The Frechet Inception Distance score, or FID for short, is a metric that calculates the distance between feature vectors calculated for real and generated images.
The score summarizes how similar the two groups are in terms of statistics on computer vision features of the raw images calculated using the inception v3 model used for image classification. Lower scores indicate the two groups of images are more similar, or have more similar statistics, with a perfect score being 0.0 indicating that the two groups of images are identical.
The FID score is used to evaluate the quality of images generated by generative adversarial networks, and lower scores have been shown to correlate well with higher quality images.
In this tutorial, you will discover how to implement the Frechet Inception Distance for evaluating generated images.
After completing this tutorial, you will know:
- The Frechet Inception Distance summarizes the distance between the Inception feature vectors for real and generated images in the same domain.
- How to calculate the FID score and implement the calculation from scratch in NumPy.
- How to implement the FID score using the Keras deep learning library and calculate it with real images.
Kick-start your project with my new book Generative Adversarial Networks with Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
- Updated Oct 2019: Fixed minor typo in the description of the method.

How to Implement the Frechet Inception Distance (FID) From Scratch for Evaluating Generated Images
Photo by dronepicr, some rights reserved.
Tutorial Overview
This tutorial is divided into five parts; they are:
- What Is the Frechet Inception Distance?
- How to Calculate the Frechet Inception Distance
- How to Implement the Frechet Inception Distance With NumPy
- How to Implement the Frechet Inception Distance With Keras
- How to Calculate the Frechet Inception Distance for Real Images
What Is the Frechet Inception Distance?
The Frechet Inception Distance, or FID for short, is a metric for evaluating the quality of generated images and specifically developed to evaluate the performance of generative adversarial networks.
The FID score was proposed and used by Martin Heusel, et al. in their 2017 paper titled “GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium.”
The score was proposed as an improvement over the existing Inception Score, or IS.
For the evaluation of the performance of GANs at image generation, we introduce the “Frechet Inception Distance” (FID) which captures the similarity of generated images to real ones better than the Inception Score.
— GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium, 2017.
The inception score estimates the quality of a collection of synthetic images based on how well the top-performing image classification model Inception v3 classifies them as one of 1,000 known objects. The scores combine both the confidence of the conditional class predictions for each synthetic image (quality) and the integral of the marginal probability of the predicted classes (diversity).
The inception score does not capture how synthetic images compare to real images. The goal in developing the FID score was to evaluate synthetic images based on the statistics of a collection of synthetic images compared to the statistics of a collection of real images from the target domain.
Drawback of the Inception Score is that the statistics of real world samples are not used and compared to the statistics of synthetic samples.
— GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium, 2017.
Like the inception score, the FID score uses the inception v3 model. Specifically, the coding layer of the model (the last pooling layer prior to the output classification of images) is used to capture computer-vision-specific features of an input image. These activations are calculated for a collection of real and generated images.
The activations are summarized as a multivariate Gaussian by calculating the mean and covariance of the images. These statistics are then calculated for the activations across the collection of real and generated images.
The distance between these two distributions is then calculated using the Frechet distance, also called the Wasserstein-2 distance.
The difference of two Gaussians (synthetic and real-world images) is measured by the Frechet distance also known as Wasserstein-2 distance.
— GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium, 2017.
The use of activations from the Inception v3 model to summarize each image gives the score its name of “Frechet Inception Distance.”
A lower FID indicates better-quality images; conversely, a higher score indicates a lower-quality image and the relationship may be linear.
The authors of the score show that lower FID scores correlate with better-quality images when systematic distortions were applied such as the addition of random noise and blur.
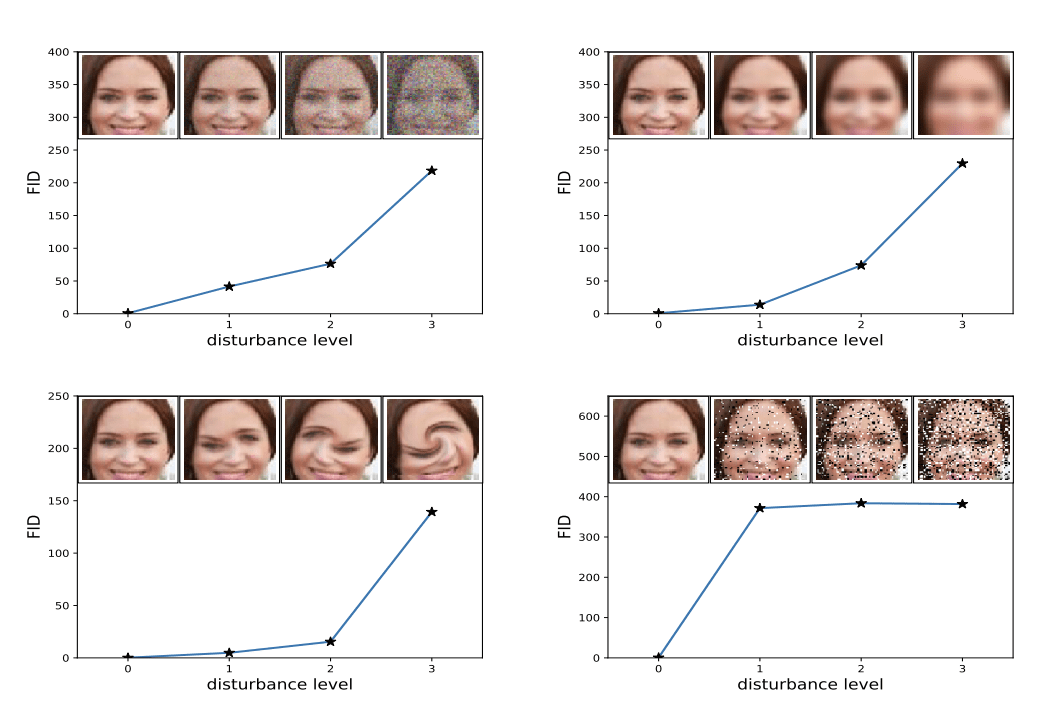
Example of How Increased Distortion of an Image Correlates with High FID Score.
Taken from: GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium.
How to Calculate the Frechet Inception Distance
The FID score is calculated by first loading a pre-trained Inception v3 model.
The output layer of the model is removed and the output is taken as the activations from the last pooling layer, a global spatial pooling layer.
This output layer has 2,048 activations, therefore, each image is predicted as 2,048 activation features. This is called the coding vector or feature vector for the image.
A 2,048 feature vector is then predicted for a collection of real images from the problem domain to provide a reference for how real images are represented. Feature vectors can then be calculated for synthetic images.
The result will be two collections of 2,048 feature vectors for real and generated images.
The FID score is then calculated using the following equation taken from the paper:
- d^2 = ||mu_1 – mu_2||^2 + Tr(C_1 + C_2 – 2*sqrt(C_1*C_2))
The score is referred to as d^2, showing that it is a distance and has squared units.
The “mu_1” and “mu_2” refer to the feature-wise mean of the real and generated images, e.g. 2,048 element vectors where each element is the mean feature observed across the images.
The C_1 and C_2 are the covariance matrix for the real and generated feature vectors, often referred to as sigma.
The ||mu_1 – mu_2||^2 refers to the sum squared difference between the two mean vectors. Tr refers to the trace linear algebra operation, e.g. the sum of the elements along the main diagonal of the square matrix.
The sqrt is the square root of the square matrix, given as the product between the two covariance matrices.
The square root of a matrix is often also written as M^(1/2), e.g. the matrix to the power of one half, which has the same effect. This operation can fail depending on the values in the matrix because the operation is solved using numerical methods. Commonly, some elements in the resulting matrix may be imaginary, which often can be detected and removed.
Want to Develop GANs from Scratch?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
How to Implement the Frechet Inception Distance With NumPy
Implementing the calculation of the FID score in Python with NumPy arrays is straightforward.
First, let’s define a function that will take a collection of activations for real and generated images and return the FID score.
The calculate_fid() function listed below implements the procedure.
Here, we implement the FID calculation almost directly. It is worth noting that the official implementation in TensorFlow implements elements of the calculation in a slightly different order, likely for efficiency, and introduces additional checks around the matrix square root to handle possible numerical instabilities.
I recommend reviewing the official implementation and extending the implementation below to add these checks if you experience problems calculating the FID on your own datasets.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# calculate frechet inception distance def calculate_fid(act1, act2): # calculate mean and covariance statistics mu1, sigma1 = act1.mean(axis=0), cov(act1, rowvar=False) mu2, sigma2 = act2.mean(axis=0), cov(act2, rowvar=False) # calculate sum squared difference between means ssdiff = numpy.sum((mu1 - mu2)**2.0) # calculate sqrt of product between cov covmean = sqrtm(sigma1.dot(sigma2)) # check and correct imaginary numbers from sqrt if iscomplexobj(covmean): covmean = covmean.real # calculate score fid = ssdiff + trace(sigma1 + sigma2 - 2.0 * covmean) return fid |
We can then test out this function to calculate the inception score for some contrived feature vectors.
Feature vectors will probably contain small positive values and will have a length of 2,048 elements. We can construct two lots of 10 images worth of feature vectors with small random numbers as follows:
|
1 2 3 4 5 6 |
... # define two collections of activations act1 = random(10*2048) act1 = act1.reshape((10,2048)) act2 = random(10*2048) act2 = act2.reshape((10,2048)) |
One test would be to calculate the FID between a set of activations and itself, which we would expect to have a score of 0.0.
We can then calculate the distance between the two sets of random activations, which we would expect to be a large number.
|
1 2 3 4 5 6 7 |
... # fid between act1 and act1 fid = calculate_fid(act1, act1) print('FID (same): %.3f' % fid) # fid between act1 and act2 fid = calculate_fid(act1, act2) print('FID (different): %.3f' % fid) |
Tying this all together, the complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# example of calculating the frechet inception distance import numpy from numpy import cov from numpy import trace from numpy import iscomplexobj from numpy.random import random from scipy.linalg import sqrtm # calculate frechet inception distance def calculate_fid(act1, act2): # calculate mean and covariance statistics mu1, sigma1 = act1.mean(axis=0), cov(act1, rowvar=False) mu2, sigma2 = act2.mean(axis=0), cov(act2, rowvar=False) # calculate sum squared difference between means ssdiff = numpy.sum((mu1 - mu2)**2.0) # calculate sqrt of product between cov covmean = sqrtm(sigma1.dot(sigma2)) # check and correct imaginary numbers from sqrt if iscomplexobj(covmean): covmean = covmean.real # calculate score fid = ssdiff + trace(sigma1 + sigma2 - 2.0 * covmean) return fid # define two collections of activations act1 = random(10*2048) act1 = act1.reshape((10,2048)) act2 = random(10*2048) act2 = act2.reshape((10,2048)) # fid between act1 and act1 fid = calculate_fid(act1, act1) print('FID (same): %.3f' % fid) # fid between act1 and act2 fid = calculate_fid(act1, act2) print('FID (different): %.3f' % fid) |
Running the example first reports the FID between the act1 activations and itself, which is 0.0 as we expect (Note: the sign of the score can be ignored).
The distance between the two collections of random activations is also as we expect: a large number, which in this case was 358.
|
1 2 |
FID (same): -0.000 FID (different): 358.927 |
You may want to experiment with the calculation of the FID score and test other pathological cases.
How to Implement the Frechet Inception Distance With Keras
Now that we know how to calculate the FID score and to implement it in NumPy, we can develop an implementation in Keras.
This involves the preparation of the image data and using a pretrained Inception v3 model to calculate the activations or feature vectors for each image.
First, we can load the Inception v3 model in Keras directly.
|
1 2 3 |
... # load inception v3 model model = InceptionV3() |
This will prepare a version of the inception model for classifying images as one of 1,000 known classes. We can remove the output (the top) of the model via the include_top=False argument. Painfully, this also removes the global average pooling layer that we require, but we can add it back via specifying the pooling=’avg’ argument.
When the output layer of the model is removed, we must specify the shape of the input images, which is 299x299x3 pixels, e.g. the input_shape=(299,299,3) argument.
Therefore, the inception model can be loaded as follows:
|
1 2 3 |
... # prepare the inception v3 model model = InceptionV3(include_top=False, pooling='avg', input_shape=(299,299,3)) |
This model can then be used to predict the feature vector for one or more images.
Our images are likely to not have the required shape. We will use the scikit-image library to resize the NumPy array of pixel values to the required size. The scale_images() function below implements this.
|
1 2 3 4 5 6 7 8 9 |
# scale an array of images to a new size def scale_images(images, new_shape): images_list = list() for image in images: # resize with nearest neighbor interpolation new_image = resize(image, new_shape, 0) # store images_list.append(new_image) return asarray(images_list) |
Note, you may need to install the scikit-image library. This can be achieved as follows:
|
1 |
sudo pip install scikit-image |
Once resized, the image pixel values will also need to be scaled to meet the expectations for inputs to the inception model. This can be achieved by calling the preprocess_input() function.
We can update our calculate_fid() function defined in the previous section to take the loaded inception model and two NumPy arrays of image data as arguments, instead of activations. The function will then calculate the activations before calculating the FID score as before.
The updated version of the calculate_fid() function is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# calculate frechet inception distance def calculate_fid(model, images1, images2): # calculate activations act1 = model.predict(images1) act2 = model.predict(images2) # calculate mean and covariance statistics mu1, sigma1 = act1.mean(axis=0), cov(act1, rowvar=False) mu2, sigma2 = act2.mean(axis=0), cov(act2, rowvar=False) # calculate sum squared difference between means ssdiff = numpy.sum((mu1 - mu2)**2.0) # calculate sqrt of product between cov covmean = sqrtm(sigma1.dot(sigma2)) # check and correct imaginary numbers from sqrt if iscomplexobj(covmean): covmean = covmean.real # calculate score fid = ssdiff + trace(sigma1 + sigma2 - 2.0 * covmean) return fid |
We can then test this function with some contrived collections of images, in this case, 10 32×32 images with random pixel values in the range [0,255].
|
1 2 3 4 5 6 |
... # define two fake collections of images images1 = randint(0, 255, 10*32*32*3) images1 = images1.reshape((10,32,32,3)) images2 = randint(0, 255, 10*32*32*3) images2 = images2.reshape((10,32,32,3)) |
We can then convert the integer pixel values to floating point values and scale them to the required size of 299×299 pixels.
|
1 2 3 4 5 6 7 |
... # convert integer to floating point values images1 = images1.astype('float32') images2 = images2.astype('float32') # resize images images1 = scale_images(images1, (299,299,3)) images2 = scale_images(images2, (299,299,3)) |
Then the pixel values can be scaled to meet the expectations of the Inception v3 model.
|
1 2 3 4 |
... # pre-process images images1 = preprocess_input(images1) images2 = preprocess_input(images2) |
Then calculate the FID scores, first between a collection of images and itself, then between the two collections of images.
|
1 2 3 4 5 6 7 |
... # fid between images1 and images1 fid = calculate_fid(model, images1, images1) print('FID (same): %.3f' % fid) # fid between images1 and images2 fid = calculate_fid(model, images1, images2) print('FID (different): %.3f' % fid) |
Tying all of this together, the complete example is listed below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
# example of calculating the frechet inception distance in Keras import numpy from numpy import cov from numpy import trace from numpy import iscomplexobj from numpy import asarray from numpy.random import randint from scipy.linalg import sqrtm from keras.applications.inception_v3 import InceptionV3 from keras.applications.inception_v3 import preprocess_input from keras.datasets.mnist import load_data from skimage.transform import resize # scale an array of images to a new size def scale_images(images, new_shape): images_list = list() for image in images: # resize with nearest neighbor interpolation new_image = resize(image, new_shape, 0) # store images_list.append(new_image) return asarray(images_list) # calculate frechet inception distance def calculate_fid(model, images1, images2): # calculate activations act1 = model.predict(images1) act2 = model.predict(images2) # calculate mean and covariance statistics mu1, sigma1 = act1.mean(axis=0), cov(act1, rowvar=False) mu2, sigma2 = act2.mean(axis=0), cov(act2, rowvar=False) # calculate sum squared difference between means ssdiff = numpy.sum((mu1 - mu2)**2.0) # calculate sqrt of product between cov covmean = sqrtm(sigma1.dot(sigma2)) # check and correct imaginary numbers from sqrt if iscomplexobj(covmean): covmean = covmean.real # calculate score fid = ssdiff + trace(sigma1 + sigma2 - 2.0 * covmean) return fid # prepare the inception v3 model model = InceptionV3(include_top=False, pooling='avg', input_shape=(299,299,3)) # define two fake collections of images images1 = randint(0, 255, 10*32*32*3) images1 = images1.reshape((10,32,32,3)) images2 = randint(0, 255, 10*32*32*3) images2 = images2.reshape((10,32,32,3)) print('Prepared', images1.shape, images2.shape) # convert integer to floating point values images1 = images1.astype('float32') images2 = images2.astype('float32') # resize images images1 = scale_images(images1, (299,299,3)) images2 = scale_images(images2, (299,299,3)) print('Scaled', images1.shape, images2.shape) # pre-process images images1 = preprocess_input(images1) images2 = preprocess_input(images2) # fid between images1 and images1 fid = calculate_fid(model, images1, images1) print('FID (same): %.3f' % fid) # fid between images1 and images2 fid = calculate_fid(model, images1, images2) print('FID (different): %.3f' % fid) |
Running the example first summarizes the shapes of the fabricated images and their rescaled versions, matching our expectations.
Note: the first time the InceptionV3 model is used, Keras will download the model weights and save them into the ~/.keras/models/ directory on your workstation. The weights are about 100 megabytes and may take a moment to download depending on the speed of your internet connection.
The FID score between a given set of images and itself is 0.0, as we expect, and the distance between the two collections of random images is about 35.
|
1 2 3 4 |
Prepared (10, 32, 32, 3) (10, 32, 32, 3) Scaled (10, 299, 299, 3) (10, 299, 299, 3) FID (same): -0.000 FID (different): 35.495 |
How to Calculate the Frechet Inception Distance for Real Images
It may be useful to calculate the FID score between two collections of real images.
The Keras library provides a number of computer vision datasets, including the CIFAR-10 dataset. These are color photos with the small size of 32×32 pixels and is split into train and test elements and can be loaded as follows:
|
1 2 3 |
... # load cifar10 images (images1, _), (images2, _) = cifar10.load_data() |
The training dataset has 50,000 images, whereas the test dataset has only 10,000 images. It may be interesting to calculate the FID score between these two datasets to get an idea of how representative the test dataset is of the training dataset.
Scaling and scoring 50K images takes a long time, therefore, we can reduce the “training set” to a 10K random sample as follows:
|
1 2 3 |
... shuffle(images1) images1 = images1[:10000] |
Tying this all together, we can calculate the FID score between a sample of the train and the test dataset as follows.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
# example of calculating the frechet inception distance in Keras for cifar10 import numpy from numpy import cov from numpy import trace from numpy import iscomplexobj from numpy import asarray from numpy.random import shuffle from scipy.linalg import sqrtm from keras.applications.inception_v3 import InceptionV3 from keras.applications.inception_v3 import preprocess_input from keras.datasets.mnist import load_data from skimage.transform import resize from keras.datasets import cifar10 # scale an array of images to a new size def scale_images(images, new_shape): images_list = list() for image in images: # resize with nearest neighbor interpolation new_image = resize(image, new_shape, 0) # store images_list.append(new_image) return asarray(images_list) # calculate frechet inception distance def calculate_fid(model, images1, images2): # calculate activations act1 = model.predict(images1) act2 = model.predict(images2) # calculate mean and covariance statistics mu1, sigma1 = act1.mean(axis=0), cov(act1, rowvar=False) mu2, sigma2 = act2.mean(axis=0), cov(act2, rowvar=False) # calculate sum squared difference between means ssdiff = numpy.sum((mu1 - mu2)**2.0) # calculate sqrt of product between cov covmean = sqrtm(sigma1.dot(sigma2)) # check and correct imaginary numbers from sqrt if iscomplexobj(covmean): covmean = covmean.real # calculate score fid = ssdiff + trace(sigma1 + sigma2 - 2.0 * covmean) return fid # prepare the inception v3 model model = InceptionV3(include_top=False, pooling='avg', input_shape=(299,299,3)) # load cifar10 images (images1, _), (images2, _) = cifar10.load_data() shuffle(images1) images1 = images1[:10000] print('Loaded', images1.shape, images2.shape) # convert integer to floating point values images1 = images1.astype('float32') images2 = images2.astype('float32') # resize images images1 = scale_images(images1, (299,299,3)) images2 = scale_images(images2, (299,299,3)) print('Scaled', images1.shape, images2.shape) # pre-process images images1 = preprocess_input(images1) images2 = preprocess_input(images2) # calculate fid fid = calculate_fid(model, images1, images2) print('FID: %.3f' % fid) |
Running the example may take some time depending on the speed of your workstation.
At the end of the run, we can see that the FID score between the train and test datasets is about five.
|
1 2 3 |
Loaded (10000, 32, 32, 3) (10000, 32, 32, 3) Scaled (10000, 299, 299, 3) (10000, 299, 299, 3) FID: 5.492 |
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Papers
- GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium, 2017.
- Are GANs Created Equal? A Large-Scale Study, 2017.
- Pros and Cons of GAN Evaluation Measures, 2018.
Code Projects
- Official Implementation in TensorFlow, GitHub.
- Frechet Inception Distance (FID score) in PyTorch, GitHub.
API
- numpy.trace API.
- numpy.cov API.
- numpy.iscomplexobj API.
- Keras Inception v3 Model
- scikit-image Library
Articles
- Frechet Inception Distance, 2017.
- Frechet Inception Distance, 2018.
- Frechet distance, Wikipedia.
- Covariance matrix, Wikipedia.
- Square root of a matrix, Wikipedia.
Summary
In this tutorial, you discovered how to implement the Frechet Inception Distance for evaluating generated images.
Specifically, you learned:
- The Frechet Inception Distance summarizes the distance between the Inception feature vectors for real and generated images in the same domain.
- How to calculate the FID score and implement the calculation from scratch in NumPy.
- How to implement the FID score using the Keras deep learning library and calculate it with real images.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop Generative Adversarial Networks Today!

Develop Your GAN Models in Minutes
...with just a few lines of python codeDiscover how in my new Ebook:
Generative Adversarial Networks with Python
It provides self-study tutorials and end-to-end projects on:
DCGAN, conditional GANs, image translation, Pix2Pix, CycleGAN
and much more...
 for Evaluating GANs")


")
")
")
Hi Jason,
Thanks a lot for your tutorials and keep touching lives with your awesome tutorials.
Thanks, I’m glad the help!
Hi Jason,
May I know is this method suitable to measure for synthetic time series data? Or is there any suitable approach to measure?
No.
I’m not sure off the cuff, sorry.
Hi, Thnx for valuable tutorial. Suppose i have generated data for two classes from two classes Positive & Negative, by running GAN two times. Then should i have to measure FID by taking same classes i.e. Positive original vs Positive Generated and same for negative. Or i have to mix the classes i.e. (Positive original + Negative Original) vs (Positive Generate + negative Generated).
Not sure I follow, sorry.
FID is run on generated images regardless of “class”.
hello
thanks for this great tutorial
its important to consider a batch size?
in other implementation i see batch size for calculating fid
how to add this feature?
thank you in advance
I guess it does not matter for the calculation, but does for the efficiency of the calculation – e.g. running batches of images through the model.
thank you for your replay
i have a another question
when i want to calculate fid score between real and genereated images
i must use test dataset or train dataset or both is allowed ???
thank you very much
You are generating new images, there is no train/test dataset in this case.
hello
thank you for replay
consider a conditinal gan such as Pix2Pix
for calculating FID we need two directory of images (real and fake images)
this image(input images to generator and target images) must be from test dataset?
Thank you very much for explaining
Ah yes, I see. I forgot how fid worked. It’s been a year.
Hey Jason, great tutorials as usual. I have got a custom dataset with a dimension of 64*64*1(grayscale) per image. In order to scale it up with the Inception model, should I convert it to the RGB color-space?
Hmmm, I don’t have a good off the cuff answer. Perhaps try it and see what happens.
Hey Jason, I tried it but got an error stating that the input image depth must be 3. So I did an np.dstack((img, img, img)) on my dataset to make it as per the model requirements and it worked. As usual, thanks for your amazing blogs, they are really helping me implement my projects.
Well done!
Amazing Work Once Again, I am using the CelebA dataset, how many images will be enough to generate for calculating FID.
Thanks.
Hundreds or perhaps thousands.
thank you, i did apply your FID implementation with some modification on 4000+ images, the quality of the images is ok, yet i get an FID score of 20000+, while the same images gives FID of 200+ on other implementations, probably my modification and addition of ImageDataGenerator might be responsible for that.
Interesting.
Thank you so much , for everything that i’m searching about GAN you have a tutorial with awesome code explanations .Keep Going
Thanks!
Thanks a lot. I’m doing my thesis on GANs and you’re saving me!
You’re welcome!
Thank you for all your great tutorials on GANs.
A question that crosses my mind is whether IS or FID scores are just metrics or we can use them as loss functions too ( 1 – FID)?
Off the cuff, they are just metrics.
Hi Jason,
You will have to check, but skimage resize automatically changes the range from 0-255 to 0-1. So the output of the function will be (299, 299, 3) between 0-1. You then apply preprocess_input, which is defined as:
def preprocess_input(x):
x /= 255.
x -= 0.5
x *= 2.
return x
Presumably you are double scaling. You can add preserve_range=True in resize to avoid that.
When doing anything except classification with pretrained networks they tend to be kind of robusts to details like these, but then of course, that it what makes them terrible in terms of adversarial robustness.
Thanks for the tip Simon! I’ll investigate.
resize() does not appear to change the range of the pixel values.
Hi Jason,
How do we calculate the FID score if the dataset size is less than 2048 images?
2048 is not related to the number of images used to calculate the score.
Hi Jason,
In the Official Implementation in TensorFlow, GitHub – they say:
IMPORTANT: The number of samples to calculate the Gaussian statistics (mean and covariance) should be greater than the dimension of the coding layer, here 2048 for the Inception pool 3 layer. Otherwise the covariance is not full rank resulting in complex numbers and nans by calculating the square root.
We recommend using a minimum sample size of 10,000 to calculate the FID otherwise the true FID of the generator is underestimated.
In my case I do not have that many samples. Is it still Ok to calculate the FID on very little samples (<2048)?
Fair enough.
Perhaps don’t use the official implementation to meet the requirements you listd.
Dear Jason,
I have finished the first two parts of your book “GAN with Python”. I have written a review about it:
http://questioneurope.blogspot.com/2020/09/generative-adversarial-networks-with.html
Kind regards,
Dominique
Well done!
Dear Dr. Jason
Hello,thank you for wonderful works.
I have a question. Could I use this to calculate fid value between datasets in my local path to another datasets in my local path?
I used like this:
images1 = list(glob(str(“real images path”)))
shuffle(images1)
images1 = images1[:1000]
images1 = DataFrame(images1)
images2 = DataFrame(list(glob(str(“generated images path”))))
But I got a error like this:
ValueError: Input 0 of layer conv2d_846 is incompatible with the layer: : expected min_ndim=4, found ndim=2. Full shape received: (None, 1)
You’re welcome.
Sorry, I don’t know why you got this error. Perhaps you can post your entire code listing and error to stackoverflow.com
Hi Jason, thanks for the tutorials. Does the FID score have value when applied to a GAN generating images which don’t belong to any of the 1000 classes that inception v3 was trained on?
It will give a score, not sure that it will be as useful.
Hi Jason,
Firstly , thanks a lot for sharing your knowledge. Truly appreciate it.
I tried using your codes on 10000 images. No problem.
It was also alright to compare 20000 images.
however, from 30000 images onwards, memory issues begin to come up.
It’s almost impossible to calculate FID for 50000 images as recommended to get reliable FID values. Even when I used on a system with 117 GB memory.
How could we get around memory issues?
Perhaps you can try using a machine with more memory, e.g. in the cloud?
Perhaps you can try using fewer images?
Perhaps you can try scaling down the image sizes?
Okay thanks Jason.
Hi Jason, amazing job. Can the feature vector for evaluating the FID score be extracted for another network, e.g., a Residual Network?
Thanks.
Perhaps.
Dear Jason,
Thank you very much for your sharing. Your tutorials help me a lot.
There is a question I want to seek your suggestions about FID. Can we use it in different other datasets, for example, my own dataset?
Best regards,
Rui Guo
I think so, perhaps experiment.
Hello Jason,
Thank you very much for your sharing.
I found that the ‘calculate_fid’ function may not suitable for calculating only a one-pair comparison. As the variable name implies ‘images1’, the numpy function will fail with only input one pair image.
Since the covariance matrix is a single value, the msqrt, trace will not work properly.
For example.
act_1, act_2 = model.predict(im_1), model.predict(im_2)
one_sigma_val_1 = cov(act1, rowvar=False)
one_sigma_val_2 = cov(act2, rowvar=False)
…
covmean = sqrtm(one_sigma_val_1.dot(one_sigma_val_2 )) // error this line.
Best regards,
Josef Huang
Thanks.
HI . did you find solution for this error
Hi Jason
Thank you for the great tutorial
Can FID be useful for non image and 1D data sets, like generating “gene expression” data ?
Hey, thanks for this! why do we assume that the dist. of hte features of both fakes and reals is gaussian?
Hi Rachel…The following resource may add clarity:
https://www.itl.nist.gov/div898/handbook/pmd/section4/pmd445.htm
This link is broken and I have the same question. Why would we assume that the features would be gaussian
Nevermind, sorry, I got the link to work. I will see it now. sorry
Hi Jason,
May I know what is the recommended number of samples for calculating FID score?
Hi Mohamed..The following resource may be of interest:
https://openaccess.thecvf.com/content_CVPR_2020/papers/Chong_Effectively_Unbiased_FID_and_Inception_Score_and_Where_to_Find_CVPR_2020_paper.pdf
Hi, there’s a problem with the link to the paper. I found the working link as of now: https://arxiv.org/abs/1706.08500#
Thank you Kien!
Nice post!
Thank you!
Hi Naooooooo…You are very welcome! Thank you for the feedback and support!
Thank you for sharing this informative article on implementing the Frechet Inception Distance (FID) for evaluating GANs. It provides a clear and detailed explanation of what FID is and how to calculate it from scratch using NumPy and with the Keras deep learning library. This will be a valuable resource for anyone working with generative adversarial networks.
Thank you for your feedback and support Brandi! We greatly support it!
Hi, newbie question here. I followed the code through but the FID calculation returned an error. Here’s the full traceback that I got:
ValueError Traceback (most recent call last)
Cell In[7], line 32
29 images2 = preprocess_input(images2)
31 # fid between images1 and images2
—> 32 fid = calculate_fid(model, images1, images2)
33 print(‘FID (different): %.3f’ % fid)
Cell In[3], line 22, in calculate_fid(model, images1, images2)
20 ssdiff = np.sum((mu1 – mu2)**2.0)
21 # calculate sqrt of product between cov
—> 22 covmean = sqrtm(sigma1.dot(sigma2))
23 # check and correct imaginary numbers from sqrt
24 if iscomplexobj(covmean):
File /opt/conda/lib/python3.10/site-packages/scipy/linalg/_matfuncs_sqrtm.py:160, in sqrtm(A, disp, blocksize)
158 A = _asarray_validated(A, check_finite=True, as_inexact=True)
159 if len(A.shape) != 2:
–> 160 raise ValueError(“Non-matrix input to matrix function.”)
161 if blocksize < 1:
162 raise ValueError("The blocksize should be at least 1.")
ValueError: Non-matrix input to matrix function.
Could you help me point out where did I do wrong?
Thanks in advance!
Hi AN…Did you copy and paste code or type it in? Also, you may want to try your code in Google Colab.
Hi James, I tried to type the code manually but no luck. Also tried to copy/paste with edits to the indentation but it still gives the same error. Google Colab also returned the same result
Hi James, thanks for this information and for answering so many questions through the years.
I have one, Im generating fundus images, and I have been evaluating them with your code. Now, i’ve read many papers and none of them explains how they did their implementation of the FID, they just report it. So how much percent of the database should I take for a test dataset, and the FID i get from the test is the one i should report?. Thank you so much.
Hi Hector…You are very welcome! The amount of data to use for evaluating the Frechet Inception Distance (FID) when working with Generative Adversarial Networks (GANs) can vary depending on several factors, including the complexity of the dataset, the diversity of the generated samples, and the computational resources available.
However, as a general guideline, it’s recommended to use a sizable amount of data that is representative of the dataset you’re working with. Typically, people use tens of thousands of samples for computing FID scores. For instance, 50,000 samples from both the real data distribution and the generated data distribution is a common choice.
Using too few samples can lead to unreliable FID scores, as they might not capture the full diversity of the data distribution. On the other hand, using too many samples can become computationally expensive. Therefore, a balance needs to be struck based on the specifics of your project and the resources available.
Additionally, it’s important to ensure that the FID computation is consistent between different experiments to enable fair comparisons.
I want to ask if FID is proposed as an improvement over the existing Inception Score, then why do most research paper I have read, they always evaluate on 2 metrics at the same time, why not use only FID but also use Inception Score too ? Could you please help me understand this ? Thanks
Bruce
Hi Bruce…While we cannot speak to why authors may reference specific metrics, we do offer some thoughts on FID.
The Fréchet Inception Distance (FID) is a metric used to evaluate the quality of images generated by generative models, such as Generative Adversarial Networks (GANs). It measures the similarity between the distribution of generated images and the distribution of real images. The FID is particularly useful in scenarios where the goal is to produce high-quality, realistic images. Here are some specific instances when you might apply FID in machine learning:
1. **Evaluating GAN Performance**: When training GANs or similar generative models, FID provides a quantitative measure to assess how well the model is performing in terms of generating realistic images. It’s commonly used as a benchmark to compare different models or configurations.
2. **Model Selection**: During the development phase, you might experiment with various architectures, hyperparameters, or training techniques. FID can help in selecting the model that produces the most realistic images by providing a comparative metric.
3. **Monitoring Training Progress**: FID can be calculated periodically during the training process to monitor how the model’s performance evolves over time. A decreasing FID score indicates that the model is generating images that are becoming increasingly similar to the target dataset.
4. **Research and Development**: In academic or industrial research, FID is often used to validate the effectiveness of new generative models or improvements to existing models. It serves as a standard metric to report in research papers and technical documentation.
5. **Fine-tuning and Optimization**: After selecting a generative model, FID can be used to fine-tune the model’s parameters or the training process to achieve better performance. It helps in optimizing the model to produce images that are closer to the real dataset in terms of statistical properties.
6. **Benchmarking Against Competing Approaches**: When comparing different generative models or techniques, FID provides a common ground for evaluation. It’s used to benchmark the model’s ability to generate realistic images against competing approaches.
To calculate the FID, features from a pre-trained Inception model are extracted for both generated and real images. Then, the mean and covariance of these features are computed for both sets of images. The FID is calculated as the Fréchet distance between these two multivariate Gaussians, with lower scores indicating closer similarity between the distributions of generated and real images.
It’s important to note that while FID is a widely used metric due to its sensitivity to both the quality and diversity of generated images, it should not be the sole metric for evaluating generative models. Other factors and metrics, such as Inception Score (IS) and qualitative assessments, should also be considered for a comprehensive evaluation.
My Fid score for gan generated images is 0.0002,using this FID code,.Is my score is correct or wrong
The Frechet Inception Distance (FID) score is a widely used metric for evaluating the quality and diversity of images generated by Generative Adversarial Networks (GANs). It measures the similarity between the distribution of generated images and real images, with a lower FID score indicating greater similarity and, by extension, better quality of the generated images. The FID score is calculated using features extracted from an intermediate layer of the Inception v3 model, comparing the mean and covariance of the generated images to those of the real images.
An FID score of 0.0002 is extremely low, suggesting that the generated images are almost identical to the real images, based on the features extracted by the Inception model. While achieving a low FID score is desirable, a score that low is quite unusual and could indicate a few different things:
1. **Exceptional Performance:** If your GAN model has been meticulously tuned and trained on a very specific or constrained dataset, it’s possible (though still quite rare) to achieve such a low score legitimately, indicating extremely high-quality image generation.
2. **Overfitting:** Such a low score might suggest that the GAN has overfitted to the training data. This means it’s not generating new, diverse images but rather reproducing training images or generating images very close to them. This would reduce its utility for generating new content since it’s essentially memorizing rather than generalizing from the training data.
3. **Evaluation Error:** There could be an issue with how the FID score was calculated. This might involve mistakes in the implementation of the FID calculation, errors in the datasets used for evaluation (for example, using a very small or non-representative sample of images for comparison), or issues with the feature extraction process.
4. **Dataset Characteristics:** If the dataset is extremely uniform (for example, very slight variations on the same image), even a well-functioning GAN might achieve such a low score simply because there isn’t much variation in the data to begin with.
To determine if your FID score is accurate and reflective of your GAN’s performance, consider the following steps:
– **Review the FID Calculation Code:** Ensure the code is correctly implemented. Comparing your implementation against well-established ones or using a widely recognized library for the calculation can help verify its accuracy.
– **Evaluate with Standard Benchmarks:** If possible, test your GAN and FID calculation on a dataset with known benchmark FID scores to see if your scores align with expected results.
– **Check the Diversity of Your Generated Images:** Manually inspect the generated images to assess their diversity and quality. If they seem too similar to the training images or lack variation, overfitting might be an issue.
– **Cross-Validation:** Consider using different subsets of your data for training and evaluation or applying other metrics like Inception Score (IS) or Precision and Recall for GANs (PR) to get a more comprehensive assessment of your GAN’s performance.
Hello!
I am a student trying to learn more about GANs and came across your (very helpful) resource. However, when I run your code, my FID score for the same images is not 0, but instead an extremely large value, and my FID score for different images is even larger still. I was wondering if you knew how to solve this problem?
This is my output for the running of the image model:
Prepared (10, 32, 32, 3) (10, 32, 32, 3)
Scaled (10, 299, 299, 3) (10, 299, 299, 3)
1/1 [==============================] – 2s 2s/step
1/1 [==============================] – 0s 425ms/step
FID (same): 694412041954855888943625996677483848827241164739444736.000
1/1 [==============================] – 0s 416ms/step
1/1 [==============================] – 0s 411ms/step
FID (different): -2453839756149402799309509623417646099843038183163411885984616328058594297069187715703102349152223137354258579036886706025398272.000
Hi Matt…Did you copy and paste the code or type it in? Also, you may want to try your model code in Google Colab. Let us know what you find out!
Hi Jason,
thank you so much for all of this information.
I am currently trying the code and seem to be getting a similar issue with Matt:
My FID is FID: 4707826301540010572876842067405749812076766583348025884672.000 even for the same set of images. Also, this is through google colab!
One of the edits I am making to the code is to reduce the dimensions of the 3D matrix, or else I would get the error message ValueError: m has more than 2 dimensions for the mu1,mu2 calculations. Do you recommend any methods as to how I can reduce the dimensions to calculate the mean?
Hi Burk…To address the issue of reducing the dimensions of a 3D matrix to calculate means, especially if you’re encountering errors like
ValueError: m has more than 2 dimensions, there are a few strategies you can use depending on what exactly you need for your calculations. Here’s a breakdown of common methods:### 1. Using
numpy.meanIf you are using NumPy, you can calculate the mean across specific axes using
numpy.mean, which allows you to maintain the control over dimensionality.#### Example
Suppose you have a 3D matrix
Xwith shape(samples, time_steps, features)and you want to compute the mean across thetime_stepsdimension:pythonimport numpy as np
# Create a dummy 3D array
X = np.random.rand(100, 10, 5) # 100 samples, 10 time steps, 5 features per step
# Calculate the mean across the time steps (axis=1)
mean_X = np.mean(X, axis=1)
print(mean_X.shape) # This will print (100, 5)
### 2. Flattening
If you just want to collapse all dimensions and calculate a global mean, you can use
numpy.flattento collapse your 3D matrix into a 1D array and then calculate the mean.#### Example
python
# Flatten the entire array and compute the overall mean
flat_X = X.flatten()
mean_flat_X = np.mean(flat_X)
print(mean_flat_X)
### 3. Reshaping
Another approach could be reshaping the matrix into a 2D array if you need to perform operations that inherently work on 2D data.
#### Example
If you want to compute the mean of each feature across all samples and time steps separately:
python
# Reshape to merge samples and time steps
reshaped_X = X.reshape(-1, X.shape[2]) # Merging the first two dimensions
mean_features = np.mean(reshaped_X, axis=0)
print(mean_features.shape) # This will print (5,)
### 4. Using
numpy.apply_along_axisIf the means need to be calculated in a more complex manner or if additional functions need to be applied, you can use
numpy.apply_along_axisto apply a function along a specific axis.#### Example
Calculate the mean of each feature across time for each sample separately:
python
# Apply a custom function along the time steps axis for each feature
custom_mean = np.apply_along_axis(np.mean, 1, X)
print(custom_mean.shape) # This will print (100, 5)
### Selecting the Right Method
– **Dimension of Interest**: Choose the axis parameter carefully based on which dimensions represent what in your data (e.g., samples, time steps, features).
– **Purpose of Reduction**: Consider why you are reducing dimensions (e.g., to input into a model, for simplification, for visualization) as this will guide your method choice.
– **Preservation of Information**: Be mindful of how dimension reduction affects the information contained in the data. Collapsing dimensions can sometimes obscure important patterns.
Using these methods should help you manage and manipulate the dimensions of your data effectively for mean calculation or any other statistical analysis you might need to perform.
hi when i run your code i got this : FID score for the same images is not 0
1/1 [==============================] – 3s 3s/step
1/1 [==============================] – 2s 2s/step
FID (same): 118480295255423599417400525363044703603931959014258651430912.000
1/1 [==============================] – 2s 2s/step
1/1 [==============================] – 3s 3s/step
FID (different): -197010030981972396061395200500718069025398696352327233339741467021228608857486053057071331274424578204033139951534080.000
Hi Jack…Did you copy and paste the data or type it in? Also, have your tried your implementation in Google Colab?
hello , i am copying and past your code but not working ,for Same data is not 0 ,i use all code numpy and keras.
Hi elhoucine…PLease provide more detail around any errors or results of your model so that we may better assist you.
When i run code in google colab it not give FID=0 for same image,but it working fine in jupyter notebook
Thank you very for your help, it is very useful
i have a question please
how we can implement keras code between only two images ?
Thank you
Hi Moony…To compute the **Fréchet Inception Distance (FID)** between two images using Keras, you can follow these steps. The FID score measures the distance between two distributions, often used to evaluate the quality of images generated by GANs by comparing them to real images. In your case, you want to calculate the FID between only two images, which is possible, though the metric is usually more reliable when comparing distributions of multiple images.
Here’s a step-by-step guide to implement FID between two images using Keras:
### Steps to Implement FID:
1. **Load the InceptionV3 Model**:
The FID is computed using activations from an Inception model pre-trained on ImageNet. Keras provides this model directly.
2. **Preprocess the Images**:
The images need to be resized to the input shape required by InceptionV3 (299×299) and then preprocessed according to the model’s requirements (i.e., scaling pixel values between -1 and 1).
3. **Extract Features from the Images**:
Use the pre-trained InceptionV3 model to extract features from the images. This is done by removing the final classification layer and using the activations from a layer like
avg_pool.4. **Compute the Fréchet Distance**:
The FID score is computed using the mean and covariance of the feature vectors extracted from the images.
### Code Example (for two images)
pythonimport numpy as np
from keras.applications.inception_v3 import InceptionV3, preprocess_input
from keras.preprocessing.image import load_img, img_to_array
from scipy.linalg import sqrtm
# Load pre-trained InceptionV3 model and remove the top layer
inception_model = InceptionV3(include_top=False, pooling='avg', input_shape=(299, 299, 3))
# Helper function to preprocess the image
def preprocess_image(image_path):
img = load_img(image_path, target_size=(299, 299)) # Resize image to match InceptionV3 input size
img = img_to_array(img) # Convert image to numpy array
img = np.expand_dims(img, axis=0) # Add batch dimension
img = preprocess_input(img) # Preprocess for InceptionV3 (-1 to 1 scaling)
return img
# Function to calculate FID between two images
def calculate_fid(image1_path, image2_path):
# Preprocess both images
image1 = preprocess_image(image1_path)
image2 = preprocess_image(image2_path)
# Use the InceptionV3 model to extract features
act1 = inception_model.predict(image1)
act2 = inception_model.predict(image2)
# Calculate the mean and covariance of the activations
mu1, sigma1 = act1.mean(axis=0), np.cov(act1, rowvar=False)
mu2, sigma2 = act2.mean(axis=0), np.cov(act2, rowvar=False)
# Calculate the sum of squared differences between means
ssdiff = np.sum((mu1 - mu2) ** 2.0)
# Compute sqrt of product of covariance matrices
covmean, _ = sqrtm(sigma1.dot(sigma2), disp=False)
# Check for imaginary numbers and correct them
if np.iscomplexobj(covmean):
covmean = covmean.real
# Calculate the FID score
fid = ssdiff + np.trace(sigma1 + sigma2 - 2.0 * covmean)
return fid
# Example usage: replace with your image paths
image1_path = 'image1.jpg'
image2_path = 'image2.jpg'
fid_score = calculate_fid(image1_path, image2_path)
print(f"FID score between the two images: {fid_score}")
### Explanation:
1. **InceptionV3 Model**: We load the InceptionV3 model without the top layer (
include_top=False) and set the pooling to ‘avg’ to get the feature vectors after the global average pooling layer.2. **Preprocessing**: The images are resized to 299×299 and scaled to the correct range (InceptionV3 expects inputs in the range [-1, 1]).
3. **Feature Extraction**: We pass the preprocessed images through the InceptionV3 model to extract the feature activations.
4. **FID Calculation**: The FID score is computed using the formula:
\[
\text{FID} = \|\mu_1 – \mu_2\|^2 + \text{Tr}(\Sigma_1 + \Sigma_2 – 2(\Sigma_1\Sigma_2)^{1/2})
\]
where \( \mu_1 \) and \( \mu_2 \) are the means, and \( \Sigma_1 \) and \( \Sigma_2 \) are the covariance matrices of the activations of the two images.
### Notes:
– Since you are comparing just two images, the covariance matrices might not be well-formed. In practice, FID is usually computed over a large number of samples.
– This implementation assumes that the images are stored in files. If your images are in memory, you can adjust the code to use
img_to_arrayandpreprocess_inputaccordingly.This should give you the FID score between two images!
thank you for your help.
i appreciated that, but there is some problem
i run the code as it is bur the output give me
ValueError: Non-matrix input to matrix function.
and colab mentioned to that line
covmean = sqrtm(sigma1.dot(sigma2))
could you help me ?
thank you very much