Machine learning predictive modeling performance is only as good as your data, and your data is only as good as the way you prepare it for modeling.
The most common approach to data preparation is to study a dataset and review the expectations of a machine learning algorithms, then carefully choose the most appropriate data preparation techniques to transform the raw data to best meet the expectations of the algorithm. This is slow, expensive, and requires a vast amount of expertise.
An alternative approach to data preparation is to grid search a suite of common and commonly useful data preparation techniques to the raw data. This is an alternative philosophy for data preparation that treats data transforms as another hyperparameter of the modeling pipeline to be searched and tuned.
This approach requires less expertise than the traditional manual approach to data preparation, although it is computationally costly. The benefit is that it can aid in the discovery of non-intuitive data preparation solutions that achieve good or best performance for a given predictive modeling problem.
In this tutorial, you will discover how to use the grid search approach for data preparation with tabular data.
After completing this tutorial, you will know:
Grid search provides an alternative approach to data preparation for tabular data, where transforms are tried as hyperparameters of the modeling pipeline.
How to use the grid search method for data preparation to improve model performance over a baseline for a standard classification dataset.
How to grid search sequences of data preparation methods to further improve model performance.
Kick-start your project with my new book Data Preparation for Machine Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
How to Grid Search Data Preparation Techniques Photo by Wall Boat, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
Grid Search Technique for Data Preparation
Dataset and Performance Baseline
Wine Classification Dataset
Baseline Model Performance
Grid Search Approach to Data Preparation
Grid Search Technique for Data Preparation
Data preparation can be challenging.
The approach that is most often prescribed and followed is to analyze the dataset, review the requirements of the algorithms, and transform the raw data to best meet the expectations of the algorithms.
This can be effective but is also slow and can require deep expertise with data analysis and machine learning algorithms.
An alternative approach is to treat the preparation of input variables as a hyperparameter of the modeling pipeline and to tune it along with the choice of algorithm and algorithm configurations.
This might be a data transform that “should not work” or “should not be appropriate for the algorithm” yet results in good or great performance. Alternatively, it may be the absence of a data transform for an input variable that is deemed “absolutely required” yet results in good or great performance.
This can be achieved by designing a grid search of data preparation techniques and/or sequences of data preparation techniques in pipelines. This may involve evaluating each on a single chosen machine learning algorithm, or on a suite of machine learning algorithms.
The benefit of this approach is that it always results in suggestions of modeling pipelines that give good relative results. Most importantly, it can unearth the non-obvious and unintuitive solutions to practitioners without the need for deep expertise.
We can explore this approach to data preparation with a worked example.
Before we dive into a worked example, let’s first select a standard dataset and develop a baseline in performance.
Want to Get Started With Data Preparation?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Dataset and Performance Baseline
In this section, we will first select a standard machine learning dataset and establish a baseline in performance on this dataset. This will provide the context for exploring the grid search method of data preparation in the next section.
Wine Classification Dataset
We will use the wine classification dataset.
This dataset has 13 input variables that describe the chemical composition of samples of wine and requires that the wine be classified as one of three types.
# split the columns into input and output variables
X,y=data[:,:-1],data[:,-1]
# summarize the shape of the loaded data
print(X.shape,y.shape)
Running the example, we can see that the dataset was loaded correctly and that there are 179 rows of data with 13 input variables and a single target variable.
1
(178, 13) (178,)
Next, let’s evaluate a model on this dataset and establish a baseline in performance.
Baseline Model Performance
We can establish a baseline in performance on the wine classification task by evaluating a model on the raw input data.
In this case, we will evaluate a logistic regression model.
First, we can define a function to load the dataset and perform some minimal data preparation to ensure the inputs are numeric and the target is label encoded.
Running the example evaluates the model performance and reports the mean and standard deviation classification accuracy.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the logistic regression model fit on the raw input data achieved the average classification accuracy of about 95.3 percent, providing a baseline in performance.
1
Accuracy: 0.953 (0.048)
Next, let’s explore whether we can improve the performance using the grid-search-based approach to data preparation.
Grid Search Approach to Data Preparation
In this section, we can explore whether we can improve performance using the grid search approach to data preparation.
The first step is to define a series of modeling pipelines to evaluate, where each pipeline defines one (or more) data preparation techniques and ends with a model that takes the transformed data as input.
We will define a function to create these pipelines as a list of tuples, where each tuple defines the short name for the pipeline and the pipeline itself. We will evaluate a range of different data scaling methods (e.g. MinMaxScaler and StandardScaler), distribution transforms (QuantileTransformer and KBinsDiscretizer), as well as dimensionality reduction transforms (PCA and SVD).
Running the example evaluates the performance of each pipeline and reports the mean and standard deviation classification accuracy.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that standardizing the input variables and using a quantile transform both achieves the best result with a classification accuracy of about 98.7 percent, an improvement over the baseline with no data preparation that achieved a classification accuracy of 95.3 percent.
You can add your own modeling pipelines to the get_pipelines() function and compare their result.
Can you get better results?
Let me know in the comments below.
1
2
3
4
5
6
>norm: 0.976 (0.031)
>std: 0.987 (0.023)
>quan: 0.987 (0.023)
>kbins: 0.968 (0.045)
>pca: 0.963 (0.039)
>svd: 0.953 (0.048)
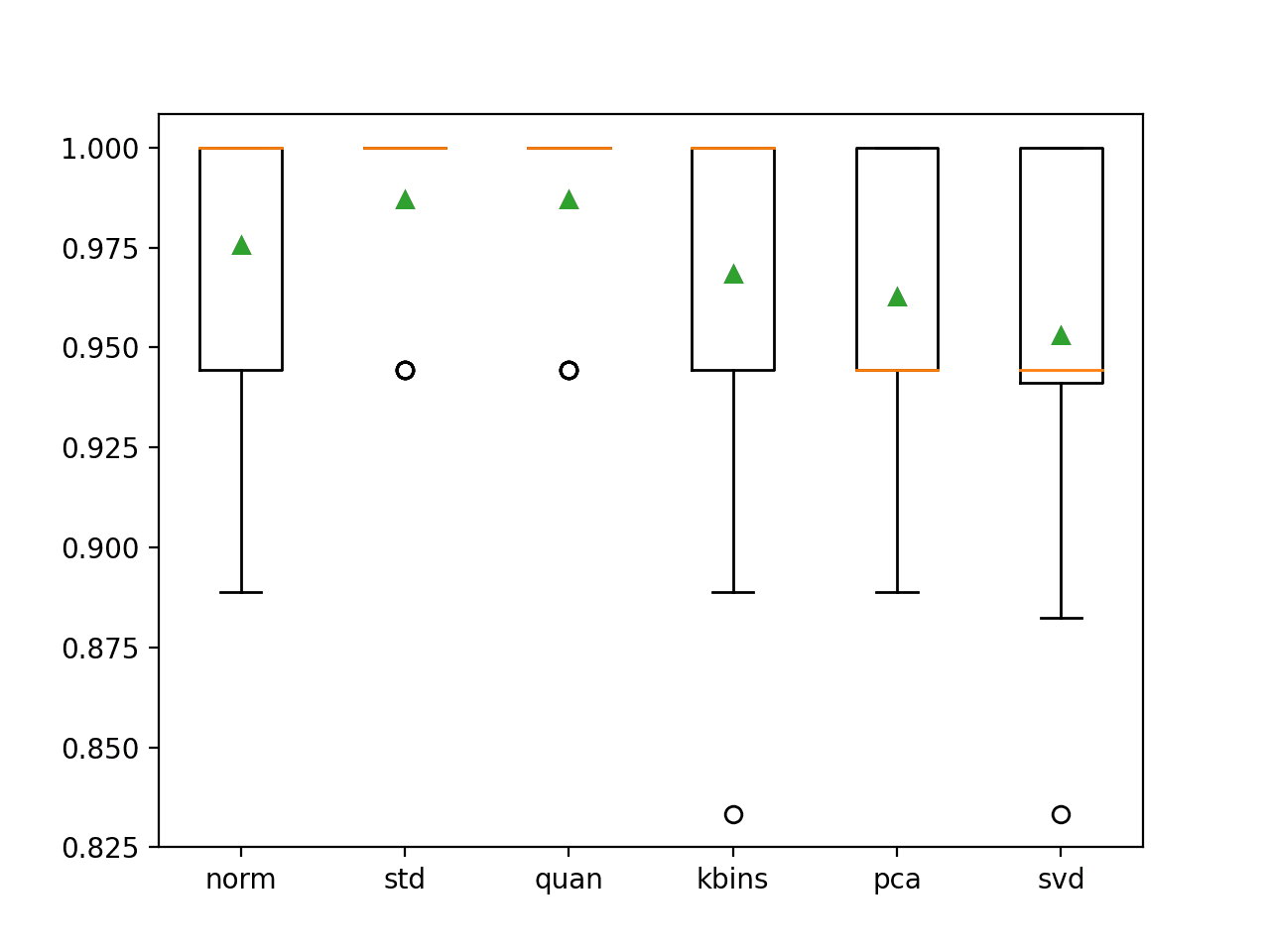
A figure is created showing box and whisker plots that summarize the distribution of classification accuracy scores for each data preparation technique. We can see that the distribution of scores for the standardization and quantile transforms are compact and very similar and have an outlier. We can see that the spread of scores for the other transforms is larger and skewing down.
The results may suggest that standardizing the dataset is probably an important step in the data preparation and related transforms, such as the quantile transform, and perhaps even the power transform may offer benefits if combined with standardization by making one or more input variables more Gaussian.
Box and Whisker Plot of Classification Accuracy for Different Data Transforms on the Wine Classification Dataset
We can also explore sequences of transforms to see if they can offer a lift in performance.
For example, we might want to apply RFE feature selection after the standardization transform to see if the same or better results can be used with fewer input variables (e.g. less complexity).
We might also want to see if a power transform preceded with a data scaling transform can achieve good performance on the dataset as we believe it could given the success of the quantile transform.
The updated get_pipelines() function with sequences of transforms is provided below.
Running the example evaluates the performance of each pipeline and reports the mean and standard deviation classification accuracy.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
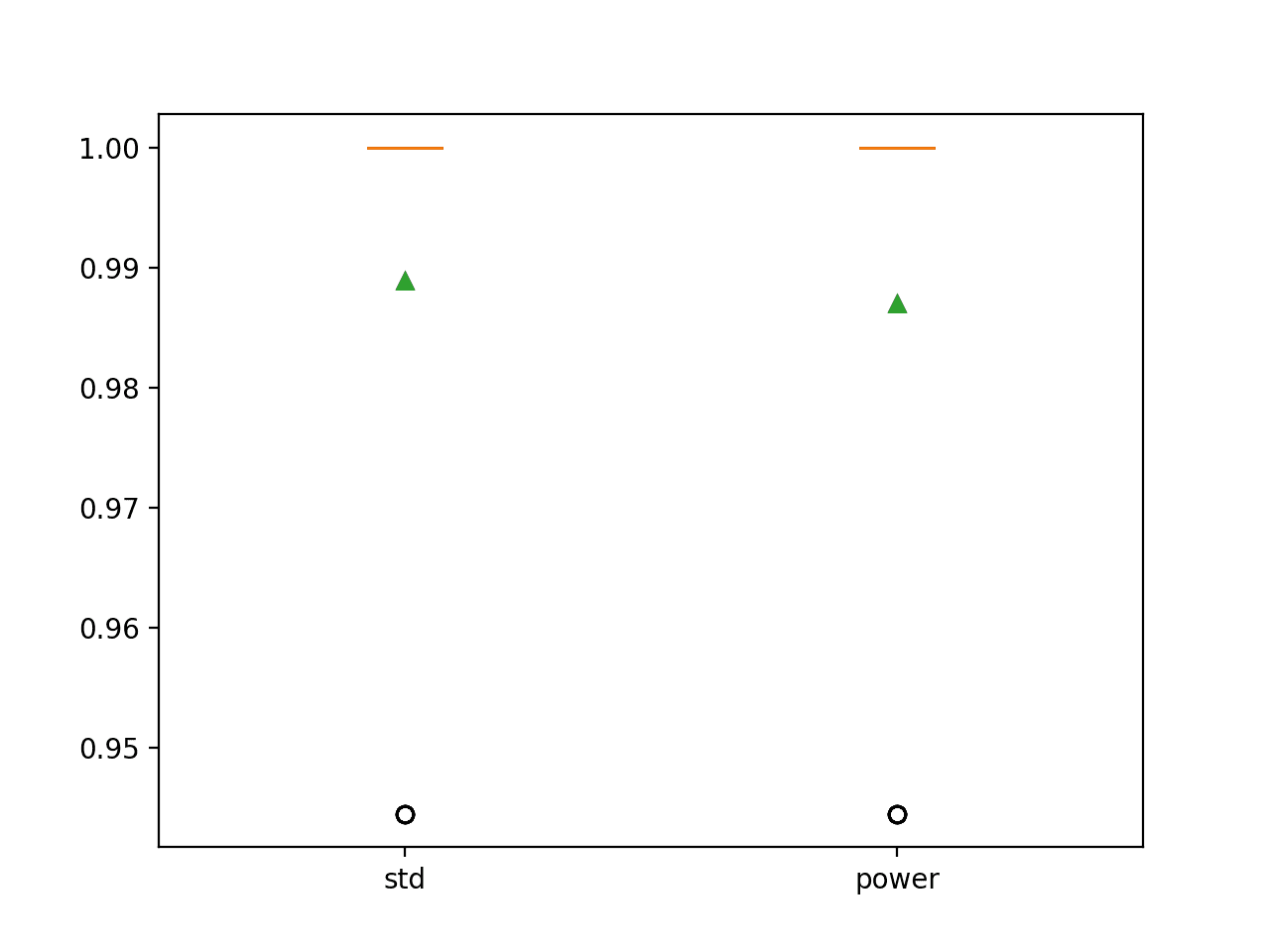
In this case, we can see that the standardization with feature selection offers an additional lift in accuracy from 98.7 percent to 98.9 percent, although the data scaling and power transform do not offer any additional benefit over the quantile transform.
1
2
>std: 0.989 (0.022)
>power: 0.987 (0.023)
A figure is created showing box and whisker plots that summarize the distribution of classification accuracy scores for each data preparation technique.
We can see that the distribution of results for both pipelines of transforms is compact with very little spread other than outlier.
Box and Whisker Plot of Classification Accuracy for Different Sequences of Data Transforms on the Wine Classification Dataset
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
In this tutorial, you discovered how to use a grid search approach for data preparation with tabular data.
Specifically, you learned:
Grid search provides an alternative approach to data preparation for tabular data, where transforms are tried as hyperparameters of the modeling pipeline.
How to use the grid search method for data preparation to improve model performance over a baseline for a standard classification dataset.
How to grid search sequences of data preparation methods to further improve model performance.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
It provides self-study tutorials with full working code on: Feature Selection, RFE, Data Cleaning, Data Transforms, Scaling, Dimensionality Reduction,
and much more...
Bring Modern Data Preparation Techniques to Your Machine Learning Projects
Nice post as always. May i know how to apply grid search for LSTM (neural network) model? Bcoz its very important to choose the hyper parameters for best results. Thanks in advance jason
Conclusion
For the downloaded file wine.csv, you need to have read_csv include the parameter delim_whitespace = True, otherwise without the parameter, you get the mess shown at the beginning of my comment
What is the purpose of passing the ‘model’ variable in get_pipelines? It does not get attached to a particular pipeline within the get_pipelines(model) function.
Not including ‘model’ parameter in the get_pipelines() function produced the same result
Dear Dr Jason,
PROBLEM SOLVED – THE ‘model’ variable is still used as a step for various pipelines within get_pipelines() because it ‘model’ is a global variable.
The reason why we got the same result is that whether get_pipelines(model) OR get_pipelines(), the ‘model’ is still added to the steps within the get_pipelines(model) or get_pipelines().
How does model get passed without needing the ‘model’ parameter in get_pipelines()?
Answer is that ‘model’ is GLOBAL.
How is that GLOBAL?
Answer ‘model’ is a global variable which the function get_pipelines() uses the globally declared variable ‘model’ within the get_pipelines().
1
2
# 'model' is declared externally to get_pipelines()
model=LogisticRegression(solver='liblinear')
You may ask how does it get used within get_pipelines()?
Answer: here is a typical few lines used in get_pipelines():
1
2
3
4
5
6
7
8
9
10
11
12
def get_pipelines()):#note the absence of the 'model' variable. 'model' is globally assigned
pipelines=list()
# normalize
p=Pipeline([('s',MinMaxScaler()),('m',model)]);#NOTE 'model' is obtained globally
#blah blah blah
returnpipelines
...................
...................
#Declare our model
model=LogisticRegression(solver='liblinear')
# get the modeling pipelines
pipelines=get_pipelines();#model is used within get_pipelines() because 'model' is global
Conclusion – this is the danger of using global variables. If a module/function needs to be passed to a module, the parameter needs to be a different name to the global variable to limit the scope of the global variable.
Dear Dr Jason,
Thank you for your reply. I should have been clearer.
Yes ‘model’ is added to the end of each pipeline “,,,within that function.” At the same time, there was no need to declare the function as get_pipelines(model) since ‘model’ was (i) declared outside the function and (ii) because ‘model’ was declared outside the function, ‘model’ was able to be used within get_pipelines() without passing the parameter ‘model’ in your version of get_pipelines(model).
Thus ‘model’ in your example is global.
Thank you, your response is appreciated,
Anthony of Sydney








Nice post as always. May i know how to apply grid search for LSTM (neural network) model? Bcoz its very important to choose the hyper parameters for best results. Thanks in advance jason
Yes, see this tutorial:
https://machinelearningmastery.com/how-to-grid-search-deep-learning-models-for-time-series-forecasting/
Dear Dr Jason,
I downloaded the file ‘wine.csv’ from your site.
There seems to be a format error when loading the dataset.
If I downloaded as in the above code:
The above does not look right. So I added another parameter in read_csv
Conclusion
For the downloaded file wine.csv, you need to have read_csv include the parameter delim_whitespace = True, otherwise without the parameter, you get the mess shown at the beginning of my comment
Hope that helps,
Anthony of Sydney
Here is the dataset in CSV format:
https://raw.githubusercontent.com/jbrownlee/Datasets/master/wine.csv
All datasets are located here:
https://github.com/jbrownlee/Datasets
Dear Dr Jason,
Thank you for this tutorial.
Under the subheading “Grid Search Approach to Data Preparation” there is a function called
I noticed that passing the ‘model’ parameter did not get attached to the pipeline. Nor was the ‘model’ added as part of a pipeline.
So I re-wrote the module without passing the ‘model’ parameter such as:
I obtained the same result using the get_pipelines() function.
What is the purpose of passing the ‘model’ variable in get_pipelines? It does not get attached to a particular pipeline within the get_pipelines(model) function.
Not including ‘model’ parameter in the get_pipelines() function produced the same result
Thank you,
Anthony of Sydney.
Dear Dr Jason,
PROBLEM SOLVED – THE ‘model’ variable is still used as a step for various pipelines within get_pipelines() because it ‘model’ is a global variable.
The reason why we got the same result is that whether get_pipelines(model) OR get_pipelines(), the ‘model’ is still added to the steps within the get_pipelines(model) or get_pipelines().
How does model get passed without needing the ‘model’ parameter in get_pipelines()?
Answer is that ‘model’ is GLOBAL.
How is that GLOBAL?
Answer ‘model’ is a global variable which the function get_pipelines() uses the globally declared variable ‘model’ within the get_pipelines().
You may ask how does it get used within get_pipelines()?
Answer: here is a typical few lines used in get_pipelines():
Conclusion – this is the danger of using global variables. If a module/function needs to be passed to a module, the parameter needs to be a different name to the global variable to limit the scope of the global variable.
Thank you,
Anthony of Sydney
No, “model” is passed as an argument to get_pipelines() where it is added to the end of each pipeline.
The model is added to the end of each pipeline in that function.
Dear Dr Jason,
Thank you for your reply. I should have been clearer.
Yes ‘model’ is added to the end of each pipeline “,,,within that function.” At the same time, there was no need to declare the function as get_pipelines(model) since ‘model’ was (i) declared outside the function and (ii) because ‘model’ was declared outside the function, ‘model’ was able to be used within get_pipelines() without passing the parameter ‘model’ in your version of get_pipelines(model).
Thus ‘model’ in your example is global.
Thank you, your response is appreciated,
Anthony of Sydney
Yes, but I don’t recommend using/relying-on globals, therefore it was provided as an argument to the function for use within the function.
Dear Dr Jason,
Thank you, it is appreciated. It clarified the danger of global variables.
Anthony of Sydney.