It is a central question in applied machine learning.
In a recent paper by Randal Olson and others, they attempt to answer it and give you a guide for algorithms and parameters to try on your problem first, before spot checking a broader suite of algorithms.
In this post, you will discover a study and findings from evaluating many machine learning algorithms across a large number of machine learning datasets and the recommendations made from this study.
After reading this post, you will know:
That ensemble tree algorithms perform well across a wide range of datasets.
That it is critical to test a suite of algorithms on a problem as there is no silver bullet algorithm.
That it is critical to test a suite of configurations for a given algorithm as it can result in as much as a 50% improvement on some problems.
Kick-start your project with my new book XGBoost With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Start With Gradient Boosting, but Always Spot Check Algorithms and Configurations Photo by Ritesh Man Tamrakar, some rights reserved.
The goal of their work was to address the question that every practitioner faces when getting started on their predictive modeling problem; namely:
What algorithm should I use?
The authors describe this problem as choice overload, as follows:
Although having several readily-available ML algorithm implementations is advantageous to bioinformatics researchers seeking to move beyond simple statistics, many researchers experience “choice overload” and find difficulty in selecting the right ML algorithm for their problem at hand.
They approach the problem by running a decent sample of algorithms across a large sample of standard machine learning datasets to see what algorithms and parameters work best in general.
They describe their paper as:
… a thorough analysis of 13 state-of-the-art, commonly used machine learning algorithms on a set of 165 publicly available classification problems in order to provide data-driven algorithm recommendations to current researchers
A total of 13 different algorithms were chosen for the study.
Algorithms were chosen to provide a mix of types or underlying assumptions.
The goal was to represent the most common classes of algorithms used in the literature, as well as recent state-of-the-art algorithms
The complete list of algorithms is provided below.
Gaussian Naive Bayes (GNB)
Bernoulli Naive Bayes (BNB)
Multinomial Naive Bayes (MNB)
Logistic Regression (LR)
Stochastic Gradient Descent (SGD)
Passive Aggressive Classifier (PAC)
Support Vector Classifier (SVC)
K-Nearest Neighbor (KNN)
Decision Tree (DT)
Random Forest (RF)
Extra Trees Classifier (ERF)
AdaBoost (AB)
Gradient Tree Boosting (GTB)
The scikit-learn library was used for the implementations of these algorithms.
Each algorithm has zero or more parameters, and a grid search across sensible parameter values was performed for each algorithm.
For each algorithm, the hyperparameters were tuned using a fixed grid search.
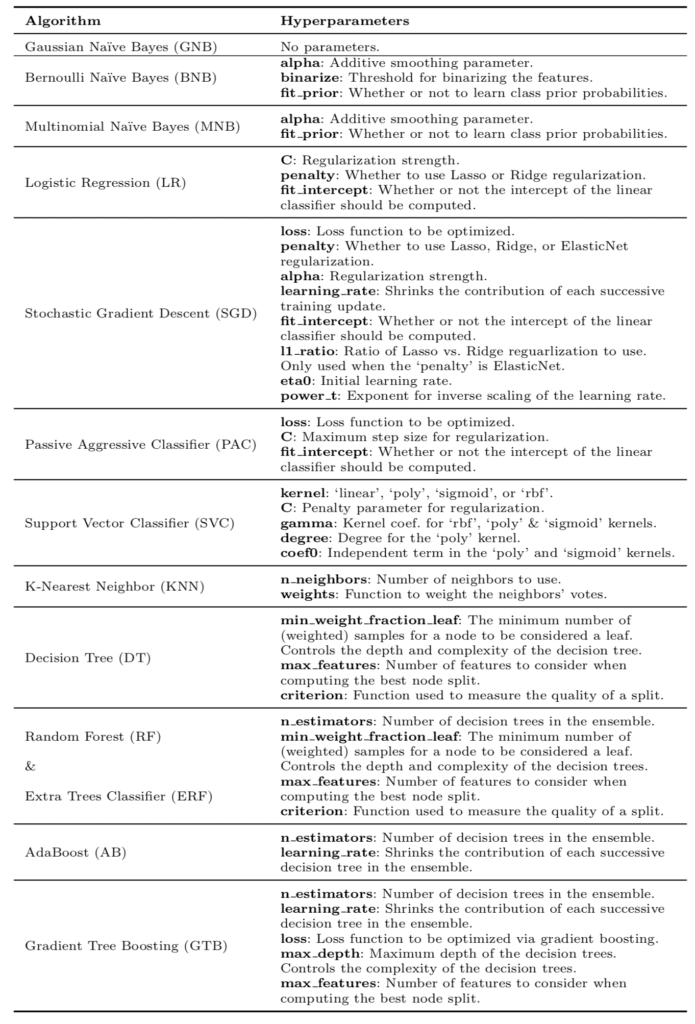
A table of algorithms and the hyperparameters evaluated is listed below, taken from the paper.
Table of Algorithms and Parameters
Algorithms were evaluated using 10-fold cross-validation and the balanced accuracy measure.
Cross-validation was not repeated, perhaps introducing some statistical noise into the results.
Machine Learning Datasets
A selection of 165 standard machine learning problems were selected for the study.
Many of the problems were drawn from the field of bioinformatics, although not all datasets belong to this field of study.
All prediction problems were classification type problems with two or more classes.
The algorithms were compared on 165 supervised classification datasets from the Penn Machine Learning Benchmark (PMLB). […] PMLB is a collection of publicly available classification problems that have been standardized to the same format and collected in a central location with easy access via Python.
The datasets were drawn from the Penn Machine Learning Benchmark (PMLB) collection, which is a project that provides standard machine learning datasets in a uniform format and made available by a simple Python API. You can learn more about this dataset catalog on the GitHub Project:
All datasets were standardized prior to fitting models.
Prior to evaluating each ML algorithm, we scaled the features of every dataset by subtracting the mean and scaling the features to unit variance.
Other data preparation was not performed, nor feature selection or feature engineering.
Analysis of Results
The large number of experiments performed resulted in a lot of skill scores to analyze.
The analysis of the results was handled well, asking interesting questions and providing findings in the form of easy-to-understand charts.
The entire experimental design consisted of over 5.5 million ML algorithm and parameter evaluations in total, resulting in a rich set of data that is analyzed from several viewpoints…
Algorithm performance was ranked for each dataset, then the average rank of each algorithm was calculated.
This provided a rough and easy to understand idea of which algorithms performed well or not, on average.
The results showed that both Gradient boosting and random forest had the lowest rank (performed best) and that the Naive Bayes approaches had the highest rank (performed worst) on average.
The post-hoc test underlines the impressive performance of Gradient Tree Boosting, which significantly outperforms every algorithm except Random Forest at the p < 0.01 level.
This is demonstrated with a nice chart, taken from the paper.
Algorithm Mean Rank
No single algorithm performs best or worst.
This is wisdom known to machine learning practitioners, but difficult to grasp for beginners in the field.
There is no silver bullet and you must test a suite of algorithms on a given dataset to see what works best.
… it is worth noting that no one ML algorithm performs best across all 165 datasets. For example, there are 9 datasets for which Multinomial NB performs as well as or better than Gradient Tree Boosting, despite being the overall worst- and best-ranked algorithms, respectively. Therefore, it is still important to consider different ML algorithms when applying ML to new datasets.
Further, picking the right algorithm is not enough. You must also pick the right configuration of the algorithm for your dataset.
… both selecting the right ML algorithm and tuning its parameters is vitally important for most problems.
The results found that tuning an algorithm lifted skill of a method anywhere from 3% to 50%, depending on the algorithm and the dataset.
The results demonstrate why it is unwise to use default ML algorithm hyperparameters: tuning often improves an algorithm’s accuracy by 3-5%, depending on the algorithm. In some cases, parameter tuning led to CV accuracy improvements of 50%.
This is demonstrated with a chart from the paper that shows the spread of improvement offered by parameter tuning on each algorithm.
Algorithm performance improvement via parameter tuning
Not all algorithms are required.
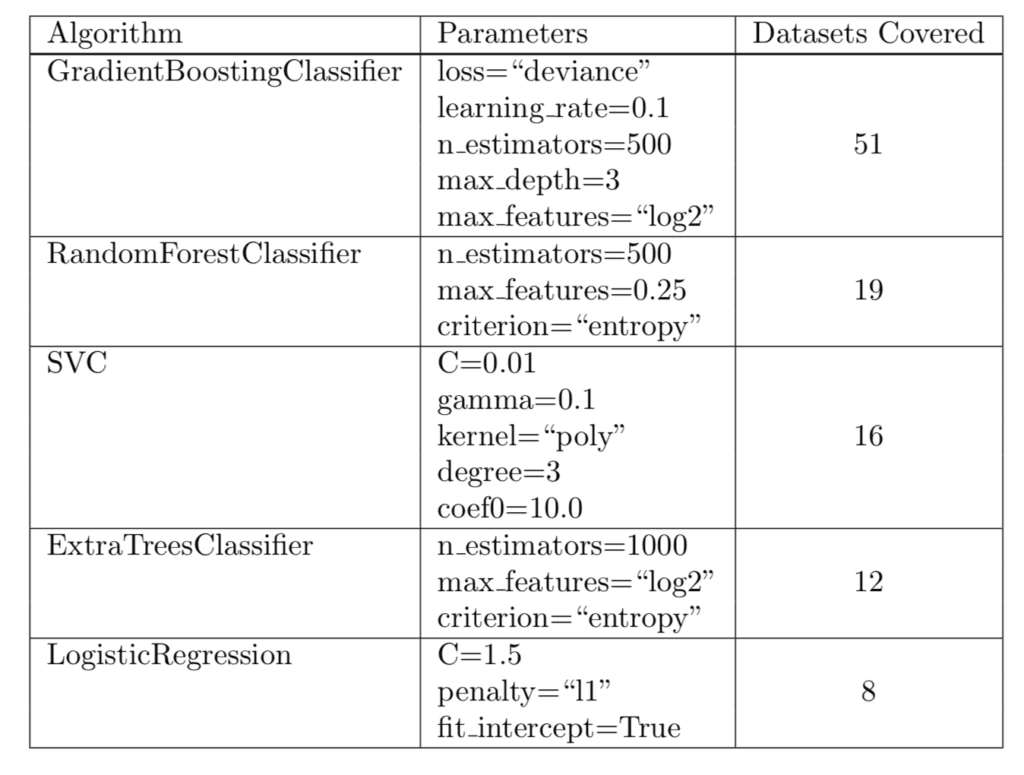
The results found that five algorithms and specific parameters achieved top 1% in performance across 106 of the 165 tested datasets.
These five algorithms are recommended as a starting point for spot checking algorithms on a given dataset in bioinformatics, but I would suggest also more generally:
Gradient Boosting
Random Forest
Support Vector Classifier
Extra Trees
Logistic Regression
The paper provides a table of these algorithms, including the recommend parameter settings and the number of datasets covered, e.g. where the algorithm and configuration achieved top 1% performance.
Suggested Algorithms
Practical Findings
There are two big findings from this paper that are valuable for practitioners, especially those starting out or those who are under pressure to get a result on their own predictive modeling problem.
1. Use Ensemble Trees
If in doubt or under time pressure, use ensemble tree algorithms such as gradient boosting and random forest on your dataset.
The analysis demonstrates the strength of state-of-the-art, tree-based ensemble algorithms, while also showing the problem-dependent nature of ML algorithm performance.
2. Spot Check and Tune
No one can look at your problem and tell you what algorithm to use, and there is no silver bullet algorithm.
You must test a suite of algorithms and a suite of parameters for each algorithm to see what works best for your specific problem.
In addition, the analysis shows that selecting the right ML algorithm and thoroughly tuning its parameters can lead to a significant improvement in predictive accuracy on most problems, and is a critical step in every ML application.
I talk about this all the time; for example, see the post:
I have avoided unsupervised methods because historically I have not found them useful for predictive modeling (the useful part of ML). I will cover them in the future.
Dear Dr Jason,
Based on the chart “the spread of improvement offered by parameter tuning on each algorithm”, isn’t the passive/aggressive algorithm the best one because the boxplot does not have any outliers. But it’s not the ‘top 1%’.
To put in another way how do you interpret the set of boxplots in this chart?
I would recommend looking at the medians or means of the distribution and interpret differences between distributions using statistical hypothesis tests.
Oskar, yes, DataRobot would produce model scoring based on the data and response variable. Rapidminer just put out a product their AutoModeler product. It is very similar.
Both are really good products depending on your intended goals.
Thanks Jason for bringing it to us. What about Simple Neural Networks for classification data sets – I think they will over-perform all 13 ML algorithms. If this is true, then how do you see the future of ML compared to Deep Learning (DL), because with no or very little feature extraction one can get much better results (provided there are sufficient data sets and processing power).
I am presently using R studio for forecasting macroeconomic and financial variables.
Now i want to explore the machine learning for timeseries forecasting.
Thank you for your awesome blog. I have one question about regression and gradientboosting:
I get one variable X that varies in function of time, but we also know that X depending of different features like temperature, flow, etc. and fouling. We would like to correct the X values for a given temperature, given flow etc. … Goal is a the end to have just variation of fouling during time (for a given temperature, given flow… to compare just the fouling). How to do that because if I use regression like gradientboosting, I suppose that of I lose fouling information (if we have overfitting for example).
Thanks,









Hi Jason,
Great post!
A question:
->when to use a deep learning vs Gradient Boosting/Random Forest?
and
->unsupervised learning used to cover classification topics
example
https://github.com/curiousily/Credit-Card-Fraud-Detection-using-Autoencoders-in-Keras
would you please kindly cover unsupervised learning in your blog? We have a lot of articles but zip about unsupervised L….
Would you also kindly cover creation of the simple chat-bot (eg using seq2seq translator you posted?)
Thanks for the suggestions.
I have avoided unsupervised methods because historically I have not found them useful for predictive modeling (the useful part of ML). I will cover them in the future.
Dear Dr Jason,
Based on the chart “the spread of improvement offered by parameter tuning on each algorithm”, isn’t the passive/aggressive algorithm the best one because the boxplot does not have any outliers. But it’s not the ‘top 1%’.
To put in another way how do you interpret the set of boxplots in this chart?
Thank you,
Anthony of Belield
I would recommend looking at the medians or means of the distribution and interpret differences between distributions using statistical hypothesis tests.
This is more or less what datarobot.com professes to do, right?
I don’t know sorry.
Oskar, yes, DataRobot would produce model scoring based on the data and response variable. Rapidminer just put out a product their AutoModeler product. It is very similar.
Both are really good products depending on your intended goals.
Thanks for sharing. I expect that amazon/google ML API services do the same sort of thing.
Great article, well-written and organized.
I’m just getting started with this stuff now and appreciate resources like this.
Thanks. I hope it helps.
Thanks Jason for bringing it to us. What about Simple Neural Networks for classification data sets – I think they will over-perform all 13 ML algorithms. If this is true, then how do you see the future of ML compared to Deep Learning (DL), because with no or very little feature extraction one can get much better results (provided there are sufficient data sets and processing power).
No one single algorithm is the best at all problems.
Stochastic gradient boosting is great for tabular data, neural nets are great for text/image and other analog data.
Great article!
Thanks.
I am presently using R studio for forecasting macroeconomic and financial variables.
Now i want to explore the machine learning for timeseries forecasting.
Great!
Hi Jason,
Is there a plan on your end to have a XGBOOST example with multiclassification problem? Or can you suggest a reliable source for that?
Thanks
You can adapt any binary classification example for multi-class classification.
Hi Jason,
Thank you for your awesome blog. I have one question about regression and gradientboosting:
I get one variable X that varies in function of time, but we also know that X depending of different features like temperature, flow, etc. and fouling. We would like to correct the X values for a given temperature, given flow etc. … Goal is a the end to have just variation of fouling during time (for a given temperature, given flow… to compare just the fouling). How to do that because if I use regression like gradientboosting, I suppose that of I lose fouling information (if we have overfitting for example).
Thanks,
Sounds like you want to model a time series dataset with xgboost.
In that case, past observations become input features. This will help:
https://machinelearningmastery.com/convert-time-series-supervised-learning-problem-python/