Stochastic Gradient Descent is an important and widely used algorithm in machine learning.
In this post you will discover how to use Stochastic Gradient Descent to learn the coefficients for a simple linear regression model by minimizing the error on a training dataset.
After reading this post you will know:
- The form of the Simple Linear Regression model.
- The difference between gradient descent and stochastic gradient descent
- How to use stochastic gradient descent to learn a simple linear regression model.
Kick-start your project with my new book Master Machine Learning Algorithms, including step-by-step tutorials and the Excel Spreadsheet files for all examples.
Let’s get started.
- Updated Feb/2021: Fixed typo in predicted values.

Linear Regression Tutorial Using Gradient Descent for Machine Learning
Photo by Stig Nygaard, some rights reserved.
Tutorial Data Set
The data set we are using is completely made up.
Here is the raw data. The attribute x is the input variable and y is the output variable that we are trying to predict. If we got more data, we would only have x values and we would be interested in predicting y values.
|
1 2 3 4 5 6 |
x y 1 1 2 3 4 3 3 2 5 5 |
Below is a simple scatter plot of x versus y.
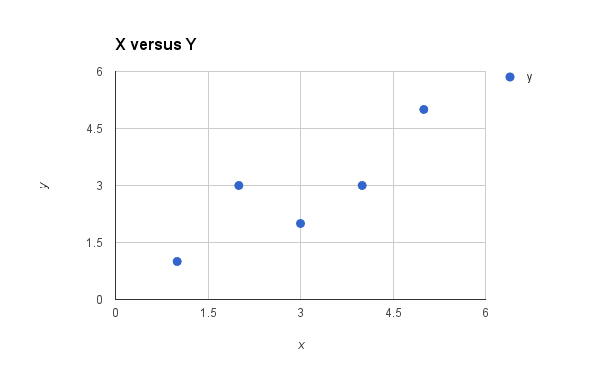
Plot of the Dataset for Simple Linear Regression
We can see the relationship between x and y looks kind-of linear. As in, we could probably draw a line somewhere diagonally from the bottom left of the plot to the top right to generally describe the relationship between the data. This is a good indication that using linear regression might be appropriate for this little dataset.
Get your FREE Algorithms Mind Map

Sample of the handy machine learning algorithms mind map.
I've created a handy mind map of 60+ algorithms organized by type.
Download it, print it and use it.
Also get exclusive access to the machine learning algorithms email mini-course.
Simple Linear Regression
When we have a single in put attribute (x) and we want to use linear regression, this is called simple linear regression.
With simple linear regression we want to model our data as follows:
y = B0 + B1 * x
This is a line where y is the output variable we want to predict, x is the input variable we know and B0 and B1 are coefficients we need to estimate.
B0 is called the intercept because it determines where the line intercepts the y axis. In machine learning we can call this the bias, because it is added to offset all predictions that we make. The B1 term is called the slope because it defines the slope of the line or how x translates into a y value before we add our bias.
The model is called Simple Linear Regression because there is only one input variable (x). If there were more input variables (e.g. x1, x2, etc.) then this would be called multiple regression.
Stochastic Gradient Descent
Gradient Descent is the process of minimizing a function by following the gradients of the cost function.
This involves knowing the form of the cost as well as the derivative so that from a given point you know the gradient and can move in that direction, e.g. downhill towards the minimum value.
In Machine learning we can use a similar technique called stochastic gradient descent to minimize the error of a model on our training data.
The way this works is that each training instance is shown to the model one at a time. The model makes a prediction for a training instance, the error is calculated and the model is updated in order to reduce the error for the next prediction.
This procedure can be used to find the set of coefficients in a model that result in the smallest error for the model on the training data. Each iteration the coefficients, called weights (w) in machine learning language are updated using the equation:
w = w – alpha * delta
Where w is the coefficient or weight being optimized, alpha is a learning rate that you must configure (e.g. 0.1) and gradient is the error for the model on the training data attributed to the weight.
Simple Linear Regression with Stochastic Gradient Descent
The coefficients used in simple linear regression can be found using stochastic gradient descent.
Linear regression is a linear system and the coefficients can be calculated analytically using linear algebra. Stochastic gradient descent is not used to calculate the coefficients for linear regression in practice (in most cases).
Linear regression does provide a useful exercise for learning stochastic gradient descent which is an important algorithm used for minimizing cost functions by machine learning algorithms.
As stated above, our linear regression model is defined as follows:
y = B0 + B1 * x
Gradient Descent Iteration #1
Let’s start with values of 0.0 for both coefficients.
B0 = 0.0
B1 = 0.0
y = 0.0 + 0.0 * x
We can calculate the error for a prediction as follows:
error = p(i) – y(i)
Where p(i) is the prediction for the i’th instance in our dataset and y(i) is the i’th output variable for the instance in the dataset.
We can now calculate he predicted value for y using our starting point coefficients for the first training instance:
x=1, y=1
p(i) = 0.0 + 0.0 * 1
p(i) = 0
Using the predicted output, we can calculate our error:
error = 0 – 1
error = -1
We can now use this error in our equation for gradient descent to update the weights. We will start with updating the intercept first, because it is easier.
We can say that B0 is accountable for all of the error. This is to say that updating the weight will use just the error as the gradient. We can calculate the update for the B0 coefficient as follows:
B0(t+1) = B0(t) – alpha * error
Where B0(t+1) is the updated version of the coefficient we will use on the next training instance, B0(t) is the current value for B0 alpha is our learning rate and error is the error we calculate for the training instance. Let’s use a small learning rate of 0.01 and plug the values into the equation to work out what the new and slightly optimized value of B0 will be:
B0(t+1) = 0.0 – 0.01 * -1.0
B0(t+1) = 0.01
Now, let’s look at updating the value for B1. We use the same equation with one small change. The error is filtered by the input that caused it. We can update B1 using the equation:
B1(t+1) = B1(t) – alpha * error * x
Where B1(t+1) is the update coefficient, B1(t) is the current version of the coefficient, alpha is the same learning rate described above, error is the same error calculated above and x is the input value.
We can plug in our numbers into the equation and calculate the updated value for B1:
B1(t+1) = 0.0 – 0.01 * -1 * 1
B1(t+1) = 0.01
We have just finished the first iteration of gradient descent and we have updated our weights to be B0=0.01 and B1=0.01. This process must be repeated for the remaining 4 instances from our dataset.
One pass through the training dataset is called an epoch.
Gradient Descent Iteration #20
Let’s jump ahead.
You can repeat this process another 19 times. This is 4 complete epochs of the training data being exposed to the model and updating the coefficients.
Here is a list of all of the values for the coefficients over the 20 iterations that you should see:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
B0 B1 0.01 0.01 0.0397 0.0694 0.066527 0.176708 0.08056049 0.21880847 0.1188144616 0.410078328 0.1235255337 0.4147894001 0.1439944904 0.4557273134 0.1543254529 0.4970511637 0.1578706635 0.5076867953 0.1809076171 0.6228715633 0.1828698253 0.6248337715 0.1985444516 0.6561830242 0.2003116861 0.6632519622 0.1984110104 0.657549935 0.2135494035 0.7332419008 0.2140814905 0.7337739877 0.2272651958 0.7601413984 0.2245868879 0.7494281668 0.219858174 0.7352420252 0.230897491 0.7904386102 |
I think that 20 iterations or 4 epochs is a nice round number and a good place to stop. You could keep going if you wanted.
Your values should match closely, but may have minor differences due to different spreadsheet programs and different precisions. You can plug each pair of coefficients back into the simple linear regression equation. This is useful because we can calculate a prediction for each training instance and in turn calculate the error.
Below is a plot of the error for each set of coefficients as the learning process unfolded. This is a useful graph as it shows us that error was decreasing with each iteration and starting to bounce around a bit towards the end.
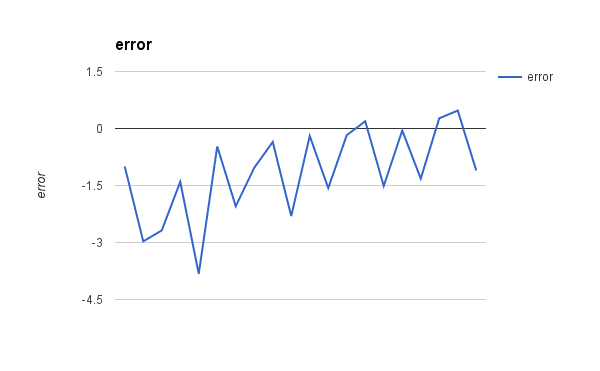
Linear Regression Gradient Descent Error versus Iteration
You can see that our final coefficients have the values B0=0.230897491 and B1=0.7904386102
Let’s plug them into our simple linear Regression model and make a prediction for each point in our training dataset.
|
1 2 3 4 5 6 |
x Prediction 1 1.02133610122753 2 1.81177471140694 4 3.39265193176576 3 2.60221332158635 5 4.18309054194517 |
We can plot our dataset again with these predictions overlaid (x vs y and x vs prediction). Drawing a line through the 5 predictions gives us an idea of how well the model fits the training data.
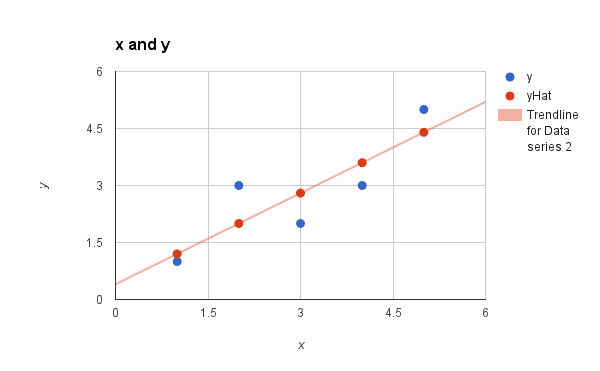
Simple Linear Regression Model
Summary
In this post you discovered the simple linear regression model and how to train it using stochastic gradient descent.
You work through the application of the update rule for gradient descent. You also learned how to make predictions with a learned linear regression model.
Do you have any questions about this post or about simple linear regression with stochastic gradient descent? Leave a comment and ask your question and I will do my best to answer it.
Discover How Machine Learning Algorithms Work!

See How Algorithms Work in Minutes
...with just arithmetic and simple examples
Discover how in my new Ebook:
Master Machine Learning Algorithms
It covers explanations and examples of 10 top algorithms, like:
Linear Regression, k-Nearest Neighbors, Support Vector Machines and much more...
Finally, Pull Back the Curtain on
Machine Learning Algorithms
Skip the Academics. Just Results.






God Bless you and your family . Your duties was every bright so keep it up.
My loard jesus bless your mind and your duties. I don’t have more words.
Thanks Tadele.
u explain it very well. thank you so much.
Thanks for your kind words effa. I’m glad you found the post useful.
I am getting somewhat confused between epoch and iteration.Is epoch or iteration depends on number of observations in training dataset?
I am having dataset as (year,cost)= [(2005,40.15), (2006,49.8), (2007,60), (2008,75), (2009,83), (2010,90), (2011,111), (2012,128). (2013,128), (2014,138), (2015,160),(2016,175) and I want to apply linear regression with stochastic gradient descent.what epoch or iteration should i set?
One epoch is one run through the entire training dataset.
An iteration may be an epoch or it may be an update for one training observation (one row in the training data), depending on the context (training iteration vs update iteration).
Hi Jason, i am investgating stochastic gradient descent for logistic regression with more than 1 response variable and am struggling.
I have tried this using the same formula but with a different calculation for the error term [error=Y-(1/1+exp(-BX))]
I have plugged this into the equations you have provided but the coefficients to not seem to be converging. Is there anything that i am missing? A
See this tutorial Alex:
https://machinelearningmastery.com/implement-logistic-regression-stochastic-gradient-descent-scratch-python/
Hi Jason
Thank you for this great tutorial .
Can we use the same equations fir updating the weights for multiple linear regression
w = w – a * error * x
for each weight where a is the learning rate and e is the error?
Thank you again.
Hi Maged…You are very welcome! You may find the following of interest: https://machinelearningmastery.com/?s=multi+linear+regression
Hi Jason,
where is the parameter m (number of training examples) in update procedure? In other tutorials it is like this:
B0(t+1) = B0(t) – alpha / m * error
B1(t+1) = B1(t) – alpha / m * error * x
I’m not sure what you mean Serb. There is no “m” in the above equations.
Yes, i see that there is no m, but it should be there. Since the cost function is defined as follows:
J(B0, B1) = 1/(2*m) * (p(i) – y(i))^2
in order to determine the parameters B0 and B1 it is necessary to minimize this function using a gradient descent and find partial derivatives of the cost function with respect to B0 and B1. At the end you get equations for B0 and B1 where there is “m”.
Jason,
You mention these weight updating equations:
B0(t+1) = B0(t) – alpha / m * error
B1(t+1) = B1(t) – alpha / m * error * x
B0 representing the slope of our to-be regression line and B1 the intercept.
In other tutorials I see people (https://www.youtube.com/watch?v=JsX0D92q1EI&t=16s) multiplying x into the slope weight update calculation and not the intercept like so:
B0(t+1) = B0(t) – alpha / m * error * x
B1(t+1) = B1(t) – alpha / m * error
Can you explain if this is incorrect or what I’ve mistaken?
Hi Daniel,
The update equations used in this post are based on those presented in the textbook “Artificial Intelligence A Modern Approach”, section 18.6.1 Univariate linear regression on Page 718. See this reference for the derivation.
I cannot speak for the equations in the youtube video.
Hi Daniel,
I believe you might be mixing up stochastic and batch gradient descend.
In batch gradient descend you calculate the total error for all the examples and divide it by the number of examples for a ‘mean error’.
On the other hand, in stochastic gradient descend, as in this article, you tackle one example at a time, so no need to calculate a mean by diving with the number of examples.
I hope this helps.
Also this post might help clear thing up:
https://machinelearningmastery.com/gentle-introduction-mini-batch-gradient-descent-configure-batch-size/
Actually the m isn’t necessary. It all depends upon the learning rate chosen the whole thing (alpha / m) may be regarded as a single constant. The point is, the learning rate is all the matters, the m is just another constant.
Can you make a similar post on logistic regression where we could get to actually see some interations of the gradient descent?
Ty.
Hi Akash,
Here is a tutorial for Logistic Regression with SGD:
https://machinelearningmastery.com/implement-logistic-regression-stochastic-gradient-descent-scratch-python/
while i am trying to calculate the second example, i am getting the values as .03 and 0.06 but not as shown in the picture… please help me
Remember to use the updated values from the last iteration as the starting values on the current iteration.
I provide complete spreadsheet examples in my book:
https://machinelearningmastery.com/master-machine-learning-algorithms/
your .03 is the value of y(x) when b0 = .01 and b1= .01
to get second iteration you need to put inputs in this formula: b0= b0 – alpha* error and b1 = b1 – alpha * error*x where x is 3
Great tip.
i mean in the second iteration, i am getting the values as 0.03 and 0.06 instead of 0.0397 0.0694. Please help me ASAP
Hi, what is the convergence point? How we understand that is the minimum point of the function? You stopped calculation with B0=0.230897491 and B1=0.7904386102. And then calculated predicted values. Can you please explain why it stopped on this B0 B1 values? It should be error=0? How we see it? Thank you!
Great question.
You can evaluate the coefficients after each update to get an idea of the model error.
You can then use the model error to determine when to stop updating the model, such as when the error levels out and stops decreasing.
thanks for the post/tutorial Jason! In relation to Jenny’s question on when does the model converge – in the plot you showed, error seems generally to be getting closer to zero per iteration (I guess we could say it is being minimized). I just wanted to confirm 2 points:
1 – the error you plotted is the model error (computed by evaluating the coefficients and comparing to the correct values) right?
2 – we often see graphs plotting error vs iteration with the error decreasing over time (http://i42.tinypic.com/dvmt6o.png); is error in your graph just plotted on a different scale? or why do most training graphs have error decreasing from a positive number to zero?
Would really appreciate some clarification, and thanks again for the tutorial!
Belal
The error is calculated on the data and how many mistakes the model made when making predictions.
Thanks a lot for such a nice post, I have doubt in calculation of y coordinate using B0 and B1 value. Acc. to me we are using y=B0+B1*x (to calculate y predicted), but considering B0=0.230897491 and B1=0.7904386102, answer of first instance(x=1,y=1) should be y(predicted)=1.0213361012 as (y=(0.230897491)+(0.7904386102)*1), but in your post it is 0.9551001992., so am I doing something wrong or intercepted it wrongly?
Guide me if I am missing somewhere?
I am stuck at same question.
The values of B0=0.230897491 and B1=0.7904386102 are actually for the 21th iteration therefore its wrong.If you look at the graph of the values you would notice the 20th iteration values of B0 and B1 are 0.219858174 0.7352420252 respectively.Substitute the values gives the correct predictions(.95…). Small human error I guess 🙂
If anyone wants to learn more about Simple linear regression, visit below link http://yasirchoudhary.blogspot.in/2017/06/linear-regression.html?m=1
Thanks for sharing.
Thanks a lot!
Finally understood this .
I’m glad to hear it!
How can I find the value of theta 0 and theta 1 with the given training set(x,y)..so that linear regression will be able to fit the data perfectly..?
Rarely do models fit the data perfectly unless the data was contrived.
Using a linalg approach will give a more robust estimate if the data can fit into memory.
A model is a tradeoff.
Is SGD the same as backpropagation? When classifying images into two categories (e.g. Cats and Dogs) is the model computing linear regression. If not, what would this be classified as?
No, gradient descent is a search algorithm, backpropagation is a way of estimating error in a neural net.
Hi Dr. Brownlee: Definitely a great tutorial! I was able to reproduce the same results. Can this algorithm be modified for multiple parameters? I am trying to understand linear regression for more than one parameter and the tutorials I have found use excel or some other tool the black boxes the actual algorithm.
Yes, linear regression can have multiple inputs.
Did I miss the derivative here?
I do not cover the derivation.
I have read the post, but I am not very clear about the difference between Gradient Descent and Stochastic Gradient Descent in this particular example. You have shown that in Stochastic Gradient Descent, we take one example at a time and update the coefficients. But what happens in case of Gradient Descent?
Perhaps this post will make it clearer:
https://machinelearningmastery.com/gentle-introduction-mini-batch-gradient-descent-configure-batch-size/
hi sir, im maruthi please let tell me step by step procedure.As a fresher i understand 50% only.
Why do you choose not to square the sum of distances in the loss function? In my class we did everything similar to what you outlined except that part in order to make the function differentiable.
For the value of b0=0.01 b1=0.01 the corresponding values of x and y are 1. When we put those in the linear equation we get y_predict=0.01+0.01*1 I am not getting 0.95 as the first value. Am i doing something wrong?
Please tell me
The prediction was made after many after the model was learned with the coefficients B0=0.230897491 and B1=0.7904386102
hi Jason ,
how can should i decide the learning rate for my model , any suggestion.
Trial and error, test a range of values on a log scale, e.g. [0.1, 0.01, 0.001, …]
when i am applying the B0 and B1 value to the linear regression, i am getting a different predicted value. can u just rectify my doubt?
Perhaps your coefficients differ from the tutorial?
Jason,
Thanks for the post. It is very pedagogical.
I wonder about implementing the Gradient Descent with Mini Batches for your example. When updating the B1, what would be the value of x to be iput in your equation B1(t+1) = B1(t) – alpha * error * x ?
Still on the mini batch example, will the error to be input in both B0 and B1 equations equal to the square root of the sum of the squared error ?
Thanks a lot.
When using a batch, the values are averaged over all examples in the batch/mini-batch.
what is cost function?
It is the function by which we estimate the error of the model, and seek to minimize over training.
Hi Jason,
While we use gradient descent in Linear Regression, then why can’t we use alpha learning rate as parameter in sklearn module. Is it not required or is there some another theory behind it?
Because sklearn does not use gradient descent, it use linear algebra, like this post:
https://machinelearningmastery.com/solve-linear-regression-using-linear-algebra/
from where that prediction values come ? can you break down this step “plug the values simple linear Regression model and make a prediction for each point in our training dataset.”
Thank you
An input is multiplied by the coefficients and summed to give a prediction.
Great Great article. Jason, you’re articles are so detailed. Thank you very much.
Thanks, I’m glad it helped.
Thank you Jason, your tutorials are very helpful
I would like to ask you the following question:
I tried to use gradient descent for logistic regression and I had used this code to calculate accuracy :
def accuracy(self, x, actual_classes, probab_threshold=0.5):
predicted_classes = (self.predict(x) >= probab_threshold).astype(int)
predicted_classes = predicted_classes.flatten()
accuracy = np.mean(predicted_classes == actual_classes)
return accuracy * 100
I would Like to get confusion metrics that it is used for getting this result because the sklearn confusion matrix return a different accuracy value
Yes, sklearn does not use gradient descent, it uses a different optimization algorithm and therefore will give a different result.
thanks for your quick reply
so in this case, if we need to calculate precision and recall how we can do.
Is there also a different way? because I need to compare the algorithm results with other machine learning classifiers results.
You must calculate error, such as MAE or MSE or RMSE.
ok, thank you very much
No problem.
What are the disadvantages of using gradient descent for linear regression?
It is slow and inefficient compared to a least squares solution.
Hello, I wonder what if we have beside b0 and b1 other coefficients like b2, b3 and so on, how can we find their values using gradient descent also?
would it be:
B2(t+1) = B2(t) – alpha * error * x2
B3(t+1) = B3(t) – alpha * error * x3
and so on ?
Thank you
I give an example here:
https://machinelearningmastery.com/implement-linear-regression-stochastic-gradient-descent-scratch-python/
Hi Jason,
If we use Linear regression algo having 9 to 10 inputs, then does it uses the linear algebra to compute the values of parameters or it uses Gradient Descent for parameters computation ?
Thanks.
Use linear algebra unless the data violates the expectations of the linear algebra method or does not fit into memory.
Hi Jason,
Do you any any comprehensive tutorial that calculates the standard error and all the statistical parameters associated with Multiple Regression. If not please suggest a good resource.
I don’t think so, sorry.
Hello Jason. How do we calculate the coefficients for the 20 iterations. That is from the 2nd iterations, I do not understand how you came up with the values for BO and B1.
Repeat the process for one iteration 20 times.
Or see this example:
https://machinelearningmastery.com/implement-linear-regression-stochastic-gradient-descent-scratch-python/
Thank you.
Hi sir,
Thank you for the clear article.
I have one doubt please.
why do we use the formula
b0(1) = b0(0) * alpha * error
also why do we use
b1(1) = b1(0) * alpha * error * x
why do we multiply with x i.e input for b1 ?
This implementation is based on the description in “artificial intelligence a modern approach” I believe.
Why do you want to use that formula?
How to calculate m
What is m?
good, it was really helpful
Thanks.
For implementing the gradient descent on simple linear regression which of the following is not required for initial setup :
1). Defining cost function
2). Update rules of slop and intercept
3). Optimal learning rate for slope and intercept
4). Initial guess for slope and intercept……..
Looks like an interview question to me!
I’d go with 3.
Is it true that a large learning rate leads to faster convergence?????
Or
A small learning rate is always best for gradient descent ????
There is no best learning rate in general, we have to see what works best for a given objective function/dataset.
Awesome sharing with full of information I was searching for. Your complete guidance gave me a wonderful end up. Great going.
Thanks.
How can I implement into multiple linear regression?
Perhaps this will help:
https://machinelearningmastery.com/solve-linear-regression-using-linear-algebra/
Hi,
I followed you to apply the method, for practice I built a code to test the method. I have noticed that for points with small X values the method works great, however when there is a large variety of points with large X values the method fails to converge, and in fact we get an explosion of the gradient.
Is there a way to deal with this problem.
Thanks
Linear regression should be the easiest to perform due to its linearity. But in fact, the scenario you see is not unexpected. One way to do is preprocess the data before feed into the model. In your case, probably you want to normalize the X to avoid extremely large range.