A Generative Adversarial Network, or GAN, is a type of neural network architecture for generative modeling.
Generative modeling involves using a model to generate new examples that plausibly come from an existing distribution of samples, such as generating new photographs that are similar but specifically different from a dataset of existing photographs.
A GAN is a generative model that is trained using two neural network models. One model is called the “generator” or “generative network” model that learns to generate new plausible samples. The other model is called the “discriminator” or “discriminative network” and learns to differentiate generated examples from real examples.
The two models are set up in a contest or a game (in a game theory sense) where the generator model seeks to fool the discriminator model, and the discriminator is provided with both examples of real and generated samples.
After training, the generative model can then be used to create new plausible samples on demand.
GANs have very specific use cases and it can be difficult to understand these use cases when getting started.
In this post, we will review a large number of interesting applications of GANs to help you develop an intuition for the types of problems where GANs can be used and useful. It’s not an exhaustive list, but it does contain many example uses of GANs that have been in the media.
We will divide these applications into the following areas:
- Generate Examples for Image Datasets
- Generate Photographs of Human Faces
- Generate Realistic Photographs
- Generate Cartoon Characters
- Image-to-Image Translation
- Text-to-Image Translation
- Semantic-Image-to-Photo Translation
- Face Frontal View Generation
- Generate New Human Poses
- Photos to Emojis
- Photograph Editing
- Face Aging
- Photo Blending
- Super Resolution
- Photo Inpainting
- Clothing Translation
- Video Prediction
- 3D Object Generation
Did I miss an interesting application of GANs or great paper on a specific GAN application?
Please let me know in the comments.
Kick-start your project with my new book Generative Adversarial Networks with Python, including step-by-step tutorials and the Python source code files for all examples.
Generate Examples for Image Datasets
Generating new plausible samples was the application described in the original paper by Ian Goodfellow, et al. in the 2014 paper “Generative Adversarial Networks” where GANs were used to generate new plausible examples for the MNIST handwritten digit dataset, the CIFAR-10 small object photograph dataset, and the Toronto Face Database.

Examples of GANs used to Generate New Plausible Examples for Image Datasets.Taken from Generative Adversarial Nets, 2014.
This was also the demonstration used in the important 2015 paper titled “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks” by Alec Radford, et al. called DCGAN that demonstrated how to train stable GANs at scale. They demonstrated models for generating new examples of bedrooms.

Example of GAN-Generated Photographs of Bedrooms.Taken from Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
Importantly, in this paper, they also demonstrated the ability to perform vector arithmetic with the input to the GANs (in the latent space) both with generated bedrooms and with generated faces.
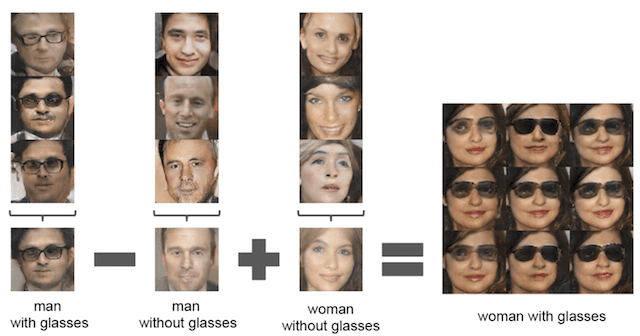
Example of Vector Arithmetic for GAN-Generated Faces.Taken from Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
Generate Photographs of Human Faces
Tero Karras, et al. in their 2017 paper titled “Progressive Growing of GANs for Improved Quality, Stability, and Variation” demonstrate the generation of plausible realistic photographs of human faces. They are so real looking, in fact, that it is fair to call the result remarkable. As such, the results received a lot of media attention. The face generations were trained on celebrity examples, meaning that there are elements of existing celebrities in the generated faces, making them seem familiar, but not quite.

Examples of Photorealistic GAN-Generated Faces.Taken from Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
Their methods were also used to demonstrate the generation of objects and scenes.

Example of Photorealistic GAN-Generated Objects and ScenesTaken from Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
Examples from this paper were used in a 2018 report titled “The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation” to demonstrate the rapid progress of GANs from 2014 to 2017 (found via this tweet by Ian Goodfellow).

Example of the Progression in the Capabilities of GANs from 2014 to 2017.Taken from The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation, 2018.
Want to Develop GANs from Scratch?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Generate Realistic Photographs
Andrew Brock, et al. in their 2018 paper titled “Large Scale GAN Training for High Fidelity Natural Image Synthesis” demonstrate the generation of synthetic photographs with their technique BigGAN that are practically indistinguishable from real photographs.

Example of Realistic Synthetic Photographs Generated with BigGANTaken from Large Scale GAN Training for High Fidelity Natural Image Synthesis, 2018.
Generate Cartoon Characters
Yanghua Jin, et al. in their 2017 paper titled “Towards the Automatic Anime Characters Creation with Generative Adversarial Networks” demonstrate the training and use of a GAN for generating faces of anime characters (i.e. Japanese comic book characters).

Example of GAN-Generated Anime Character Faces.Taken from Towards the Automatic Anime Characters Creation with Generative Adversarial Networks, 2017.
Inspired by the anime examples, a number of people have tried to generate Pokemon characters, such as the pokeGAN project and the Generate Pokemon with DCGAN project, with limited success.

Example of GAN-Generated Pokemon Characters.Taken from the pokeGAN project.
Image-to-Image Translation
This is a bit of a catch-all task, for those papers that present GANs that can do many image translation tasks.
Phillip Isola, et al. in their 2016 paper titled “Image-to-Image Translation with Conditional Adversarial Networks” demonstrate GANs, specifically their pix2pix approach for many image-to-image translation tasks.
Examples include translation tasks such as:
- Translation of semantic images to photographs of cityscapes and buildings.
- Translation of satellite photographs to Google Maps.
- Translation of photos from day to night.
- Translation of black and white photographs to color.
- Translation of sketches to color photographs.

Example of Photographs of Daytime Cityscapes to Nighttime With pix2pix.Taken from Image-to-Image Translation with Conditional Adversarial Networks, 2016.

Example of Sketches to Color Photographs With pix2pix.Taken from Image-to-Image Translation with Conditional Adversarial Networks, 2016.
Jun-Yan Zhu in their 2017 paper titled “Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks” introduce their famous CycleGAN and a suite of very impressive image-to-image translation examples.
The example below demonstrates four image translation cases:
- Translation from photograph to artistic painting style.
- Translation of horse to zebra.
- Translation of photograph from summer to winter.
- Translation of satellite photograph to Google Maps view.

Example of Four Image-to-Image Translations Performed With CycleGANTaken from Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, 2017.
The paper also provides many other examples, such as:
- Translation of painting to photograph.
- Translation of sketch to photograph.
- Translation of apples to oranges.
- Translation of photograph to artistic painting.

Example of Translation from Paintings to Photographs With CycleGAN.Taken from Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, 2017.
Text-to-Image Translation (text2image)
Han Zhang, et al. in their 2016 paper titled “StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks” demonstrate the use of GANs, specifically their StackGAN to generate realistic looking photographs from textual descriptions of simple objects like birds and flowers.

Example of Textual Descriptions and GAN-Generated Photographs of BirdsTaken from StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks, 2016.
Scott Reed, et al. in their 2016 paper titled “Generative Adversarial Text to Image Synthesis” also provide an early example of text to image generation of small objects and scenes including birds, flowers, and more.

Example of Textual Descriptions and GAN-Generated Photographs of Birds and Flowers.Taken from Generative Adversarial Text to Image Synthesis.
Ayushman Dash, et al. provide more examples on seemingly the same dataset in their 2017 paper titled “TAC-GAN – Text Conditioned Auxiliary Classifier Generative Adversarial Network“.
Scott Reed, et al. in their 2016 paper titled “Learning What and Where to Draw” expand upon this capability and use GANs to both generate images from text and use bounding boxes and key points as hints as to where to draw a described object, like a bird.
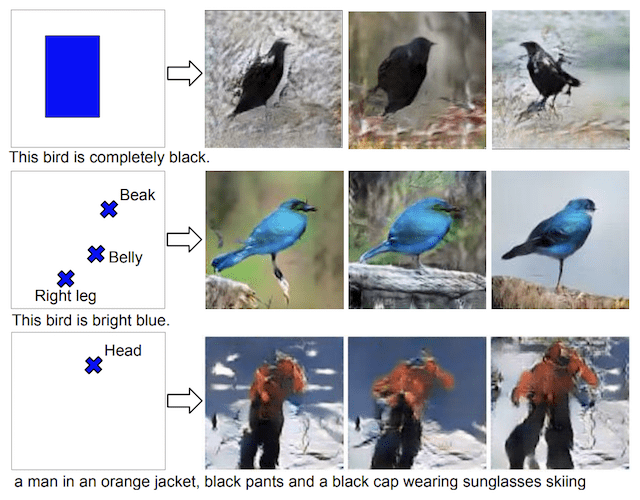
Example of Photos of Object Generated From Text and Position Hints With a GAN.Taken from Learning What and Where to Draw, 2016.
Semantic-Image-to-Photo Translation
Ting-Chun Wang, et al. in their 2017 paper titled “High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs” demonstrate the use of conditional GANs to generate photorealistic images given a semantic image or sketch as input.

Example of Semantic Image and GAN-Generated Cityscape Photograph.Taken from High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs, 2017.
Specific examples included:
- Cityscape photograph, given semantic image.
- Bedroom photograph, given semantic image.
- Human face photograph, given semantic image.
- Human face photograph, given sketch.
They also demonstrate an interactive editor for manipulating the generated image.
Face Frontal View Generation
Rui Huang, et al. in their 2017 paper titled “Beyond Face Rotation: Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal View Synthesis” demonstrate the use of GANs for generating frontal-view (i.e. face on) photographs of human faces given photographs taken at an angle. The idea is that the generated front-on photos can then be used as input to a face verification or face identification system.

Example of GAN-based Face Frontal View Photo GenerationTaken from Beyond Face Rotation: Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal View Synthesis, 2017.
Generate New Human Poses
Liqian Ma, et al. in their 2017 paper titled “Pose Guided Person Image Generation” provide an example of generating new photographs of human models with new poses.

Example of GAN-Generated Photographs of Human PosesTaken from Pose Guided Person Image Generation, 2017.
Photos to Emojis
Yaniv Taigman, et al. in their 2016 paper titled “Unsupervised Cross-Domain Image Generation” used a GAN to translate images from one domain to another, including from street numbers to MNIST handwritten digits, and from photographs of celebrities to what they call emojis or small cartoon faces.

Example of Celebrity Photographs and GAN-Generated Emojis.Taken from Unsupervised Cross-Domain Image Generation, 2016.
Photograph Editing
Guim Perarnau, et al. in their 2016 paper titled “Invertible Conditional GANs For Image Editing” use a GAN, specifically their IcGAN, to reconstruct photographs of faces with specific specified features, such as changes in hair color, style, facial expression, and even gender.
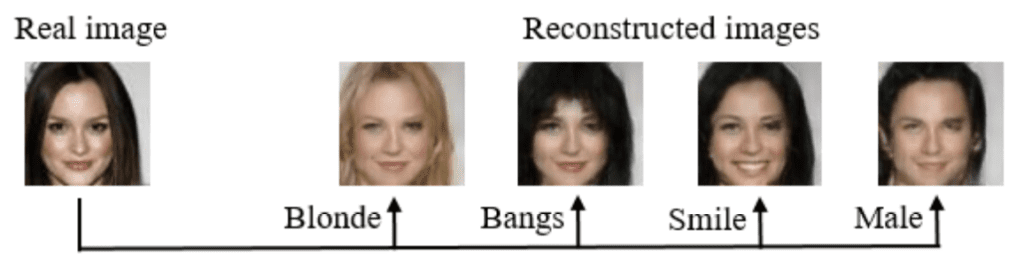
Example of Face Photo Editing with IcGAN.Taken from Invertible Conditional GANs For Image Editing, 2016.
Ming-Yu Liu, et al. in their 2016 paper titled “Coupled Generative Adversarial Networks” also explore the generation of faces with specific properties such as hair color, facial expression, and glasses. They also explore the generation of other images, such as scenes with varied color and depth.

Example of GANs used to Generate Faces With and Without Blond Hair.Taken from Coupled Generative Adversarial Networks, 2016.
Andrew Brock, et al. in their 2016 paper titled “Neural Photo Editing with Introspective Adversarial Networks” present a face photo editor using a hybrid of variational autoencoders and GANs. The editor allows rapid realistic modification of human faces including changing hair color, hairstyles, facial expression, poses, and adding facial hair.
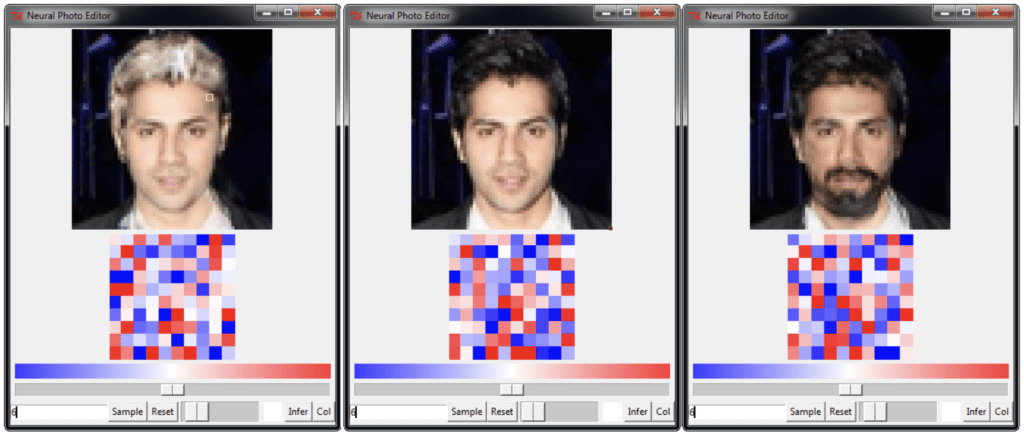
Example of Face Editing Using the Neural Photo Editor Based on VAEs and GANs.Taken from Neural Photo Editing with Introspective Adversarial Networks, 2016.
He Zhang, et al. in their 2017 paper titled “Image De-raining Using a Conditional Generative Adversarial Network” use GANs for image editing, including examples such as removing rain and snow from photographs.

Example of Using a GAN to Remove Rain From PhotographsTaken from Image De-raining Using a Conditional Generative Adversarial Network
Face Aging
Grigory Antipov, et al. in their 2017 paper titled “Face Aging With Conditional Generative Adversarial Networks” use GANs to generate photographs of faces with different apparent ages, from younger to older.

Example of Photographs of Faces Generated With a GAN With Different Apparent Ages.Taken from Face Aging With Conditional Generative Adversarial Networks, 2017.
Zhifei Zhang, in their 2017 paper titled “Age Progression/Regression by Conditional Adversarial Autoencoder” use a GAN based method for de-aging photographs of faces.

Example of Using a GAN to Age Photographs of FacesTaken from Age Progression/Regression by Conditional Adversarial Autoencoder, 2017.
Photo Blending
Huikai Wu, et al. in their 2017 paper titled “GP-GAN: Towards Realistic High-Resolution Image Blending” demonstrate the use of GANs in blending photographs, specifically elements from different photographs such as fields, mountains, and other large structures.

Example of GAN-based Photograph Blending.Taken from GP-GAN: Towards Realistic High-Resolution Image Blending, 2017.
Super Resolution
Christian Ledig, et al. in their 2016 paper titled “Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network” demonstrate the use of GANs, specifically their SRGAN model, to generate output images with higher, sometimes much higher, pixel resolution.

Example of GAN-Generated Images With Super Resolution. Taken from Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, 2016.
Huang Bin, et al. in their 2017 paper tilted “High-Quality Face Image SR Using Conditional Generative Adversarial Networks” use GANs for creating versions of photographs of human faces.

Example of High-Resolution Generated Human FacesTaken from High-Quality Face Image SR Using Conditional Generative Adversarial Networks, 2017.
Subeesh Vasu, et al. in their 2018 paper tilted “Analyzing Perception-Distortion Tradeoff using Enhanced Perceptual Super-resolution Network” provide an example of GANs for creating high-resolution photographs, focusing on street scenes.

Example of High-Resolution GAN-Generated Photographs of Buildings.Taken from Analyzing Perception-Distortion Tradeoff using Enhanced Perceptual Super-resolution Network, 2018.
Photo Inpainting
Deepak Pathak, et al. in their 2016 paper titled “Context Encoders: Feature Learning by Inpainting” describe the use of GANs, specifically Context Encoders, to perform photograph inpainting or hole filling, that is filling in an area of a photograph that was removed for some reason.

Example of GAN-Generated Photograph Inpainting Using Context Encoders.Taken from Context Encoders: Feature Learning by Inpainting describe the use of GANs, specifically Context Encoders, 2016.
Raymond A. Yeh, et al. in their 2016 paper titled “Semantic Image Inpainting with Deep Generative Models” use GANs to fill in and repair intentionally damaged photographs of human faces.

Example of GAN-based Inpainting of Photographs of Human FacesTaken from Semantic Image Inpainting with Deep Generative Models, 2016.
Yijun Li, et al. in their 2017 paper titled “Generative Face Completion” also use GANs for inpainting and reconstructing damaged photographs of human faces.

Example of GAN Reconstructed Photographs of FacesTaken from Generative Face Completion, 2017.
Clothing Translation
Donggeun Yoo, et al. in their 2016 paper titled “Pixel-Level Domain Transfer” demonstrate the use of GANs to generate photographs of clothing as may be seen in a catalog or online store, based on photographs of models wearing the clothing.

Example of Input Photographs and GAN-Generated Clothing PhotographsTaken from Pixel-Level Domain Transfer, 2016.
Video Prediction
Carl Vondrick, et al. in their 2016 paper titled “Generating Videos with Scene Dynamics” describe the use of GANs for video prediction, specifically predicting up to a second of video frames with success, mainly for static elements of the scene.

Example of Video Frames Generated With a GAN.Taken from Generating Videos with Scene Dynamics, 2016.
3D Object Generation
Jiajun Wu, et al. in their 2016 paper titled “Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling” demonstrate a GAN for generating new three-dimensional objects (e.g. 3D models) such as chairs, cars, sofas, and tables.

Example of GAN-Generated Three Dimensional Objects.Taken from Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling
Matheus Gadelha, et al. in their 2016 paper titled “3D Shape Induction from 2D Views of Multiple Objects” use GANs to generate three-dimensional models given two-dimensional pictures of objects from multiple perspectives.

Example of Three-Dimensional Reconstructions of a Chair From Two-Dimensional Images.Taken from 3D Shape Induction from 2D Views of Multiple Objects, 2016.
Further Reading
This section provides more lists of GAN applications to complement this list.
- gans-awesome-applications: Curated list of awesome GAN applications and demo.
- Some cool applications of GANs, 2018.
- GANs beyond generation: 7 alternative use cases, 2018.
Summary
In this post, you discovered a large number of applications of Generative Adversarial Networks, or GANs.
Did I miss an interesting application of GANs or a great paper on specific GAN application?
Please let me know in the comments.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop Generative Adversarial Networks Today!

Develop Your GAN Models in Minutes
...with just a few lines of python codeDiscover how in my new Ebook:
Generative Adversarial Networks with Python
It provides self-study tutorials and end-to-end projects on:
DCGAN, conditional GANs, image translation, Pix2Pix, CycleGAN
and much more...
")
")



")
Really nice overview. Thanks Jason
Thanks!
They say a picture is worth a 1000 words and I say a great article like this is worth a 1000 book. Thanks Jason.
Thanks, I’m glad it helps to shed some light on what GANs can do.
uh, I like the Photos to Emojis application. any code sharing ?
Yes, I hope to have many exampels soon.
Hi Jason,
I have taken your course bundles ,
Could you share some good resources or code examples of gan, I would like to do some practice
Yes, I am working on a book on GANs at the moment.
Please let me know when finished 🙂
I will!
This article is awesome thank you ssso much
You’re welcome.
Do you have plan to post some tutorials about Autoencode?
I may in the future, what do you want to know about autoencoders exactly? E.g. do you mean VAEs?
Hello! Jason. I really love your article on GANs. I was wondering if you could help with any current research areas on GANs. I am a masters student and would like to write my thesis on GANs. Thank you
This is a common question that I answer here:
https://machinelearningmastery.com/faq/single-faq/what-research-topic-should-i-work-on
Thank you very impressive!!!
Thanks.
Hello. Really nice to see so many cool application to GANs.
Can you please elaborate on photos to emoji…Domain transfer Network!!
Thanks for the suggestion.
Jason, this is great. I am an analyst in the retail technology space currently writing a piece on the potential for GANs. Any chance to connect? (my email address provided)
Thanks.
You can contact me any time directly here:
https://machinelearningmastery.com/contact/
Hi Jason,
Is there a book for GANs coming soon?
Yes, I hope to release it in a week or two.
Nice post Jason as always. Since gathering feedback labels from a deployed model is expensive. Can GANs be used to create new ‘feedbacks’, based on a few real samples, to update a ML model in production?. Considering just numerical features, not images.
Yes – GANs can be used as a type of data augmentation – to hallucinate new plausible examples from the target domain.
Has anyone put GAN to good use other than just playing around with and also please make a tutorial series around Productionizing models (including GAN because I searched all over internet and no one teaches how GANs can be put to production)
I have seen/read about fit GAN models integrated into image processing apps for desktop and some for mobile.
Great suggestion, thanks.
Is book released?
Yes, thanks for asking:
https://machinelearningmastery.com/generative_adversarial_networks/
Hi Jason, excellent post, are you also planning the write the Python implementations of the above use cases, it would be really very helpful for us.
Thanks.
I cover many of the examples, you can gets started here:
https://machinelearningmastery.com/start-here/#gans
Hi jason , thank you very much
my field is telecomm. i’m searching for good applications in biomedical and telecommunications
do you have any suggestions ?
Perhaps search on scholar.google.com
Hi Jason,
Is there currently any application for GAN on NLP?
Cheers,
Adam
Good question.
I’m sure there are people working on it, I’m not across it sorry.
The main unsupervised methods in NLP are language models – that will effectively achieve what you would expect a GAN would in the same domain – generating sequences of words. You can get started with language models here:
https://machinelearningmastery.com/start-here/#nlp
I beg to disagree, Jason – NLP are example of supervised and/or self-supervised models. They are based on self-attention mechanism from 2017’s OpenAI paper (Vaswani et al.).
Yes, I know I’m writing this in 2024 😉 but I’m currently writing a paper of generative AI developments and wherever I research, most authors say NLP is not trained an unsupervised learning. Unless I’m missing something obvious.
Hi Moni…Natural Language Processing (NLP) encompasses a wide range of techniques and methodologies for enabling computers to understand and process human (natural) languages. It can involve both supervised and unsupervised learning, as well as other approaches.
– **Supervised Learning in NLP**: Many NLP tasks use supervised learning, where a model is trained on a labeled dataset. This means that the input data is accompanied by the correct output. Tasks like sentiment analysis, named entity recognition, and machine translation often use supervised learning techniques. For instance, in sentiment analysis, the model is trained on texts that are labeled with sentiments (e.g., positive, negative, neutral), and it learns to predict the sentiment of new, unseen texts.
– **Unsupervised Learning in NLP**: There are also NLP tasks that use unsupervised learning, where the model learns patterns from untagged data. Clustering and topic modeling are examples of unsupervised learning tasks in NLP. For example, in topic modeling, algorithms are used to discover the main topics that emerge from a large collection of documents, without any prior labeling of the documents.
– **Other Approaches**: Beyond supervised and unsupervised learning, NLP also makes use of semi-supervised learning (where the model learns from a combination of labeled and unlabeled data), reinforcement learning (where models learn to make decisions), and rule-based approaches (where explicit rules, rather than models derived from data, are used to process language).
Thus, NLP is not exclusively tied to supervised learning; it leverages a variety of machine learning and linguistic approaches depending on the specific task and available data.
Hi Jason,
Thanks for the nice overview!
I am wondering if there are any reserach on applications of GAN in Cybersecurity?
Cheers,
Maryam
There maybe, perhaps search on scholar.google.com
I am a undergrad student of third year I have to do a project with GAN i have an idea about how could it be implemented. The idea is “you input image of unstitched cloth and it output a stitch cloth or may be your picture wearing the cloth” please help me out
Yes, you can adapt one of the tutorial here for your project:
https://machinelearningmastery.com/start-here/#gans
Hi Midhat, the idea sounds interesting, did you manage to to do it. I am new to GANs.
cheers, Malko
Thanks for the article; i’m trying to understand the article, maybe can be use trading applications.
Best Regards;
Mehmet
I don’t know about trading, sorry.
Hi Jason, do you know some applications of GANs outside the field of computer Vision?
Thanks,
Mars
I believe people are using them in other domains such as time series, but I believe vision is the area of biggest success.
If one had a corpus of medical terminology, where sections of words (tokens?) would be reused, e.g., myocardiopathy and “myo” and “cardio” would be used in other new words, this seems a more well defined type of language. Would this be an appropriate or more possible “language” generation for an adversarial network? (sorry if the question doesn’t make sense, very new to this).
I imagine an input for a term (the new language) would be “muscle heart atrophy,” the corresponding term would be myocardiophathy for training. Then I’d want a new term generated (output) that corresponds to “muscle stomach pain.”
Thanks.
Perhaps a language model instead of a GAN:
https://machinelearningmastery.com/start-here/#nlp
I was wondering if you can name/discuss some non-photo-related applications.
Good suggestion, thanks.
Did you have something specific in mind?
Generally, I was thinking about different problems, but was not sure if I am able to map them to GAN problem.
For example, because GAN is a generative, I think of generating new photo/text based on given data (like most of the examples that are available online)
but, how about generating a random number? Is it possible to use GAN?
When I think about it, I am not sure how the discriminator will be.
Or is it possible to use GAN to find the next number in a series of patterned number?
e.g. 1, 3, 5, ?
That would be a sequence prediction model:
https://machinelearningmastery.com/start-here/#lstm
Or a time series forecasting model:
https://machinelearningmastery.com/start-here/#deep_learning_time_series
You can generate text using a language model, GANs are not needed:
https://machinelearningmastery.com/start-here/#nlp
You can generate random numbers directly:
https://machinelearningmastery.com/how-to-generate-random-numbers-in-python/
Thank you for the explanations and links. By random number I meant:
Suppose I pretend to have a sequence of random numbers (0s and 1s), I want to see if GAN can generate the next random number or not (to see whether the sequence is truly random or not).
Does not sound like a good use for a GAN.
There are statistical tests for randomness.
For the mentioned problem, I used NN, LSTM, SVM for the prediction, but I wanted to see if GAN can be used for those applications as well. Most of the applications I read/saw for GAN were photo-related.
I stumbled onto this article. I used to be a DB programmer many years ago, so I thought I would read about GANs. I find it interesting, but started thinking about how human interaction with what is generated might affect the outcome.
I also love art. Years ago, I found a program that generated random artistic shapes and colors and textures.. which I used as starting points for many of my digital art pieces. There were actually a few of these programs available at the time. One was called “Reptile”. I forget the name of the others.
Anyway, I would take these random number generated images and place them into Photoshop layers and adjust the transparency of the top layer to about 50% and rotate it until I “saw” something recognizable. I would then bring out what I saw using digital art tools that are included in Photoshop. I created a lot of artwork this way.
Here’s the amazing part. I never knew what I would “find”, but the images I found this way and refined into digital paintings, turned out to often be “predictive” in some way.. of things to come. I saw a martial arts master for instance and many years later, I got a job in a martial arts studio.. although I had no interest in martial arts at the time. I saw an herbalist with a basket full of fresh picked herbs.. and later became very interested in natural healing.
These are only a few of the predictive images I saw and refined into full blown pieces of art. So, I have to wonder if it is possible that what we call “random” may, in fact, be not so random after all. Is it possible that we (our human field of energy – beyond time & space?) somehow meld or cooperate or influence the generating that seems to be completely random? I can’t help but think of quantum physics and the “observer” effect.
Will GANs images be influenced by the intent or observation of the person observing the outcome? Is there really such a thing as “random”?
Thanks for sharing.
Not really, unless you can encode the feedback into the model.
Not so fast. Many studies have been done on influencing random number generators with good old intention and mental concentration. If you haven’t heard of Dean Radin then check him out. There is a statistically significant repeatable result in this area of legitimate research. That means these GANs are potentially more than tools but extensions of our mind. If they monitor our dopamine and we are the discriminator it won’t take long before our relationship with art changes radically. We will be so high it will be dangerous.
I cannot download the free mini-course. I have the message: safari can’t establish a secure connexion.
Sorry to hear that, you can access it here:
https://machinelearningmastery.com/how-to-get-started-with-generative-adversarial-networks-7-day-mini-course/
can image inpainting be used in computer vision images to construct and occluded or obstructed object in 3d images. e.g. pedestrian or bike behind a truck or car ?
Maybe. Perhaps check the literature?
Well, I started looking into the papers recently. I haven’t come across any good one yet.
I am particularly interested to generate LiDar image of objects which are partially occluded.
Thanks for the article.
I am trying to generate frame between two animation frame using AI technology like GAN .
unlike many other animations software do. Is it possible to do ? I have seen using styleGAN ,generated images attributes can be manipulated by Modifying the latent vector. Does it work for full body images like walking, running, standing pose.
Best Regards
Aminul
Perhaps. It depends on the data.
Maybe develop some prototypes for your domain and discover how effective the methods can be for you.
Thanks for your reply. Yes, I will try.
Is there any work to generate frame between two animation frame using AI technology ?
I expect so, it’s not my area of expertise sorry.
Thank you for the useful content.
Can GANs or Autoencoders be used for generating images from vector data or scalar inputs? For instance, if I know that for input vector [0,0,1] the output is a black cat, and for input [1,1.3,0] the output is a grey dog, and I have a dataset like this. Can we train a DL model to tell us what is the output for vector [1, 2, 3]?
In summary, can we generate images based on input vectors or scalar?
Have you seen this type of work?
Sure. That is how GANs work. Perhaps start here:
https://machinelearningmastery.com/start-here/#gans
Thanks. I have a lot to read now 🙂
Great!
Hey, great article! Well written and engaging. I learned a lot!
Only one thing, you may have failed to enunciate the GAN in music.
Thanks.
Thanks for the very useful article. The applications of GAN that are included here are really impressive. Apart from these, an important application of GAN is to generate synthetic data so that more data samples are obtained through data generation, this is an area I am currently working on. Would request you to include an example of synthetic data with GAN in any of your upcoming articles or write ups on GAN. Thanks
Thanks.
I would recommend image augmentation instead of GANs for that use case:
https://machinelearningmastery.com/how-to-configure-image-data-augmentation-when-training-deep-learning-neural-networks/
Hi, These topics are really interesting. I planning to do research for my Software Enginering degree on “Text-to-Image Translation” or “Photo inpainting”. I would like know how to proceed on learning on these topics related to GANs. If you could drop some sources where I could be able learn them, that would be really good. Thanks
Thanks.
Sounds like a fun project. Yes, GANs can be used for in-painting, perhaps for text-to-image – I’m not sure off the cuff.
You can search for papers on these topics here:
https://scholar.google.com/
Thanks,
Can I use GAN with Network data? Or it’s specifically used for the image.
Any link else.
GANs are designed for image data.
Thanks for replay,
I should stop the training step when loss_discriminator = loss_generator = 0.5 else can I use early stopping?
Hi, thank you for your help. I would like to ask you about using GAN with image classification
e.g. face recognition. Is that possible with GAN?
Yes, but GANs are for generating images, not for classifying images. At least in general.
There are GANs that can co-train a classification model. The output of GANs might also provide additional training data for a classification model. Although both of these cases will need a lot of evidence to prove they add value.
Hi Jason. I came across quite a few papers about face aging progression using GANs. Do you know which is the current state-of-the-art choice with widespread adoption?
No sorry, perhaps check the literature on scholar.google.com
Hi Jason, thanks for this information
I am wondering, can I use GAN to detect the fake faces?
I don’t think so, you would be better off developing a dedicated classification model.
This model depend on what? I mean, if you can suggest which suitable model can help me
Help you with what exactly?
I have tabular data and image data , I need to use tabular data and image data as input . and generate a set of image data as out put.
which
You can use a multi-input model, one input for image data and one for tabular, this will help:
https://machinelearningmastery.com/keras-functional-api-deep-learning/
Hello, is it possible to use the images and some of the arrangements you used for posting to organize and fill out in my study activities? (There’s no purpose for profit. I’ll write down the source)
https://machinelearningmastery.com/faq/single-faq/can-i-use-your-code-in-my-own-project/
Hi, as a content creator i would like to create a serie of randomly generated image characters … as im not a programmer and dont want to outsource so to retain full control of creative flow, is there any saas or software, service that allows me to achieve result for afee ? Pls help. Tx
Can’t think of anything like this available commercially, but if you’re asking for SaaS due to concerns about computation resources, then you can surely build your own model and host it on Amazon or other cloud providers.
I am looking for a gan that allows me to work with human bodies for artistic purposes, to make bodies strange. Obviously to better realize the shape of the body, it is necessary that they are naked. Do you have any GAN ideas that could help me do my job?
What did you tried?
you can add image outpainting (not inpainting) as other applications.
Hi Atomiciaz…Do you have any specific questions regarding the tutorial that we can address?
Regards,
Hello,
Are GAN’s are used for Generative Design in 3D Cad models to generate cad models like PTC Creo Generative Topology Optimization
Thanks.
Hi Bharath…While I cannot speak to that particular application, the following may be helpful:
https://machinelearningmastery.com/books-on-generative-adversarial-networks-gans/
https://machinelearningmastery.com/impressive-applications-of-generative-adversarial-networks/
Can GAN design used for log analysis?
Inputs can be error with actual logs.How can we distinguish it as a normal log and train the model
Hi Anna…We do not currently have such a tutorial related directly to that objective, however the following may be of interest:
https://machinelearningmastery.com/what-are-generative-adversarial-networks-gans/
Hi Jason,
Thank you so much for providing such an informative article. I am looking for a GAN variant which can synthesize both the new sample(one dimensional time-series waveforms or signals) and the associated sequence labels. Do you have any suggestions.
Thank you!
Hi Ryan…This type of GAN is known as a conditional GAN, where the generator is conditioned on a specific label or class information in addition to random noise.
Hi Jason,
Thank you so much for this informative article.
I am wondering if there is a kind of GAN that can be used to generate both the new samples (1 dimensional waveforms) and their corresponding sequence labels.
Any suggestions or ideas are highly appreciated!
Hi Ryan…That is a great question! Yes, a Generative Adversarial Network (GAN) can be used to generate both new samples and their corresponding sequence labels. This type of GAN is known as a conditional GAN, where the generator is conditioned on a specific label or class information in addition to random noise.
In the case of generating 1 dimensional waveforms and their corresponding sequence labels, the input to the generator would be a combination of noise and the desired label. The generator would then output a synthetic waveform and its corresponding label. The discriminator would receive both the synthetic waveform and its corresponding label, as well as real waveforms and their corresponding labels, and try to distinguish between them.
Training a conditional GAN to generate both the waveform and its corresponding label would require a large amount of labeled training data. The quality of the generated samples would also depend on the complexity of the data distribution and the effectiveness of the network architecture and training procedure.
Hi James,
Thank you so much for answering. I also have a following question.
Do you know if it is feasible to combine the conditional GAN and the infoGAN?
It seems the current GAN has their own advantage and I am wondering if there is a possibility that they can be combined as one which possess the advantages from both or all of them?
Thank you so much!
Ryan
Do GAN models play a role in traffic analysis or network anomaly detection? you may recall that threat actors generate fake traffic or perturb the traffic to deceive classifiers. What is your take on this?
Hi Isyaku…The following resource may be of interest:
https://www.atlantis-press.com/journals/ijcis/125954216/view
I am not a student.
Just retired with a lot of free time and I like technology.
The applications of Gans are many and interesting.
But why so few who deal with sounds or music?
Greece, Lesvos, Mytilini,
29/12/24
Hi kospod…It’s wonderful that you have the time and interest to explore technology, especially something as fascinating as GANs (Generative Adversarial Networks). You’re right—GANs have a multitude of applications, yet their use in sound and music has been comparatively less explored than in areas like image synthesis or video generation. There are several reasons for this disparity:
—
### 1. **Complexity of Audio Data**
– Audio signals are high-dimensional and continuous, which makes them more challenging to process than images, which are represented as 2D pixel arrays.
– Audio often has both time (temporal) and frequency (spectral) components that need to be modeled simultaneously, requiring more specialized architectures.
### 2. **Perceptual Quality Challenges**
– For images, the human visual system is relatively forgiving. However, the human ear is much more sensitive to irregularities in sound. This makes it harder to generate audio that is perceptually convincing.
– Evaluating the quality of generated audio is more subjective and less straightforward than evaluating visual content.
### 3. **Data Representation Issues**
– Audio can be represented in different ways: raw waveforms, spectrograms, or MIDI data. Each representation has its own set of challenges when used with GANs.
– For instance, raw waveforms require models to handle extremely long sequences, which can be computationally expensive.
### 4. **Lack of Large, Labeled Datasets**
– GANs are often data-hungry, and while there are many large datasets for images, audio datasets (especially for music) are less abundant and sometimes restricted due to copyright issues.
### 5. **Dominance of Other Models in Audio**
– In the audio domain, models like Recurrent Neural Networks (RNNs), Transformers, or WaveNet (autoregressive models) have been more successful and widely used for tasks like music generation and speech synthesis. These models sometimes overshadow GAN-based approaches.
—
### Promising Developments and Applications in Audio GANs
Despite these challenges, there have been some exciting advances in using GANs for audio:
1. **Speech Synthesis and Enhancement**
– GANs like WaveGAN and MelGAN are used to generate and refine high-quality speech from spectrograms or low-quality audio.
2. **Music Generation**
– Models like MuseGAN have been developed to create multi-instrument music compositions.
3. **Audio Style Transfer**
– GANs can transfer styles between audio tracks, similar to style transfer in images. For example, converting a piano track to sound like a violin.
4. **Sound Effects Generation**
– GANs are being used to generate realistic sound effects for games and movies.
5. **Voice Conversion**
– GANs can modify one person’s voice to sound like another’s or change the emotional tone of speech.
—
### Growing Interest
As computational power increases and audio-specific GAN architectures improve, we can expect more innovative applications in sound and music. If you’re interested in exploring this field, here are some ways to start:
– **Look into existing models like WaveGAN, MelGAN, and MuseGAN.**
– **Experiment with freely available datasets (e.g., MAESTRO for piano music or NSynth for musical notes).**
– **Consider exploring hybrid models that combine GANs with other architectures like RNNs or Transformers.**
The intersection of GANs and music is still a growing area, and it’s an exciting time to dive in!
Hello there,
Good work on all different applications of GANs.
Have you looked at generating tabular data for network packets/traffic something like NSL-KDD and what can be a good evaluation of synthetic data?
Hi Shalini…Yes, generating synthetic tabular data for network packets/traffic, similar to the **NSL-KDD dataset**, is a common practice in cybersecurity, network anomaly detection, and adversarial ML research. Here’s how you can approach this and evaluate the synthetic data:
—
### **1. Generating Synthetic Tabular Data for Network Traffic**
#### **Approaches:**
– **Rule-based Simulation**: Define rules based on real network patterns (e.g., normal vs. attack packets).
– **Statistical Sampling**: Fit a probability distribution to real data and sample new data.
– **Generative Models**:
– **GANs (e.g., CTGAN, Tabular GAN)**: Learn the distribution and generate synthetic records.
– **VAEs (Variational Autoencoders)**: Encode and decode data to create new synthetic samples.
– **Copulas**: Capture dependencies between variables and generate samples.
– **Traffic Replay Tools**:
– **Tcpreplay**: Reproduce network traffic from PCAP files.
– **Scapy (Python)**: Generate custom network packets.
—
### **2. Evaluating the Quality of Synthetic Data**
#### **Evaluation Criteria:**
1. **Statistical Similarity** (How well it mimics real data)
– **Feature Distribution Comparison**: KS Test, Wasserstein Distance, Jensen-Shannon Divergence.
– **Pairwise Correlations**: Compare covariance matrices.
– **PCA/UMAP Visualization**: Compare cluster separation in latent space.
2. **Machine Learning Utility** (How useful it is for training ML models)
– **Downstream Task Performance**: Train ML models (e.g., Random Forest, XGBoost, DNN) on synthetic data and test on real data.
– **TSTR (Train-Synthetic, Test-Real)**: Check if a model trained on synthetic data generalizes to real data.
3. **Privacy & Security** (If sensitive data is leaked)
– **Membership Inference Attack (MIA)**: Test if real samples can be distinguished from synthetic ones.
– **Attribute Disclosure Risk**: Measure if adversaries can infer missing real attributes.
4. **Diversity & Coverage** (How well it covers different scenarios)
– **Mode Collapse Check**: Ensure diverse attack patterns are generated.
– **Novelty Detection**: Compare synthetic samples to see if they introduce new attack variations.
—
### **Best Tools for Synthetic Data Generation & Evaluation**
– **SDV (Synthetic Data Vault)**: Provides statistical & ML-based synthetic data generation.
– **CTGAN, TVAE (Tabular Variational Autoencoder)**: Deep-learning-based synthetic data generation.
– **scikit-learn & scipy.stats**: Basic statistical modeling for synthetic sampling.
– **seaborn, matplotlib, pandas-profiling**: For visual evaluation of distributions.