XGBoost is an efficient implementation of gradient boosting for classification and regression problems.
It is both fast and efficient, performing well, if not the best, on a wide range of predictive modeling tasks and is a favorite among data science competition winners, such as those on Kaggle.
XGBoost can also be used for time series forecasting, although it requires that the time series dataset be transformed into a supervised learning problem first. It also requires the use of a specialized technique for evaluating the model called walk-forward validation, as evaluating the model using k-fold cross validation would result in optimistically biased results.
In this tutorial, you will discover how to develop an XGBoost model for time series forecasting.
After completing this tutorial, you will know:
- XGBoost is an implementation of the gradient boosting ensemble algorithm for classification and regression.
- Time series datasets can be transformed into supervised learning using a sliding-window representation.
- How to fit, evaluate, and make predictions with an XGBoost model for time series forecasting.
Kick-start your project with my new book XGBoost With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
- Update Aug/2020: Fixed bug in the calculation of MAE, updated model config to make better predictions (thanks Kaustav!)

How to Use XGBoost for Time Series Forecasting
Photo by gothopotam, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
- XGBoost Ensemble
- Time Series Data Preparation
- XGBoost for Time Series Forecasting
XGBoost Ensemble
XGBoost is short for Extreme Gradient Boosting and is an efficient implementation of the stochastic gradient boosting machine learning algorithm.
The stochastic gradient boosting algorithm, also called gradient boosting machines or tree boosting, is a powerful machine learning technique that performs well or even best on a wide range of challenging machine learning problems.
Tree boosting has been shown to give state-of-the-art results on many standard classification benchmarks.
— XGBoost: A Scalable Tree Boosting System, 2016.
It is an ensemble of decision trees algorithm where new trees fix errors of those trees that are already part of the model. Trees are added until no further improvements can be made to the model.
XGBoost provides a highly efficient implementation of the stochastic gradient boosting algorithm and access to a suite of model hyperparameters designed to provide control over the model training process.
The most important factor behind the success of XGBoost is its scalability in all scenarios. The system runs more than ten times faster than existing popular solutions on a single machine and scales to billions of examples in distributed or memory-limited settings.
— XGBoost: A Scalable Tree Boosting System, 2016.
XGBoost is designed for classification and regression on tabular datasets, although it can be used for time series forecasting.
For more on the gradient boosting and XGBoost implementation, see the tutorial:
First, the XGBoost library must be installed.
You can install it using pip, as follows:
|
1 |
sudo pip install xgboost |
Once installed, you can confirm that it was installed successfully and that you are using a modern version by running the following code:
|
1 2 3 |
# xgboost import xgboost print("xgboost", xgboost.__version__) |
Running the code, you should see the following version number or higher.
|
1 |
xgboost 1.0.1 |
Although the XGBoost library has its own Python API, we can use XGBoost models with the scikit-learn API via the XGBRegressor wrapper class.
An instance of the model can be instantiated and used just like any other scikit-learn class for model evaluation. For example:
|
1 2 3 |
... # define model model = XGBRegressor() |
Now that we are familiar with XGBoost, let’s look at how we can prepare a time series dataset for supervised learning.
Time Series Data Preparation
Time series data can be phrased as supervised learning.
Given a sequence of numbers for a time series dataset, we can restructure the data to look like a supervised learning problem. We can do this by using previous time steps as input variables and use the next time step as the output variable.
Let’s make this concrete with an example. Imagine we have a time series as follows:
|
1 2 3 4 5 6 |
time, measure 1, 100 2, 110 3, 108 4, 115 5, 120 |
We can restructure this time series dataset as a supervised learning problem by using the value at the previous time step to predict the value at the next time-step.
Reorganizing the time series dataset this way, the data would look as follows:
|
1 2 3 4 5 6 7 |
X, y ?, 100 100, 110 110, 108 108, 115 115, 120 120, ? |
Note that the time column is dropped and some rows of data are unusable for training a model, such as the first and the last.
This representation is called a sliding window, as the window of inputs and expected outputs is shifted forward through time to create new “samples” for a supervised learning model.
For more on the sliding window approach to preparing time series forecasting data, see the tutorial:
We can use the shift() function in Pandas to automatically create new framings of time series problems given the desired length of input and output sequences.
This would be a useful tool as it would allow us to explore different framings of a time series problem with machine learning algorithms to see which might result in better-performing models.
The function below will take a time series as a NumPy array time series with one or more columns and transform it into a supervised learning problem with the specified number of inputs and outputs.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# transform a time series dataset into a supervised learning dataset def series_to_supervised(data, n_in=1, n_out=1, dropnan=True): n_vars = 1 if type(data) is list else data.shape[1] df = DataFrame(data) cols = list() # input sequence (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) # forecast sequence (t, t+1, ... t+n) for i in range(0, n_out): cols.append(df.shift(-i)) # put it all together agg = concat(cols, axis=1) # drop rows with NaN values if dropnan: agg.dropna(inplace=True) return agg.values |
We can use this function to prepare a time series dataset for XGBoost.
For more on the step-by-step development of this function, see the tutorial:
Once the dataset is prepared, we must be careful in how it is used to fit and evaluate a model.
For example, it would not be valid to fit the model on data from the future and have it predict the past. The model must be trained on the past and predict the future.
This means that methods that randomize the dataset during evaluation, like k-fold cross-validation, cannot be used. Instead, we must use a technique called walk-forward validation.
In walk-forward validation, the dataset is first split into train and test sets by selecting a cut point, e.g. all data except the last 12 days is used for training and the last 12 days is used for testing.
If we are interested in making a one-step forecast, e.g. one month, then we can evaluate the model by training on the training dataset and predicting the first step in the test dataset. We can then add the real observation from the test set to the training dataset, refit the model, then have the model predict the second step in the test dataset.
Repeating this process for the entire test dataset will give a one-step prediction for the entire test dataset from which an error measure can be calculated to evaluate the skill of the model.
For more on walk-forward validation, see the tutorial:
The function below performs walk-forward validation.
It takes the entire supervised learning version of the time series dataset and the number of rows to use as the test set as arguments.
It then steps through the test set, calling the xgboost_forecast() function to make a one-step forecast. An error measure is calculated and the details are returned for analysis.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# walk-forward validation for univariate data def walk_forward_validation(data, n_test): predictions = list() # split dataset train, test = train_test_split(data, n_test) # seed history with training dataset history = [x for x in train] # step over each time-step in the test set for i in range(len(test)): # split test row into input and output columns testX, testy = test[i, :-1], test[i, -1] # fit model on history and make a prediction yhat = xgboost_forecast(history, testX) # store forecast in list of predictions predictions.append(yhat) # add actual observation to history for the next loop history.append(test[i]) # summarize progress print('>expected=%.1f, predicted=%.1f' % (testy, yhat)) # estimate prediction error error = mean_absolute_error(test[:, -1], predictions) return error, test[:, 1], predictions |
The train_test_split() function is called to split the dataset into train and test sets.
We can define this function below.
|
1 2 3 |
# split a univariate dataset into train/test sets def train_test_split(data, n_test): return data[:-n_test, :], data[-n_test:, :] |
We can use the XGBRegressor class to make a one-step forecast.
The xgboost_forecast() function below implements this, taking the training dataset and test input row as input, fitting a model, and making a one-step prediction.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# fit an xgboost model and make a one step prediction def xgboost_forecast(train, testX): # transform list into array train = asarray(train) # split into input and output columns trainX, trainy = train[:, :-1], train[:, -1] # fit model model = XGBRegressor(objective='reg:squarederror', n_estimators=1000) model.fit(trainX, trainy) # make a one-step prediction yhat = model.predict([testX]) return yhat[0] |
Now that we know how to prepare time series data for forecasting and evaluate an XGBoost model, next we can look at using XGBoost on a real dataset.
XGBoost for Time Series Forecasting
In this section, we will explore how to use XGBoost for time series forecasting.
We will use a standard univariate time series dataset with the intent of using the model to make a one-step forecast.
You can use the code in this section as the starting point in your own project and easily adapt it for multivariate inputs, multivariate forecasts, and multi-step forecasts.
We will use the daily female births dataset, that is the monthly births across three years.
You can download the dataset from here, place it in your current working directory with the filename “daily-total-female-births.csv“.
The first few lines of the dataset look as follows:
|
1 2 3 4 5 6 7 |
"Date","Births" "1959-01-01",35 "1959-01-02",32 "1959-01-03",30 "1959-01-04",31 "1959-01-05",44 ... |
First, let’s load and plot the dataset.
The complete example is listed below.
|
1 2 3 4 5 6 7 8 9 |
# load and plot the time series dataset from pandas import read_csv from matplotlib import pyplot # load dataset series = read_csv('daily-total-female-births.csv', header=0, index_col=0) values = series.values # plot dataset pyplot.plot(values) pyplot.show() |
Running the example creates a line plot of the dataset.
We can see there is no obvious trend or seasonality.
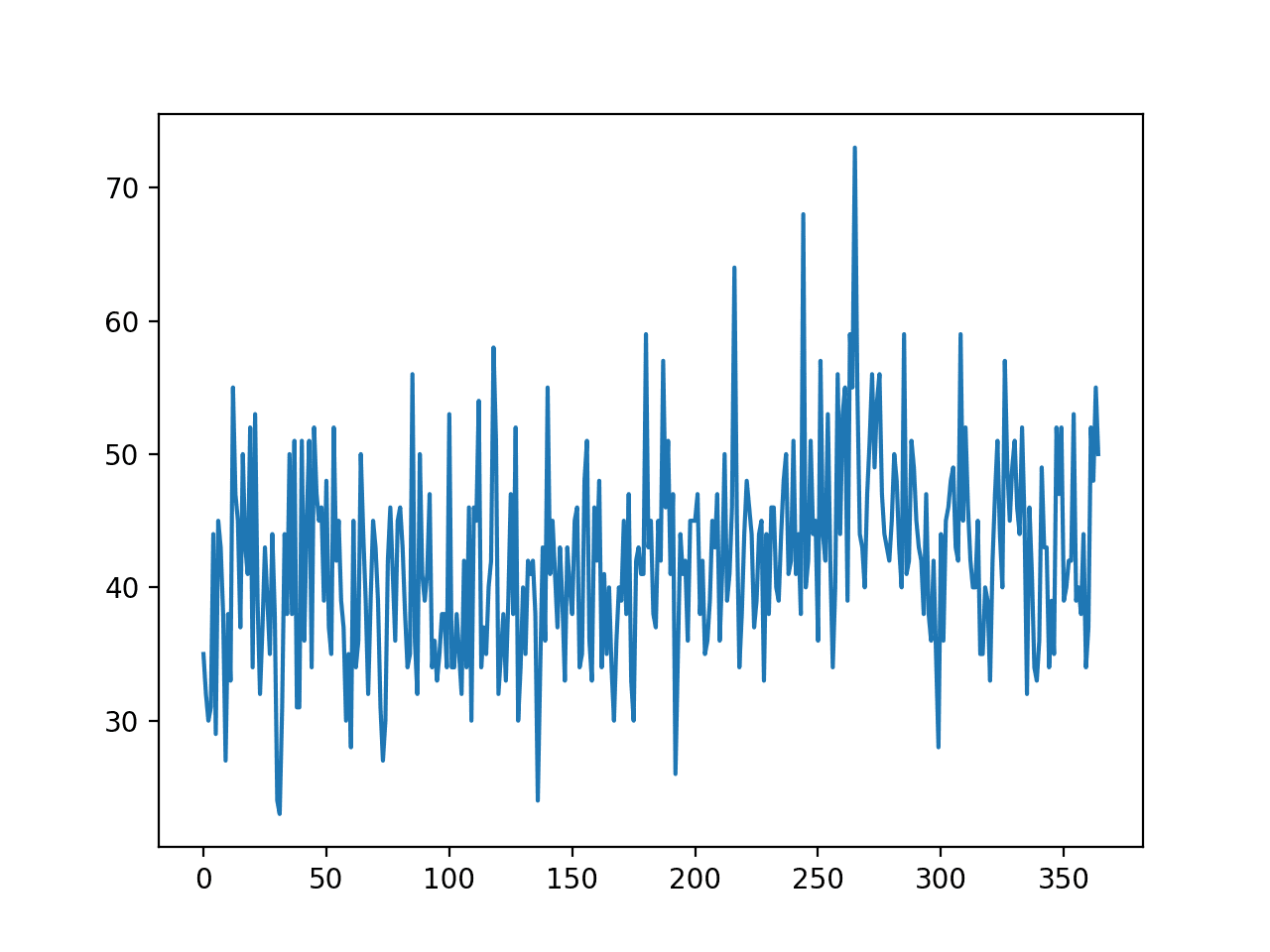
Line Plot of Monthly Births Time Series Dataset
A persistence model can achieve a MAE of about 6.7 births when predicting the last 12 days. This provides a baseline in performance above which a model may be considered skillful.
Next, we can evaluate the XGBoost model on the dataset when making one-step forecasts for the last 12 days of data.
We will use only the previous 6 time steps as input to the model and default model hyperparameters, except we will change the loss to ‘reg:squarederror‘ (to avoid a warning message) and use a 1,000 trees in the ensemble (to avoid underlearning).
The complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
# forecast monthly births with xgboost from numpy import asarray from pandas import read_csv from pandas import DataFrame from pandas import concat from sklearn.metrics import mean_absolute_error from xgboost import XGBRegressor from matplotlib import pyplot # transform a time series dataset into a supervised learning dataset def series_to_supervised(data, n_in=1, n_out=1, dropnan=True): n_vars = 1 if type(data) is list else data.shape[1] df = DataFrame(data) cols = list() # input sequence (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) # forecast sequence (t, t+1, ... t+n) for i in range(0, n_out): cols.append(df.shift(-i)) # put it all together agg = concat(cols, axis=1) # drop rows with NaN values if dropnan: agg.dropna(inplace=True) return agg.values # split a univariate dataset into train/test sets def train_test_split(data, n_test): return data[:-n_test, :], data[-n_test:, :] # fit an xgboost model and make a one step prediction def xgboost_forecast(train, testX): # transform list into array train = asarray(train) # split into input and output columns trainX, trainy = train[:, :-1], train[:, -1] # fit model model = XGBRegressor(objective='reg:squarederror', n_estimators=1000) model.fit(trainX, trainy) # make a one-step prediction yhat = model.predict(asarray([testX])) return yhat[0] # walk-forward validation for univariate data def walk_forward_validation(data, n_test): predictions = list() # split dataset train, test = train_test_split(data, n_test) # seed history with training dataset history = [x for x in train] # step over each time-step in the test set for i in range(len(test)): # split test row into input and output columns testX, testy = test[i, :-1], test[i, -1] # fit model on history and make a prediction yhat = xgboost_forecast(history, testX) # store forecast in list of predictions predictions.append(yhat) # add actual observation to history for the next loop history.append(test[i]) # summarize progress print('>expected=%.1f, predicted=%.1f' % (testy, yhat)) # estimate prediction error error = mean_absolute_error(test[:, -1], predictions) return error, test[:, -1], predictions # load the dataset series = read_csv('daily-total-female-births.csv', header=0, index_col=0) values = series.values # transform the time series data into supervised learning data = series_to_supervised(values, n_in=6) # evaluate mae, y, yhat = walk_forward_validation(data, 12) print('MAE: %.3f' % mae) # plot expected vs preducted pyplot.plot(y, label='Expected') pyplot.plot(yhat, label='Predicted') pyplot.legend() pyplot.show() |
Running the example reports the expected and predicted values for each step in the test set, then the MAE for all predicted values.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
We can see that the model performs better than a persistence model, achieving a MAE of about 5.9 births, compared to 6.7 births.
Can you do better?
You can test different XGBoost hyperparameters and numbers of time steps as input to see if you can achieve better performance. Share your results in the comments below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
>expected=42.0, predicted=44.5 >expected=53.0, predicted=42.5 >expected=39.0, predicted=40.3 >expected=40.0, predicted=32.5 >expected=38.0, predicted=41.1 >expected=44.0, predicted=45.3 >expected=34.0, predicted=40.2 >expected=37.0, predicted=35.0 >expected=52.0, predicted=32.5 >expected=48.0, predicted=41.4 >expected=55.0, predicted=46.6 >expected=50.0, predicted=47.2 MAE: 5.957 |
A line plot is created comparing the series of expected values and predicted values for the last 12 days of the dataset.
This gives a geometric interpretation of how well the model performed on the test set.
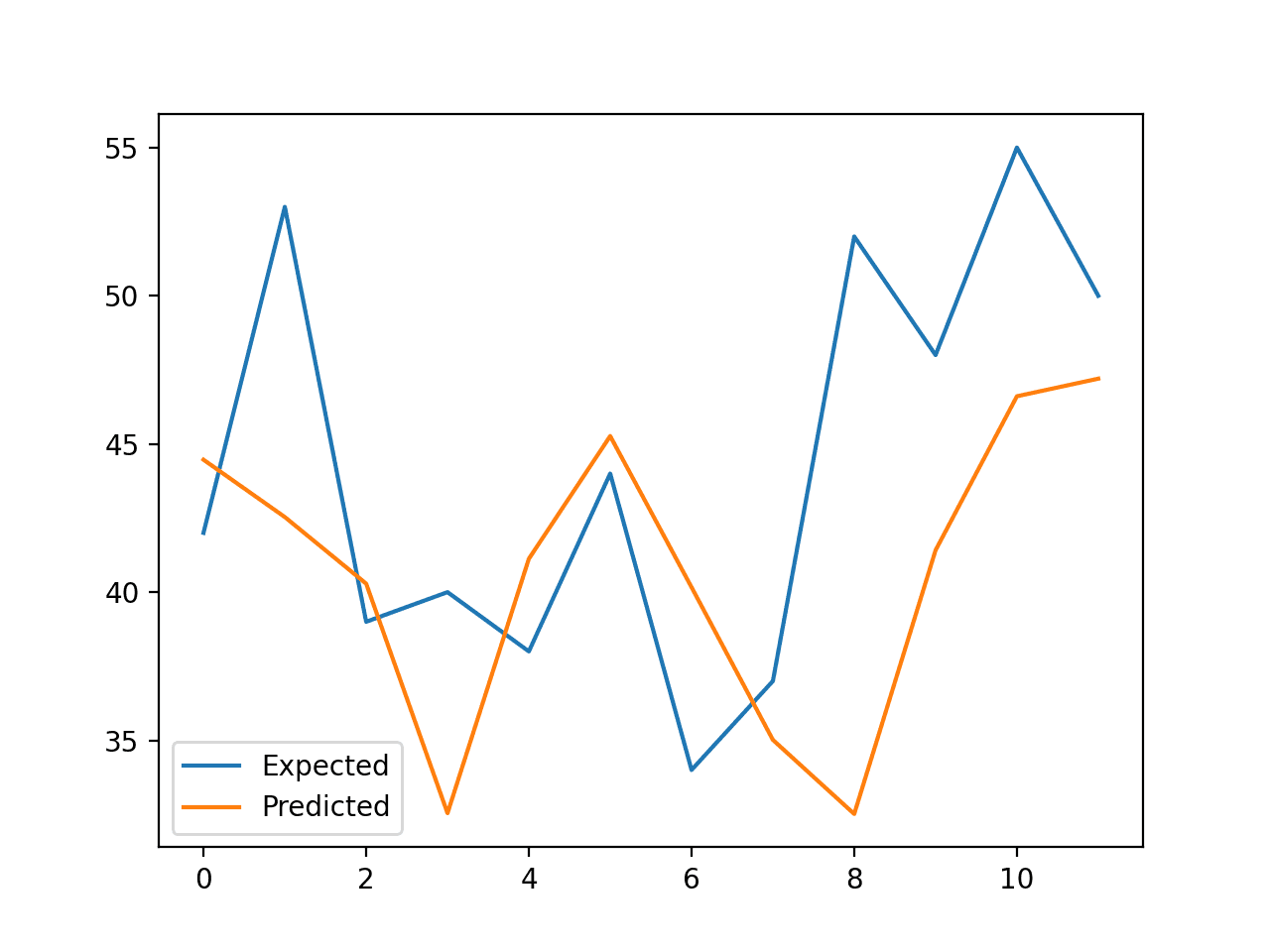
Line Plot of Expected vs. Births Predicted Using XGBoost
Once a final XGBoost model configuration is chosen, a model can be finalized and used to make a prediction on new data.
This is called an out-of-sample forecast, e.g. predicting beyond the training dataset. This is identical to making a prediction during the evaluation of the model: as we always want to evaluate a model using the same procedure that we expect to use when the model is used to make prediction on new data.
The example below demonstrates fitting a final XGBoost model on all available data and making a one-step prediction beyond the end of the dataset.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
# finalize model and make a prediction for monthly births with xgboost from numpy import asarray from pandas import read_csv from pandas import DataFrame from pandas import concat from xgboost import XGBRegressor # transform a time series dataset into a supervised learning dataset def series_to_supervised(data, n_in=1, n_out=1, dropnan=True): n_vars = 1 if type(data) is list else data.shape[1] df = DataFrame(data) cols = list() # input sequence (t-n, ... t-1) for i in range(n_in, 0, -1): cols.append(df.shift(i)) # forecast sequence (t, t+1, ... t+n) for i in range(0, n_out): cols.append(df.shift(-i)) # put it all together agg = concat(cols, axis=1) # drop rows with NaN values if dropnan: agg.dropna(inplace=True) return agg.values # load the dataset series = read_csv('daily-total-female-births.csv', header=0, index_col=0) values = series.values # transform the time series data into supervised learning train = series_to_supervised(values, n_in=6) # split into input and output columns trainX, trainy = train[:, :-1], train[:, -1] # fit model model = XGBRegressor(objective='reg:squarederror', n_estimators=1000) model.fit(trainX, trainy) # construct an input for a new preduction row = values[-6:].flatten() # make a one-step prediction yhat = model.predict(asarray([row])) print('Input: %s, Predicted: %.3f' % (row, yhat[0])) |
Running the example fits an XGBoost model on all available data.
A new row of input is prepared using the last 6 days of known data and the next month beyond the end of the dataset is predicted.
|
1 |
Input: [34 37 52 48 55 50], Predicted: 42.708 |
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Related Tutorials
- A Gentle Introduction to the Gradient Boosting Algorithm for Machine Learning
- Time Series Forecasting as Supervised Learning
- How to Convert a Time Series to a Supervised Learning Problem in Python
- How To Backtest Machine Learning Models for Time Series Forecasting
Summary
In this tutorial, you discovered how to develop an XGBoost model for time series forecasting.
Specifically, you learned:
- XGBoost is an implementation of the gradient boosting ensemble algorithm for classification and regression.
- Time series datasets can be transformed into supervised learning using a sliding-window representation.
- How to fit, evaluate, and make predictions with an XGBoost model for time series forecasting.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Discover The Algorithm Winning Competitions!

Develop Your Own XGBoost Models in Minutes
...with just a few lines of Python
Discover how in my new Ebook:
XGBoost With Python
It covers self-study tutorials like:
Algorithm Fundamentals, Scaling, Hyperparameters, and much more...
Bring The Power of XGBoost To Your Own Projects
Skip the Academics. Just Results.






The result does not really look convincing
Fair enough.
Consider the model a template that you can apply on your own projects.
Excellent explained very nicely
Keep it up
Thanks!
Can I use xgboost for multivariate time series data ?
Sure.
This article doesn’t make a cogent argument for using XGBoost for time-series or time dependent data.
Without any sort of weighting based on time, the algorithm has no way of knowing how to incorporate time – it just looks at isolated points e.g. A yields 400, B yields 510 with no chronological relationship between A and B. The expected vs predicted graph you show clearly indicates that the model fails to establish a proper relationship between time and predictions.
I’ve tried to implement XGBoost in financial forecasting with 2 years historical data, it just doesn’t work well. Sometimes you can get better accuracies with ensembling techniques, but nothing really beats a true time series model. In that case, I’d use the pmdarima package and the auto.arima function is fantastic.
I get that you could use this as an example template, but I think it’s not really instructional until you measure this against a time-series model or apply some sort of time weights to non-time series models to get a clear idea of what options exist.
At worst, this article is misleading. At best, it’s flawed and requires more testing and examples.
I appreciate you putting this out there because it brings up some good questions on how to approach time series problems with some more flexibility, I’d look forward to a more thorough article on this topic.
Thanks for sharing, sorry it does not work for your specific datasets.
I disagree that it is misleading.
I agree with Rahul, in that this does not seem to account for things that time-series models are designed to address, such as seasonality, whether the data is stationary or not, etc.
Sure, only try it on your data if you think it offers some benefit over other methods.
You can engineer some new features that will potentially account for seasonality if you are creative enough.
Agreed!
This is a framework for applying Xgboost to time-series data. Like a lot of what we do in data science, it is experimental and it may or may not work on your specific problem.
You say it cant incorporate time because it cant apply a weighting, but there is no hard and fast rule that says that’s what has to happen. If you believe that you are making a critical mistake in data science (or any science for that matter) by applying your assumptions onto what should provide good results, as opposed to experimenting and letting the results inform you about what works.
No machine learning model inherently knows about time, its not a human being, all it knows about is data points. What we care about is whether our chosen machine learning algorithm can accurately enough map those input data points to an output data point.
I have applied XGBoost to financial modelling problems, and with the right data sets, correct feature engineering, optimisations, lots of experimentation and importantly not letting my assumptions get in the way about what will work and what wont, I have got it to work, but it was by no means easy to resolve. Don’t discredit it just because you could not.
Dear Dr Jason,
I have a question on single variable data such as “sunspot” data. There are no X values or features. It is called “univariate” as shown in your blog https://machinelearningmastery.com/time-series-datasets-for-machine-learning/. Yes univariate datasets have date information as in dd-mm-yyyy info or it could be derived by an array of x = [i for i in range(len(mydataset))].
Can model evaluation such as train-test-splitting, model, RepeatedClassifiedKFold and cross_val_score be performed on univariate time series with time a feature of X and y the univariate data series, for example sunspot data?
Thank you,
Anthony of Sydney
It is univariate. Date/times are dropped.
Cross-validation is generally invalid for time series data, see this:
https://machinelearningmastery.com/backtest-machine-learning-models-time-series-forecasting/
Dear Dr Jason,
Thank you for averting to the sitehttps://machinelearningmastery.com/backtest-machine-learning-models-time-series-forecasting/.
Despite no cross-validation, nevertheless train/test split is still performed and the sunspot data is used as an example dataset to “experiment” with.
Thank you, it is appreciated.
Anthony of Sydney
Obviously, if you have the birth rate from 1960 and from then on, we can really test how good the model is.
Also, since the time is left out, you cannot treat gappy time series, as often happens for natural phemonena like variable star research.
Thanks for your note.
Hi Jason! do you think we could have a multivariate variation of this?
Great suggestion!
Yes please do a multi X – one Y variation!!!
That should be a trivial change to the code. Did you try?
Do you need to detrend and deseasonalize the data when using XGBoost?
Depends. Try with and without and compare the results.
Hi Jason, can the code be modified to make more than a one step prediction at the end of the dataset? If so any tips 🙂
For example could I go further out than
yhat = model.predict(asarray([row]))? I am also running my own dataset, one month of a building electricity usage (kW) on 15 minute intervals… My results are pretty good for the expected & predicted plots.I was just curious about being able to predict more data than 1 minute 15 data point.. Thanks
Good question.
Yes, you could use one of the following wrapper classes:
https://machinelearningmastery.com/multi-output-regression-models-with-python/
Jason thanks for the additional info… For time series application (as I mentioned electricity dataset) would you recommend going for Chained Multioutput Regression tactic? OR the Direct Multioutput Regression as mentioned in the link you sent?
Perhaps test both and discover what works well.
I’m not sure that is the best way to do it, but i have a loop that appends the forecast to the dataset, and re-trains XGB
values = df.close.values
preds = []
for i in range(10):
# transform the time series data into supervised learning
train = series_to_supervised(values, n_in=6)
# split into input and output columns
trainX, trainy = train[:, :-1], train[:, -1]
# fit model
model = XGBRegressor(objective=’reg:squarederror’, n_estimators=1000)
model.fit(trainX, trainy)
# construct an input for a new preduction
row = values[-6:].flatten()
# make a one-step prediction
yhat = model.predict(asarray([row]))
print(‘Input: %s, Predicted: %.3f’ % (row, yhat[0]))
values = np.append(values, yhat)
preds.append(yhat)
The preds array contains the next 10 forecasted steps
thanks mate! you saved my project
Hi ben it would be great if you can share your code i am also trying to implement on the electricity data.
Thanks
Jason one other question. If I create some plots with the code for expected & predicted analysis. Can I save this model in like a pickle to use on the prediction code? OR would the models be the same parameters between the
# forecast monthly births with xgboost
# forecast monthly births with xgboostscripts?I believe you can pickle an xgboost model. Perhaps test it to confirm.
Wondering why have you returned test[:,1] in the walk_forward_validation() function, and why is that being used to calculate error? Shouldnt it be test[:,-1]? We are predicting the last column right, hence it should be compared with the last column
You’re right, looks like a typo.
Fixed. Thanks!
Even what you’re returning should be corrected then right?
Correct!
No idea what I was thinking. More coffee is needed…
Thanks for pointing out these dumb errors.
Hi Jason. Thanks for the material.
I think there is an error on error calculus:
mean_absolute_error(test[:, -1], predictions)
If you pay attention on “test[:, -1]” you is notice the array isn’t align with the correct values.
I’m right?
Sorry. I made a confusion. It’s ok!
No problem.
I believe the code is correct.
It is common for models to mostly forecast the previous value as the next value, called a persistence forecast. When plotted, it looks like the forecast is one step behind the observations.
Hi Jason. Thanks for the material. After reading your explanation about xgboost, I want to try to use this method for time series forecasting. You mentioned in the article that this method can be extended to multivariate input. I want to use several parameters to predict the cyclical trend of another correlated parameter. How should I adjust the existing method?
You’re welcome.
The same function for preparing the data can be used directly I believe. Try it and see.
Hi Jason.
Thanks for providing helpful tutorials. I am subscribing your super bundle package, and all of them are very useful for self training.
Wonder if you have solutions for multivariate, multi-timesteps forecast using XGBoost. I could not find if in your book, xgboost_with_python. Thanks !
Thanks!
Good question. I don’t have examples of time series in the xgboost book.
You can adapt the above example to work with multivariate time series data directly. Multi-step could be achieved if the xgboost supports multiple output directly (I think it does) or if you use a multi output regression wrapper class from here:
https://machinelearningmastery.com/multi-output-regression-models-with-python/
Thank you for such a great resource!
Why are you using XGBoost, not Random Forest, for example? Does XGBoost work better for such kind of tasks? If yes, why?
No reason other than many people asked me how to use xgboost for time series.
Hi Jason, thanks for the tutorial . What I want to ask is that each time when I make a prediction for a new data in real case, I need to transform it into supervised learning datasets with all the history data. Is that correct? In my understanding, only this way can get the lag information for the new data. If it’s true, how to improve the performance if I have big volume of history data? Every time I make a prediction, I need to shift all the history data again. Especially if I have multivariate, that would be time consuming. Finding a solution for that case. Thanks
Yes.
Test different amounts of lag, different data transforms, different model configs in order to discover what works best for your dataset.
Hi Jason,
Just to verify/clarify, when the chart is made, “expected” == “actual” data, right? We are comparing predicted values to actual/expected data…
I just wanted to verify the words that expected means actual real data.
It is expected vs predicted, expected is the data in the dataset.
Hi Jason,
Could I use this
walk_forward_validationyou demonstrated that predicts one future value with MultiOutputRegressor ?Ultimately I want to predict multiple future values with something like:
MultiOutputRegressor(XGBRegressor(objective='reg:squarederror', n_estimators=1000))Would I need to modify my
walk_forward_validationto reflect myMultiOutputRegressorprocess that is ultimately my end goal?My
XGBRegressor(objective='reg:squarederror', n_estimators=1000)is the exact same used in mywalk_forward_validationand as with the sci kit learn wrapperMultiOutputRegressorthat predicts 24 future values. Curious if this matters at all or if thewalk_forward_validationwould be meaning less because I am usingMultiOutputRegressorHopefully that makes sense! Thank you so much for your posts, the results using this process have been much better than ARIMA or LSTM methods..
Maybe. You may have to experiment.
Jason,
Is there anything wrong with using a neural network with
MultiOutputRegressor?Ive been experimenting with the sci kit learn
MLPRegressormodel = MLPRegressor(max_iter=2000, shuffle=False)multi_output_regr = MultiOutputRegressor(model)The thought ran across my head to ask since I notice that all NN for time series forecasting seems to be all about a pattern recognition like LSTM…
I don’t see why not. Perhaps try it and see how you go.
Jason would it be real strange to train an MLP NN (not shuffled data) on a time series dataset with a lot of dummy variables that represent day-of-week & time-of-day, along with an outside air temperature sensor reading (electricity power dataset). Save the model in a pickel file…
If I only have 1 years data, could I ever inverse transform the training dataset to test the model in like a block chain format with calculated dummy variables?
2 questions sorry!
Hard to say, perhaps try it and see.
Hi Ben,
Did multioutput regressor work for you with the walk forward validation? If it did, would you please share what modifications work for you
Thanks
Great tutorial as always. I noticed that you’re not using xgboost’s early stopping feature – where it compares the training performance to a test set, and stops training more trees if the performance has flattened out.
Is this because you’re unable to alter n_estimators for every step that you walk forward? Basically you’d need to manually set (or do a GridSearchCV) to find the best n_estimators across all walk-forward steps?
Thanks.
Early stopping is hard to do with time series data, e.g. you cannot reasonably define a validation set.
It might be simpler to grid search different numbers of trees on the walk-forward validation test harness.
Hi Jason,
Thanks for the great tutorial.
It helps me a lot.
I just wonder how I can use XGBoost to forecast the new value for the next 30 days?
There are many ways to use an xgboost model for multi-step predictions, here are some ideas:
https://machinelearningmastery.com/multi-step-time-series-forecasting/
Hi Jason,
I read that XGB cannot extrapolate trend, if a trend is observed, would it help to add a well fitted ARIMA as a feature?
Source: https://www.kaggle.com/c/web-traffic-time-series-forecasting/discussion/38352
Thanks for sharing.
Use whatever works best for your dataset.
why??
you said:
A new row of input is prepared using the last 6 months of known data and the next month beyond the end of the dataset is predicted.
Input: [34 37 52 48 55 50], Predicted: 42.708
but i saw:
the new row of input is prepared using the last 6 days of data( the model was trainned with all day of years) and the next day beyond the end of ….
the dataframe has 365 row, and each row is a day, so you sent to model [(34 37 52 48 55, lagged feature), (50=the value i want to predict)] and predict only the next day to 159-12-31 (50)] that are the last 6 days:
360 1959-12-27 37
361 1959-12-28 52
362 1959-12-29 48
363 1959-12-30 55
364 1959-12-31 50
thus, you prediced the next day that is ,42.708
am i wrong jason?
Sorry, not sure I follow.
You can frame the prediction prediction any way that you want.
Just a clarification that may be causing some confusion in the comments, Jason mentions “last 12 months” but this is really the last 12 days in the data. The dataset, as it stands, has 365 days in it from 1959, and Jason is using the last 12 days, he’s not actually doing anything with months at all from what I see.
Thanks! Fixed.
Hey Jason, thanks a lot for this really helpful guide. It worked fine for predicting last 12 days using my own dataset but when I tried to predict last 195 days in dataset with 780 records I got follwing error message: “IndexError: too many indices for array: array is 1-dimensional, but 2 were indexed”. I think this only works until 99 days, correct?
There is no limit on the number of days to predict, perhaps check your data preparation and the model.
Thanks for the reply!! I’m new to machine learning and can’t really figure out how I can predict last 195 values based on first 585 data points? I changed n_test in walk_forward_validation to 195 and n_in from series_to_supervised to 585. It seems to work fine but I’m not sure whether it is acutally using 585 values to predict these. Can you please confirm this?
Perhaps you can inspect the data after you prepared it to confirm the data preparation step is doing what you expect.
hi jason, may i ask does the data have to be stationary when using xgboost to do forecast ? can a non-stationary time series work
No, but it is probably a good idea.
Hello Jason, sir,
I hope you are doing well.
I am in a uni project where I have to find user ID (Classify the user) using other features (IoT Wearable data – FitRec). I plan to do XGBClassifier on that data (which I think is multivariate time series data), but I am challenged with feeding the data in Python—wondering if you can advise if the XGBoost is suitable for this problem? If yes, how can I feed data into a model?
Also, how can we add both time series and non-time-series data together in the model to get the output?
Looking forward to your reply. Thanks, Sir
Regards
Payal Joshi
I recommend testing a suite of different algorithms in order to discover what works well or best for your specific dataset.
Can’t believe I got baited so hard into thinking that this would work. It didn’t.
The example works just fine.
Sorry to hear that you had problems running the example, perhaps you can summarize the issue you had or error you saw?
Perhaps these tips will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Can I make 10 out-of-sample forecasts and if yes, how?
Call model.predict() with any input data you like.
Why when I predict a 100 points dataset using 10-step predictions at a time for 10 times appending the predicted value in testX the MAE is smaller when I predict 10 points appending 5 actual values in train for 10 times? It does make sense
I don’t know. Perhaps double check your code and results.
Thank you for the great tutorial Jason! You mentioned that a walk forward validation technique should be used to respect the time series nature of the data. In the boosting algorithm, each estimator is trained on a bootstrap sample. Would it make sense for the algorithm to use block bootstrap sampling instead of traditional bootstrap sampling to respect the time series nature of the data?
As long as the model is fit on the past and evaluated on the future, no data leakage will occur.
Very resourceful tutorial Jason , Thank you. I was wandering whether Python has any package for MAPE like one you have used for calculating MAE.
See this:
https://scikit-learn.org/stable/modules/generated/sklearn.metrics.mean_absolute_percentage_error.html
Hi Jason,
Is it possible to forecast for future periods using XGBoost model ? if possible how?
we are predicting the results using test data but for future period i dont have any data.
Sure. Call model.predict()
Hi Jason, thanks for the wonderful article, I tried calling model. predict() for future value prediction & getting an error.
–> 38 yhat11=model.predict()
39
40 print(yhat11)
TypeError: predict() missing 1 required positional argument: ‘X’
The model knows how to produce the output based on the input. But you must provide the input. It is expecting you to write yhat11 = model.predict(X) for some X
Hi Jason
Thank you for posting a very informative tutorial.
I am able to run your code correctly for one step ahead but when i try multi-step forecasting it generates the following error during the “fit” model call:
alidate_meta_shape
assert len(data.shape) == 1 or (
AssertionError
I think you should do one step at a time and feed the forecasted value back into input for next step. That would be easier.
Thank you for your reply.
This is an excellent pointer to multi step prediction. However, in my case it would be good that I am more interested in predicting multiple steps for one input query.
Regards
Quite difficult with decision tree but you can try to set up data with multistep output for the training. In this case you need way more data to train as you are in much higher dimensionality.
How to forecast future values with xg boost like we did in arima next 7 days or next one month ? How do I pass next one week date and predict values ? Any examples please suggest me
Hi Manju…the following is great starting point to address your questions.
https://towardsdatascience.com/xgboost-for-time-series-youre-gonna-need-a-bigger-boat-9d329efa6814
Hi Jason,
thanks for the post.
Some people have raised the same question but I would like to extend your code to multivariate series.
Having 10 time series, want to predict 1 sample ahead for all of them.
The problem in my pov is the series_to_supervised function. How should I modify it?
my second thought is: in order to facilitate the algorithm I would like to insert exogenous variables to the dataset, like year, month, as features which can help it to identify seasonality.
To such problem I call them exogenous because I am not asking the xgboost to predict also year and month but just to use them as additional info.
So the second question is:
can one specify during training to xgboost function arguments such “exogenous” variables?
like xgboostRegressor(exog=df).fit(x,y), where df is a dataframe of two variables year, month
thanks a lot
Luigi
Hi Jason,
It’ an really amazing illustration of XGBoost and time series methods. I have a question on the potential problem of having data leakage “from the future” if one provides a DataFrame instead of a data series to the function series_to_supervised().
I believe in the current implementation, if one has multiple features then when splitting the dataframe into time windows, the last time window containing the label at the time we want to predict will share the same timestep with some features that we use for training. So essentially we will use some features that have the same timestep as the label that we want to predict making this inconsistent. Is that right or am I missing something? I think if one uses a dataframe with multiple features, one should drop the time windows for the features that have the same timestep as the labels.
For instance in the example you showed, if we had an 2 features, and keeping a time window of 6, then instead of having 6 windows for the features at the previous time steps plus 1for the label at the future timestep, then we would have 6*2 features at the previous step plus 1 for the label at the future time step AND plus 1 for the extra feature at the future timestep. So this extra feature in the future should be dropped no otherwise we would be training already knowing some unavailable data.
I hope I was clear. Thank you again.
Cheers
Hi Gabriele…Please reduce to a single question so that I may better assist you.
great tutorial. Should testX, testy = test[i, :-1], test[i, -1] not be outside of for loop in walk forward validation function? As per my observation test[i] is appended to the history but I do not see any altercation to the test set. Thanks!
Hello…Please clarify which code listing you are referencing and whether you have executed it. That is…which code listing and what issue or error if any has been encountered?
~I have a related observation…Dataset has 365 rows of daily data, which reduce to 359 after adding lagged data for 6 days and dropping NaNs… train_test_split() will simply split this data into Train as first 347 rows [0:346] and Test as last 347 rows [12:358]… History is instantiated as Train… inside the loop, we’ll append rows from Test one by one to History dataset => which means History had rows 0:346 to begin with, and with first iteration data at row 12 of original dataset will be appended to it, then row 13, row 14, and so on, until the loop finishes… Not sure what this achieves? Unless I’m missing something.
Nevermind the earlier comment. Test dataset is not what I thought it was. It’s just the last 12 rows. And you are forecasting on them, one step at a time, and re-fitting the model on an expanding window of data.
HI Jason, asusual excellent article.
“Date”,”Births”
“1959-01-01”,35
“1959-01-02”,32
“1959-01-03”,30
“1959-01-04”,31
“1959-01-05”,44
“Date”,”Sex”
“1959-01-01”,M
“1959-01-02”,M
“1959-01-03”,F
“1959-01-04”,F
“1959-01-05”,M
If I want to do time series forecastingm just by replacing “Births” with “Sex”, where sex is categorical data. Does this article works? or any other suggestions from your side. please.
Hi jason,
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
The n_vars doesnt have any impact in the code or used second time. please confirm.
This is my question too, What happens to other features? So why do they define n_vars = 1?
Hi, I have a question, I don’t understand, please help me clarify this. thank you.
About this model in function
def xgboost_forecast(train, testX):
model = XGBRegressor(objective=’reg:squarederror’, n_estimators=1000)
model.fit(trainX, trainy)
every time, def walk_forward_validation(data, n_test):
for i in range(len(test)):
calls: xgboost_forecast(train, testX).
is that mean, every time in the loop, the model is re-created?
in xgboost_forecast, the model is new created,
so every time calls for ‘i’, the model is a new model.
this model does not remember anything about the last training status or weights?
is that right? if I understand wrongly?
thank you, please explain this to me.
Hi Ling…The model is being used with the additional data that is as the walk forward process is advancing.
Hi James,
thank you so much for all the inputs you offer.
I have a question regarding the forward expanding window approach – how can I adjust the code so that I get a 3-step ahead or 6 step ahead forecast?
Thanks in advance!
Hi James,
thank you so much for the inputs you offer.
I have a question regarding the forward expanding window approach – how can I adjust the code so that I receive a 3-step, 6-step or 12-step ahead forecast?
Thanks in advance!
Hi Christo…You could modify the following to set the step ahead:
mae, y, yhat = walk_forward_validation(data, 12)
HI Jason,
I have a question about multivariate multistep XGBoost. As I included calendar variables, I know input features of multiple step ahead( example time t + 6), such as the week of year as we know these in advance.
However when I predict, the model only takes the input features up till t.
Do you know how to include exogenous input features for XGBoost or LSTM.
Or you I have to change the supervised learning part?
ps. thanks already for all the knowlegde about machine learning, as it is going to help me graduating my master degree
Kind regards,
Raudhi
Hi Raudhi…The following resource may help add clarity:
https://www.datacamp.com/tutorial/tutorial-time-series-forecasting
you dont explain everything so that we buy your EBook ?
does your EBook gives more details than that? cause if it was like that i wont bother buying it.
Thank you for the feedback Bouhaouita! We offer a great deal of free content that you are more than welcome to access:
https://machinelearningmastery.com/start-here/
It works for n_out = 1 but when I set it to something else like 2, it fails. It seems it can only predict one step ahead. What am I doing wrong?
Hi Michael…Did you copy and paste the code or type it in? Also, you may want to try the code in Google Colab.
If I understood correctly, each time you perform a walk forward validation a new model is trained. But at the end if I want to end up with one model which one should I choose?
Hi Kostas…You may find the following resource of interest:
https://machinelearningmastery.com/backtest-machine-learning-models-time-series-forecasting/
Hello Jason;
I have used lstm for multi step time series forecasting but ı need a bencmark between lstm result and machine learning ensemble methods in my master thesis. I have chosen xgboost but ı could not implement multi step xgboost. Can you recommend any way for me? method for multistep xgboost or any other way for my thesis issue?
By the way I always use machine learning mastery in my data science adventure. Thank you very much for all.
Hi Gizem…You may want consider a classical approach such as SARIMA as a benchmark:
https://machinelearningmastery.com/sarima-for-time-series-forecasting-in-python/
Hi,
Given a dataset like the below, where for each date we know the amount of F/M births, does XGBoost support prediction of both F and M at the same time, or do we need to run this twice, once for each gender?
“Date”,”BirthsF”,”BirthsM”
“1990-01-01”,35,32
“1990-01-02”,32,43
“1990-01-03”,30,41
…
“1990-12-31”,34,27
Hi John…Each feature would represent a separate time-series. The following resource may also be of interest:
https://machinelearningmastery.com/standard-multivariate-multi-step-multi-site-time-series-forecasting-problem/
Hey Jason thanks for the great material!
I am confused about these lines at the end of the article:
# construct an input for a new preduction
row = values[-6:].flatten()
# make a one-step prediction
yhat = model.predict(asarray([row]))
which print the following:
Input: [34 37 52 48 55 50], Predicted: 42.708
We pass an input of length 6 and you get a single output, while I was expecting to get 6 outputs.
We did not specify 6 as input size (I am still trying to understand if xgboost has this option) during training so what is going on here and how does .predict() work?
Hi JacoSol…The following resource may add clarity around the use of model.predict.
https://www.educba.com/keras-predict/
Hi Jason/James,
Thanks for the tutorial.
I am working fitting the model once and using the same model to predict each new step in a loop and found that the model pretty much predicts a similar value every time it sees new data.
I noticed you are refitting the model every time you predict a new step and I implemented this with significantly better results.
My question; is there an explanation for why XGBoost behaves in this way? Do I have to re-fit my model on the historical data before predicting each new step?
Ultimately, can I train a model once and get the desired results from predicting new steps in a loop?
Thanks for your time.
Dear Jason, thanks so much for your page. If i have multivariate inputs (for example 3 additional features) then should i do sliding windows? Or it just for the existing birth data as input? Thanks so much.
Hi Herlina…You are very welcome! We recommend deep learning techniques for this purpose:
https://machinelearningmastery.com/start-here/#deep_learning_time_series
Kind of simple approach to consider using XGBoost for multiple time periods ahead.
You simply have to train another model that shifts the X table by two periods instead of 1.
Then let’s say you need a prediction for 3 periods ahead, you would train another model that shifts X table by 3 periods and so on.
This is the approach I would use to try and make predictions more than a single period ahead.
I tried to run the same code without changing anything in the jupyter notebook. I divided the whole code into pieces. When I try to calculate mae values. I got the following error: “IndexError: index -1 is out of bounds for axis 1 with size 0”. What should I do to solve that problem?
P.S. I’m a new learner!
Hello…Did you copy and paste the code or type it in? This could be the source of error.
Copied and pasted it, but it gave an error
Hi Jason,
as usual, a wonderful post. I was stuck with the multivariate data series, but then I read this post and another one and realized that I needed the bloody sliding window (the shift function). Anyway, just want to share the results I see after using xgboost for stock price forecasting.
Most of the times (around 80%) the difference between the prediction and the real Y is < 0.1. If we consider a difference 30) account for around 14.5%.
As you said, xgboost is a powerful tool and it’s impressive that often the difference is smaller than 0.1. At the same time, it’s odd that around 15% of the times the difference is big, even more than 200. Having said that, so far this is the best tool I tested with stocks.
Do you see roughly the same results with xgboost?
Do you think it’s the best tool for stock forecasting and regression?
Thank you
Michelangelo
Hi Michelangelo…It’s great to hear about your experience with using XGBoost for stock price forecasting! XGBoost has indeed proven to be a powerful tool for many regression and classification tasks due to its efficiency and effectiveness at handling various types of data, including time series data like stock prices.
### XGBoost in Stock Price Forecasting
Regarding the results you’re seeing—80% of predictions having an error smaller than 0.1 and about 14.5% with substantial errors—it’s actually quite common in financial modeling. Stock price movements can be influenced by many unpredictable external factors like market news, economic changes, and investor sentiment, which may not always be captured in past price movements and basic features.
The occurrence of large errors (e.g., greater than 200) might point to events or trends not captured by your current model setup. This could include:
– **Volatility spikes** caused by unforeseen events.
– **Model overfitting** on the training data but failing to generalize well on unseen data.
– **Lack of relevant features** that could better capture the dynamics of the market.
### Is XGBoost the Best Tool?
XGBoost is highly competitive for many applications, but whether it’s the best tool depends on the specific use case:
– **Advantages**: It’s robust against overfitting (especially in large datasets), handles mixed data types well, and has built-in support for regularization and missing values.
– **Limitations**: It might not capture time-dependent patterns as effectively as some other methods specifically tailored for time series analysis.
### Alternatives to Consider
1. **LSTM and GRU**: These are types of recurrent neural networks that are designed to handle sequences, like time series data, which might capture the temporal dependencies in stock price movements better.
2. **ARIMA/SARIMA**: Traditional time series forecasting models that are well-suited for univariate time series data with a clear trend or seasonal patterns.
3. **Facebook Prophet**: Designed for forecasting at scale, dealing effectively with daily seasonality in a robust way, which might be beneficial for stock price forecasts.
4. **Ensemble Methods**: Combining the predictions from multiple models (like XGBoost, LSTM, and ARIMA) can sometimes yield better results than any single model alone.
### Recommendations
– **Feature Engineering**: Try incorporating more features that capture external factors or refine the features based on domain knowledge.
– **Model Tuning**: Continue tuning hyperparameters, or explore different loss functions that might penalize large errors more significantly.
– **Evaluation Metrics**: Consider using different metrics for evaluating your models, such as MAPE (Mean Absolute Percentage Error) or MASE (Mean Absolute Scaled Error), which might give you better insight into the performance.
Experimentation is key in machine learning and especially in unpredictable fields like stock forecasting. Keep testing with different models and combinations of features to find the best fit for your specific data and forecasting needs.
Thanks for your reply James. When I was checking the results with xgboost, I saw all these tiny differences and my reaction was “What’s going on here?! Did I do something wrong?”. It seemed to me impossible the differences were so small. Just to explain how powerful xgboost is.
I’m trying to regress the stock prices on a monthly basis, not day by day. Anyway, I agree with what you said about the big differences.
In regards to the tools you listed:
1 in this stage I’d like to avoid the neural networks as they are “heavy” as you know;
2 ARIMA/SARIMA seem more appropriate for univariate datasets, while I’m using multivariate data series with more than 20 features.
3 Facebook Prophet, I don’t like the brand Facebook and everything connected to it, then I prefer staying away from it;
4 Ensemble Methods, that’s what I’m testing. I see very good results with xgboost coupled with ADABoost and/or SVM. I transformed the regression problem into a classification problem and I reached a precision of around 92%
Thanks again for your great work!