Often your raw data for machine learning is not in an ideal form for modeling.
You need to prepare or reshape it to meet the expectations of different machine learning algorithms.
In this post you will discover two techniques that you can use to transform your machine learning data ready for modeling.
After reading this post you will know:
How to convert a real valued attribute into a discrete distribution called discretization.
How to convert a discrete attribute into multiple real values called dummy variables.
When to discretize or create dummy variables from your data.
Kick-start your project with my new book Machine Learning Mastery With Weka, including step-by-step tutorials and clear screenshots for all examples.
Let’s get started.
Update Mar/2018: Added alternate link to download the dataset as the original appears to have been taken down.
Discretize Numerical Attributes
Some machine learning algorithms prefer or find it easier to work with discrete attributes.
For example, decision tree algorithms can choose split points in real valued attributes, but are much cleaner when split points are chosen between bins or predefined groups in the real-valued attributes.
Discrete attributes are those that describe a category, called nominal attributes. Those attributes that describe a category that where there is a meaning in the order for the categories are called ordinal attributes. The process of converting a real-valued attribute into an ordinal attribute or bins is called discretization.
You can discretize your real valued attributes in Weka using the Discretize filter.
The tutorial below demonstrates how to use the Discretize filter. The Pima Indians onset of diabetes dataset is used to demonstrate this filter because of the input values are real-valued and grouping them into bins may make sense.
You can also access the dataset directory in your installation of Weka under the data/ directory by loading the file diabetes.arff.
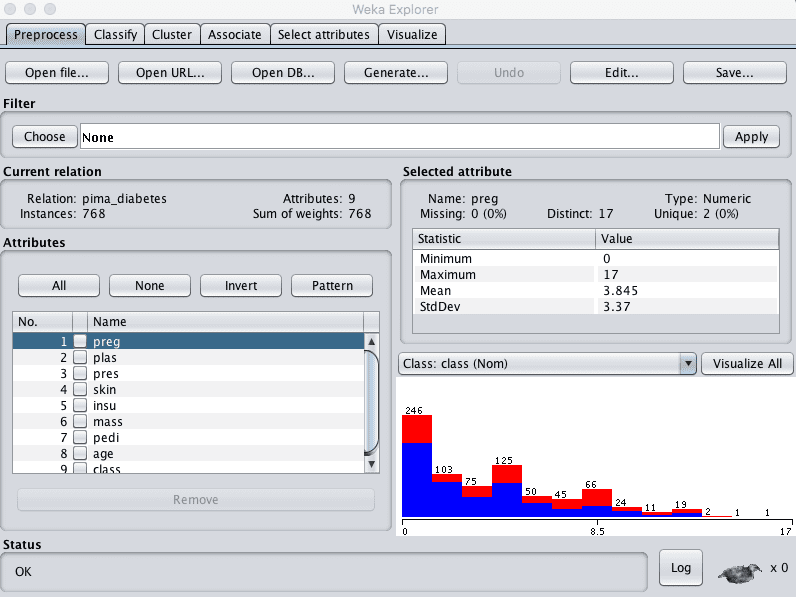
1. Open the Weka Explorer.
2. Load the Pima Indians onset of diabetes dataset.
Weka Explorer Loaded Diabetes Dataset
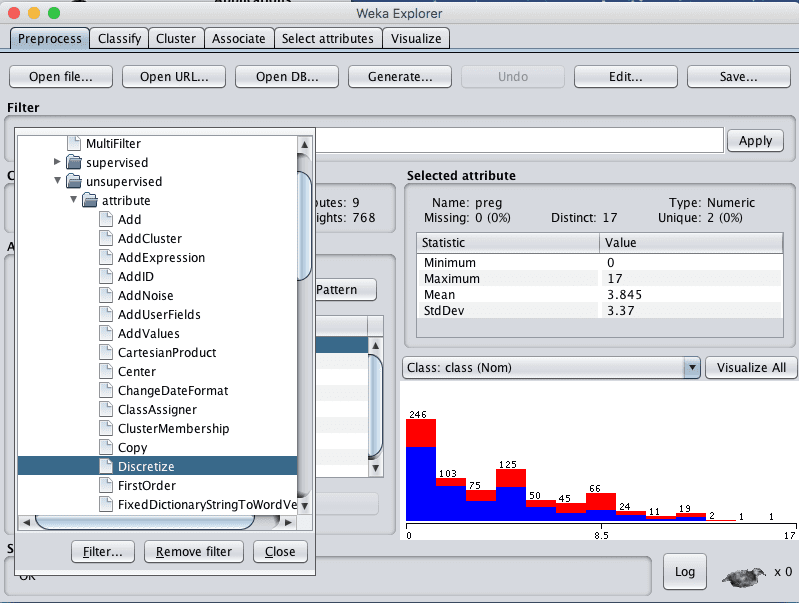
3. Click the “Choose” button for the Filter and select Discretize, it is under unsupervised.attribute.Discretize.
Weka Select Discretize Data Filter
4. Click on the filter to configure it. You can select the indices of the attributes to discretize, the default is to discretize all attributes, which is what we will do in this case. Click the “OK” button.
5. Click the “Apply” button to apply the filter.
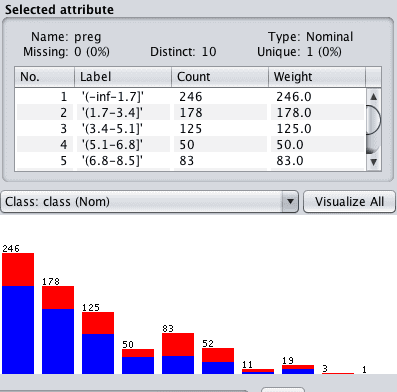
You can click on each attribute and review the details in the “Selected attribute” window to confirm that the filter was applied successfully.
Weka Discretized Attribute
Discretizing your real valued attributes is most useful when working with decision tree type algorithms. It is perhaps more useful when you believe that there are natural groupings within the values of given attributes.
Need more help with Weka for Machine Learning?
Take my free 14-day email course and discover how to use the platform step-by-step.
Click to sign-up and also get a free PDF Ebook version of the course.
Convert Nominal Attributes to Dummy Variables
Some machine learning algorithms prefer to use real valued inputs and do not support nominal or ordinal attributes.
Nominal attributes can be converted to real values. This is done by creating one new binary attribute for each category. For a given instance that has a category for that value, the binary attribute is set to 1 and the binary attributes for the other categories is set to 0. This process is called creating dummy variables.
You can create dummy binary variables from nominal attributes in Weka using the NominalToBinary filter.
The recipe below demonstrates how to use the NominalToBinary filter. The Contact Lenses dataset is used to demonstrate this filter because the attributes are all nominal and provide plenty of opportunity for creating dummy variables.
3. Click the “Choose” button for the Filter and select NominalToBinary, it is under unsupervised.attribute.NominalToBinary.
Weka Select NominalToBinary Data Filter
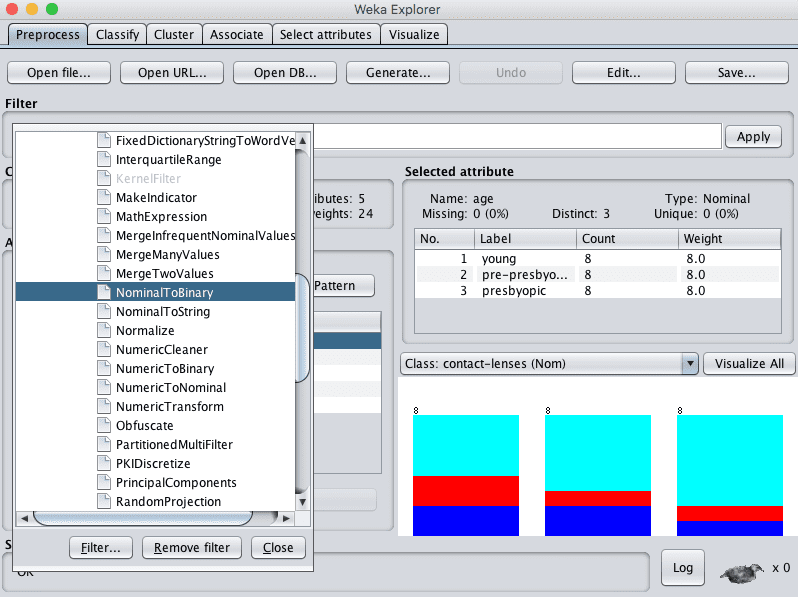
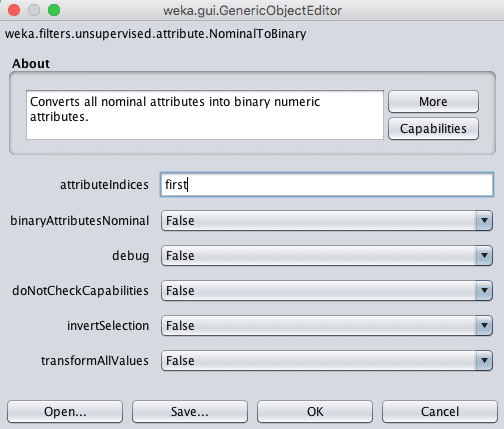
4. Click on the filter to configure it. You can select the indices of the attributes to convert to binary values, the default is to convert all attributes. Change it to only the first attribute. Click the “OK” button.
Weka NominalToBinary Data Filter Configuration
5. Click the “Apply” button to apply the filter.
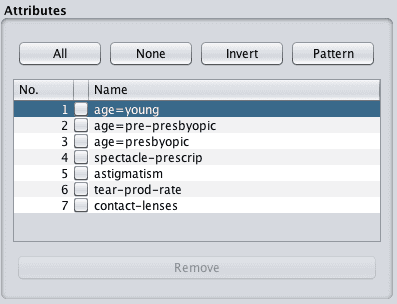
Reviewing the list of attributes will show that the age attribute has been removed and replaced with three new binary attributes: age=young, age=pre-presbyopic and age=presbyopic.
Weka Nominal Attribute Converted to Dummary Variables
Creating dummy variables is useful for techniques that do not support nominal input variables like linear regression and logistic regression. It can also prove useful in techniques like k-nearest neighbors and artificial neural networks.
Summary
In this post you discovered how to transform your machine learning data to meet the expectations of different machine learning algorithms.
Specifically, you learned:
How to convert real valued input attributes to nominal attributes called discretization.
How to convert a categorical input variable to multiple binary input attributes called dummy variables.
When to use discretization and dummy variables when modeling data.
Do you have any questions about data transforms or about this post? Ask your questions in the comments and I will do my best to answer them.
Discretize will discretize the values according to a number of bins (n). Weka will simply cut the range of the values in n subsets, and give the value of the subset to the instances. This is if your attribute is really a continuous variable.
Numeric To Nominal is to transform some Numeric values into a Nominal variable, if this attributes has few unique values. For example, if you have an ID attribute which clusters your dataset in few subsets, it may be wise to convert it into a Nominal attribute instead of treating it like a number. This applies for attributes which are not really continuous, but treated as numeric by Weka because they are numbers.
Hello.
I would like to give diffrent numerical values to to arff file to class attribute.
Values:3.4,4.5,3.3 etc how can I input them
Can I know the format.
Hi, thanks so much for the tutorial. Is there a way to change my output class from numeric to binary nominal? I have a dataset of product reviews with ratings from 1-10, and I would like to use Weka to learn to distinguish between Positive (1-5) and Negative(6-10), taking into account the ranking of the ratings if possible. Thanks!
Hello, thanx for tutorial. I have data set that has 10 class and I want to build multiclass MLP model in weka. I want to predict probability for each class as output of network. For this reason i convert my attribute column to dummies columns but i cannot select as train_y data in weka. How to fix that?
How to convert the string attribute to numeric attribute in weka??
example-
If their are 3 classes of iris disorder-Iris-setosa,Iris-versicolor,Iris-virginica
and if we want to convert it into numeric type .
…numbering as toarray()in python








what is the diffrence between discretize and Numeric To Nominal
They sound the same to me.
Discretize will discretize the values according to a number of bins (n). Weka will simply cut the range of the values in n subsets, and give the value of the subset to the instances. This is if your attribute is really a continuous variable.
Numeric To Nominal is to transform some Numeric values into a Nominal variable, if this attributes has few unique values. For example, if you have an ID attribute which clusters your dataset in few subsets, it may be wise to convert it into a Nominal attribute instead of treating it like a number. This applies for attributes which are not really continuous, but treated as numeric by Weka because they are numbers.
Very helpful!
Hello.
I would like to give diffrent numerical values to to arff file to class attribute.
Values:3.4,4.5,3.3 etc how can I input them
Can I know the format.
If you want to predict numerical values, this is referred to as regression instead of classification.
Perhaps this will help:
https://machinelearningmastery.com/faq/single-faq/what-is-the-difference-between-classification-and-regression
Is it possible to perform the ranking of soccer players through weka?
I have a database with data like, height, weight, speed, strength, agility, kick preference, reputation, etc.
Would you like to know which technique to use for rankings?
Another question … how can nominal numeric transforms be possible?
Perhaps.
It might be easier to use rating algorithms, for example:
https://en.wikipedia.org/wiki/Elo_rating_system
how to descretize date value to be by years instead of equal width
Depends on your data.
Hi, thanks so much for the tutorial. Is there a way to change my output class from numeric to binary nominal? I have a dataset of product reviews with ratings from 1-10, and I would like to use Weka to learn to distinguish between Positive (1-5) and Negative(6-10), taking into account the ranking of the ratings if possible. Thanks!
Yes, perhaps there is a data filter that can perform this operation. Sorry, I don’t have a worked example.
Hello, thanx for tutorial. I have data set that has 10 class and I want to build multiclass MLP model in weka. I want to predict probability for each class as output of network. For this reason i convert my attribute column to dummies columns but i cannot select as train_y data in weka. How to fix that?
I’m not sure, sorry.
How to convert the string attribute to numeric attribute in weka??
example-
If their are 3 classes of iris disorder-Iris-setosa,Iris-versicolor,Iris-virginica
and if we want to convert it into numeric type .
…numbering as toarray()in python
I believe the ARFF format will help define the categorical variables correctly for you to use in Weka:
https://machinelearningmastery.com/load-csv-machine-learning-data-weka/
Is it possible to change your Weka code to produce slightly different results?
Sure.
Thanks, very helpful.
You’re welcome.