Cancer detection is a popular example of an imbalanced classification problem because there are often significantly more cases of non-cancer than actual cancer.
A standard imbalanced classification dataset is the mammography dataset that involves detecting breast cancer from radiological scans, specifically the presence of clusters of microcalcifications that appear bright on a mammogram. This dataset was constructed by scanning the images, segmenting them into candidate objects, and using computer vision techniques to describe each candidate object.
It is a popular dataset for imbalanced classification because of the severe class imbalance, specifically where 98 percent of candidate microcalcifications are not cancer and only 2 percent were labeled as cancer by an experienced radiographer.
In this tutorial, you will discover how to develop and evaluate models for the imbalanced mammography cancer classification dataset.
After completing this tutorial, you will know:
How to load and explore the dataset and generate ideas for data preparation and model selection.
How to evaluate a suite of machine learning models and improve their performance with data cost-sensitive techniques.
How to fit a final model and use it to predict class labels for specific cases.
Kick-start your project with my new book Imbalanced Classification with Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Develop an Imbalanced Classification Model to Detect Microcalcifications Photo by Bernard Spragg. NZ, some rights reserved.
Tutorial Overview
This tutorial is divided into five parts; they are:
Mammography Dataset
Explore the Dataset
Model Test and Baseline Result
Evaluate Models
Evaluate Machine Learning Algorithms
Evaluate Cost-Sensitive Algorithms
Make Predictions on New Data
Mammography Dataset
In this project, we will use a standard imbalanced machine learning dataset referred to as the “mammography” dataset or sometimes “Woods Mammography.”
The focus of the problem is on detecting breast cancer from radiological scans, specifically the presence of clusters of microcalcifications that appear bright on a mammogram.
The dataset involved first started with 24 mammograms with a known cancer diagnosis that were scanned. The images were then pre-processed using image segmentation computer vision algorithms to extract candidate objects from the mammogram images. Once segmented, the objects were then manually labeled by an experienced radiologist.
A total of 29 features were extracted from the segmented objects thought to be most relevant to pattern recognition, which was reduced to 18, then finally to seven, as follows (taken directly from the paper):
Area of object (in pixels).
Average gray level of the object.
Gradient strength of the object’s perimeter pixels.
Root mean square noise fluctuation in the object.
Contrast, average gray level of the object minus the average of a two-pixel wide border surrounding the object.
A low order moment based on shape descriptor.
There are two classes and the goal is to distinguish between microcalcifications and non-microcalcifications using the features for a given segmented object.
Non-microcalcifications: negative case, or majority class.
Microcalcifications: positive case, or minority class.
A number of models were evaluated and compared in the original paper, such as neural networks, decision trees, and k-nearest neighbors. Models were evaluated using ROC Curves and compared using the area under ROC Curve, or ROC AUC for short.
ROC Curves and area under ROC Curves were chosen with the intent to minimize the false-positive rate (complement of the specificity) and maximize the true-positive rate (sensitivity), the two axes of the ROC Curve. The use of the ROC Curves also suggests the desire for a probabilistic model from which an operator can select a probability threshold as the cut-off between the acceptable false positive and true positive rates.
Their results suggested a “linear classifier” (seemingly a Gaussian Naive Bayes classifier) performed the best with a ROC AUC of 0.936 averaged over 100 runs.
Next, let’s take a closer look at the data.
Want to Get Started With Imbalance Classification?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Explore the Dataset
The Mammography dataset is a widely used standard machine learning dataset, used to explore and demonstrate many techniques designed specifically for imbalanced classification.
We can see that the dataset has six rather than the seven input variables. It is possible that the first input variable listed in the paper (area in pixels) was removed from this version of the dataset.
The input variables are numerical (real-valued) and the target variable is the string with ‘-1’ for the majority class and ‘1’ for the minority class. These values will need to be encoded as 0 and 1 respectively to meet the expectations of classification algorithms on binary imbalanced classification problems.
The dataset can be loaded as a DataFrame using the read_csv() Pandas function, specifying the location and the fact that there is no header line.
1
2
3
4
5
...
# define the dataset location
filename='mammography.csv'
# load the csv file as a data frame
dataframe=read_csv(filename,header=None)
Once loaded, we can summarize the number of rows and columns by printing the shape of the DataFrame.
1
2
3
...
# summarize the shape of the dataset
print(dataframe.shape)
We can also summarize the number of examples in each class using the Counter object.
Running the example first loads the dataset and confirms the number of rows and columns, that is 11,183 rows and six input variables and one target variable.
The class distribution is then summarized, confirming the severe class imbalanced with approximately 98 percent for the majority class (no cancer) and approximately 2 percent for the minority class (cancer).
1
2
3
(11183, 7)
Class='-1', Count=10923, Percentage=97.675%
Class='1', Count=260, Percentage=2.325%
The dataset appears to generally match the dataset described in the SMOTE paper. Specifically in terms of the ratio of negative to positive examples.
A typical mammography dataset might contain 98% normal pixels and 2% abnormal pixels.
Also, the specific number of examples in the minority and majority classes also matches the paper.
The experiments were conducted on the mammography dataset. There were 10923 examples in the majority class and 260 examples in the minority class originally.
I believe this is the same dataset, although I cannot explain the mismatch in the number of input features, e.g. six compared to seven in the original paper.
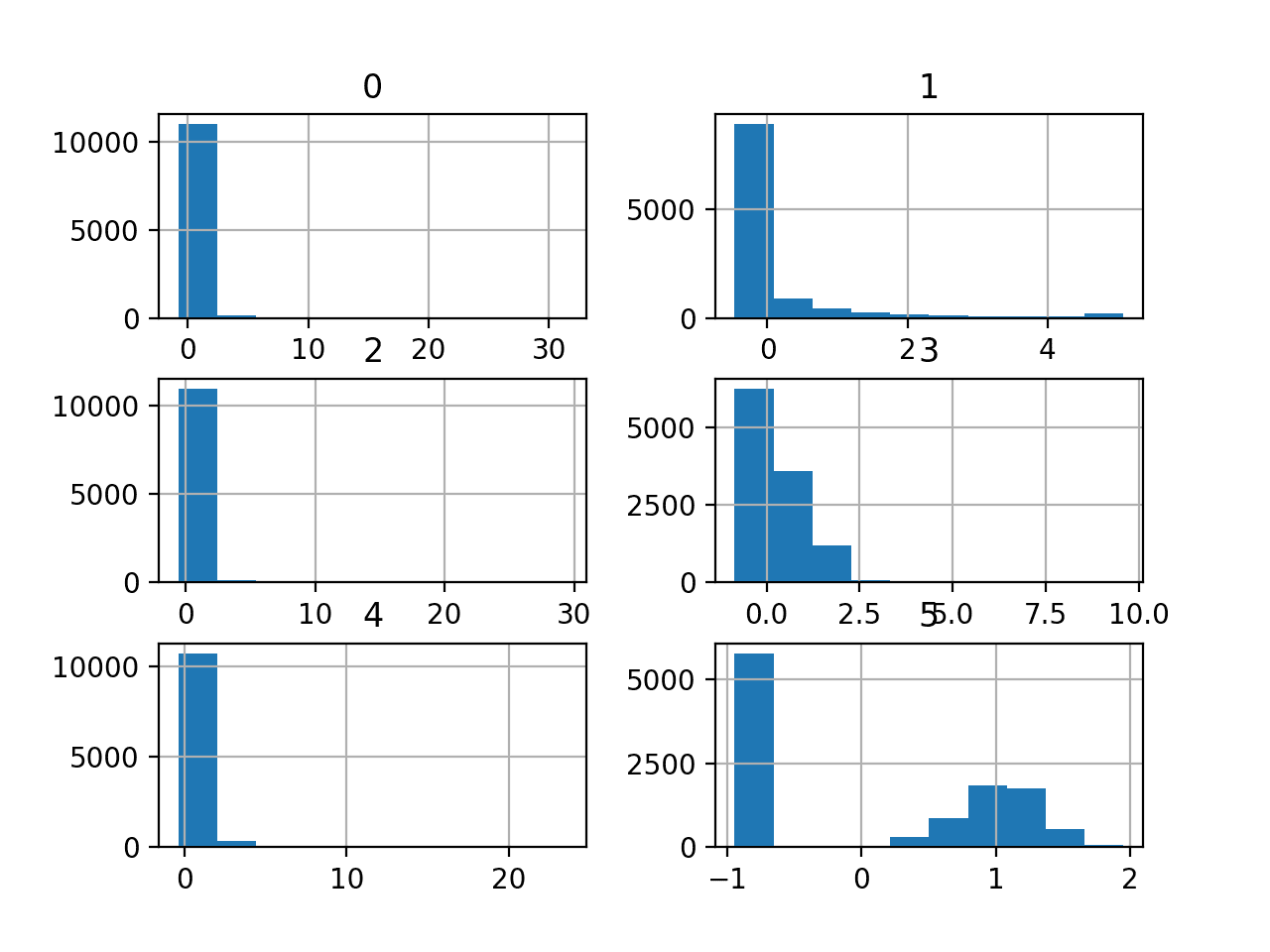
We can also take a look at the distribution of the six numerical input variables by creating a histogram for each.
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
# create histograms of numeric input variables
from pandas import read_csv
from matplotlib import pyplot
# define the dataset location
filename='mammography.csv'
# load the csv file as a data frame
df=read_csv(filename,header=None)
# histograms of all variables
df.hist()
pyplot.show()
Running the example creates the figure with one histogram subplot for each of the six numerical input variables in the dataset.
We can see that the variables have differing scales and that most of the variables have an exponential distribution, e.g. most cases falling into one bin, and the rest falling into a long tail. The final variable appears to have a bimodal distribution.
Depending on the choice of modeling algorithms, we would expect scaling the distributions to the same range to be useful, and perhaps the use of some power transforms.
Histogram Plots of the Numerical Input Variables for the Mammography Dataset
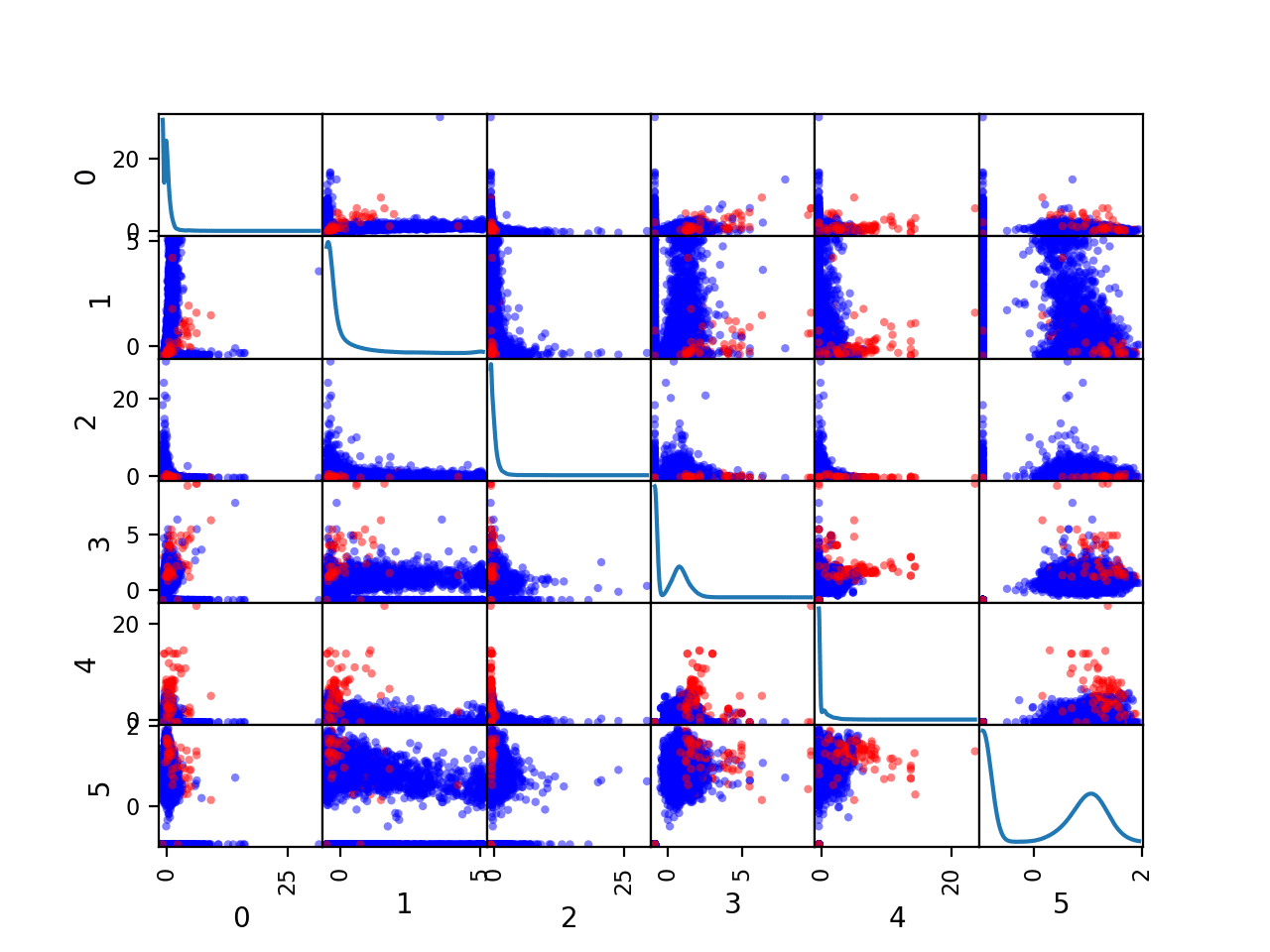
We can also create a scatter plot for each pair of input variables, called a scatter plot matrix.
This can be helpful to see if any variables relate to each other or change in the same direction, e.g. are correlated.
We can also color the dots of each scatter plot according to the class label. In this case, the majority class (no cancer) will be mapped to blue dots and the minority class (cancer) will be mapped to red dots.
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# create pairwise scatter plots of numeric input variables
from pandas import read_csv
from pandas.plotting import scatter_matrix
from matplotlib import pyplot
# define the dataset location
filename='mammography.csv'
# load the csv file as a data frame
df=read_csv(filename,header=None)
# define a mapping of class values to colors
color_dict={"'-1'":'blue',"'1'":'red'}
# map each row to a color based on the class value
colors=[color_dict[str(x)]forxindf.values[:,-1]]
# pairwise scatter plots of all numerical variables
scatter_matrix(df,diagonal='kde',color=colors)
pyplot.show()
Running the example creates a figure showing the scatter plot matrix, with six plots by six plots, comparing each of the six numerical input variables with each other. The diagonal of the matrix shows the density distribution of each variable.
Each pairing appears twice both above and below the top-left to bottom-right diagonal, providing two ways to review the same variable interactions.
We can see that the distributions for many variables do differ for the two-class labels, suggesting that some reasonable discrimination between the cancer and no cancer cases will be feasible.
Scatter Plot Matrix by Class for the Numerical Input Variables in the Mammography Dataset
Now that we have reviewed the dataset, let’s look at developing a test harness for evaluating candidate models.
Model Test and Baseline Result
We will evaluate candidate models using repeated stratified k-fold cross-validation.
The k-fold cross-validation procedure provides a good general estimate of model performance that is not too optimistically biased, at least compared to a single train-test split. We will use k=10, meaning each fold will contain about 11183/10 or about 1,118 examples.
Stratified means that each fold will contain the same mixture of examples by class, that is about 98 percent to 2 percent no-cancer to cancer objects. Repetition indicates that the evaluation process will be performed multiple times to help avoid fluke results and better capture the variance of the chosen model. We will use three repeats.
This means a single model will be fit and evaluated 10 * 3 or 30 times and the mean and standard deviation of these runs will be reported.
We will evaluate and compare models using the area under ROC Curve or ROC AUC calculated via the roc_auc_score() function.
We can define a function to load the dataset and split the columns into input and output variables. We will correctly encode the class labels as 0 and 1. The load_dataset() function below implements this.
1
2
3
4
5
6
7
8
9
10
11
# load the dataset
def load_dataset(full_path):
# load the dataset as a numpy array
data=read_csv(full_path,header=None)
# retrieve numpy array
data=data.values
# split into input and output elements
X,y=data[:,:-1],data[:,-1]
# label encode the target variable to have the classes 0 and 1
y=LabelEncoder().fit_transform(y)
returnX,y
We can then define a function that will evaluate a given model on the dataset and return a list of ROC AUC scores for each fold and repeat.
The evaluate_model() function below implements this, taking the dataset and model as arguments and returning the list of scores.
Finally, we can evaluate a baseline model on the dataset using this test harness.
A model that predicts the a random class in proportion to the base rate of each class will result in a ROC AUC of 0.5, the baseline in performance on this dataset. This is a so-called “no skill” classifier.
This can be achieved using the DummyClassifier class from the scikit-learn library and setting the “strategy” argument to ‘stratified‘.
1
2
3
...
# define the reference model
model=DummyClassifier(strategy='stratified')
Once the model is evaluated, we can report the mean and standard deviation of the ROC AUC scores directly.
Running the example first loads and summarizes the dataset.
We can see that we have the correct number of rows loaded, and that we have six computer vision derived input variables. Importantly, we can see that the class labels have the correct mapping to integers with 0 for the majority class and 1 for the minority class, customary for imbalanced binary classification datasets.
Next, the average of the ROC AUC scores is reported.
As expected, the no-skill classifier achieves the worst-case performance of a mean ROC AUC of approximately 0.5. This provides a baseline in performance, above which a model can be considered skillful on this dataset.
1
2
(11183, 6) (11183,) Counter({0: 10923, 1: 260})
Mean ROC AUC: 0.503 (0.016)
Now that we have a test harness and a baseline in performance, we can begin to evaluate some models on this dataset.
Evaluate Models
In this section, we will evaluate a suite of different techniques on the dataset using the test harness developed in the previous section.
The goal is to both demonstrate how to work through the problem systematically and to demonstrate the capability of some techniques designed for imbalanced classification problems.
The reported performance is good, but not highly optimized (e.g. hyperparameters are not tuned).
Can you do better? If you can achieve better ROC AUC performance using the same test harness, I’d love to hear about it. Let me know in the comments below.
Evaluate Machine Learning Algorithms
Let’s start by evaluating a mixture of machine learning models on the dataset.
It can be a good idea to spot check a suite of different linear and nonlinear algorithms on a dataset to quickly flush out what works well and deserves further attention, and what doesn’t.
We will evaluate the following machine learning models on the mammography dataset:
Logistic Regression (LR)
Support Vector Machine (SVM)
Bagged Decision Trees (BAG)
Random Forest (RF)
Gradient Boosting Machine (GBM)
We will use mostly default model hyperparameters, with the exception of the number of trees in the ensemble algorithms, which we will set to a reasonable default of 1,000.
We will define each model in turn and add them to a list so that we can evaluate them sequentially. The get_models() function below defines the list of models for evaluation, as well as a list of model short names for plotting the results later.
At the end of the run, we can plot each sample of scores as a box and whisker plot with the same scale so that we can directly compare the distributions.
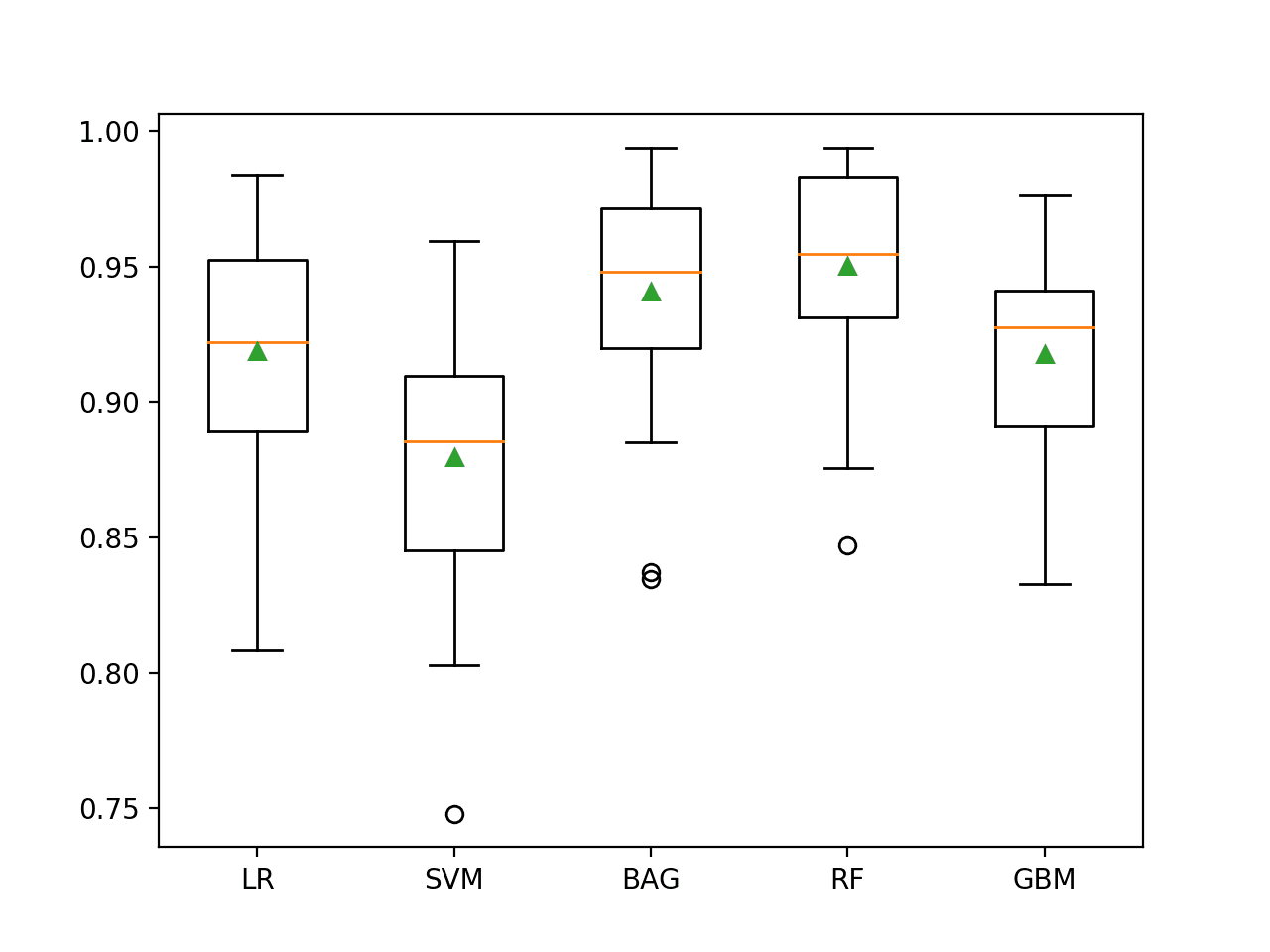
Running the example evaluates each algorithm in turn and reports the mean and standard deviation ROC AUC.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that all of the tested algorithms have skill, achieving a ROC AUC above the default of 0.5.
The results suggest that the ensemble of decision tree algorithms performs better on this dataset with perhaps Random Forest performing the best, with a ROC AUC of about 0.950.
It is interesting to note that this is better than the ROC AUC described in the paper of 0.93, although we used a different model evaluation procedure.
The evaluation was a little unfair to the LR and SVM algorithms as we did not scale the input variables prior to fitting the model. We can explore this in the next section.
1
2
3
4
5
>LR 0.919 (0.040)
>SVM 0.880 (0.049)
>BAG 0.941 (0.041)
>RF 0.950 (0.036)
>GBM 0.918 (0.037)
A figure is created showing one box and whisker plot for each algorithm’s sample of results. The box shows the middle 50 percent of the data, the orange line in the middle of each box shows the median of the sample, and the green triangle in each box shows the mean of the sample.
We can see that both BAG and RF have a tight distribution and a mean and median that closely align, perhaps suggesting a non-skewed and Gaussian distribution of scores, e.g. stable.
Box and Whisker Plot of Machine Learning Models on the Imbalanced Mammography Dataset
Now that we have a good first set of results, let’s see if we can improve them with cost-sensitive classifiers.
Evaluate Cost-Sensitive Algorithms
Some machine learning algorithms can be adapted to pay more attention to one class than another when fitting the model.
These are referred to as cost-sensitive machine learning models and they can be used for imbalanced classification by specifying a cost that is inversely proportional to the class distribution. For example, with a 98 percent to 2 percent distribution for the majority and minority classes, we can specify to give errors on the minority class a weighting of 98 and errors for the majority class a weighting of 2.
Three algorithms that offer this capability are:
Logistic Regression (LR)
Support Vector Machine (SVM)
Random Forest (RF)
This can be achieved in scikit-learn by setting the “class_weight” argument to “balanced” to make these algorithms cost-sensitive.
For example, the updated get_models() function below defines the cost-sensitive version of these three algorithms to be evaluated on our dataset.
Additionally, when exploring the dataset, we noticed that many of the variables had a seemingly exponential data distribution. Sometimes we can better spread the data for a variable by using a power transform on each variable. This will be particularly helpful to the LR and SVM algorithm and may also help the RF algorithm.
We can implement this within each fold of the cross-validation model evaluation process using a Pipeline. The first step will learn the PowerTransformer on the training set folds and apply it to the training and test set folds. The second step will be the model that we are evaluating. The pipeline can then be evaluated directly using our evaluate_model() function, for example:
1
2
3
4
5
6
7
...
# defines pipeline steps
steps=[('p',PowerTransformer()),('m',models[i])]
# define pipeline
pipeline=Pipeline(steps=steps)
# evaluate the pipeline and store results
scores=evaluate_model(X,y,pipeline)
Tying this together, the complete example of evaluating power transformed cost-sensitive machine learning algorithms on the mammography dataset is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
# cost-sensitive machine learning algorithms on the mammography dataset
from numpy import mean
from numpy import std
from pandas import read_csv
from matplotlib import pyplot
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import PowerTransformer
from sklearn.pipeline import Pipeline
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
# load the dataset
def load_dataset(full_path):
# load the dataset as a numpy array
data=read_csv(full_path,header=None)
# retrieve numpy array
data=data.values
# split into input and output elements
X,y=data[:,:-1],data[:,-1]
# label encode the target variable to have the classes 0 and 1
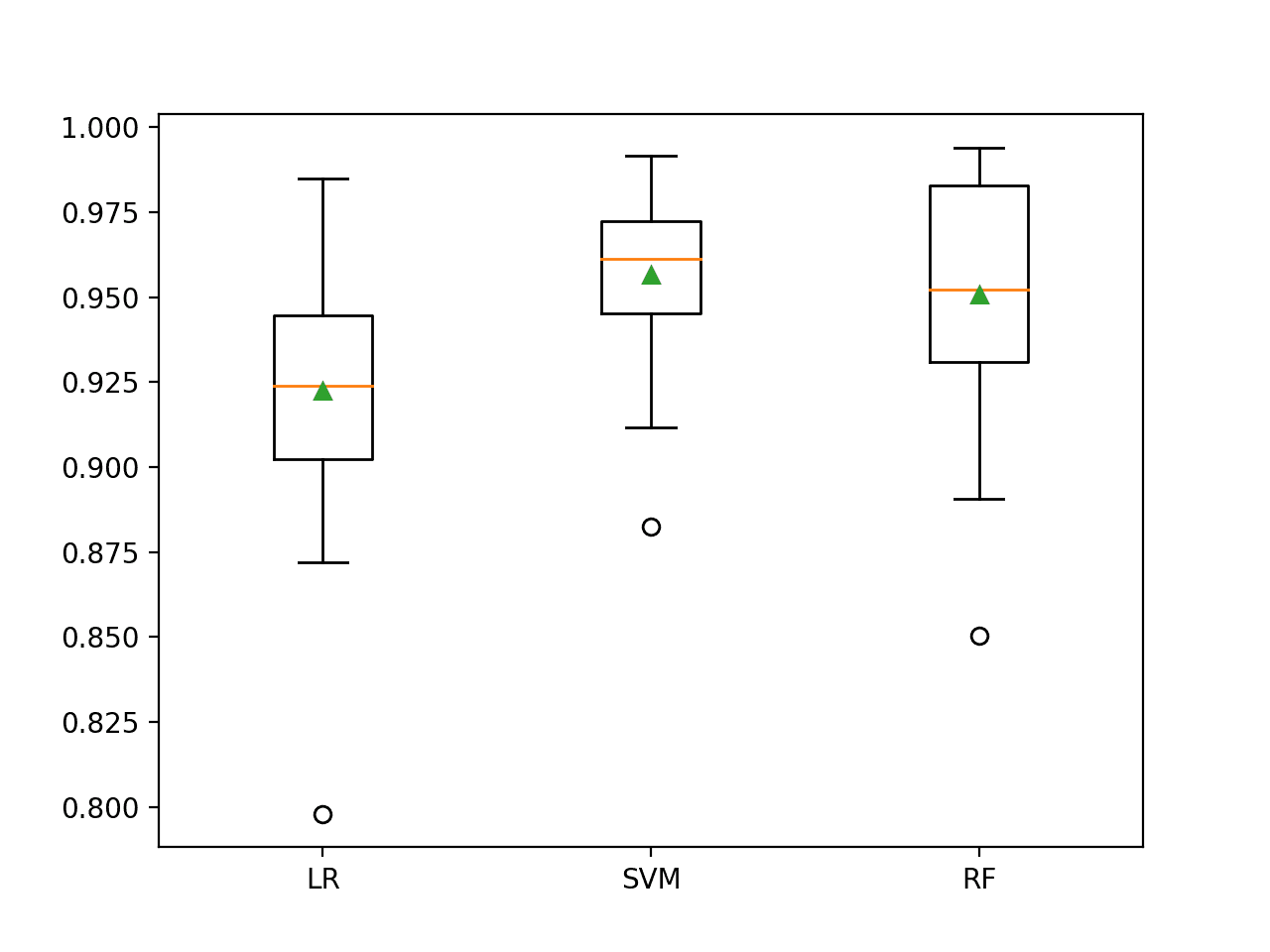
Running the example evaluates each algorithm in turn and reports the mean and standard deviation ROC AUC.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that all three of the tested algorithms achieved a lift on ROC AUC compared to their non-transformed and cost-insensitive versions. It would be interesting to repeat the experiment without the transform to see if it was the transform or the cost-sensitive version of the algorithms, or both that resulted in the lifts in performance.
In this case, we can see the SVM achieved the best performance, performing better than RF in this and the previous section and achieving a mean ROC AUC of about 0.957.
1
2
3
>LR 0.922 (0.036)
>SVM 0.957 (0.024)
>RF 0.951 (0.035)
Box and whisker plots are then created comparing the distribution of ROC AUC scores.
The SVM distribution appears compact compared to the other two models. As such the performance is likely stable and may make a good choice for a final model.
Box and Whisker Plots of Cost-Sensitive Machine Learning Models on the Imbalanced Mammography Dataset
Next, let’s see how we might use a final model to make predictions on new data.
Make Predictions on New Data
In this section, we will fit a final model and use it to make predictions on single rows of data
We will use the cost-sensitive version of the SVM model as the final model and a power transform on the data prior to fitting the model and making a prediction. Using the pipeline will ensure that the transform is always performed correctly on input data.
Once defined, we can fit it on the entire training dataset.
1
2
3
...
# fit the model
pipeline.fit(X,y)
Once fit, we can use it to make predictions for new data by calling the predict() function. This will return the class label of 0 for “no cancer”, or 1 for “cancer“.
For example:
1
2
3
4
5
...
# define a row of data
row=[...]
# make prediction
yhat=model.predict([row])
To demonstrate this, we can use the fit model to make some predictions of labels for a few cases where we know if the case is a no cancer or cancer.
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# fit a model and make predictions for the on the mammography dataset
from pandas import read_csv
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import PowerTransformer
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
# load the dataset
def load_dataset(full_path):
# load the dataset as a numpy array
data=read_csv(full_path,header=None)
# retrieve numpy array
data=data.values
# split into input and output elements
X,y=data[:,:-1],data[:,-1]
# label encode the target variable to have the classes 0 and 1
Running the example first fits the model on the entire training dataset.
Then the fit model used to predict the label of no cancer cases is chosen from the dataset file. We can see that all cases are correctly predicted.
Then some cases of actual cancer are used as input to the model and the label is predicted. As we might have hoped, the correct labels are predicted for all cases.
1
2
3
4
5
6
7
8
No Cancer:
>Predicted=0 (expected 0)
>Predicted=0 (expected 0)
>Predicted=0 (expected 0)
Cancer:
>Predicted=1 (expected 1)
>Predicted=1 (expected 1)
>Predicted=1 (expected 1)
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
It provides self-study tutorials and end-to-end projects on: Performance Metrics, Undersampling Methods, SMOTE, Threshold Moving, Probability Calibration, Cost-Sensitive Algorithms
and much more...
Bring Imbalanced Classification Methods to Your Machine Learning Projects
“This means a single model will be fit and evaluated 10 * 3 or 30 times and the mean and standard deviation of these runs will be reported.”
I thought at every step of the k-Fold Cross-Validation a new model object gets trained from the scratch and not the same one, according to what I’ve once read here:
One more great tutorial to cementing the imbalance model training and input data preparation as they are PowerTransformer() sklearn unction.
In my case. I also apply StandardScaler() sklearn function to “regularize” the dataset input.
I do not know if in the scientific literature they also call these dataset input preparation as “regularizers” as I did?. But, I rather prefer to use this analogy.
I also add 2 other models (ExtraTreesClassifier and XGBClassifier) to the 5 ones suggested by you in order to compare the performance between them
My results are that:
– without applying any data preparation (StandardScaler or PowerTransformer) and without any imbalance weight penalisation the ExtraTreesClassifier model is the best one (around 0.955 on “roc_auc” metric.
– with StandardScaler plus PowerTransformer but without imbalance weight compensation the ExtraTreesClassifier and RandomForestClassifier are the best ones, around 0.95
– and finally, with StandarScaler plus PowerTransformer plus weight classes compensation, the SVC model followed by BaggingClassifier are the best ones.
So SVC is finally the best one with a ‘roc_auc’ score around 0.96
So my conclusion is that different models have different sensitivity to these tools (StandardScalar, PowerTransformer, class_weights compensation, etc ) …So it depend on each study case.
One final question. I see the Sklearn models, does not have a way to save the model’s weights after training (such it is the case of tensorflow/keras), so before apply them (e.g. in order to predict new outputs) each time the model must be re-trained?
thank you for all these great tutorials Jason very instructive
I just applied SMOTE and results improved significantly. Like day and night:
>LR 0.934 (0.005)
>SVM 0.980 (0.003)
>BAG 0.993 (0.001)
>RF 0.993 (0.001)
>GBM 0.994 (0.001)
>XGB 0.995 (0.001)
Last one – XGBClassifier without SMOTE wasn’t good at all.
I did some grid search for XGB to give it the some advantage without SMOTE XGBClassifier(n_estimators=100, use_label_encoder=False, scale_pos_weight=0.1, eval_metric=’logloss’)
results without SMOTE:
>LR 0.922 (0.038)
>SVM 0.959 (0.018)
>BAG 0.942 (0.027)
>RF 0.949 (0.028)
>GBM 0.919 (0.034)
>XGB 0.955 (0.023)








Does regression suffer from imbalanced dataset?
There are such a thing, but it is different from ideas of imbalance in classification.
See the books here for examples:
https://machinelearningmastery.com/resources-for-imbalanced-classification/
As usual, great reference. Thank you so much!
Thanks.
Hi
In this blog post it says:
“This means a single model will be fit and evaluated 10 * 3 or 30 times and the mean and standard deviation of these runs will be reported.”
I thought at every step of the k-Fold Cross-Validation a new model object gets trained from the scratch and not the same one, according to what I’ve once read here:
https://machinelearningmastery.com/k-fold-cross-validation/
which at the step 4 says:
4. Retain the evaluation score and discard the model
Thanks
Yes, every fold fits a new model and calculates a score. We then have a population of scores that we summarize. There’s no contradiction.
Hi Jason,
I think you have not used SMOTE here and the predictions are done without it.
Also if we have a larger dataset what to do than. Is it good to go without SMOTE for these kind of datasets.
SMOTE was not used in this tutorial.
If you want to use SNOTE, try it and see how it compares to other methods.
Hi Jason,
One more great tutorial to cementing the imbalance model training and input data preparation as they are PowerTransformer() sklearn unction.
In my case. I also apply StandardScaler() sklearn function to “regularize” the dataset input.
I do not know if in the scientific literature they also call these dataset input preparation as “regularizers” as I did?. But, I rather prefer to use this analogy.
I also add 2 other models (ExtraTreesClassifier and XGBClassifier) to the 5 ones suggested by you in order to compare the performance between them
My results are that:
– without applying any data preparation (StandardScaler or PowerTransformer) and without any imbalance weight penalisation the ExtraTreesClassifier model is the best one (around 0.955 on “roc_auc” metric.
– with StandardScaler plus PowerTransformer but without imbalance weight compensation the ExtraTreesClassifier and RandomForestClassifier are the best ones, around 0.95
– and finally, with StandarScaler plus PowerTransformer plus weight classes compensation, the SVC model followed by BaggingClassifier are the best ones.
So SVC is finally the best one with a ‘roc_auc’ score around 0.96
So my conclusion is that different models have different sensitivity to these tools (StandardScalar, PowerTransformer, class_weights compensation, etc ) …So it depend on each study case.
One final question. I see the Sklearn models, does not have a way to save the model’s weights after training (such it is the case of tensorflow/keras), so before apply them (e.g. in order to predict new outputs) each time the model must be re-trained?
thank you for all these great tutorials Jason very instructive
I just applied SMOTE and results improved significantly. Like day and night:
>LR 0.934 (0.005)
>SVM 0.980 (0.003)
>BAG 0.993 (0.001)
>RF 0.993 (0.001)
>GBM 0.994 (0.001)
>XGB 0.995 (0.001)
Last one – XGBClassifier without SMOTE wasn’t good at all.
I did some grid search for XGB to give it the some advantage without SMOTE XGBClassifier(n_estimators=100, use_label_encoder=False, scale_pos_weight=0.1, eval_metric=’logloss’)
results without SMOTE:
>LR 0.922 (0.038)
>SVM 0.959 (0.018)
>BAG 0.942 (0.027)
>RF 0.949 (0.028)
>GBM 0.919 (0.034)
>XGB 0.955 (0.023)
Great work!
Well done!
Hi Jason,
I have a question related to image analysis – how is an image segmented to perform its analysis?
This topic is very interesting and important, especially in the analysis of tomography or magnetic resonance images.
I would find it very relevant to create a tutorial that talked about this important technique related to image analysis.
Thank’s a lot!
What do you mean by image analysis?
Hi Jason, what should be the approach for unsupervised approach? Can you please share a code snippet or example?
May be you can see the code here: https://machinelearningmastery.com/one-class-classification-algorithms/
Hope this can help you start.