The encoder-decoder architecture for recurrent neural networks is proving to be powerful on a host of sequence-to-sequence prediction problems in the field of natural language processing.
Attention is a mechanism that addresses a limitation of the encoder-decoder architecture on long sequences, and that in general speeds up the learning and lifts the skill of the model on sequence-to-sequence prediction problems.
In this post, you will discover patterns for implementing the encoder-decoder model with and without attention.
After reading this post, you will know:
- The direct versus the recursive implementation pattern for the encoder-decoder recurrent neural network.
- How attention fits into the direct implementation pattern for the encoder-decoder model.
- How attention can be implemented with the recursive implementation pattern for the encoder-decoder model.
Kick-start your project with my new book Long Short-Term Memory Networks With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

Implementation Patterns for the Encoder-Decoder RNN Architecture with Attention
Photo by Philip McErlean, some rights reserved.
Encoder-Decoder with Attention
The encoder-decoder model for recurrent neural networks is an architecture for sequence-to-sequence prediction problems where the length of input sequences is different to the length of output sequences.
It is comprised of two sub-models, as its name suggests:
- Encoder: The encoder is responsible for stepping through the input time steps and encoding the entire sequence into a fixed length vector called a context vector.
- Decoder: The decoder is responsible for stepping through the output time steps while reading from the context vector.
A problem with the architecture is that performance is poor on long input or output sequences. The reason is believed to be because of the fixed-sized internal representation used by the encoder.
Attention is an extension to the architecture that addresses this limitation. It works by first providing a richer context from the encoder to the decoder and a learning mechanism where the decoder can learn where to pay attention in the richer encoding when predicting each time step in the output sequence.
For more on the encoder-decoder architecture, see the post:
Direct Encoder-Decoder Implementation
There are multiple ways to implement the encoder-decoder architecture as a system.
One approach is to have the output generated in entirety from the decoder given the input to the encoder. This is how the model is often described.
… we propose a novel neural network architecture that learns to encode a variable-length sequence into a fixed-length vector representation and to decode a given fixed-length vector representation back into a variable-length sequence.
— Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation, 2014.
We will call this model the direct encoder-decoder implementation, for lack of a better name.
To make this clear, let’s work through a vignette for French-to-English neural machine translation.
- A sentence of French is provided to the model as input.
- The encoder reads the sentence one word at a time and encodes the sequence as a fixed-length vector.
- The decoder reads the encoded input and outputs each word in English.
Below is a depiction of this implementation.
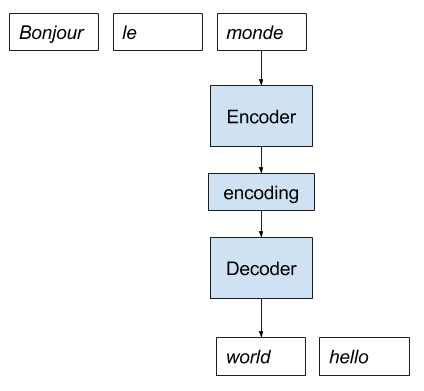
Direct Encoder Decoder Model Implementation for Neural Machine Translation
Recursive Encoder-Decoder Implementation
Another implementation is to frame the model such that it generates only one word and the model is called recursively to generate the entire output sequence.
We will call this the recursive implementation (for lack of a better name) to distinguish it from the above description.
In their paper on caption generation models titled “Where to put the Image in an Image Caption
Generator,” Marc Tanti, et al. refer to the direct approach as the “continuous view“:
Traditionally, neural language models are depicted […] where strings are thought of as being continuously generated. A new word is generated after each time step, with the RNN’s state being combined with the last generated word in order to generate the next word. We refer to this as the ‘continuous view’.
— Where to put the Image in an Image Caption Generator, 2017.
They refer to the recursive implementation as the “discontinuous view“:
We propose to think of the RNN in terms of a series of discontinuous snapshots over time, with each word being generated from the entire prefix of previous words and with the RNN’s state being reinitialised each time. We refer to this as the ‘discontinuous view’
— Where to put the Image in an Image Caption Generator, 2017.
We can step through this approach for the same French-to-English neural machine translation example using the recursive implementation.
- A sentence of French is provided to the model as input.
- The encoder reads the sentence one word at a time and encodes the sequence as a fixed-length vector.
- The decoder reads the encoded input and outputs one English word.
- The output is taken as input along with the encoded French sentence, go to Step 3.
Below is a depiction of this implementation.

Recursive Encoder Decoder Model Implementation for Neural Machine Translation
To start the process, a “start-of-sequence” token may need to be provided to the model as input for the output sequence generated so far.
The entire output sequence generated so far may be replayed as input to the decoder with or without the encoded input sequence to allow the decoder to arrive at the same internal state prior to predicting the next word as would have been achieved if the model generated the entire output sequence at once, as in the previous section.
Merge Encoder-Decoder Implementation
The recursive implementation can imitate outputting the entire sequence at once as in the first model.
The recursive implementation also allows you to vary the model and seek perhaps a simpler or more skillful model.
One example is to also encode the input sequence and use the decoder model to learn how to best combine the encoded input sequence and output sequence generated so far. Marc Tanti, et al. in their paper “What is the Role of Recurrent Neural Networks (RNNs) in an Image Caption Generator?” call this the “merge model.”
… at a given time step, the merge architecture predicts what to generate next by combining the RNNencoded prefix of the string generated so far (the ‘past’ of the generation process) with non-linguistic information (the guide of the generation process).
— What is the Role of Recurrent Neural Networks (RNNs) in an Image Caption Generator?, 2017
The model is still called recursively, only the internal structure of the model is varied. We can make this clear with a depiction.

Merge Encoder Decoder Model Implementation for Neural Machine Translation
Direct Encoder-Decoder with Attention Implementation
We can now consider the attention mechanism in the context of these different implementations for the Encoder-Decoder recurrent neural network architecture.
Canonical attention, as described by Bahdanau et al. in their paper “Neural Machine Translation by Jointly Learning to Align and Translate,” involves a few elements as follows:
- Richer encoding. The output from the encoder is expanded to provide information across all words in the input sequence, not just the final output from the last word in the sequence.
- Alignment model. A new small neural network model is used to align or relate the expanded encoding using the attended output from the decoder from the previous time step.
- Weighted encoding. A weighting for the alignment that can be used as a probability distribution over the encoded input sequence.
- Weighted context vector. The weighting applied to the encoded input sequence that can then be used to decode the next word.
Note, in all of these encoder-decoder models there is a difference between the output of the model (next predicted word) and the output of the decoder (internal representation). The decoder does not output a word directly; often a fully connected layer is connected to decoder that outputs a probability distribution over the vocabulary of words, which is then further searched using a heuristic like a beam search.
For more detail on how to calculate attention in the encoder-decoder model, see the post:
We can make a cartoon of the direct encoder-decoder model with attention, as below.
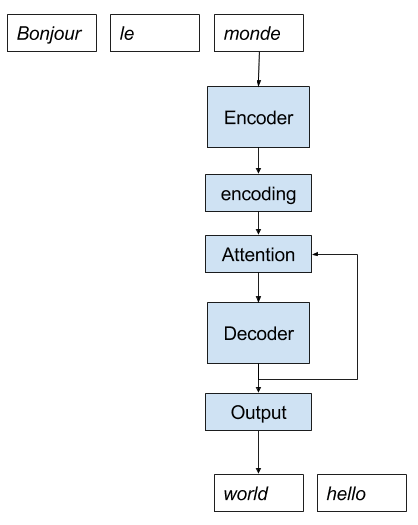
Direct Encoder Decoder With Attention Model Implementation for Neural Machine Translation
Attention can be challenging to implement in a direct encoder-decoder model. This is because efficient neural network libraries with vectorized equations that require all information to be available prior to the computation.
This need is disrupted by the need for the model to access the attended output from the decoder for each prediction made.
Recursive Encoder-Decoder with Attention Implementation
Attention lends itself to a recursive description and implementation.
A recursive implementation of attention requires that in addition to making the output sequence generated so far available to the decoder, that the outputs of the decoder generated from the previous time step could be provided to the attention mechanism for predicting the next word.
We can make this clearer with a cartoon.

Recursive Encoder Decoder With Attention Model Implementation for Neural Machine Translation
The recursive approach also introduces additional flexibility to try out new designs.
For example, Luong, et al. in their paper “Effective Approaches to Attention-based Neural Machine Translation” take this a step further and propose that the output of the decoder from the previous time step (h(t-1)) can also be fed as inputs to the decoder, instead of being used in the attention calculation. They call this an “input-feeding” model.
The effects of having such connections are twofold: (a) we hope to make the model fully aware of previous alignment choices, and (b) we create a very deep network spanning both horizontally and vertically
— Effective Approaches to Attention-based Neural Machine Translation, 2015.
Interestingly, this input feeding coupled with their local attention resulted in state-of-the-art performance (at their time of writing) on a standard machine translation task.
The input-feeding approach is related to the merge model. Instead of providing the decoded output from the last time step alone, the merge model provides an encoding of all previously generated time steps.
One could imagine attention in the decoder harnessing this encoding to help decode the encoded input sequence, or perhaps employing attention on both encodings.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Posts
- Encoder-Decoder Long Short-Term Memory Networks
- Attention in Long Short-Term Memory Recurrent Neural Networks
- How Does Attention Work in Encoder-Decoder Recurrent Neural Networks
Papers
- Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation, 2014.
- Neural Machine Translation by Jointly Learning to Align and Translate, 2015.
- Where to put the Image in an Image Caption Generator, 2017.
- What is the Role of Recurrent Neural Networks (RNNs) in an Image Caption Generator?, 2017
- Effective Approaches to Attention-based Neural Machine Translation, 2015.
Summary
In this post, you discovered patterns for implementing the encoder-decoder model with and without attention.
Specifically, you learned:
- The direct versus the recursive implementation pattern for the encoder-decoder recurrent neural network.
- How attention fits into the direct implementation pattern for the encoder-decoder model.
- How attention can be implemented with the recursive implementation pattern for the encoder-decoder model.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop LSTMs for Sequence Prediction Today!

Develop Your Own LSTM models in Minutes
...with just a few lines of python code
Discover how in my new Ebook:
Long Short-Term Memory Networks with Python
It provides self-study tutorials on topics like:
CNN LSTMs, Encoder-Decoder LSTMs, generative models, data preparation, making predictions and much more...
Finally Bring LSTM Recurrent Neural Networks to
Your Sequence Predictions Projects
Skip the Academics. Just Results.






In which chapter you have that tutorial?
What are you referring to Tom?
Sorry for not being clear Jason.
My question was – Do you have this article in “Long Short-Term Memory Networks with Python” book.
I did not know if you have “Attention” covered in the book.
Thanks
No. This post and the topic of attention are not covered in the book.
I am waiting for the official release of attention in the Keras API then I might add attention to the book.
Any plan to add “attention ” topic in the book this is a very important topic, I guess 🙂
I hope so. When the Keras implementation is finalized I will start work on it.