and its 10th day of the month, and only 2000 (20% of 10000) units have been sold, I want a model that can predict, how much % of the forecast I can achieve at the end of the month.
I have 3 years of daily demand data of around 500 odd SKUs.
Can you help me out to build a model?
I also want to tell the model about certain holidays that keeps on changing by a fortnight or so every year, so that the model has that kind of dynamic capability.
Thanks in advance!
That sounds like a fun project.
Perhaps you can frame it as a forecast of the expected total sales for the month given sales over the last n days, then covert predictions to percentages?
Hi Jason,
you are using only the first column “global_active_power” for training and evaluation right? So why are you creating an additional “column sub_metering_4” when it is not used anyway?
Consistency with the other tutorials on the same dataset.
hi,
thanks for sharing beautiful excercise. I was trying to apply the same on my use case.
where i have to predict for next 72 hours data and I have hourly level data.
so first I am trying to do it for 24 hours. for that I have taken n_input as 24, in order to predict for next 24 hours. m i going in the right direction?
Also How much time will it take to run all the 10 models?
Perhaps try it and see?
I tried but it kept on running for more than an hour so i stopped in between, worrying that might be doing something wrong..
Also one question- I have to do future forecasting for more than one variable. 6 columns to be specific.- have to do time series for next 72 hours for 6 columns. So can it be done for multivariate ?
Perhaps try a different model for each variable vs a single model for all variables and see what works best.
Hi Jason,
Thank you very much for the great resources & examples. In using these resources, I have built a model from scratch (thanks to you!) but think I need some help.
My objective is similar to the one described above, using historical data to predict “today’s” output. I am trying to predict how long specific flights will be based on numerical weather factors.
Up until this point, I have been feeding in my dataset & manually making the training set ALL data from inception to T-1 & the test set becomes the data rows that have today’s date. This is somewhat accurate but I wish to have my model start in the middle of my data and “walk forward” up until today.
There is a small wrinkle, the flights being tracked & predicted each day changes. Is it possible to create a walk forward multi step prediction model when the data you’re predicting changes each day?
For instance, let’s say we’re tracking just 10 total planes. Planes 1, 3, &9 are flying today, I would want the model to go back in time to the mid point, and predict the times for 1 3 & 9 based off of their historical performance. Does this make sense? The specific factors for each flight do not change, just the planes that are flying that specific day change.
Thanks,
John
Not sure I see the problem, sorry John.
Perhaps experiment with diffrent framings of the problem to better understand the nature of the prediction task?
Hi Jason,
Thanks for this informative tutorial. Could you help me where can I found a tutorial that has all the steps to ( check seasonality, trend ..etc. and apply ( training, validation and testing ) split into the data. then fitting the model and do the forecast for time-series dataset, please?
Each dataset and model is different, this might help:
https://machinelearningmastery.com/machine-learning-data-transforms-for-time-series-forecasting/
Hi Jason,
Can you please explain what is the exact meaning of the lines calculating overall RMSE? I mean the following par
s = 0
for row in range(actual.shape[0]):
for col in range(actual.shape[1]):
s += (actual[row, col] – predicted[row, col])**2
score = sqrt(s / (actual.shape[0] * actual.shape[1]))
Regards,
Karolina
RMSE across all multi-step forecasted values.
Hi, can we use direct approach for ARIMA model?
If yes, is there any tutorial for the same?
If not, how can I train an ARIMA model to do 4-step prediction?
Yes.
No, I don’t think I have a tutorial for ARIMA, but I do for ml models. You can search the blog.
I have used direct approach for ML models, MLP and LSTM. In that case, we reorganize the data from ‘series’ to ‘supervised’ format. So it’s straightforward on how to train and test ML models.
For ARIMA, however, we give entire series as training set and use predict fucntion to get one or more out-of-sample predictions.
So, here’s my question, direct method requires us to train multi mudels for different time steps, so how can I organize data for different models?
Internally, ARIMA is creating a supervised learning version of the problem with lag inputs.
Each model may require its own custom data preparation.
Hello sir,
Great work and thanks for sharing. I am getting completely confused when I am trying to use multivariate input to a single model to make recursive predictions. Any help on that would be appreciated.
Let’s say I have 8 input features (x variable), and 1 output prediction (y variable), I am planning to use this 1 prediction in a recursive fashion to predict next 6 values, in the way you mentioned I will be shifting my input 1 step to include my current prediction to make next prediction right? But what if I want to recursively forecast this way?
Input features (8 values)——————————————————–>predict (1st value)
Input features (8 values) + predict (1st value)——————————–>predict (2nd value)
Input features (8 values) + predict (1st value) + predict (2nd value)——->predict (3rd value)
It will require custom code to use the predicted output as an input on subsequent forecasts.
Greetings, Dr Brownlee!
I probably have misunderstooded the “recursive multistep” concept. In the code you shared with us (def evaluate_model(train, test) ==> # get real observation and add to history for predicting the next week) wasn’t it supposed to use yhat PLUS somehow-I-don’t-know-how predicted inputs for predicting next week yhat?
In real data out-of-sample predictions, how would we perform recursive multistep predictions? Can you point a direction for custom code to use the predicted output as an input on subsequent forecasts?
Thanks in advance!
You can configure the inputs to the model based on whatever data (inputs and predictions) you have at prediction time.
Hi Jason, thanks for this informative article.
I have a question : how should we proceed if we want to include some explanatory variables (like temperature,price of energy…) in addition to the 7 lags in order to predict the total active power for the next 7 days ?
You’re welcome.
Good question, you can re-frame the multivariate time series as a supervised learning problem and use the data to train a static ml model.
See this for an example for preparing the data:
https://machinelearningmastery.com/how-to-develop-lstm-models-for-multi-step-time-series-forecasting-of-household-power-consumption/
See this for forecasting with an ad hoc ml algorithm:
https://machinelearningmastery.com/random-forest-for-time-series-forecasting/
I hope that helps as a first step.
Thank you very much, I’ve just read the two articles, I’ll use them.
In fact, I was trying to predict the demand for energy over the next 24 hours and I have variables such as the energy produced by different sources at each hour, the price of energy at each hour, as well as the climatic variables (temperature, wind speed, pressure, precipitation…) at each hour. With your articles, I now have a rough idea of how to do this, but there are still uncertainties about for example how many delays I should use.
Nice work.
Perhaps experiment and discover what works best for your specific model and dataset.
Hi Jason! I am currently implementing the recursive multi-step forecasting technique on multivariate data. It has given me extremely good results, so thank you!
However, I have a fear about overfitting. How can I tell if my model is overfit or not?
Well done!
If you have poor performance on hold out data – maybe your overfitting. You can then investigate/diagnose the model with learning curves (which can be hard to do for time series data with walk-forward validation).
Just focus on optimizing out of sample performance.
What do you mean by hold-out data?
Also in investigating the code, I am a bit confused since we fit on train_x and then we predict using train_x[-1, :]. Doesn’t that mean we are predicting on data that we already fitted the model on?
Hold out data is data not used to train the model, e.g. often a test set or validation set.
We are using walk forward validation, you can learn more about this procedure here:
https://machinelearningmastery.com/backtest-machine-learning-models-time-series-forecasting/
Thanks for the clarification!
I have another question then – is there a need to detrend/deseasonalize the data before setting it up as a machine learning problem? I ask this because it seems like we are adding the correlations back in by changing the features to lagged features.
I saw in your reply to a question to a person named Amin in this article: https://machinelearningmastery.com/time-series-forecasting-supervised-learning that we should detrend/deseasonalize but I’m not sure why now.
Yes, it is a good idea to make a time series stationary prior to modeling.
If you’re unsure, model with and without the transform and use the approach that works best for your dataset.
you have explained well, but from coding standards point of view, you have written in a verybad way. Its very difficult to understand which method calling which method. you must atleast make sure atleast you consume all methods from one main method in a sequential manner
Thank you for your feedback.
Hi,
Hope you are doing well. How can we change the prediction from weekly to daily?
I tried to make the dataset with the hourly consumptions, and divide it into the 24 datapoints frames.
Perhaps you can fit the model on daily data, then adjust the model and the data to have one day of data in the output part of each sample.
Hello Jason, in Recursive multi-step would you recommend fit again the model after making the prediction of one day?
Try with and without a refit of the model and use whatever works best for you on your data and model.
Hi Dr. Jason,
Is it okay to compute RMSE across all multi-step forecasted values? That is, assuming you want to make h+5 forecast periods, you compute RMSE for each h forecast and take average RMSE across all forecasts (each RMSE per forecast horizon). If so, could you please direct me to papers or resources that dealt with the said approach?
Thanks
It should be OK mathematically (I believe you know how to implement such function) but I don’t think it make sense because the prediction into the future are less and less accurate. Hence you’re like combining different things into one metric.
Great tutorial!
The is for one house hold prediction, can I ask how to extend to thousands or even millions of house holds?
Hi Henry…You may find the following helpful:
https://machinelearningmastery.com/multivariate-time-series-forecasting-lstms-keras/
Hi Jason,
I just purchased your book, and started working on univariate multi-step lstm for the power usage dataset. I am trying to adjust your code to my task. I have 48 months sequence of target variable values (with 6 features). I need to predict last 12 target values based on 36 months training set. How should I reshape my input data? I believe, I should use n_input=36, n_out=12, and n_features=6. Alternative variant: n_input=12. Please, suggest.
Hi Vladimir…The following may be beneficial:
https://machinelearningmastery.com/reshape-input-data-long-short-term-memory-networks-keras/
Hi Jason, thank you so much for this tutorial, it is extremely helpful to an ML beginner such as myself.
As a power engineer I have just one remark – while aggregating initial data by day you added up all of the active power values in kW, which makes no physical sense. We could either calculate average active power value over each day, or calculate total energy consumed in kWh during each minute (active power [kW] / 60), which then could be aggregated by day, giving us the actual total power consumed each day.
I actually did similar model comparison to yours by creating ‘Total consumption [kWh]’ column in the daily dataset and validated all the models on how good they were in predicting household’s daily electricity demand. These are my results:
Name RMSE [kWh] MAPE
LinearRegression 6.473 23.167%
Lasso 8.08 33.215%
Ridge 6.461 23.218%
ElasticNet 8.01 32.871%
HuberRegressor 6.542 22.032%
Lars 6.473 23.167%
LassoLars 8.08 33.215%
PassiveAggressiveRegressor 7.043 22.561%
RANSACRegressor 7.827 25.496%
SGDRegressor 6.451 23.093%
Hi Michal…Thank you for your feedback! We greatly appreciate it.