Generative Adversarial Networks, or GANs, are deep learning architecture generative models that have seen wide success.
There are thousands of papers on GANs and many hundreds of named-GANs, that is, models with a defined name that often includes “GAN“, such as DCGAN, as opposed to a minor extension to the method. Given the vast size of the GAN literature and number of models, it can be, at the very least, confusing and frustrating as to know what GAN models to focus on.
In this post, you will discover the Generative Adversarial Network models that you need to know to establish a useful and productive foundation in the field.
After reading this post, you will know:
- The foundation GAN models that provide the basis for the field of study.
- The extension GAN models that build upon what works and lead the way for more advanced models.
- The advanced GAN models that push the limits of the architecture and achieve impressive results.
Kick-start your project with my new book Generative Adversarial Networks with Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

A Tour of Generative Adversarial Network Models and Extensions
Photo by Tomek Niedzwiedz, some rights reserved.
Overview
This tutorial is divided into three parts; they are:
- Foundation
- Generative Adversarial Network (GAN)
- Deep Convolutional Generative Adversarial Network (DCGAN)
- Extensions
- Conditional Generative Adversarial Network (cGAN)
- Information Maximizing Generative Adversarial Network (InfoGAN)
- Auxiliary Classifier Generative Adversarial Network (AC-GAN)
- Stacked Generative Adversarial Network (StackGAN)
- Context Encoders
- Pix2Pix
- Advanced
- Wasserstein Generative Adversarial Network (WGAN)
- Cycle-Consistent Generative Adversarial Network (CycleGAN)
- Progressive Growing Generative Adversarial Network (Progressive GAN)
- Style-Based Generative Adversarial Network (StyleGAN)
- Big Generative Adversarial Network (BigGAN)
Foundation Generative Adversarial Networks
This section summarizes the foundational GAN models from which most, if not all, other GANs build upon.
Generative Adversarial Network (GAN)
The Generative Adversarial Network architecture and first empirical demonstration of the approach was described in the 2014 paper by Ian Goodfellow, et al. titled “Generative Adversarial Networks.”
The paper describes the architecture succinctly involving a generator model that takes as input points from a latent space and generates an image, and a discriminator model that classifies images as either real (from the dataset) or fake (output by the generator).
We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that a sample came from the training data rather than G. The training procedure for G is to maximize the probability of D making a mistake.
— Generative Adversarial Networks, 2014.
The models are comprised of fully connected layers (MLPs) with ReLU activations in the generator and maxout activations in the discriminator and was applied to standard image datasets such as MNIST and CIFAR-10.
We trained adversarial nets as a range of datasets including MNIST, the Toronto Face Database (TFD), and CIFAR-10. The generator nets used a mixture of rectifier linear activations and sigmoid activations, while the discriminator net used maxout activations. Dropout was applied in training the discriminator net.
— Generative Adversarial Networks, 2014.
Deep Convolutional Generative Adversarial Network (DCGAN)
The deep convolutional generative adversarial network, or DCGAN for short, is an extension of the GAN architecture for using deep convolutional neural networks for both the generator and discriminator models and configurations for the models and training that result in the stable training of a generator model.
We introduce a class of CNNs called deep convolutional generative adversarial networks (DCGANs), that have certain architectural constraints, and demonstrate that they are a strong candidate for unsupervised learning.
— Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
The DCGAN is important because it suggested the constraints on the model required to effectively develop high-quality generator models in practice. This architecture, in turn, provided the basis for the rapid development of a large number of GAN extensions and applications.
We propose and evaluate a set of constraints on the architectural topology of Convolutional GANs that make them stable to train in most settings.
— Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
Want to Develop GANs from Scratch?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Generative Adversarial Network Extensions
This section summarizes named GAN models that provide some of the more common or widely used discrete extensions to the GAN model architecture or training process.
Conditional Generative Adversarial Network (cGAN)
The conditional generative adversarial network, or cGAN for short, is an extension to the GAN architecture that makes use of information in addition to the image as input both to the generator and the discriminator models. For example, if class labels are available, they can be used as input.
Generative adversarial nets can be extended to a conditional model if both the generator and discriminator are conditioned on some extra information y. y could be any kind of auxiliary information, such as class labels or data from other modalities. We can perform the conditioning by feeding y into the both the discriminator and generator as additional input layer.
— Conditional Generative Adversarial Nets, 2014.
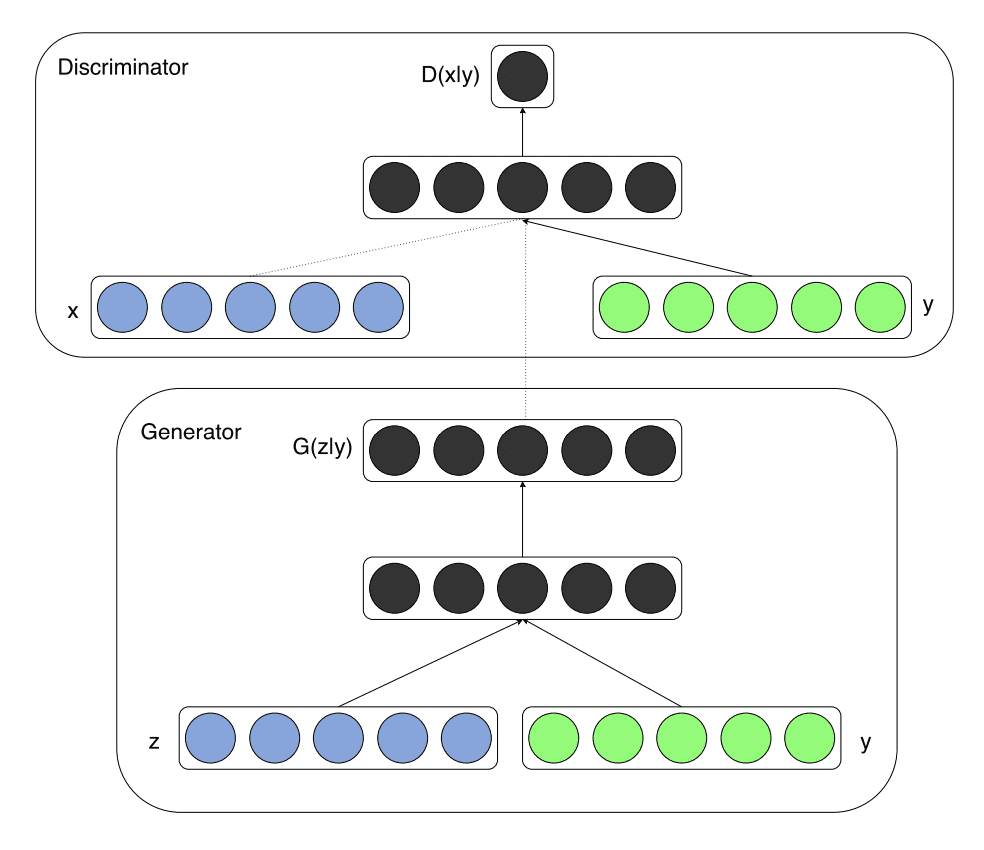
Example of the Model Architecture for a Conditional Generative Adversarial Network (cGAN).
Taken from: Conditional Generative Adversarial Nets.
Information Maximzing Generative Adversarial Network (InfoGAN)
The info generative adversarial network, or InfoGAN for short, is an extension to the GAN that attempts to structure the input or latent space for the generator. Specifically, the goal is to add specific semantic meaning to the variables in the latent space.
… , when generating images from the MNIST dataset, it would be ideal if the model automatically chose to allocate a discrete random variable to represent the numerical identity of the digit (0-9), and chose to have two additional continuous variables that represent the digit’s angle and thickness of the digit’s stroke.
— InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets, 2016.
This is achieved by separating points in the latent space into both noise and latent codes. The latent codes are then used to condition or control specific semantic properties in the generated image.
… rather than using a single unstructured noise vector, we propose to decompose the input noise vector into two parts: (i) z, which is treated as source of incompressible noise; (ii) c, which we will call the latent code and will target the salient structured semantic features of the data distribution
— InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets, 2016.

Example of Using Latent Codes to vary Features in Generated Handwritten Digits With an InfoGAN.
Taken from: InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets.
Auxiliary Classifier Generative Adversarial Network (AC-GAN)
The auxiliary classifier generative adversarial network, or AC-GAN, is an extension to the GAN that both changes the generator to be class conditional as with the cGAN, and adds an additional or auxiliary model to the discriminator that is trained to reconstruct the class label.
… we introduce a model that combines both strategies for leveraging side information. That is, the model proposed below is class conditional, but with an auxiliary decoder that is tasked with reconstructing class labels.
— Conditional Image Synthesis With Auxiliary Classifier GANs, 2016.
This architecture means that the discriminator both predicts the likelihood of the image given the class label and the class label given the image.
The discriminator gives both a probability distribution over sources and a probability distribution over the class labels, P(S | X), P(C | X) = D(X).
— Conditional Image Synthesis With Auxiliary Classifier GANs, 2016.
Stacked Generative Adversarial Network (StackGAN)
The stacked generative adversarial network, or StackGAN, is an extension to the GAN to generate images from text using a hierarchical stack of conditional GAN models.
… we propose Stacked Generative Adversarial Networks (StackGAN) to generate 256×256 photo-realistic images conditioned on text descriptions.
— StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks, 2016.
The architecture is comprised of a series of text- and image-conditional GAN models. The first level generator (Stage-I GAN) is conditioned on text and generates a low-resolution image. The second level generator (Stage-II GaN) is conditioned both on the text and on the low-resolution image output by the first level and outputs a high-resolution image.
Low-resolution images are first generated by our Stage-I GAN. On the top of our Stage-I GAN, we stack Stage-II GAN to generate realistic high-resolution (e.g., 256×256) images conditioned on Stage-I results and text descriptions. By conditioning on the Stage-I result and the text again, Stage-II GAN learns to capture the text information that is omitted by Stage-I GAN and draws more details for the object
— StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks, 2016.
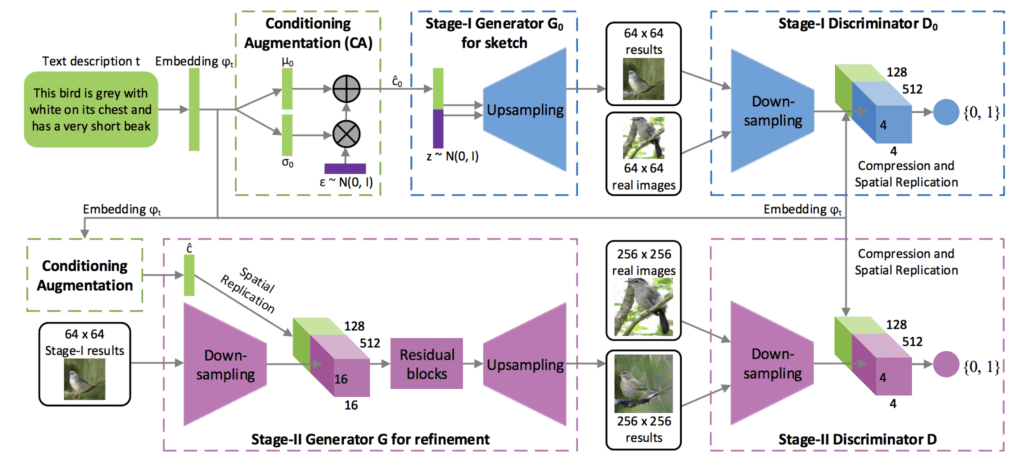
Example of the Architecture for the Stacked Generative Adversarial Network for Text to Image Generation.
Taken from: StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks.
Context Encoders
The Context Encoders model is an encoder-decoder model for conditional image generation trained using the adversarial approach devised for GANs. Although it is not referred to in the paper as a GAN model, it has many GAN features.
By analogy with auto-encoders, we propose Context Encoders – a convolutional neural network trained to generate the contents of an arbitrary image region conditioned on its surroundings.
— Context Encoders: Feature Learning by Inpainting, 2016.
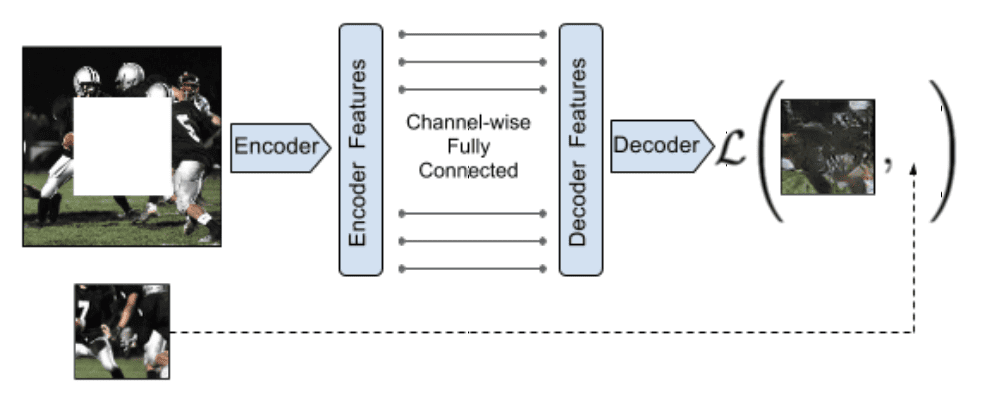
Example of the Context Encoders Encoder-Decoder Model Architecture.
Taken from: Context Encoders: Feature Learning by Inpainting
The model is trained with a joint-loss that combines both the adversarial loss of generator and discriminator models and the reconstruction loss that calculates the vector norm distance between the predicted and expected output image.
When training context encoders, we have experimented with both a standard pixel-wise reconstruction loss, as well as a reconstruction plus an adversarial loss. The latter produces much sharper results because it can better handle multiple modes in the output.
— Context Encoders: Feature Learning by Inpainting, 2016.
Pix2Pix
The pix2pix model is an extension of the GAN for image-conditional image generation, referred to as the task image-to-image translation. A U-Net model architecture is used in the generator model, and a PatchGAN model architecture is used as the discriminator model.
Our method also differs from the prior works in several architectural choices for the generator and discriminator. Unlike past work, for our generator we use a “U-Net”-based architecture, and for our discriminator we use a convolutional “PatchGAN” classifier, which only penalizes structure at the scale of image patches.
— Image-to-Image Translation with Conditional Adversarial Networks, 2016.
The loss for the generator model is updated to also include the vector distance from the target output image.
The discriminator’s job remains unchanged, but the generator is tasked to not only fool the discriminator but also to be near the ground truth output in an L2 sense. We also explore this option, using L1 distance rather than L2 as L1 encourages less blurring.
— Image-to-Image Translation with Conditional Adversarial Networks, 2016.
Advanced Generative Adversarial Networks
This section lists those GAN models that have recently led to surprising or impressive results, building upon prior GAN extensions.
These models mostly focus on developments that allow for the generation of large photorealistic images.
Wasserstein Generative Adversarial Network (WGAN)
The Wasserstein generative adversarial network, or WGAN for short, is an extension to the GAN that changes the training procedure to update the discriminator model, now called a critic, many more times than the generator model for each iteration.

Algorithm for the Wasserstein Generative Adversarial Network (WGAN).
Taken from: Wasserstein GAN.
The critic is updated to output a real-value (linear activation) instead of a binary prediction with a sigmoid activation, and the critic and generator models are both trained using “Wasserstein loss,” which is the average of the product of real and predicted values from the critic, designed to provide linear gradients that are useful for updating the model.
The discriminator learns very quickly to distinguish between fake and real, and as expected provides no reliable gradient information. The critic, however, can’t saturate, and converges to a linear function that gives remarkably clean gradients everywhere. The fact that we constrain the weights limits the possible growth of the function to be at most linear in different parts of the space, forcing the optimal critic to have this behaviour.
— Wasserstein GAN, 2017.
In addition, the weights of the critic model are clipped to keep them small, e.g. a bounding box of [-0.01. 0.01].
In order to have parameters w lie in a compact space, something simple we can do is clamp the weights to a fixed box (say W = [−0.01, 0.01]l ) after each gradient update.
— Wasserstein GAN, 2017.
Cycle-Consistent Generative Adversarial Network (CycleGAN)
The cycle-consistent generative adversarial network, or CycleGAN for short, is an extension to the GAN for image-to-image translation without paired image data. That means that examples of the target image are not required as is the case with conditional GANs, such as Pix2Pix.
… for many tasks, paired training data will not be available. We present an approach for learning to translate an image from a source domain X to a target domain Y in the absence of paired examples.
— Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, 2017.
Their approach seeks “cycle consistency” such that image translation from one domain to another is reversible, meaning it forms a consistent cycle of translation.
… we exploit the property that translation should be “cycle consistent”, in the sense that if we translate, e.g., a sentence from English to French, and then translate it back from French to English, we should arrive back at the original sentence
— Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, 2017.
This is achieved by having two generator models: one for translation X to Y and another for reconstructing X given Y. In turn, the architecture has two discriminator models.
… our model includes two mappings G : X -> Y and F : Y -> X. In addition, we introduce two adversarial discriminators DX and DY , where DX aims to distinguish between images {x} and translated images {F(y)}; in the same way, DY aims to discriminate between {y} and {G(x)}.
— Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, 2017.
Progressive Growing Generative Adversarial Network (Progressive GAN)
The progressive growing generative adversarial network, or Progressive GAN for short, is a change to the architecture and training of GAN models that involves progressively increasing the model depth during the training process.
The key idea is to grow both the generator and discriminator progressively: starting from a low resolution, we add new layers that model increasingly fine details as training progresses. This both speeds the training up and greatly stabilizes it, allowing us to produce images of unprecedented quality …
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
This is achieved by keeping the generator and discriminator symmetric in depth during training and adding layers step-wise, much like the greedy layer-wise pretraining technique in the early developing of deep neural networks, except weights in prior layers are not frozen.
We use generator and discriminator networks that are mirror images of each other and always grow in synchrony. All existing layers in both networks remain trainable throughout the training process. When new layers are added to the networks, we fade them in smoothly …
— Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
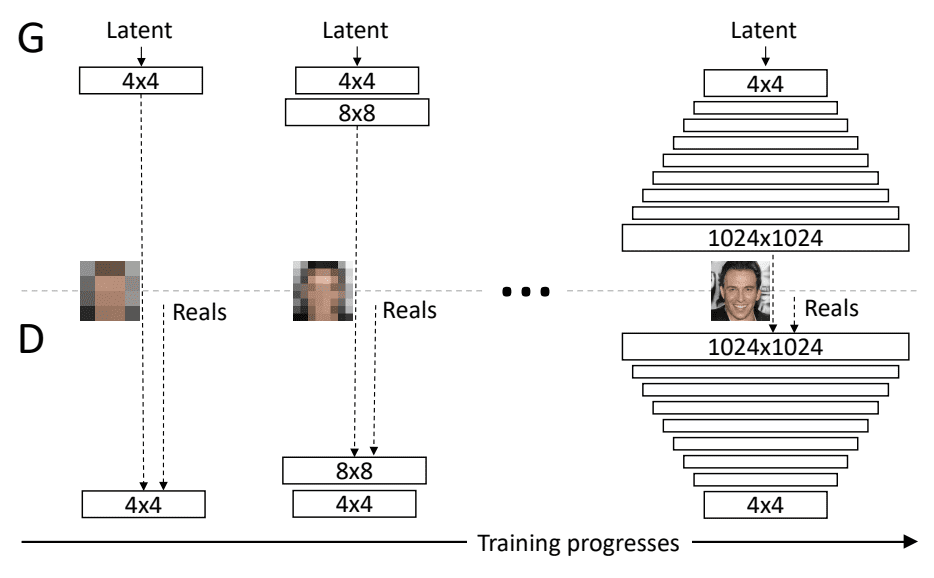
Example of the Progressive Growing of Generative Adversarial Networks During Training.
Taken from: Progressive Growing of GANs for Improved Quality, Stability, and Variation.
Big Generative Adversarial Network (BigGAN)
The big generative adversarial network, or BigGAN for short, is an approach that demonstrates how high-quality output images can be created by scaling up existing class-conditional GAN models.
We demonstrate that GANs benefit dramatically from scaling, and train models with two to four times as many parameters and eight times the batch size compared to prior art.
— Large Scale GAN Training for High Fidelity Natural Image Synthesis, 2018.
The model architecture is based on a collection of best practices across a wide range of GAN models and extensions. Further improvements are achieved through systematic experimentation.
A “truncation trick” is used where points are sampled from a truncated Gaussian latent space at generation time that is different from the untruncated distribution at training time.
Remarkably, our best results come from using a different latent distribution for sampling than was used in training. Taking a model trained with z ∼ N (0, I) and sampling z from a truncated normal (where values which fall outside a range are resampled to fall inside that range) immediately provides a boost
— Large Scale GAN Training for High Fidelity Natural Image Synthesis, 2018.
Style-Based Generative Adversarial Network (StyleGAN)
The style-based generative adversarial network, or StyleGAN for short, is an extension of the generator that allows the latent code to be used as input at different points of the model to control features of the generated image.
… we re-design the generator architecture in a way that exposes novel ways to control the image synthesis process. Our generator starts from a learned constant input and adjusts the “style” of the image at each convolution layer based on the latent code, therefore directly controlling the strength of image features at different scales.
— A Style-Based Generator Architecture for Generative Adversarial Networks, 2018.
Instead of taking the point in the latent space as input, the point is fed through a deep embedding network before being provided as input at multiple points in a generator model. In addition, noise is also added along with the output from the embedding network.
Traditionally the latent code is provided to the generator through an input layer […] We depart from this design by omitting the input layer altogether and starting from a learned constant instead. Given a latent code z in the input latent space Z, a non-linear mapping network f : Z -> W first produces w ∈ W.
— A Style-Based Generator Architecture for Generative Adversarial Networks, 2018.
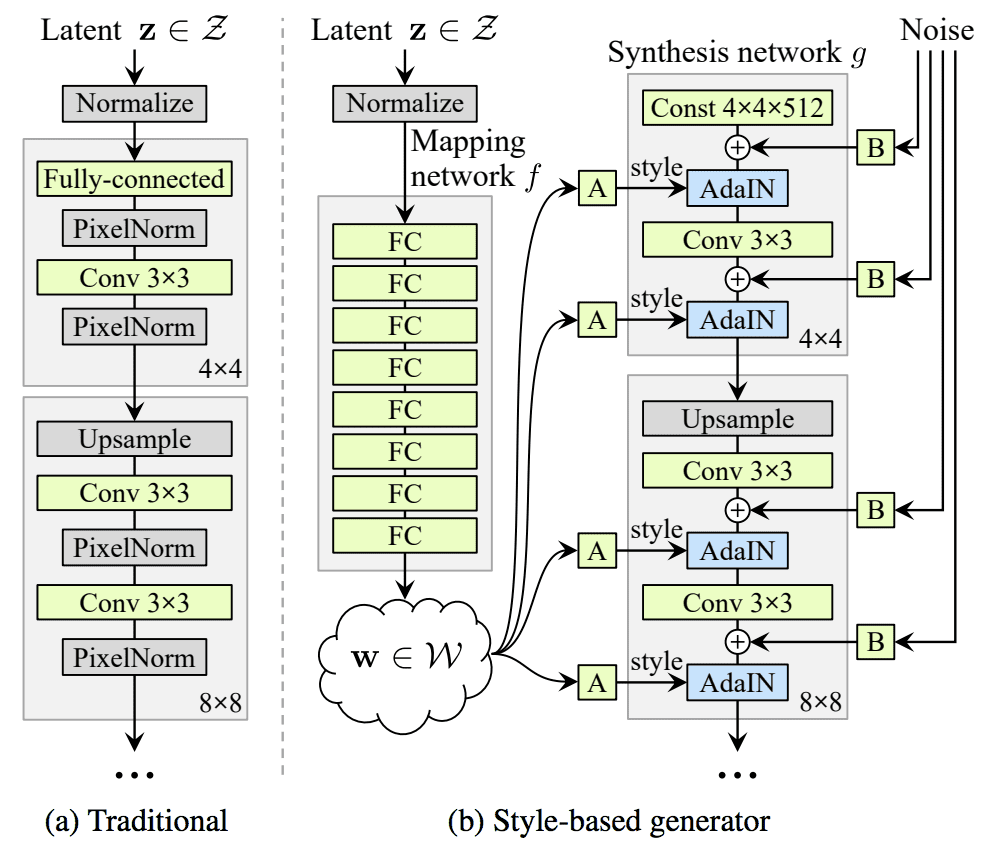
Example of the Traditional Generator Architecture Compared to the Style-Based Generator Model Architecture.
Taken from: A Style-Based Generator Architecture for Generative Adversarial Networks.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Foundation Papers
- Generative Adversarial Networks, 2014.
- Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
Extension Papers
- Conditional Generative Adversarial Nets, 2014.
- InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets, 2016.
- Conditional Image Synthesis With Auxiliary Classifier GANs, 2016.
- StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks, 2016.
- Context Encoders: Feature Learning by Inpainting, 2016.
- Image-to-Image Translation with Conditional Adversarial Networks, 2016.
Advanced Papers
- Wasserstein GAN, 2017.
- Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, 2017.
- Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
- A Style-Based Generator Architecture for Generative Adversarial Networks, 2018.
- Large Scale GAN Training for High Fidelity Natural Image Synthesis, 2018.
Articles
- Keras-GAN: Keras implementations of Generative Adversarial Networks.
- the-gan-zoo: A list of all named GANs!
Summary
In this post, you discovered the Generative Adversarial Network models that you need to know to establish a useful and productive foundation in the field
Specifically, you learned:
- The foundation GAN models that provide the basis for the field of study.
- The extension GAN models that build upon what works and lead the way for more advanced models.
- The advanced GAN models that push the limits of the architecture and achieve impressive results.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop Generative Adversarial Networks Today!

Develop Your GAN Models in Minutes
...with just a few lines of python codeDiscover how in my new Ebook:
Generative Adversarial Networks with Python
It provides self-study tutorials and end-to-end projects on:
DCGAN, conditional GANs, image translation, Pix2Pix, CycleGAN
and much more...




 in Keras")
 From Scratch")
Are you aware of any multi-label conditional GANs? I am looking for GANs that can work with a set of labels such as {‘nature’, ‘tree’, ‘park’} describing a picture. Not paired pictures; just images and their set of labels.
I have a tutorial on multi-class conditional GAN that could be adapted for multi-label:
https://machinelearningmastery.com/how-to-develop-a-conditional-generative-adversarial-network-from-scratch/
Hi,
first of all thank you for this amazing clarification between the different types of GAN.
I have a question left: Could you may tell me if CAN (Creative Adversarial Network) is also a different type of GAN or is it a separate category like NLP, GAN and now CAN?
I have read that it is a modification of GAN, but still can’t quite place it.
CAN is just a use case of GAN.
I see, thank u very much.
Sorry to bother you again: So CAN is not a model of GAN like StyleGAN?
I would consider that is a model under the GAN family.
Hi all these GANS talk about creating images while i have come across few in which they generate features and then use it for their classification task. Can you explain how is it different to create features in GANS as compared to generating images in GANS and which approach is best. Can you explain in context of multilabel classification.
Hi Abal….You may find the following interesting:
https://machinelearningmastery.com/impressive-applications-of-generative-adversarial-networks/
https://machinelearningmastery.com/books-on-generative-adversarial-networks-gans/
https://machinelearningmastery.com/resources-for-getting-started-with-generative-adversarial-networks/
Regards,