Many machine learning models perform better when input variables are carefully transformed or scaled prior to modeling.
It is convenient, and therefore common, to apply the same data transforms, such as standardization and normalization, equally to all input variables. This can achieve good results on many problems. Nevertheless, better results may be achieved by carefully selecting which data transform to apply to each input variable prior to modeling.
In this tutorial, you will discover how to apply selective scaling of numerical input variables.
After completing this tutorial, you will know:
How to load and calculate a baseline predictive performance for the diabetes classification dataset.
How to evaluate modeling pipelines with data transforms applied blindly to all numerical input variables.
How to evaluate modeling pipelines with selective normalization and standardization applied to subsets of input variables.
Kick-start your project with my new book Data Preparation for Machine Learning, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
How to Selectively Scale Numerical Input Variables for Machine Learning Photo by Marco Verch, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
Diabetes Numerical Dataset
Non-Selective Scaling of Numerical Inputs
Normalize All Input Variables
Standardize All Input Variables
Selective Scaling of Numerical Inputs
Normalize Only Non-Gaussian Input Variables
Standardize Only Gaussian-Like Input Variables
Selectively Normalize and Standardize Input Variables
Diabetes Numerical Dataset
As the basis of this tutorial, we will use the so-called “diabetes” dataset that has been widely studied as a machine learning dataset since the 1990s.
The dataset classifies patients’ data as either an onset of diabetes within five years or not. There are 768 examples and eight input variables. It is a binary classification problem.
Running the example first downloads the dataset and loads it as a DataFrame.
The shape of the dataset is printed, confirming the number of rows, and nine variables, eight input, and one target.
1
(768, 9)
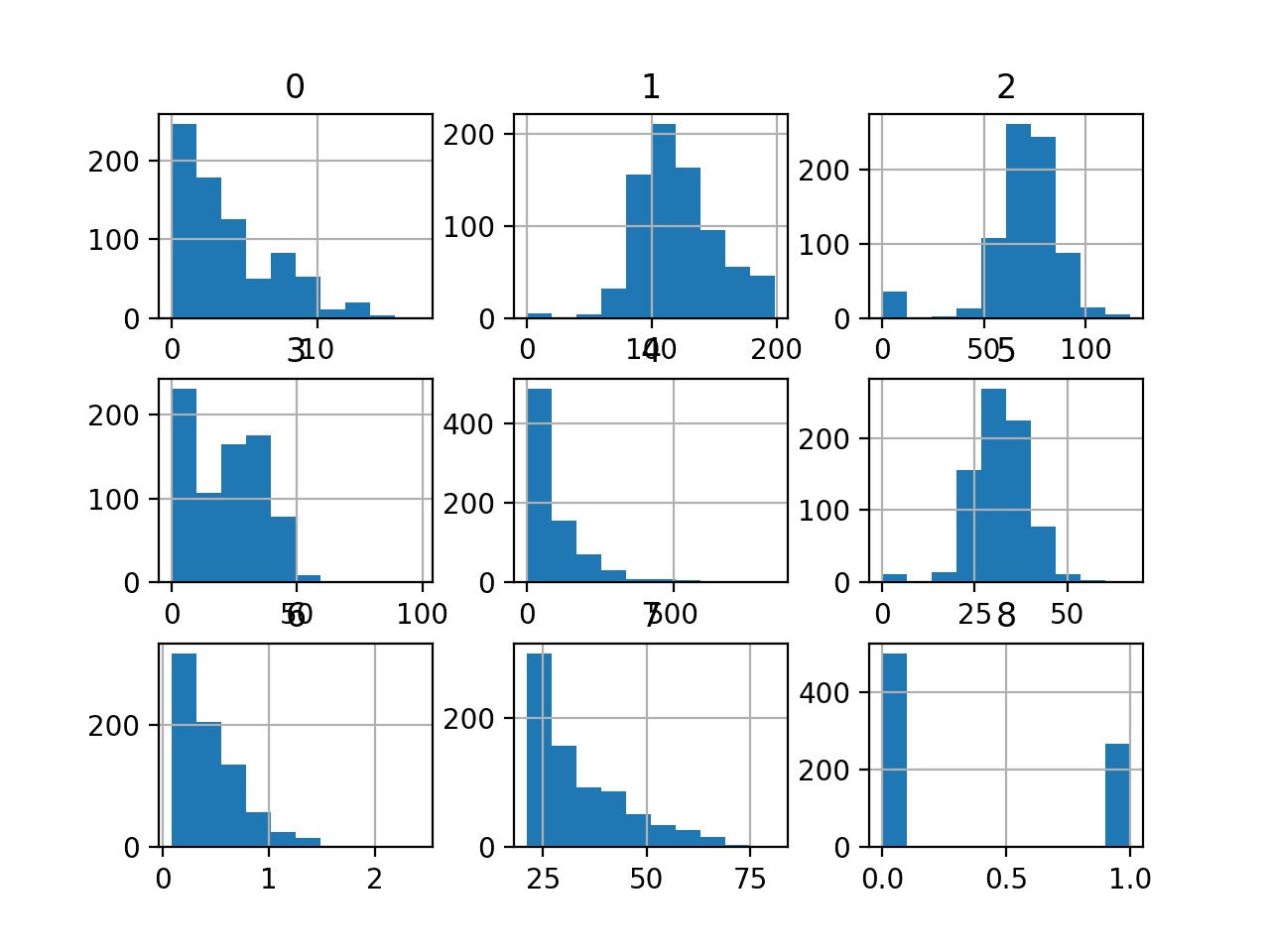
Finally, a plot is created showing a histogram for each variable in the dataset.
This is useful as we can see that some variables have a Gaussian or Gaussian-like distribution (1, 2, 5) and others have an exponential-like distribution (0, 3, 4, 6, 7). This may suggest the need for different numerical data transforms for the different types of input variables.
Histogram of Each Variable in the Diabetes Classification Dataset
Now that we are a little familiar with the dataset, let’s try fitting and evaluating a model on the raw dataset.
We will use a logistic regression model as they are a robust and effective linear model for binary classification tasks. We will evaluate the model using repeated stratified k-fold cross-validation, a best practice, and use 10 folds and three repeats.
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# evaluate a logistic regression model on the raw diabetes dataset
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.linear_model import LogisticRegression
Running the example evaluates the model and reports the mean and standard deviation accuracy for fitting a logistic regression model on the raw dataset.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the model achieved an accuracy of about 76.8 percent.
1
Accuracy: 0.768 (0.040)
Now that we have established a baseline in performance on the dataset, let’s see if we can improve the performance using data scaling.
Want to Get Started With Data Preparation?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Non-Selective Scaling of Numerical Inputs
Many algorithms prefer or require that input variables are scaled to a consistent range prior to fitting a model.
This includes the logistic regression model that assumes input variables have a Gaussian probability distribution. It may also provide a more numerically stable model if the input variables are standardized. Nevertheless, even when these expectations are violated, the logistic regression can perform well or best for a given dataset as may be the case for the diabetes dataset.
Two common techniques for scaling numerical input variables are normalization and standardization.
Normalization scales each input variable to the range 0-1 and can be implemented using the MinMaxScaler class in scikit-learn. Standardization scales each input variable to have a mean of 0.0 and a standard deviation of 1.0 and can be implemented using the StandardScaler class in scikit-learn.
To learn more about normalization, standardization, and how to use these methods in scikit-learn, see the tutorial:
A naive approach to data scaling applies a single transform to all input variables, regardless of their scale or probability distribution. And this is often effective.
Let’s try normalizing and standardizing all input variables directly and compare the performance to the baseline logistic regression model fit on the raw data.
Normalize All Input Variables
We can update the baseline code example to use a modeling pipeline where the first step is to apply a scaler and the final step is to fit the model.
This ensures that the scaling operation is fit or prepared on the training set only and then applied to the train and test sets during the cross-validation process, avoiding data leakage. Data leakage can result in an optimistically biased estimate of model performance.
This can be achieved using the Pipeline class where each step in the pipeline is defined as a tuple with a name and the instance of the transform or model to use.
1
2
3
4
5
...
# define the modeling pipeline
scaler=MinMaxScaler()
model=LogisticRegression(solver='liblinear')
pipeline=Pipeline([('s',scaler),('m',model)])
Tying this together, the complete example of evaluating a logistic regression on diabetes dataset with all input variables normalized is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# evaluate a logistic regression model on the normalized diabetes dataset
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
Running the example evaluates the modeling pipeline and reports the mean and standard deviation accuracy for fitting a logistic regression model on the normalized dataset.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that the normalization of the input variables has resulted in a drop in the mean classification accuracy from 76.8 percent with a model fit on the raw data to about 76.4 percent for the pipeline with normalization.
1
Accuracy: 0.764 (0.045)
Next, let’s try standardizing all input variables.
Standardize All Input Variables
We can update the modeling pipeline to use standardization instead of normalization for all input variables prior to fitting and evaluating the logistic regression model.
This might be an appropriate transform for those input variables with a Gaussian-like distribution, but perhaps not the other variables.
1
2
3
4
5
...
# define the modeling pipeline
scaler=StandardScaler()
model=LogisticRegression(solver='liblinear')
pipeline=Pipeline([('s',scaler),('m',model)])
Tying this together, the complete example of evaluating a logistic regression model on diabetes dataset with all input variables standardized is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# evaluate a logistic regression model on the standardized diabetes dataset
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
Running the example evaluates the modeling pipeline and reports the mean and standard deviation accuracy for fitting a logistic regression model on the standardized dataset.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that standardizing all numerical input variables has resulted in a lift in mean classification accuracy from 76.8 percent with a model evaluated on the raw dataset to about 77.2 percent for a model evaluated on the dataset with standardized input variables.
1
Accuracy: 0.772 (0.043)
So far, we have learned that normalizing all variables does not help performance, but standardizing all input variables does help performance.
Next, let’s explore if selectively applying scaling to the input variables can offer further improvement.
It allows you to specify the transform (or pipeline of transforms) to apply and the column indexes to apply them to. This can then be used as part of a modeling pipeline and evaluated using cross-validation.
You can learn more about how to use the ColumnTransformer in the tutorial:
We can explore using the ColumnTransformer to selectively apply normalization and standardization to the numerical input variables of the diabetes dataset in order to see if we can achieve further performance improvements.
Normalize Only Non-Gaussian Input Variables
First, let’s try normalizing just those input variables that do not have a Gaussian-like probability distribution and leave the rest of the input variables alone in the raw state.
We can define two groups of input variables using the column indexes, one for the variables with a Gaussian-like distribution, and one for the input variables with the exponential-like distribution.
1
2
3
4
...
# define column indexes for the variables with "normal" and "exponential" distributions
norm_ix=[1,2,5]
exp_ix=[0,3,4,6,7]
We can then selectively normalize the “exp_ix” group and let the other input variables pass through without any data preparation.
The selective transform can then be used as part of our modeling pipeline.
1
2
3
4
...
# define the modeling pipeline
model=LogisticRegression(solver='liblinear')
pipeline=Pipeline([('s',selective),('m',model)])
Tying this together, the complete example of evaluating a logistic regression model on data with selective normalization of some input variables is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# evaluate a logistic regression model on the diabetes dataset with selective normalization
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
Running the example evaluates the modeling pipeline and reports the mean and standard deviation accuracy.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see slightly better performance, increasing mean accuracy with the baseline model fit on the raw dataset with 76.8 percent to about 76.9 with selective normalization of some input variables.
The results are not as good as standardizing all input variables though.
1
Accuracy: 0.769 (0.043)
Standardize Only Gaussian-Like Input Variables
We can repeat the experiment from the previous section, although in this case, selectively standardize those input variables that have a Gaussian-like distribution and leave the remaining input variables untouched.
Tying this together, the complete example of evaluating a logistic regression model on data with selective standardizing of some input variables is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# evaluate a logistic regression model on the diabetes dataset with selective standardization
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
Running the example evaluates the modeling pipeline and reports the mean and standard deviation accuracy.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that we achieved a lift in performance over both the baseline model fit on the raw dataset with 76.8 percent and over the standardization of all input variables that achieved 77.2 percent. With selective standardization, we have achieved a mean accuracy of about 77.3 percent, a modest but measurable bump.
1
Accuracy: 0.773 (0.041)
Selectively Normalize and Standardize Input Variables
The results so far raise the question as to whether we can get a further lift by combining the use of selective normalization and standardization on the dataset at the same time.
This can be achieved by defining both transforms and their respective column indexes for the ColumnTransformer class, with no remaining variables being passed through.
Tying this together, the complete example of evaluating a logistic regression model on data with selective normalization and standardization of the input variables is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# evaluate a logistic regression model on the diabetes dataset with selective scaling
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
Running the example evaluates the modeling pipeline and reports the mean and standard deviation accuracy.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, interestingly, we can see that we have achieved the same performance as standardizing all input variables with 77.2 percent.
Further, the results suggest that the chosen model performs better when the non-Gaussian like variables are left as-is than being standardized or normalized.
I would not have guessed at this finding, which highlights the importance of careful experimentation.
1
Accuracy: 0.772 (0.040)
Can you do better?
Try other transforms or combinations of transforms and see if you can achieve better results.
Share your findings in the comments below.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
It provides self-study tutorials with full working code on: Feature Selection, RFE, Data Cleaning, Data Transforms, Scaling, Dimensionality Reduction,
and much more...
Bring Modern Data Preparation Techniques to Your Machine Learning Projects
Are they equivalent to Keras models (for classification and regression) ?
What is difference between a Keras MLP and a Sklearn MLP?
Using MLPClassifier/ MLPRegressor is it possbile to manage only tabular data or images, text, etc., as well?
Are they Machine Learning or Deep Learning?
Thanks,
Marco
Hi, Jason, thank you so much, I have learned so much!
I have a question, if my output variable is also taken as one part of the input variables, should I normalize it?
I modeled a xgboostclassifier (binary classification) on raw data. As I understand (correct me if i’m wrong), xgboostclassifier does not use a weighted sum of the input or distance measures like logistic regression, neural networks, and k-nearest neighbors do.
So the question is, would you recommend trying scaling raw input variables (such as normalization, standardization, powertransform/Box-Cox) for xgboostclassifier as a general practice?
Hi Jason,
Thank you for the tutorial. I have a question. If I use the trained model to make predictions with new data, of which the range and distribution could be slightly different from train dataset, how should I process the new data before using the model to make predictions?
Thank you
Hi Jason
Thanks for sharing your story. It is very educational and teaches many young students how to preprocess numerical variables before modeling. However, you could have used a non-parametric model to also compare, since logistic regression requires, before being used as a model, that the data satisfy its hypotheses.








Hello Jason,
I’ve seen a couple of Sklearn APIs:
neural_network.MLPClassifier([…])
neural_network.MLPRegressor([…])
Are they equivalent to Keras models (for classification and regression) ?
What is difference between a Keras MLP and a Sklearn MLP?
Using MLPClassifier/ MLPRegressor is it possbile to manage only tabular data or images, text, etc., as well?
Are they Machine Learning or Deep Learning?
Thanks,
Marco
Thanks,
Marco
They are different. Sorry, I have not used them. I use keras exclusively for neural networks.
Neural networks / deep learning are a type of machine learning:
https://machinelearningmastery.com/faq/single-faq/how-are-ml-and-deep-learning-related
Hello Jason,
so I can cosider them as deep learning?
neural_network.MLPClassifier()
neural_network.MLPRegressor()
Thanks,
Marco
Sure.
Dear Dr Jason,
In the listing above the “Want to Get Started With Data Preparation?” promotion,
I used the dataset as per url.
I wanted to crash test the listing by replacing the following lines
With this – don’t convert X to float nor to force y to string.
That is I did not need convert X to float nor used the astype(‘str’) and got the same results.
On examining X and y before the transform, the X and y did not need a transform.
Question: is it a good idea to transform the data to ensure that the data is what the program is supposed to handle?
Thank you,
Anthony of Sydney
Nice.
Sometimes I get overly cautious/defensive with my code.
Hi, Jason, thank you so much, I have learned so much!
I have a question, if my output variable is also taken as one part of the input variables, should I normalize it?
Do you mean lag outputs as input, like a time series or sequence classification?
If so, yes try scaling the variable.
Hi Jason,
I modeled a xgboostclassifier (binary classification) on raw data. As I understand (correct me if i’m wrong), xgboostclassifier does not use a weighted sum of the input or distance measures like logistic regression, neural networks, and k-nearest neighbors do.
So the question is, would you recommend trying scaling raw input variables (such as normalization, standardization, powertransform/Box-Cox) for xgboostclassifier as a general practice?
No.
Hi Jason,
Thank you for the tutorial. I have a question. If I use the trained model to make predictions with new data, of which the range and distribution could be slightly different from train dataset, how should I process the new data before using the model to make predictions?
Thank you
You are very welcome Jingyi! The following resources will hopefully add clarity:
https://machinelearningmastery.com/update-neural-network-models-with-more-data/
https://machinelearningmastery.com/what-is-generalization-in-machine-learning/
Hi Jason
Thanks for sharing your story. It is very educational and teaches many young students how to preprocess numerical variables before modeling. However, you could have used a non-parametric model to also compare, since logistic regression requires, before being used as a model, that the data satisfy its hypotheses.
Thanks anyways for your contribution!
Thank you Ernesto for your valuable feedback and support!