Time series forecasting is a process, and the only way to get good forecasts is to practice this process.
In this tutorial, you will discover how to forecast the number of monthly armed robberies in Boston with Python.
Working through this tutorial will provide you with a framework for the steps and the tools for working through your own time series forecasting problems.
After completing this tutorial, you will know:
How to check your Python environment and carefully define a time series forecasting problem.
How to create a test harness for evaluating models, develop a baseline forecast, and better understand your problem with the tools of time series analysis.
How to develop an autoregressive integrated moving average model, save it to file, and later load it to make predictions for new time steps.
Kick-start your project with my new book Time Series Forecasting With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Updated Jul/2018: Fixed a typo in the preparation of the ACF/PACF plots (thanks Patrick Wolf).
Updated Apr/2019: Updated the link to dataset.
Updated Aug/2019: Updated data loading to use new API.
Updated Feb/2020: Updated to_csv() to remove warnings.
Updated Dec/2020: Updated modeling for changes to the API.
Time Series Forecast Case Study with Python – Monthly Armed Robberies in Boston Photo by Tim Sackton, some rights reserved.
Overview
In this tutorial, we will work through a time series forecasting project from end-to-end, from downloading the dataset and defining the problem to training a final model and making predictions.
This project is not exhaustive, but shows how you can get good results quickly by working through a time series forecasting problem systematically.
The steps of this project that we will work through are as follows:
Environment.
Problem Description.
Test Harness.
Persistence.
Data Analysis.
ARIMA Models
Model Validation
This will provide a template for working through a time series prediction problem that you can use on your own dataset.
Stop learning Time Series Forecasting the slow way!
Take my free 7-day email course and discover how to get started (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
1. Environment
This tutorial assumes an installed and working SciPy environment and dependencies, including:
SciPy
NumPy
Matplotlib
Pandas
scikit-learn
statsmodels
I used Python 2.7. Are you on Python 3? let me know how you go in the comments.
This script will help you check your installed versions of these libraries.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# check the versions of key python libraries
# scipy
import scipy
print('scipy: %s'%scipy.__version__)
# numpy
import numpy
print('numpy: %s'%numpy.__version__)
# matplotlib
import matplotlib
print('matplotlib: %s'%matplotlib.__version__)
# pandas
import pandas
print('pandas: %s'%pandas.__version__)
# statsmodels
import statsmodels
print('statsmodels: %s'%statsmodels.__version__)
# scikit-learn
import sklearn
print('sklearn: %s'%sklearn.__version__)
The results on my workstation used to write this tutorial are as follows:
1
2
3
4
5
6
scipy: 1.5.4
numpy: 1.18.5
matplotlib: 3.3.3
pandas: 1.1.4
statsmodels: 0.12.1
sklearn: 0.23.2
2. Problem Description
The problem is to predict the number of monthly armed robberies in Boston, USA.
The dataset provides the number of monthly armed robberies in Boston from January 1966 to October 1975, or just under 10 years of data.
The values are a count and there are 118 observations.
Download the dataset as a CSV file and place it in your current working directory with the filename “robberies.csv“.
3. Test Harness
We must develop a test harness to investigate the data and evaluate candidate models.
This involves two steps:
Defining a Validation Dataset.
Developing a Method for Model Evaluation.
3.1 Validation Dataset
The dataset is not current. This means that we cannot easily collect updated data to validate the model.
Therefore we will pretend that it is October 1974 and withhold the last one year of data from analysis and model selection.
This final year of data will be used to validate the final model.
The code below will load the dataset as a Pandas Series and split into two, one for model development (dataset.csv) and the other for validation (validation.csv).
Running the example creates two files and prints the number of observations in each.
1
Dataset 106, Validation 12
The specific contents of these files are:
dataset.csv: Observations from January 1966 to October 1974 (106 observations)
validation.csv: Observations from November 1974 to October 1975 (12 observations)
The validation dataset is 10% of the original dataset.
Note that the saved datasets do not have a header line, therefore we do not need to cater to this when working with these files later.
3.2. Model Evaluation
Model evaluation will only be performed on the data in dataset.csv prepared in the previous section.
Model evaluation involves two elements:
Performance Measure.
Test Strategy.
3.2.1 Performance Measure
The observations are a count of robberies.
We will evaluate the performance of predictions using the root mean squared error (RMSE). This will give more weight to predictions that are grossly wrong and will have the same units as the original data.
Any transforms to the data must be reversed before the RMSE is calculated and reported to make the performance between different methods directly comparable.
We can calculate the RMSE using the helper function from the scikit-learn library mean_squared_error() that calculates the mean squared error between a list of expected values (the test set) and the list of predictions. We can then take the square root of this value to give us an RMSE score.
For example:
1
2
3
4
5
6
7
8
from sklearn.metrics import mean_squared_error
from math import sqrt
...
test=...
predictions=...
mse=mean_squared_error(test,predictions)
rmse=sqrt(mse)
print('RMSE: %.3f'%rmse)
3.2.2 Test Strategy
Candidate models will be evaluated using walk-forward validation.
This is because a rolling-forecast type model is required from the problem definition. This is where one-step forecasts are needed given all available data.
The walk-forward validation will work as follows:
The first 50% of the dataset will be held back to train the model.
The remaining 50% of the dataset will be iterated and test the model.
For each step in the test dataset:
A model will be trained.
A one-step prediction made and the prediction stored for later evaluation.
The actual observation from the test dataset will be added to the training dataset for the next iteration.
The predictions made during the iteration of the test dataset will be evaluated and an RMSE score reported.
Given the small size of the data, we will allow a model to be re-trained given all available data prior to each prediction.
We can write the code for the test harness using simple NumPy and Python code.
Firstly, we can split the dataset into train and test sets directly. We’re careful to always convert a loaded dataset to float32 in case the loaded data still has some String or Integer data types.
1
2
3
4
5
# prepare data
X=series.values
X=X.astype('float32')
train_size=int(len(X)*0.50)
train,test=X[0:train_size],X[train_size:]
Next, we can iterate over the time steps in the test dataset. The train dataset is stored in a Python list as we need to easily append a new observation each iteration and Numpy array concatenation feels like overkill.
The prediction made by the model is called yhat for convention, as the outcome or observation is referred to as y and yhat (a ‘y‘ with a mark above) is the mathematical notation for the prediction of the y variable.
The prediction and observation are printed each observation for a sanity check prediction in case there are issues with the model.
The first step before getting bogged down in data analysis and modeling is to establish a baseline of performance.
This will provide both a template for evaluating models using the proposed test harness and a performance measure by which all more elaborate predictive models can be compared.
The baseline prediction for time series forecasting is called the naive forecast, or persistence.
This is where the observation from the previous time step is used as the prediction for the observation at the next time step.
We can plug this directly into the test harness defined in the previous section.
Running the test harness prints the prediction and observation for each iteration of the test dataset.
The example ends by printing the RMSE for the model.
In this case, we can see that the persistence model achieved an RMSE of 51.844. This means that on average, the model was wrong by about 51 robberies for each prediction made.
1
2
3
4
5
6
7
...
>Predicted=241.000, Expected=287
>Predicted=287.000, Expected=355
>Predicted=355.000, Expected=460
>Predicted=460.000, Expected=364
>Predicted=364.000, Expected=487
RMSE: 51.844
We now have a baseline prediction method and performance; now we can start digging into our data.
5. Data Analysis
We can use summary statistics and plots of the data to quickly learn more about the structure of the prediction problem.
In this section, we will look at the data from four perspectives:
Summary Statistics.
Line Plot.
Density Plots.
Box and Whisker Plot.
5.1 Summary Statistics.
Open the data dataset.csv file and/or the original robberies.csv file in a text editor and look at the data.
A quick check suggests that there are are no obviously missing observations. We may have noticed this earlier if we tried to force the series to floating point values and values like NaN or ‘?‘ were in the data.
Summary statistics provide a quick look at the limits of observed values. It can help to get a quick idea of what we are working with.
The example below calculates and prints summary statistics for the time series.
1
2
3
from pandas import read_csv
series=read_csv('dataset.csv')
print(series.describe())
Running the example provides a number of summary statistics to review.
Some observations from these statistics include:
The number of observations (count) matches our expectation, meaning we are handling the data correctly.
The mean is about 173, which we might consider our level in this series.
The standard deviation (average spread from the mean) is relatively large at 112 robberies.
The percentiles along with the standard deviation do suggest a large spread to the data.
1
2
3
4
5
6
7
8
count 106.000000
mean 173.103774
std 112.231133
min 29.000000
25% 74.750000
50% 144.500000
75% 271.750000
max 487.000000
The large spread in this series will likely make highly accurate predictions difficult if it is caused by random fluctuation (e.g. not systematic).
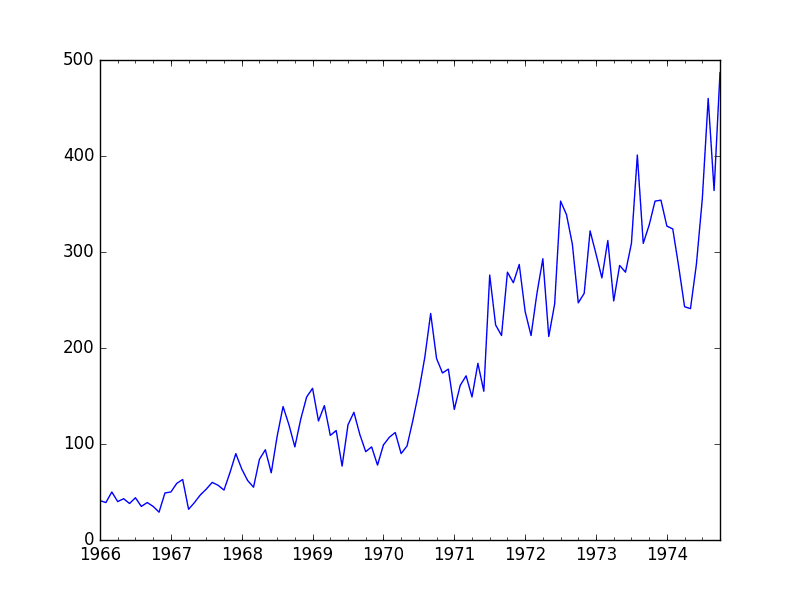
5.2 Line Plot
A line plot of a time series can provide a lot of insight into the problem.
The example below creates and shows a line plot of the dataset.
1
2
3
4
5
from pandas import read_csv
from matplotlib import pyplot
series=read_csv('dataset.csv')
series.plot()
pyplot.show()
Run the example and review the plot. Note any obvious temporal structures in the series.
Some observations from the plot include:
There is an increasing trend of robberies over time.
There do not appear to be any obvious outliers.
There are relatively large fluctuations from year to year, up and down.
The fluctuations at later years appear larger than fluctuations at earlier years.
The trend means the dataset is almost certainly non-stationary and the apparent change in fluctuation may also contribute.
Monthly Boston Robberies Line Plot
These simple observations suggest we may see benefit in modeling the trend and removing it from the time series.
Alternately, we could use differencing to make the series stationary for modeling. We may even need two levels of differencing if there is a growth trend in the fluctuations in later years.
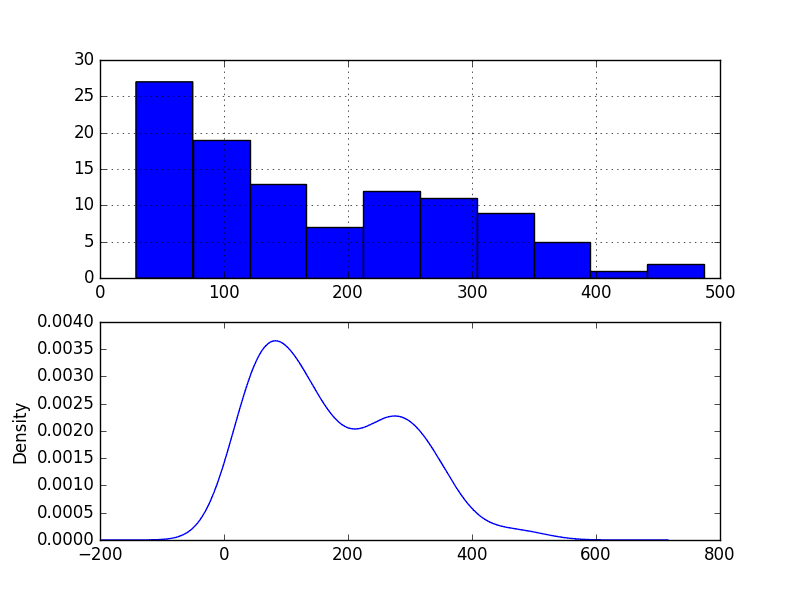
5.3 Density Plot
Reviewing plots of the density of observations can provide further insight into the structure of the data.
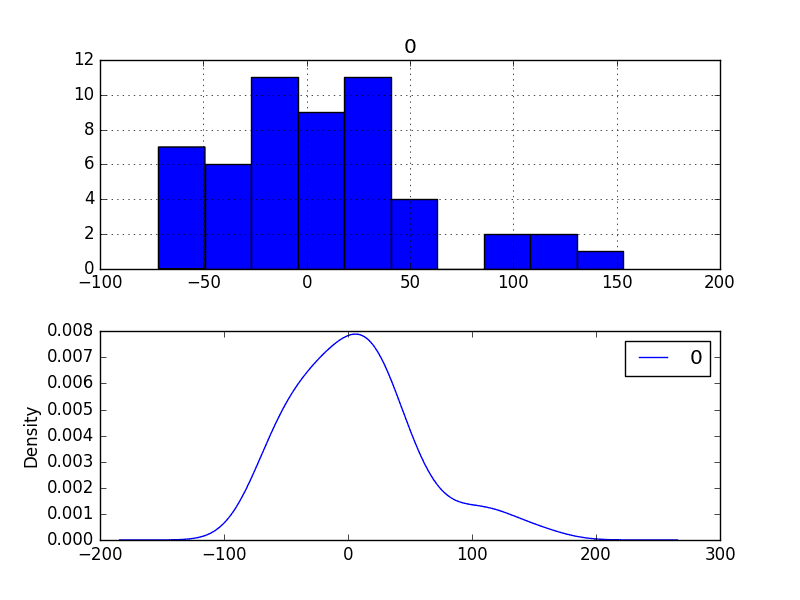
The example below creates a histogram and density plot of the observations without any temporal structure.
1
2
3
4
5
6
7
8
9
from pandas import read_csv
from matplotlib import pyplot
series=read_csv('dataset.csv')
pyplot.figure(1)
pyplot.subplot(211)
series.hist()
pyplot.subplot(212)
series.plot(kind='kde')
pyplot.show()
Run the example and review the plots.
Some observations from the plots include:
The distribution is not Gaussian.
The distribution is left shifted and may be exponential or a double Gaussian.
Monthly Boston Robberies Density Plot
We may see some benefit in exploring some power transforms of the data prior to modeling.
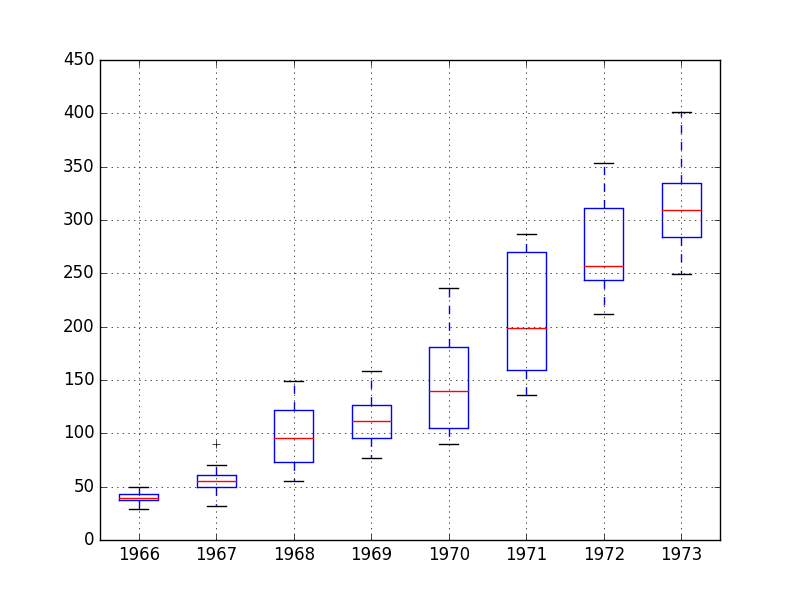
5.4 Box and Whisker Plots
We can group the monthly data by year and get an idea of the spread of observations for each year and how this may be changing.
We do expect to see some trend (increasing mean or median), but it may be interesting to see how the rest of the distribution may be changing.
The example below groups the observations by year and creates one box and whisker plot for each year of observations. The last year (1974) only contains 10 months and may not be a useful comparison with the other 12 months of observations in the other years. Therefore only data between 1966 and 1973 was plotted.
Running the example creates 8 box and whisker plots side-by-side, one for each of the 8 years of selected data.
Some observations from reviewing the plot include:
The median values for each year (red line) show a trend that may not be linear.
The spread, or middle 50% of the data (blue boxes), differ, but perhaps not consistently over time.
The earlier years, perhaps first 2, are quite different from the rest of the dataset.
Monthly Boston Robberies Box and Whisker Plots
The observations suggest that the year-to-year fluctuations may not be systematic and hard to model. They also suggest that there may be some benefit in clipping the first two years of data from modeling if it is indeed quite different.
This yearly view of the data is an interesting avenue and could be pursued further by looking at summary statistics from year-to-year and changes in summary stats from year-to-year.
Next, we can start looking at predictive models of the series.
6. ARIMA Models
In this section, we will develop Autoregression Integrated Moving Average, or ARIMA, models for the problem.
We will approach this in four steps:
Developing a manually configured ARIMA model.
Using a grid search of ARIMA to find an optimized model.
Analysis of forecast residual errors to evaluate any bias in the model.
Explore improvements to the model using power transforms.
6.1 Manually Configured ARIMA
Nonseasonal ARIMA(p,d,q) requires three parameters and is traditionally configured manually.
Analysis of the time series data assumes that we are working with a stationary time series.
The time series is almost certainly non-stationary. We can make it stationary by first differencing the series and using a statistical test to confirm that the result is stationary.
The example below creates a stationary version of the series and saves it to file stationary.csv.
Running the example outputs the result of a statistical significance test of whether the series is stationary. Specifically, the augmented Dickey-Fuller test.
The results show that the test statistic value -3.980946 is smaller than the critical value at 5% of -2.893. This suggests that we can reject the null hypothesis with a significance level of less than 5% (i.e. a low probability that the result is a statistical fluke).
Rejecting the null hypothesis means that the process has no unit root, and in turn that the time series is stationary or does not have time-dependent structure.
1
2
3
4
5
6
ADF Statistic: -3.980946
p-value: 0.001514
Critical Values:
5%: -2.893
1%: -3.503
10%: -2.584
This suggests that at least one level of differencing is required. The d parameter in our ARIMA model should at least be a value of 1.
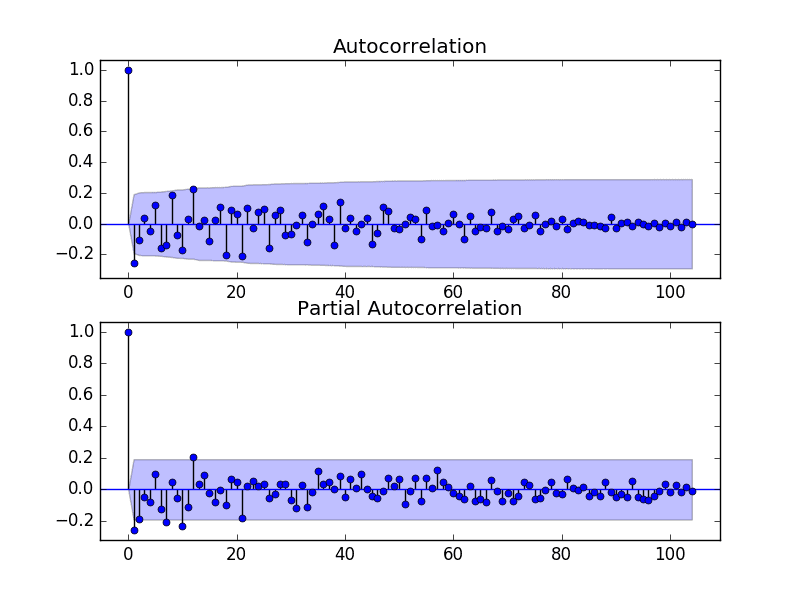
The next step is to select the lag values for the Autoregression (AR) and Moving Average (MA) parameters, p and q respectively.
We can do this by reviewing Autocorrelation Function (ACF) and Partial Autocorrelation Function (PACF) plots.
The example below creates ACF and PACF plots for the series.
1
2
3
4
5
6
7
8
9
10
11
from pandas import read_csv
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf
from matplotlib import pyplot
series=read_csv('stationary.csv')
pyplot.figure()
pyplot.subplot(211)
plot_acf(series,ax=pyplot.gca())
pyplot.subplot(212)
plot_pacf(series,ax=pyplot.gca())
pyplot.show()
Run the example and review the plots for insights into how to set the p and q variables for the ARIMA model.
Below are some observations from the plots.
The ACF shows a significant lag for 1 month.
The PACF shows a significant lag for perhaps 2 months, with significant lags spotty out to perhaps 12 months.
Both the ACF and PACF show a drop-off at the same point, perhaps suggesting a mix of AR and MA.
A good starting point for the p and q values is 1 or 2.
Monthly Boston Robberies ACF and PACF Plots
This quick analysis suggests an ARIMA(1,1,2) on the raw data may be a good starting point.
Experimentation shows that this configuration of ARIMA does not converge and results in errors by the underlying library. Some experimentation shows that the model does not appear to be stable, with non-zero AR and MA orders defined at the same time.
The model can be simplified to ARIMA(0,1,2). The example below demonstrates the performance of this ARIMA model on the test harness.
Running this example results in an RMSE of 49.821, which is lower than the persistence model.
1
2
3
4
5
6
7
...
>Predicted=280.614, Expected=287
>Predicted=302.079, Expected=355
>Predicted=340.210, Expected=460
>Predicted=405.172, Expected=364
>Predicted=333.755, Expected=487
RMSE: 49.821
This is a good start, but we may be able to get improved results with a better configured ARIMA model.
6.2 Grid Search ARIMA Hyperparameters
Many ARIMA configurations are unstable on this dataset, but there may be other hyperparameters that result in a well-performing model.
In this section, we will search values of p, d, and q for combinations that do not result in error, and find the combination that results in the best performance. We will use a grid search to explore all combinations in a subset of integer values.
Specifically, we will search all combinations of the following parameters:
p: 0 to 12.
d: 0 to 3.
q: 0 to 12.
This is (13 * 4 * 13), or 676, runs of the test harness and will take some time to execute.
The complete worked example with the grid search version of the test harness is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
# grid search ARIMA parameters for time series
import warnings
from pandas import read_csv
from statsmodels.tsa.arima.model import ARIMA
from sklearn.metrics import mean_squared_error
from math import sqrt
# evaluate an ARIMA model for a given order (p,d,q) and return RMSE
def evaluate_arima_model(X,arima_order):
# prepare training dataset
X=X.astype('float32')
train_size=int(len(X)*0.50)
train,test=X[0:train_size],X[train_size:]
history=[xforxintrain]
# make predictions
predictions=list()
fortinrange(len(test)):
model=ARIMA(history,order=arima_order)
model_fit=model.fit()
yhat=model_fit.forecast()[0]
predictions.append(yhat)
history.append(test[t])
# calculate out of sample error
rmse=sqrt(mean_squared_error(test,predictions))
returnrmse
# evaluate combinations of p, d and q values for an ARIMA model
The graphs suggest a Gaussian-like distribution with a longer right tail.
This is perhaps a sign that the predictions are biased, and in this case that perhaps a power-based transform of the raw data before modeling might be useful.
Residual Errors Density Plots
It is also a good idea to check the time series of the residual errors for any type of autocorrelation. If present, it would suggest that the model has more opportunity to model the temporal structure in the data.
The example below re-calculates the residual errors and creates ACF and PACF plots to check for any significant autocorrelation.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# ACF and PACF plots of forecast residual errors
from pandas import read_csv
from pandas import DataFrame
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf
The results suggest that what little autocorrelation is present in the time series has been captured by the model.
Residual Errors ACF and PACF Plots
6.4 Box-Cox Transformed Dataset
The Box-Cox transform is a method that is able to evaluate a suite of power transforms, including, but not limited to, log, square root, and reciprocal transforms of the data.
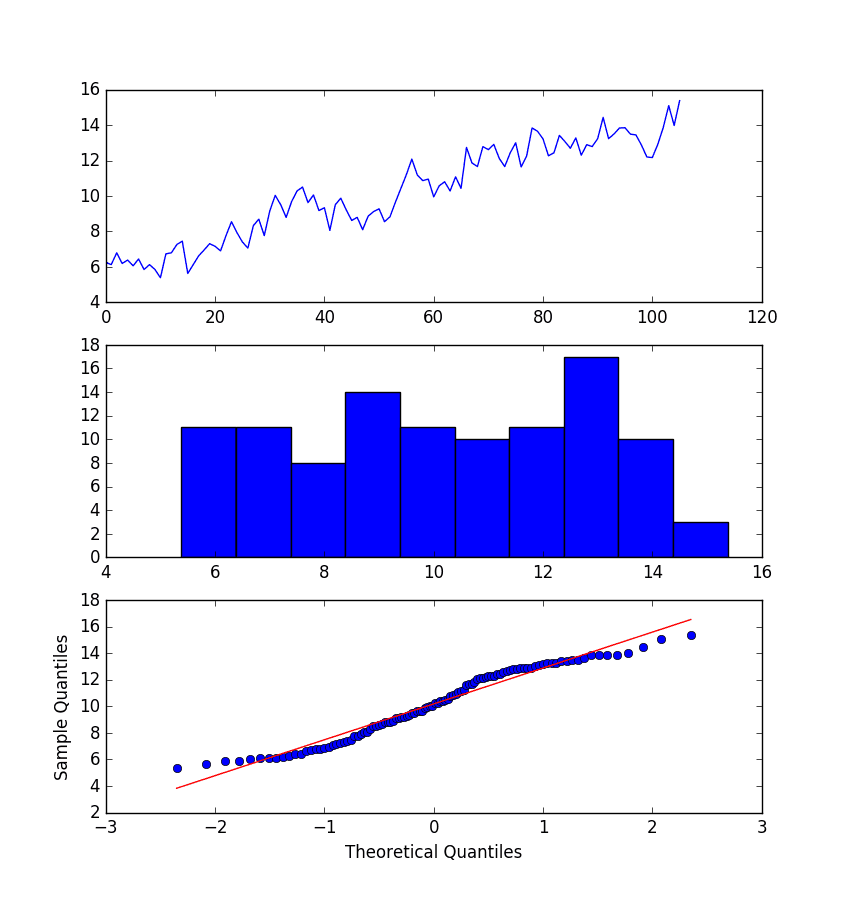
The example below performs a log transform of the data and generates some plots to review the effect on the time series.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
from pandas import read_csv
from pandas import DataFrame
from scipy.stats import boxcox
from matplotlib import pyplot
from statsmodels.graphics.gofplots import qqplot
series=read_csv('dataset.csv')
X=series.values
transformed,lam=boxcox(X)
print('Lambda: %f'%lam)
pyplot.figure(1)
# line plot
pyplot.subplot(311)
pyplot.plot(transformed)
# histogram
pyplot.subplot(312)
pyplot.hist(transformed)
# q-q plot
pyplot.subplot(313)
qqplot(transformed,line='r',ax=pyplot.gca())
pyplot.show()
Running the example creates three graphs: a line chart of the transformed time series, a histogram showing the distribution of transformed values, and a Q-Q plot showing how the distribution of values compared to an idealized Gaussian distribution.
Some observations from these plots are follows:
The large fluctuations have been removed from the line plot of the time series.
The histogram shows a flatter or more uniform (well behaved) distribution of values.
The Q-Q plot is reasonable, but still not a perfect fit for a Gaussian distribution.
BoxCox Transform Plots of Monthly Boston Robberies
Undoubtedly, the Box-Cox transform has done something to the time series and may be useful.
Before proceeding to test the ARIMA model with the transformed data, we must have a way to reverse the transform in order to convert predictions made with a model trained on the transformed data back into the original scale.
The boxcox() function used in the example finds an ideal lambda value by optimizing a cost function.
The lambda is used in the following function to transform the data:
This transform function can be reversed directly, as follows:
1
2
x = exp(transform) if lambda == 0
x = exp(log(lambda * transform + 1) / lambda)
This inverse Box-Cox transform function can be implemented in Python as follows:
1
2
3
4
5
6
7
# invert box-cox transform
from math import log
from math import exp
def boxcox_inverse(value,lam):
iflam==0:
returnexp(value)
returnexp(log(lam *value+1)/lam)
We can re-evaluate the ARIMA(0,1,2) model with the Box-Cox transform.
This involves first transforming the history prior to fitting the ARIMA model, then inverting the transform on the prediction before storing it for later comparison with the expected values.
The boxcox() function can fail. In practice, I have seen this and it appears to be signaled by a returned lambda value of less than -5. By convention, lambda values are evaluated between -5 and 5.
A check is added for a lambda value less than -5, and if this the case, a lambda value of 1 is assumed and the raw history is used to fit the model. A lambda value of 1 is the same as “no-transform” and therefore the inverse transform has no effect.
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# evaluate ARIMA models with box-cox transformed time series
Running the example prints the predicted and expected value each iteration.
Note, you may see warnings when using the boxcox() transform function; for example:
1
2
RuntimeWarning: overflow encountered in square
llf -= N / 2.0 * np.log(np.sum((y - y_mean)**2. / N, axis=0))
These can be ignored for now.
The final RMSE of the model on the transformed data was 49.443. This is a smaller error than the ARIMA model on untransformed data, but only slightly, and it may or may not be statistically different.
1
2
3
4
5
6
7
...
>Predicted=276.253, Expected=287
>Predicted=299.811, Expected=355
>Predicted=338.997, Expected=460
>Predicted=404.509, Expected=364
>Predicted=349.336, Expected=487
RMSE: 49.443
We will use this model with the Box-Cox transform as the final model.
7. Model Validation
After models have been developed and a final model selected, it must be validated and finalized.
Validation is an optional part of the process, but one that provides a ‘last check’ to ensure we have not fooled or lied to ourselves.
This section includes the following steps:
Finalize Model: Train and save the final model.
Make Prediction: Load the finalized model and make a prediction.
Validate Model: Load and validate the final model.
7.1 Finalize Model
Finalizing the model involves fitting an ARIMA model on the entire dataset, in this case, on a transformed version of the entire dataset.
Once fit, the model can be saved to file for later use. Because a Box-Cox transform is also performed on the data, we need to know the chosen lambda so that any predictions from the model can be converted back to the original, untransformed scale.
The example below fits an ARIMA(0,1,2) model on the Box-Cox transform dataset and saves the whole fit object and the lambda value to file.
model.pkl This is the ARIMAResult object from the call to ARIMA.fit(). This includes the coefficients and all other internal data returned when fitting the model.
model_lambda.npy This is the lambda value stored as a one-row, one-column NumPy array.
This is probably overkill and all that is really needed for operational use are the AR and MA coefficients from the model, the d parameter for the number of differences, perhaps the lag observations and model residuals, and the lambda value for the transform.
7.2 Make Prediction
A natural case may be to load the model and make a single forecast.
This is relatively straightforward and involves restoring the saved model and the lambda and calling the forecast() method.
The example below loads the model, makes a prediction for the next time step, inverses the Box-Cox transform, and prints the prediction.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# load the finalized model and make a prediction
from statsmodels.tsa.arima.model import ARIMAResults
from math import exp
from math import log
import numpy
# invert box-cox transform
def boxcox_inverse(value,lam):
iflam==0:
returnexp(value)
returnexp(log(lam *value+1)/lam)
model_fit=ARIMAResults.load('model.pkl')
lam=numpy.load('model_lambda.npy')
yhat=model_fit.forecast()[0]
yhat=boxcox_inverse(yhat,lam)
print('Predicted: %.3f'%yhat)
Running the example prints the prediction of about 452.
If we peek inside validation.csv, we can see that the value on the first row for the next time period is 452. The model got it 100% correct, which is very impressive (or lucky).
1
Predicted: 452.043
7.3 Validate Model
We can load the model and use it in a pretend operational manner.
In the test harness section, we saved the final 12 months of the original dataset in a separate file to validate the final model.
We can load this validation.csv file now and use it see how well our model really is on “unseen” data.
There are two ways we might proceed:
Load the model and use it to forecast the next 12 months. The forecast beyond the first one or two months will quickly start to degrade in skill.
Load the model and use it in a rolling-forecast manner, updating the transform and model for each time step. This is the preferred method as it is how one would use this model in practice, as it would achieve the best performance.
As with model evaluation in previous sections, we will make predictions in a rolling-forecast manner. This means that we will step over lead times in the validation dataset and take the observations as an update to the history.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
# evaluate the finalized model on the validation dataset
from pandas import read_csv
from matplotlib import pyplot
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.tsa.arima.model import ARIMAResults
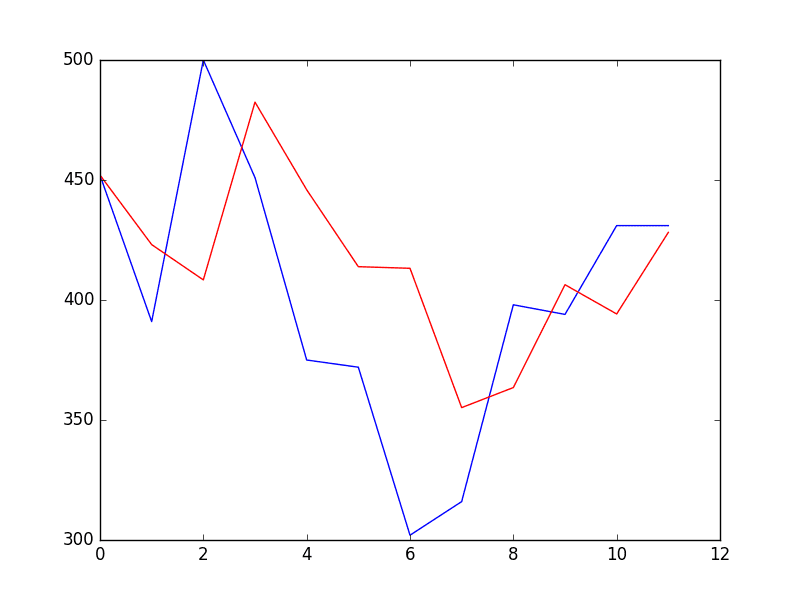
Running the example prints each prediction and expected value for the time steps in the validation dataset.
The final RMSE for the validation period is predicted at 53 robberies. This is not too different to the expected error of 49, but I would expect that it is also not too different from a simple persistence model.
1
2
3
4
5
6
7
8
9
10
11
12
13
>Predicted=452.043, Expected=452
>Predicted=423.088, Expected=391
>Predicted=408.378, Expected=500
>Predicted=482.454, Expected=451
>Predicted=445.944, Expected=375
>Predicted=413.881, Expected=372
>Predicted=413.209, Expected=302
>Predicted=355.159, Expected=316
>Predicted=363.515, Expected=398
>Predicted=406.365, Expected=394
>Predicted=394.186, Expected=431
>Predicted=428.174, Expected=431
RMSE: 53.078
A plot of the predictions compared to the validation dataset is also provided.
The forecast does have the characteristic of a persistence forecast. This does suggest that although this time series does have an obvious trend, it is still a reasonably difficult problem.
Forecast for Validation Time Steps
Tutorial Extensions
This tutorial was not exhaustive; there may be more that you can do to improve the result.
This section lists some ideas.
Statistical Significance Tests. Use a statistical test to check if the difference in results between different models is statistically significant. The Student t-test would be a good place to start.
Grid Search with Data Transforms. Repeat the grid search in the ARIMA hyperparameters with the Box-Cox transform and see if a different and better set of parameters can be achieved.
Inspect Residuals. Investigate the residual forecast errors on the final model with Box-Cox transforms to see if there is a further bias and/or autocorrelation that can be addressed.
Lean Model Saving. Simplify model saving to only store the required coefficients rather than the entire ARIMAResults object.
Manually Handle Trend. Model the trend directly with a linear or nonlinear model and explicitly remove it from the series. This may result in better performance if the trend is nonlinear and can be modeled better than the linear case.
Confidence Interval. Display the confidence intervals for the predictions on the validation dataset.
Data Selection. Consider modeling the problem without the first two years of data and see if this has an impact on forecast skill.
Did you implement any of these extensions? Were you able to get a better result?
Share your findings in the comments below.
Summary
In this tutorial, you discovered the steps and the tools for a time series forecasting project with Python.
We covered a lot of ground in this tutorial, specifically:
How to develop a test harness with a performance measure and evaluation method and how to quickly develop a baseline forecast and skill.
How to use time series analysis to raise ideas for how to best model the forecast problem.
How to develop an ARIMA model, save it, and later load it to make predictions on new data.
How did you do? Do you have any questions about this tutorial?
Ask your questions in the comments below and I will do my best to answer.
Want to Develop Time Series Forecasts with Python?
Hi Jason, thanks for the tutorial.
What happens if I have a highly correlated data, lets say the autocorrealtion has a significant lag of 40 temporal units. Is ARIMA a good model? How can I take advantage of the highly data correlation.
I suspect that the p parameter is not going to be 40, how can estimate it?
I am trying to use ARIMA to forecast bitcoin price using different sample frequencies. However usigma (0,1,2) or (1,1,2) pdq the model seems to follow the original data but with lagged, and performs quite bad.
What is the difference between using model.resid from calculating residual explicitly by finding out the difference between predicted values and observed values?
I have a time series but tried. It is not working please can you explain to me
series = Series.from_csv(‘dataset.csv’)
groups = series[‘1966′:’1973’].groupby(TimeGrouper(‘A’))
years = DataFrame()
for name, group in groups:
years[name.year] = group.values
years.boxplot()
pyplot.show()
Hey Jason, Great Tutorial. How can we use ARIMA for multi- series forecasting (let’s say forecasting simultaneously for 10 products) where the data available is on daily basis.
I am currently reading through your blog. The topics covered as well as your style of explaining things are really amazing. Thank you very much for your efforts!
In terms of this tutorial, I noted that the acf and the pacf chart under chapter 6.1 are not reproducible by using the dataset.csv (in my opinion). This line of code here is wrong :
series = Series.from_csv(‘dataset.csv’)
The csv-file to read from should be “stationary.csv” (as we have to use the corrected dataset).
This is the code I am using in Python 3.x (Series.from_csv is deprecated):
df = pd.read_csv(‘stationary.csv’,header=None,sep=’,’)
df.columns = [‘Date’,’Robberies’]
series = pd.Series(data=df[‘Robberies’])
series.index = pd.to_datetime(df[‘Date’])
Hi,
Yes thank you for the modelling and write up. It is excellent! I am new to Python and the forecasting topic has been quite the challenge.
Question:
Why does the line: X = X.astype(‘float32’)
yield this
ValueError: could not convert string to float: Oct-75
in Python 2.7
Here are my preliminary work station results:
scipy: 1.1.0
numpy: 1.14.5
matplotlib: 2.2.2
pandas: 0.23.3
sklearn: 0.19.2
statsmodels: 0.9.0
I am trying to replace:
series = Series.from_csv(‘robberies.csv’, header=0)
and replace it with
read_csv
command. Can anyone tell me what needs to be replaced so that I can follow along with the tutorial?
Thanks
It does, but not for section 6.1-6.3
Here is the error message:
Traceback (most recent call last):
File “/Users/adampatel/Documents/Test ARIMA Inputs.py”, line 47, in
series = read_csv(‘dataset.csv’, header=0, parse_dates=[0], index_col=0, squeeze=True)
File “/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/pandas/io/parsers.py”, line 678, in parser_f
return _read(filepath_or_buffer, kwds)
File “/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/pandas/io/parsers.py”, line 440, in _read
parser = TextFileReader(filepath_or_buffer, **kwds)
File “/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/pandas/io/parsers.py”, line 787, in __init__
self._make_engine(self.engine)
File “/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/pandas/io/parsers.py”, line 1014, in _make_engine
self._engine = CParserWrapper(self.f, **self.options)
File “/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/pandas/io/parsers.py”, line 1708, in __init__
self._reader = parsers.TextReader(src, **kwds)
File “pandas/_libs/parsers.pyx”, line 384, in pandas._libs.parsers.TextReader.__cinit__
File “pandas/_libs/parsers.pyx”, line 695, in pandas._libs.parsers.TextReader._setup_parser_source
IOError: File dataset.csv does not exist
The only difference between Jason’s code and mine is:
series = Series.from_csv(‘robberies.csv’, header=0)
and replace it with
from pandas import read_csv
series = read_csv(‘dataset.csv’, header=0, parse_dates=[0], index_col=0, squeeze=True)
I recommend limiting lags, ACF/PACF and even ARIMA models in general assume that the output is a function of recent observations, not of the entire dataset.
Hey when I’m running the pacf function as below
import numpy as np
from pandas import Series
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf
from matplotlib import pyplot
series = Series.from_csv(‘stationary.csv’)
pyplot.figure()
pyplot.subplot(212)
plot_pacf(series, ax=pyplot.gca())
pyplot.show()
I get the following error any help would be useful
ipython-input-68-f01e5d803de5> in ()
7 pyplot.figure()
8 pyplot.subplot(212)
—-> 9 plot_pacf(series, ax=pyplot.gca())
10 pyplot.show()
~/.local/lib/python3.5/site-packages/statsmodels/tsa/stattools.py in pacf(x, nlags, method, alpha)
599 ret = pacf_ols(x, nlags=nlags)
600 elif method in [‘yw’, ‘ywu’, ‘ywunbiased’, ‘yw_unbiased’]:
–> 601 ret = pacf_yw(x, nlags=nlags, method=’unbiased’)
602 elif method in [‘ywm’, ‘ywmle’, ‘yw_mle’]:
603 ret = pacf_yw(x, nlags=nlags, method=’mle’)
~/.local/lib/python3.5/site-packages/statsmodels/tsa/stattools.py in pacf_yw(x, nlags, method)
518 pacf = [1.]
519 for k in range(1, nlags + 1):
–> 520 pacf.append(yule_walker(x, k, method=method)[0][-1])
521 return np.array(pacf)
522
~/.local/lib/python3.5/site-packages/statsmodels/regression/linear_model.py in yule_walker(X, order, method, df, inv, demean)
1259 if method not in [“unbiased”, “mle”]:
1260 raise ValueError(“ACF estimation method must be ‘unbiased’ or ‘MLE'”)
-> 1261 X = np.array(X, dtype=np.float64)
1262 if demean:
1263 X -= X.mean() # automatically demean’s X
ValueError: could not convert string to float: ‘[0.98]’
Thanks for this tutorial.
What if the data included the locations of the crimes within Boston? If the locations were of a particular city block in which the crime accurred, there quite possibliy could be a relationship between crimes in different areas. ie. The criminals could rob a place and then rob another place minutes later.
How would you approach this problem if location data were to be added?
Hi Jason, thanks for your tutorial! It was very helpful.
The fluctuations might be explained by exogenous variables, are you planning to cover SARIMAX in a tutorial as well?
Nice tutorial! I just have a question. After saving the model into pkl file, let say I want to deploy it into a website or app, if ever what will be the input of this ARIMA forecasting model? Is it the range of forecasting ( to forecast the next 6 months or 12 months, so I need an input of either 6 or 12). Or it has a default ranged that it will forecast a fix number of months. Or is it the date series that is needed to be an input, etc. etc. Thanks in advance!
in “Box-Cox Transformed Dataset”
transform = log(x), if lambda == 0
transform = (x^lambda – 1) / lambda, if lambda != 0
when “lambda==0”, it should be “transformed=history-1”, but your code is “transformed=history”.
Is my understand wrong?
The boxcox() function can fail. In practice, I have seen this and it appears to be signaled by a returned lambda value of less than -5. By convention, lambda values are evaluated between -5 and 5.
Hi.
Amazing tutorial… awesome blog. I’m delighted with all your articles till now.
As beginner I have a question. Is related to ad fuller result, and it could be trivial because nobody asked it before, but is confusing me.
You say:
“The results show that the test statistic value -3.980946 is smaller than the critical value at 5% of -2.893.
This suggests that we can reject the null hypothesis with a significance level of less than 5%
(i.e. a low probability that the result is a statistical fluke).”
Rejecting the null hypothesis means that the process has no unit root,
and in turn that the time series is stationary or does not have time-dependent structure.
Ok Due that reason and that pValue = 0.001514 << 0.5. Then it is an stationary serie…Isn't it?
After that, The numerical values are presented, for ad fuller test
Immediately you state: "This suggests that at least one level of differencing is required."
The d parameter in our ARIMA model should at least be a value of 1.
Ok I'm agree because it runs. And acf points in that direction…
But… Why? If we need to make a diff is in order to make the serie stationary, and it was…
what am I losing?
Thank you, again for you work. It is really useful
Why questions are really hard. Perhaps the series was not stationary and the result was accurate and the low probability came true, or perhaps the test was a bad fit for the data for some reason I did’n think of. Or some other reason.
I prefer to focus on the pragmatic – what works – what gives a result we can use on the project now. Engineering, not science.
Oh!! Then can I derive that probably result of ad fuller test is not sacred? I mean it can be erroneous by several reasons and it can be convenient to do another short of test to be more confident. If It is, then you have give me a great lesson because any one trend to make a single test. Thank you.
first of all I want to thank you for your clear explanations. I really like how you present the tutorial and list the different steps that one needs to take to fully develop a forecasting project.
I am currently going through your case study and I noticed that you are using the file ‘dataset.csv’ for your manually configured ARIMA model. From my understanding, this is not correct because the ARIMA model needs a stationary serie in order to work as intended. Shouldn’t we need to use the ‘stationary.csv’ dataset here?
Thank you very much again.
Cheers from Germany!
Ana Debroy
I also noticed that you are actually only using the ‘dataset.csv’ file, even after generating the ‘stationary.csv’ file.
My questions here are:
– Shouldn’t we also use the ‘stationar.csv’ for ALL code after the initial analysis of our dataset?
– And before validating the model, do we need to also differentiate the ‘validation.csv’ dataset?
From my understanding, we will get more error if we try to compare a forecast that was generated with a differentiated dataset against the validation data that was not differentiated.
thanks for another tutorial.
I wonder however if you haven’t mixed up the ACF and PACF when determining the p and q of the model.
You say the following:
“The ACF shows a significant lag for 1 month.
The PACF shows a significant lag for perhaps 2 months, with significant lags spotty out to perhaps 12 months.
Both the ACF and PACF show a drop-off at the same point, perhaps suggesting a mix of AR and MA.
A good starting point for the p and q values is 1 or 2.”
If PACF shows a significant lag for perhaps 2 months, then p value should be 2 and q should be 1 since we use PACF in order to assess p and ACF in order to assess q.





")
")
")

WOW! Amaizing tutorial! thanks!
Thanks!
The most comprehensive tutorial I ever came across,
a big thank you!
Thanks Arthur.
Hi Jason, thanks for the tutorial.
What happens if I have a highly correlated data, lets say the autocorrealtion has a significant lag of 40 temporal units. Is ARIMA a good model? How can I take advantage of the highly data correlation.
I suspect that the p parameter is not going to be 40, how can estimate it?
I am trying to use ARIMA to forecast bitcoin price using different sample frequencies. However usigma (0,1,2) or (1,1,2) pdq the model seems to follow the original data but with lagged, and performs quite bad.
Thanks agin,
The price may be a random walk:
https://machinelearningmastery.com/gentle-introduction-random-walk-times-series-forecasting-python/
Computers are fast and ARIMA models are easy to fit. Consider trying a suite of model parameters:
https://machinelearningmastery.com/grid-search-arima-hyperparameters-with-python/
What is the difference between using model.resid from calculating residual explicitly by finding out the difference between predicted values and observed values?
They may be exactly the same thing.
I have a time series but tried. It is not working please can you explain to me
series = Series.from_csv(‘dataset.csv’)
groups = series[‘1966′:’1973’].groupby(TimeGrouper(‘A’))
years = DataFrame()
for name, group in groups:
years[name.year] = group.values
years.boxplot()
pyplot.show()
What is the problem exactly?
This is a great tutorial! Thanks!
I’m glad it helped!
Hey Jason, Great Tutorial. How can we use ARIMA for multi- series forecasting (let’s say forecasting simultaneously for 10 products) where the data available is on daily basis.
Thanks
I hope to cover this topic in the future.
Hi Jason,
I am currently reading through your blog. The topics covered as well as your style of explaining things are really amazing. Thank you very much for your efforts!
In terms of this tutorial, I noted that the acf and the pacf chart under chapter 6.1 are not reproducible by using the dataset.csv (in my opinion). This line of code here is wrong :
series = Series.from_csv(‘dataset.csv’)
The csv-file to read from should be “stationary.csv” (as we have to use the corrected dataset).
This is the code I am using in Python 3.x (Series.from_csv is deprecated):
df = pd.read_csv(‘stationary.csv’,header=None,sep=’,’)
df.columns = [‘Date’,’Robberies’]
series = pd.Series(data=df[‘Robberies’])
series.index = pd.to_datetime(df[‘Date’])
Greetings from Hamburg, Germany
Patrick
Thanks Patrick, fixed.
I am using Python 3 as well. Thanks Patrick. Solved my problem.
Hi,
Yes thank you for the modelling and write up. It is excellent! I am new to Python and the forecasting topic has been quite the challenge.
Question:
Why does the line: X = X.astype(‘float32’)
yield this
ValueError: could not convert string to float: Oct-75
in Python 2.7
It looks like you are trying to convert date data that is a string to a number.
Yeah, I removed the 0 column that contained a numbered list of observations. The conversion works now!
Glad to hear it.
Here are my preliminary work station results:
scipy: 1.1.0
numpy: 1.14.5
matplotlib: 2.2.2
pandas: 0.23.3
sklearn: 0.19.2
statsmodels: 0.9.0
I am trying to replace:
series = Series.from_csv(‘robberies.csv’, header=0)
and replace it with
read_csv
command. Can anyone tell me what needs to be replaced so that I can follow along with the tutorial?
Thanks
Sorry, so far this seems to work:
from pandas import read_csv
series = read_csv(‘dataset.csv’, header=0, parse_dates=[0], index_col=0, squeeze=True)
Although, I am still working on month and year format….
It does, but not for section 6.1-6.3
Here is the error message:
Traceback (most recent call last):
File “/Users/adampatel/Documents/Test ARIMA Inputs.py”, line 47, in
series = read_csv(‘dataset.csv’, header=0, parse_dates=[0], index_col=0, squeeze=True)
File “/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/pandas/io/parsers.py”, line 678, in parser_f
return _read(filepath_or_buffer, kwds)
File “/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/pandas/io/parsers.py”, line 440, in _read
parser = TextFileReader(filepath_or_buffer, **kwds)
File “/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/pandas/io/parsers.py”, line 787, in __init__
self._make_engine(self.engine)
File “/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/pandas/io/parsers.py”, line 1014, in _make_engine
self._engine = CParserWrapper(self.f, **self.options)
File “/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/pandas/io/parsers.py”, line 1708, in __init__
self._reader = parsers.TextReader(src, **kwds)
File “pandas/_libs/parsers.pyx”, line 384, in pandas._libs.parsers.TextReader.__cinit__
File “pandas/_libs/parsers.pyx”, line 695, in pandas._libs.parsers.TextReader._setup_parser_source
IOError: File dataset.csv does not exist
The only difference between Jason’s code and mine is:
series = Series.from_csv(‘robberies.csv’, header=0)
and replace it with
from pandas import read_csv
series = read_csv(‘dataset.csv’, header=0, parse_dates=[0], index_col=0, squeeze=True)
Can someone help?
Check your file path(s)
Because you have not created the dataset.csv yet.
You must follow the tutorial steps in order.
Perhaps print the loaded data to confirm it was loaded correctly?
You can use it directly:
When I attempt to run the entire data set using the plot_pacf function, I get the error:
Warning (from warnings module):
File “/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-packages/statsmodels/regression/linear_model.py”, line 1283
return rho, np.sqrt(sigmasq)
RuntimeWarning: invalid value encountered in sqrt
and a variation of the recorded results above.
If I limit the lags to 50, I get the same observations for the first 50 lags above.
Can someone explain this?
I recommend limiting lags, ACF/PACF and even ARIMA models in general assume that the output is a function of recent observations, not of the entire dataset.
Hey when I’m running the pacf function as below
import numpy as np
from pandas import Series
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf
from matplotlib import pyplot
series = Series.from_csv(‘stationary.csv’)
pyplot.figure()
pyplot.subplot(212)
plot_pacf(series, ax=pyplot.gca())
pyplot.show()
I get the following error any help would be useful
ipython-input-68-f01e5d803de5> in ()
7 pyplot.figure()
8 pyplot.subplot(212)
—-> 9 plot_pacf(series, ax=pyplot.gca())
10 pyplot.show()
~/.local/lib/python3.5/site-packages/statsmodels/graphics/tsaplots.py in plot_pacf(x, ax, lags, alpha, method, use_vlines, title, zero, vlines_kwargs, **kwargs)
221 acf_x = pacf(x, nlags=nlags, alpha=alpha, method=method)
222 else:
–> 223 acf_x, confint = pacf(x, nlags=nlags, alpha=alpha, method=method)
224
225 _plot_corr(ax, title, acf_x, confint, lags, irregular, use_vlines,
~/.local/lib/python3.5/site-packages/statsmodels/tsa/stattools.py in pacf(x, nlags, method, alpha)
599 ret = pacf_ols(x, nlags=nlags)
600 elif method in [‘yw’, ‘ywu’, ‘ywunbiased’, ‘yw_unbiased’]:
–> 601 ret = pacf_yw(x, nlags=nlags, method=’unbiased’)
602 elif method in [‘ywm’, ‘ywmle’, ‘yw_mle’]:
603 ret = pacf_yw(x, nlags=nlags, method=’mle’)
~/.local/lib/python3.5/site-packages/statsmodels/tsa/stattools.py in pacf_yw(x, nlags, method)
518 pacf = [1.]
519 for k in range(1, nlags + 1):
–> 520 pacf.append(yule_walker(x, k, method=method)[0][-1])
521 return np.array(pacf)
522
~/.local/lib/python3.5/site-packages/statsmodels/regression/linear_model.py in yule_walker(X, order, method, df, inv, demean)
1259 if method not in [“unbiased”, “mle”]:
1260 raise ValueError(“ACF estimation method must be ‘unbiased’ or ‘MLE'”)
-> 1261 X = np.array(X, dtype=np.float64)
1262 if demean:
1263 X -= X.mean() # automatically demean’s X
ValueError: could not convert string to float: ‘[0.98]’
I have some suggestions here:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
Hi Jason
Thanks for this tutorial.
What if the data included the locations of the crimes within Boston? If the locations were of a particular city block in which the crime accurred, there quite possibliy could be a relationship between crimes in different areas. ie. The criminals could rob a place and then rob another place minutes later.
How would you approach this problem if location data were to be added?
It depends on the specific dataset.
Perhaps prototype a few different framings of the problem in order to discover what works best.
Hi Jason, thanks for your tutorial! It was very helpful.
The fluctuations might be explained by exogenous variables, are you planning to cover SARIMAX in a tutorial as well?
I show how to use SARIMA here:
https://machinelearningmastery.com/how-to-grid-search-sarima-model-hyperparameters-for-time-series-forecasting-in-python/
I how how to add exog vars to SARIMA (e.g. SARIMAX) here:
https://machinelearningmastery.com/time-series-forecasting-methods-in-python-cheat-sheet/
Hi – How do you save (p,d,q) so that you can use them to apply them later on to your data?
You could save the resulting model:
https://machinelearningmastery.com/save-arima-time-series-forecasting-model-python/
The link for the data isn’t working. I found the data at this site
https://rstudio-pubs-static.s3.amazonaws.com/153780_a9970c82ef5546479e0ceedc3efef520.html
It will require some manual manipulation to get into a csv
## Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
## 1966 41 39 50 40 43 38 44 35 39 35 29 49
## 1967 50 59 63 32 39 47 53 60 57 52 70 90
## 1968 74 62 55 84 94 70 108 139 120 97 126 149
## 1969 158 124 140 109 114 77 120 133 110 92 97 78
## 1970 99 107 112 90 98 125 155 190 236 189 174 178
## 1971 136 161 171 149 184 155 276 224 213 279 268 287
## 1972 238 213 257 293 212 246 353 339 308 247 257 322
## 1973 298 273 312 249 286 279 309 401 309 328 353 354
## 1974 327 324 285 243 241 287 355 460 364 487 452 391
## 1975 500 451 375 372 302 316 398 394 431 431
Here is the direct link:
https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-robberies.csv
is there a funtion, package that can handle multiple diferences and reverse than to make the forecast, like 5 lags on a ARIMA model?
Consider the SARIMA model that adds differencing for seasons:
https://machinelearningmastery.com/sarima-for-time-series-forecasting-in-python/
Nice tutorial! I just have a question. After saving the model into pkl file, let say I want to deploy it into a website or app, if ever what will be the input of this ARIMA forecasting model? Is it the range of forecasting ( to forecast the next 6 months or 12 months, so I need an input of either 6 or 12). Or it has a default ranged that it will forecast a fix number of months. Or is it the date series that is needed to be an input, etc. etc. Thanks in advance!
Thanks!
Yes, you can specify the number of steps to forecast.
This tutorial gives an example:
https://machinelearningmastery.com/make-sample-forecasts-arima-python/
Great tutorial as always!
Thanks!
in “Box-Cox Transformed Dataset”
transform = log(x), if lambda == 0
transform = (x^lambda – 1) / lambda, if lambda != 0
when “lambda==0”, it should be “transformed=history-1”, but your code is “transformed=history”.
Is my understand wrong?
I write the wrong number
when “lambda==1”, it should be “transformed=history-1”, but your code is “transformed=history”
Why do you say that exactly?
in Section 6.4, you say lambda values are evaluated between -5 and 5, so you wrote the following code:
if lam < -5:
transformed, lam = history, 1
But according to the equation "transform = (x^lambda – 1) / lambda, if lambda != 0", Why shouldn't the code look like this:
if lam < -5:
transformed, lam = history-1, 1
From the post:
Yes, you can change it if you like.
Hi.
Amazing tutorial… awesome blog. I’m delighted with all your articles till now.
As beginner I have a question. Is related to ad fuller result, and it could be trivial because nobody asked it before, but is confusing me.
You say:
“The results show that the test statistic value -3.980946 is smaller than the critical value at 5% of -2.893.
This suggests that we can reject the null hypothesis with a significance level of less than 5%
(i.e. a low probability that the result is a statistical fluke).”
Rejecting the null hypothesis means that the process has no unit root,
and in turn that the time series is stationary or does not have time-dependent structure.
Ok Due that reason and that pValue = 0.001514 << 0.5. Then it is an stationary serie…Isn't it?
After that, The numerical values are presented, for ad fuller test
Immediately you state: "This suggests that at least one level of differencing is required."
The d parameter in our ARIMA model should at least be a value of 1.
Ok I'm agree because it runs. And acf points in that direction…
But… Why? If we need to make a diff is in order to make the serie stationary, and it was…
what am I losing?
Thank you, again for you work. It is really useful
Thanks!
Why questions are really hard. Perhaps the series was not stationary and the result was accurate and the low probability came true, or perhaps the test was a bad fit for the data for some reason I did’n think of. Or some other reason.
I prefer to focus on the pragmatic – what works – what gives a result we can use on the project now. Engineering, not science.
according to your code, i think because you have applied the first difference before doing the adf test.
Yes!!!! You are Right. Just to remove trend. That is the reason. I’ve read this article several times.. It was I had lost. Thank you
Oh!! Then can I derive that probably result of ad fuller test is not sacred? I mean it can be erroneous by several reasons and it can be convenient to do another short of test to be more confident. If It is, then you have give me a great lesson because any one trend to make a single test. Thank you.
It is a probabilistic statistical test, not ground truth.
With the line below
dataset.to_csv(‘dataset.csv’, index=False, header=False)
I get the following error
File “”, line 1
dataset.to_csv(‘dataset.csv’, index=False, header=False)
^
SyntaxError: invalid syntax
I am using Python 3 and my versions
scipy: 1.1.0
numpy: 1.15.4
matplotlib: 3.0.3
pandas: 0.23.4
sklearn: 0.20.1
statsmodels: 0.11.1
Sorry to hear that, this will help:
https://machinelearningmastery.com/faq/single-faq/why-does-the-code-in-the-tutorial-not-work-for-me
stationary.to_csv(‘stationary.csv’, header=False)
Hi Jason,
first of all I want to thank you for your clear explanations. I really like how you present the tutorial and list the different steps that one needs to take to fully develop a forecasting project.
I am currently going through your case study and I noticed that you are using the file ‘dataset.csv’ for your manually configured ARIMA model. From my understanding, this is not correct because the ARIMA model needs a stationary serie in order to work as intended. Shouldn’t we need to use the ‘stationary.csv’ dataset here?
Thank you very much again.
Cheers from Germany!
Ana Debroy
I also noticed that you are actually only using the ‘dataset.csv’ file, even after generating the ‘stationary.csv’ file.
My questions here are:
– Shouldn’t we also use the ‘stationar.csv’ for ALL code after the initial analysis of our dataset?
– And before validating the model, do we need to also differentiate the ‘validation.csv’ dataset?
From my understanding, we will get more error if we try to compare a forecast that was generated with a differentiated dataset against the validation data that was not differentiated.
Recall that ARIMA has a d parameter that can be used to difference a series and make it stationary.
We only use stationary.csv in the manually configured part of the tutorial.
Hi Jason,
thanks for another tutorial.
I wonder however if you haven’t mixed up the ACF and PACF when determining the p and q of the model.
You say the following:
“The ACF shows a significant lag for 1 month.
The PACF shows a significant lag for perhaps 2 months, with significant lags spotty out to perhaps 12 months.
Both the ACF and PACF show a drop-off at the same point, perhaps suggesting a mix of AR and MA.
A good starting point for the p and q values is 1 or 2.”
If PACF shows a significant lag for perhaps 2 months, then p value should be 2 and q should be 1 since we use PACF in order to assess p and ACF in order to assess q.
https://www.itl.nist.gov/div898/handbook/pmc/section4/pmc446.htm
regards,
Ivan.
You’re welcome.
I don’t believe so. Also see this for interpreting the terms:
https://machinelearningmastery.com/gentle-introduction-autocorrelation-partial-autocorrelation/