The k-fold cross-validation procedure is a standard method for estimating the performance of a machine learning algorithm or configuration on a dataset.
A single run of the k-fold cross-validation procedure may result in a noisy estimate of model performance. Different splits of the data may result in very different results.
Repeated k-fold cross-validation provides a way to improve the estimated performance of a machine learning model. This involves simply repeating the cross-validation procedure multiple times and reporting the mean result across all folds from all runs. This mean result is expected to be a more accurate estimate of the true unknown underlying mean performance of the model on the dataset, as calculated using the standard error.
In this tutorial, you will discover repeated k-fold cross-validation for model evaluation.
After completing this tutorial, you will know:
- The mean performance reported from a single run of k-fold cross-validation may be noisy.
- Repeated k-fold cross-validation provides a way to reduce the error in the estimate of mean model performance.
- How to evaluate machine learning models using repeated k-fold cross-validation in Python.
Kick-start your project with my new book Machine Learning Mastery With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

Repeated k-Fold Cross-Validation for Model Evaluation in Python
Photo by lina smith, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
- k-Fold Cross-Validation
- Repeated k-Fold Cross-Validation
- Repeated k-Fold Cross-Validation in Python
k-Fold Cross-Validation
It is common to evaluate machine learning models on a dataset using k-fold cross-validation.
The k-fold cross-validation procedure divides a limited dataset into k non-overlapping folds. Each of the k folds is given an opportunity to be used as a held back test set, whilst all other folds collectively are used as a training dataset. A total of k models are fit and evaluated on the k hold-out test sets and the mean performance is reported.
For more on the k-fold cross-validation procedure, see the tutorial:
The k-fold cross-validation procedure can be implemented easily using the scikit-learn machine learning library.
First, let’s define a synthetic classification dataset that we can use as the basis of this tutorial.
The make_classification() function can be used to create a synthetic binary classification dataset. We will configure it to generate 1,000 samples each with 20 input features, 15 of which contribute to the target variable.
The example below creates and summarizes the dataset.
|
1 2 3 4 5 6 |
# test classification dataset from sklearn.datasets import make_classification # define dataset X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=1) # summarize the dataset print(X.shape, y.shape) |
Running the example creates the dataset and confirms that it contains 1,000 samples and 10 input variables.
The fixed seed for the pseudorandom number generator ensures that we get the same samples each time the dataset is generated.
|
1 |
(1000, 20) (1000,) |
Next, we can evaluate a model on this dataset using k-fold cross-validation.
We will evaluate a LogisticRegression model and use the KFold class to perform the cross-validation, configured to shuffle the dataset and set k=10, a popular default.
The cross_val_score() function will be used to perform the evaluation, taking the dataset and cross-validation configuration and returning a list of scores calculated for each fold.
The complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# evaluate a logistic regression model using k-fold cross-validation from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression # create dataset X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=1) # prepare the cross-validation procedure cv = KFold(n_splits=10, random_state=1, shuffle=True) # create model model = LogisticRegression() # evaluate model scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # report performance print('Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) |
Running the example creates the dataset, then evaluates a logistic regression model on it using 10-fold cross-validation. The mean classification accuracy on the dataset is then reported.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the model achieved an estimated classification accuracy of about 86.8 percent.
|
1 |
Accuracy: 0.868 (0.032) |
Now that we are familiar with k-fold cross-validation, let’s look at an extension that repeats the procedure.
Repeated k-Fold Cross-Validation
The estimate of model performance via k-fold cross-validation can be noisy.
This means that each time the procedure is run, a different split of the dataset into k-folds can be implemented, and in turn, the distribution of performance scores can be different, resulting in a different mean estimate of model performance.
The amount of difference in the estimated performance from one run of k-fold cross-validation to another is dependent upon the model that is being used and on the dataset itself.
A noisy estimate of model performance can be frustrating as it may not be clear which result should be used to compare and select a final model to address the problem.
One solution to reduce the noise in the estimated model performance is to increase the k-value. This will reduce the bias in the model’s estimated performance, although it will increase the variance: e.g. tie the result more to the specific dataset used in the evaluation.
An alternate approach is to repeat the k-fold cross-validation process multiple times and report the mean performance across all folds and all repeats. This approach is generally referred to as repeated k-fold cross-validation.
… repeated k-fold cross-validation replicates the procedure […] multiple times. For example, if 10-fold cross-validation was repeated five times, 50 different held-out sets would be used to estimate model efficacy.
— Page 70, Applied Predictive Modeling, 2013.
Importantly, each repeat of the k-fold cross-validation process must be performed on the same dataset split into different folds.
Repeated k-fold cross-validation has the benefit of improving the estimate of the mean model performance at the cost of fitting and evaluating many more models.
Common numbers of repeats include 3, 5, and 10. For example, if 3 repeats of 10-fold cross-validation are used to estimate the model performance, this means that (3 * 10) or 30 different models would need to be fit and evaluated.
- Appropriate: for small datasets and simple models (e.g. linear).
As such, the approach is suited for small- to modestly-sized datasets and/or models that are not too computationally costly to fit and evaluate. This suggests that the approach may be appropriate for linear models and not appropriate for slow-to-fit models like deep learning neural networks.
Like k-fold cross-validation itself, repeated k-fold cross-validation is easy to parallelize, where each fold or each repeated cross-validation process can be executed on different cores or different machines.
Repeated k-Fold Cross-Validation in Python
The scikit-learn Python machine learning library provides an implementation of repeated k-fold cross-validation via the RepeatedKFold class.
The main parameters are the number of folds (n_splits), which is the “k” in k-fold cross-validation, and the number of repeats (n_repeats).
A good default for k is k=10.
A good default for the number of repeats depends on how noisy the estimate of model performance is on the dataset. A value of 3, 5, or 10 repeats is probably a good start. More repeats than 10 are probably not required.
|
1 2 3 |
... # prepare the cross-validation procedure cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1) |
The example below demonstrates repeated k-fold cross-validation of our test dataset.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# evaluate a logistic regression model using repeated k-fold cross-validation from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import RepeatedKFold from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression # create dataset X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=1) # prepare the cross-validation procedure cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1) # create model model = LogisticRegression() # evaluate model scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) # report performance print('Accuracy: %.3f (%.3f)' % (mean(scores), std(scores))) |
Running the example creates the dataset, then evaluates a logistic regression model on it using 10-fold cross-validation with three repeats. The mean classification accuracy on the dataset is then reported.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the model achieved an estimated classification accuracy of about 86.7 percent, which is lower than the single run result reported previously of 86.8 percent. This may suggest that the single run result may be optimistic and that the result from three repeats might be a better estimate of the true mean model performance.
|
1 |
Accuracy: 0.867 (0.031) |
The expectation of repeated k-fold cross-validation is that the repeated mean would be a more reliable estimate of model performance than the result of a single k-fold cross-validation procedure.
This may mean less statistical noise.
One way this could be measured is by comparing the distributions of mean performance scores under differing numbers of repeats.
We can imagine that there is a true unknown underlying mean performance of a model on a dataset and that repeated k-fold cross-validation runs estimate this mean. We can estimate the error in the mean performance from the true unknown underlying mean performance using a statistical tool called the standard error.
The standard error can provide an indication for a given sample size of the amount of error or the spread of error that may be expected from the sample mean to the underlying and unknown population mean.
Standard error can be calculated as follows:
- standard_error = sample_standard_deviation / sqrt(number of repeats)
We can calculate the standard error for a sample using the sem() scipy function.
Ideally, we would like to select a number of repeats that shows both minimization of the standard error and stabilizing of the mean estimated performance compared to other numbers of repeats.
The example below demonstrates this by reporting model performance with 10-fold cross-validation with 1 to 15 repeats of the procedure.
We would expect that more repeats of the procedure would result in a more accurate estimate of the mean model performance, given the law of large numbers. Although, the trials are not independent, so the underlying statistical principles become challenging.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# compare the number of repeats for repeated k-fold cross-validation from scipy.stats import sem from numpy import mean from numpy import std from sklearn.datasets import make_classification from sklearn.model_selection import RepeatedKFold from sklearn.model_selection import cross_val_score from sklearn.linear_model import LogisticRegression from matplotlib import pyplot # evaluate a model with a given number of repeats def evaluate_model(X, y, repeats): # prepare the cross-validation procedure cv = RepeatedKFold(n_splits=10, n_repeats=repeats, random_state=1) # create model model = LogisticRegression() # evaluate model scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1) return scores # create dataset X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=1) # configurations to test repeats = range(1,16) results = list() for r in repeats: # evaluate using a given number of repeats scores = evaluate_model(X, y, r) # summarize print('>%d mean=%.4f se=%.3f' % (r, mean(scores), sem(scores))) # store results.append(scores) # plot the results pyplot.boxplot(results, labels=[str(r) for r in repeats], showmeans=True) pyplot.show() |
Running the example reports the mean and standard error classification accuracy using 10-fold cross-validation with different numbers of repeats.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the default of one repeat appears optimistic compared to the other results with an accuracy of about 86.80 percent compared to 86.73 percent and lower with differing numbers of repeats.
We can see that the mean seems to coalesce around a value of about 86.5 percent. We might take this as the stable estimate of model performance and in turn, choose 5 or 6 repeats that seem to approximate this value first.
Looking at the standard error, we can see that it decreases with an increase in the number of repeats and stabilizes with a value around 0.003 at around 9 or 10 repeats, although 5 repeats achieve a standard error of 0.005, half of that achieved with a single repeat.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
>1 mean=0.8680 se=0.011 >2 mean=0.8675 se=0.008 >3 mean=0.8673 se=0.006 >4 mean=0.8670 se=0.006 >5 mean=0.8658 se=0.005 >6 mean=0.8655 se=0.004 >7 mean=0.8651 se=0.004 >8 mean=0.8651 se=0.004 >9 mean=0.8656 se=0.003 >10 mean=0.8658 se=0.003 >11 mean=0.8655 se=0.003 >12 mean=0.8654 se=0.003 >13 mean=0.8652 se=0.003 >14 mean=0.8651 se=0.003 >15 mean=0.8653 se=0.003 |
A box and whisker plot is created to summarize the distribution of scores for each number of repeats.
The orange line indicates the median of the distribution and the green triangle represents the arithmetic mean. If these symbols (values) coincide, it suggests a reasonable symmetric distribution and that the mean may capture the central tendency well.
This might provide an additional heuristic for choosing an appropriate number of repeats for your test harness.
Taking this into consideration, using five repeats with this chosen test harness and algorithm appears to be a good choice.
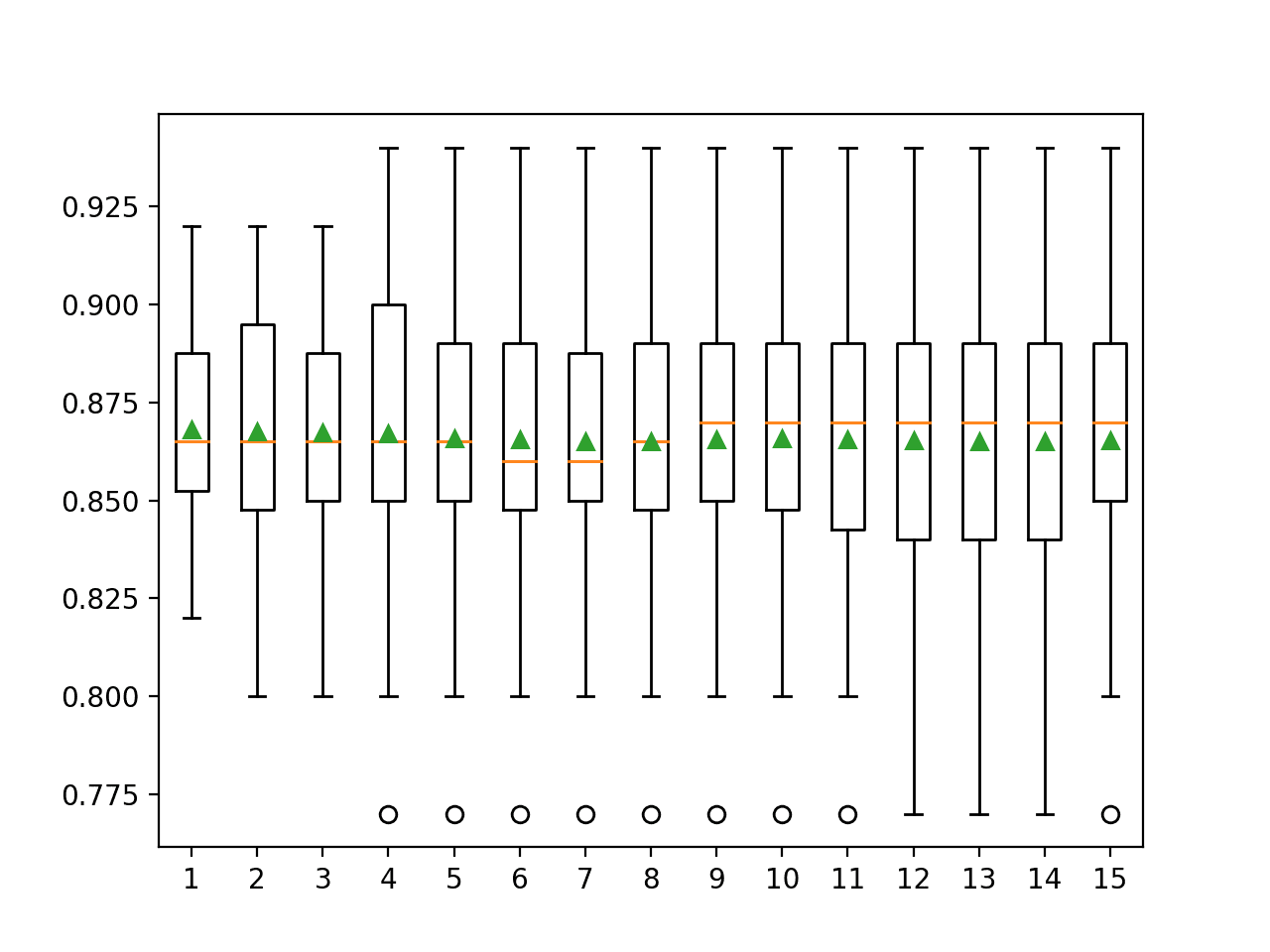
Box and Whisker Plots of Classification Accuracy vs Repeats for k-Fold Cross-Validation
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Tutorials
- A Gentle Introduction to k-fold Cross-Validation
- How to Fix k-Fold Cross-Validation for Imbalanced Classification
APIs
- sklearn.model_selection.KFold API.
- sklearn.model_selection.RepeatedKFold API.
- sklearn.model_selection.LeaveOneOut API.
- sklearn.model_selection.cross_val_score API.
Articles
Summary
In this tutorial, you discovered repeated k-fold cross-validation for model evaluation.
Specifically, you learned:
- The mean performance reported from a single run of k-fold cross-validation may be noisy.
- Repeated k-fold cross-validation provides a way to reduce the error in the estimate of mean model performance.
- How to evaluate machine learning models using repeated k-fold cross-validation in Python.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Discover Fast Machine Learning in Python!

Develop Your Own Models in Minutes
...with just a few lines of scikit-learn code
Learn how in my new Ebook:
Machine Learning Mastery With Python
Covers self-study tutorials and end-to-end projects like:
Loading data, visualization, modeling, tuning, and much more...
Finally Bring Machine Learning To
Your Own Projects
Skip the Academics. Just Results.






Thanks for this highlitght Jason, very clear and well illustrated as usual.
Regarding the results of the repeated k-fold example, I wonder if it really mean something to choose 5 repeats instead of 1 or 11.
The results does not seem to be significantly different taking a simple 3 sigma range.
>1 mean=0.8680 se=0.011 => 0.8680 lies in [0.835, 0.901]
> 5 mean=0.8658 se=0.005 => 0.8658 lies in [0.851, 0.881]
> 11 mean=0.8655 se=0.003 => 0.8655 lies in [0.856, 0.874]
Nevertheless, I aggree we have to choose a number of repetitions that do not underestimate the variance of the performances. For that reason and to limit the computation time, 4 or 5 would be nice.
It seems the biais is not a problem in this particular question of performance evaluation.
Thanks
Jerome
Thanks.
Yes, agreed.
Thank you very much jason, will you please prepare a tutorial about curve estimation and nonlinear regression with equations cause till now you don’t have any tutorial about this subject.
Thanks for the suggestion.
Hi Jason,
Thanks for tutorial on K-fold validation. Can we find which exact data out of total data was used in each fold. In my case, fold 7 gives best accuracy whereas avg final accuracy is less. I was thinking, if we can take model related to this particular fold. Can we save model for each fold.
Yes, this tutorial will step through the folds and report which rows (row indexes) are in each fold:
https://machinelearningmastery.com/k-fold-cross-validation/
Hello, Jason. So, I performed the steps above using my database, and found out that with 7 repetitions the accuracy of the model it’s good. Now, how do I fit this model, so I can make predictions? Please, give me the directions. Tks.
Fit the model on all data directly and start making predictions, e.g. model.fit(X, y)
Perhaps this will help:
https://machinelearningmastery.com/train-final-machine-learning-model/
And this:
https://machinelearningmastery.com/make-predictions-scikit-learn/
Thank you! Now I understand. Thanks Jason!
You’re welcome!
Hi Jason, thank you for this post! I have a question that I could really use your help with answering.
What type of evaluation technique (k-fold cv or train/test) would you suggest for a CNN (EfficientNet) being used with transfer learning and a small dataset (400 images) very different from the imagenet weights being used?
I initially thought train/test would be sufficient but I see that you’ve stated that the results are generally very optimistic. I also see that this sort of k-fold cv, although much more accurate, is better suited for simple models.
Any direction would be greatly appreciated!
If you have the resources, repeated stratified k fold cv, if not, a train/test split.
Thank you so much! 🙂
You’re welcome.
Hello Jason, Thanks for this great blog. I have been learning lots of informations from you. I have a question about, is it logical to use train_test_split and kfold cross validation at the same time ?
For example, First, I apply train_test_split and divide dataset as X_train, X_test and y_train, y_test and I used Kfold to X_train and y_train and find results and then Can I use same model to predict X_train? Is that logical ?
You’re welcome.
You can do anything you like that gives you confidence in the results.
In practice, no, not really. Use one or the other.
Dear Jason,
Thank you very much for this tutorial, and the whole website in general. Excellent information and it’s great that you’re actually here to help people with their questions. It means a lot!
When diving into the topic of Repeated K-fold Cross Validation, I came across a remark on wikipedia which led to this (https://limo.libis.be/primo-explore/fulldisplay?docid=LIRIAS1655861&context=L&vid=Lirias&search_scope=Lirias&tab=default_tab&lang=en_US&fromSitemap=1) article.
The article posits that repeated k-fold cross validation does not necessarily lead to a better estimation of the expected Learner accuracy in the total population, compared to regular k-fold cross validation. They support their hypothesis with a suitable explanation and also with model data.
My question is: What do you (as an expert) feel about the authors’ claims, and if not repeated k-fold cross validation, what type of validation would you suggest?
You’re welcome.
Thanks for sharing, I’m not familiar with the piece, sorry.
Jason,
With Kfold CV using k=25, you would get 25 splits of the data, but you would perform that random split one time. With repeated Kfold k=5 and 5 repeats, you would get 25 splits of the data, but that data would be randomly split 5 times. So, if you don’t set the random_state parameter, I can see where the 25 splits would be different between the two strategies. If you set the random_state parameter to an integer, is there truly a difference?
Thanks
Jeff
Just to be clear, wouldn’t 5 repeats of k=5 with random_state set to an integer, just give me the same 5 folds 5 times over?
Thanks
Jeff
No, different shuffle + split of data for each repeat.
Correct. Random state controls how the data is split (the shuffle of the data prior to split).
Fixing the random state ensures we get the same shuffle and in turn same split each time the code is run.
Shuffle uses a pseudorandom number generator and random state is the seed:
https://machinelearningmastery.com/introduction-to-random-number-generators-for-machine-learning/
I agree with Jeff, you should do RepeatedCrossValidation without random_state equal to any number, thus on each repetation, k-folds will be splitted randomly. Otherwise there is no point to do repeated crossvalidation imo.
If you fix the seed at the start, you will get the same sequence of random numbers across all repeats, not for each repeat. See this:
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.RepeatedKFold.html
Hi Jason!
Thanks for all! Your blog is very usefull to me!
I was wondering if there is a method to run a repeated estratified k-fold?
Thanks,
Mariana
Thanks!
Yes, see this:
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.RepeatedStratifiedKFold.html
Thank you for this!
Clarified all the questions in my head and provided me with solid practical steps to actualize repeated k-fold cv
You’re welcome.
Hi Jason,
Thank your for the tutorial!
My question:
I see same random_state argument on Kfold() and RepeatedKfold() …but I see only ‘shuffle’ argument on Kfold() but not in RepeatedKfold() ….Why?
I guessing in RepeatedKfold we perform the equivalent to ‘shuffle’ argument thought repeating via n_repeat argument via random_state argument …am I right?
Off the cuff (without deep thought), I suspect shuffle is assumed in the implementation as you suggest.
Heyy Jayson,
Can you please infer the differences between Gridsearch cv and RepeatedKFold (I saw both in sklearn).
Thank You.
PS: I am just a newbie to ML and I don’t know if I asked something foolish.
Grid search is for tuning model hyperparameters.
Repeated k-fold cross-validation is for evaluating model performance.
You can use repeated k-fold CV in a grid search if you want.
Actually, after some reading, I suppose RepeatedKFold can be used in the cv parameter of Gridsearch.
Now I wonder what’s the difference between the Gridsearchcv and cross_val_score ?
Both give us scores after cross-validation right?
The cross_val_score() function will provide an evaluation of a single model/configuration using cross-validation.
Heyy Jayson,
Saw your reply (for the first) after my second comment only (some network glitches).
And, so RepeatedKFold is actually analogous to RMSE, MAE etc?
Because I was looking for good performance measures for my model using non-linear data, as my reviewer commented that R2 score is not a good score for non-linear models. And that’s when I stumbled upon cross-validation.
So, what I understood is like, when we use Repeatedkfold in Gridsearch,
The GridSearch takes one permutation of the given hyperparameters, fit them in our dataset and check the model performance using RepeatedKfold.
Then Gridsearch takes another permutation, run it and Repeatedkfold calculates the model performance of that permutation.
And so on….
Finally from all the Repeatekfold scores, we can identify which is the best permutation.
Is this right?
And Thank you so much for the timely replies. You really take efforts for us beginners, which is very much appreciatable.
No, repeatedkfold is an evaluation procedure, RMSE and MAE are metrics.
Yes, grid search will evaluate each config using the specified evaluation procedure, like repeatedkfold. The “best” config has the best metric score using the evaluation procedure.
Hi sir,
Would repeated k fold cross validation be suitable for a sample of 20k data points?
One more doubt… you are putting the random_state=1 in repeated k fold CV. But will it not destroy the meaning of number of repeates? I mean giving some value to random state means producing the same output in each run.
Just a doubt. Please clear if I am wrong.
No, it ensures each time we evaluate a model on the test harness it gets the same split of data.
Sure. Try it and see.
Thanks for your reply. I tried with my my dataset and i found that the results are absolutely same for 10 fold and repeated 10 fold CV ( tried upto 3 repeats) for a fixed random state.
What can be the reason for the same results?
Something wrong in model or the noiseless dataset?
Well done!
Perhaps the data and model are very stable.
I’ve read both this breakdown and the one on nested cross validation.
How might we use them both? Is there any advantage to it? I have this vague idea that we could put the repeated cross validation in the inner portion of a nested cross validation and to get a higher confidence result than with a single inner cross validation run.
Yes you can do that. In fact, the inner loop should see fewer data, hence using repeated CV can help bring back the accuracy.
Hi Jason,
May I ask, with this or similar pipeline incorporated with classification report (i.e. cv), how will obtain a consensus supports for in class/label. like that of finding average precision for 5 folds i.e. cross validation (cv) =5?
Thank you.
Best
Hi Malik…The following resource may be of interest:
https://machinelearningmastery.com/training-validation-test-split-and-cross-validation-done-right/
How to use Statistical hypothesis testing for time series forecasting models? Which one is preferable?
Hi Hebi…The following resource may be of interest:
https://machinelearningmastery.com/sarima-for-time-series-forecasting-in-python/
Hi, this tutorial is so great! It’s very clear! I have one question in my own project, due to the fact that my algorithm selects different “features” differently with the different datasets (as K-fold selected training sample and testing sample randomly), thus, there’re no features in some of the iterations failing to build a model. The question is how can we report this? What did this mean?
Hi Hangbin…You are very welcome! The following resource may add clarity regarding feature selection as it relates to stochastic algorithms:
https://machinelearningmastery.com/feature-selection-with-optimization/
What would be an appropriate translation of “folds” (k) in German for my thesis? Or should I stick with the English term?
Thanks in advance
Hi Stefan…You may wish to confirm with your advisor.