How to Score Probability Predictions in Python and
Develop an Intuition for Different Metrics.
Predicting probabilities instead of class labels for a classification problem can provide additional nuance and uncertainty for the predictions.
The added nuance allows more sophisticated metrics to be used to interpret and evaluate the predicted probabilities. In general, methods for the evaluation of the accuracy of predicted probabilities are referred to as scoring rules or scoring functions.
In this tutorial, you will discover three scoring methods that you can use to evaluate the predicted probabilities on your classification predictive modeling problem.
After completing this tutorial, you will know:
The log loss score that heavily penalizes predicted probabilities far away from their expected value.
The Brier score that is gentler than log loss but still penalizes proportional to the distance from the expected value.
The area under ROC curve that summarizes the likelihood of the model predicting a higher probability for true positive cases than true negative cases.
Kick-start your project with my new book Probability for Machine Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Update Sept/2018: Fixed description of AUC no skill.
A Gentle Introduction to Probability Scoring Methods in Python Photo by Paul Balfe, some rights reserved.
Tutorial Overview
This tutorial is divided into four parts; they are:
Log Loss Score
Brier Score
ROC AUC Score
Tuning Predicted Probabilities
Log Loss Score
Log loss, also called “logistic loss,” “logarithmic loss,” or “cross entropy” can be used as a measure for evaluating predicted probabilities.
Each predicted probability is compared to the actual class output value (0 or 1) and a score is calculated that penalizes the probability based on the distance from the expected value. The penalty is logarithmic, offering a small score for small differences (0.1 or 0.2) and enormous score for a large difference (0.9 or 1.0).
A model with perfect skill has a log loss score of 0.0.
In order to summarize the skill of a model using log loss, the log loss is calculated for each predicted probability, and the average loss is reported.
The log loss can be implemented in Python using the log_loss() function in scikit-learn.
For example:
1
2
3
4
5
6
7
8
9
10
from sklearn.metrics import log_loss
...
model=...
testX,testy=...
# predict probabilities
probs=model.predict_proba(testX)
# keep the predictions for class 1 only
probs=probs[:,1]
# calculate log loss
loss=log_loss(testy,probs)
In the binary classification case, the function takes a list of true outcome values and a list of probabilities as arguments and calculates the average log loss for the predictions.
We can make a single log loss score concrete with an example.
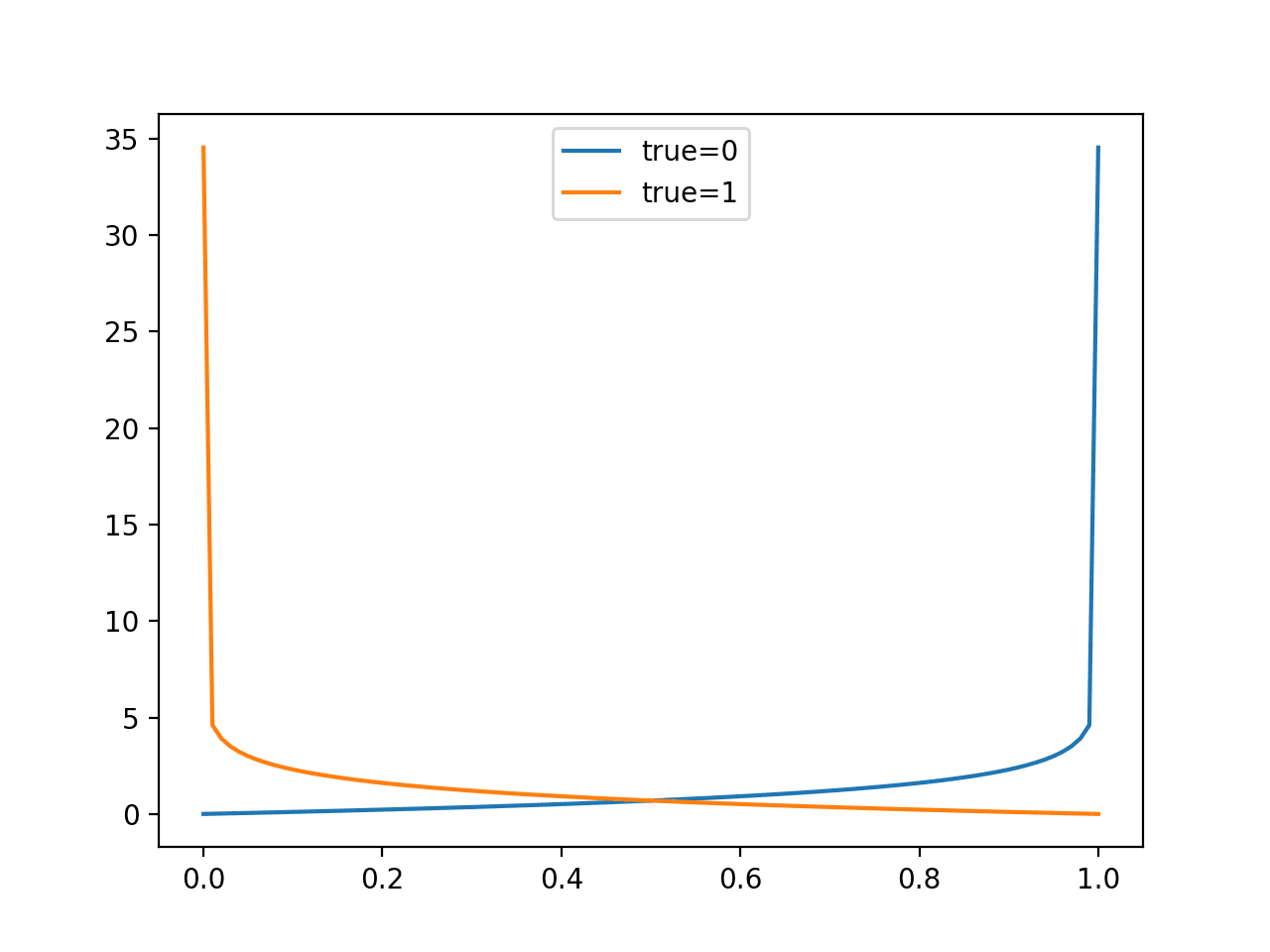
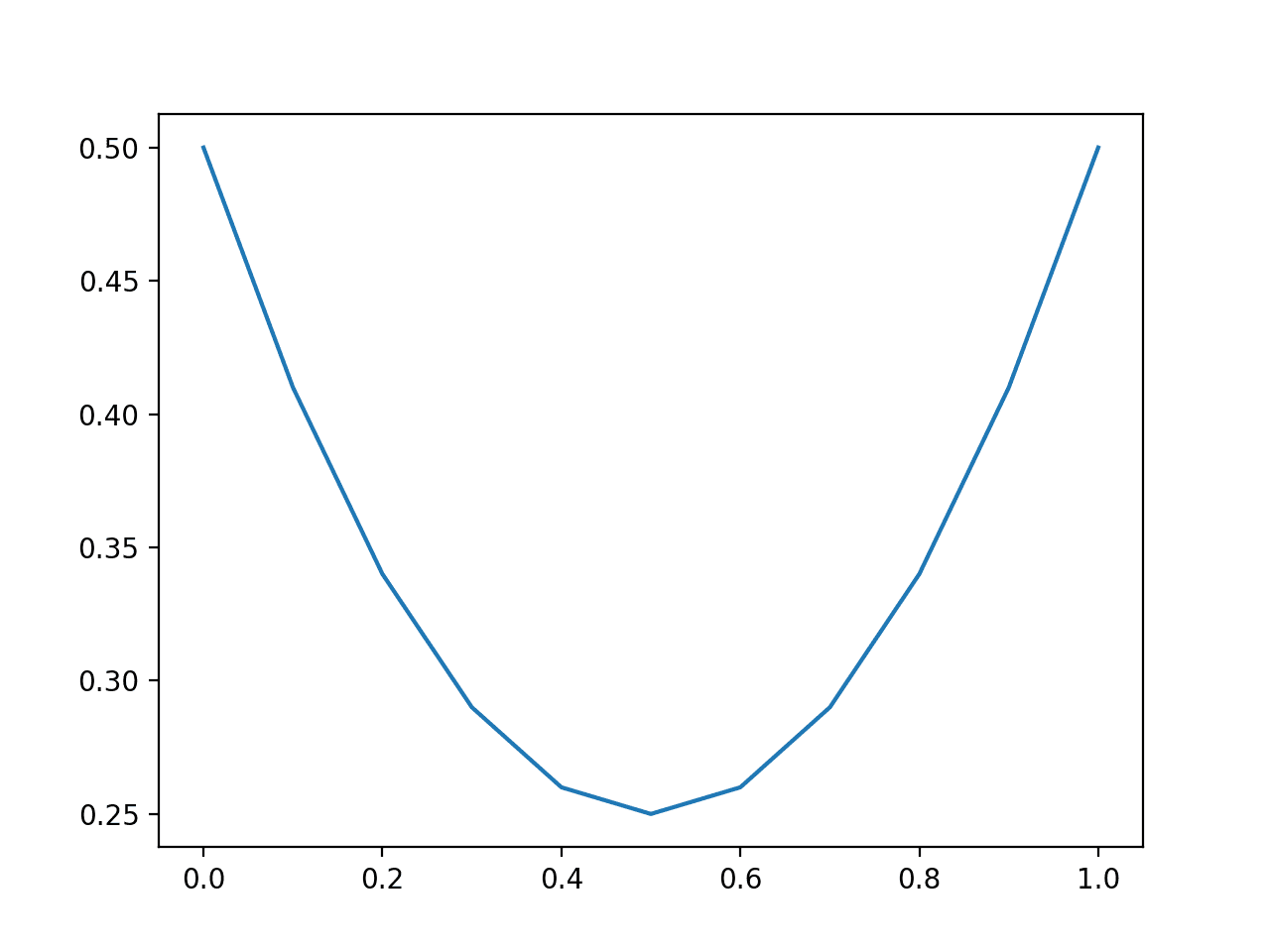
Given a specific known outcome of 0, we can predict values of 0.0 to 1.0 in 0.01 increments (101 predictions) and calculate the log loss for each. The result is a curve showing how much each prediction is penalized as the probability gets further away from the expected value. We can repeat this for a known outcome of 1 and see the same curve in reverse.
Running the example creates a line plot showing the loss scores for probability predictions from 0.0 to 1.0 for both the case where the true label is 0 and 1.
This helps to build an intuition for the effect that the loss score has when evaluating predictions.
Line Plot of Evaluating Predictions with Log Loss
Model skill is reported as the average log loss across the predictions in a test dataset.
As an average, we can expect that the score will be suitable with a balanced dataset and misleading when there is a large imbalance between the two classes in the test set. This is because predicting 0 or small probabilities will result in a small loss.
We can demonstrate this by comparing the distribution of loss values when predicting different constant probabilities for a balanced and an imbalanced dataset.
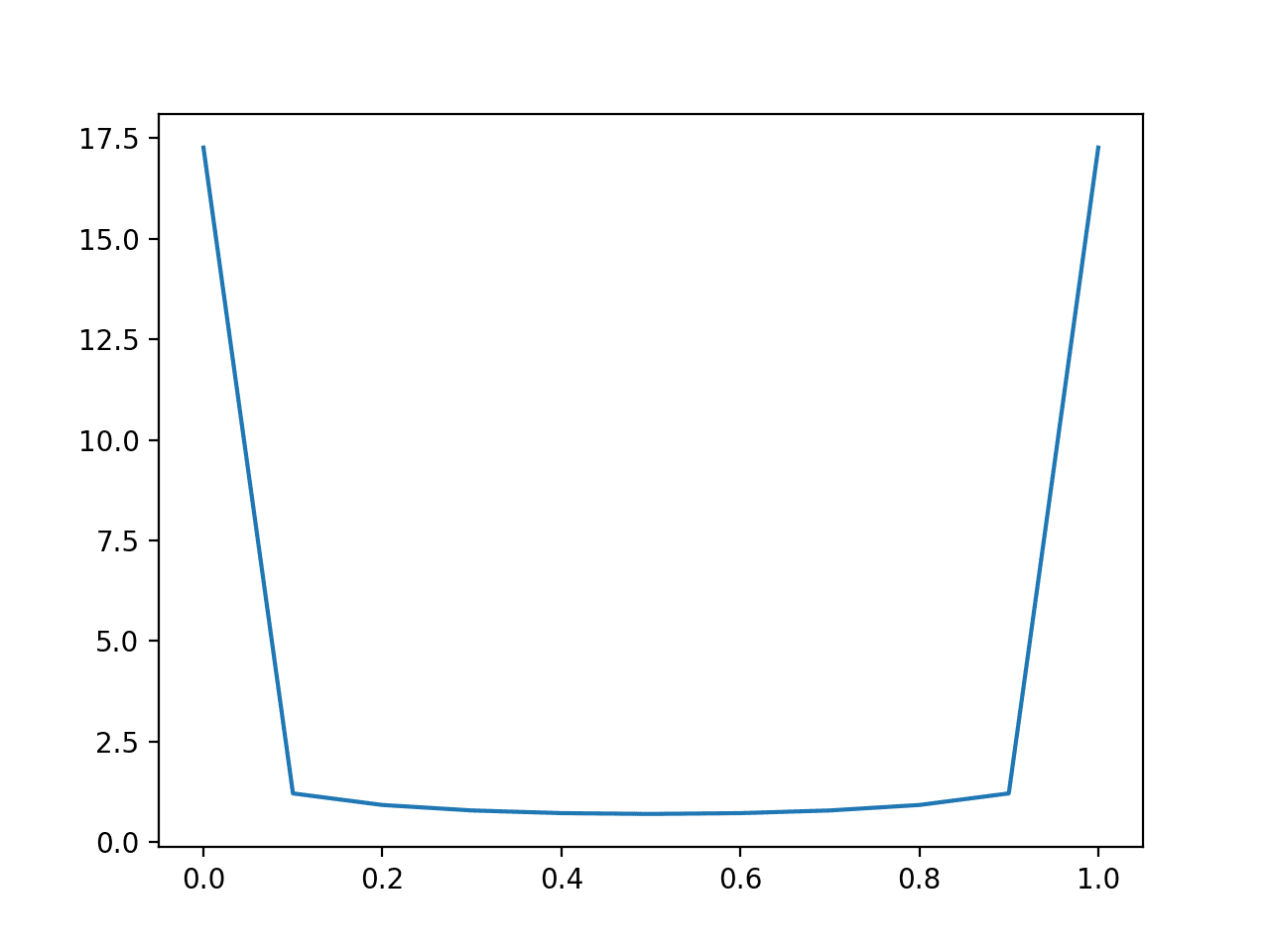
First, the example below predicts values from 0.0 to 1.0 in 0.1 increments for a balanced dataset of 50 examples of class 0 and 1.
1
2
3
4
5
6
7
8
9
10
11
12
# plot impact of logloss with balanced datasets
from sklearn.metrics import log_loss
from matplotlib import pyplot
from numpy import array
# define a balanced dataset
testy=[0forxinrange(50)]+[1forxinrange(50)]
# loss for predicting different fixed probability values
Running the example, we can see that a model is better-off predicting probabilities values that are not sharp (close to the edge) and are back towards the middle of the distribution.
The penalty of being wrong with a sharp probability is very large.
Line Plot of Predicting Log Loss for Balanced Dataset
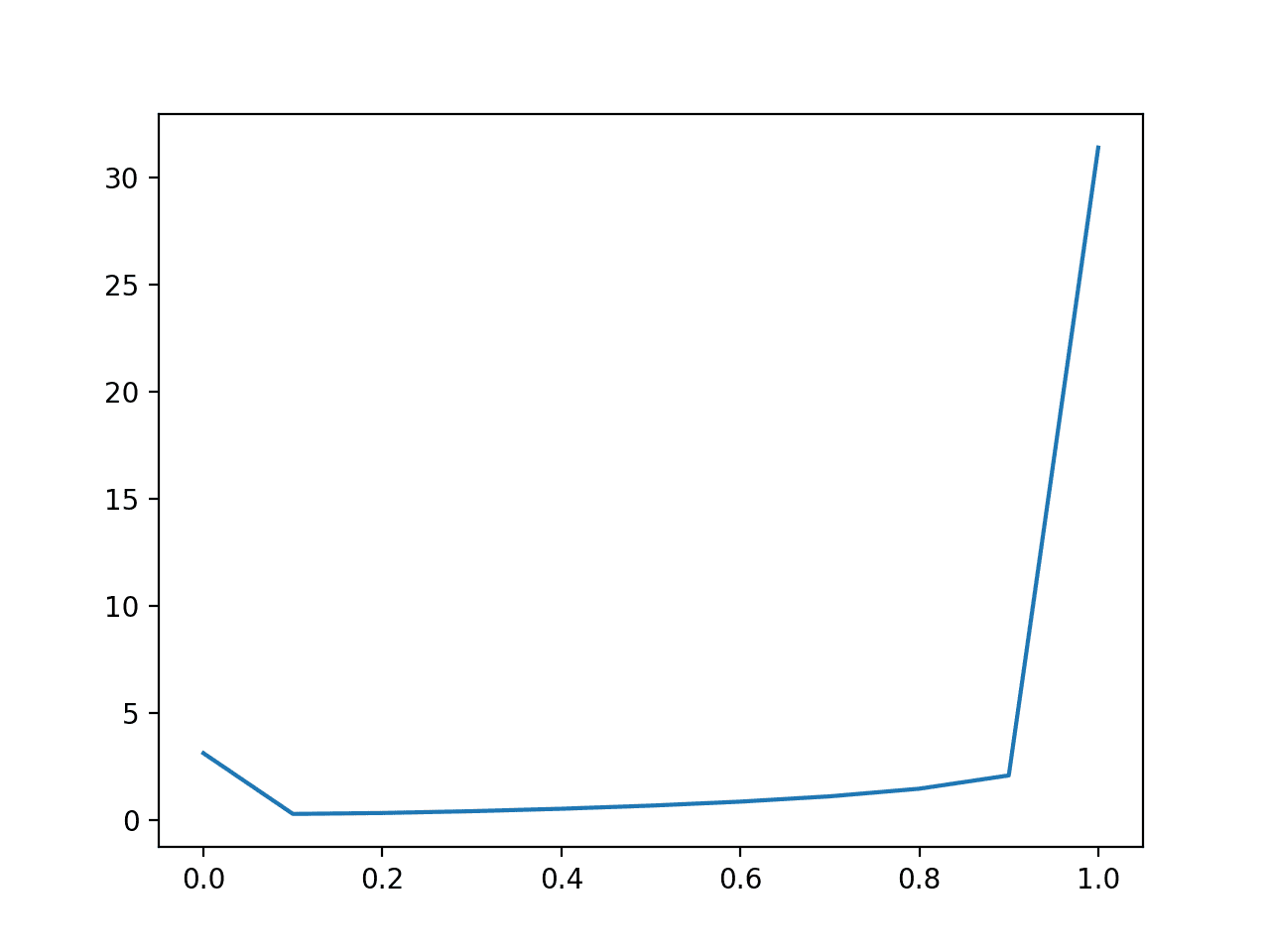
We can repeat this experiment with an imbalanced dataset with a 10:1 ratio of class 0 to class 1.
1
2
3
4
5
6
7
8
9
10
11
12
# plot impact of logloss with imbalanced datasets
from sklearn.metrics import log_loss
from matplotlib import pyplot
from numpy import array
# define an imbalanced dataset
testy=[0forxinrange(100)]+[1forxinrange(10)]
# loss for predicting different fixed probability values
Here, we can see that a model that is skewed towards predicting very small probabilities will perform well, optimistically so.
The naive model that predicts a constant probability of 0.1 will be the baseline model to beat.
The result suggests that model skill evaluated with log loss should be interpreted carefully in the case of an imbalanced dataset, perhaps adjusted relative to the base rate for class 1 in the dataset.
Line Plot of Predicting Log Loss for Imbalanced Dataset
Want to Learn Probability for Machine Learning
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Brier Score
The Brier score, named for Glenn Brier, calculates the mean squared error between predicted probabilities and the expected values.
The score summarizes the magnitude of the error in the probability forecasts.
The error score is always between 0.0 and 1.0, where a model with perfect skill has a score of 0.0.
Predictions that are further away from the expected probability are penalized, but less severely as in the case of log loss.
The skill of a model can be summarized as the average Brier score across all probabilities predicted for a test dataset.
The Brier score can be calculated in Python using the brier_score_loss() function in scikit-learn. It takes the true class values (0, 1) and the predicted probabilities for all examples in a test dataset as arguments and returns the average Brier score.
For example:
1
2
3
4
5
6
7
8
9
10
from sklearn.metrics import brier_score_loss
...
model=...
testX,testy=...
# predict probabilities
probs=model.predict_proba(testX)
# keep the predictions for class 1 only
probs=probs[:,1]
# calculate bier score
loss=brier_score_loss(testy,probs)
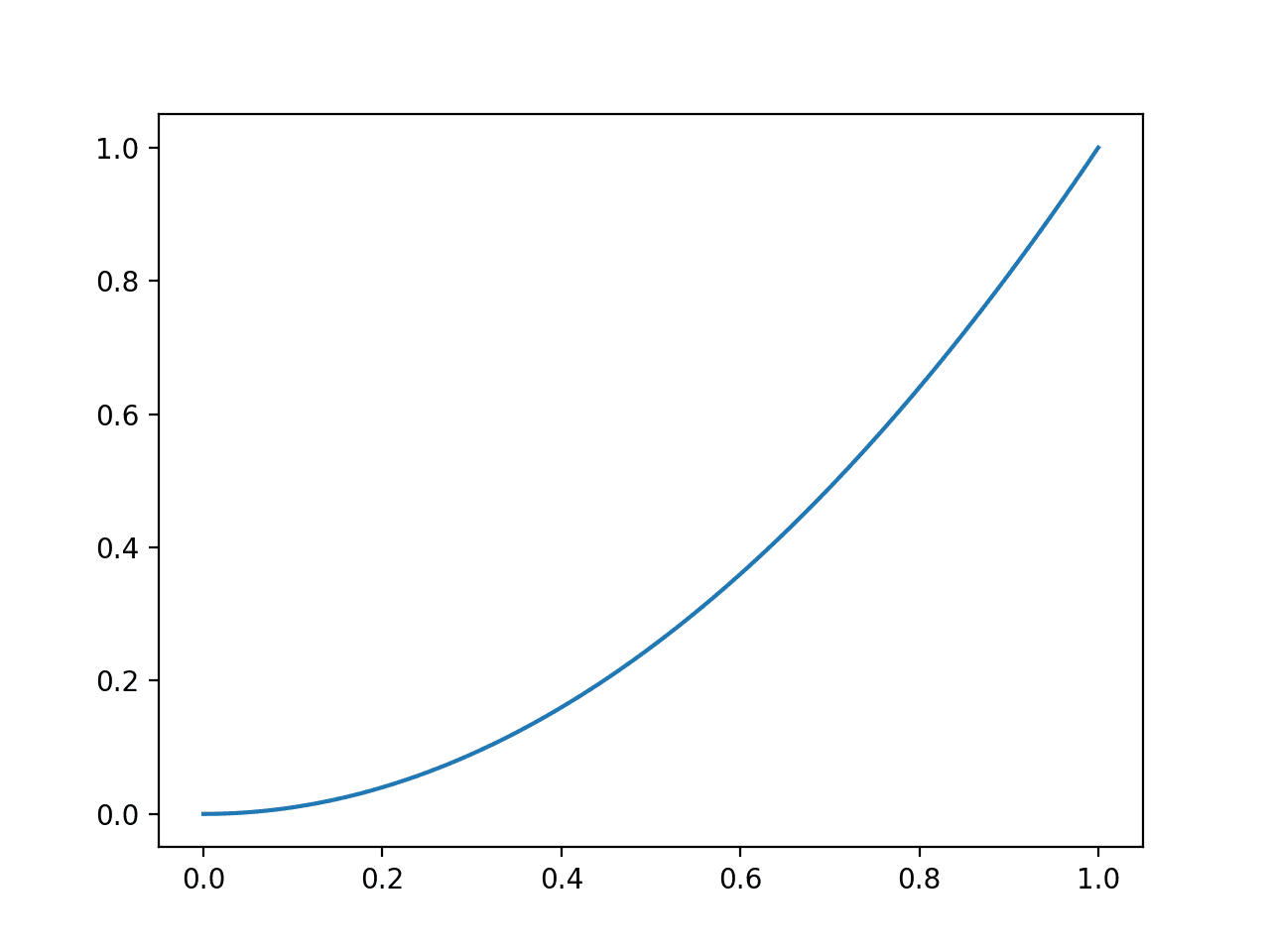
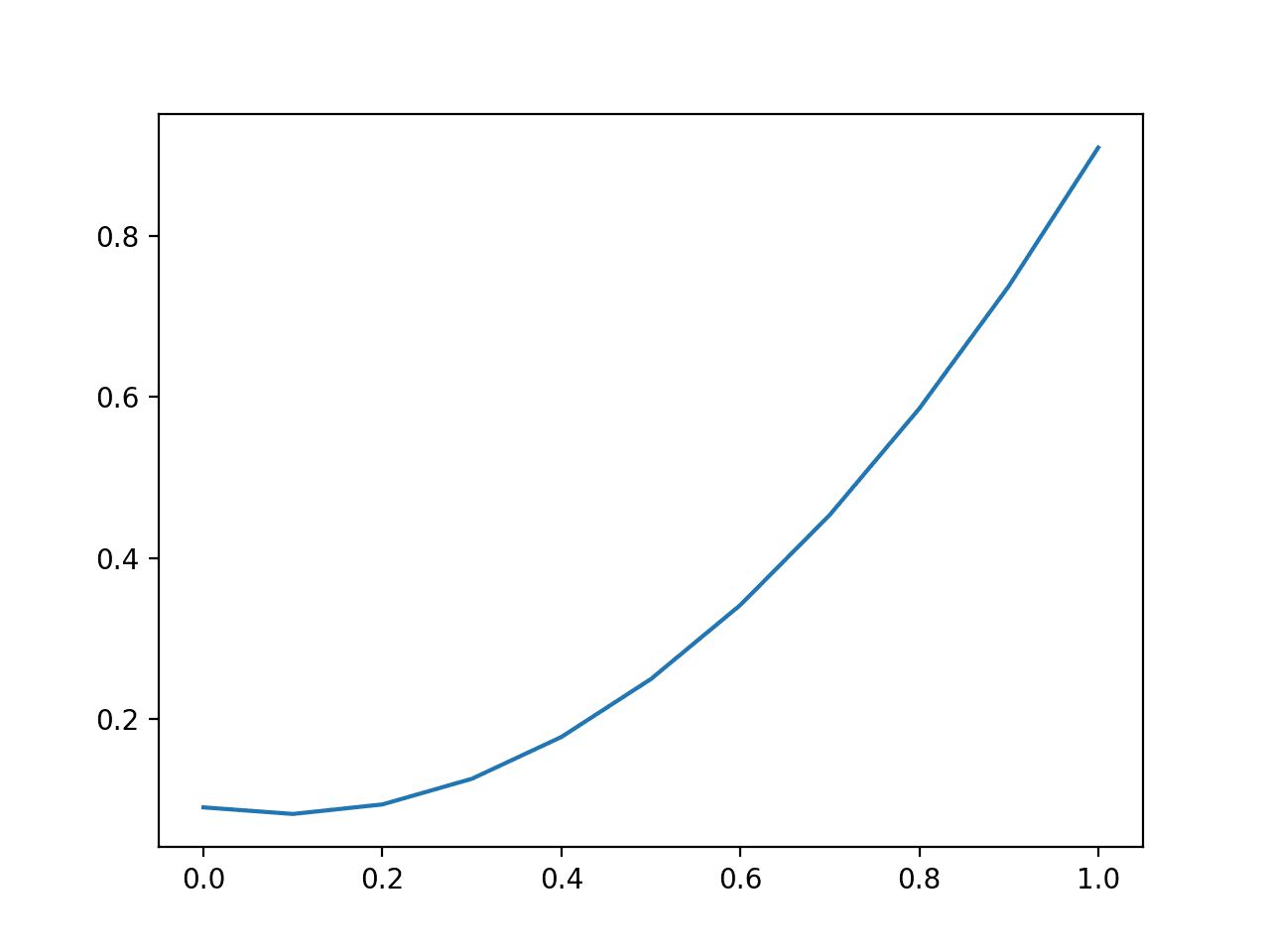
We can evaluate the impact of prediction errors by comparing the Brier score for single probability forecasts in increasing error from 0.0 to 1.0.
Running the example creates a plot of the probability prediction error in absolute terms (x-axis) to the calculated Brier score (y axis).
We can see a familiar quadratic curve, increasing from 0 to 1 with the squared error.
Line Plot of Evaluating Predictions with Brier Score
Model skill is reported as the average Brier across the predictions in a test dataset.
As with log loss, we can expect that the score will be suitable with a balanced dataset and misleading when there is a large imbalance between the two classes in the test set.
We can demonstrate this by comparing the distribution of loss values when predicting different constant probabilities for a balanced and an imbalanced dataset.
First, the example below predicts values from 0.0 to 1.0 in 0.1 increments for a balanced dataset of 50 examples of class 0 and 1.
1
2
3
4
5
6
7
8
9
10
11
12
# plot impact of brier score with balanced datasets
from sklearn.metrics import brier_score_loss
from matplotlib import pyplot
from numpy import array
# define a balanced dataset
testy=[0forxinrange(50)]+[1forxinrange(50)]
# brier score for predicting different fixed probability values
Running the example, we can see that a model is better-off predicting middle of the road probabilities values like 0.5.
Unlike log loss that is quite flat for close probabilities, the parabolic shape shows the clear quadratic increase in the score penalty as the error is increased.
Line Plot of Predicting Brier Score for Balanced Dataset
We can repeat this experiment with an imbalanced dataset with a 10:1 ratio of class 0 to class 1.
1
2
3
4
5
6
7
8
9
10
11
12
# plot impact of brier score with imbalanced datasets
from sklearn.metrics import brier_score_loss
from matplotlib import pyplot
from numpy import array
# define an imbalanced dataset
testy=[0forxinrange(100)]+[1forxinrange(10)]
# brier score for predicting different fixed probability values
Running the example, we see a very different picture for the imbalanced dataset.
Like the average log loss, the average Brier score will present optimistic scores on an imbalanced dataset, rewarding small prediction values that reduce error on the majority class.
In these cases, Brier score should be compared relative to the naive prediction (e.g. the base rate of the minority class or 0.1 in the above example) or normalized by the naive score.
This latter example is common and is called the Brier Skill Score (BSS).
1
BSS = 1 - (BS / BS_ref)
Where BS is the Brier skill of model, and BS_ref is the Brier skill of the naive prediction.
The Brier Skill Score reports the relative skill of the probability prediction over the naive forecast.
A good update to the scikit-learn API would be to add a parameter to the brier_score_loss() to support the calculation of the Brier Skill Score.
Line Plot of Predicting Brier Score for Imbalanced Dataset
ROC AUC Score
A predicted probability for a binary (two-class) classification problem can be interpreted with a threshold.
The threshold defines the point at which the probability is mapped to class 0 versus class 1, where the default threshold is 0.5. Alternate threshold values allow the model to be tuned for higher or lower false positives and false negatives.
Tuning the threshold by the operator is particularly important on problems where one type of error is more or less important than another or when a model is makes disproportionately more or less of a specific type of error.
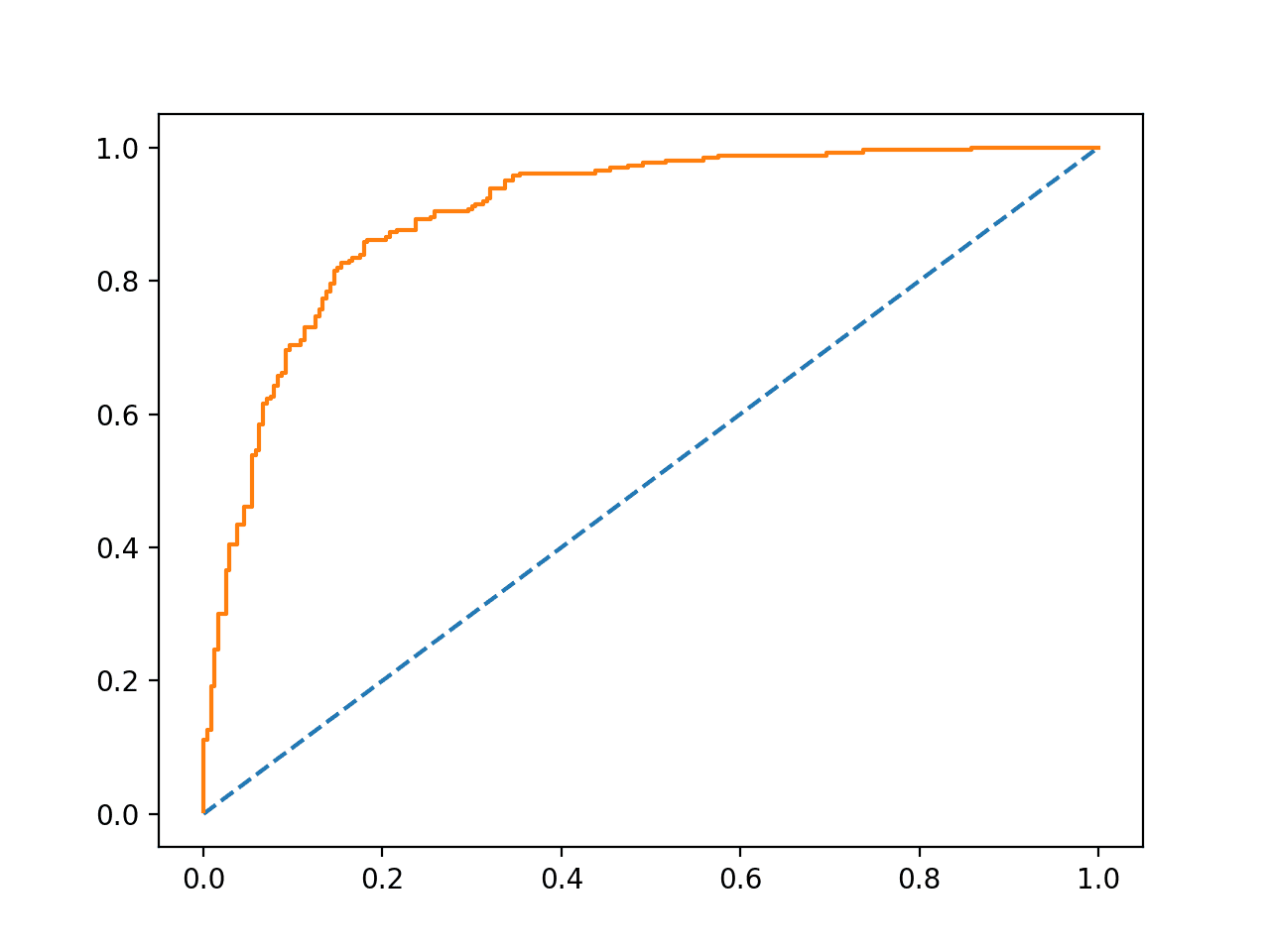
The Receiver Operating Characteristic, or ROC, curve is a plot of the true positive rate versus the false positive rate for the predictions of a model for multiple thresholds between 0.0 and 1.0.
Predictions that have no skill for a given threshold are drawn on the diagonal of the plot from the bottom left to the top right. This line represents no-skill predictions for each threshold.
Models that have skill have a curve above this diagonal line that bows towards the top left corner.
Below is an example of fitting a logistic regression model on a binary classification problem and calculating and plotting the ROC curve for the predicted probabilities on a test set of 500 new data instances.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# roc curve
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# keep probabilities for the positive outcome only
probs=probs[:,1]
# calculate roc curve
fpr,tpr,thresholds=roc_curve(testy,probs)
# plot no skill
pyplot.plot([0,1],[0,1],linestyle='--')
# plot the roc curve for the model
pyplot.plot(fpr,tpr)
# show the plot
pyplot.show()
Running the example creates an example of a ROC curve that can be compared to the no skill line on the main diagonal.
Example ROC Curve
The integrated area under the ROC curve, called AUC or ROC AUC, provides a measure of the skill of the model across all evaluated thresholds.
An AUC score of 0.5 suggests no skill, e.g. a curve along the diagonal, whereas an AUC of 1.0 suggests perfect skill, all points along the left y-axis and top x-axis toward the top left corner. An AUC of 0.0 suggests perfectly incorrect predictions.
Predictions by models that have a larger area have better skill across the thresholds, although the specific shape of the curves between models will vary, potentially offering opportunity to optimize models by a pre-chosen threshold. Typically, the threshold is chosen by the operator after the model has been prepared.
This function takes a list of true output values and predicted probabilities as arguments and returns the ROC AUC.
For example:
1
2
3
4
5
6
7
8
9
10
from sklearn.metrics import roc_auc_score
...
model=...
testX,testy=...
# predict probabilities
probs=model.predict_proba(testX)
# keep the predictions for class 1 only
probs=probs[:,1]
# calculate log loss
loss=roc_auc_score(testy,probs)
An AUC score is a measure of the likelihood that the model that produced the predictions will rank a randomly chosen positive example above a randomly chosen negative example. Specifically, that the probability will be higher for a real event (class=1) than a real non-event (class=0).
This is an instructive definition that offers two important intuitions:
Naive Prediction. A naive prediction under ROC AUC is any constant probability. If the same probability is predicted for every example, there is no discrimination between positive and negative cases, therefore the model has no skill (AUC=0.5).
Insensitivity to Class Imbalance. ROC AUC is a summary on the models ability to correctly discriminate a single example across different thresholds. As such, it is unconcerned with the base likelihood of each class.
Below, the example demonstrating the ROC curve is updated to calculate and display the AUC.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# roc auc
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# keep probabilities for the positive outcome only
probs=probs[:,1]
# calculate roc auc
auc=roc_auc_score(testy,probs)
print(auc)
Running the example calculates and prints the ROC AUC for the logistic regression model evaluated on 500 new examples.
1
0.9028044871794871
An important consideration in choosing the ROC AUC is that it does not summarize the specific discriminative power of the model, rather the general discriminative power across all thresholds.
It might be a better tool for model selection rather than in quantifying the practical skill of a model’s predicted probabilities.
Tuning Predicted Probabilities
Predicted probabilities can be tuned to improve or even game a performance measure.
For example, the log loss and Brier scores quantify the average amount of error in the probabilities. As such, predicted probabilities can be tuned to improve these scores in a few ways:
Making the probabilities less sharp (less confident). This means adjusting the predicted probabilities away from the hard 0 and 1 bounds to limit the impact of penalties of being completely wrong.
Shift the distribution to the naive prediction (base rate). This means shifting the mean of the predicted probabilities to the probability of the base rate, such as 0.5 for a balanced prediction problem.
Generally, it may be useful to review the calibration of the probabilities using tools like a reliability diagram. This can be achieved using the calibration_curve() function in scikit-learn.
Some algorithms, such as SVM and neural networks, may not predict calibrated probabilities natively. In these cases, the probabilities can be calibrated and in turn may improve the chosen metric. Classifiers can be calibrated in scikit-learn using the CalibratedClassifierCV class.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
In this tutorial, you discovered three metrics that you can use to evaluate the predicted probabilities on your classification predictive modeling problem.
Specifically, you learned:
The log loss score that heavily penalizes predicted probabilities far away from their expected value.
The Brier score that is gentler than log loss but still penalizes proportional to the distance from the expected value
The area under ROC curve that summarizes the likelihood of the model predicting a higher probability for true positive cases than true negative cases.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
It provides self-study tutorials and end-to-end projects on: Bayes Theorem, Bayesian Optimization, Distributions, Maximum Likelihood, Cross-Entropy, Calibrating Models
and much more...
Many thanks for this. I have calculated a Brier Skill score on my horse ratings. I did this by calculating the naive score by applying Brier to the fraction of winners in the data set which is 0.1055 or 10.55%. Using this with the Brier skill score formula and the raw Brier score I get a BSS of 0.0117
This is better than zero which is good but how good ?
Do you have a tutorial for maximum Likelihood classification ?. Basically, I want to calculate a probability threshold value for every feature in X against class 0 or 1. Do you know how can we achieve this ?
I noticed something strange with the Brier score: brier_score_loss([1], [1], pos_label=1) returns 1 instead of 0. brier_score_loss([1], [0], pos_label=1) returns 0 instead of 1.
Looking into the source code, it seems that brier_score_loss breaks like this only when y_true contains a single unique class (like [1]).
I’m using the log loss for the Random Forest Model, and for some reason my log loss score is above 1 (1.53). Do you perhaps have any idea, as to why this could be?
Thank you for your machine learning post. Very useful!
My question is related to better understand probability predictions in Binary classification vs. Regression prediction with continuous numerical output for the same binary classification.
Imagine I have two groups of things, so I talk of binary classification. For example I use “sigmoid” function for my unique output neuron in my keras model. OK.
But anyway, imagine the intrinsic problem is not discrete (two values o classes) but a continuous values evolution between both classes, that anyway I can simplifying setting e.g. 0.5 probability as the frontier or threshold to distinguish between one class from the other. Ok. No problem.
But when I apply the regression prediction (I set up also a single neuron as output layer in my model ) But I got a continuous output values.
My question is : is the continuos probability of binary classification (between 0 and 1) equivalent to regression value of the regression classification, in terms of evolution between both classes (even values in regression and not limit to 0 and 1 (but can be from – infinity to + infinity) ? Is it right?
If we are optimizing a model under cross entropy loss, the output layer of the net could be a sigmoid or linear. We use sigmoid because we know we will always get a values in [0,1]. It could be linear activation, and the model will have to work a little harder to do the right thing.
Hi Jason, thank you for posting this excellent and useful tutorial! Things I learned:
(1) The interpretation of the AUC ROC score, as the chance that the model ranks a randomly chosen positive example higher than a randomly chosen negative example.
(2) AUC ROC score is robust against class imbalance.
(3) Brier Score and Cross-Entropy Loss both suffer from “overconfidence bias” under class imbalance
(4) Brier Skill Score is robust to class imbalance
Question: is there a modification of cross-entropy loss that is an analog of the Brier Skill Score? I.e. is there a modification of cross-entropy loss that mitigates against “overconfidence bias” under class imbalance?
Hi Jason,
Hi Jason,
I create classification model,
But I found that get other probabilities for same data ,
When I run the training process and when use with model .
Please advice
I have a question about the use of the Brier’s score (bearing in mind that I’m very new to both ML and python). I am currently using Brier’s score to evaluate constructed models. The goal of the model is to predict an estimated probability of a binary event, so I believe the Brier’s score is appropriate for this case. However, I am using cross-validation in the lightgbm package and random_search to determine the best hyperparameters. ‘brier’s score’ isn’t an available metric within ‘lgb.cv’, meaning that I can’t easily select the parameters which resulted in the lowest value for Brier’s score. Is the MSE equivalent in this case? i.e. could I use MSE as the evaluation metric for the CV and hyperparameter selection and then evaluate the final model using Brier’s score for a more sensible interpretation?
Generally, I would encourage you to use model to make predictions, save them to file, and load them in a new Python program and perform some analysis, including calculating metrics.
I don’t know about lightgbm, but perhaps you can simply define a new metrics function and make use of brier skill from sklearn?
Hi, I can’t seem to get the concept of postive class and negative class. For example in the context of whether or not a patient has cancer. A positive class would be “has cancer” class. But in the context of predicting if an object is a dog or a cat, how can we determine which class is the positive class? Or is there no importance whatever choice we make?
Thank you
2 small typos detected during lecture (in Log-Loss and Brier Score sections):
# define an *imbalanced* dataset
testy = [0 for x in range(50)] + [1 for x in range(50)]
Great post! Thank you. I think the “Line Plot of Evaluating Predictions with Brier Score” should be the other way around. Since, you are evaluating the predictions for a 1 true value not a 0 true value.
Great post as always. Consider an imbalance classification problem. 5 % are positive cases. binary classification problem. We are requested a model that can predict probabilities and the positive class is more important.
Would it make sense to use a probabilistc prediction method metric (like the Brier skill score) whitin a pipeline including a Data sampling method (ie SmoteTeeNN) .
PS: I recommend your books to all users here 🙂 Well worth the investement for a top down approach in learning machine learning.








Many thanks for this. I have calculated a Brier Skill score on my horse ratings. I did this by calculating the naive score by applying Brier to the fraction of winners in the data set which is 0.1055 or 10.55%. Using this with the Brier skill score formula and the raw Brier score I get a BSS of 0.0117
This is better than zero which is good but how good ?
To be a valid score of model performance, you would calculate the score for all forecasts in a period.
Do you have a tutorial for maximum Likelihood classification ?. Basically, I want to calculate a probability threshold value for every feature in X against class 0 or 1. Do you know how can we achieve this ?
No, sorry.
Yes I calculated the Brier base score for 0.1055 and then I calculated the Brier score for all my ratings thats 49,277 of them
Thank for this, Jason.
I noticed something strange with the Brier score:
brier_score_loss([1], [1], pos_label=1)returns 1 instead of 0.brier_score_loss([1], [0], pos_label=1)returns 0 instead of 1.Looking into the source code, it seems that
brier_score_lossbreaks like this only wheny_truecontains a single unique class (like[1]).This stems from a bug that is already reported here:
https://github.com/scikit-learn/scikit-learn/issues/9300
A quick workaround for your code would be to replace this line:
losses = [brier_score_loss([1], [x], pos_label=[1]) for x in yhat]
with the following:
losses = [2 * brier_score_loss([0, 1], [0, x], pos_label=[1]) for x in yhat]
Interesting. I guess it might not make much sense to evaluate a single forecast using Brier.
Brier score should be applicable for any number of forecasts.
Having a bug in
sklearnshouldn’t change that. 🙂That sklearn bug is also triggered when you have multiple forecasts but they all share the same true label.
Thanks for sharing.
‘An AUC score of 0.0 suggests no skill’ – here it should be 0.5 AUC, right? 0.0 would mean a perfect skill you just need to invert the classes.
Nice article ! Very well explained. Thanks
Thanks, fixed!
Hi Jason,
I’m using the log loss for the Random Forest Model, and for some reason my log loss score is above 1 (1.53). Do you perhaps have any idea, as to why this could be?
Thank You!
Yes it could be many reasons.
I have some suggestions here:
https://machinelearningmastery.com/machine-learning-performance-improvement-cheat-sheet/
Hi Jason!
Thank you for your machine learning post. Very useful!
My question is related to better understand probability predictions in Binary classification vs. Regression prediction with continuous numerical output for the same binary classification.
Imagine I have two groups of things, so I talk of binary classification. For example I use “sigmoid” function for my unique output neuron in my keras model. OK.
But anyway, imagine the intrinsic problem is not discrete (two values o classes) but a continuous values evolution between both classes, that anyway I can simplifying setting e.g. 0.5 probability as the frontier or threshold to distinguish between one class from the other. Ok. No problem.
But when I apply the regression prediction (I set up also a single neuron as output layer in my model ) But I got a continuous output values.
My question is : is the continuos probability of binary classification (between 0 and 1) equivalent to regression value of the regression classification, in terms of evolution between both classes (even values in regression and not limit to 0 and 1 (but can be from – infinity to + infinity) ? Is it right?
Thank you
Probably, if I understand you correctly.
If we are optimizing a model under cross entropy loss, the output layer of the net could be a sigmoid or linear. We use sigmoid because we know we will always get a values in [0,1]. It could be linear activation, and the model will have to work a little harder to do the right thing.
Does that help?
Hi Jason, thank you for posting this excellent and useful tutorial! Things I learned:
(1) The interpretation of the AUC ROC score, as the chance that the model ranks a randomly chosen positive example higher than a randomly chosen negative example.
(2) AUC ROC score is robust against class imbalance.
(3) Brier Score and Cross-Entropy Loss both suffer from “overconfidence bias” under class imbalance
(4) Brier Skill Score is robust to class imbalance
Question: is there a modification of cross-entropy loss that is an analog of the Brier Skill Score? I.e. is there a modification of cross-entropy loss that mitigates against “overconfidence bias” under class imbalance?
Nicely done!
Not sure I follow, they measure different things. Horses for courses and all that.
Point taken about horses for courses.
I’ll try again, then. Disregarding any mention of Brier score:
Is there a modified version of the cross-entropy score that is unbiased under class imbalance?
Not that I’m aware.
Hi Jason,
Hi Jason,
I create classification model,
But I found that get other probabilities for same data ,
When I run the training process and when use with model .
Please advice
What do you mean exactly, perhaps you can elaborate?
Thanks for the great article, Jason.
I have a question about the use of the Brier’s score (bearing in mind that I’m very new to both ML and python). I am currently using Brier’s score to evaluate constructed models. The goal of the model is to predict an estimated probability of a binary event, so I believe the Brier’s score is appropriate for this case. However, I am using cross-validation in the lightgbm package and random_search to determine the best hyperparameters. ‘brier’s score’ isn’t an available metric within ‘lgb.cv’, meaning that I can’t easily select the parameters which resulted in the lowest value for Brier’s score. Is the MSE equivalent in this case? i.e. could I use MSE as the evaluation metric for the CV and hyperparameter selection and then evaluate the final model using Brier’s score for a more sensible interpretation?
Thanks,
Rex
Thanks Rex.
Good question.
Generally, I would encourage you to use model to make predictions, save them to file, and load them in a new Python program and perform some analysis, including calculating metrics.
I don’t know about lightgbm, but perhaps you can simply define a new metrics function and make use of brier skill from sklearn?
Hi Jason,
thanks for this awesome tutorial!
I was a little confused with Brier, but when I ran the example, it became clear that your picture was mirrored and yhat==1 has a zero Brier loss.
i have sklearn 0.21.3
Thanks, I’m glad it helped.
Hi, I can’t seem to get the concept of postive class and negative class. For example in the context of whether or not a patient has cancer. A positive class would be “has cancer” class. But in the context of predicting if an object is a dog or a cat, how can we determine which class is the positive class? Or is there no importance whatever choice we make?
Thank you
It does not apply in that case, or the choice is arbitrary.
Great text Jason!
2 small typos detected during lecture (in Log-Loss and Brier Score sections):
# define an *imbalanced* dataset
testy = [0 for x in range(50)] + [1 for x in range(50)]
Regards!
Thanks, fixed!
Hey Jason,
Looks like the “Line Plot of Evaluating Predictions with Brier Score” is not correct
How so?
Hi Jason,
Great post! Thank you. I think the “Line Plot of Evaluating Predictions with Brier Score” should be the other way around. Since, you are evaluating the predictions for a 1 true value not a 0 true value.
Thanks.
Hello Jason. How can scoring be used to measure feature importance? I would like to select a handful of features after estimating the probabilities.
You must use statistical feature selection methods, see this:
https://machinelearningmastery.com/feature-selection-with-real-and-categorical-data/
Hi Jason,
Great post as always. Consider an imbalance classification problem. 5 % are positive cases. binary classification problem. We are requested a model that can predict probabilities and the positive class is more important.
Would it make sense to use a probabilistc prediction method metric (like the Brier skill score) whitin a pipeline including a Data sampling method (ie SmoteTeeNN) .
PS: I recommend your books to all users here 🙂 Well worth the investement for a top down approach in learning machine learning.
I try to avoid being perspective, perhaps this decision tree will help:
https://machinelearningmastery.com/tour-of-evaluation-metrics-for-imbalanced-classification/
Thanks for an informative article.
The Brier-score seems to be the same as the Mean Squared Error (MSE).
Is that correct?
If that is the case, would it not be better to report the error term using the same units as the data, by taking the root of the MSE, i.e. RMSE?
Yes, same calculation.
I don’t think so – I have not seen the root of brier score (RMSE) reported for probabilities.
Hi Jason,
We appreciate your perspective.
A quick question: how can I apply ROC AUC to a situation involving many classes?
Hi Issakafadil…You may find the following of interest:
https://towardsdatascience.com/multiclass-classification-evaluation-with-roc-curves-and-roc-auc-294fd4617e3a