5-Steps To Get Started and Get Good at Machine Learning
I teach a 5-step process that you can use to get your start in applied machine learning.
It is unconventional.
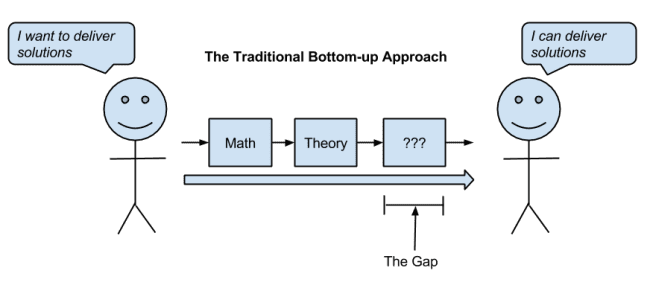
The traditional way to teach machine learning is bottom-up.
Start with the theory and math, then algorithm implementations, then send you off to figure out how to start solving real-world problems.
The traditional approach to getting started in machine learning has a gap on the path to practitioner.
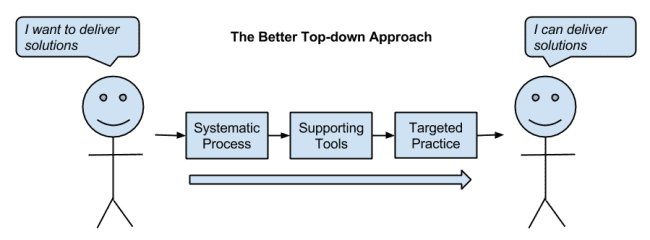
The Machine Learning Mastery approach flips this and starts with the outcome that is most valuable.
It targets the outcome that business wants to pay for: how to deliver a result.
A result in the form of a set of predictions or model that can reliably make predictions.
This is a top-down and results-first approach.
Starting with the goal of achieving the result that is most desirable in the marketplace, what is the shortest path to take you, the practitioner, to that result?
Do you want to reliably get above average results on problem after problem?
You need to follow a systematic process.
A process allows you to harness and reuse best practices.
It means you don’t have to rely on memory or intuition.
It guides you through a project end-to-end.
It means that you always know what to do next.
It can be tailored to your specific problem types and tools.
A systematic process is the difference between a roller coaster of good and bad results on the one hand and above average and forever improving results on the other.
I would choose above average and forever improving results every time.
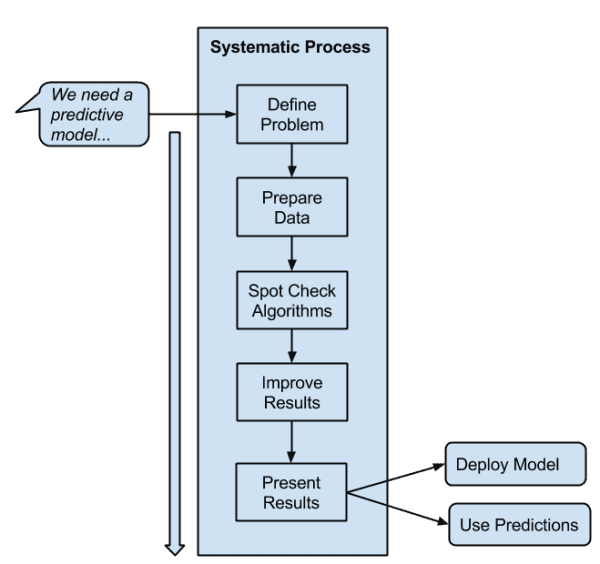
A process template that I recommend is as follows:
Step 1: Define your problem.
Step 2: Prepare your data.
Step 3: Spot-check algorithms.
Step 4: Improve results.
Step 5: Present results.
Below is a nice cartoon to summarize this systematic process:
Select a systematic and repeatable process that you can use to deliver results consistently.
You can learn more about this process in the post:
You do not have to use this process, but you do need a systematic process for working through predictive modeling problems.
Step 3: Pick a Tool
Pick a best-of-breed tool that you can use to deliver machine learning results.
Map your process onto the tool and learn how to use it most effectively.
There are three tools I recommend the most:
Weka Machine Learning Workbench (Perfect for beginners). Weka offers a GUI interface and no code is required. I use it for quick one-off modeling problems.
Python Ecosystem (Perfect for intermediate). Specifically pandas and scikit-learn on top of the SciPy platform. You can use the same code and models in development and they are reliable enough to run in operations.
R Platform (Perfect for advanced). R was designed for statistical computing, and although the language is arcane and some of the packages are poorly documented, it offers the most methods as well as state of the art techniques.
Keras for Deep Learning. It uses Python meaning you can leverage the whole Python ecosystem which saves a lot of time. The interface is very clean, whilst also supporting the power of the Theano and Keras back-ends.
XGBoost for Gradient Boosting. It is the fastest implementation of the technique around. It also supports both R and Python allowing you to leverage either platform in your project.
Once you have a process and a tool, you need to practice.
You need to practice a lot.
Practice on standard machine learning datasets.
Use real-world datasets, collected from an actual problem domain (rather than contrived).
Use small datasets that fit into memory or an excel spreadsheet.
Use well-understood datasets so you know what kind of results to expect.
Practice on different types of datasets. Practice on problems that make you uncomfortable as you will have to push your skills to get a solution. Seek out different traits in data problems, such as:
Different types of supervised learning such as classification and regression.
Different sized datasets from tens, hundreds, thousands and millions of instances.
Different numbers of attributes from less than ten, tens, hundreds and thousands of attributes.
Different attribute types from real, integer, categorical, ordinal and mixtures.
Different domains that force you to quickly understand and characterize a new problem in which you have no previous experience.
Use the UCI Machine Learning Repository
These are the most used and best-understood datasets and the best place to start.
I am a research student, Im working on ML using MATLAB, any advice on how to learn good programming skills in MATLAB? Im completely new to this field..I am trying to make a hybrid model with an optimization algorithm and ML. I have codes for both but dont know how to go further.
Thanks in advance.
I think matlab is great for developing strong linear algebra skills and multivariate statistics. It might be the best environment to study these things.
I also think that if you want to learn ML algorithms from these two perspectives that it is the best place to be. But it is not the fastest way to learn about algorithms or the only approach.
If you take this slower first-principles approach you will need to do a lot of reading on the optimization algorithms and math you are using to learn how to integrate them.
wonderful guide, I like this approach and I’ll put it to action right now. I would like hear from you when it’s the right time to start participating in kaggle competitions?
Great site and great resources. I purchased the machine learning mastery with R and it really does help with the concepts. Especially towards the end when I do the projects from beginning to end, does it really then come together.
I did want to ask this though: do you have any suggestions about the next logical step, which is translating the data to a business person(I,e, your boss, who is not a machine learner)?
Suppose I go through the entire process, find a good algorithm that works on my test data, and run it against a ‘truly live’ unknown data, what is the next step? Are their probabilities assigned to my results or to each variables or is it just ‘based on my algorithm, “most likely”, this will happen.
Not really sure how to frame the newly learned knowledge.
Maybe this is something you can add in the next book update?
Your tutorials are very information. Beginners like me feel lost in the jungle of academic resources while figuring out what to learn especially in the case of machine learning. Thank you for providing proper guidance.
Can you provide intuitive and easy to learn resources for getting started in scikit-learn, numpy and matplotlib.?Official documentation seems to be very formal just like an academic paper.
In your opinion, once you finished a portfolio project that is well commented and structured in a Jupyter notebook, what is the best way to write a readme file to include with the notebook? What should one include in that file?
Thanks Jason! This is an outstanding example of how many years of work and resurch can be summarized into just few pages perfect suitable for begginers. Really well thought out.
This is pure genius! I have never found any blog or website such helpful. After completing GRE and TOEFL, I am bewildered to find my area of interest. Now it feels like Machine Learning is an area I should try at least.
Thanks, Jason!
May God be with you so that you can continue doing such wonderful things.
Hi Jason, of course, you have the best content related to the field of machine learning on the internet. However, I am unable to find tips about “how to get hired” in this field. Will you also please elaborate on some information about the corporate of this industry? Like, for a beginner, either we have to apply for small start-ups or big tech giants. Thanks in advance.





")
")
Hi Jason, Thanks for sharing. A great content for beginners.
Thanks Mrutyunjaya.
Dear Jason Brownlee,
Really awesome guide to take start of Machine Learning!
APPRECIATED
Thanks.
awesome guide…helped a lot………
I’m glad it helped neelam.
This is pure gold! Thanks.
I’m glad you liked it Adolfo.
yes…!!! really
Thanks!
Awesome post. Thanks for breaking down the steps so clearly.
This really give me hope that ML is doable 🙂
I’m glad you found it useful Debs.
Big thanks Jason..wonderful for beginners.
I’m glad you found it useful Beena.
Great article..
I am a research student, Im working on ML using MATLAB, any advice on how to learn good programming skills in MATLAB? Im completely new to this field..I am trying to make a hybrid model with an optimization algorithm and ML. I have codes for both but dont know how to go further.
Thanks in advance.
Hi Sarah,
I think matlab is great for developing strong linear algebra skills and multivariate statistics. It might be the best environment to study these things.
I also think that if you want to learn ML algorithms from these two perspectives that it is the best place to be. But it is not the fastest way to learn about algorithms or the only approach.
If you take this slower first-principles approach you will need to do a lot of reading on the optimization algorithms and math you are using to learn how to integrate them.
Jason thanks for sharing
I’m glad you liked it Jonathan.
Do you think you will follow this approach?
wonderful guide, I like this approach and I’ll put it to action right now. I would like hear from you when it’s the right time to start participating in kaggle competitions?
Great to hear David!
I recommend getting started with Kaggle after you have confidence with the smaller datasets on the UCI ML Repository.
Great site and great resources. I purchased the machine learning mastery with R and it really does help with the concepts. Especially towards the end when I do the projects from beginning to end, does it really then come together.
I did want to ask this though: do you have any suggestions about the next logical step, which is translating the data to a business person(I,e, your boss, who is not a machine learner)?
Suppose I go through the entire process, find a good algorithm that works on my test data, and run it against a ‘truly live’ unknown data, what is the next step? Are their probabilities assigned to my results or to each variables or is it just ‘based on my algorithm, “most likely”, this will happen.
Not really sure how to frame the newly learned knowledge.
Maybe this is something you can add in the next book update?
Great suggestion Lau.
This post may help as a start:
https://machinelearningmastery.com/how-to-use-machine-learning-results/
I agree, this topic needs it’s own book.
Your tutorials are very information. Beginners like me feel lost in the jungle of academic resources while figuring out what to learn especially in the case of machine learning. Thank you for providing proper guidance.
Can you provide intuitive and easy to learn resources for getting started in scikit-learn, numpy and matplotlib.?Official documentation seems to be very formal just like an academic paper.
Start here:
https://machinelearningmastery.com/start-here/#python
I’m glad to hear it Madhav.
Oh God, What a great resource!!!
Thanks Jason!!!
I’m glad it helps. Hang in there!
Thanks Jason for the informative post ????
In your opinion, once you finished a portfolio project that is well commented and structured in a Jupyter notebook, what is the best way to write a readme file to include with the notebook? What should one include in that file?
Describe what the project is all about, the problem, the solution, your findings, extensions, etc.
Thanks Jason! This is an outstanding example of how many years of work and resurch can be summarized into just few pages perfect suitable for begginers. Really well thought out.
Thanks, I hope it helps.
Absolute gold standard guide. Many thanks Jason
Thanks!
This is pure genius! I have never found any blog or website such helpful. After completing GRE and TOEFL, I am bewildered to find my area of interest. Now it feels like Machine Learning is an area I should try at least.
Thanks, Jason!
May God be with you so that you can continue doing such wonderful things.
Thanks, I’m happy that the post was useful.
Hi Jason, of course, you have the best content related to the field of machine learning on the internet. However, I am unable to find tips about “how to get hired” in this field. Will you also please elaborate on some information about the corporate of this industry? Like, for a beginner, either we have to apply for small start-ups or big tech giants. Thanks in advance.
I don’t give hiring advice, sorry.
Thanks!!
You’re welcome.
Thanks and it’s great content for people who want to start their journey in ML world
You are welcome Suresh! The following location is a great starting point for your machine learning journey:
https://machinelearningmastery.com/start-here/