Often, the input features for a predictive modeling task interact in unexpected and often nonlinear ways.
These interactions can be identified and modeled by a learning algorithm. Another approach is to engineer new features that expose these interactions and see if they improve model performance. Additionally, transforms like raising input variables to a power can help to better expose the important relationships between input variables and the target variable.
These features are called interaction and polynomial features and allow the use of simpler modeling algorithms as some of the complexity of interpreting the input variables and their relationships is pushed back to the data preparation stage. Sometimes these features can result in improved modeling performance, although at the cost of adding thousands or even millions of additional input variables.
In this tutorial, you will discover how to use polynomial feature transforms for feature engineering with numerical input variables.
After completing this tutorial, you will know:
Some machine learning algorithms prefer or perform better with polynomial input features.
How to use the polynomial features transform to create new versions of input variables for predictive modeling.
How the degree of the polynomial impacts the number of input features created by the transform.
Kick-start your project with my new book Data Preparation for Machine Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
How to Use Polynomial Feature Transforms for Machine Learning Photo by D Coetzee, some rights reserved.
Tutorial Overview
This tutorial is divided into five parts; they are:
Polynomial Features
Polynomial Feature Transform
Sonar Dataset
Polynomial Feature Transform Example
Effect of Polynomial Degree
Polynomial Features
Polynomial features are those features created by raising existing features to an exponent.
For example, if a dataset had one input feature X, then a polynomial feature would be the addition of a new feature (column) where values were calculated by squaring the values in X, e.g. X^2. This process can be repeated for each input variable in the dataset, creating a transformed version of each.
As such, polynomial features are a type of feature engineering, e.g. the creation of new input features based on the existing features.
The “degree” of the polynomial is used to control the number of features added, e.g. a degree of 3 will add two new variables for each input variable. Typically a small degree is used such as 2 or 3.
Generally speaking, it is unusual to use d greater than 3 or 4 because for large values of d, the polynomial curve can become overly flexible and can take on some very strange shapes.
It is also common to add new variables that represent the interaction between features, e.g a new column that represents one variable multiplied by another. This too can be repeated for each input variable creating a new “interaction” variable for each pair of input variables.
A squared or cubed version of an input variable will change the probability distribution, separating the small and large values, a separation that is increased with the size of the exponent.
This separation can help some machine learning algorithms make better predictions and is common for regression predictive modeling tasks and generally tasks that have numerical input variables.
Typically linear algorithms, such as linear regression and logistic regression, respond well to the use of polynomial input variables.
Linear regression is linear in the model parameters and adding polynomial terms to the model can be an effective way of allowing the model to identify nonlinear patterns.
For example, when used as input to a linear regression algorithm, the method is more broadly referred to as polynomial regression.
Polynomial regression extends the linear model by adding extra predictors, obtained by raising each of the original predictors to a power. For example, a cubic regression uses three variables, X, X2, and X3, as predictors. This approach provides a simple way to provide a non-linear fit to data.
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Polynomial Feature Transform
The polynomial features transform is available in the scikit-learn Python machine learning library via the PolynomialFeatures class.
The features created include:
The bias (the value of 1.0)
Values raised to a power for each degree (e.g. x^1, x^2, x^3, …)
Interactions between all pairs of features (e.g. x1 * x2, x1 * x3, …)
For example, with two input variables with values 2 and 3 and a degree of 2, the features created would be:
1 (the bias)
2^1 = 2
3^1 = 3
2^2 = 4
3^2 = 9
2 * 3 = 6
We can demonstrate this with an example:
1
2
3
4
5
6
7
8
9
10
# demonstrate the types of features created
from numpy import asarray
from sklearn.preprocessing import PolynomialFeatures
# define the dataset
data=asarray([[2,3],[2,3],[2,3]])
print(data)
# perform a polynomial features transform of the dataset
trans=PolynomialFeatures(degree=2)
data=trans.fit_transform(data)
print(data)
Running the example first reports the raw data with two features (columns) and each feature has the same value, either 2 or 3.
Then the polynomial features are created, resulting in six features, matching what was described above.
1
2
3
4
5
6
7
[[2 3]
[2 3]
[2 3]]
[[1. 2. 3. 4. 6. 9.]
[1. 2. 3. 4. 6. 9.]
[1. 2. 3. 4. 6. 9.]]
The “degree” argument controls the number of features created and defaults to 2.
The “interaction_only” argument means that only the raw values (degree 1) and the interaction (pairs of values multiplied with each other) are included, defaulting to False.
The “include_bias” argument defaults to True to include the bias feature.
We will take a closer look at how to use the polynomial feature transforms on a real dataset.
First, let’s introduce a real dataset.
Sonar Dataset
The sonar dataset is a standard machine learning dataset for binary classification.
It involves 60 real-valued inputs and a two-class target variable. There are 208 examples in the dataset and the classes are reasonably balanced.
A baseline classification algorithm can achieve a classification accuracy of about 53.4 percent using repeated stratified 10-fold cross-validation. Top performance on this dataset is about 88 percent using repeated stratified 10-fold cross-validation.
The dataset describes radar returns of rocks or simulated mines.
max 0.137100 0.233900 0.305900 ... 0.044000 0.036400 0.043900
[8 rows x 60 columns]
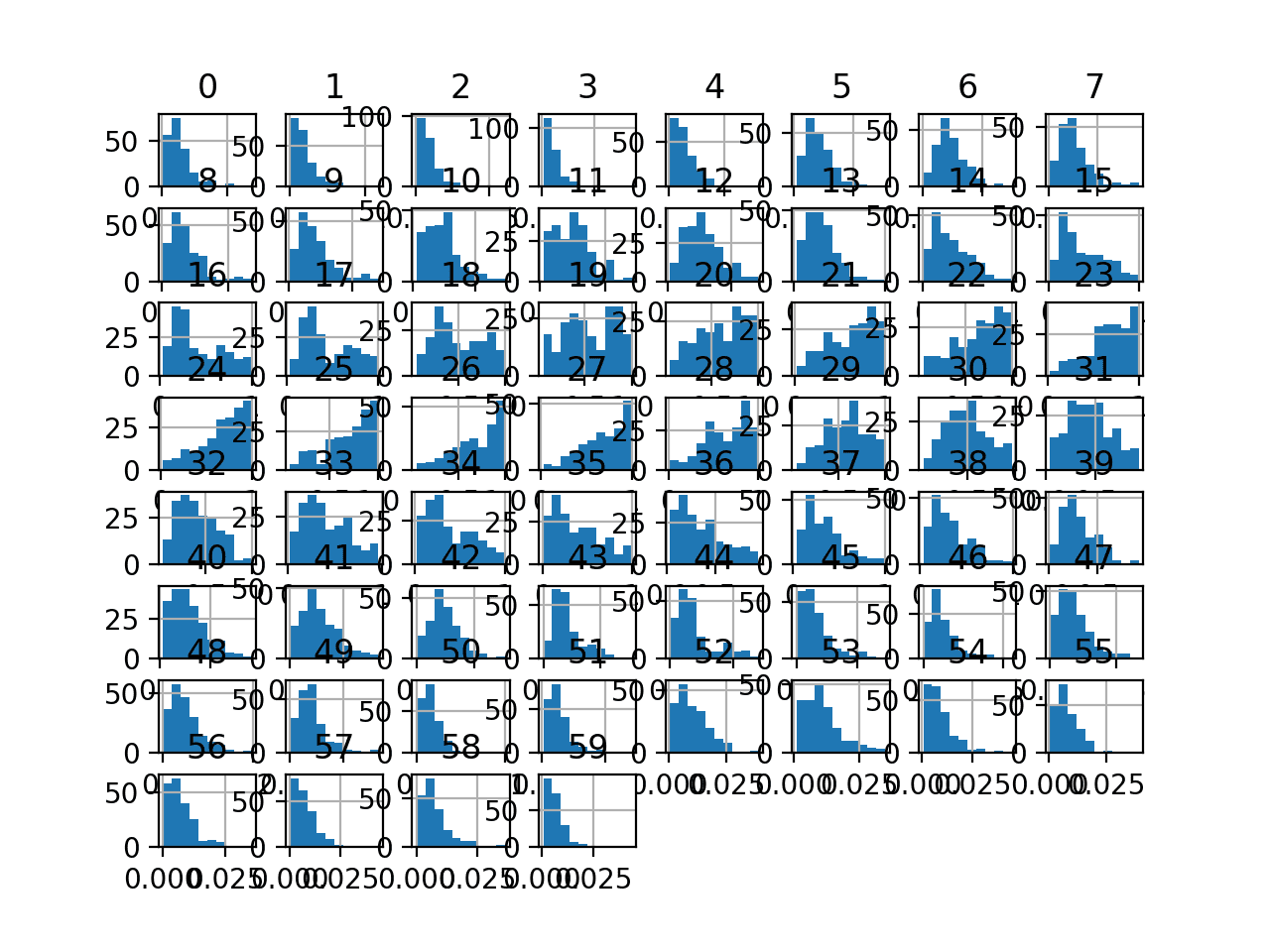
Finally, a histogram is created for each input variable.
If we ignore the clutter of the plots and focus on the histograms themselves, we can see that many variables have a skewed distribution.
Histogram Plots of Input Variables for the Sonar Binary Classification Dataset
Next, let’s fit and evaluate a machine learning model on the raw dataset.
We will use a k-nearest neighbor algorithm with default hyperparameters and evaluate it using repeated stratified k-fold cross-validation. The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# evaluate knn on the raw sonar dataset
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.neighbors import KNeighborsClassifier
Running the example evaluates a KNN model on the raw sonar dataset.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
We can see that the model achieved a mean classification accuracy of about 79.7 percent, showing that it has skill (better than 53.4 percent) and is in the ball-park of good performance (88 percent).
1
Accuracy: 0.797 (0.073)
Next, let’s explore a polynomial features transform of the dataset.
Polynomial Feature Transform Example
We can apply the polynomial features transform to the Sonar dataset directly.
In this case, we will use a degree of 3.
1
2
3
4
...
# perform a polynomial features transform of the dataset
trans=PolynomialFeatures(degree=3)
data=trans.fit_transform(data)
Let’s try it on our sonar dataset.
The complete example of creating a polynomial features transform of the sonar dataset and summarizing the created features is below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# visualize a polynomial features transform of the sonar dataset
from pandas import read_csv
from pandas import DataFrame
from pandas.plotting import scatter_matrix
from sklearn.preprocessing import PolynomialFeatures
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running the example, we can see that the polynomial features transform results in a lift in performance from 79.7 percent accuracy without the transform to about 80.0 percent with the transform.
1
Accuracy: 0.800 (0.077)
Next, let’s explore the effect of different scaling ranges.
Effect of Polynomial Degree
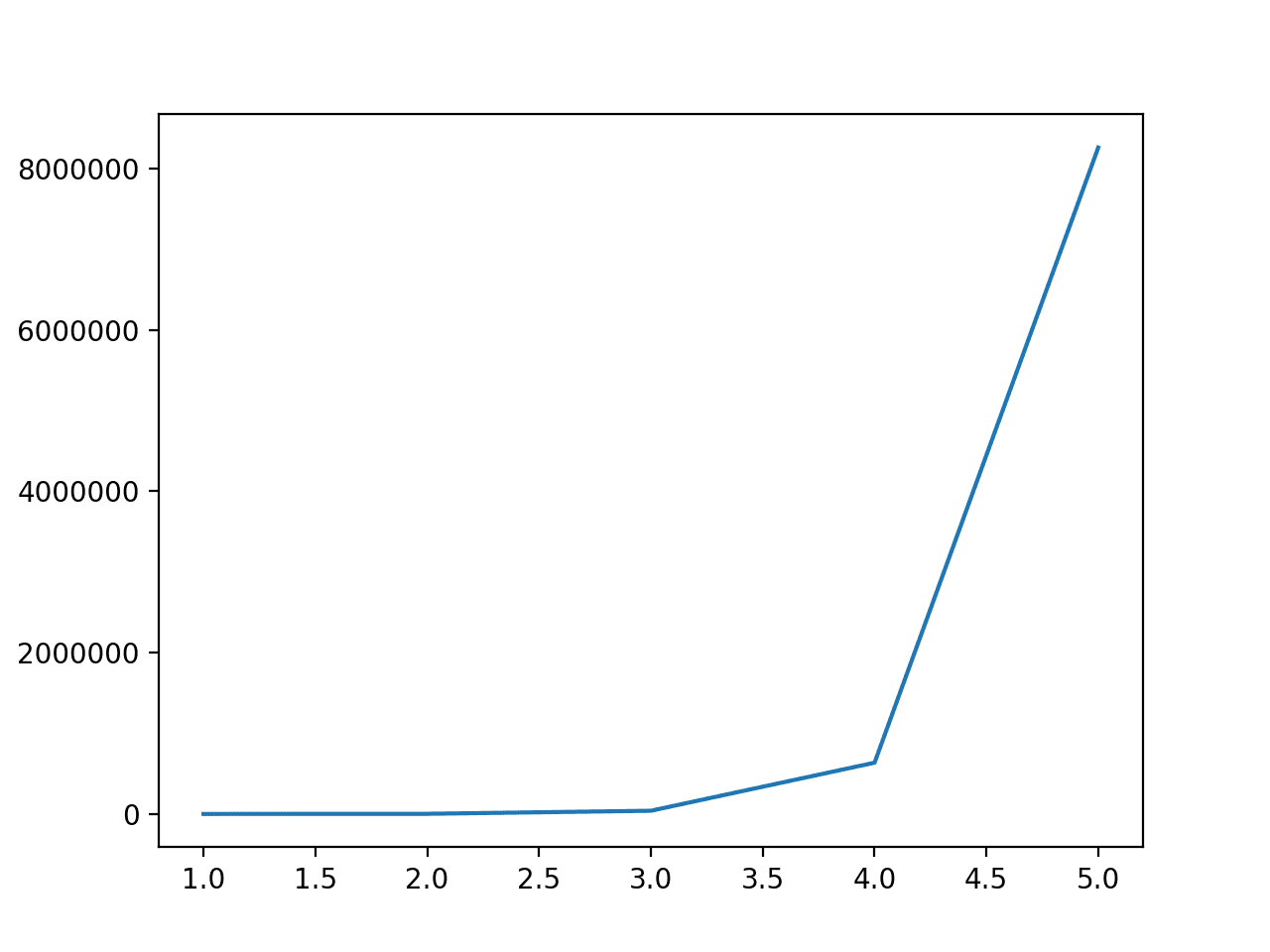
The degree of the polynomial dramatically increases the number of input features.
To get an idea of how much this impacts the number of features, we can perform the transform with a range of different degrees and compare the number of features in the dataset.
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# compare the effect of the degree on the number of created features
from pandas import read_csv
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import PolynomialFeatures
Running the example reports the mean classification accuracy for each polynomial degree.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that performance is generally worse than no transform (degree 1) except for a degree 3.
It might be interesting to explore scaling the data before or after performing the transform to see how it impacts model performance.
1
2
3
4
>1 0.797 (0.073)
>2 0.793 (0.085)
>3 0.800 (0.077)
>4 0.795 (0.079)
Box and whisker plots are created to summarize the classification accuracy scores for each polynomial degree.
We can see that performance remains flat, perhaps with the first signs of overfitting with a degree of 4.
Box Plots of Degree for the Polynomial Feature Transform vs. Classification Accuracy of KNN on the Sonar Dataset
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
It provides self-study tutorials with full working code on: Feature Selection, RFE, Data Cleaning, Data Transforms, Scaling, Dimensionality Reduction,
and much more...
Bring Modern Data Preparation Techniques to Your Machine Learning Projects
This case study is not convincing regarding the benefits of polynomial models.
You started with 200 datapoints and 60 variables. After adding 1000+ variables you raised model accuracy by 0.3%.
1: This level of increase can be achieved by chance, i.e. just retraining the original model.
2: There is no holdout set cv. Realistically you’d have 150 observations to model with and most models would overfit without feature selection.
3: It demonstrates well how OO nature of python modules is cumbersome for statistical workflows. The same can be done in R using half the LOC and twice the readability.
Yes, the same transform object must be used for the train and test datasets. E.g. it is fit on the training set and applied to the train and test sets.
your blog posts are incredibly interesting for a practitioner like me! This time I have a question: does the polynomial feature transform not introduce multicollinearity (e.g. correlation between x and x^2), which in turn could lead to model performance degradation?
Dear Dr Jason,
I have to say that I didn’t understand the patterns produced by the transforms of PolynomialFeatures.
I did the following with interactions and polynomials and interactions only using the array [1,2,3,4]
1
2
3
4
5
6
7
8
9
10
from numpy import asarray
from sklearn.preprocessing import PolynomialFeatures
# define the dataset
data=asarray([[1,2,3,4]])
# perform a polynomial features transform of the dataset
Dear Dr Jason,
I was experimenting with the code under the subheading “Polynomial Feature Transform Example” which is also in Listing 23.10, page 310 (327 of 398) of your book.
Note I did not use the pipeline since BUT I used the transformed polynomial features X2.
I still got the same result.
1
2
3
# report pipeline performance
mean(n_scores),std(n_scores)
(0.799920634920635,0.07675259734559173)
The question is: In the original code the pipeline seemed to have performed the PolynomialFeatures function of degree 3 without putting the transformed(X) = X2 into the cross_val_score function.
Put it another way, in the original code, how is that pipeline managed to calculate the transformed featurs without using the transformed features in the cross_val_score. Yet I got the same result.
Dear Dr Jason,
“The pipeline performs the transform to the input data, and the transformed data is then passed to the model.”
The issue was clarified
Thank you.
Anthony of Sydney.
Hi Jason,
Thank you for the article, it’s very informative. My question is in regards to the application of this technique. Should the conversion of features to a polynomial be used for regression problems or can they be used for classification problems as well?
Thank you,
Bill
I have a question. What is the correct order to make in the Pipeline: StandardScale and Polynomial Features or Polynomial Features and StandardScale? I’m confused about that.
Hi, I have only 1 independent feature which exhibit non linear relationship with the target, should I create polynomial features from that independent variable for tree based model?
I created polynomial features upto degree 4 and they improved my linear regression model R2 score significantly (validated by Cross Validation). However my question is that the newly created polynomial features are highly correlated to the original feature from which they are generated with pearson correlation values above 0.80. Isn’t it lead to multicollinearity problem? Or is it acceptable to accept the results of the model?
Dear Jason thanks a lot for your advice. I have another question please. You mentioned with a book reference that “for large values of d (degree) the polynomial curves becomes overly flexible and can take very strange shapes”. My question is for large value of d say 5, if the linear model performance is increasing plus i do not see any abnormality in the regression line, can we keep those features to build the model?
Actually in my case i have 13 features, i find out the most important feature, created 5 degree polynomial features from that single most important feature, observed considerable improvement in model performance till d=5 , and it started reducing at d=6.. I hope you understand my question. thanks in advance.
Hi Jason, I have a question please. What if I created a polynomial feature having VIF=5.6, p-value=0.7 facilitated to improve the Adj. R2 by 2.5%. How do I can interpret such feature?
Thanks please.
but Jason Brownlee wrote above:
“For example, with two input variables with values 2 and 3 and a degree of 2, the features created would be:
1 (the bias)
2^1 = 2
3^1 = 3
2^2 = 4
3^2 = 9
2 * 3 = 6”
I have generated new features through polynomial degree =2, now should I replace/discard original features or should keep all features and their poly features for regression

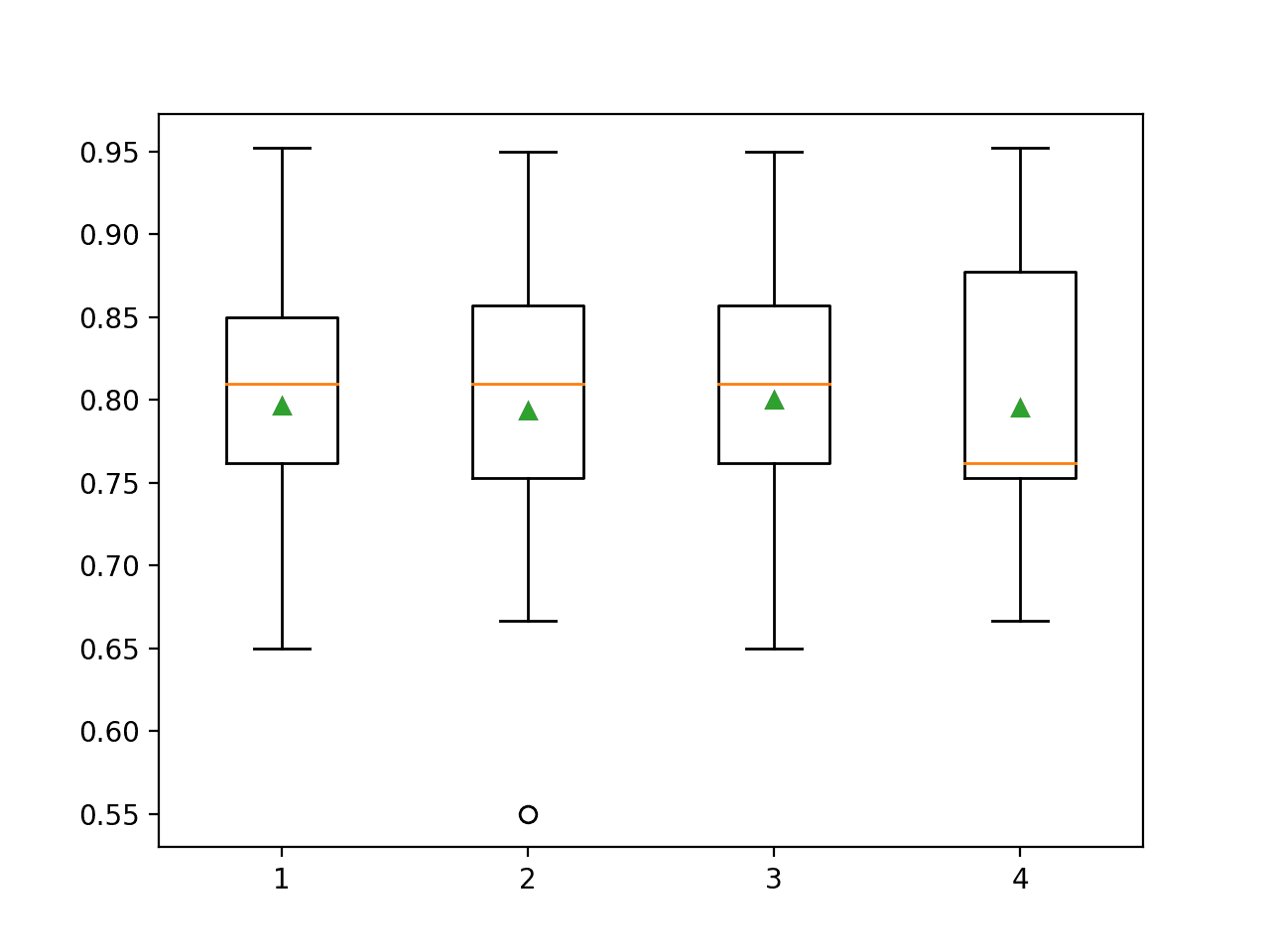







Hello, again 🙂
I am using feedforward neural network as a regression by using (5 input features/ sensors readings).
I want to try Polynomial Feature Transform for this project to create more input features
My question is:
Can I do (RobustScaler) or (StandardScaler) after doing PolynomialFeatures?
Thank you very much
Yes.
One approach would be to apply the transforms as part of a pipeline to your dataset, then provide the data to the model.
This case study is not convincing regarding the benefits of polynomial models.
You started with 200 datapoints and 60 variables. After adding 1000+ variables you raised model accuracy by 0.3%.
1: This level of increase can be achieved by chance, i.e. just retraining the original model.
2: There is no holdout set cv. Realistically you’d have 150 observations to model with and most models would overfit without feature selection.
3: It demonstrates well how OO nature of python modules is cumbersome for statistical workflows. The same can be done in R using half the LOC and twice the readability.
Yes, I could make a better case. Thanks for the feedback.
Hello Jason,
Is it possible to perform polynomial regression with Keras?
Do you have any easy example?
Thanks
Marco
Yes, you can generate the features then pass them to your keras model.
No, I don’t have an example but it should be straightforward.
Thanks for your sharing,
If we want to make predictions, should we also implement the Polynomial Feature Transform for the test data?
Thanks again
Yes, the same transform object must be used for the train and test datasets. E.g. it is fit on the training set and applied to the train and test sets.
Hello Jason,
your blog posts are incredibly interesting for a practitioner like me! This time I have a question: does the polynomial feature transform not introduce multicollinearity (e.g. correlation between x and x^2), which in turn could lead to model performance degradation?
Many thanks
Thanks.
It may which could impact some linear models.
Dear Dr Jason,
I have to say that I didn’t understand the patterns produced by the transforms of PolynomialFeatures.
I did the following with interactions and polynomials and interactions only using the array [1,2,3,4]
With the assistance of the 2nd answer of https://stackoverflow.com/questions/51906274/cannot-understand-with-sklearns-polynomialfeatures you get the following pattern.
Then fit_transform(data) produces the form
If you exclude the the squares of a^2, b^2, c^2 and d^2.
Which is of the type:
What of degree 3 and 2 values, eg data = [a,b]
Number of transformed outputs = (n + d)!/(n! * d!) where n = number of numbers, d = degree of polynomial.
Eg number of numbers = 3, degree of polynomial = 2,
number of transformed outputs = (n + d)! / (n! * d!) = 5!/(3! * 2!) =10
Eg number of numbers = 2, degree of polynomial = 3
number of transformed outputs = 5!/(2!*3!) = 10
Thank you,
Anthony of Sydney
Thanks for sharing your findings.
Dear Dr Jason,
I was experimenting with the code under the subheading “Polynomial Feature Transform Example” which is also in Listing 23.10, page 310 (327 of 398) of your book.
The particular lines of interest are:
I ask the question “,,,why didn’t the author transform by
and feed that into the cross_val_score?
Note I did not use the pipeline since BUT I used the transformed polynomial features X2.
I still got the same result.
The question is: In the original code the pipeline seemed to have performed the PolynomialFeatures function of degree 3 without putting the transformed(X) = X2 into the cross_val_score function.
Put it another way, in the original code, how is that pipeline managed to calculate the transformed featurs without using the transformed features in the cross_val_score. Yet I got the same result.
Thank you,
Anthony of Sydney
The pipeline performs the transform to the input data, and the transformed data is then passed to the model.
You can learn more about how pipelines work here:
https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.Pipeline.html
Dear Dr Jason,
“The pipeline performs the transform to the input data, and the transformed data is then passed to the model.”
The issue was clarified
Thank you.
Anthony of Sydney.
Happy to hear that.
Hi Jason,
Thank you for the article, it’s very informative. My question is in regards to the application of this technique. Should the conversion of features to a polynomial be used for regression problems or can they be used for classification problems as well?
Thank you,
Bill
Polynomial features can help on regression and classification tasks, perhaps try and compare to results of the same model without polynomial features.
Hi Jason,
I have a question. What is the correct order to make in the Pipeline: StandardScale and Polynomial Features or Polynomial Features and StandardScale? I’m confused about that.
My advice would be to test to see if it makes a difference.
My gut says in this case it probably does not matter.
Got it! Thank you so much! Your website is awesome!
You’re welcome.
Thanks!
Hi, I have only 1 independent feature which exhibit non linear relationship with the target, should I create polynomial features from that independent variable for tree based model?
Perhaps try it and compare results to other methods.
I created polynomial features upto degree 4 and they improved my linear regression model R2 score significantly (validated by Cross Validation). However my question is that the newly created polynomial features are highly correlated to the original feature from which they are generated with pearson correlation values above 0.80. Isn’t it lead to multicollinearity problem? Or is it acceptable to accept the results of the model?
It may be.
Focus on model performance. If the model performs better, then keep the new features.
Dear Jason thanks a lot for your advice. I have another question please. You mentioned with a book reference that “for large values of d (degree) the polynomial curves becomes overly flexible and can take very strange shapes”. My question is for large value of d say 5, if the linear model performance is increasing plus i do not see any abnormality in the regression line, can we keep those features to build the model?
Actually in my case i have 13 features, i find out the most important feature, created 5 degree polynomial features from that single most important feature, observed considerable improvement in model performance till d=5 , and it started reducing at d=6.. I hope you understand my question. thanks in advance.
Sure, use whatever works best for your data and test harness. Ensure your test harness is robust so that you don’t trick yourself.
Thanks a lot for your replies. Highly appreciate your awesome articles always.
Thanks.
Hi Jason, I have a question please. What if I created a polynomial feature having VIF=5.6, p-value=0.7 facilitated to improve the Adj. R2 by 2.5%. How do I can interpret such feature?
Thanks please.
Sorry, I try to avoid interpreting results for readers.
Perhaps compare results to other methods and use what works best or looks more reliable for your specific application.
Thanks for your quick reply. I appreciate it. Your comments are valuable for learners like me.
You’re welcome.
Your articles are really fantastic and full of details and explanations and examples. you are the Jedi Master! 😀
Thanks!
with 2 input variables with values 2,3,4 and a degree of 2. Which is the order output variables?
Maybe this?
1 (the bias)
2^1
3^1
4^1
2^2
3^2
4^2
2*3
3*4
Try to replace
data = asarray([[2,3,4],[2,3,4]])
and you will see it is:
1, 2^1, 3^1, 4^1, 2^2, 2*3, 2*4, 3^2, 3*4, 4^2
but Jason Brownlee wrote above:
“For example, with two input variables with values 2 and 3 and a degree of 2, the features created would be:
1 (the bias)
2^1 = 2
3^1 = 3
2^2 = 4
3^2 = 9
2 * 3 = 6”
So, it seems the interactions are the last.
You look at the output of the code, not the bullet points, you will see it was in the order [2,3,4,6,9] instead.
I have generated new features through polynomial degree =2, now should I replace/discard original features or should keep all features and their poly features for regression
Hi Salaf…The following may be of interest to you for understanding transformations of datasets in general:
https://machinelearningmastery.com/how-to-improve-neural-network-stability-and-modeling-performance-with-data-scaling/