Linear regression is a very simple method but has proven to be very useful for a large number of situations.
In this post, you will discover exactly how linear regression works step-by-step. After reading this post you will know:
- How to calculate a simple linear regression step-by-step.
- How to perform all of the calculations using a spreadsheet.
- How to make predictions on new data using your the model.
- A shortcut that greatly simplifies the calculation.
This tutorial was written for developers and does not assume any prior background in mathematics or statistics.
This tutorial was written with the intention that you will follow along in your own spreadsheet, which will help to make the concepts stick.
Kick-start your project with my new book Master Machine Learning Algorithms, including step-by-step tutorials and the Excel Spreadsheet files for all examples.
Let’s get started.
Update #1: Fixed a bug in the calculation of RMSE.

Simple Linear Regression Tutorial for Machine Learning
Photo by Catface27, some rights reserved.
Tutorial Data Set
The data set we are using is completely made up.
Below is the raw data.
|
1 2 3 4 5 6 |
x y 1 1 2 3 4 3 3 2 5 5 |
The attribute x is the input variable and y is the output variable that we are trying to predict. If we got more data, we would only have x values and we would be interested in predicting y values.
Below is a simple scatter plot of x versus y.
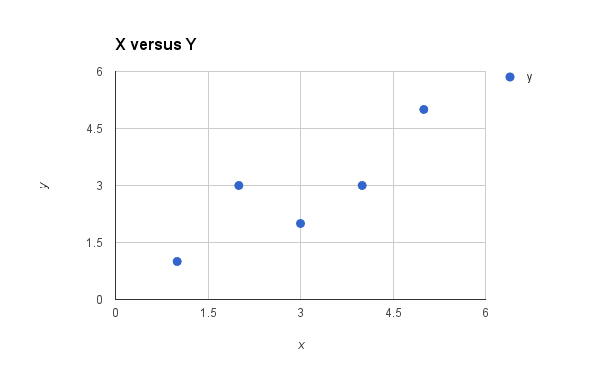
Plot of the Dataset for Simple Linear Regression
We can see the relationship between x and y looks kind of linear. As in, we could probably draw a line somewhere diagonally from the bottom left of the plot to the top right to generally describe the relationship between the data.
This is a good indication that using linear regression might be appropriate for this little dataset.
Get your FREE Algorithms Mind Map

Sample of the handy machine learning algorithms mind map.
I've created a handy mind map of 60+ algorithms organized by type.
Download it, print it and use it.
Also get exclusive access to the machine learning algorithms email mini-course.
Simple Linear Regression
When we have a single input attribute (x) and we want to use linear regression, this is called simple linear regression.
If we had multiple input attributes (e.g. x1, x2, x3, etc.) This would be called multiple linear regression. The procedure for linear regression is different and simpler than that for multiple linear regression, so it is a good place to start.
In this section we are going to create a simple linear regression model from our training data, then make predictions for our training data to get an idea of how well the model learned the relationship in the data.
With simple linear regression we want to model our data as follows:
y = B0 + B1 * x
This is a line where y is the output variable we want to predict, x is the input variable we know and B0 and B1 are coefficients that we need to estimate that move the line around.
Technically, B0 is called the intercept because it determines where the line intercepts the y-axis. In machine learning we can call this the bias, because it is added to offset all predictions that we make. The B1 term is called the slope because it defines the slope of the line or how x translates into a y value before we add our bias.
The goal is to find the best estimates for the coefficients to minimize the errors in predicting y from x.
Simple regression is great, because rather than having to search for values by trial and error or calculate them analytically using more advanced linear algebra, we can estimate them directly from our data.
We can start off by estimating the value for B1 as:
B1 = sum((xi-mean(x)) * (yi-mean(y))) / sum((xi – mean(x))^2)
Where mean() is the average value for the variable in our dataset. The xi and yi refer to the fact that we need to repeat these calculations across all values in our dataset and i refers to the i’th value of x or y.
We can calculate B0 using B1 and some statistics from our dataset, as follows:
B0 = mean(y) – B1 * mean(x)
Not that bad right? We can calculate these right in our spreadsheet.
Estimating The Slope (B1)
Let’s start with the top part of the equation, the numerator.
First we need to calculate the mean value of x and y. The mean is calculated as:
1/n * sum(x)
Where n is the number of values (5 in this case). You can use the AVERAGE() function in your spreadsheet. Let’s calculate the mean value of our x and y variables:
mean(x) = 3
mean(y) = 2.8
Now we need to calculate the error of each variable from the mean. Let’s do this with x first:
|
1 2 3 4 5 6 |
x mean(x) x - mean(x) 1 3 -2 2 3 -1 4 3 1 3 3 0 5 3 2 |
Now let’s do that for the y variable
|
1 2 3 4 5 6 |
y mean(y) y - mean(y) 1 2.8 -1.8 3 2.8 0.2 3 2.8 0.2 2 2.8 -0.8 5 2.8 2.2 |
We now have the parts for calculating the numerator. All we need to do is multiple the error for each x with the error for each y and calculate the sum of these multiplications.
|
1 2 3 4 5 6 |
x - mean(x) y - mean(y) Multiplication -2 -1.8 3.6 -1 0.2 -0.2 1 0.2 0.2 0 -0.8 0 2 2.2 4.4 |
Summing the final column we have calculated our numerator as 8.
Now we need to calculate the bottom part of the equation for calculating B1, or the denominator. This is calculated as the sum of the squared differences of each x value from the mean.
We have already calculated the difference of each x value from the mean, all we need to do is square each value and calculate the sum.
|
1 2 3 4 5 6 |
x - mean(x) squared -2 4 -1 1 1 1 0 0 2 4 |
Calculating the sum of these squared values gives us up denominator of 10
Now we can calculate the value of our slope.
B1 = 8 / 10
B1 = 0.8
Estimating The Intercept (B0)
This is much easier as we already know the values of all of the terms involved.
B0 = mean(y) – B1 * mean(x)
or
B0 = 2.8 – 0.8 * 3
or
B0 = 0.4
Easy.
Making Predictions
We now have the coefficients for our simple linear regression equation.
y = B0 + B1 * x
or
y = 0.4 + 0.8 * x
Let’s try out the model by making predictions for our training data.
|
1 2 3 4 5 6 |
x y predicted y 1 1 1.2 2 3 2 4 3 3.6 3 2 2.8 5 5 4.4 |
We can plot these predictions as a line with our data. This gives us a visual idea of how well the line models our data.
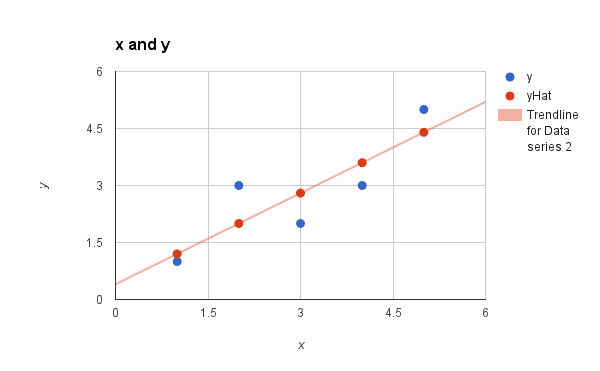
Simple Linear Regression Model
Estimating Error
We can calculate a error for our predictions called the Root Mean Squared Error or RMSE.
RMSE = sqrt( sum( (pi – yi)^2 )/n )
Where sqrt() is the square root function, p is the predicted value and y is the actual value, i is the index for a specific instance, n is the number of predictions, because we must calculate the error across all predicted values.
First we must calculate the difference between each model prediction and the actual y values.
|
1 2 3 4 5 6 |
pred-y y error 1.2 1 0.2 2 3 -1 3.6 3 0.6 2.8 2 0.8 4.4 5 -0.6 |
We can easily calculate the square of each of these error values (error*error or error^2).
|
1 2 3 4 5 6 |
error squared error 0.2 0.04 -1 1 0.6 0.36 0.8 0.64 -0.6 0.36 |
The sum of these errors is 2.4 units, dividing by n and taking the square root gives us:
RMSE = 0.692
Or, each prediction is on average wrong by about 0.692 units.
Shortcut
Before we wrap up I want to show you a quick shortcut for calculating the coefficients.
Simple linear regression is the simplest form of regression and the most studied. There is a shortcut that you can use to quickly estimate the values for B0 and B1.
Really it is a shortcut for calculating B1. The calculation of B1 can be re-written as:
B1 = corr(x, y) * stdev(y) / stdev(x)
Where corr(x) is the correlation between x and y an stdev() is the calculation of the standard deviation for a variable.
Correlation (also known as Pearson’s correlation coefficient) is a measure of how related two variables are in the range of -1 to 1. A value of 1 indicates that the two variables are perfectly positively correlated, they both move in the same direction and a value of -1 indicates that they are perfectly negatively correlated, when one moves the other moves in the other direction.
Standard deviation is a measure of how much on average the data is spread out from the mean.
You can use the function PEARSON() in your spreadsheet to calculate the correlation of x and y as 0.852 (highly correlated) and the function STDEV() to calculate the standard deviation of x as 1.5811 and y as 1.4832.
Plugging these values in we have:
B1 = 0.852 * 1.4832 / 1.5811
B1 = 0.799
Close enough to the above value of 0.8. Note that we get 0.8 if we use the fuller precision in our spreadsheet for the correlation and standard deviation equations.
Summary
In this post you discovered how to implement linear regression step-by-step in a spreadsheet. You learned:
- How to estimate the coefficients for a simple linear regression model from your training data.
- How to make predictions using your learned model.
Do you have any questions about this post or linear regression? Leave a comment and ask your question, I’ll do my best to answer.
Discover How Machine Learning Algorithms Work!

See How Algorithms Work in Minutes
...with just arithmetic and simple examples
Discover how in my new Ebook:
Master Machine Learning Algorithms
It covers explanations and examples of 10 top algorithms, like:
Linear Regression, k-Nearest Neighbors, Support Vector Machines and much more...
Finally, Pull Back the Curtain on
Machine Learning Algorithms
Skip the Academics. Just Results.






I took half of one day to learn, It is very good, Thanks to Jasom.
I’m glad you found it useful Chen.
can you help me solve a question in this subject that i am stuck?
Thank you . Very usefull article
I don’t have the math skills obviously. But this stuff is so bizarre. I have a machine learning course on Udemy.com and I have no idea what is going on or the why.
I don’t know if the course I have is bad, meaning the instructor isn’t good or just over my head. But I have absolutely no clue what this stuff means or does. And the code in python is just weird.
Anybody got a suggestion for a Udemy course on machine learning for dumb people? This stuff is really really hard. Well one hour into my course definitely made me feel stupid.
It is strange when you get started.
Perhaps this will help:
https://machinelearningmastery.com/start-here/#getstarted
Specifically this:
https://machinelearningmastery.com/think-machine-learning/
There is a tutorial on youtube help me a lot on understanding a bit of linear regression you should definitely check it out
https://www.youtube.com/watch?v=ujTCoH21GlA&list=PLzMcBGfZo4-mP7qA9cagf68V06sko5otr
Thanks for sharing.
You r a wonderful tutor. God send
Keep up the beautiful work..
Thank you for your kind words AmiMo.
Hi Jason,
many thanks for an amazing blog! I am reading everything and there are so many new things I learned here.
Correct me if I am wrong, but I think there is a small mistake in the calculation of RMSE in this post. I believe the sum of squared errors should be averaged and then squared. The results is weird as well: RMSE = 1.549 exceeds the error for each data point.
Yes, thanks Dominika. It is on my TODO list to fix this up.
Update: I have fixed the calculation of RMSE.
First of all, it is good article with explanation..
I have a query.
At the end we got RMSE value, but what part of the equation train , so that our error reduces at optimal level or near to zero.
Please explain,if feasible.
Hi chandan, on some problems we may not be able to get zero error because of the noise in the problem.
hello jason this is really helpful.
I have query.
how to set value of theta for minimise cost function in linear regression
What do you mean by theta in this context pranaya? Learning rate? A coefficient value?
hi Jason ,
your article on simple linear regression is awesome. is there any tutorial for Ridge Regression .
Thanks Deependra. Sorry, nothing on ridge regression right now.
Could you please explain the following equation?
B1 = sum((xi-mean(x)) * (yi-mean(y))) / sum((xi – mean(x))^2)
How did you get this equation? I mean B1 is the slope, so it should look something like ((y2-y1)/(x2-x1)).
New to this
Hi Amar, you can see the explanation of the equation here:
https://en.wikipedia.org/wiki/Simple_linear_regression#Fitting_the_regression_line
this is not proper !!!!
Perhaps my tutorial is not a good fit for you.
Oh, really Jeersserg!!! what exactly is not proper???
Thankzzz a lot 🙂
You’re welcome Asbar.
You are Awesome Jason. Thanks for the article.
You’re welcome.
A big work done by Jason.
Thanks Jason,
Thanks Munir.
Hi Json,
Thank you for the good tutorial.God bless you
I’m glad you found it useful Nuwan.
Very simple and convenient to apply.
Jason you made it simple. Pl carry on the job of educating.
Thanks.
Oh yeah Raja !
hmmm , assss
What is this Raja…???
Hi Jason, M a little confused here, may be its because of the formula interpretation that is mentioned here:
B1 = corr(x, y) * stdev(y) / stdev(x)
Also,
corr(x,y) = (Covariance of x & y)/stdev(x)*stdev(y)
So does that makes: B1= (Covariance of x & y) / (stdev(x))^2)
Please correct me if I am wrong, This is bugging me. With this we don’t have to calculate stdev(y) .Kindly explain !
You can see the derivation here:
https://en.wikipedia.org/wiki/Simple_linear_regression
wonderful tutorial. I had a lot of confusion on finding Theta. I had gone through a lot of youtube and other web site tutorials.. Now i understood.
I’m glad to hear that.
Explained very well in excellent manner. I am glad I found this tutorial.. Thank you Jason
Thanks Hima.
Thank you Jason for the wonderful article,
One clarification, for the given dataset list, this is the beat fit and we don’t need to adjust B0 and B1, is my assumption right?
It is a fit, perhaps not the best as we used a stochastic process.
i am not able to understand whole. please explain in good way
Very good Article. I don’t understand why we calculated RMSE here. Could you please explain?
It is the error of the predictions used to summarize the skill of the model.
You can use other error metrics if you prefer.
As you are probability in statistics there are many assumptions that you make with respect to the underlying data. How is it the machine learning can dismiss these?
By focusing on the skill of the predictive model over all other concerns.
It transforms the problem from “what is going on in the data” to “what will make the predictions more skillful”.
In the section : Making predictions: How did you get the value of field ” Predicted Y”
By using the regression equation that we developed and entering in the input data (x).
This is great help. Thank you, Jason!
Thanks Esther, I’m glad to hear that.
Hi Jason, the algorithms mind map link is not working !
You can get it from here:
https://machinelearningmastery.leadpages.co/machine-learning-algorithms-mini-course/
Thank you very much Jason for the wonderful explanation,,as everyone knows how tough the subject machine learning is ,,u made it so simple ,keep doing ,God bless u,once again thank you
Thanks AJ, hang in there!
Thanks Jason for this wonderful explanation.
Have you done any blogs on multiple linear regression as well.
Plz attach the link if so…
Yes, use the search at the top of the page.
I am sorry but I am unable to find that blog through the search box at the top, so plz can you send me the link of that blog….
jason can you please derive it for logistic and multiple regessions
Thanks for the suggestion.
Really your blogs are very helpful in learning.
Thanks, I’m glad to hear that.
Hi Jason,
Hope u are doing great!
Really appreciate your idea of using Excel to understand the algo better. We sometimes, ignore the power of simpler things.
Thanks.
Thanks, I hope it helps.
How do you create the data OR better yet if I copied the data into a csv file, how do import it into python?
This post shows how to load a CSV file in Python:
https://machinelearningmastery.com/load-machine-learning-data-python/
First of all thank you very much for explaining in very simple manner.
Now the question 🙂
At the end of the tutorial you have explained the shortcut method to calculate coefficient B1,
Do we have the shortcut method for the other coefficient B0 as well?
Thank you
B0 can be calculated from B1 in the same way.
Please can you explain how linear regression works in detail like for getting the best fit line how we use OLS estimates and all?
Thanks for the suggestion.
It is a very simple way to explain the overall concept of linear regression. Very impressive and superb. Very easy to understand. Excellent
Thanks.
Excellent Jason for simplifying the analysis.
I have doubt in calculating the error which u mentioned “each prediction is on average wrong by about 0.692 units.”
What does this mean. Anyhow the prediction is good by looking at the scatter plot.
Is there any range available for RMSE. It means if it close to value 1, then more error available.
I am newbie and do not understand.
Error scores are usually relative to the scale and units of the output variable (e.g. cm, feet, dollars, etc). They are best interpreted in the context of a little domain expertise for the problem.
Awesome Explanation. I am much clearer about the concept.
I’m glad it helped.
Hi Jason,
Thanks a lot for all your posts. I am really enjoying myself learning ML!!!
I have one doubt in the above post. Using the above method, we will get only one value for B0 and B1 right? How do we go about minimising the errors using this method and finding new B0 and B1? Pls correct me if i have misinterpreted something here.
Regards
Sara.
Yes, the process will give you one set of coefficients, that is the model.
The learning process will minimize error.
Hey Jason,
It was a great explanation for simple linear regression.
But what will be the equation of multiple linear regression and how will I calculate the constants in it?
Thanks in advance.
You simply add more variables (X) and coefficients (beta).
Hi, Jason
I read “Fitting the regression line” part on Wiki ( https://en.wikipedia.org/wiki/Simple_linear_regression#Fitting_the_regression_line ). But I cant find alpha_hat and beta_hat for minimization problem myself. So Can you explain or give me some math references so that i can solve the problem myself ?.
Thanks.
Perhaps this book:
https://amzn.to/2LET8rD
Hi Jason,
I’m a student of Bachelor of Technology. Can you suggest me a book to get start with Data Science and Machine Learning.
Start for free right here:
https://machinelearningmastery.com/start-here/
Hi Jason, very good article with detailed explanation which I couldn’t find it in any other sites. Thanks a lot for that.
“How to use” is very clear, it would be nice if “when to use” is also mentioned.
Many forums mentioned, that 1 dependent variable and 1 independent variable is the criteria, but I feel with same criteria there can be non-linear data also. please help me out how to find “when to use what”.
Thanks again for the detailed explanation.
Thanks Krishna.
Great explanation.
I’m very happy and much more excited to learn using your this blog post as my first machine learning algorithm.
Thanks a lot…!!!
Thanks.
Very nice explanation sir.
Thanks.
could you please record video for ML tutorials? it would catch so many attentions
Thanks for the suggestion.
I think video is too passive, we are a community of “doers” not “watchers”.
Thank Jason,
Very helpful point.
can you please continue to multiple linear regression.
Thanks for the suggestion.
Thank u so much
You’re welcome.
Thank Jason.
I searched a lot about Linear regression but I didn’t find a good source. This source is very good. Thanks, bro.
Thanks, I’m glad it helped.
your article is very good , i able to understand the simple linear regression concepts very easily. thanks for great article.
Thanks, I’m happy to hear that.
Thank you very much sir for a wonderfull explanation..
You’re welcome. I’m happy that it helped.
Thank you sir, you explained very good. keep it up. can you explain Kernel PCA ?
Thanks.
Great suggestion!
Very simple and interested way in explanation. Keep going fot other prediction algorithm ????
Thanks.
Thank you so much for sharing the valuable information. Easy to understand and can get the details without using any tools.
After doing these calculations, I hope we can consider the model which we built is accurate. Please suggest.
A model can be evaluated by making predictions on data not used during training and calculating the error between the predictions and expected values.
Got it. Thanks for the clarification
You’re welcome.
Why not use the pinv () Pseudoinverse to get the B0 and B1 parameters ? anyway reference for me to check out the “short-cut” method ? this method is good in not doing the inverse-matrix operation. thank you.
Yes, see this:
https://en.wikipedia.org/wiki/Simple_linear_regression
And this:
https://machinelearningmastery.com/solve-linear-regression-using-linear-algebra/
Thank you for this explanation. It was easier to learn the concept by reading your guide for 15 mins vs a 2 hour class! Hope you’re keeping well and safe
Thanks!
Hi Jason, great article. I was wondering if you have similar article for Multiple linear regression
Perhaps this will help:
https://machinelearningmastery.com/multi-output-regression-models-with-python/
Hi Jason,
I have data which records my mood every day. I collected it over almost a year, it has 2 columns, date and mood. There are 5 types of moods which were recorded along with the date. Now using this data I want to predict my mood on a certain date in future. I want to know can you help me with this, I’m a beginner absolute newbie in DS & ML. I’m thinking of using LinearRegression we can predict the outcome.
Can you suggest me how to approach the solution? How can I pass a date as an argument to ML Algo to predict the mood? Please help me.
NOTE: If you want I can share the data, nothing personal in it. Anybody who is interested in this please contact me on maxlinkdir[at]Gmail[dot]com
Thanks.
Sounds like a time series problem:
https://machinelearningmastery.com/start-here/#timeseries
Perhaps time series classification:
https://machinelearningmastery.com/start-here/#deep_learning_time_series
Or try constructing a supervised learning problem for normal classification:
https://machinelearningmastery.com/convert-time-series-supervised-learning-problem-python/
Hi,
Thank you for your reply. I’ll try my best to solve it by using TimeSeries. First I need to read a lot about it, as I’m learning DS & ML on my own. I’ll need some time to solve this I think. Whenever I crack the problem, I’ll message you here.
Thanks once again.
You’re welcome.
Hi Jason,
It is a awesome resource, just one doubt, as RMSE is 0.69, does it mean our model is 69 % not predicting the values correctly, in other words our model is 31 % giving correct predictions.
Also, after estimating the errors , do we need to sum the square numbers or average them, as
pointed by Dominika Tkaczyk on 30th September 2016.
Would appreciate if you could clarify this.
Thanks.
No it is the prediction error of the model. Think about it as on average a prediction will be about 0.69 units wrong, whatever the units of the target variable happen to be.
Hi Jason,
It took few hours to do it. It is really worth doing it without coding.
Regards,
S Dash.
Well done!
Thanks, for the tutorial.One of the best tutorials over the internet for a basic understanding of regression.
Thanks!
Hi Jason, this helped me clear my doubts and made it fairly simple to understand the concept and application of simple linear regression. Really appreciate the effort. Thanks
You’re welcome.
Hi Jason,
It is an awesome article and one of the best resources in the machine learning tutorials. could you please explain about finding coefficients in multiple regression with kerasregressor?
See this example:
https://machinelearningmastery.com/regression-tutorial-keras-deep-learning-library-python/