Machine learning algorithms make assumptions about the dataset you are modeling.
Often, raw data is comprised of attributes with varying scales. For example, one attribute may be in kilograms and another may be a count. Although not required, you can often get a boost in performance by carefully choosing methods to rescale your data.
In this post you will discover how you can rescale your data so that all of the data has the same scale.
After reading this post you will know:
How to normalize your numeric attributes between the range of 0 and 1.
How to standardize your numeric attributes to have a 0 mean and unit variance.
When to choose normalization or standardization.
Kick-start your project with my new book Machine Learning Mastery With Weka, including step-by-step tutorials and clear screenshots for all examples.
Let’s get started.
Update March/2018: Added alternate link to download the dataset as the original appears to have been taken down.
Predict the Onset of Diabetes
The dataset used for this example is the Pima Indians onset of diabetes dataset.
It is a classification problem where each instance represents medical details for one patient and the task is to predict whether the patient will have an onset of diabetes within the next five years.
This is a good dataset to practice scaling as the 8 input variables all have varying scales, such as the count of the number of times the patient was pregnant (preg) and the calculation of the patients body mass index (mass).
Download the dataset and place it in your current working directory.
You can also access this dataset in your Weka installation, under the data/ directory in the file called diabetes.arff.
Weka Load Diabetes Dataset
About Data Filters in Weka
Weka provides filters for transforming your dataset. The best way to see what filters are supported and to play with them on your dataset is to use the Weka Explorer.
The “Filter” pane allows you to choose a filter.
Weka Filter Pane for Choosing Data Filters
Filters are divided into two types:
Supervised Filters: That can be applied but require user control in some way. Such as rebalancing instances for a class.
Unsupervised Filters: That can be applied in an undirected manner. For example, rescale all values to the range 0-to-1.
Personally, I think the distinction between these two types of filters is a little arbitrary and confusing. Nevertheless, that is how they are laid out.
Within these two groups, filters are further divided into filters for Attributes and Instances:
Attribute Filters: Apply an operation on attributes or one attribute at a time.
Instance Filters: Apply an operation on instance or one instance at a time.
This distinction makes a lot more sense.
After you have selected a filter, its name will appear in the box next to the “Choose” button.
You can configure a filter by clicking its name which will open the configuration window. You can change the parameters of the filter and even save or load the configuration of the filter itself. This is great for reproducibility.
Weka Data Filter Configuration
You can learn more about each configuration option by hovering over it and reading the tooltip.
You can also read all of the details about the filter including the configuration, papers and books for further reading and more information about the filter works by clicking the “More” button.
Weka Data Filter More Information
You can close the help and apply the configuration by clicking the “OK” button.
You can apply a filter to your loaded dataset by clicking the “Apply” button next to the filter name.
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
Normalize Your Numeric Attributes
Data normalization is the process of rescaling one or more attributes to the range of 0 to 1. This means that the largest value for each attribute is 1 and the smallest value is 0.
Normalization is a good technique to use when you do not know the distribution of your data or when you know the distribution is not Gaussian (a bell curve).
You can normalize all of the attributes in your dataset with Weka by choosing the Normalize filter and applying it to your dataset.
You can use the following recipe to normalize your dataset:
1. Open the Weka Explorer.
2. Load your dataset.
Weka Explorer Loaded Diabetes Dataset
3. Click the “Choose” button to select a Filter and select unsupervised.attribute.Normalize.
Weka Select Normalize Data Filter
4. Click the “Apply” button to normalize your dataset.
5. Click the “Save” button and type a filename to save the normalized copy of your dataset.
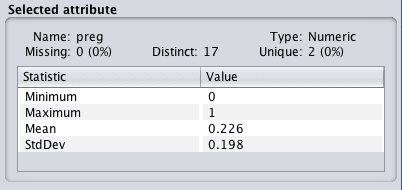
Reviewing the details of each attribute in the “Selected attribute” window will give you confidence that the filter was successful and that each attribute was rescaled to the range of 0 to 1.
Weka Normalized Data Distribution
You can use other scales such as -1 to 1, which is useful when using support vector machines and adaboost.
Normalization is useful when your data has varying scales and the algorithm you are using does not make assumptions about the distribution of your data, such as k-nearest neighbors and artificial neural networks.
Standardize Your Numeric Attributes
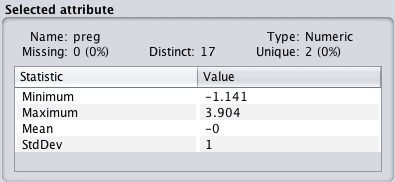
Data standardization is the process of rescaling one or more attributes so that they have a mean value of 0 and a standard deviation of 1.
Standardization assumes that your data has a Gaussian (bell curve) distribution. This does not strictly have to be true, but the technique is more effective if your attribute distribution is Gaussian.
You can standardize all of the attributes in your dataset with Weka by choosing the Standardize filter and applying it your dataset.
You can use the following recipe to standardize your dataset:
1. Open the Weka Explorer
2. Load your dataset.
3. Click the “Choose” button to select a Filter and select unsupervised.attribute.Standardize.
Weka Select Standardize Data Filter
4. Click the “Apply” button to normalize your dataset.
5. Click the “Save” button and type a filename to save the standardized copy of your dataset.
Reviewing the details of each attribute in the “Selected attribute” window will give you confidence that the filter was successful and that each attribute has a mean of 0 and a standard deviation of 1.
Weka Standardized Data Distribution
Standardization is useful when your data has varying scales and the algorithm you are using does make assumptions about your data having a Gaussian distribution, such as linear regression, logistic regression and linear discriminant analysis.
Summary
In this post you discovered how to rescale your dataset in Weka.
Specifically, you learned:
How to normalize your dataset to the range 0 to 1.
How to standardize your data to have a mean of 0 and a standard deviation of 1.
When to use normalization and standardization.
Do you have any questions about scaling your data or about this post? Ask your questions in the comments and I will do my best to answer.
Hello. I find the post quite interesting and clear but let me give you an example:
I have a dataset with different features, 6 Numeric and 3 Nominal.
The numeric features are:
salary, commission and hvalue (in euros)
age and hyears (in years) and
zip code (a 4 digit number)
Can I just standardize those features because they do have a different scales?
I mean my classification task (with class feature = group), with standardized dataset obtains far better results (with test’s set accuracy) than with a non-standardized dataset.
Generally, it is a good idea to standardize data that has a Gaussian (bell curve) distribution and normalize otherwise.
Not all algorithms require this type of data prep, some require it.
If in doubt, create 3 copies of your data (raw, standardized, normalized) and evaluate many algorithms on all 3. you can dive into more nuanced data preparation later, but this brute force technique will get a good result quickly.
I understand that standarization should not be done to categorical variables as it has lowest value of 0 and highest value of 1 while standarization should be done to continuous variable. I am confused that count data should be standarized or not following the same method subtracting the data by mean and dividing by standard deviation? Also I heard that standarization should be done for both dependent and independent variable for centering and scaling all the data to be same.
StandardScaler() in Python – All the examples I see online are applying standardization to entire x features. What if my features are a mix of nominal and real valued features. For e.g.: if one feature is sex coded as 0 and 1 and the other feature is age from 0 to 100. If I apply standard scaler to entire training dataset it will scale both variables. Should both be scaled. If not how do I selectively apply it to real valued features and not the nominal features.
It sounds like the above question is asking about filtering a subset of columns in Python, not a subset of rows in Weka. @Jason, although your article is about Weka filtering, can you provide a more thorough answer to Lily’s question about filtering different column types in Python? Thanks.
Thanks for the great explanation.
So if my understanding is correct, you are normalizing / standardizing each variable within its values (based on the data set that you have) ? not across the instance or whole dataset numeric values?
and what to do if you want only few numeric variables normalized but might want some other main ones in there original range of values?
Hi. If i normalise my data for training and testing and after that i get my predicting model. Do i have to always normalise the new data before feeding to the model for prediction?
jason, great walk through, thanks – question…i’m working with a massive dataset 5k+ obs., 500+ variables. there are numerics, integers, and nominals, and there’s a mix of continuous, discrete and ordinals. the predictor variable is continuous. i’ll need to perform a PCA, but before I do, i’m struggling to understand if i need to standardize or normalize every variable’s observations…obv. some need it, but i’m not sure if they all do.
The PCA may only make sense for the numerical data. You should standardize and normalized beforehand or as part of the PCA.
Also, confirm that you need to use a PCA, perhaps try some feature selection methods first in order to discover a baseline performance. Then adopt PCA if it lifts skill.
Does Variance of a feature have any role to play in selecting normalize/standardize…? I yes , can you please throw some light on what other considerations we have to take into account .
would you please let me know how the new data (let’s say one observation) should be normalized ? (e.g. in standardization case, should I use the mean and standard deviation of the training dataset?)
Dear sir,
how to perform standardization for training and testing dataset. I have train and test split and what perform standardization. I don’t think it is okay to perform standardization separately. Thanks
I’ve built a neural network using Keras.
1. I’ve found through experiments that I constantly get better forecasting results if I don’t apply a scaler on a specific column (temperature). Does it make any sense? Is it acceptable not to apply a scaler on all the columns?
2. Although you recommend for a neural network to use normalization, do I understand it right, that for example in case of temperature it is better to use standardization, because the temperature tomorrow can be bigger than the maximum until today and vice versa.
Hi Jason,I’m doing a project that comparison the performance of transformation and I normalize and standardize data but when I bring it to classify they both give the same result.(which is I don’t think that it possible to give the same result because the data is completely different) Do you think i did something wrong in the tranformation process ? Or do you have tutorials for transformation data and then classified it.
You mean it’s normal that the results are the same right?
Because first i think that the process of normalize and standardize are different so the result should be different too.
by the way thank you so much.
Hi Jason,
I would like your insight about my problem.
I have a data set of about 100 features, I can normalize or standerize and choose the correct algorithm. However due to my constraints I can only choose 6 features relevant from my data.
Is there a way to determine which features will give me best results?
Shay.
Correct me if I am wrong but wont Weka scale the whole data set before train test split. Should we not scale on the train data and apply the scaling from this to the test data
Hello Jason!
My question is that if we have a column which contains journal full names then how we can standardize the journal values according to ISO abbreviation method ?
Is there a way to change the minimum and maximum value that is being considered?
Specifically, if I am splitting the data and then want to normalize the attribute values in the test data, I need the minimum and maximum values of the train data to be considered.
Hello, I find your article really interesting. Thanks for sharing. I actually have a patient dataset(700patients). Each patient has 10~20 rows of lab test results at the time of visit to the hospital. My task is to predict what kind of drug the patient need in the next visit. I am trying to use an LSTM model. My question is
1. Do I need to scale my data?
2. If so, should I scale the data patient and feature wise? Or should I fit a scaler on the training set by each column?









Hello. I find the post quite interesting and clear but let me give you an example:
I have a dataset with different features, 6 Numeric and 3 Nominal.
The numeric features are:
salary, commission and hvalue (in euros)
age and hyears (in years) and
zip code (a 4 digit number)
Can I just standardize those features because they do have a different scales?
I mean my classification task (with class feature = group), with standardized dataset obtains far better results (with test’s set accuracy) than with a non-standardized dataset.
Hi Mark,
Generally, it is a good idea to standardize data that has a Gaussian (bell curve) distribution and normalize otherwise.
Not all algorithms require this type of data prep, some require it.
If in doubt, create 3 copies of your data (raw, standardized, normalized) and evaluate many algorithms on all 3. you can dive into more nuanced data preparation later, but this brute force technique will get a good result quickly.
I understand that standarization should not be done to categorical variables as it has lowest value of 0 and highest value of 1 while standarization should be done to continuous variable. I am confused that count data should be standarized or not following the same method subtracting the data by mean and dividing by standard deviation? Also I heard that standarization should be done for both dependent and independent variable for centering and scaling all the data to be same.
It really only makes sense if the data distribution is Gaussian. Count data rarely is, it is more likely a power distribution.
StandardScaler() in Python – All the examples I see online are applying standardization to entire x features. What if my features are a mix of nominal and real valued features. For e.g.: if one feature is sex coded as 0 and 1 and the other feature is age from 0 to 100. If I apply standard scaler to entire training dataset it will scale both variables. Should both be scaled. If not how do I selectively apply it to real valued features and not the nominal features.
Great question Lily,
I believe the PartitionedMultiFilter is a way of using a filter on a subset of rows, more details here:
http://weka.sourceforge.net/doc.dev/weka/filters/unsupervised/attribute/PartitionedMultiFilter.html
It sounds like the above question is asking about filtering a subset of columns in Python, not a subset of rows in Weka. @Jason, although your article is about Weka filtering, can you provide a more thorough answer to Lily’s question about filtering different column types in Python? Thanks.
I think this post might help Amanda:
https://machinelearningmastery.com/data-preparation-gradient-boosting-xgboost-python/
Thanks for the great explanation.
So if my understanding is correct, you are normalizing / standardizing each variable within its values (based on the data set that you have) ? not across the instance or whole dataset numeric values?
and what to do if you want only few numeric variables normalized but might want some other main ones in there original range of values?
– MP
Hi MP,
You can selectively normalize a subset of attributes.
how are the values distributed after applying the filter(normalise)?
Same distribution, just a new scale.
Hi. If i normalise my data for training and testing and after that i get my predicting model. Do i have to always normalise the new data before feeding to the model for prediction?
Yes.
How i select only one attribute to normalize? I select one attribute but it normalize all.
You could extract the column, normalized it, then create a new dataset with the other columns and the normalized column.
Simple numpy tools like hstack() can be used to create a dataset from columns:
https://machinelearningmastery.com/gentle-introduction-n-dimensional-arrays-python-numpy/
jason, great walk through, thanks – question…i’m working with a massive dataset 5k+ obs., 500+ variables. there are numerics, integers, and nominals, and there’s a mix of continuous, discrete and ordinals. the predictor variable is continuous. i’ll need to perform a PCA, but before I do, i’m struggling to understand if i need to standardize or normalize every variable’s observations…obv. some need it, but i’m not sure if they all do.
https://www.eia.gov/consumption/residential/data/2015/xls/codebook2015_public_v3.xlsx
any advice or guidance you can offer would be extremely helpful!
The PCA may only make sense for the numerical data. You should standardize and normalized beforehand or as part of the PCA.
Also, confirm that you need to use a PCA, perhaps try some feature selection methods first in order to discover a baseline performance. Then adopt PCA if it lifts skill.
Hello Jason,
Does Variance of a feature have any role to play in selecting normalize/standardize…? I yes , can you please throw some light on what other considerations we have to take into account .
Thanks
Not really.
would you please let me know how the new data (let’s say one observation) should be normalized ? (e.g. in standardization case, should I use the mean and standard deviation of the training dataset?)
New data should be prepared using the same method used to prepare the training data.
How do I Normalize and Standardize data from Weka Java code, and not from the GUI?
Sorry, I don’t have examples of using the Weka API.
Dear sir,
how to perform standardization for training and testing dataset. I have train and test split and what perform standardization. I don’t think it is okay to perform standardization separately. Thanks
You can fit the standardization process on the train set and apply it to the train and test sets.
I’ve built a neural network using Keras.
1. I’ve found through experiments that I constantly get better forecasting results if I don’t apply a scaler on a specific column (temperature). Does it make any sense? Is it acceptable not to apply a scaler on all the columns?
2. Although you recommend for a neural network to use normalization, do I understand it right, that for example in case of temperature it is better to use standardization, because the temperature tomorrow can be bigger than the maximum until today and vice versa.
Yes, scaling is not always required, but it can improve stability. Often Weka models will scale automatically for you.
Yes, standardization is preferred if the data is Gaussian.
Hi Jason,I’m doing a project that comparison the performance of transformation and I normalize and standardize data but when I bring it to classify they both give the same result.(which is I don’t think that it possible to give the same result because the data is completely different) Do you think i did something wrong in the tranformation process ? Or do you have tutorials for transformation data and then classified it.
No, this sounds reasonable.
You mean it’s normal that the results are the same right?
Because first i think that the process of normalize and standardize are different so the result should be different too.
by the way thank you so much.
Hi,
Do you also normalize the label y?Or just the features X, when using linear regression.
I generally recommend try normalizing everything.
Thank you so much, I have get a lot fruitful concept
You’re welcome.
Hi Jason,
I would like your insight about my problem.
I have a data set of about 100 features, I can normalize or standerize and choose the correct algorithm. However due to my constraints I can only choose 6 features relevant from my data.
Is there a way to determine which features will give me best results?
Shay.
Yes, try different combinations and discover which combination results in the best performance.
Or use a feature selection scoring method:
https://machinelearningmastery.com/feature-selection-with-real-and-categorical-data/
Correct me if I am wrong but wont Weka scale the whole data set before train test split. Should we not scale on the train data and apply the scaling from this to the test data
Yes, ideally we would fit the scaling on training data, and apply to train and test.
And how do we do that, Jason? I cant’ figure this out.
Good question, I don’t recall how to do it in Weka off the cuff, perhaps try messaging the support/email list:
https://machinelearningmastery.com/help-with-weka/
Hello Jason!
My question is that if we have a column which contains journal full names then how we can standardize the journal values according to ISO abbreviation method ?
Perhaps try modeling the problem as a seq2seq problem using an encoder-decoder.
This will help you to get started:
https://machinelearningmastery.com/start-here/#nlp
Hello,
How does the normalization filter in Weka consider the minimum and maximum values?
Are the min and max values of each feature considered to normalize that feature or are they the min and max value of the entire dataset?
Ideally, having separate min and max values for each feature(column) will not work fine on the test set, right?
Thanks in advance.
The minimum and maximum values are estimated from the available data, specifically from each column of data.
Is there a way to change the minimum and maximum value that is being considered?
Specifically, if I am splitting the data and then want to normalize the attribute values in the test data, I need the minimum and maximum values of the train data to be considered.
Is this possible on Weka? If so, how?
Thanks for the help.
Yes, if you implement it yourself you can specify the range.
The weka implementation might support you specifying a range, I’m not sure.
Perhaps try asking on the weka user group?
Hello, I find your article really interesting. Thanks for sharing. I actually have a patient dataset(700patients). Each patient has 10~20 rows of lab test results at the time of visit to the hospital. My task is to predict what kind of drug the patient need in the next visit. I am trying to use an LSTM model. My question is
1. Do I need to scale my data?
2. If so, should I scale the data patient and feature wise? Or should I fit a scaler on the training set by each column?
Any advice would be really helpful! thanks
Thanks.
Perhaps evaluate your model with and without scaled data and compare the results.
Typically data is scaled per feature (column), although perhaps patient-wise scaling makes sense in your case.