Gradient boosting is one of the most powerful techniques for applied machine learning and as such is quickly becoming one of the most popular.
But how do you configure gradient boosting on your problem?
In this post you will discover how you can configure gradient boosting on your machine learning problem by looking at configurations reported in books, papers and as a result of competitions.
After reading this post, you will know:
How to configure gradient boosting according to the original sources.
Ideas for configuring the algorithm from defaults and suggestions in standard implementations.
Rules of thumb for configuring gradient boosting and XGBoost from a top Kaggle competitors.
Kick-start your project with my new book XGBoost With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
How to Configure the Gradient Boosting Algorithm Photo by Chris Sorge, some rights reserved.
Need help with XGBoost in Python?
Take my free 7-day email course and discover xgboost (with sample code).
Click to sign-up now and also get a free PDF Ebook version of the course.
The v-M trade-off is clearly evident; smaller values of v give rise to larger optimal M-values. They also provide higher accuracy, with a diminishing return for v < 0.125. The misclassification error rate is very flat for M > 200, so that optimal M-values for it are unstable. … the qualitative nature of these results is fairly universal.
He suggests to first set a large value for the number of trees, then tune the shrinkage parameter to achieve the best results. Studies in the paper preferred a shrinkage value of 0.1, a number of trees in the range 100 to 500 and the number of terminal nodes in a tree between 2 and 8.
In the 1999 paper “Stochastic Gradient Boosting“, Friedman reiterated the preference for the shrinkage parameter:
The “shrinkage” parameter 0 < v < 1 controls the learning rate of the procedure. Empirically …, it was found that small values (v <= 0.1) lead to much better generalization error.
In the paper, Friedman introduces and empirically investigates stochastic gradient boosting (row-based sub-sampling). He finds that almost all subsampling percentages are better than so-called deterministic boosting and perhaps 30%-to-50% is a good value to choose on some problems and 50%-to-80% on others.
… the best value of the sampling fraction … is approximately 40% (f=0.4) … However, sampling only 30% or even 20% of the data at each iteration gives considerable improvement over no sampling at all, with a corresponding computational speed-up by factors of 3 and 5 respectively.
He also studied the effect of the number of terminal nodes in trees finding values like 3 and 6 better than larger values like 11, 21 and 41.
In both cases the optimal tree size as averaged over 100 targets is L = 6. Increasing the capacity of the base learner by using larger trees degrades performance through “over-fitting”.
In his talk titled “Gradient Boosting Machine Learning” at H2O, Trevor Hastie made the comment that in general gradient boosting performs better than random forest, which in turn performs better than individual decision trees.
Gradient Boosting > Random Forest > Bagging > Single Trees
They comment that a good value the number of nodes in the tree (J) is about 6, with generally good values in the range of 4-to-8.
Although in many applications J = 2 will be insufficient, it is unlikely that J > 10 will be required. Experience so far indicates that 4 <= J <= 8 works well in the context of boosting, with results being fairly insensitive to particular choices in this range.
They suggest monitoring the performance on a validation dataset in order to calibrate the number of trees and to use an early stopping procedure once performance on the validation dataset begins to degrade.
As in Friedman’s first gradient boosting paper, they comment on the trade-off between the number of trees (M) and the learning rate (v) and recommend a small value for the learning rate < 0.1.
Smaller values of v lead to larger values of M for the same training risk, so that there is a tradeoff between them. … In fact, the best strategy appears to be to set v to be very small (v < 0.1) and then choose M by early stopping.
Also, as in Friedman’s stochastic gradient boosting paper, they recommend a subsampling percentage (n) without replacement with a value of about 50%.
A typical value for n can be 1/2, although for large N, n can be substantially smaller than 1/2.
Configuration of Gradient Boosting in R
The gradient boosting algorithm is implemented in R as the gbm package.
Reviewing the package documentation, the gbm() function specifies sensible defaults:
n.trees = 100 (number of trees).
interaction.depth = 1 (number of leaves).
n.minobsinnode = 10 (minimum number of samples in tree terminal nodes).
shrinkage = 0.001 (learning rate).
It is interesting to note that a smaller shrinkage factor is used and that stumps are the default. The small shrinkage is explained by Ridgeway next.
In the vignette for using the gbm package in R titled “Generalized Boosted Models: A guide to the gbm package“, Greg Ridgeway provides some usage heuristics. He suggest firs setting the learning rate (lambda) to as small as possible then tuning the number of trees (iterations or T) using cross validation.
In practice I set lambda to be as small as possible and then select T by cross-validation. Performance is best when lambda is as small as possible performance with decreasing marginal utility for smaller and smaller lambda.
He comments on his rationale for setting the default shrinkage to the small value of 0.001 rather than 0.1.
It is important to know that smaller values of shrinkage (almost) always give improved predictive performance. That is, setting shrinkage=0.001 will almost certainly result in a model with better out-of-sample predictive performance than setting shrinkage=0.01. … The model with shrinkage=0.001 will likely require ten times as many iterations as the model with shrinkage=0.01
Ridgeway also uses quite large numbers of trees (called iterations here), thousands rather than hundreds
I usually aim for 3,000 to 10,000 iterations with shrinkage rates between 0.01 and 0.001.
Configuration of Gradient Boosting in scikit-learn
It is useful to review the default configuration for the algorithm in this library.
There are many parameters, but below are a few key defaults.
learning_rate=0.1 (shrinkage).
n_estimators=100 (number of trees).
max_depth=3.
min_samples_split=2.
min_samples_leaf=1.
subsample=1.0.
It is interesting to note that the default shrinkage does match Friedman and that the tree depth is not set to stumps like the R package. A tree depth of 3 (if the created tree was symmetrical) will have 8 leaf nodes, matching the upper bound of the preferred number of terminal nodes in Friedman’s studies (alternately max_leaf_nodes can be set).
In the scikit-learn user guide under the section titled “Gradient Tree Boosting” the authors comment that setting the maximum leaf nodes has a similar effect to setting the max depth to the maximum leaf nodes minus one, but results in worse performance.
We found that max_leaf_nodes=k gives comparable results to max_depth=k-1 but is significantly faster to train at the expense of a slightly higher training error.
In a small study demonstrating regularization methods for gradient boosting titled “Gradient Boosting regularization“, the results show the benefit of using both shrinkage and sub-sampling.
Configuration of Gradient Boosting in XGBoost
The XGBoost library is dedicated to the gradient boosting algorithm.
It too specifies default parameters that are interesting to note, firstly the XGBoost Parameters page:
eta=0.3 (shrinkage or learning rate).
max_depth=6.
subsample=1.
This shows a higher learning rate and a larger max depth than we see in most studies and other libraries. Similarly, we can summarize the default parameters for XGBoost in the Python API reference.
max_depth=3.
learning_rate=0.1.
n_estimators=100.
subsample=1.
These defaults are generally more in-line with scikit-learn defaults and recommendations from the papers.
He also provide a terse configuration strategy for new problems:
Run the default configuration (and presumably review learning curves?).
If the system is overlearning, slow the learning down (using shrinkage?).
If the system is underlearning, speed the learning up to be more aggressive (using shrinkage?).
In Owen Zhang’s talk to the NYC Data Science Academy in 2015 titled “Winning Data Science Competitions“, he provides some general tips for configuring gradient boost with XGBoost. Owen is a heavy user of gradient boosting.
My confession: I (over)use GBM. When in doubt, use GBM.
He provides some tips for configuring gradient boosting:
learning rate + number of trees: Target 500-to-1000 trees and tune learning rate.
number of samples in leaf: the number of observations needed to get a good mean estimate.
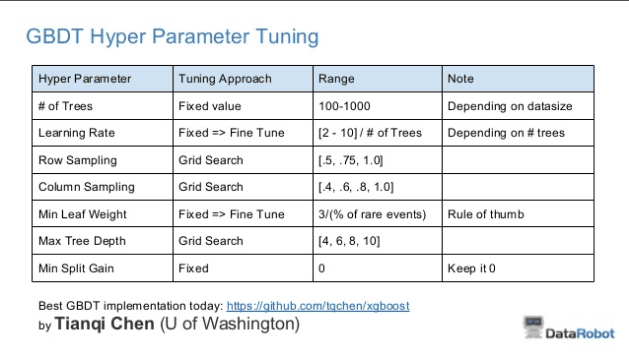
can you please elaborate rare events (from Owen Zhang Table of Suggestions for Hyperparameter Tuning of XGBoost Table) and event rate (from Owen Zhang Suggestions for Tuning XGBoost)? This page looks very informative and useful for everyone..
Hi Jason,
Hope you are well. Thanks for the amazing information on machine learning techniques. Currently I’m working on the GBM in R and I’m trying to figureout the best parameters for our GBM model. However, based on what I found and read and also based on your information about the GBM parameter tuning, the lower learning rate should result in a better AUC. However, I have checked this with the piece of code below:
gbm1 h2o.auc(gbm1)
[1] 0.8592122
> gbm2 h2o.auc(gbm2)
[1] 0.8628086
> gbm3 h2o.auc(gbm3)
[1] 0.8628086
************************************************************************************************************************************************************************************************************************************
The difference between gbm1 and gbm2 in their learn_rate. GBM 2 has bigger learn_rate than the first one but ends to a better result. It made me very confused about what I have read and I would appreciate if you could please help me to understand the problem.
I see Chan’s slide everywhere, but cannot find an explanation for selecting the number of trees “depending on datasize”. Does it get any more specific than fewer trees for smaller datasets?
Thank u jason for curating such an awesome list of articles.
I have a binary classification where positive class is 10 to 20% . Have 50 to 100k data but lot of columns 1000 to 2000 many of them 0( one hot vectors)
My problem is i am getting a very low recall on positive class which is the one i care more about. Tried default sklearn and did a few tweakssimilar to ones above.Any ideas on specific things to try other than undersampling?
how do I restrict predictions to a certain for example 0-1. I am working on a prediction model for a probabilities and Gradient Boost is return numbers lower than 0 and higher than 1.
Hi Jason,
Thanks for this crisp article. I have highly unbalanced data. what exact parameters/Attributes should is tune in GradientBoostingClassifier() and from what value i should start. also i am ok if my Recall value/False Positive number is higher. Please help me with this
The function to measure the quality of a split. Supported criteria are “friedman_mse” for the mean squared error with improvement score by Friedman, “mse” for mean squared error, and “mae” for the mean absolute error. The default value of “friedman_mse” is generally the best as it can provide a better approximation in some cases.
I am struggle to understand the intuition behind this parameter. dont we split trees using gini impurity? the internet also has limited explanation on this.
One small correction: when you write about comparing max leaf nodes and max depth, you wirte “setting the max depth to one minus the maximum leaf nodes” but it shall be otherwise around according to the citation provided below this text, i.e. “k-1”
Hi Dear,
thanks for this post. please, I have 2 questions
1- for multiclass classification is GBC work in one vs rest? so if I have 3 classes and 100 trees so the total trees of the model are 300?
2- please could you tell me how the condition is done at each node and how chooses which feature at first? I know the decision tree depends on gini or entropy calculation but here the matter is difficult for me.










Thanks
I’m glad you found the post useful.
Thanks for providing integrated material of gradient boosting
I’m glad you found it useful.
can you please elaborate rare events (from Owen Zhang Table of Suggestions for Hyperparameter Tuning of XGBoost Table) and event rate (from Owen Zhang Suggestions for Tuning XGBoost)? This page looks very informative and useful for everyone..
Hi Jason,
Hope you are well. Thanks for the amazing information on machine learning techniques. Currently I’m working on the GBM in R and I’m trying to figureout the best parameters for our GBM model. However, based on what I found and read and also based on your information about the GBM parameter tuning, the lower learning rate should result in a better AUC. However, I have checked this with the piece of code below:
gbm1 h2o.auc(gbm1)
[1] 0.8592122
> gbm2 h2o.auc(gbm2)
[1] 0.8628086
> gbm3 h2o.auc(gbm3)
[1] 0.8628086
************************************************************************************************************************************************************************************************************************************
The difference between gbm1 and gbm2 in their learn_rate. GBM 2 has bigger learn_rate than the first one but ends to a better result. It made me very confused about what I have read and I would appreciate if you could please help me to understand the problem.
Perhaps you are hitting the wall in terms of what there is to learn in your data.
See this post for more general ideas:
https://machinelearningmastery.com/machine-learning-performance-improvement-cheat-sheet/
I see Chan’s slide everywhere, but cannot find an explanation for selecting the number of trees “depending on datasize”. Does it get any more specific than fewer trees for smaller datasets?
Nope. Heuristics like this are the best we can do. That and copying other reported configurations.
Trial and error is the “art” of applied machine learning. Develop a robust test harness and try lots of different configurations.
Thank you for your good posting.
I have a one question.
You said that the important parameters in xgboost are number of trees, tree depth, step size.
In xgboost, What parameters are number of trees, tree depth, step size??
I think that tree depth is max_depth parameter and step size is eta. is it right?
Then, what’s the parameter of number of trees?
See this post for tuning the parameters:
https://machinelearningmastery.com/tune-number-size-decision-trees-xgboost-python/
Thank u jason for curating such an awesome list of articles.
I have a binary classification where positive class is 10 to 20% . Have 50 to 100k data but lot of columns 1000 to 2000 many of them 0( one hot vectors)
My problem is i am getting a very low recall on positive class which is the one i care more about. Tried default sklearn and did a few tweakssimilar to ones above.Any ideas on specific things to try other than undersampling?
Perhaps this post will give you some ideas:
https://machinelearningmastery.com/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/
how do I restrict predictions to a certain for example 0-1. I am working on a prediction model for a probabilities and Gradient Boost is return numbers lower than 0 and higher than 1.
Perhaps model your problem as a classification problem and predict probabilities?
Very nice article. Thanks I’d like to make a cheatsheet using those findings
Thanks.
Hi Jason,
Thanks for this crisp article. I have highly unbalanced data. what exact parameters/Attributes should is tune in GradientBoostingClassifier() and from what value i should start. also i am ok if my Recall value/False Positive number is higher. Please help me with this
I have some suggestions here that might help:
https://machinelearningmastery.com/tactics-to-combat-imbalanced-classes-in-your-machine-learning-dataset/
Hi Jason,
Many thanks for this article! in sklearn GradientBoostingClassifier, there is this parameter:
“criterion”: string, optional (default=”friedman_mse”)
The function to measure the quality of a split. Supported criteria are “friedman_mse” for the mean squared error with improvement score by Friedman, “mse” for mean squared error, and “mae” for the mean absolute error. The default value of “friedman_mse” is generally the best as it can provide a better approximation in some cases.
I am struggle to understand the intuition behind this parameter. dont we split trees using gini impurity? the internet also has limited explanation on this.
many thanks for your help
best,
sam
link: https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html#sklearn.ensemble.GradientBoostingClassifier
Not sure off hand, I’d recommend the paper on the topic or one of the good books like ISLR or ESL.
Hi Jason, really good post!
One small correction: when you write about comparing max leaf nodes and max depth, you wirte “setting the max depth to one minus the maximum leaf nodes” but it shall be otherwise around according to the citation provided below this text, i.e. “k-1”
Thanks. Fixed.
Hi Dear,
thanks for this post. please, I have 2 questions
1- for multiclass classification is GBC work in one vs rest? so if I have 3 classes and 100 trees so the total trees of the model are 300?
2- please could you tell me how the condition is done at each node and how chooses which feature at first? I know the decision tree depends on gini or entropy calculation but here the matter is difficult for me.
I believe gradient boosting can model multi-class classification directly (e.g. trees that output multiple class labels).
Features are selected based on the chosen tree construction metric – depends on the implementation.
1- see
https://scikit-learn.org/stable/modules/multiclass.html
and this
https://stats.stackexchange.com/questions/459432/multiclass-gradient-boosting-how-to-derive-the-initial-guess-how-to-predict-a
2-please could you explain what do you mean by tree construction metric and it will be kind of you if you have a good tutorial about it.
Thanks for sharing, you can also see some examples of the usage of these classes here:
https://machinelearningmastery.com/one-vs-rest-and-one-vs-one-for-multi-class-classification/
Tree construction metrics are typically gini or entropy.
I think the default learning_rate in python is also 0.3 (that’s what I see as out of box XGBoost’s parameters).
Hi Udit…You may find the following of interest:
https://machinelearningmastery.com/tune-learning-rate-for-gradient-boosting-with-xgboost-in-python/