It can be challenging to develop a neural network predictive model for a new dataset.
One approach is to first inspect the dataset and develop ideas for what models might work, then explore the learning dynamics of simple models on the dataset, then finally develop and tune a model for the dataset with a robust test harness.
This process can be used to develop effective neural network models for classification and regression predictive modeling problems.
In this tutorial, you will discover how to develop a Multilayer Perceptron neural network model for the Wood’s Mammography classification dataset.
After completing this tutorial, you will know:
How to load and summarize the Wood’s Mammography dataset and use the results to suggest data preparations and model configurations to use.
How to explore the learning dynamics of simple MLP models on the dataset.
How to develop robust estimates of model performance, tune model performance and make predictions on new data.
Let’s get started.
Develop a Neural Network for Woods Mammography Dataset Photo by Larry W. Lo, some rights reserved.
Tutorial Overview
This tutorial is divided into 4 parts; they are:
Woods Mammography Dataset
Neural Network Learning Dynamics
Robust Model Evaluation
Final Model and Make Predictions
Woods Mammography Dataset
The first step is to define and explore the dataset.
We will be working with the “mammography” standard binary classification dataset, sometimes called “Woods Mammography“.
The focus of the problem is on detecting breast cancer from radiological scans, specifically the presence of clusters of microcalcifications that appear bright on a mammogram.
There are two classes and the goal is to distinguish between microcalcifications and non-microcalcifications using the features for a given segmented object.
Non-microcalcifications: negative case, or majority class.
Microcalcifications: positive case, or minority class.
The Mammography dataset is a widely used standard machine learning dataset, used to explore and demonstrate many techniques designed specifically for imbalanced classification.
Note: To be crystal clear, we are NOT “solving breast cancer“. We are exploring a standard classification dataset.
Below is a sample of the first 5 rows of the dataset
Running the example loads the dataset directly from the URL and reports the shape of the dataset.
In this case, we can confirm that the dataset has 7 variables (6 input and one output) and that the dataset has 11,183 rows of data.
This a modest sized dataset for a neural network and suggests that a small network would be appropriate.
It also suggests that using k-fold cross-validation would be a good idea given that it will give a more reliable estimate of model performance than a train/test split and because a single model will fit in seconds instead of hours or days with the largest datasets.
1
(11183, 7)
Next, we can learn more about the dataset by looking at summary statistics and a plot of the data.
1
2
3
4
5
6
7
8
9
10
11
12
# show summary statistics and plots of the mammography dataset
max 3.150844e+01 5.085849e+00 ... 2.361712e+01 1.949027e+00
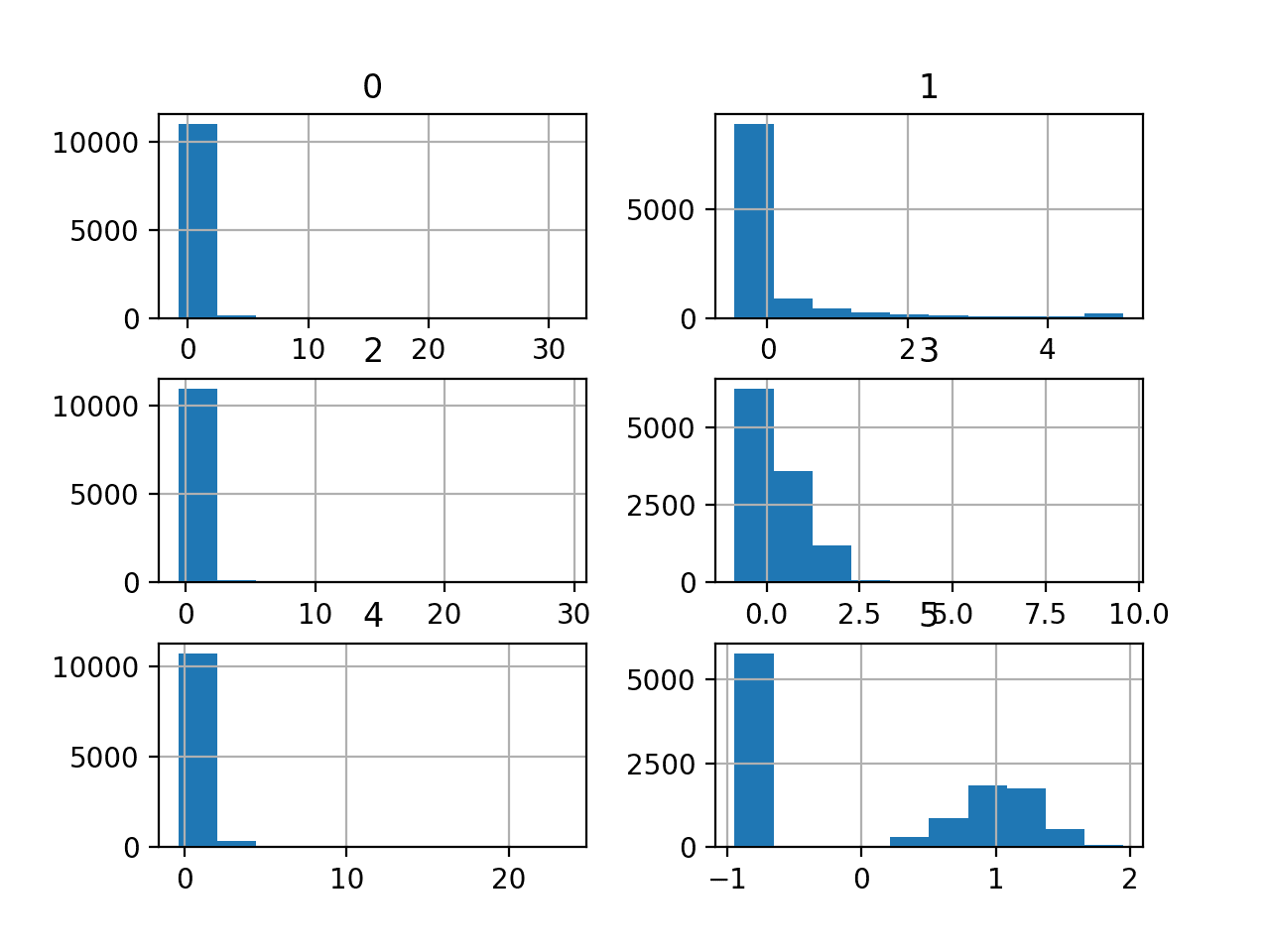
A histogram plot is then created for each variable.
We can see that perhaps most variables have an exponential distribution, and perhaps variable 5 (the last input variable) is Gaussian with outliers/missing values.
We may have some benefit in using a power transform on each variable in order to make the probability distribution less skewed which will likely improve model performance.
Histograms of the Mammography Classification Dataset
It may be helpful to know how imbalanced the dataset actually is.
We can use the Counter object to count the number of examples in each class, then use those counts to summarize the distribution.
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
# summarize the class ratio of the mammography dataset
Running the example summarizes the class distribution, confirming the severe class imbalanced with approximately 98 percent for the majority class (no cancer) and approximately 2 percent for the minority class (cancer).
1
2
Class='-1', Count=10923, Percentage=97.675%
Class='1', Count=260, Percentage=2.325%
This is helpful because if we use classification accuracy, then any model that achieves an accuracy less than about 97.7% does not have skill on this dataset.
Now that we are familiar with the dataset, let’s explore how we might develop a neural network model.
Neural Network Learning Dynamics
We will develop a Multilayer Perceptron (MLP) model for the dataset using TensorFlow.
We cannot know what model architecture of learning hyperparameters would be good or best for this dataset, so we must experiment and discover what works well.
Given that the dataset is small, a small batch size is probably a good idea, e.g. 16 or 32 rows. Using the Adam version of stochastic gradient descent is a good idea when getting started as it will automatically adapt the learning rate and works well on most datasets.
Before we evaluate models in earnest, it is a good idea to review the learning dynamics and tune the model architecture and learning configuration until we have stable learning dynamics, then look at getting the most out of the model.
We can do this by using a simple train/test split of the data and review plots of the learning curves. This will help us see if we are over-learning or under-learning; then we can adapt the configuration accordingly.
First, we must ensure all input variables are floating-point values and encode the target label as integer values 0 and 1.
1
2
3
4
5
...
# ensure all data are floating point values
X=X.astype('float32')
# encode strings to integer
y=LabelEncoder().fit_transform(y)
Next, we can split the dataset into input and output variables, then into 67/33 train and test sets.
We must ensure that the split is stratified by the class ensuring that the train and test sets have the same distribution of class labels as the main dataset.
In this case, we will use one hidden layer with 50 nodes and one output layer (chosen arbitrarily). We will use the ReLU activation function in the hidden layer and the “he_normal” weight initialization, as together, they are a good practice.
Running the example first fits the model on the training dataset, then reports the classification accuracy on the test dataset.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case we can see that the model performs better than a no-skill model, given that the accuracy is above about 97.7 percent, in this case achieving an accuracy of about 98.8 percent.
1
Accuracy: 0.988
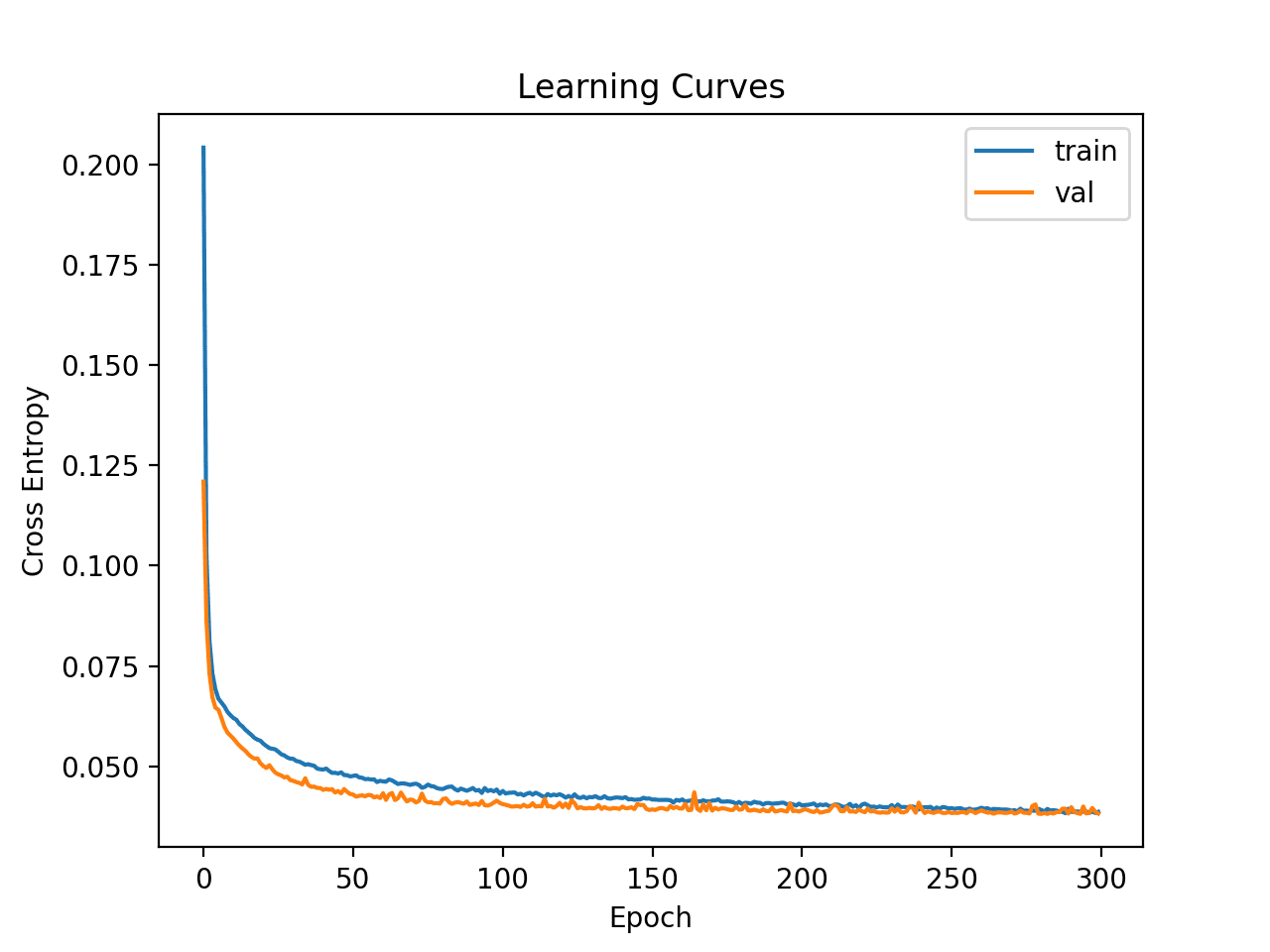
Line plots of the loss on the train and test sets are then created.
We can see that the model quickly finds a good fit on the dataset and does not appear to be over or underfitting.
Learning Curves of Simple Multilayer Perceptron on the Mammography Dataset
Now that we have some idea of the learning dynamics for a simple MLP model on the dataset, we can look at developing a more robust evaluation of model performance on the dataset.
Robust Model Evaluation
The k-fold cross-validation procedure can provide a more reliable estimate of MLP performance, although it can be very slow.
This is because k models must be fit and evaluated. This is not a problem when the dataset size is small, such as the cancer survival dataset.
We can use the StratifiedKFold class and enumerate each fold manually, fit the model, evaluate it, and then report the mean of the evaluation scores at the end of the procedure.
We can use this framework to develop a reliable estimate of MLP model performance with our base configuration, and even with a range of different data preparations, model architectures, and learning configurations.
It is important that we first developed an understanding of the learning dynamics of the model on the dataset in the previous section before using k-fold cross-validation to estimate the performance. If we started to tune the model directly, we might get good results, but if not, we might have no idea of why, e.g. that the model was over or under fitting.
If we make large changes to the model again, it is a good idea to go back and confirm that the model is converging appropriately.
The complete example of this framework to evaluate the base MLP model from the previous section is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# k-fold cross-validation of base model for the mammography dataset
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.model_selection import StratifiedKFold
Running the example reports the model performance each iteration of the evaluation procedure and reports the mean and standard deviation of classification accuracy at the end of the run.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the MLP model achieved a mean accuracy of about 98.7 percent, which is pretty close to our rough estimate in the previous section.
This confirms our expectation that the base model configuration may work better than a naive model for this dataset
1
2
3
4
5
6
7
8
9
10
11
>0.987
>0.986
>0.989
>0.987
>0.986
>0.988
>0.989
>0.989
>0.983
>0.988
Mean Accuracy: 0.987 (0.002)
Next, let’s look at how we might fit a final model and use it to make predictions.
Final Model and Make Predictions
Once we choose a model configuration, we can train a final model on all available data and use it to make predictions on new data.
In this case, we will use the model with dropout and a small batch size as our final model.
We can prepare the data and fit the model as before, although on the entire dataset instead of a training subset of the dataset.
Note: I took this row from the first row of the dataset and the expected label is a ‘-1’.
We can then make a prediction.
1
2
3
...
# make prediction
yhat=model.predict_classes([row])
Then invert the transform on the prediction, so we can use or interpret the result in the correct label (which is just an integer for this dataset).
1
2
3
...
# invert transform to get label for class
yhat=le.inverse_transform(yhat)
And in this case, we will simply report the prediction.
1
2
3
...
# report prediction
print('Predicted: %s'%(yhat[0]))
Tying this all together, the complete example of fitting a final model for the mammography dataset and using it to make a prediction on new data is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# fit a final model and make predictions on new data for the mammography dataset
Running the example fits the model on the entire dataset and makes a prediction for a single row of new data.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the model predicted a “-1” label for the input row.
1
Predicted: '-1'
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
I experimented with writing a custom callback that calculates F1 and AUC scores. There I found out that adding dense layers doesn’t contribute much to the accuracy but to the AUC and F1 scores.
So by using SMOTE on the training set and 3 dense layers I got this results on the 190 epochs:
Accuracy = 0.974
ROC AUC = 0.961
Recall AUC = 0.718
F1 score = 0.615
full_path = path+’mammography.csv’
# load the dataset
X, y = load_dataset(full_path)
# define model
model = get_nn()
# calculate accuracy, AUC and F1 score
def acc_auc_f1(y_test, yhat, tresh=0.5):
pred = (yhat > tresh).astype(“int32″)
precision, recall, _ = precision_recall_curve(y_test, yhat)
accuracy, auc_score, f_score = accuracy_score(y_test, pred), auc(recall, precision), f1_score(y_test, pred)
return accuracy, auc_score, f_score
# custom callback that executes a lambda every time F1 score increases (F1 or selected metric)
class AucActionCallback(Callback):
def __init__(self, action, validation_data, verbose=0, metric=’f1′):
super(AucActionCallback, self).__init__()
self.metric = metric.lower() # metric can be ‘acc’,’auc’, ‘f1’
self.action, self.verbose = action, verbose
(self.X_val, self.y_val) = validation_data # should be a tuple (X_test, y_test)
def on_train_begin(self, logs=None):
self.best = 0.0 # Initialize the best as 0
def on_epoch_end(self, epoch, logs=None):
# calculate scores
accuracy, auc_score, f_score = acc_auc_f1(self.y_val, self.model.predict(self.X_val))
accuracy = round(accuracy * 100, 2)
# store to the logs – history
logs[‘acc’], logs[‘auc’], logs[‘f1’] = accuracy, auc_score, f_score
# calculate current depending on the metric chosen
current = f_score if self.metric == ‘f1’ else auc_score if self.metric == ‘auc’ else accuracy
# print scores
if self.verbose >= 2:
print(f”{epoch}: Accuracy {accuracy}% \tAUC {round(auc_score, 4)} \tF1 score = {round(f_score, 4)}”)
# update best value
if current > self.best:
if self.verbose >= 1:
print(f”{epoch}: >>> action at \t{self.metric.upper()} = {round(current,5)} > {round(self.best,5)}”)
self.best = current
self.action() # execute lambda
#train split must be stratified
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1, test_size=0.3, stratify=y)
# apply SMOTE only on test set – validation should be left untouched for correct calculations
X_train, y_train = SMOTE().fit_resample(X_train, y_train)
# save model on F1 increase
filePathWeights = path+”NN.best.hdf5″
checkpoint = AucActionCallback(lambda: model.save(filePathWeights), validation_data=(X_test, y_test), verbose=2)
# fit the model
history = model.fit(X_train, y_train, epochs=200, batch_size=32, verbose=0, callbacks=[checkpoint])
# load best weights
model.load_weights(filePathWeights)
XGBClassifier in the same conditions (using SMOTE on the training set 70/30) got this result in a few seconds:
Accuracy = 99.45
ROC AUC = 0.945
Recall AUC = 0.885
F1 score = 0.884







Would not be a better estimate of usability the more used, in medicine at least, Sensitivity and specificity ?
Perhaps.
I experimented with writing a custom callback that calculates F1 and AUC scores. There I found out that adding dense layers doesn’t contribute much to the accuracy but to the AUC and F1 scores.
So by using SMOTE on the training set and 3 dense layers I got this results on the 190 epochs:
Accuracy = 0.974
ROC AUC = 0.961
Recall AUC = 0.718
F1 score = 0.615
full_path = path+’mammography.csv’
# load the dataset
X, y = load_dataset(full_path)
# define model
model = get_nn()
# calculate accuracy, AUC and F1 score
def acc_auc_f1(y_test, yhat, tresh=0.5):
pred = (yhat > tresh).astype(“int32″)
precision, recall, _ = precision_recall_curve(y_test, yhat)
accuracy, auc_score, f_score = accuracy_score(y_test, pred), auc(recall, precision), f1_score(y_test, pred)
return accuracy, auc_score, f_score
# custom callback that executes a lambda every time F1 score increases (F1 or selected metric)
class AucActionCallback(Callback):
def __init__(self, action, validation_data, verbose=0, metric=’f1′):
super(AucActionCallback, self).__init__()
self.metric = metric.lower() # metric can be ‘acc’,’auc’, ‘f1’
self.action, self.verbose = action, verbose
(self.X_val, self.y_val) = validation_data # should be a tuple (X_test, y_test)
def on_train_begin(self, logs=None):
self.best = 0.0 # Initialize the best as 0
def on_epoch_end(self, epoch, logs=None):
# calculate scores
accuracy, auc_score, f_score = acc_auc_f1(self.y_val, self.model.predict(self.X_val))
accuracy = round(accuracy * 100, 2)
# store to the logs – history
logs[‘acc’], logs[‘auc’], logs[‘f1’] = accuracy, auc_score, f_score
# calculate current depending on the metric chosen
current = f_score if self.metric == ‘f1’ else auc_score if self.metric == ‘auc’ else accuracy
# print scores
if self.verbose >= 2:
print(f”{epoch}: Accuracy {accuracy}% \tAUC {round(auc_score, 4)} \tF1 score = {round(f_score, 4)}”)
# update best value
if current > self.best:
if self.verbose >= 1:
print(f”{epoch}: >>> action at \t{self.metric.upper()} = {round(current,5)} > {round(self.best,5)}”)
self.best = current
self.action() # execute lambda
#train split must be stratified
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1, test_size=0.3, stratify=y)
# apply SMOTE only on test set – validation should be left untouched for correct calculations
X_train, y_train = SMOTE().fit_resample(X_train, y_train)
# save model on F1 increase
filePathWeights = path+”NN.best.hdf5″
checkpoint = AucActionCallback(lambda: model.save(filePathWeights), validation_data=(X_test, y_test), verbose=2)
# fit the model
history = model.fit(X_train, y_train, epochs=200, batch_size=32, verbose=0, callbacks=[checkpoint])
# load best weights
model.load_weights(filePathWeights)
Well done!
How do you format python code in comments?
You can add PRE tags around your code.
XGBClassifier in the same conditions (using SMOTE on the training set 70/30) got this result in a few seconds:
Accuracy = 99.45
ROC AUC = 0.945
Recall AUC = 0.885
F1 score = 0.884
hii Can you type the full code in word file or note
This will help you copy the code:
https://machinelearningmastery.com/faq/single-faq/how-do-i-copy-code-from-a-tutorial
please do u have a report on this project?
I do not.