The most commonly reported measure of classifier performance is accuracy: the percent of correct classifications obtained.
This metric has the advantage of being easy to understand and makes comparison of the performance of different classifiers trivial, but it ignores many of the factors which should be taken into account when honestly assessing the performance of a classifier.
What Is Meant By Classifier Performance?
Classifier performance is more than just a count of correct classifications.
Consider, for interest, the problem of screening for a relatively rare condition such as cervical cancer, which has a prevalence of about 10% (actual stats). If a lazy Pap smear screener was to classify every slide they see as “normal”, they would have a 90% accuracy. Very impressive! But that figure completely ignores the fact that the 10% of women who do have the disease have not been diagnosed at all.
Some Performance Metrics
In a previous blog post we discussed some of the other performance metrics which can be applied to the assessment of a classifier. To review:
Most classifiers produce a score, which is then thresholded to decide the classification. If a classifier produces a score between 0.0 (definitely negative) and 1.0 (definitely positive), it is common to consider anything over 0.5 as positive.
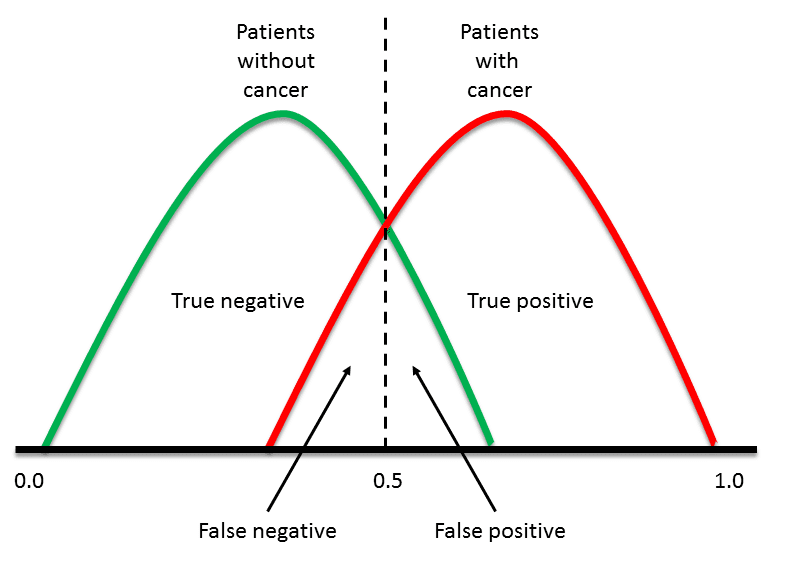
However, any threshold applied to a dataset (in which PP is the positive population and NP is the negative population) is going to produce true positives (TP), false positives (FP), true negatives (TN) and false negatives (FN) (Figure 1). We need a method which will take into account all of these numbers.
Figure 1. Overlapping datasets will always generate false positives and negatives as well as true positives and negatives
Once you have numbers for all of these measures, some useful metrics can be calculated.
Accuracy = (1 – Error) = (TP + TN)/(PP + NP) = Pr(C), the probability of a correct classification.
Sensitivity = TP/(TP + FN) = TP/PP = the ability of the test to detect disease in a population of diseased individuals.
Specificity = TN/(TN + FP) = TN / NP = the ability of the test to correctly rule out the disease in a disease-free population.
Let’s calculate these metrics for some reasonable real-world numbers. If we have 100,000 patients, of which 200 (20%) actually have cancer, we might see the following test results (Table 1):
Table 1. Illustration of diagnostic test performance for “reasonable” values for Pap smear screening
In other words, our test will correctly identify 80% of people with the disease, but 30% of healthy people will incorrectly test positive. By only considering the sensitivity (or accuracy) of the test, potentially important information is lost.
By considering our wrong results as well as our correct ones we get much greater insight into the performance of the classifier.
One way to overcome the problem of having to choose a cutoff is to start with a threshold of 0.0, so that every case is considered as positive. We correctly classify all of the positive cases, and incorrectly classify all of the negative cases. We then move the threshold over every value between 0.0 and 1.0, progressively decreasing the number of false positives and increasing the number of true positives.
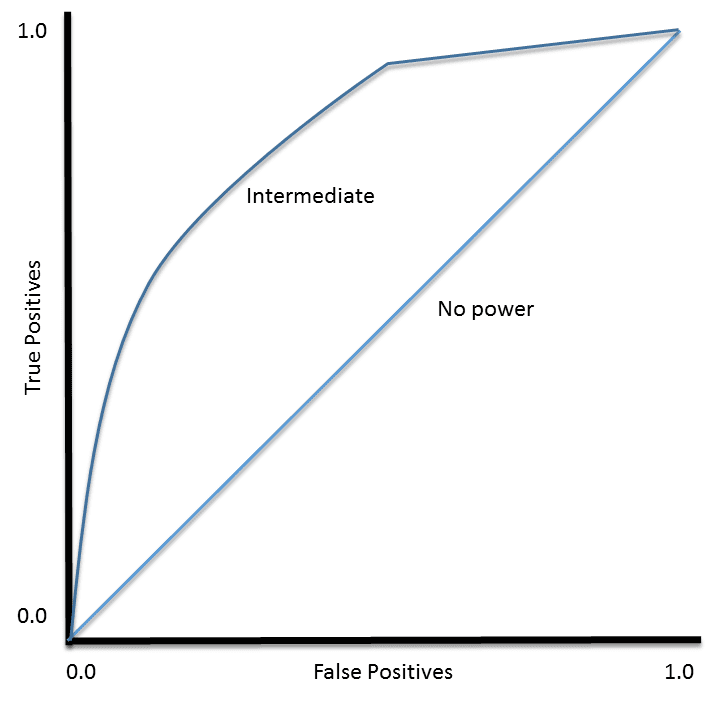
TP (sensitivity) can then be plotted against FP (1 – specificity) for each threshold used. The resulting graph is called a Receiver Operating Characteristic (ROC) curve (Figure 2). ROC curves were developed for use in signal detection in radar returns in the 1950’s, and have since been applied to a wide range of problems.
Figure 2. Examples of ROC curves
For a perfect classifier the ROC curve will go straight up the Y axis and then along the X axis. A classifier with no power will sit on the diagonal, whilst most classifiers fall somewhere in between.
ROC analysis provides tools to select possibly optimal models and to discard suboptimal ones independently from (and prior to specifying) the cost context or the class distribution
It is immediately apparent that a ROC curve can be used to select a threshold for a classifier which maximises the true positives, while minimising the false positives.
However, different types of problems have different optimal classifier thresholds. For a cancer screening test, for example, we may be prepared to put up with a relatively high false positive rate in order to get a high true positive, it is most important to identify possible cancer sufferers.
For a follow-up test after treatment, however, a different threshold might be more desirable, since we want to minimise false negatives, we don’t want to tell a patient they’re clear if this is not actually the case.
Performance Assessment
ROC curves also give us the ability to assess the performance of the classifier over its entire operating range. The most widely-used measure is the area under the curve (AUC). As you can see from Figure 2, the AUC for a classifier with no power, essentially random guessing, is 0.5, because the curve follows the diagonal. The AUC for that mythical being, the perfect classifier, is 1.0. Most classifiers have AUCs that fall somewhere between these two values.
An AUC of less than 0.5 might indicate that something interesting is happening. A very low AUC might indicate that the problem has been set up wrongly, the classifier is finding a relationship in the data which is, essentially, the opposite of that expected. In such a case, inspection of the entire ROC curve might give some clues as to what is going on: have the positives and negatives been mislabelled?
Classifier Comparison
The AUC can be used to compare the performance of two or more classifiers. A single threshold can be selected and the classifiers’ performance at that point compared, or the overall performance can be compared by considering the AUC.
Most published reports compare AUCs in absolute terms: “Classifier 1 has an AUC of 0.85, and classifier 2 has an AUC of 0.79, so classifier 1 is clearly better“. It is, however, possible to calculate whether differences in AUC are statistically significant. For full details, see the Hanley & McNeil (1982) paper listed below.
In this post I have used a biomedical example, and ROC curves are widely used in the biomedical sciences. The technique is, however, applicable to any classifier producing a score for each case, rather than a binary decision.
Neural networks and many statistical algorithms are examples of appropriate classifiers, while approaches such as decision trees are less suited. Algorithms which have only two possible outcomes (such as the cancer / no cancer example used here) are most suited to this approach.
Any sort of data which can be fed into appropriate classifiers can be subjected to ROC curve analysis.
Great post, very informative! I can see that when there is one measurement observed from the populations which is being used to separate two classes, the idea of incrementing the decision threshold from low to high and obtaining sensitivity and specificity results at each increment is intuitive. However, what can we do when there are 2 or more measurements being used to predict the response?
To add an additional concern, I understand that various classifier equations generate decision thresholds in various ways. How will the methods of manipulating a multi-dimensional decision threshold vary from classifier to classifier?
Great post, very informative! Could you please tell me what tool you used to plot the two figure in this passage?i like the style of the line,i want to try it.
Thank you!
I recently write a blog about how the ROC curve relates with Type I error and Power of statistical test. Hope it gives more background to this excellent ROC article.
hi,
i was thinking about ROC curve for a binary classifier (neural net) but i got a bit confused. Since its a discrete classifier,it has only 0 and 1 as a response so i cant change a threshold. I also know that you can use any covariate as a threshold value but in neural nets there are no separate features to be used as a covariate. So as far as i understand, i can only have sensitivity and specificity values rather than a curve. Am i right in understanding this?
As we increase the threshold from 0 to 1, after a certain value both the False Positives and True Positives decrease, they don’t have an inverse relationship as suggested here “We then move the threshold over every value between 0.0 and 1.0, progressively decreasing the number of false positives and increasing the number of true positives.” Or am I reading it incorrectly. Eg: If the threshold is at 1 then True Positive is zero .
Hi, thank you for the post, always easier to understand with application examples. A couple of notes: 200 is not 20%, but 0.2% from 100000. All positive means threshold 1, not 0. And at that threshold (all positive) TP is 1 but FP is also 1. By decreasing the threshold BOTH TP and FP decrease. I believe a more intuitive explanation would be to start with threshold of 0 (all negative) when there are no positive cases at all and both TP and FP are 0. By incrrasing the threshold we get higher TP but also higher FP (gain-loss balance).
Hey,
Thank for you post as always.
I have however a question, how would one go about selecting automatically a threshold value that both maximises TP rate and minimises FP rate.
Thanks Jason. This is indeed very useful. One quick question- Does this mean that ROC curves can only be used for probabilistic classifiers like Logistic Regression but not for discrete ones like decision trees?
Hi Jason,
In describing how the ROC curve is built, you write:
“We then move the threshold over every value between 0.0 and 1.0, progressively decreasing the number of false positives and increasing the number of true positives.”
While I understand that increasing the threshold will decrease the number of false positives (as less points will be classified as positives overall) how does that increase the number of true positives? Didn’t you mean true negatives here?
Increasing the threshold will make the classifier more restrictive about what it classifies as positive and so I don’t see how that would increase the number of true positives.







Very thoughful summary of ROC curves and AUC!
I created a 14-minute video explaining ROC curves using a simple visualization, and I wanted to share it since many of my students have found it to be helpful: http://www.dataschool.io/roc-curves-and-auc-explained/
Great post, very informative! I can see that when there is one measurement observed from the populations which is being used to separate two classes, the idea of incrementing the decision threshold from low to high and obtaining sensitivity and specificity results at each increment is intuitive. However, what can we do when there are 2 or more measurements being used to predict the response?
To add an additional concern, I understand that various classifier equations generate decision thresholds in various ways. How will the methods of manipulating a multi-dimensional decision threshold vary from classifier to classifier?
Thank you!
Great post, very informative! Could you please tell me what tool you used to plot the two figure in this passage?i like the style of the line,i want to try it.
Thank you!
Thank you so much for the post. It was really informative. If some more references are provided that will be useful.
Thanks for the feedback Divya Nair.
I recently write a blog about how the ROC curve relates with Type I error and Power of statistical test. Hope it gives more background to this excellent ROC article.
https://phdstatsphys.wordpress.com/2017/09/04/roc-curve-with-type-i-and-ii-error-the-short-story/
Thanks for sharing.
hi,
i was thinking about ROC curve for a binary classifier (neural net) but i got a bit confused. Since its a discrete classifier,it has only 0 and 1 as a response so i cant change a threshold. I also know that you can use any covariate as a threshold value but in neural nets there are no separate features to be used as a covariate. So as far as i understand, i can only have sensitivity and specificity values rather than a curve. Am i right in understanding this?
Hi,
As we increase the threshold from 0 to 1, after a certain value both the False Positives and True Positives decrease, they don’t have an inverse relationship as suggested here “We then move the threshold over every value between 0.0 and 1.0, progressively decreasing the number of false positives and increasing the number of true positives.” Or am I reading it incorrectly. Eg: If the threshold is at 1 then True Positive is zero .
Thanks.
It is a trade-off, but not an equal tradeoff.
Hi, thank you for the post, always easier to understand with application examples. A couple of notes: 200 is not 20%, but 0.2% from 100000. All positive means threshold 1, not 0. And at that threshold (all positive) TP is 1 but FP is also 1. By decreasing the threshold BOTH TP and FP decrease. I believe a more intuitive explanation would be to start with threshold of 0 (all negative) when there are no positive cases at all and both TP and FP are 0. By incrrasing the threshold we get higher TP but also higher FP (gain-loss balance).
Hey,
Thank for you post as always.
I have however a question, how would one go about selecting automatically a threshold value that both maximises TP rate and minimises FP rate.
Thank you in advance !
Perhaps test each threshold linearly until a suitable trade-off is found?
Thanks Jason. This is indeed very useful. One quick question- Does this mean that ROC curves can only be used for probabilistic classifiers like Logistic Regression but not for discrete ones like decision trees?
Yes. Although methods can be used to get probabilities from trees/svm/etc. that can be calibrated and then used with a ROC.
1) 200 is not 20% in 100,000
2) While calculating sensitivty you have mentioned
Sensitivity = TP/(TP + FN) = 160 / (160 + 40) = 80.0%
But FN should be 29,940 right??
Hi Jason,
In describing how the ROC curve is built, you write:
“We then move the threshold over every value between 0.0 and 1.0, progressively decreasing the number of false positives and increasing the number of true positives.”
While I understand that increasing the threshold will decrease the number of false positives (as less points will be classified as positives overall) how does that increase the number of true positives? Didn’t you mean true negatives here?
Increasing the threshold will make the classifier more restrictive about what it classifies as positive and so I don’t see how that would increase the number of true positives.
Thanks