Using a Haar cascade classifier in OpenCV is simple. You just need to provide the trained model in an XML file to create the classifier. Training one from scratch, however, is not so straightforward. In this tutorial, you will see how the training should be like. In particular, you will learn:
What are the tools to train a Haar cascade in OpenCV
How to prepare data for training
How to run the training
Kick-start your project with my book Machine Learning in OpenCV. It provides self-study tutorials with working code.
Let’s get started.
Training a Haar Cascade Object Detector in OpenCV Photo by Adrià Crehuet Cano. Some rights reserved.
Overview
This post is divided into five parts; they are:
The Problem of Training Cascade Classifier in OpenCV
Setup of Environment
Overview of the Training of Cascade Classifier
Prepare Training DAta
Training Haar Cascade Classifier
The Problem of Training Cascade Classifier in OpenCV
OpenCV has been around for many years and has many versions. OpenCV 5 is in development at the time of writing and the recommended version is OpenCV 4, or version 4.8.0, to be precise.
There has been a lot of clean-up between OpenCV 3 and OpenCV 4. Most notably a large amount of code has been rewritten. The change is substantial and quite a number of functions are changed. This included the tool to train the Haar cascade classifier.
A cascade classifier is not a simple model like SVM that you can train easily. It is an ensemble model that uses AdaBoost. Therefore, the training involves multiple steps. OpenCV 3 has a command line tool to help do such training, but the tool has been broken in OpenCV 4. The fix is not available yet.
Therefore, it is only possible to train a Haar cascade classifier using OpenCV 3. Fortunately, you can discard it after the training and revert to OpenCV 4 once you save the model in an XML file. This is what you are going to do in this post.
You cannot have OpenCV 3 and OpenCV 4 co-exist in Python. Therefore, it is recommended to create a separate environment for training. In Python, you can use the venv module to create a virtual environment, which is simply to create a separate set of installed modules. Alternatives would be using Anaconda or Pyenv, which are different architectures under the same philosophy. Among all of the above, you should see the Anaconda environment as the easiest for this task.
Want to Get Started With Machine Learning with OpenCV?
Take my free email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Setup of Environment
It is easier if you’re using Anaconda, you can use the following command to create and use a new environment and name it as “cvtrain”:
1
2
conda create-ncvtrain python'opencv>=3,<4'
conda activate cvtrain
You know you’re ready if you find the command opencv_traincascade is available:
If you’re using pyenv or venv, you need more steps. First, create an environment and install OpenCV (you should notice the different name of the package than Anaconda ecosystem):
1
2
3
4
# create an environment and install opencv 3
pyenv virtualenv3.11cvtrain
pyenv activate cvtrain
pip install'opencv-python>=3,<4'
This allows you to run Python programs using OpenCV but you do not have the command line tools for training. To get the tools, you need to compile them from source code by following these steps:
Download OpenCV source code and switch to 3.4 branch
1
2
3
4
5
# download OpenCV source code and switch to 3.4 branch
git clonehttps://github.com/opencv/opencv
cd opencv
git checkout3.4
cd..
Create the build directory separate from the repository directory:
1
2
mkdir build
cd build
Prepare the build directory with cmake tool, and referring to the OpenCV repository:
1
cmake../opencv
Run make to compile (you may need to have the developer libraries installed in your system first)
1
2
make
ls bin
The tools you need will be in the bin/ directory, as shown by the last command above
The command line tools needed are opencv_traincascade and opencv_createsamples. The rest of this post assumes you have these tools available.
Overview of the Training of Cascade Classifier
You are going to train a cascade classifier using OpenCV tools. The classifier is an ensemble model using AdaBoost. Simply, multiple smaller models are created where each of them is weak in classification. Combined, it becomes a strong classifier with a good rates of precision and recall.
Each of the weak classifiers is a binary classifier. To train them, you need some positive samples and negative samples. The negative samples are easy: You provide some random pictures to OpenCV and let OpenCV select a rectangular region (better if there are no target objects in these pictures). The positive samples, however, are provided as an image and the bounding box in which the object lies perfectly in the box.
Once these datasets are provided, OpenCV will extract the Haar features from both and use them to train many classifiers. Haar features are from partitioning the positive or negative samples into rectangular regions. How the partitioning is done involves some randomness. Therefore, it takes time for OpenCV to find the best way to derive the Haar features for this classification task.
In OpenCV, you just need to provide the training data in image files in a format that OpenCV can read (such as JPEG or PNG). For negative samples, all it needs is a plain text file of their filenames. For positive samples, an “info file” is required, which is a plaintext file with the details of the filename, how many objects are in the picture, and the corresponding bounding boxes.
The positive data samples for training should be in a binary format. OpenCV provides a tool opencv_createsamples to generate the binary format from the “info file”. Then these positive samples, together with the negative samples, are provided to another tool opencv_traincascade to run the training and produce the model output in the format of an XML file. This is the XML file you can load into a OpenCV Haar cascade classifier.
Prepare Training Data
Let’s consider creating a cat face detector. To train such a detector, you need the dataset first. One possibility is the Oxford-IIIT Pet Dataset, at this location:
This is an 800MB dataset, a small one by the standards of computer vision datasets. The images are annotated in the Pascal VOC format. In short, each image has a corresponding XML file that looks like the following:
XHTML
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
<?xml version="1.0"?>
<annotation>
<folder>OXIIIT</folder>
<filename>Abyssinian_100.jpg</filename>
<source>
<database>OXFORD-IIIT Pet Dataset</database>
<annotation>OXIIIT</annotation>
<image>flickr</image>
</source>
<size>
<width>394</width>
<height>500</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>cat</name>
<pose>Frontal</pose>
<truncated>0</truncated>
<occluded>0</occluded>
<bndbox>
<xmin>151</xmin>
<ymin>71</ymin>
<xmax>335</xmax>
<ymax>267</ymax>
</bndbox>
<difficult>0</difficult>
</object>
</annotation>
The XML file tells you which image file it is referring to (Abyssinian_100.jpg in the example above), and what object it contains, with the bounding box between the tags <bndbox></bndbox>.
To extract the bounding boxes from the XML file, you can use the following function:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import xml.etree.ElementTree asET
def read_voc_xml(xmlfile:str)->dict:
root=ET.parse(xmlfile).getroot()
boxes={"filename":root.find("filename").text,
"objects":[]}
forbox inroot.iter('object'):
bb=box.find('bndbox')
obj={
"name":box.find('name').text,
"xmin":int(bb.find("xmin").text),
"ymin":int(bb.find("ymin").text),
"xmax":int(bb.find("xmax").text),
"ymax":int(bb.find("ymax").text),
}
boxes["objects"].append(obj)
returnboxes
An example of the dictionary returned by the above function is as follows:
With these, it is easy to create the dataset for the training: In the Oxford-IIT Pet dataset, the photos are either cats or dogs. You can let all dog photos as negative samples. Then all the cat photos will be positive samples with appropriate bounding box set.
The “info file” that OpenCV expects for positive samples is a plaintext file with each line in the following format:
1
filename N x0 y0 w0 h0 x1 y1 w1 h1 ...
The number following the filename is the count of bounding boxes on that image. Each bounding box is a positive sample. What follows it are the bounding boxes. Each box is specified by the pixel coordinate at its top left corner and the width and height of the box. For the best result of the Haar cascade classifier, the bounding box should be in the same aspect ratio as the model expects.
Assume the Pet dataset you downloaded is located in the directory dataset/, which you should see the files are organized like the following:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
dataset
|--annotations
||--README
||--list.txt
||--test.txt
||--trainval.txt
||--trimaps
|||--Abyssinian_1.png
|||--Abyssinian_10.png
||...
|||--yorkshire_terrier_98.png
||`--yorkshire_terrier_99.png
|`--xmls
||--Abyssinian_1.xml
||--Abyssinian_10.xml
|...
||--yorkshire_terrier_189.xml
|`--yorkshire_terrier_190.xml
`--images
|--Abyssinian_1.jpg
|--Abyssinian_10.jpg
...
|--yorkshire_terrier_98.jpg
`--yorkshire_terrier_99.jpg
With this, it is easy to create the “info file” for positive samples and the list of negative sample files, using the following program:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
import pathlib
import xml.etree.ElementTree asET
import numpy asnp
def read_voc_xml(xmlfile:str)->dict:
"""read the Pascal VOC XML and return (filename, object name, bounding box)
where bounding box is a vector of (xmin, ymin, xmax, ymax). The pixel
# write the output to `negative.dat` and `postiive.dat`
with open("negative.dat","w")asfp:
fp.write("\n".join(negative))
with open("positive.dat","w")asfp:
fp.write("\n".join(positive))
This program scans all the XML files from the dataset, then extracts the bounding boxes from each if it is a cat photo. The list negative will hold the paths to dog photos. The list positive will hold the paths to cat photos as well as the bounding boxes in the format described above, each line as one string. After the loop, these two lists are written to the disk as files negative.dat and positive.dat.
The content of negative.dat is trivial. The content of postiive.dat is like the following:
1
2
3
4
5
dataset/images/Siamese_102.jpg115492194176
dataset/images/Bengal_152.jpg1848187201
dataset/images/Abyssinian_195.jpg186109115
dataset/images/Russian_Blue_135.jpg122890103117
dataset/images/Persian_122.jpg16016230228
The step before you run the training is to convert positive.dat into a binary format. This is done using the following command line:
This command should be run in the same directory as positive.dat such that the dataset images can be found. The output of this command will be positive.vec. It is also known as the “vec file”. In doing so, you need to specify the width and height of the window using -w and -h arguments. This is to resize the image cropped by the bounding box into this pixel size before writing to the vec file. This should also match the window size specified when you run the training.
Training Haar Cascade Classifier
Training a classifier takes time. It is done in multiple stages. Intermediate files are to be written in each stage, and once all the stages are completed, you will have the trained model saved in an XML file. OpenCV expects all these generated files to be stored in a directory.
Run the training process is indeed straightforward. Let’s consider creating a new directory cat_detect to store the generated files. Once the directory is created, you can run the training using the command line tool opencv_traincascade:
Note the use of positive.vec as positive samples and negative.dat as negative samples. Also note that, the -w and -h parameters are same as what you used previously in the opencv_createsamples command. Other command line arguments are explained as follows:
-data <dirname>: Where the trained classifier is stored. This directory should already exist
-vec <filename>: The vec file of positive samples
-bg <filename>: The list of negative samples, also known as “background” images
-numPos <N>: number of positive samples used in training for every stage
-numNeg <N>: number of negative samples used in training for every stage
-numStages <N>: number of cascade stages to be trained
-w <width> and -h <height>: The pixel size for an object. This must be the same as used during training samples creation with opencv_createsamples tool
-minHitRate <rate>: The minimum desired true positive rate for each stage. Training a stage would not terminate until this is met.
-maxFalseAlarmRate <rate>: The maximum desired false positive rate for each stage. Training a stage would not terminate until this is met.
-maxDepth <N>: maximum depth of a weak tree
-maxWeakCount <N>: maximum number of weak trees for every stage
Not all of these arguments are required. But you should try different combinations to see if you can train a better detector.
During training, you will see the following screen:
Number of unique features given windowSize [30,30] : 394725
===== TRAINING 0-stage =====
<BEGIN
POS count : consumed 900 : 900
NEG count : acceptanceRatio 2000 : 1
Precalculation time: 3
+----+---------+---------+
| N | HR | FA |
+----+---------+---------+
| 1| 1| 1|
+----+---------+---------+
| 2| 1| 1|
+----+---------+---------+
| 3| 1| 1|
+----+---------+---------+
| 4| 1| 0.8925|
+----+---------+---------+
| 5| 0.998889| 0.7785|
...
| 19| 0.995556| 0.503|
+----+---------+---------+
| 20| 0.995556| 0.492|
+----+---------+---------+
END>
...
Training until now has taken 0 days 2 hours 55 minutes 44 seconds.
===== TRAINING 9-stage =====
<BEGIN
POS count : consumed 900 : 948
NEG count : acceptanceRatio 2000 : 0.00723552
Precalculation time: 4
+----+---------+---------+
| N | HR | FA |
+----+---------+---------+
| 1| 1| 1|
+----+---------+---------+
| 2| 1| 1|
+----+---------+---------+
| 3| 1| 1|
+----+---------+---------+
| 4| 1| 1|
+----+---------+---------+
| 5| 0.997778| 0.9895|
...
| 50| 0.995556| 0.5795|
+----+---------+---------+
| 51| 0.995556| 0.4895|
+----+---------+---------+
END>
Training until now has taken 0 days 3 hours 25 minutes 12 seconds.
You should notice that the training run for $N$ stages is numbered 0 to $N-1$. Some stages may take longer to train. At the beginning, the training parameters are displayed to make clear what it is doing. Then in each stage, a table will be printed, one row at a time. The table shows three columns: The feature number N, the hit rate HR (true positive rate) and the false alarm rate FA (false positive rate).
Before stage 0, you should see it printed minHitRate of 0.995 and maxFalseAlarmRate of 0.5. Therefore, each stage will find many Haar features until the classifier can keep the hit rate above 0.995 while the false alarm rate is below 0.5. Ideally you want the hit rate be 1 and the false alarm rate be 0. Since Haar cascade is an ensemble, you get a correct prediction if you are right in the majority. Approximately, you can consider the classifier of $n$ stages with hit rate $p$ and false alarm rate $q$ to have overall hit rate $p^n$ and overall false alarm rate $q^n$. In the above setting, $n=10$, $p>0.995$, $q<0.5$. Therefore, the overall false alarm rate would be below 0.1% and overall hit rate above 95%.
This training command takes over 3 hours to finish on a modern computer. The output will be named cascade.xml under the output directory. You can check the result with a sample code like the following:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
import cv2
image='dataset/images/Abyssinian_88.jpg'
model='cat_detect/cascade.xml'
classifier=cv2.CascadeClassifier(model)
img=cv2.imread(image)
# Convert the image to grayscale
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# Perform object detection
objects=classifier.detectMultiScale(gray,
scaleFactor=1.1,minNeighbors=5,
minSize=(30,30))
# Draw rectangles around detected objects
for(x,y,w,h)inobjects:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
# Display the result
cv2.imshow('Object Detection',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
The result would depends on how well your model trained, and also depends on the arguments you passed on into detectMultiScale(). See the previous post for how to set up these arguments.
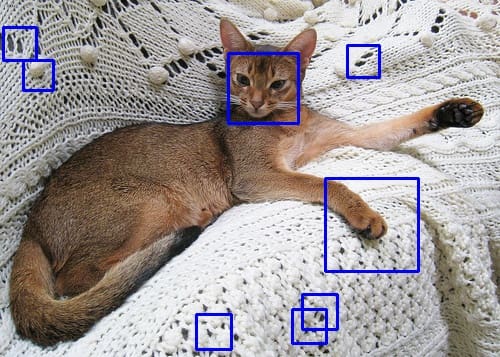
The above code runs the detector in one image from the dataset. You may see a result like the following:
Example output using the trained Haar cascade object detector
You see some false positives, but the cat’s face has been detected. There are multiple ways to improve the quality. For example, the training dataset you used above does not use a square bounding box, while you used a square shape for training and detection. Adjusting the dataset may improve. Similarly, the other parameters you used on the training command line also affect the result. However, you should be aware that Haar cascade detector is very fast but the more stages you use, the slower it will be.
Further Reading
This section provides more resources on the topic if you want to go deeper.
It provides self-study tutorials with all working code in Python to turn you from a novice to expert. It equips you with logistic regression, random forest, SVM, k-means clustering, neural networks,
and much more...all using the machine learning module in OpenCV
Kick-start your deep learning journey with hands-on exercises
Hi Pedro…The opencv_traincascade command is used in OpenCV for training a cascade classifier (typically used in face or object detection), but if you’re encountering a “command not found” error, it likely means that the command isn’t in your system’s PATH, or OpenCV hasn’t been installed correctly.
Here are steps to troubleshoot:
1. **Check OpenCV Installation**:
– Ensure that OpenCV is installed with the extra modules, which include opencv_traincascade.
– If OpenCV was compiled from source, verify that the installation path includes the executable.
2. **Locate the Executable**:
– You can use find or locate to find opencv_traincascade: bash
find / -name "opencv_traincascade" 2>/dev/null
– Note the location of the executable if it’s found.
3. **Add to PATH**:
– If the executable is located outside standard directories (like /usr/local/bin), you can add it to your PATH: bash
export PATH=$PATH:/path/to/opencv/bin
– Replace /path/to/opencv/bin with the directory where opencv_traincascade is located. Add this line to your .bashrc or .zshrc file to make it persistent.
4. **Rebuild OpenCV with Contrib Modules**:
– If you don’t find the command, it might be missing because OpenCV wasn’t built with the contrib modules. You can install OpenCV with these modules as follows: bash
git clone https://github.com/opencv/opencv.git
git clone https://github.com/opencv/opencv_contrib.git
mkdir -p build && cd build
cmake -D OPENCV_EXTRA_MODULES_PATH=../opencv_contrib/modules ../opencv
make -j4
sudo make install
– This will ensure that opencv_traincascade is included.
After these steps, try running opencv_traincascade again. Let me know if the issue persists, and I can help with further troubleshooting.








I’m getting command not found when running opencv_traincascade
Hi Pedro…The
opencv_traincascadecommand is used in OpenCV for training a cascade classifier (typically used in face or object detection), but if you’re encountering a “command not found” error, it likely means that the command isn’t in your system’s PATH, or OpenCV hasn’t been installed correctly.Here are steps to troubleshoot:
1. **Check OpenCV Installation**:
– Ensure that OpenCV is installed with the extra modules, which include
opencv_traincascade.– If OpenCV was compiled from source, verify that the installation path includes the executable.
2. **Locate the Executable**:
– You can use
findorlocateto findopencv_traincascade:bash
find / -name "opencv_traincascade" 2>/dev/null
– Note the location of the executable if it’s found.
3. **Add to PATH**:
– If the executable is located outside standard directories (like
/usr/local/bin), you can add it to your PATH:bash
export PATH=$PATH:/path/to/opencv/bin
– Replace
/path/to/opencv/binwith the directory whereopencv_traincascadeis located. Add this line to your.bashrcor.zshrcfile to make it persistent.4. **Rebuild OpenCV with Contrib Modules**:
– If you don’t find the command, it might be missing because OpenCV wasn’t built with the contrib modules. You can install OpenCV with these modules as follows:
bash
git clone https://github.com/opencv/opencv.git
git clone https://github.com/opencv/opencv_contrib.git
mkdir -p build && cd build
cmake -D OPENCV_EXTRA_MODULES_PATH=../opencv_contrib/modules ../opencv
make -j4
sudo make install
– This will ensure that
opencv_traincascadeis included.After these steps, try running
opencv_traincascadeagain. Let me know if the issue persists, and I can help with further troubleshooting.