Autoencoder is a type of neural network that can be used to learn a compressed representation of raw data.
An autoencoder is composed of an encoder and a decoder sub-models. The encoder compresses the input and the decoder attempts to recreate the input from the compressed version provided by the encoder. After training, the encoder model is saved and the decoder is discarded.
The encoder can then be used as a data preparation technique to perform feature extraction on raw data that can be used to train a different machine learning model.
In this tutorial, you will discover how to develop and evaluate an autoencoder for classification predictive modeling.
After completing this tutorial, you will know:
- An autoencoder is a neural network model that can be used to learn a compressed representation of raw data.
- How to train an autoencoder model on a training dataset and save just the encoder part of the model.
- How to use the encoder as a data preparation step when training a machine learning model.
Let’s get started.

How to Develop an Autoencoder for Classification
Photo by Bernd Thaller, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
- Autoencoders for Feature Extraction
- Autoencoder for Classification
- Encoder as Data Preparation for Predictive Model
Autoencoders for Feature Extraction
An autoencoder is a neural network model that seeks to learn a compressed representation of an input.
An autoencoder is a neural network that is trained to attempt to copy its input to its output.
— Page 502, Deep Learning, 2016.
They are an unsupervised learning method, although technically, they are trained using supervised learning methods, referred to as self-supervised.
Autoencoders are typically trained as part of a broader model that attempts to recreate the input.
For example:
- X = model.predict(X)
The design of the autoencoder model purposefully makes this challenging by restricting the architecture to a bottleneck at the midpoint of the model, from which the reconstruction of the input data is performed.
There are many types of autoencoders, and their use varies, but perhaps the more common use is as a learned or automatic feature extraction model.
In this case, once the model is fit, the reconstruction aspect of the model can be discarded and the model up to the point of the bottleneck can be used. The output of the model at the bottleneck is a fixed-length vector that provides a compressed representation of the input data.
Usually they are restricted in ways that allow them to copy only approximately, and to copy only input that resembles the training data. Because the model is forced to prioritize which aspects of the input should be copied, it often learns useful properties of the data.
— Page 502, Deep Learning, 2016.
Input data from the domain can then be provided to the model and the output of the model at the bottleneck can be used as a feature vector in a supervised learning model, for visualization, or more generally for dimensionality reduction.
Next, let’s explore how we might develop an autoencoder for feature extraction on a classification predictive modeling problem.
Autoencoder for Classification
In this section, we will develop an autoencoder to learn a compressed representation of the input features for a classification predictive modeling problem.
First, let’s define a classification predictive modeling problem.
We will use the make_classification() scikit-learn function to define a synthetic binary (2-class) classification task with 100 input features (columns) and 1,000 examples (rows). Importantly, we will define the problem in such a way that most of the input variables are redundant (90 of the 100 or 90 percent), allowing the autoencoder later to learn a useful compressed representation.
The example below defines the dataset and summarizes its shape.
|
1 2 3 4 5 6 |
# synthetic classification dataset from sklearn.datasets import make_classification # define dataset X, y = make_classification(n_samples=1000, n_features=100, n_informative=10, n_redundant=90, random_state=1) # summarize the dataset print(X.shape, y.shape) |
Running the example defines the dataset and prints the shape of the arrays, confirming the number of rows and columns.
|
1 |
(1000, 100) (1000,) |
Next, we will develop a Multilayer Perceptron (MLP) autoencoder model.
The model will take all of the input columns, then output the same values. It will learn to recreate the input pattern exactly.
The autoencoder consists of two parts: the encoder and the decoder. The encoder learns how to interpret the input and compress it to an internal representation defined by the bottleneck layer. The decoder takes the output of the encoder (the bottleneck layer) and attempts to recreate the input.
Once the autoencoder is trained, the decoder is discarded and we only keep the encoder and use it to compress examples of input to vectors output by the bottleneck layer.
In this first autoencoder, we won’t compress the input at all and will use a bottleneck layer the same size as the input. This should be an easy problem that the model will learn nearly perfectly and is intended to confirm our model is implemented correctly.
We will define the model using the functional API; if this is new to you, I recommend this tutorial:
Prior to defining and fitting the model, we will split the data into train and test sets and scale the input data by normalizing the values to the range 0-1, a good practice with MLPs.
|
1 2 3 4 5 6 7 8 |
... # split into train test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # scale data t = MinMaxScaler() t.fit(X_train) X_train = t.transform(X_train) X_test = t.transform(X_test) |
We will define the encoder to have two hidden layers, the first with two times the number of inputs (e.g. 200) and the second with the same number of inputs (100), followed by the bottleneck layer with the same number of inputs as the dataset (100).
To ensure the model learns well, we will use batch normalization and leaky ReLU activation.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
... # define encoder visible = Input(shape=(n_inputs,)) # encoder level 1 e = Dense(n_inputs*2)(visible) e = BatchNormalization()(e) e = LeakyReLU()(e) # encoder level 2 e = Dense(n_inputs)(e) e = BatchNormalization()(e) e = LeakyReLU()(e) # bottleneck n_bottleneck = n_inputs bottleneck = Dense(n_bottleneck)(e) |
The decoder will be defined with a similar structure, although in reverse.
It will have two hidden layers, the first with the number of inputs in the dataset (e.g. 100) and the second with double the number of inputs (e.g. 200). The output layer will have the same number of nodes as there are columns in the input data and will use a linear activation function to output numeric values.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
... # define decoder, level 1 d = Dense(n_inputs)(bottleneck) d = BatchNormalization()(d) d = LeakyReLU()(d) # decoder level 2 d = Dense(n_inputs*2)(d) d = BatchNormalization()(d) d = LeakyReLU()(d) # output layer output = Dense(n_inputs, activation='linear')(d) # define autoencoder model model = Model(inputs=visible, outputs=output) |
The model will be fit using the efficient Adam version of stochastic gradient descent and minimizes the mean squared error, given that reconstruction is a type of multi-output regression problem.
|
1 2 3 |
... # compile autoencoder model model.compile(optimizer='adam', loss='mse') |
We can plot the layers in the autoencoder model to get a feeling for how the data flows through the model.
|
1 2 3 |
... # plot the autoencoder plot_model(model, 'autoencoder_no_compress.png', show_shapes=True) |
The image below shows a plot of the autoencoder.
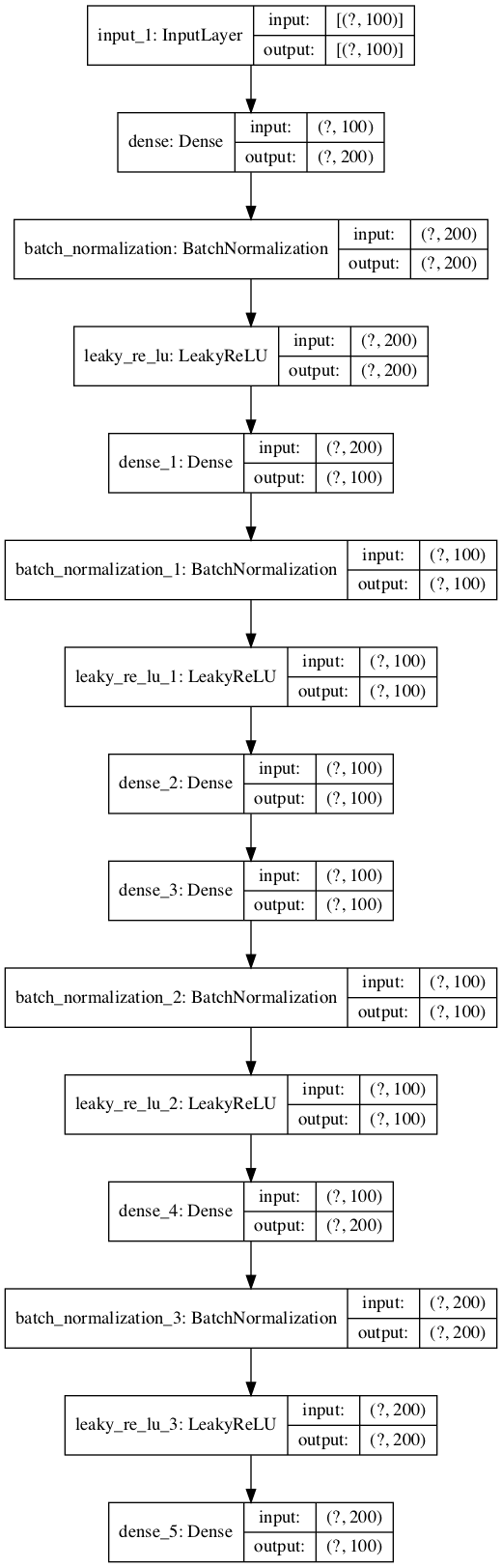
Plot of Autoencoder Model for Classification With No Compression
Next, we can train the model to reproduce the input and keep track of the performance of the model on the hold-out test set.
|
1 2 3 |
... # fit the autoencoder model to reconstruct input history = model.fit(X_train, X_train, epochs=200, batch_size=16, verbose=2, validation_data=(X_test,X_test)) |
After training, we can plot the learning curves for the train and test sets to confirm the model learned the reconstruction problem well.
|
1 2 3 4 5 6 |
... # plot loss pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() pyplot.show() |
Finally, we can save the encoder model for use later, if desired.
|
1 2 3 4 5 6 |
... # define an encoder model (without the decoder) encoder = Model(inputs=visible, outputs=bottleneck) plot_model(encoder, 'encoder_no_compress.png', show_shapes=True) # save the encoder to file encoder.save('encoder.h5') |
As part of saving the encoder, we will also plot the encoder model to get a feeling for the shape of the output of the bottleneck layer, e.g. a 100 element vector.
An example of this plot is provided below.
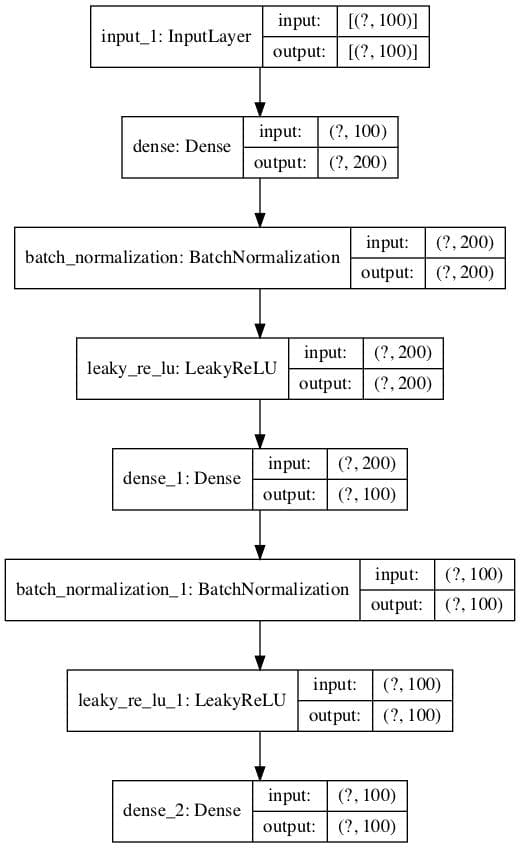
Plot of Encoder Model for Classification With No Compression
Tying this all together, the complete example of an autoencoder for reconstructing the input data for a classification dataset without any compression in the bottleneck layer is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
# train autoencoder for classification with no compression in the bottleneck layer from sklearn.datasets import make_classification from sklearn.preprocessing import MinMaxScaler from sklearn.model_selection import train_test_split from tensorflow.keras.models import Model from tensorflow.keras.layers import Input from tensorflow.keras.layers import Dense from tensorflow.keras.layers import LeakyReLU from tensorflow.keras.layers import BatchNormalization from tensorflow.keras.utils import plot_model from matplotlib import pyplot # define dataset X, y = make_classification(n_samples=1000, n_features=100, n_informative=10, n_redundant=90, random_state=1) # number of input columns n_inputs = X.shape[1] # split into train test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # scale data t = MinMaxScaler() t.fit(X_train) X_train = t.transform(X_train) X_test = t.transform(X_test) # define encoder visible = Input(shape=(n_inputs,)) # encoder level 1 e = Dense(n_inputs*2)(visible) e = BatchNormalization()(e) e = LeakyReLU()(e) # encoder level 2 e = Dense(n_inputs)(e) e = BatchNormalization()(e) e = LeakyReLU()(e) # bottleneck n_bottleneck = n_inputs bottleneck = Dense(n_bottleneck)(e) # define decoder, level 1 d = Dense(n_inputs)(bottleneck) d = BatchNormalization()(d) d = LeakyReLU()(d) # decoder level 2 d = Dense(n_inputs*2)(d) d = BatchNormalization()(d) d = LeakyReLU()(d) # output layer output = Dense(n_inputs, activation='linear')(d) # define autoencoder model model = Model(inputs=visible, outputs=output) # compile autoencoder model model.compile(optimizer='adam', loss='mse') # plot the autoencoder plot_model(model, 'autoencoder_no_compress.png', show_shapes=True) # fit the autoencoder model to reconstruct input history = model.fit(X_train, X_train, epochs=200, batch_size=16, verbose=2, validation_data=(X_test,X_test)) # plot loss pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() pyplot.show() # define an encoder model (without the decoder) encoder = Model(inputs=visible, outputs=bottleneck) plot_model(encoder, 'encoder_no_compress.png', show_shapes=True) # save the encoder to file encoder.save('encoder.h5') |
Running the example fits the model and reports loss on the train and test sets along the way.
Note: if you have problems creating the plots of the model, you can comment out the import and call the plot_model() function.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we see that loss gets low, but does not go to zero (as we might have expected) with no compression in the bottleneck layer. Perhaps further tuning the model architecture or learning hyperparameters is required.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
... 42/42 - 0s - loss: 0.0032 - val_loss: 0.0016 Epoch 196/200 42/42 - 0s - loss: 0.0031 - val_loss: 0.0024 Epoch 197/200 42/42 - 0s - loss: 0.0032 - val_loss: 0.0015 Epoch 198/200 42/42 - 0s - loss: 0.0032 - val_loss: 0.0014 Epoch 199/200 42/42 - 0s - loss: 0.0031 - val_loss: 0.0020 Epoch 200/200 42/42 - 0s - loss: 0.0029 - val_loss: 0.0017 |
A plot of the learning curves is created showing that the model achieves a good fit in reconstructing the input, which holds steady throughout training, not overfitting.
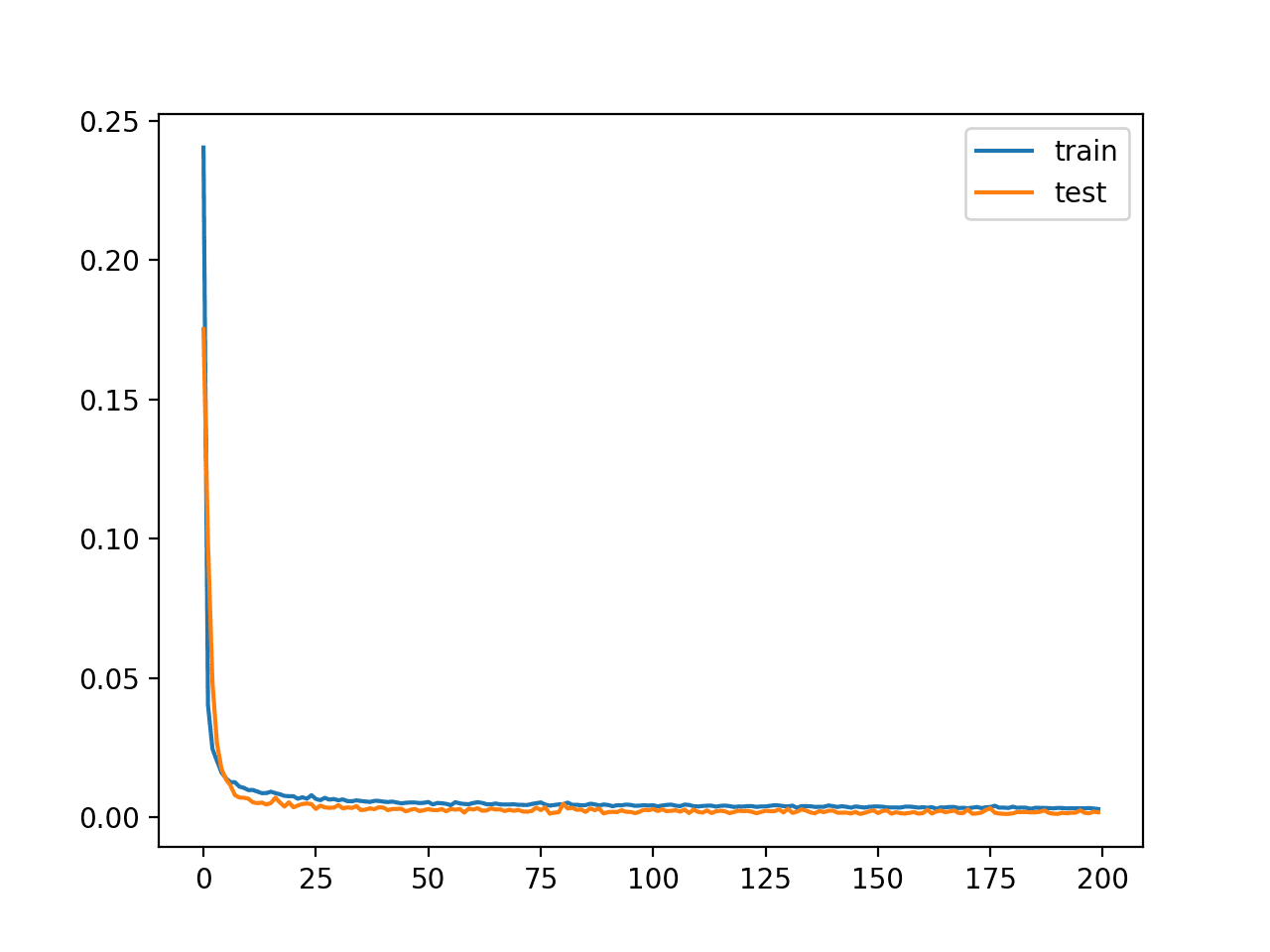
Learning Curves of Training the Autoencoder Model Without Compression
So far, so good. We know how to develop an autoencoder without compression.
Next, let’s change the configuration of the model so that the bottleneck layer has half the number of nodes (e.g. 50).
|
1 2 3 4 |
... # bottleneck n_bottleneck = round(float(n_inputs) / 2.0) bottleneck = Dense(n_bottleneck)(e) |
Tying this together, the complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
# train autoencoder for classification with with compression in the bottleneck layer from sklearn.datasets import make_classification from sklearn.preprocessing import MinMaxScaler from sklearn.model_selection import train_test_split from tensorflow.keras.models import Model from tensorflow.keras.layers import Input from tensorflow.keras.layers import Dense from tensorflow.keras.layers import LeakyReLU from tensorflow.keras.layers import BatchNormalization from tensorflow.keras.utils import plot_model from matplotlib import pyplot # define dataset X, y = make_classification(n_samples=1000, n_features=100, n_informative=10, n_redundant=90, random_state=1) # number of input columns n_inputs = X.shape[1] # split into train test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # scale data t = MinMaxScaler() t.fit(X_train) X_train = t.transform(X_train) X_test = t.transform(X_test) # define encoder visible = Input(shape=(n_inputs,)) # encoder level 1 e = Dense(n_inputs*2)(visible) e = BatchNormalization()(e) e = LeakyReLU()(e) # encoder level 2 e = Dense(n_inputs)(e) e = BatchNormalization()(e) e = LeakyReLU()(e) # bottleneck n_bottleneck = round(float(n_inputs) / 2.0) bottleneck = Dense(n_bottleneck)(e) # define decoder, level 1 d = Dense(n_inputs)(bottleneck) d = BatchNormalization()(d) d = LeakyReLU()(d) # decoder level 2 d = Dense(n_inputs*2)(d) d = BatchNormalization()(d) d = LeakyReLU()(d) # output layer output = Dense(n_inputs, activation='linear')(d) # define autoencoder model model = Model(inputs=visible, outputs=output) # compile autoencoder model model.compile(optimizer='adam', loss='mse') # plot the autoencoder plot_model(model, 'autoencoder_compress.png', show_shapes=True) # fit the autoencoder model to reconstruct input history = model.fit(X_train, X_train, epochs=200, batch_size=16, verbose=2, validation_data=(X_test,X_test)) # plot loss pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='test') pyplot.legend() pyplot.show() # define an encoder model (without the decoder) encoder = Model(inputs=visible, outputs=bottleneck) plot_model(encoder, 'encoder_compress.png', show_shapes=True) # save the encoder to file encoder.save('encoder.h5') |
Running the example fits the model and reports loss on the train and test sets along the way.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we see that loss gets similarly low as the above example without compression, suggesting that perhaps the model performs just as well with a bottleneck half the size.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
... 42/42 - 0s - loss: 0.0029 - val_loss: 0.0010 Epoch 196/200 42/42 - 0s - loss: 0.0029 - val_loss: 0.0013 Epoch 197/200 42/42 - 0s - loss: 0.0030 - val_loss: 9.4472e-04 Epoch 198/200 42/42 - 0s - loss: 0.0028 - val_loss: 0.0015 Epoch 199/200 42/42 - 0s - loss: 0.0033 - val_loss: 0.0021 Epoch 200/200 42/42 - 0s - loss: 0.0027 - val_loss: 8.7731e-04 |
A plot of the learning curves is created, again showing that the model achieves a good fit in reconstructing the input, which holds steady throughout training, not overfitting.
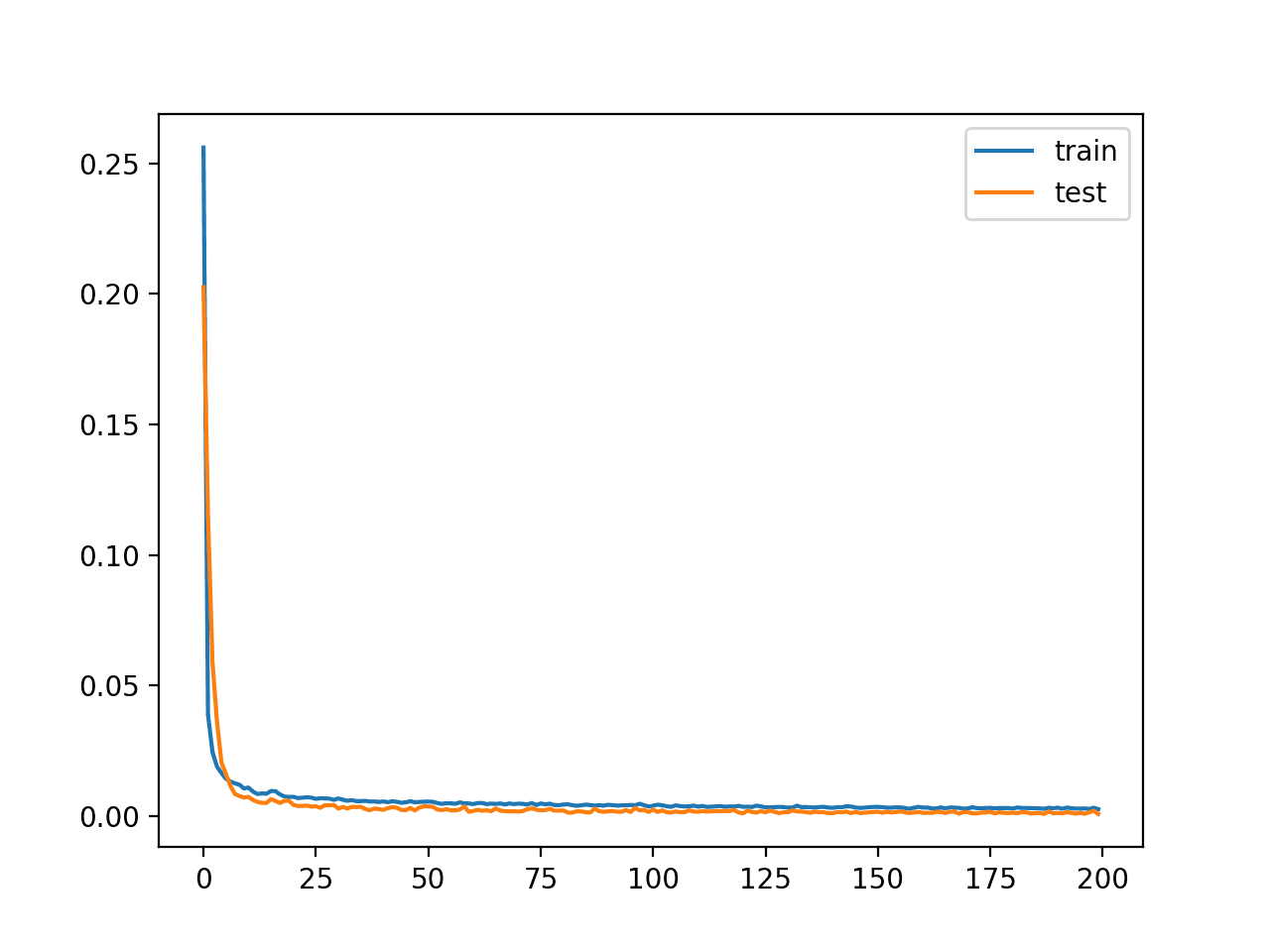
Learning Curves of Training the Autoencoder Model With Compression
The trained encoder is saved to the file “encoder.h5” that we can load and use later.
Next, let’s explore how we might use the trained encoder model.
Encoder as Data Preparation for Predictive Model
In this section, we will use the trained encoder from the autoencoder to compress input data and train a different predictive model.
First, let’s establish a baseline in performance on this problem. This is important as if the performance of a model is not improved by the compressed encoding, then the compressed encoding does not add value to the project and should not be used.
We can train a logistic regression model on the training dataset directly and evaluate the performance of the model on the holdout test set.
The complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# baseline in performance with logistic regression model from sklearn.datasets import make_classification from sklearn.preprocessing import MinMaxScaler from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score # define dataset X, y = make_classification(n_samples=1000, n_features=100, n_informative=10, n_redundant=90, random_state=1) # split into train test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # scale data t = MinMaxScaler() t.fit(X_train) X_train = t.transform(X_train) X_test = t.transform(X_test) # define model model = LogisticRegression() # fit model on training set model.fit(X_train, y_train) # make prediction on test set yhat = model.predict(X_test) # calculate accuracy acc = accuracy_score(y_test, yhat) print(acc) |
Running the example fits a logistic regression model on the training dataset and evaluates it on the test set.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the model achieves a classification accuracy of about 89.3 percent.
We would hope and expect that a logistic regression model fit on an encoded version of the input to achieve better accuracy for the encoding to be considered useful.
|
1 |
0.8939393939393939 |
We can update the example to first encode the data using the encoder model trained in the previous section.
First, we can load the trained encoder model from the file.
|
1 2 3 |
... # load the model from file encoder = load_model('encoder.h5') |
We can then use the encoder to transform the raw input data (e.g. 100 columns) into bottleneck vectors (e.g. 50 element vectors).
This process can be applied to the train and test datasets.
|
1 2 3 4 5 |
... # encode the train data X_train_encode = encoder.predict(X_train) # encode the test data X_test_encode = encoder.predict(X_test) |
We can then use this encoded data to train and evaluate the logistic regression model, as before.
|
1 2 3 4 5 6 7 |
... # define the model model = LogisticRegression() # fit the model on the training set model.fit(X_train_encode, y_train) # make predictions on the test set yhat = model.predict(X_test_encode) |
Tying this together, the complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
# evaluate logistic regression on encoded input from sklearn.datasets import make_classification from sklearn.preprocessing import MinMaxScaler from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score from tensorflow.keras.models import load_model # define dataset X, y = make_classification(n_samples=1000, n_features=100, n_informative=10, n_redundant=90, random_state=1) # split into train test sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=1) # scale data t = MinMaxScaler() t.fit(X_train) X_train = t.transform(X_train) X_test = t.transform(X_test) # load the model from file encoder = load_model('encoder.h5') # encode the train data X_train_encode = encoder.predict(X_train) # encode the test data X_test_encode = encoder.predict(X_test) # define the model model = LogisticRegression() # fit the model on the training set model.fit(X_train_encode, y_train) # make predictions on the test set yhat = model.predict(X_test_encode) # calculate classification accuracy acc = accuracy_score(y_test, yhat) print(acc) |
Running the example first encodes the dataset using the encoder, then fits a logistic regression model on the training dataset and evaluates it on the test set.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the model achieves a classification accuracy of about 93.9 percent.
This is a better classification accuracy than the same model evaluated on the raw dataset, suggesting that the encoding is helpful for our chosen model and test harness.
|
1 |
0.9393939393939394 |
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Tutorials
- A Gentle Introduction to LSTM Autoencoders
- How to Use the Keras Functional API for Deep Learning
- TensorFlow 2 Tutorial: Get Started in Deep Learning With tf.keras
Books
- Deep Learning, 2016.
APIs
Articles
Summary
In this tutorial, you discovered how to develop and evaluate an autoencoder for classification predictive modeling.
Specifically, you learned:
- An autoencoder is a neural network model that can be used to learn a compressed representation of raw data.
- How to train an autoencoder model on a training dataset and save just the encoder part of the model.
- How to use the encoder as a data preparation step when training a machine learning model.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.




 for Feature Selection in Python")

Thanks Jason,
Can you explain again why we would expect the results of a compressed dataset with the encoder to give better results than the raw dataset? Aren’t we just losing information by compressing?
I thought that the value of the compression would be that we would be dealing with a smaller dataset with less features.
I guess somehow it’s learned more useful latent features similar to how embeddings work? Is that the case?
Thanks
We don’t expect it to give better performance, but if it does, it’s great for our project.
It is similar to an embedding for discrete data.
Yes – similar to dimensionality reduction or feature selection, but using less features is only useful if we get same or better performance.
I think what he was asking was, why on Earth would this compression EVER improve a result?
Thanks.
The bottleneck may be able to compress large/complex input features into a lower-dimensional space. This can be helpful as dimensionality reduction. This compression may or may not be helpful to predictive models, often it is.
Because input dimensions may be too large for our model to fit with the training data we have. By compressing input data, we can fit the model with less likelihood of overfitting.
It not only reduce the dimensionality of the data, you are applying filters to the features, so the
operations performed by the network could generate new features that may help to understand better the inputs.
Its like when we filter signal, we get new features from that transformation and we can see more clearly some charcateristics on the transformed space.
Also, because of going through auto-encoder, it will generates hidden nonlinear interactions between features, something might not be learned from a logistic regression
Thanks for this tutorial!
How does encoder.save(‘encoder.h5’) get the learned weights from the model object? How does instantiating a new model object using encoder = Model(inputs=visible, outputs=bottleneck) allow us to keep the weights?
Saving the model involves saving both the architecture and weights into a single file. We can then load it and use it directly.
More on saving and loading models here:
https://machinelearningmastery.com/save-load-keras-deep-learning-models/
In that line we define a new model with layers now shared between two models – the encoder-decoder model and the encoder model. We only keep the encoder model.
Dear Jason,
Sir I can’t see how did you eliminate the decodeing part and just extracting features from the encoding part, from the code !
I only see you using the whole model !
Please, I need to extract features from the decoding part then feed them to a classifier like the SVM !
We define an encoder model and save it by itself. We also define a complete model that re-uses some of the layers of the encoder. We don’t save this complete model.
Does that help?
Hello sir… I just wanted to know which type of autoencoder you used in this .. like is it sparse, stacked or multilayer autoencoder.
I don’t know how it might fit into a taxonomy sorry. It’s just an autoencoder, nothing fancy.
Dear Jason, thank you for all informative sharings. I confused in one point like John. How does new encoder model learns weights from the autoencoder or why don’t we compile encoder model?
You’re welcome.
We train the encoder as part of the autoencoder, but then only save the encoder part. The weights are shared between the two models.
No beed need to compile the encoder as it is not trained directly.
Dear Jason,
Thanks for the nice tutorial. Is there an efficient way to see how the data is projected on the bottleneck? I would like to compare the projection with PCA.
Thanks!
Yes. You can create a PCA projection of the encoded bottleneck vectors if you like.
Alright. Do you have a tutorial for visualizing the principal components?
I don’t think so.
It’s pretty straightforward, retrieve the vectors, run a PCA and then scatter plot the result.
Perhaps start here:
https://machinelearningmastery.com/?s=Principal+Component&post_type=post&submit=Search
Thank you so much for this informative tutorial. Please let me know the required version of keras and tensorflow to implement this codes.
You can use the latest version of Keras and TensorFlow libraries.
Dear Jason
this is a classification problem then why we take the loss as MSE
We use MSE loss for the reconstruction error for the inputs – which are numeric.
Thanks for this tutorial. Is it possible to make a single prediction? Which transformation should do we apply?
Yes, encode the input with the encoder, then pass the input to the predict() function of the trained model.
Jason, now a days you are showing the code only in python.. kindly show the same in R language for R users too.. thank you
Thanks for the suggestion.
Dear Jason, I think there is a typo mistake in
# train autoencoder for classification with no compression in the bottleneck layer
in filt calling
you writ “history = model.fit(X_train, X_train, epochs=200, batch_size=16, verbose=2, validation_data=(X_test,X_test)) ”
I think y_train Not 2 of X_train
with best regards
thnks for tutorial
No, it is correct.
The autoencoder is being trained to reconstruct the input – that is the whole idea of the autoencoder.
Dear Dr. Jason,
Thank you for the tutorial.
The method looks good for determining the number of clusters in unsupervised learning. I tried to reduce the dimensions with it and estimate the number of clusters first on the large synthetic dataset (more than 25000 instances and 100 features) with 10 informative features and then repeat it on the same real noisy data. I achieved good results in both cases by reducing the number of features to less than the informative ones, five in my case. This method helps to see the clear “elbows” of AIC, BIC informative criteria in the plot of the Gaussian Mixture Model, and fasten the work of algorithm in times.
You’re welcome.
Nice work, thanks for sharing your finding!
Hi… can we use this tutorial for multi label classification problem??
The autoencoder can be used directly, just change the predictive model that makes use of the encoded input.
Hi,
Is it possible to use autoencoder model in Multinomial Logistic Regression for multi label classification of unlabeled data (unsupervised)?
Hi Santobedi…The following may be of interest to you:
https://machinelearningmastery.com/autoencoder-for-regression/
Hi Jason:
Thank you very much for all your free great tutorial catalog … one of the best in the world !.that serves as inspiration to my following work!
I share my conclusions after applying several modification to your baseline autoencoder classification code:
1.) Code Modifications:
1.1) I decided to compare accuracies results from 5 different classification models:
(LogisticRegression, SVC, ExtratreesClassifier, RandomForestClassifier, XGBClassifier)
1.2) I apply statistical evaluation to model results trough well known “KFold()” and “cross_val_score()” functions of SKLearn library
1.3) and very important I apply several rates of autoencoding features compression such as 1 (no compression at all), 1/2 (your election) , 1/4 (even more compressed) and of course not autoencoding and even expand features to double to see what happen (some kind of embedding?)) …
2.) my conclusion, after obtaining the same approach results as your LogisticRegression model, are the results are more sensitive to the model chosen:
sometimes autoencoding it is no better results that not autoencoding, and sometines 1/4 compression is the best …so a lot of variations that indicate you have to work in a heuristic way for every particular problem!
In particular my best results are chosen SVC classification model and not autoencoding bu on logistic regression model it is true the best results are achieved by autoencoding and feature compression (1/2).
It is a pity that I can no insert here (I do not know how?) my graphs results to visualize it!
As I said you provide us with the basic tools and concepts and then we can experiment variations on those ideas
Thanks!
Well done, that sounds like a great experiment.
Likely results are limited by the synthetic dataset. Perhaps the results would be more interesting/varied with a larger and more realistic dataset where feature extraction can play an important role.
As a matter of fact I applied the same autoencoder analysis to a more “realistic” dataset as “breast cancer” and “diabetes pima india” and I got similar results of previous one, but with less accuracy around 75% for Cancer and 77% for Diabetes, probably because of few samples (286 for cancer and 768 for diabetes)…
In both cases cases LogisticRegression is now the best model with and without autoencoding and compression… I remember got same results using ‘onehotencoding’ in the cancer case …
So “trial and error” with different models and different encoding methods for each particular problema seem to be the only way-out…
Very nice work!
No silver bullet for feature extraction, and all that. Just another method in our toolbox.
Hello
I need a matlab code for this tutorial
Sorry, I do not have any matlab code.
Hi Jason,
Thank you very much for this insightful guide.
When using an AE solely for feature creation, can you skip the steps on decoding and fitting? i.e. just use the encoder part:
# define encoder
visible = Input(shape=(n_inputs,))
# encoder level 1
e = Dense(n_inputs*2)(visible)
e = BatchNormalization()(e)
e = LeakyReLU()(e)
# encoder level 2
e = Dense(n_inputs)(e)
e = BatchNormalization()(e)
e = LeakyReLU()(e)
# bottleneck
n_bottleneck = n_inputs
bottleneck = Dense(n_bottleneck)(e)
And then ‘create’ the new features by jumping to:
encoder = Model(inputs=visible, outputs=bottleneck)
X_train_encode = encoder.predict(X_train)
X_test_encode = encoder.predict(X_test)
In other words, is there any need to encode and fit when only using the AE to create features?
Thank you very much.
This is exactly what we do at the end of the tutorial.
But you load and use the saved encoder at the end of the tutorial – encoder = load_model(‘encoder.h5’). Just wondering if encoding and fitting prior to saving the encoder has any impact at the end when creating. Thanks
* decoding and fitting
The encoder model must be fit before it can be used.
You can choose to save the fit encoder model to file or not, it does not make a difference to its performance.
The decoder is not saved, it is discarded.
Why do we fit the encoder model in feature creation, if fitting is just used to reconstruct the input (which we don’t need)?
It is fit on the reconstruction project, then we discard the decoder and are left with just the encoder that knows how to compress input data in a useful way.
Got it, thank you very much. Just wanted to ensure that the loss and val_loss are still relevant when using the latent representation, even though the decoder is discarded.
The loss is only relevant to the task of reconstructing input.
The encoding achieved at the bottleneck layer may or may not be helpful to a prediction task using the input data, it depends on the specific dataset.
Generally, it can be helpful – the whole idea of the tutorial is to teach you how to do this so you can test it on your data and find out.
Ok so loss is not relevant when only taking the encoded representation. I am trying to compare different (feature extraction) autoencoders. I was hoping to do so by comparing the loss and val_loss, but I guess doing so is only relevant when fitting a model for classification, after extracting the AE features.
Thanks
Yes, the only relevant comparison (for predictive modeling) is the effect on a classifier/regressor that uses the encoded input.
Dear Jason,
I am going to use the encoder part as a tool that generates a new features and I will combine them with the original data set.
So, How can I control the number of new features I want to get, in the code?
Good question.
Control over the number of features in the encoding is via the number of nodes in the bottleneck layer.
I already did, But it always gives me number of features like equal my original input.
Here is the code I changed.
Or if you have time please send me the modified version which gave me 10 new featues.
abdelrahmanahmedfayed@gmail.com
# define encoder
visible = Input(shape=(n_inputs,))
# encoder level 1
e = Dense(round(float(n_inputs) / 2.0))(visible)
e = BatchNormalization()(e)
e = LeakyReLU()(e)
# encoder level 2
e = Dense(round(float(n_inputs) / 2.0))(e)
e = BatchNormalization()(e)
e = LeakyReLU()(e)
# bottleneck
n_bottleneck = 10
bottleneck = Dense(n_bottleneck)(e)
Sorry, I don’t have the capacity to customize the tutorial for you.
Can we use this code for multi-class classification? Which lines will be tweaked in that case?
Jason Brownlee, please give a hint at least, I am searching an article on autoencoder for multiclass classification for weeks.
Yes, with no change.
Dear Jason,
Thank you very much for your tutorials!
I need some clarification in this following code
# encode the train data
X_train_encode = encoder.predict(X_train)
# encode the test data
X_test_encode = encoder.predict(X_test)
My first query is, what actually we do in this code?
My second query is, if we have the embedding (i.e compressed data ) of dataset then we can proceed directly from the bottleneck layer output to logistic regression classification model. why we need this above code, I mean why we predict for new x_train
We are using the trained encoder to encode the input data for train and test sets.
The output of the encoder is the bottleneck.
This encoded data is fed as input to the logistic regression model.
Dear Jason,
Please tell me have to extract the latent space features given by the bottle neck layer as CSV file. Is it possible?.The type(encoder) is tensorflow.python.keras.engine.functional.Functional
You can if you like, predict each input via the encoder and save results to csv.
Dear Jason,
The features extracted from the bottleneck layer has NAN values, please give some suggestions to get rid of them.
Thank you
That is surprising, perhaps these tips will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Dear Jason,
Sorry, your code is working perfectly fine for me but I tried this with my own problem then I got these NAN values so I asked you to suggest some good practices or may be the reason or solution to avoid it.
Thank you
Perhaps check that you scaled your data prior to modeling and that your data does not contain nan values.
Good stuff. Tried exploding the number of features with polynomials, and then passing them through the autoencoder to get rid of the useless ones. Worked like a charm. Thanks.
Wow, very cool idea to test!
(why didn’t I think of that???)
Well done!
Dear Jason,
Can Auto Encoder be used to classify multiple classes? For example, 5 classes?
Sure.
Dear Dr. Jason,
Thank you for the tutorial.
I looked at the code but did not know where to apply my database.
in which section and how can I do this?
Perhaps this will help you load your dataset:
https://machinelearningmastery.com/load-machine-learning-data-python/
Hello Dr. Jason,
I appreciate your amazing tutorial.
I have a problem with my input shape when I want to define encoder and decoder part.
My input shape is : (75, 75, 3). I have no idea how should adjust conv layer according to my input.
Thank you for your help in advance
The above example is for tabular data, not images sorry.
thanks Jason for great tutorial:) I have a question if we can use autoencoder for extract features from images rather than tabular data if yes can you provide me any links that make me understand it Plz?
Sure, it is called transfer learning:
https://machinelearningmastery.com/how-to-use-transfer-learning-when-developing-convolutional-neural-network-models/
Dear Dr. Jason,
Thank You for your tutorial.
I am working on time-series data. I know the input data is compressed in the encoded state and the features can be visualized on that compressed data. But, I want to visualize my original input data on those encoded features (like we can visualize in PCA and clusters). Is it possible to do so? If yes, please suggest!
No.
Hi, Jason,
Thank you so much for this tutorial. I’m working on a fault detection classification. There two datasets involved. One is fault free data (normal) and the other is on faulty operations which contains the labels of the faults. Can I train, the autoencoder on the fault free(normal) and later use the encoder on the “fault” data for SVM classification?
Perhaps try it and compare results to a model operating on both datasets.
so as long as the encoder is applied to a similar data it should be good right (sort of transfer learning)?
Perhaps.
Hello Jason,
Your tutorials have been a lot of help to me when I was learning this stuff. In fact, even now, when I am looking up something related to implementing something using Python, particularly neural net related, first thing I try is to look for one of your tutorials. Having said that, recently I found no such information on using TFP (tensorflow’s probability module) for doing probabilistic programming, particularly VAEs. Although this may not be a good place to ask about VAEs, but I would give it a try nonetheless.
Could you do a small tutorial on this subject matter using TFP ?
Thanks in advance.
Thanks!
Thank you for the suggestion.
Hey Jason! Thanks. Can you please how would we modify modify.fit() when using own image dataset? Perhaps using ImageDataGenerator of Keras, but how do we use it in model.fit()?
I doin’t think this example is an appropriate place to start for working with image data, perhaps start here:
https://machinelearningmastery.com/start-here/#dlfcv
Sorry, typo.
model.fit()
How do you reshape the encoded data (in your case this is X_train_encode) so that it is two dimensional and aligns with the y train. I trained an autoencoder and my resulting x_train_encode had a latent space of 32 X 32 X 32 though I originally had 5900 images and each were 254 X 254 X 254. Now, how do I match this matrix of 32 x 32 x32 with my y_train and the photos for training with classifiers like KNN or SVM? Thank you!
The above example is not for images.
If you are working with images, I would recommend starting here:
https://machinelearningmastery.com/start-here/#dlfcv
Hi,
Thank you so much for the post!
I am wondering why the validation loss is lower than the training loss?
Is it related to the way tensorflow computes losses?
Thanks,
It may be a statistical fluke.
It may be that the validation dataset is small and not representative of the training set.
Hi,
I’m training a model with a similar architecture, and I also found that the validation loss is much lower than the training loss. Although it doesn’t affect the result of my model, I’d like to figure out why such nonsense situation happens all the time. I first thought there may be data leakage, and therefore I have used different ways to split my training and validation dataset. However, it is still the same case. After a few more attempts, I soon solve the problem when I changed the loss function from mean squared error to (1 – structural similarity). So I’m wondering if the computation of the losses cause the problem just as Yahya mentioned. Please let me know if you have any new thought on the issue after seeing my reply.
Thanks
Perhaps the validation dataset is too small or not representative of the training dataset.
I’d tried to split my dataset into half, with 50% of it as training set and the another half as validation set. And I also tried not to shuffle the dataset, but these doesn’t change much. I’ve never seen that other than autoencoder. It’s just weird, and I’m not sure if I should ignore the issue.
Perhaps explore alternate model configs too?
can we use the encoder as a data preparation step to train a neural network model?
Sure. But why not train your model directly instead.
i want to pretrained the model using autoencoder to get weight inisialization, and then use the weight for neural network model. do you have the tutorial for me?
Not really, sorry.
This might give you ideas:
https://machinelearningmastery.com/how-to-improve-performance-with-transfer-learning-for-deep-learning-neural-networks/
how we can find accuracy for this classifier I have need the values of accuracy not graphical representation from x-ray images in python I need source code
Perhaps this will help:
https://scikit-learn.org/stable/modules/generated/sklearn.metrics.accuracy_score.html
Hi Jason
Thanks for the amazing tutorial.
When I ran the code for my dataset, the model ran and the loss decreased with the epochs. But a warning came-
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built.
model.compile_metricswill be empty until you train or evaluate the model.Do you know why this coming? I couldn’t find anything online. Thanks in advance
You’re welcome.
You can probably safely ignore that warning for now.
Hey, Jason,
Thank you so much for this tutorial. i wanna create a model for authorship verification form text to determine if two document are writing by the same author or not, using the autoencoder but i have a lot of problems i don’t understand the dataset and how can i train and build my model.
please help understand it !!
this is the architecture of data set:
the first .jsonl file is as below :
{“id”: “6cced668-6e51-5212-873c-717f2bc91ce6”, “fandoms”: [“Fandom 1”, “Fandom 2”], “pair”: [“Text 1…”, “Text 2…”]}
{“id”: “ae9297e9-2ae5-5e3f-a2ab-ef7c322f2647”, “fandoms”: [“Fandom 3”, “Fandom 4”], “pair”: [“Text 3…”, “Text 4…”]}
and the second .jsonl truth file is :
{“id”: “6cced668-6e51-5212-873c-717f2bc91ce6”, “same”: true, “authors”: [“1446633”, “1446633”]}
{“id”: “ae9297e9-2ae5-5e3f-a2ab-ef7c322f2647”, “same”: false, “authors”: [“1535385”, “1998978”]}
Perhaps you could experiment with different framings of the problem?
Perhaps you could model it as a binary classification task with a model that takes text from two sources?
thank you so much for your reply sir jason
I ask you for a favour sir if you can propose for me some Techniques of deep learning for this data
Test a suite of techniques and discover what works well or best.
Hi Jason, thanks for sharing your knowledge with the community. i have really leant a lot from you. infact your blogs and books are my go-to when i have doubts. i just completed your tutorial on autoencoder and would like your expert guide on a problem stated below:
dataframe_a =ID, col1, col2, col3, col4,col5,col6,col7,col8,col9 …..col21,label
dataframe_b = ID, col_A, col_B, col_C, col_D
dataframe_a has shape (3250, 23) while dataframe_b has shape (64911, 5). note: dataframe_b has no label.
performing inner join to merge both data on ‘ID’ gave a small dataof shape (274, 27) and the model perform badly
i have already trained a binary classification model on the first data (dataframe_a) and achieved an accuracy of ~70% to predict the label. it is my believe that there are some information in the second data(dataframe_b) which would help improve my model performance but as i mentioned above mapping both data on feature ‘ID’ gave a really small data.
how i can use autoencoder in combination with the model i had already trained on dataframe_a to achieve a better accuracy. Also, if you have a use-case of related to my question, please share it.
I look forward to your response. Thanks in advance
Perhaps you can mark missing values and then impute them or use a model that can ignore them.
Perhaps you can use a multi-input model that takes additional data when available or all zeros otherwise.
Thank you Jason for this very well explained tutorial, as usual.
I just wonder why did you choose Adam optimizer, is there a reason behind? Which nother opotimizer would you choose here and why?
Thank you!
You’re welcome.
I chose Adam because it works well in most cases. You can use any optimize you like.
Hi Jason,
Thank you very much for your great tutorial. I would like to use an autoencoder for dimension reduction of some 1D data (light spectrums). I have only 180 samples (from 17 patients) which each of which includes 1000 points, so the input dimension is 180*1000, and this is raw data with no feature extraction done before. I need to classify these data into two classes (cancer, non-cancer) but as the number of samples is low (180), I think it is better that I reduce the dimension from raw data=1000 to for example 50 and then apply classification for example a fully connected dense network.
I was thinking to do such a raw data dimension reduction with autoencoder as I have no idea what features I can manually extract from raw data and I thought autoencoder could do automatic feature extraction for me, and then I can use the feature vectors (e.g 180*50) as an input for any classifier.
In your tutorial you did dimension reduction from 1000*100 > 1000*50, Would you please tell me if you think I can use your approach for my data considering the little sample size I have? I would like to reach for example 180*1000 > 180*50. And also would be very kind of you if you recommend me, in general, any solution to solve this classification problem considering that I have a little data set and I also do not know which features to extract (That is why I am thinking of neural networks and possibly deep learning).
Thanks a lot in advance
Best regards
Sepi
Perhaps you can try it and compare results to fitting a model on the raw data directly then use whatever works best.
Hi Jason,
Thanks for your answer. Could you please tell me what do you mean by ‘fitting a model on the raw data directly’? Do you mean for example applying a fully connected network (dense) for classification using raw data (no feature extraction)?
Best
Sepi
Yes.
Dear Jason,
love your work, thanks a lot for everything!
Do you know if there is a possibility to retrieve the weights of the encoder, so that you can remap it on the original data to investigate which features were selected?
Best,
reini
If you have a layer, you can do layer.get_weights(); but that’s only for one layer at a time. You can’t do that with a model at once.
Greeting Dr. Jason,
Can autoencoder work with all types of datasets?
I am working on student performance data that including the student demographic information, performance in classes (final scores), and the final result (pass or no pass). When I use autoencoder, I get very weird results. I do know where was my mistake but sometimes I wonder can autoencoder deal with this kind of data!
What do you expect for an autoencoder in this case? My favorite explanation of an autoencoder is a lossy compression of the input. If you can related the compression to your problem, then autoencoder is a good model for it.
I am just trying to see how the autoencoder (feature extraction) can help to increase the performance of a predictive model that uses any traditional classifier. That would be by comparing it to the same classifier without using extract the salient features. I asked because I didn’t see any example of an autoencoder working on the same type of data!
Autoencoder in that case should be considered as a lossy compression. If you have a data point of 1000 features, you may run an autoencoder to produce a length-50 vector instead. Then you can apply the length-50 to classifier instead of a length-1000 vector. You (1) save memory and run faster because your model is less complex, and (2) potentially more accurate because we suppose the autoencoder removed the noise from the original data.
Thanks for the very informative response. One more question, how to evaluate autoencoder performance? when I list the metrics to monitor acc and val_acc during the training of autoencoder, both show very low.
Autoencoder is an unsupervised learning technique. The metric to minimize should be error between the decoder output to the encoder input.
Hai Sir,
Is there any limits about the feature vector dimensions?
Specifically, shall I use the samples having feature vector dimensions less than 10 ?
Actually I have images with varying sizes,so to input this to the encoder,I take a simple feature vector based on statistical moments and give the same as input to the autoencoder.
Could you pl give me any suggestion regarding this?
Thanks in advance.
No limit but we prefer to be as small as possible. If you happen to find one single feature that predicts the classification perfectly, you get a very nice simple model.
Thank you Sir.
Dear Jason,
Thanks for the great tutorial. Your tutorials are a great help for beginners like me. Thankyou very very much!
I am working with a multi-class classification problem. I am trying to apply autoencoder based dimensionality reduction technique. In that case, can we apply the same activation function (‘linear’) as mentioned in the code.
For deep neural networks, we were using softmax as activation function for multiclas. So can we try that activation functions like sigmoid and softmax for dimensionality reduction for multiclass classification tasks.
Thanks
Thanks for sharing. Glad you found the tutorials useful.
Dear Jason,
Love your work and thanks a lot.
Would you please explain in which the performance of Autoencoder in Keras is columnar or cross-row? On other hand, does the AE model span the input matrix column by column or row by row?
Can you tell what will be the output of autoencoder if we use it for feature extraction.
Hi msec…Please elaborate on your question so that we may better assist you.
Hi, how can we visualize the autoencoder latent vector (feature extraction) into color trajectory RGB.
Hi Mylo…You may find the following of interest:
https://hackernoon.com/latent-space-visualization-deep-learning-bits-2-bd09a46920df
Dear Jason, thank you so much for your tutorial.
In your example, you don’t compile the encoder while yo compile the model with encoder/decoder. I do not understand that.
Many thanks in advance.
Hi JB…It is just for illustration. You should compile the models.
Hi there, thanks for the tutorial!
Why does the first layer of the encoder output 2x the number of input features? Is there an advantage of doing that rather than just starting to output less than the number of features starting from the first layer?
Ie. your example has: Encoder: 100 -> 200 -> 100 -> 50 <- 100 <- 200 85 -> 70 -> 50 <- 70 <- 85 <- 100
Thanks!
PM
Hi PM…The following resource may help add clarity:
https://deep-learning-study-note.readthedocs.io/en/latest/Part%203%20(Deep%20Learning%20Research)/14%20Autoencoders/14.3%20Representational%20Power,%20Layer%20Size%20and%20Depth.html
hi, PM i’ve the same qstn as yours , if u please find the anwer ?
Hi Jason, thanks for this informative post. I tried auto encoder on my dataset (sample size is 52 aand features are 86). My validation loss is either constant or increases. What should I do?
Hi RK…You are very welcome! In this case, I would recommend concentration on data preprocessing:
https://machinelearningmastery.com/improve-model-accuracy-with-data-pre-processing/
Hi, thanks for such a great work you done.
I have a questions.
1) Is it possible to train the autoencoder with (i.e) pictures of cats and dogs, and then after training we give a new picture of cat and it automatically predict that this picture is of cat picture? is this kind of work done using autoencoder?
Hi Ibrar…Absolutely. This is the purpose of this model type.
Sir,
I am doing my project on autoencoder. My dataset dimension is 19680 rows and 64 columns. I trained the autoencoder and now I want to get the encoded features from the encoder.
What will be the dimension of the encoded features in terms of rows and columns.
Hi IJAZ…The following resource may be of interest:
https://towardsdatascience.com/autoencoder-on-dimension-reduction-100f2c98608c
Hi Jason,
thank you very much for this great tutorial.
I was wondering why you don’t have to fit the encoder. Is there a specific reason?
Thanks in advance.
Hi Pascal…You are very welcome! The following discussion may help add clarity:
https://www.kaggle.com/getting-started/116296
Hi Joson,
What could be responsible for this warming:
WARNING:tensorflow:Compiled the loaded model, but the compiled metrics have yet to be built.
model.compile_metricswill be empty until you train or evaluate the model.Hi Amina…The following discussion may prove insightful:
https://stackoverflow.com/questions/67970389/warningtensorflowcompiled-the-loaded-model-but-the-compiled-metrics-have-yet
Thanks Dr Jason for your great tutorial.
I am looking for VAE based cifar100 classification problem. In this regard,
1. Can you please suggest similar tutorial using VAE
2. How can I use it for cifar100 classification.
3. Any material or book available from your side.
I am using your GAN book that is yet to be started as first willing to implement VAE.
Thanks and Best wishes
Thanks for your tutorial, it is very useful. I have a question, I’ve searched about the theory of autoencoders, but most of the examples suggests that I should train it for one class (for example: no fraud), that way, the model can recognize the most important features of that class, and when you put the class fraud (for example), it will detect an anomaly, that’s how i’ve seen so many works, so i don’t understand if it’s that way or depends of the problem or how it works that part, although the examples don’t have the Data Preparation for Predictive Model part :c
Hi Meredith…Your understanding of training autoencoders is correct! You can learn more here:
https://medium.com/low-code-for-advanced-data-science/fraud-detection-using-a-neural-autoencoder-a5bdc244f390#id_token=eyJhbGciOiJSUzI1NiIsImtpZCI6ImVkODA2ZjE4NDJiNTg4MDU0YjE4YjY2OWRkMWEwOWE0ZjM2N2FmYzQiLCJ0eXAiOiJKV1QifQ.eyJpc3MiOiJodHRwczovL2FjY291bnRzLmdvb2dsZS5jb20iLCJhenAiOiIyMTYyOTYwMzU4MzQtazFrNnFlMDYwczJ0cDJhMmphbTRsamRjbXMwMHN0dGcuYXBwcy5nb29nbGV1c2VyY29udGVudC5jb20iLCJhdWQiOiIyMTYyOTYwMzU4MzQtazFrNnFlMDYwczJ0cDJhMmphbTRsamRjbXMwMHN0dGcuYXBwcy5nb29nbGV1c2VyY29udGVudC5jb20iLCJzdWIiOiIxMTA3MTAyODIwMDE0ODIwMjg4MzQiLCJlbWFpbCI6ImphbWVzcGNhcm1pY2hhZWxAZ21haWwuY29tIiwiZW1haWxfdmVyaWZpZWQiOnRydWUsIm5iZiI6MTcwNzY4NjQ0MCwibmFtZSI6IkphbWVzIENhcm1pY2hhZWwsIFAuRS4sIFBNUCIsInBpY3R1cmUiOiJodHRwczovL2xoMy5nb29nbGV1c2VyY29udGVudC5jb20vYS9BQ2c4b2NLSXdMdG9DYlczX21wLWxMN0t1OEdBWVF0S1VaSkdteGpIcm8zZDV2dUw9czk2LWMiLCJnaXZlbl9uYW1lIjoiSmFtZXMiLCJmYW1pbHlfbmFtZSI6IkNhcm1pY2hhZWwsIFAuRS4sIFBNUCIsImxvY2FsZSI6ImVuIiwiaWF0IjoxNzA3Njg2NzQwLCJleHAiOjE3MDc2OTAzNDAsImp0aSI6IjJiNDc5ZjUzMTVhYmQ5OWY5M2MwYzA2MDRkNDBjMDEwOTEwZTc4MTYifQ.VwJ9GOAKS61CVa7lbrQ5PmEKef1ODIbdn4UKuTdi5bMB72L9LKHsc5GyHuDOEv7fV2tRF0XReg_xaxNHl-5dh2oTAJq4QnrfhVVvQNnMdpmPl85ewWjM39QEjtFrcS2T9BZ2pEPgvXKL_wW7gimhbDBTIr8o_rOE8sGh0rpDGZaof6dWte-I62UJX-TR6COAYLi9_LRGLjMRodoNS4sorsyowVkJzJtpjXqQwCZD1fNpPv5VrXiLoxpA_7ZRuJYoHo-YvwK-cE1qTKLP3rthEEUzBZbrWDpdNmgSw1icbd34k4QenSxddgEYKN2UlVBnCZDtA7PwVi9zl-mQP2YAlA
what is the computational complexity(space and time) of the autoencoder in training and testing?
Hi Geo…The computational complexity of an **autoencoder** during **training** and **testing** depends on several factors, including the size of the input data, the structure of the neural network, and the chosen optimization algorithm. Here’s an analysis of the **time** and **space complexity**:
—
### **1. Training Complexity**
#### **Time Complexity**
The time complexity of training an autoencoder is primarily determined by the following factors:
– **Number of layers and neurons:** Denote \( L \) as the number of layers, \( n_i \) as the number of neurons in layer \( i \), and \( d \) as the input dimensionality.
– **Forward Pass:** The time complexity of a single forward pass through the autoencoder is \( O(\text{total weights}) \). For \( L \)-layer autoencoders:
\[
O\left(\sum_{i=1}^{L-1} n_i \cdot n_{i+1}\right)
\]
– **Backward Pass (Gradient Computation):** For each parameter (weights and biases), the gradient is computed, and this doubles the computation:
\[
O\left(\sum_{i=1}^{L-1} n_i \cdot n_{i+1}\right)
\]
Hence, the time complexity of one full forward and backward pass is:
\[
O\left(2 \cdot \sum_{i=1}^{L-1} n_i \cdot n_{i+1}\right)
\]
– **Training Iterations:** For \( t \) training iterations on a dataset of size \( m \):
\[
O\left(t \cdot m \cdot \sum_{i=1}^{L-1} n_i \cdot n_{i+1}\right)
\]
—
#### **Space Complexity**
– **Weights and Biases:** Requires space to store the weights and biases for each layer:
\[
O\left(\sum_{i=1}^{L-1} n_i \cdot n_{i+1}\right)
\]
– **Activations:** Requires space for the activations of all layers during the forward pass:
\[
O\left(\sum_{i=1}^{L} n_i\right)
\]
– **Gradients:** Space to store gradients for backpropagation:
\[
O\left(\sum_{i=1}^{L-1} n_i \cdot n_{i+1}\right)
\]
– **Total Space:** Combining these, the total space complexity is:
\[
O\left(\sum_{i=1}^{L-1} n_i \cdot n_{i+1} + \sum_{i=1}^{L} n_i\right)
\]
—
### **2. Testing Complexity**
#### **Time Complexity**
During testing, only the forward pass is required:
– For a single input, the complexity is:
\[
O\left(\sum_{i=1}^{L-1} n_i \cdot n_{i+1}\right)
\]
– For \( m \) test samples, it becomes:
\[
O\left(m \cdot \sum_{i=1}^{L-1} n_i \cdot n_{i+1}\right)
\]
#### **Space Complexity**
– Only space for weights, biases, and layer activations is needed:
\[
O\left(\sum_{i=1}^{L-1} n_i \cdot n_{i+1} + \sum_{i=1}^{L} n_i\right)
\]
—
### **Key Factors Affecting Complexity**
1. **Input Dimensionality (\( d \))**: High-dimensional data increases the computational load.
2. **Latent Space Size (\( h \))**: The size of the encoding influences training/testing costs.
3. **Batch Size (\( b \))**: Training is often performed in mini-batches, affecting time complexity.
4. **Network Depth and Width:** Deeper and wider networks increase weights and computational cost.
—
### **Example**
For a simple autoencoder with:
– Input size \( d \),
– Hidden layer size \( h \),
– Dataset size \( m \),
– Training epochs \( t \),
**Training Complexity:**
\[
O\left(t \cdot m \cdot (d \cdot h + h^2)\right)
\]
**Testing Complexity:**
\[
O\left(m \cdot (d \cdot h + h^2)\right)
\]
Space requirements are similarly dependent on \( d \), \( h \), and the number of layers.
—
Where is the dataset to use with the example? I coudn’t find
Hi Desy…The code provided builds the sample dataset.