Many binary classification tasks do not have an equal number of examples from each class, e.g. the class distribution is skewed or imbalanced.
A popular example is the adult income dataset that involves predicting personal income levels as above or below $50,000 per year based on personal details such as relationship and education level. There are many more cases of incomes less than $50K than above $50K, although the skew is not severe.
This means that techniques for imbalanced classification can be used whilst model performance can still be reported using classification accuracy, as is used with balanced classification problems.
In this tutorial, you will discover how to develop and evaluate a model for the imbalanced adult income classification dataset.
After completing this tutorial, you will know:
- How to load and explore the dataset and generate ideas for data preparation and model selection.
- How to systematically evaluate a suite of machine learning models with a robust test harness.
- How to fit a final model and use it to predict class labels for specific cases.
Kick-start your project with my new book Imbalanced Classification with Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

Develop an Imbalanced Classification Model to Predict Income
Photo by Kirt Edblom, some rights reserved.
Tutorial Overview
This tutorial is divided into five parts; they are:
- Adult Income Dataset
- Explore the Dataset
- Model Test and Baseline Result
- Evaluate Models
- Make Prediction on New Data
Adult Income Dataset
In this project, we will use a standard imbalanced machine learning dataset referred to as the “Adult Income” or simply the “adult” dataset.
The dataset is credited to Ronny Kohavi and Barry Becker and was drawn from the 1994 United States Census Bureau data and involves using personal details such as education level to predict whether an individual will earn more or less than $50,000 per year.
The Adult dataset is from the Census Bureau and the task is to predict whether a given adult makes more than $50,000 a year based attributes such as education, hours of work per week, etc..
— Scaling Up The Accuracy Of Naive-bayes Classifiers: A Decision-tree Hybrid, 1996.
The dataset provides 14 input variables that are a mixture of categorical, ordinal, and numerical data types. The complete list of variables is as follows:
- Age.
- Workclass.
- Final Weight.
- Education.
- Education Number of Years.
- Marital-status.
- Occupation.
- Relationship.
- Race.
- Sex.
- Capital-gain.
- Capital-loss.
- Hours-per-week.
- Native-country.
The dataset contains missing values that are marked with a question mark character (?).
There are a total of 48,842 rows of data, and 3,620 with missing values, leaving 45,222 complete rows.
There are two class values ‘>50K‘ and ‘<=50K‘, meaning it is a binary classification task. The classes are imbalanced, with a skew toward the ‘<=50K‘ class label.
- ‘>50K’: majority class, approximately 25%.
- ‘<=50K’: minority class, approximately 75%.
Given that the class imbalance is not severe and that both class labels are equally important, it is common to use classification accuracy or classification error to report model performance on this dataset.
Using predefined train and test sets, reported good classification error is approximately 14 percent or a classification accuracy of about 86 percent. This might provide a target to aim for when working on this dataset.
Next, let’s take a closer look at the data.
Want to Get Started With Imbalance Classification?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Explore the Dataset
The Adult dataset is a widely used standard machine learning dataset, used to explore and demonstrate many machine learning algorithms, both generally and those designed specifically for imbalanced classification.
First, download the dataset and save it in your current working directory with the name “adult-all.csv”
Review the contents of the file.
The first few lines of the file should look as follows:
|
1 2 3 4 5 6 |
39,State-gov,77516,Bachelors,13,Never-married,Adm-clerical,Not-in-family,White,Male,2174,0,40,United-States,<=50K 50,Self-emp-not-inc,83311,Bachelors,13,Married-civ-spouse,Exec-managerial,Husband,White,Male,0,0,13,United-States,<=50K 38,Private,215646,HS-grad,9,Divorced,Handlers-cleaners,Not-in-family,White,Male,0,0,40,United-States,<=50K 53,Private,234721,11th,7,Married-civ-spouse,Handlers-cleaners,Husband,Black,Male,0,0,40,United-States,<=50K 28,Private,338409,Bachelors,13,Married-civ-spouse,Prof-specialty,Wife,Black,Female,0,0,40,Cuba,<=50K ... |
We can see that the input variables are a mixture of numerical and categorical or ordinal data types, where the non-numerical columns are represented using strings. At a minimum, the categorical variables will need to be ordinal or one-hot encoded.
We can also see that the target variable is represented using strings. This column will need to be label encoded with 0 for the majority class and 1 for the minority class, as is the custom for binary imbalanced classification tasks.
Missing values are marked with a ‘?‘ character. These values will need to be imputed, or given the small number of examples, these rows could be deleted from the dataset.
The dataset can be loaded as a DataFrame using the read_csv() Pandas function, specifying the filename, that there is no header line, and that strings like ‘ ?‘ should be parsed as NaN (missing) values.
|
1 2 3 4 5 |
... # define the dataset location filename = 'adult-all.csv' # load the csv file as a data frame dataframe = read_csv(filename, header=None, na_values='?') |
Once loaded, we can remove the rows that contain one or more missing values.
|
1 2 3 |
... # drop rows with missing dataframe = dataframe.dropna() |
We can summarize the number of rows and columns by printing the shape of the DataFrame.
|
1 2 3 |
... # summarize the shape of the dataset print(dataframe.shape) |
We can also summarize the number of examples in each class using the Counter object.
|
1 2 3 4 5 6 7 |
... # summarize the class distribution target = dataframe.values[:,-1] counter = Counter(target) for k,v in counter.items(): per = v / len(target) * 100 print('Class=%s, Count=%d, Percentage=%.3f%%' % (k, v, per)) |
Tying this together, the complete example of loading and summarizing the dataset is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# load and summarize the dataset from pandas import read_csv from collections import Counter # define the dataset location filename = 'adult-all.csv' # load the csv file as a data frame dataframe = read_csv(filename, header=None, na_values='?') # drop rows with missing dataframe = dataframe.dropna() # summarize the shape of the dataset print(dataframe.shape) # summarize the class distribution target = dataframe.values[:,-1] counter = Counter(target) for k,v in counter.items(): per = v / len(target) * 100 print('Class=%s, Count=%d, Percentage=%.3f%%' % (k, v, per)) |
Running the example first loads the dataset and confirms the number of rows and columns, that is 45,222 rows without missing values and 14 input variables and one target variable.
The class distribution is then summarized, confirming a modest class imbalance with approximately 75 percent for the majority class (<=50K) and approximately 25 percent for the minority class (>50K).
|
1 2 3 |
(45222, 15) Class= <=50K, Count=34014, Percentage=75.216% Class= >50K, Count=11208, Percentage=24.784% |
We can also take a look at the distribution of the numerical input variables by creating a histogram for each.
First, we can select the columns with numeric variables by calling the select_dtypes() function on the DataFrame. We can then select just those columns from the DataFrame.
|
1 2 3 4 5 |
... # select columns with numerical data types num_ix = df.select_dtypes(include=['int64', 'float64']).columns # select a subset of the dataframe with the chosen columns subset = df[num_ix] |
We can then create histograms of each numeric input variable. The complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# create histograms of numeric input variables from pandas import read_csv from matplotlib import pyplot # define the dataset location filename = 'adult-all.csv' # load the csv file as a data frame df = read_csv(filename, header=None, na_values='?') # drop rows with missing df = df.dropna() # select columns with numerical data types num_ix = df.select_dtypes(include=['int64', 'float64']).columns # select a subset of the dataframe with the chosen columns subset = df[num_ix] # create a histogram plot of each numeric variable subset.hist() pyplot.show() |
Running the example creates the figure with one histogram subplot for each of the six input variables in the dataset. The title of each subplot indicates the column number in the DataFrame (e.g. zero-offset).
We can see many different distributions, some with Gaussian-like distributions, others with seemingly exponential or discrete distributions. We can also see that they all appear to have a very different scale.
Depending on the choice of modeling algorithms, we would expect scaling the distributions to the same range to be useful, and perhaps the use of some power transforms.
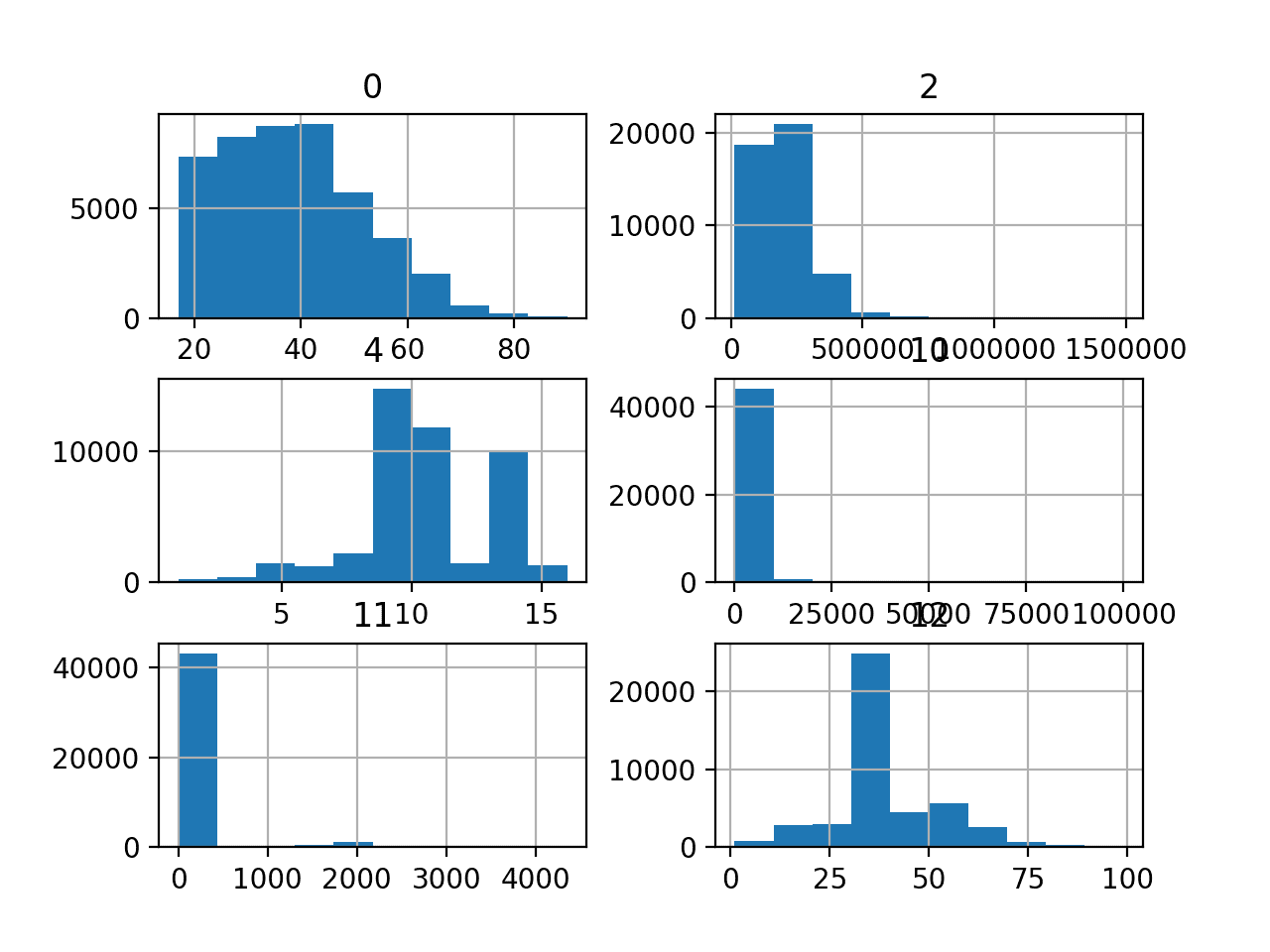
Histogram of Numeric Variables in the Adult Imbalanced Classification Dataset
Now that we have reviewed the dataset, let’s look at developing a test harness for evaluating candidate models.
Model Test and Baseline Result
We will evaluate candidate models using repeated stratified k-fold cross-validation.
The k-fold cross-validation procedure provides a good general estimate of model performance that is not too optimistically biased, at least compared to a single train-test split. We will use k=10, meaning each fold will contain about 45,222/10, or about 4,522 examples.
Stratified means that each fold will contain the same mixture of examples by class, that is about 75 percent to 25 percent for the majority and minority classes respectively. Repeated means that the evaluation process will be performed multiple times to help avoid fluke results and better capture the variance of the chosen model. We will use three repeats.
This means a single model will be fit and evaluated 10 * 3 or 30 times and the mean and standard deviation of these runs will be reported.
This can be achieved using the RepeatedStratifiedKFold scikit-learn class.
We will predict a class label for each example and measure model performance using classification accuracy.
The evaluate_model() function below will take the loaded dataset and a defined model and will evaluate it using repeated stratified k-fold cross-validation, then return a list of accuracy scores that can later be summarized.
|
1 2 3 4 5 6 7 |
# evaluate a model def evaluate_model(X, y, model): # define evaluation procedure cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # evaluate model scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) return scores |
We can define a function to load the dataset and label encode the target column.
We will also return a list of categorical and numeric columns in case we decide to transform them later when fitting models.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# load the dataset def load_dataset(full_path): # load the dataset as a numpy array dataframe = read_csv(full_path, header=None, na_values='?') # drop rows with missing dataframe = dataframe.dropna() # split into inputs and outputs last_ix = len(dataframe.columns) - 1 X, y = dataframe.drop(last_ix, axis=1), dataframe[last_ix] # select categorical and numerical features cat_ix = X.select_dtypes(include=['object', 'bool']).columns num_ix = X.select_dtypes(include=['int64', 'float64']).columns # label encode the target variable to have the classes 0 and 1 y = LabelEncoder().fit_transform(y) return X.values, y, cat_ix, num_ix |
Finally, we can evaluate a baseline model on the dataset using this test harness.
When using classification accuracy, a naive model will predict the majority class for all cases. This provides a baseline in model performance on this problem by which all other models can be compared.
This can be achieved using the DummyClassifier class from the scikit-learn library and setting the “strategy” argument to ‘most_frequent‘.
|
1 2 3 |
... # define the reference model model = DummyClassifier(strategy='most_frequent') |
Once the model is evaluated, we can report the mean and standard deviation of the accuracy scores directly.
|
1 2 3 4 5 |
... # evaluate the model scores = evaluate_model(X, y, model) # summarize performance print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) |
Tying this together, the complete example of loading the Adult dataset, evaluating a baseline model, and reporting the performance is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
# test harness and baseline model evaluation for the adult dataset from collections import Counter from numpy import mean from numpy import std from numpy import hstack from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.dummy import DummyClassifier # load the dataset def load_dataset(full_path): # load the dataset as a numpy array dataframe = read_csv(full_path, header=None, na_values='?') # drop rows with missing dataframe = dataframe.dropna() # split into inputs and outputs last_ix = len(dataframe.columns) - 1 X, y = dataframe.drop(last_ix, axis=1), dataframe[last_ix] # select categorical and numerical features cat_ix = X.select_dtypes(include=['object', 'bool']).columns num_ix = X.select_dtypes(include=['int64', 'float64']).columns # label encode the target variable to have the classes 0 and 1 y = LabelEncoder().fit_transform(y) return X.values, y, cat_ix, num_ix # evaluate a model def evaluate_model(X, y, model): # define evaluation procedure cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # evaluate model scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) return scores # define the location of the dataset full_path = 'adult-all.csv' # load the dataset X, y, cat_ix, num_ix = load_dataset(full_path) # summarize the loaded dataset print(X.shape, y.shape, Counter(y)) # define the reference model model = DummyClassifier(strategy='most_frequent') # evaluate the model scores = evaluate_model(X, y, model) # summarize performance print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) |
Running the example first loads and summarizes the dataset.
We can see that we have the correct number of rows loaded. Importantly, we can see that the class labels have the correct mapping to integers, with 0 for the majority class and 1 for the minority class, customary for imbalanced binary classification dataset.
Next, the average classification accuracy score is reported.
In this case, we can see that the baseline algorithm achieves an accuracy of about 75.2%. This score provides a lower limit on model skill; any model that achieves an average accuracy above about 75.2% has skill, whereas models that achieve a score below this value do not have skill on this dataset.
|
1 2 |
(45222, 14) (45222,) Counter({0: 34014, 1: 11208}) Mean Accuracy: 0.752 (0.000) |
Now that we have a test harness and a baseline in performance, we can begin to evaluate some models on this dataset.
Evaluate Models
In this section, we will evaluate a suite of different techniques on the dataset using the test harness developed in the previous section.
The goal is to both demonstrate how to work through the problem systematically and to demonstrate the capability of some techniques designed for imbalanced classification problems.
The reported performance is good, but not highly optimized (e.g. hyperparameters are not tuned).
Can you do better? If you can achieve better classification accuracy performance using the same test harness, I’d love to hear about it. Let me know in the comments below.
Evaluate Machine Learning Algorithms
Let’s start by evaluating a mixture of machine learning models on the dataset.
It can be a good idea to spot check a suite of different nonlinear algorithms on a dataset to quickly flush out what works well and deserves further attention, and what doesn’t.
We will evaluate the following machine learning models on the adult dataset:
- Decision Tree (CART)
- Support Vector Machine (SVM)
- Bagged Decision Trees (BAG)
- Random Forest (RF)
- Gradient Boosting Machine (GBM)
We will use mostly default model hyperparameters, with the exception of the number of trees in the ensemble algorithms, which we will set to a reasonable default of 100.
We will define each model in turn and add them to a list so that we can evaluate them sequentially. The get_models() function below defines the list of models for evaluation, as well as a list of model short names for plotting the results later.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# define models to test def get_models(): models, names = list(), list() # CART models.append(DecisionTreeClassifier()) names.append('CART') # SVM models.append(SVC(gamma='scale')) names.append('SVM') # Bagging models.append(BaggingClassifier(n_estimators=100)) names.append('BAG') # RF models.append(RandomForestClassifier(n_estimators=100)) names.append('RF') # GBM models.append(GradientBoostingClassifier(n_estimators=100)) names.append('GBM') return models, names |
We can then enumerate the list of models in turn and evaluate each, storing the scores for later evaluation.
We will one-hot encode the categorical input variables using a OneHotEncoder, and we will normalize the numerical input variables using the MinMaxScaler. These operations must be performed within each train/test split during the cross-validation process, where the encoding and scaling operations are fit on the training set and applied to the train and test sets.
An easy way to implement this is to use a Pipeline where the first step is a ColumnTransformer that applies a OneHotEncoder to just the categorical variables, and a MinMaxScaler to just the numerical input variables. To achieve this, we need a list of the column indices for categorical and numerical input variables.
The load_dataset() function we defined in the previous section loads and returns both the dataset and lists of columns that have categorical and numerical data types. This can be used to prepare a Pipeline to wrap each model prior to evaluating it. First, the ColumnTransformer is defined, which specifies what transform to apply to each type of column, then this is used as the first step in a Pipeline that ends with the specific model that will be fit and evaluated.
|
1 2 3 4 5 6 7 8 9 |
... # define steps steps = [('c',OneHotEncoder(handle_unknown='ignore'),cat_ix), ('n',MinMaxScaler(),num_ix)] # one hot encode categorical, normalize numerical ct = ColumnTransformer(steps) # wrap the model i a pipeline pipeline = Pipeline(steps=[('t',ct),('m',models[i])]) # evaluate the model and store results scores = evaluate_model(X, y, pipeline) |
We can summarize the mean accuracy for each algorithm, this will help to directly compare algorithms.
|
1 2 3 |
... # summarize performance print('>%s %.3f (%.3f)' % (names[i], mean(scores), std(scores))) |
At the end of the run, we will create a separate box and whisker plot for each algorithm’s sample of results. These plots will use the same y-axis scale so we can compare the distribution of results directly.
|
1 2 3 4 |
... # plot the results pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
Tying this all together, the complete example of evaluation a suite of machine learning algorithms on the adult imbalanced dataset is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 |
# spot check machine learning algorithms on the adult imbalanced dataset from numpy import mean from numpy import std from pandas import read_csv from matplotlib import pyplot from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OneHotEncoder from sklearn.preprocessing import MinMaxScaler from sklearn.pipeline import Pipeline from sklearn.compose import ColumnTransformer from sklearn.model_selection import cross_val_score from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import GradientBoostingClassifier from sklearn.ensemble import BaggingClassifier # load the dataset def load_dataset(full_path): # load the dataset as a numpy array dataframe = read_csv(full_path, header=None, na_values='?') # drop rows with missing dataframe = dataframe.dropna() # split into inputs and outputs last_ix = len(dataframe.columns) - 1 X, y = dataframe.drop(last_ix, axis=1), dataframe[last_ix] # select categorical and numerical features cat_ix = X.select_dtypes(include=['object', 'bool']).columns num_ix = X.select_dtypes(include=['int64', 'float64']).columns # label encode the target variable to have the classes 0 and 1 y = LabelEncoder().fit_transform(y) return X.values, y, cat_ix, num_ix # evaluate a model def evaluate_model(X, y, model): # define evaluation procedure cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1) # evaluate model scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) return scores # define models to test def get_models(): models, names = list(), list() # CART models.append(DecisionTreeClassifier()) names.append('CART') # SVM models.append(SVC(gamma='scale')) names.append('SVM') # Bagging models.append(BaggingClassifier(n_estimators=100)) names.append('BAG') # RF models.append(RandomForestClassifier(n_estimators=100)) names.append('RF') # GBM models.append(GradientBoostingClassifier(n_estimators=100)) names.append('GBM') return models, names # define the location of the dataset full_path = 'adult-all.csv' # load the dataset X, y, cat_ix, num_ix = load_dataset(full_path) # define models models, names = get_models() results = list() # evaluate each model for i in range(len(models)): # define steps steps = [('c',OneHotEncoder(handle_unknown='ignore'),cat_ix), ('n',MinMaxScaler(),num_ix)] # one hot encode categorical, normalize numerical ct = ColumnTransformer(steps) # wrap the model i a pipeline pipeline = Pipeline(steps=[('t',ct),('m',models[i])]) # evaluate the model and store results scores = evaluate_model(X, y, pipeline) results.append(scores) # summarize performance print('>%s %.3f (%.3f)' % (names[i], mean(scores), std(scores))) # plot the results pyplot.boxplot(results, labels=names, showmeans=True) pyplot.show() |
Running the example evaluates each algorithm in turn and reports the mean and standard deviation classification accuracy.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
What scores did you get?
Post your results in the comments below.
In this case, we can see that all of the chosen algorithms are skillful, achieving a classification accuracy above 75.2%. We can see that the ensemble decision tree algorithms perform the best with perhaps stochastic gradient boosting performing the best with a classification accuracy of about 86.3%.
This is slightly better than the result reported in the original paper, albeit with a different model evaluation procedure.
|
1 2 3 4 5 |
>CART 0.812 (0.005) >SVM 0.837 (0.005) >BAG 0.852 (0.004) >RF 0.849 (0.004) >GBM 0.863 (0.004) |
A figure is created showing one box and whisker plot for each algorithm’s sample of results. The box shows the middle 50 percent of the data, the orange line in the middle of each box shows the median of the sample, and the green triangle in each box shows the mean of the sample.
We can see that the distribution of scores for each algorithm appears to be above the baseline of about 75%, perhaps with a few outliers (circles on the plot). The distribution for each algorithm appears compact, with the median and mean aligning, suggesting the models are quite stable on this dataset and scores do not form a skewed distribution.
This highlights that it is not just the central tendency of the model performance that it is important, but also the spread and even worst-case result that should be considered. Especially with a limited number of examples of the minority class.
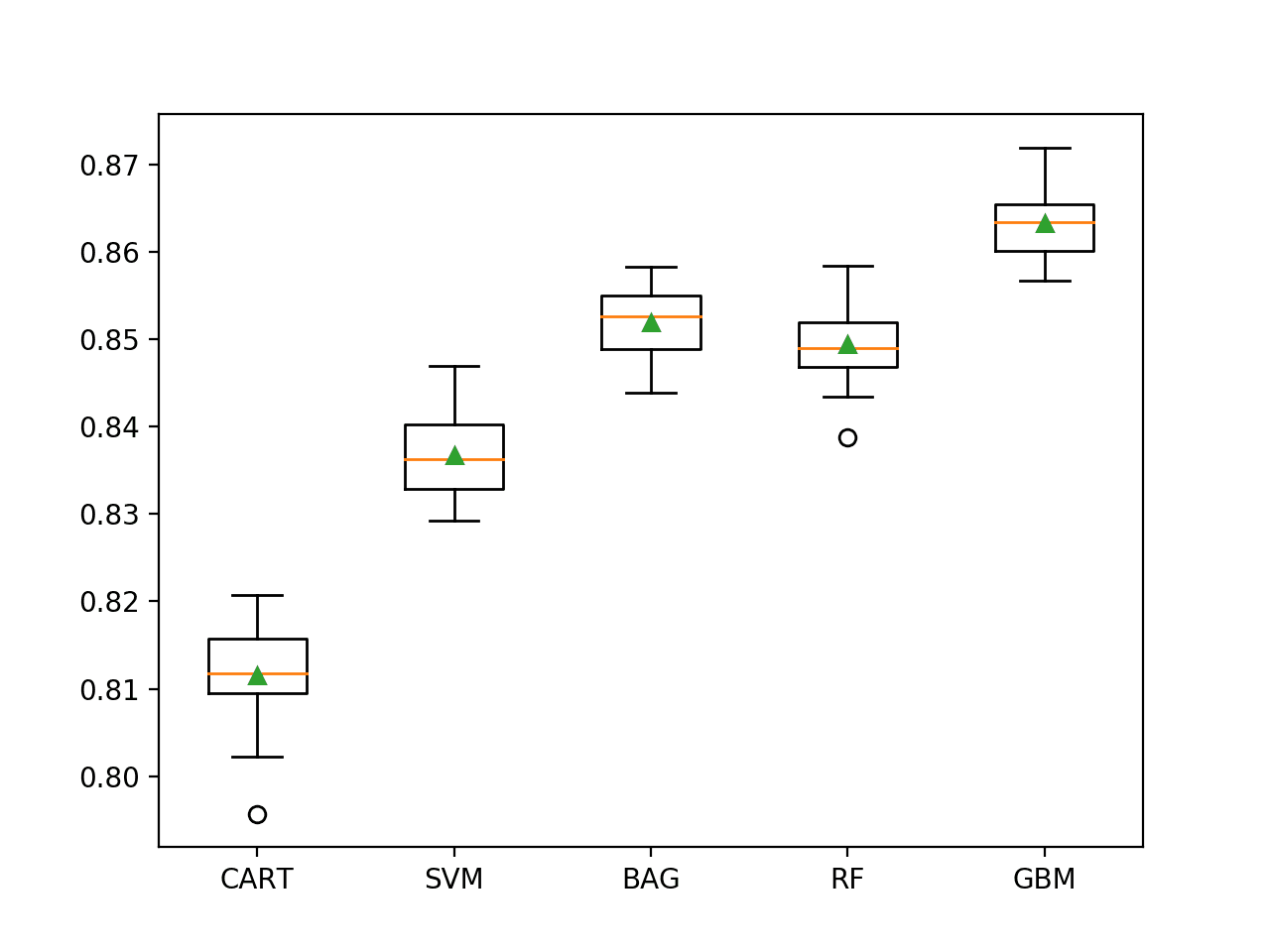
Box and Whisker Plot of Machine Learning Models on the Imbalanced Adult Dataset
Make Prediction on New Data
In this section, we can fit a final model and use it to make predictions on single rows of data.
We will use the GradientBoostingClassifier model as our final model that achieved a classification accuracy of about 86.3%. Fitting the final model involves defining the ColumnTransformer to encode the categorical variables and scale the numerical variables, then construct a Pipeline to perform these transforms on the training set prior to fitting the model.
The Pipeline can then be used to make predictions on new data directly, and will automatically encode and scale new data using the same operations as were performed on the training dataset.
First, we can define the model as a pipeline.
|
1 2 3 4 5 6 7 |
... # define model to evaluate model = GradientBoostingClassifier(n_estimators=100) # one hot encode categorical, normalize numerical ct = ColumnTransformer([('c',OneHotEncoder(),cat_ix), ('n',MinMaxScaler(),num_ix)]) # define the pipeline pipeline = Pipeline(steps=[('t',ct), ('m',model)]) |
Once defined, we can fit it on the entire training dataset.
|
1 2 3 |
... # fit the model pipeline.fit(X, y) |
Once fit, we can use it to make predictions for new data by calling the predict() function. This will return the class label of 0 for “<=50K”, or 1 for “>50K”.
Importantly, we must use the ColumnTransformer within the Pipeline to correctly prepare new data using the same transforms.
For example:
|
1 2 3 4 5 |
... # define a row of data row = [...] # make prediction yhat = pipeline.predict([row]) |
To demonstrate this, we can use the fit model to make some predictions of labels for a few cases where we know the outcome.
The complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
# fit a model and make predictions for the on the adult dataset from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OneHotEncoder from sklearn.preprocessing import MinMaxScaler from sklearn.compose import ColumnTransformer from sklearn.ensemble import GradientBoostingClassifier from imblearn.pipeline import Pipeline # load the dataset def load_dataset(full_path): # load the dataset as a numpy array dataframe = read_csv(full_path, header=None, na_values='?') # drop rows with missing dataframe = dataframe.dropna() # split into inputs and outputs last_ix = len(dataframe.columns) - 1 X, y = dataframe.drop(last_ix, axis=1), dataframe[last_ix] # select categorical and numerical features cat_ix = X.select_dtypes(include=['object', 'bool']).columns num_ix = X.select_dtypes(include=['int64', 'float64']).columns # label encode the target variable to have the classes 0 and 1 y = LabelEncoder().fit_transform(y) return X.values, y, cat_ix, num_ix # define the location of the dataset full_path = 'adult-all.csv' # load the dataset X, y, cat_ix, num_ix = load_dataset(full_path) # define model to evaluate model = GradientBoostingClassifier(n_estimators=100) # one hot encode categorical, normalize numerical ct = ColumnTransformer([('c',OneHotEncoder(),cat_ix), ('n',MinMaxScaler(),num_ix)]) # define the pipeline pipeline = Pipeline(steps=[('t',ct), ('m',model)]) # fit the model pipeline.fit(X, y) # evaluate on some <=50K cases (known class 0) print('<=50K cases:') data = [[24, 'Private', 161198, 'Bachelors', 13, 'Never-married', 'Prof-specialty', 'Not-in-family', 'White', 'Male', 0, 0, 25, 'United-States'], [23, 'Private', 214542, 'Some-college', 10, 'Never-married', 'Farming-fishing', 'Own-child', 'White', 'Male', 0, 0, 40, 'United-States'], [38, 'Private', 309122, '10th', 6, 'Divorced', 'Machine-op-inspct', 'Not-in-family', 'White', 'Female', 0, 0, 40, 'United-States']] for row in data: # make prediction yhat = pipeline.predict([row]) # get the label label = yhat[0] # summarize print('>Predicted=%d (expected 0)' % (label)) # evaluate on some >50K cases (known class 1) print('>50K cases:') data = [[55, 'Local-gov', 107308, 'Masters', 14, 'Married-civ-spouse', 'Prof-specialty', 'Husband', 'White', 'Male', 0, 0, 40, 'United-States'], [53, 'Self-emp-not-inc', 145419, '1st-4th', 2, 'Married-civ-spouse', 'Exec-managerial', 'Husband', 'White', 'Male', 7688, 0, 67, 'Italy'], [44, 'Local-gov', 193425, 'Masters', 14, 'Married-civ-spouse', 'Prof-specialty', 'Wife', 'White', 'Female', 4386, 0, 40, 'United-States']] for row in data: # make prediction yhat = pipeline.predict([row]) # get the label label = yhat[0] # summarize print('>Predicted=%d (expected 1)' % (label)) |
Running the example first fits the model on the entire training dataset.
Then the fit model used to predict the label of <=50K cases is chosen from the dataset file. We can see that all cases are correctly predicted. Then some >50K cases are used as input to the model and the label is predicted. As we might have hoped, the correct labels are predicted.
|
1 2 3 4 5 6 7 8 |
<=50K cases: >Predicted=0 (expected 0) >Predicted=0 (expected 0) >Predicted=0 (expected 0) >50K cases: >Predicted=1 (expected 1) >Predicted=1 (expected 1) >Predicted=1 (expected 1) |
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Papers
APIs
- pandas.DataFrame.select_dtypes API.
- sklearn.model_selection.RepeatedStratifiedKFold API.
- sklearn.dummy.DummyClassifier API.
Dataset
Summary
In this tutorial, you discovered how to develop and evaluate a model for the imbalanced adult income classification dataset.
Specifically, you learned:
- How to load and explore the dataset and generate ideas for data preparation and model selection.
- How to systematically evaluate a suite of machine learning models with a robust test harness.
- How to fit a final model and use it to predict class labels for specific cases.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Get a Handle on Imbalanced Classification!

Develop Imbalanced Learning Models in Minutes
...with just a few lines of python code
Discover how in my new Ebook:
Imbalanced Classification with Python
It provides self-study tutorials and end-to-end projects on:
Performance Metrics, Undersampling Methods, SMOTE, Threshold Moving, Probability Calibration, Cost-Sensitive Algorithms
and much more...






Hi,
I am getting “ValueError: could not convert string to float: ‘United-States'” when I run the code for evaluate model. Couldn’t find the a solution. Can you please help?
ANwar
Sorry to hear that, this will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Hi Jason,
Thank you for the tutorial. I’m having the same issue as Anwar above, and I’m thinking it’s because you did not encode your categorical variables. So you are feeding the cat_ix columns directly into your model.
Hopefully you can look into this and clarify.
Thanks.
Sorry to hear that you are having trouble.
We do prepare both variable types, see the section “Evaluate Machine Learning Algorithms” where we do this for the first time.
Perhaps this will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Oh seen, thanks!
Apparently, the code block before the ‘Evaluate Machine Learning Algorithms’ is the one that throws the error. So using the code there, we are unable to get a baseline performance, as the preparation had not taken place then.
The block before that uses a dummy model that does not look at the inputs.
No data prep is needed in that case and code executes directly. Perhaps confirm you are using the latest version of scikit-learn.
Please ignore my last message.
I refreshed my kernel and run in a new notebook and it worked.
Thanks for all you do, Jason
No problem. Happy to hear it, well done!
Hi Jason:
Very nice tutorial for the Adult dataset, it actually a good example of a Data Science project, especially your clean code. But I am confuse one thing:
unlike most Data Science tutorial online, your example did not have much Feature Engineering, honestly, sometimes when reading other Data Scientist’s tutorial about Feature Engineering portion, it’s really headache, they will play around the correlation with each features and the target, and they also create some made up feature from some mathematical transformation.
What’s your opinion about Feature Engineering? would you mind share some of your experience? sample or tutorial?
Thanks.
I think it’s a great idea if you have time.
This might help as a first step:
https://machinelearningmastery.com/discover-feature-engineering-how-to-engineer-features-and-how-to-get-good-at-it/
Hey mate, thanks for sharing.
A bit confused going throughsklearn
RepeatedStratifiedKFolddoc and wonder whether your technique has any form of train and test split? Or is the training done on first 9 folds with last one to get the metrics?Otherwise how can you guarantee the models are not simply learning the representation perfectly?
It is performing simple cross validation:
https://machinelearningmastery.com/k-fold-cross-validation/
It just ensures that the split is stratified. It also repeats the process a few times so we get less standard error in the mean.
Hello,
Can you please explain why you chose most frequent as strategy for the dummy classifier. What should we base our strategy choices on?
Yes, see this:
https://machinelearningmastery.com/naive-classifiers-imbalanced-classification-metrics/
I managed to get median AUC of 0.9 for this data set. I used Primeclue, an open source data mining tool (available on github).
Well done!
Hi Jason,
You mention in your code above as a comment that you are oversampling, but I do not see how you are doing that. Could you explain?
Thank you!
Looks like a typo, thanks. Fixed.
Thank you for the quick reply.
In your opinion would there be an improvement in oversampling the minority?
Additionally, is there a need to deal with some of the skewed features such as race and native-country(possibly others) where the white race and USA are dominating in terms of proportions to the overall number of samples?
Thanks!
I believe I tried it and add not see any benefit. Perhaps try it yourself to confirm.
Hi, i am trying your code, but for some reason in the evaluation part, I am get nan for mean and std of different models. Could you suggest what i could be doing wrong here ?
Thank you
Perhaps these tips will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Hi Jason,
thank you (as always) for that quick analysis. I got the exact same dataset as a case study for an interview and have a question. When it comes to the evaluation part and I want to detect wether the model is overfitting or not. Is it enough to just plot the Logloss curve and the Error curve? How would you proceed? Thanks in advance!
Marlon
You’re welcome.
Overfitting is really only something you can look at for models that learn iteratively, perhaps see this:
https://machinelearningmastery.com/overfitting-machine-learning-models/
So you mean there is no way in visualizing any curve to detect over/ underfitting with xgb?
I am getting confused. Isnt that the way you worked over here: https://machinelearningmastery.com/avoid-overfitting-by-early-stopping-with-xgboost-in-python/
Yes.
You can, after each tree is added you can evaluate the performance on the train and validation set the plot the curves. It just does not help with model selection – it is helpful for model diagnostics.
See this example:
https://machinelearningmastery.com/avoid-overfitting-by-early-stopping-with-xgboost-in-python/
Ah sorry! Then I answered my question in a way that it can be misunderstood. Thanks for your fast reply…as always 😉
You’re welcome.
hi, jason
i tried your code above until the part that is trying different classification model. for some reason my computer only shows CART result. i’ve been waiting for ~15 min but the other model’s results aren’t out yet.
do you perhaps have any idea why?i dont think its due to heavy programming, your code seems light
thank you in advance
hi again
finally the result is out, i got
>CART 0.811 (0.006)
>SVM 0.837 (0.005)
>BAG 0.853 (0.005)
>RF 0.850 (0.005)
>GBM 0.863 (0.005)
it took my computer ~2 hours to finish running it. i use spyder from anaconda and my specs are: Win 10 64 bit, Intel(R) Core(TM) i3-6006U CPU @ 2.00GHz 2.00 GHz, RAM 4GB
I can’t really tell why but I heard of similar complaints that Spyder slowing the execution down.
If you try to run it on console (i.e., not jupyter notebook), try Ctrl-C to terminate it. It will tell you where it is stopping. I can’t see why it takes so long to run, however. If you still can’t sure, try add some print() statement here and there to keep track on where the program goes. These are just first steps to learn more about what’s happening.