An empirical distribution function provides a way to model and sample cumulative probabilities for a data sample that does not fit a standard probability distribution.
As such, it is sometimes called the empirical cumulative distribution function, or ECDF for short.
In this tutorial, you will discover the empirical probability distribution function.
After completing this tutorial, you will know:
- Some data samples cannot be summarized using a standard distribution.
- An empirical distribution function provides a way of modeling cumulative probabilities for a data sample.
- How to use the statsmodels library to model and sample an empirical cumulative distribution function.
Kick-start your project with my new book Probability for Machine Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

How to Use an Empirical Distribution Function in Python
Photo by Gigi Griffis, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
- Empirical Distribution Function
- Bimodal Data Distribution
- Sampling Empirical Distribution
Empirical Distribution Function
Typically, the distribution of observations for a data sample fits a well-known probability distribution.
For example, the heights of humans will fit the normal (Gaussian) probability distribution.
This is not always the case. Sometimes the observations in a collected data sample do not fit any known probability distribution and cannot be easily forced into an existing distribution by data transforms or parameterization of the distribution function.
Instead, an empirical probability distribution must be used.
There are two main types of probability distribution functions we may need to sample; they are:
- Probability Density Function (PDF).
- Cumulative Distribution Function (CDF).
The PDF returns the expected probability for observing a value. For discrete data, the PDF is referred to as a Probability Mass Function (PMF). The CDF returns the expected probability for observing a value less than or equal to a given value.
An empirical probability density function can be fit and used for a data sampling using a nonparametric density estimation method, such as Kernel Density Estimation (KDE).
An empirical cumulative distribution function is called the Empirical Distribution Function, or EDF for short. It is also referred to as the Empirical Cumulative Distribution Function, or ECDF.
The EDF is calculated by ordering all of the unique observations in the data sample and calculating the cumulative probability for each as the number of observations less than or equal to a given observation divided by the total number of observations.
As follows:
- EDF(x) = number of observations <= x / n
Like other cumulative distribution functions, the sum of probabilities will proceed from 0.0 to 1.0 as the observations in the domain are enumerated from smallest to largest.
To make the empirical distribution function concrete, let’s look at an example with a dataset that clearly does not fit a known probability distribution.
Want to Learn Probability for Machine Learning
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Bimodal Data Distribution
We can define a dataset that clearly does not match a standard probability distribution function.
A common example is when the data has two peaks (bimodal distribution) or many peaks (multimodal distribution).
We can construct a bimodal distribution by combining samples from two different normal distributions. Specifically, 300 examples with a mean of 20 and a standard deviation of five (the smaller peak), and 700 examples with a mean of 40 and a standard deviation of five (the larger peak).
The means were chosen close together to ensure the distributions overlap in the combined sample.
The complete example of creating this sample with a bimodal probability distribution and plotting the histogram is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 |
# example of a bimodal data sample from matplotlib import pyplot from numpy.random import normal from numpy import hstack # generate a sample sample1 = normal(loc=20, scale=5, size=300) sample2 = normal(loc=40, scale=5, size=700) sample = hstack((sample1, sample2)) # plot the histogram pyplot.hist(sample, bins=50) pyplot.show() |
Running the example creates the data sample and plots the histogram.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
We have fewer samples with a mean of 20 than samples with a mean of 40, which we can see reflected in the histogram with a larger density of samples around 40 than around 20.
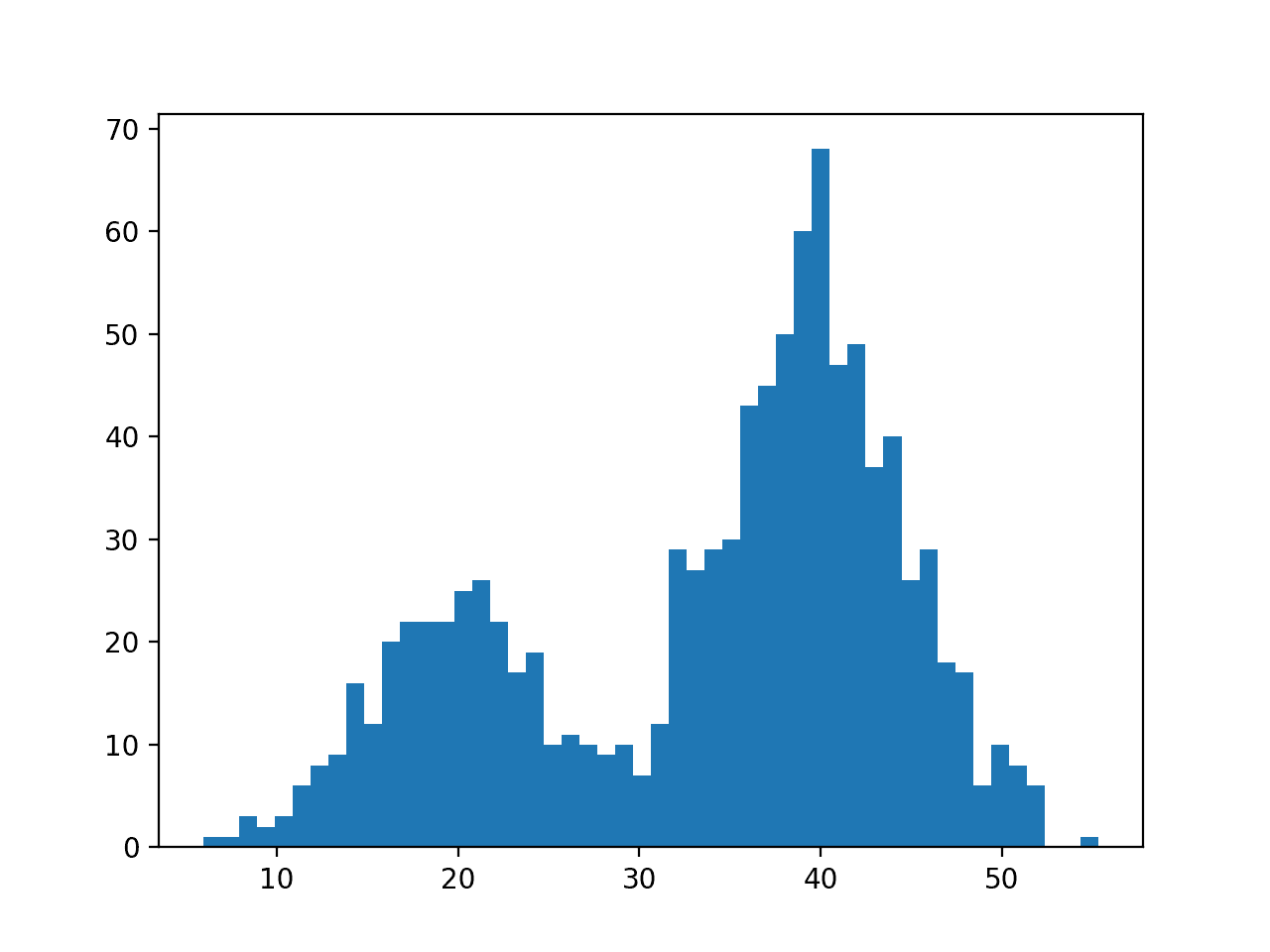
Histogram Plot of Data Sample With a Bimodal Probability Distribution
Data with this distribution does not nicely fit into a common probability distribution by design.
Below is a plot of the probability density function (PDF) of this data sample.
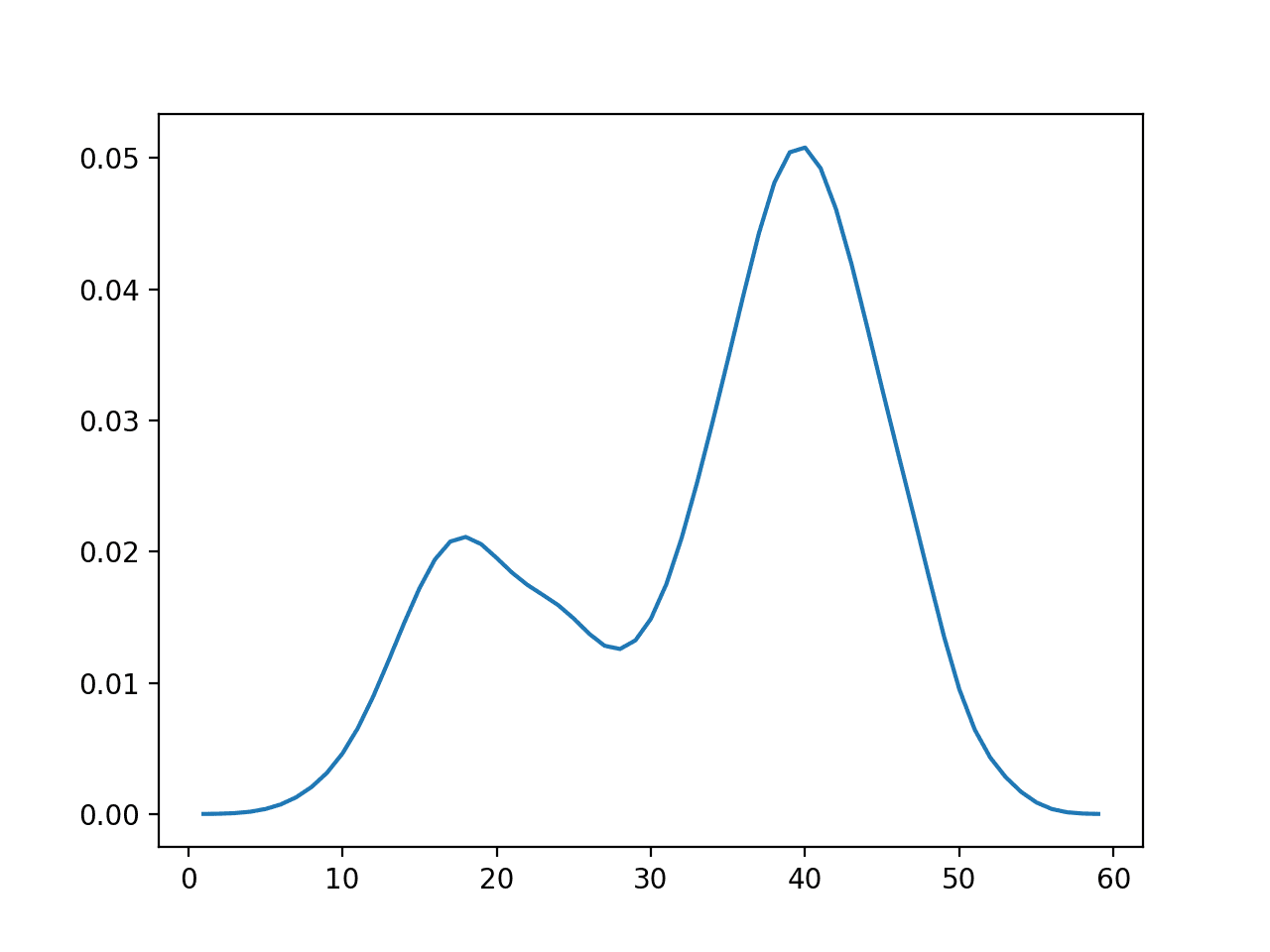
Empirical Probability Density Function for the Bimodal Data Sample
It is a good case for using an empirical distribution function.
Calculate the Empirical Distribution Function
An empirical distribution function can be fit for a data sample in Python.
The statmodels Python library provides the ECDF class for fitting an empirical cumulative distribution function and calculating the cumulative probabilities for specific observations from the domain.
The distribution is fit by calling ECDF() and passing in the raw data sample.
|
1 2 3 |
... # fit a cdf ecdf = ECDF(sample) |
Once fit, the function can be called to calculate the cumulative probability for a given observation.
|
1 2 3 4 5 |
... # get cumulative probability for values print('P(x<20): %.3f' % ecdf(20)) print('P(x<40): %.3f' % ecdf(40)) print('P(x<60): %.3f' % ecdf(60)) |
The class also provides an ordered list of unique observations in the data (the .x attribute) and their associated probabilities (.y attribute). We can access these attributes and plot the CDF function directly.
|
1 2 3 4 |
... # plot the cdf pyplot.plot(ecdf.x, ecdf.y) pyplot.show() |
Tying this together, the complete example of fitting an empirical distribution function for the bimodal data sample is below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# fit an empirical cdf to a bimodal dataset from matplotlib import pyplot from numpy.random import normal from numpy import hstack from statsmodels.distributions.empirical_distribution import ECDF # generate a sample sample1 = normal(loc=20, scale=5, size=300) sample2 = normal(loc=40, scale=5, size=700) sample = hstack((sample1, sample2)) # fit a cdf ecdf = ECDF(sample) # get cumulative probability for values print('P(x<20): %.3f' % ecdf(20)) print('P(x<40): %.3f' % ecdf(40)) print('P(x<60): %.3f' % ecdf(60)) # plot the cdf pyplot.plot(ecdf.x, ecdf.y) pyplot.show() |
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running the example fits the empirical CDF to the data sample, then prints the cumulative probability for observing three values.
|
1 2 3 |
P(x<20): 0.149 P(x<40): 0.654 P(x<60): 1.000 |
Then the cumulative probability for the entire domain is calculated and shown as a line plot.
Here, we can see the familiar S-shaped curve seen for most cumulative distribution functions, here with bumps around the mean of both peaks of the bimodal distribution.
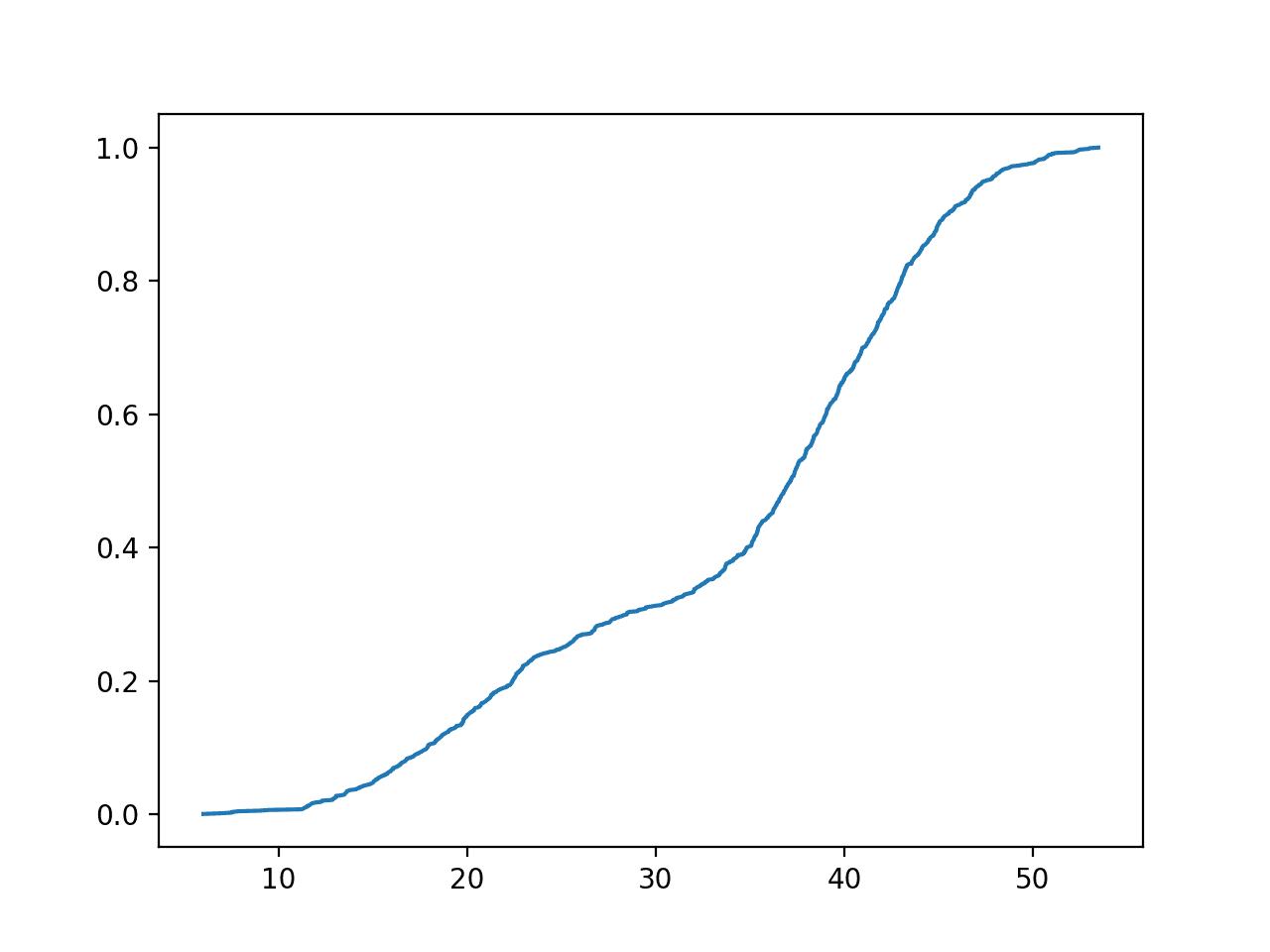
Empirical Cumulative Distribution Function for the Bimodal Data Sample
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Books
- Section 2.3.4 The empirical distribution, Machine Learning: A Probabilistic Perspective, 2012.
- Section 3.9.5 The Dirac Distribution and Empirical Distribution, Deep Learning, 2016.
API
Articles
- Empirical distribution function, Wikipedia.
- Cumulative distribution function, Wikipedia.
- Probability Density Function, Wikipedia.
- Kernel density estimation, Wikipedia.
Summary
In this tutorial, you discovered the empirical probability distribution function.
Specifically, you learned:
- Some data samples cannot be summarized using a standard distribution.
- An empirical distribution function provides a way of modeling cumulative probabilities for a data sample.
- How to use the statsmodels library to model and sample an empirical cumulative distribution function.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Get a Handle on Probability for Machine Learning!

Develop Your Understanding of Probability
...with just a few lines of python codeDiscover how in my new Ebook:
Probability for Machine Learning
It provides self-study tutorials and end-to-end projects on:
Bayes Theorem, Bayesian Optimization, Distributions, Maximum Likelihood, Cross-Entropy, Calibrating Models
and much more...






Nice Jason
Thanks!
The plot with title “Empirical Probability Density Function for the Bimodal Data Sample”. Are you sure that is empirical but not the real mixure distribution?
I believe I used KDE to estimate the PDF for the raw obs.
I made these two examples a while ago on how to fit distributions with scipy. They’re quite simple and some people might find them useful:
Kernel Density: https://glowingpython.blogspot.com/2012/08/kernel-density-estimation-with-scipy.html
Parametric distributions: https://glowingpython.blogspot.com/2012/07/distribution-fitting-with-scipy.html
Thanks for sharing.
Thank you again Jason,
I would like to know if you have made another example to explore the number of peaks…
I see that this example deals with a very special case of just two peaks…
thank you
The same example can be adapted for multiple peaks.
Hi Jason!
Can the ECDF be used as feature for training, just as like using rolling window statistics like mean etc. for model training and prediction? Is there a possibility of “data leakage”?
Thanks
Perhaps, if it is prepared using training data only you wont have leakage.
Try your idea and see.
Nice article. Thank you. I learned as you explained it simply and with good examples.
However, in the second box of code where you call the ECDF class, the line with importing this class is missing from statsmodels package.
Which example exactly?
Good day, i want to find the empirical distribution of classes a multiclass datasets.
It would be a multinomial distribution:
https://machinelearningmastery.com/discrete-probability-distributions-for-machine-learning/
if we type ecdf (20), we get the corresponding ECDF. How one can get the corresponding number by entering the ECDF?
Hi Sohaib…The following discussion may be beneficial:
https://stackoverflow.com/questions/44132543/python-inverse-empirical-cumulative-distribution-function-ecdf
if we want to find p(x>20) what to do
Hi L_R…The following discussion may help clarify:
https://stackoverflow.com/questions/44132543/python-inverse-empirical-cumulative-distribution-function-ecdf
How do I extract percentile or quantile values from the fitted ECDF Plot or KDE Plot. I want to know the x values for 50% and 90% from ECDF or KDE plot. The solution i find in the internet says to sort the data and find quantile values using some percentile function, but what is the use of creating a density function from ECDF to fit the distribution as close to actual samples when we cannot extract the quantile/percentile values from it? Any idea on how to extract percentile values from ECDF and KDE?
Hi AJAY…The following may be of interest to you:
https://www.statsmodels.org/dev/generated/statsmodels.distributions.empirical_distribution.ECDF.html