Light Gradient Boosted Machine, or LightGBM for short, is an open-source library that provides an efficient and effective implementation of the gradient boosting algorithm.
LightGBM extends the gradient boosting algorithm by adding a type of automatic feature selection as well as focusing on boosting examples with larger gradients. This can result in a dramatic speedup of training and improved predictive performance.
As such, LightGBM has become a de facto algorithm for machine learning competitions when working with tabular data for regression and classification predictive modeling tasks. As such, it owns a share of the blame for the increased popularity and wider adoption of gradient boosting methods in general, along with Extreme Gradient Boosting (XGBoost).
In this tutorial, you will discover how to develop Light Gradient Boosted Machine ensembles for classification and regression.
After completing this tutorial, you will know:
Light Gradient Boosted Machine (LightGBM) is an efficient open-source implementation of the stochastic gradient boosting ensemble algorithm.
How to develop LightGBM ensembles for classification and regression with the scikit-learn API.
How to explore the effect of LightGBM model hyperparameters on model performance.
Kick-start your project with my new book Ensemble Learning Algorithms With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
How to Develop a Light Gradient Boosted Machine (LightGBM) Ensemble Photo by GPA Photo Archive, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
Light Gradient Boosted Machine Algorithm
LightGBM Scikit-Learn API
LightGBM Ensemble for Classification
LightGBM Ensemble for Regression
LightGBM Hyperparameters
Explore Number of Trees
Explore Tree Depth
Explore Learning Rate
Explore Boosting Type
Light Gradient Boosted Machine Algorithm
Gradient boosting refers to a class of ensemble machine learning algorithms that can be used for classification or regression predictive modeling problems.
Ensembles are constructed from decision tree models. Trees are added one at a time to the ensemble and fit to correct the prediction errors made by prior models. This is a type of ensemble machine learning model referred to as boosting.
Models are fit using any arbitrary differentiable loss function and gradient descent optimization algorithm. This gives the technique its name, “gradient boosting,” as the loss gradient is minimized as the model is fit, much like a neural network.
Light Gradient Boosted Machine, or LightGBM for short, is an open-source implementation of gradient boosting designed to be efficient and perhaps more effective than other implementations.
Gradient-based One-Side Sampling, or GOSS for short, is a modification to the gradient boosting method that focuses attention on those training examples that result in a larger gradient, in turn speeding up learning and reducing the computational complexity of the method.
With GOSS, we exclude a significant proportion of data instances with small gradients, and only use the rest to estimate the information gain. We prove that, since the data instances with larger gradients play a more important role in the computation of information gain, GOSS can obtain quite accurate estimation of the information gain with a much smaller data size.
Exclusive Feature Bundling, or EFB for short, is an approach for bundling sparse (mostly zero) mutually exclusive features, such as categorical variable inputs that have been one-hot encoded. As such, it is a type of automatic feature selection.
… we bundle mutually exclusive features (i.e., they rarely take nonzero values simultaneously), to reduce the number of features.
Together, these two changes can accelerate the training time of the algorithm by up to 20x. As such, LightGBM may be considered gradient boosting decision trees (GBDT) with the addition of GOSS and EFB.
We call our new GBDT implementation with GOSS and EFB LightGBM. Our experiments on multiple public datasets show that, LightGBM speeds up the training process of conventional GBDT by up to over 20 times while achieving almost the same accuracy
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
LightGBM Scikit-Learn API
LightGBM can be installed as a standalone library and the LightGBM model can be developed using the scikit-learn API.
The first step is to install the LightGBM library, if it is not already installed. This can be achieved using the pip python package manager on most platforms; for example:
1
sudo pip install lightgbm
You can then confirm that the LightGBM library was installed correctly and can be used by running the following script.
1
2
3
# check lightgbm version
import lightgbm
print(lightgbm.__version__)
Running the script will print your version of the LightGBM library you have installed.
Your version should be the same or higher. If not, you must upgrade your version of the LightGBM library.
1
2.3.1
If you require specific instructions for your development environment, see the tutorial:
The LightGBM library has its own custom API, although we will use the method via the scikit-learn wrapper classes: LGBMRegressor and LGBMClassifier. This will allow us to use the full suite of tools from the scikit-learn machine learning library to prepare data and evaluate models.
Both models operate the same way and take the same arguments that influence how the decision trees are created and added to the ensemble.
Randomness is used in the construction of the model. This means that each time the algorithm is run on the same data, it will produce a slightly different model.
When using machine learning algorithms that have a stochastic learning algorithm, it is good practice to evaluate them by averaging their performance across multiple runs or repeats of cross-validation. When fitting a final model, it may be desirable to either increase the number of trees until the variance of the model is reduced across repeated evaluations, or to fit multiple final models and average their predictions.
Let’s take a look at how to develop a LightGBM ensemble for both classification and regression.
LightGBM Ensemble for Classification
In this section, we will look at using LightGBM for a classification problem.
First, we can use the make_classification() function to create a synthetic binary classification problem with 1,000 examples and 20 input features.
Running the example creates the dataset and summarizes the shape of the input and output components.
1
(1000, 20) (1000,)
Next, we can evaluate a LightGBM algorithm on this dataset.
We will evaluate the model using repeated stratified k-fold cross-validation with three repeats and 10 folds. We will report the mean and standard deviation of the accuracy of the model across all repeats and folds.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# evaluate lightgbm algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
Running the example reports the mean and standard deviation accuracy of the model.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see the LightGBM ensemble with default hyperparameters achieves a classification accuracy of about 92.5 percent on this test dataset.
1
Accuracy: 0.925 (0.031)
We can also use the LightGBM model as a final model and make predictions for classification.
First, the LightGBM ensemble is fit on all available data, then the predict() function can be called to make predictions on new data.
The example below demonstrates this on our binary classification dataset.
1
2
3
4
5
6
7
8
9
10
11
12
13
# make predictions using lightgbm for classification
Running the example fits the LightGBM ensemble model on the entire dataset and is then used to make a prediction on a new row of data, as we might when using the model in an application.
1
Predicted Class: 1
Now that we are familiar with using LightGBM for classification, let’s look at the API for regression.
LightGBM Ensemble for Regression
In this section, we will look at using LightGBM for a regression problem.
First, we can use the make_regression() function to create a synthetic regression problem with 1,000 examples and 20 input features.
Running the example creates the dataset and summarizes the shape of the input and output components.
1
(1000, 20) (1000,)
Next, we can evaluate a LightGBM algorithm on this dataset.
As we did with the last section, we will evaluate the model using repeated k-fold cross-validation, with three repeats and 10 folds. We will report the mean absolute error (MAE) of the model across all repeats and folds. The scikit-learn library makes the MAE negative so that it is maximized instead of minimized. This means that larger negative MAE are better and a perfect model has a MAE of 0.
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# evaluate lightgbm ensemble for regression
from numpy import mean
from numpy import std
from sklearn.datasets import make_regression
from sklearn.model_selection import cross_val_score
Running the example reports the mean and standard deviation accuracy of the model.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see the LightGBM ensemble with default hyperparameters achieves a MAE of about 60.
1
MAE: -60.004 (2.887)
We can also use the LightGBM model as a final model and make predictions for regression.
First, the LightGBM ensemble is fit on all available data, then the predict() function can be called to make predictions on new data.
The example below demonstrates this on our regression dataset.
1
2
3
4
5
6
7
8
9
10
11
12
13
# gradient lightgbm for making predictions for regression
Running the example fits the LightGBM ensemble model on the entire dataset and is then used to make a prediction on a new row of data, as we might when using the model in an application.
1
Prediction: 52
Now that we are familiar with using the scikit-learn API to evaluate and use LightGBM ensembles, let’s look at configuring the model.
LightGBM Hyperparameters
In this section, we will take a closer look at some of the hyperparameters you should consider tuning for the LightGBM ensemble and their effect on model performance.
There are many hyperparameters we can look at for LightGBM, although in this case, we will look at the number of trees and tree depth, the learning rate, and the boosting type.
For good general advice on tuning LightGBM hyperparameters, see the documentation:
An important hyperparameter for the LightGBM ensemble algorithm is the number of decision trees used in the ensemble.
Recall that decision trees are added to the model sequentially in an effort to correct and improve upon the predictions made by prior trees. As such, more trees are often better.
The number of trees can be set via the “n_estimators” argument and defaults to 100.
The example below explores the effect of the number of trees with values between 10 to 5,000.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# explore lightgbm number of trees effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
Running the example first reports the mean accuracy for each configured number of decision trees.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
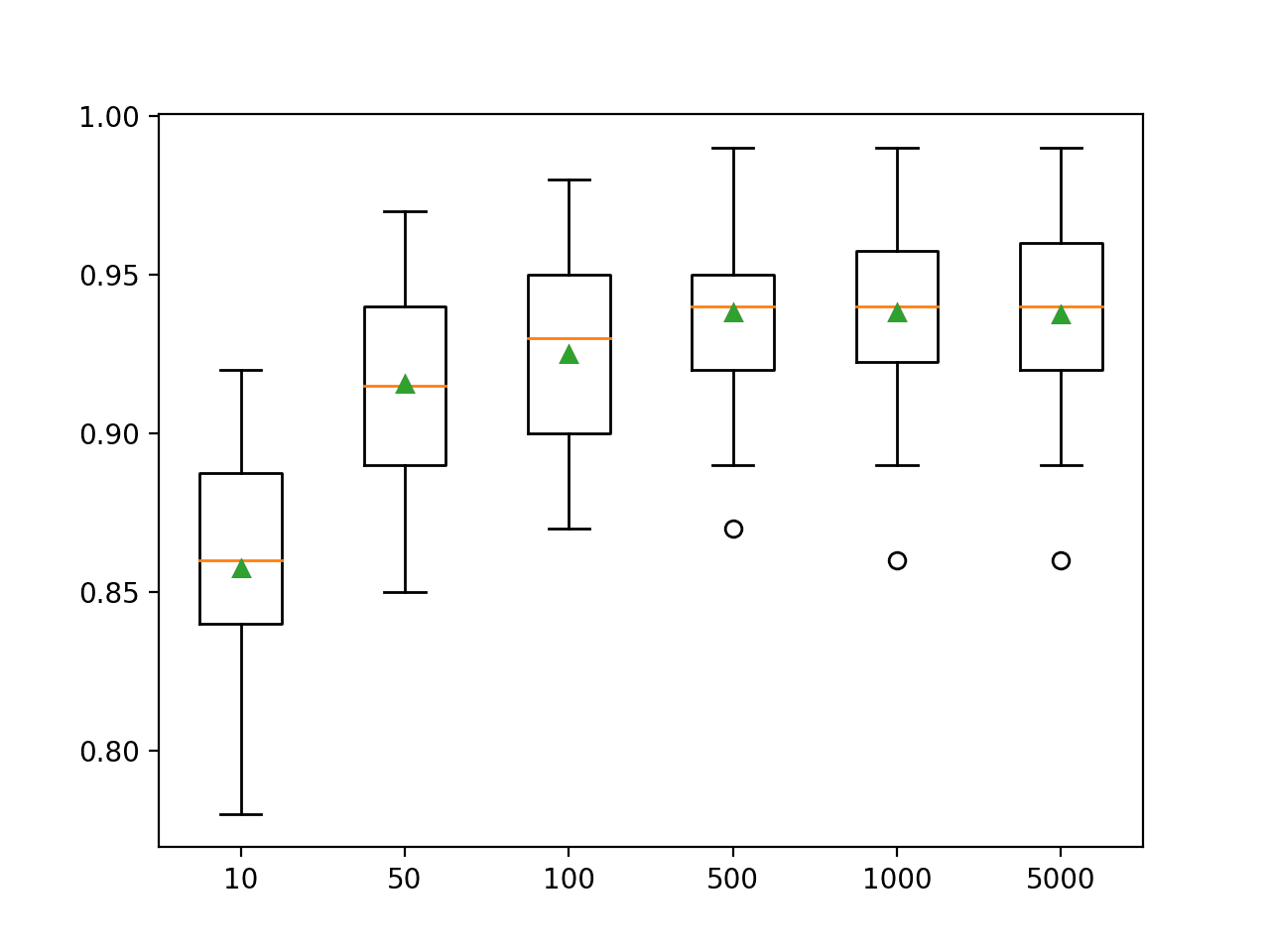
In this case, we can see that that performance improves on this dataset until about 500 trees, after which performance appears to level off.
1
2
3
4
5
6
>10 0.857 (0.033)
>50 0.916 (0.032)
>100 0.925 (0.031)
>500 0.938 (0.026)
>1000 0.938 (0.028)
>5000 0.937 (0.028)
A box and whisker plot is created for the distribution of accuracy scores for each configured number of trees.
We can see the general trend of increasing model performance and ensemble size.
Box Plots of LightGBM Ensemble Size vs. Classification Accuracy
Explore Tree Depth
Varying the depth of each tree added to the ensemble is another important hyperparameter for gradient boosting.
The tree depth controls how specialized each tree is to the training dataset: how general or overfit it might be. Trees are preferred that are not too shallow and general (like AdaBoost) and not too deep and specialized (like bootstrap aggregation).
Gradient boosting generally performs well with trees that have a modest depth, finding a balance between skill and generality.
Tree depth is controlled via the “max_depth” argument and defaults to an unspecified value as the default mechanism for controlling how complex trees are is to use the number of leaf nodes.
There are two main ways to control tree complexity: the max depth of the trees and the maximum number of terminal nodes (leaves) in the tree. In this case, we are exploring the number of leaves so we need to increase the number of leaves to support deeper trees by setting the “num_leaves” argument.
The example below explores tree depths between 1 and 10 and the effect on model performance.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# explore lightgbm tree depth effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
Running the example first reports the mean accuracy for each configured tree depth.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
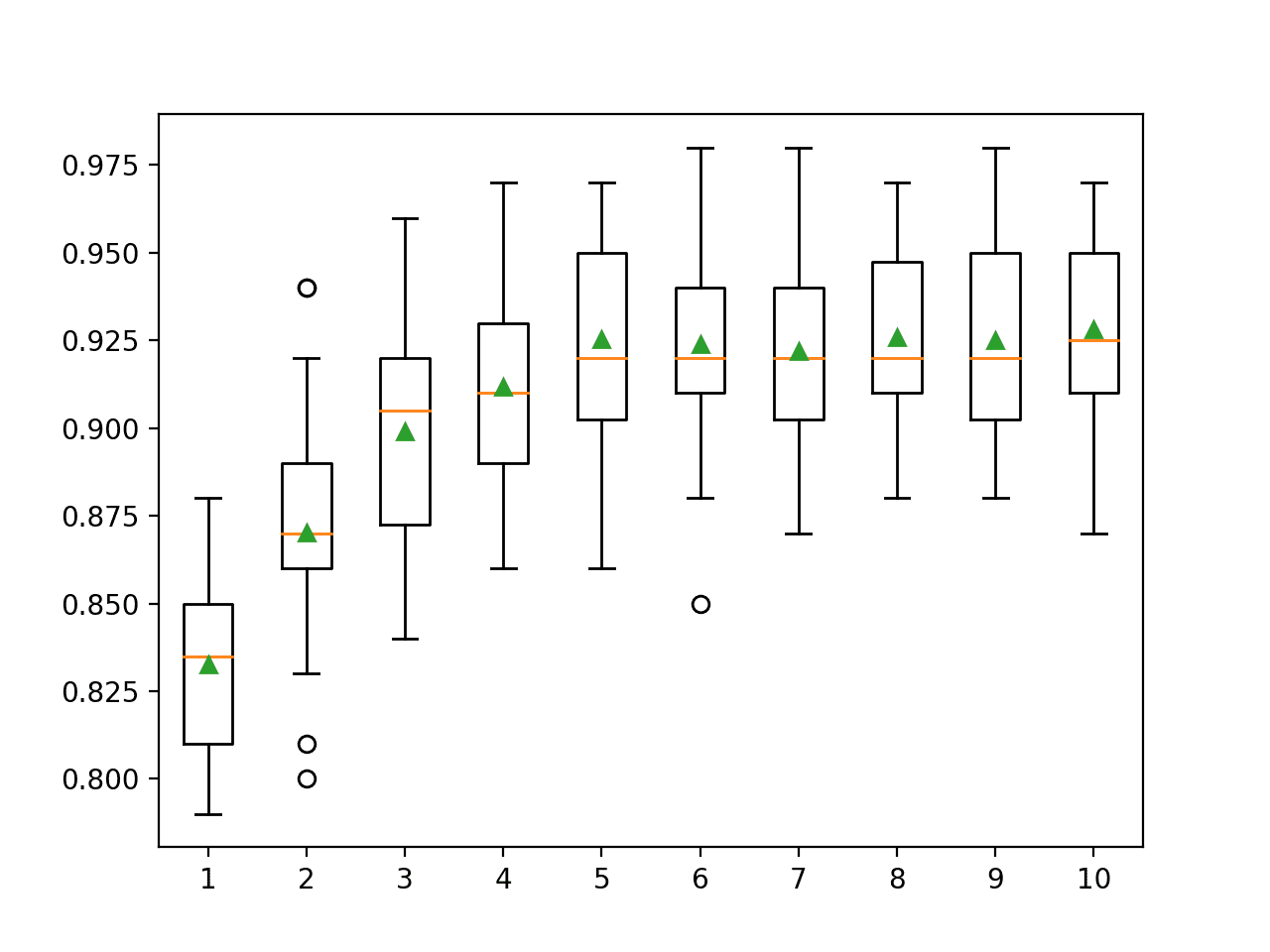
In this case, we can see that performance improves with tree depth, perhaps all the way to 10 levels. It might be interesting to explore even deeper trees.
1
2
3
4
5
6
7
8
9
10
>1 0.833 (0.028)
>2 0.870 (0.033)
>3 0.899 (0.032)
>4 0.912 (0.026)
>5 0.925 (0.031)
>6 0.924 (0.029)
>7 0.922 (0.027)
>8 0.926 (0.027)
>9 0.925 (0.028)
>10 0.928 (0.029)
A box and whisker plot is created for the distribution of accuracy scores for each configured tree depth.
We can see the general trend of increasing model performance with the tree depth to a depth of five levels, after which performance begins to sit reasonably flat.
Box Plots of LightGBM Ensemble Tree Depth vs. Classification Accuracy
Explore Learning Rate
Learning rate controls the amount of contribution that each model has on the ensemble prediction.
Smaller rates may require more decision trees in the ensemble.
The learning rate can be controlled via the “learning_rate” argument and defaults to 0.1.
The example below explores the learning rate and compares the effect of values between 0.0001 and 1.0.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# explore lightgbm learning rate effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
Running the example first reports the mean accuracy for each configured learning rate.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
In this case, we can see that a larger learning rate results in better performance on this dataset. We would expect that adding more trees to the ensemble for the smaller learning rates would further lift performance.
1
2
3
4
5
>0.0001 0.800 (0.038)
>0.0010 0.811 (0.035)
>0.0100 0.859 (0.035)
>0.1000 0.925 (0.031)
>1.0000 0.928 (0.025)
A box and whisker plot is created for the distribution of accuracy scores for each configured learning rate.
We can see the general trend of increasing model performance with the increase in learning rate all the way to the large values of 1.0.
Box Plot of LightGBM Learning Rate vs. Classification Accuracy
Explore Boosting Type
A feature of LightGBM is that it supports a number of different boosting algorithms, referred to as boosting types.
The boosting type can be specified via the “boosting_type” argument and take a string to specify the type. The options include:
‘gbdt‘: Gradient Boosting Decision Tree (GDBT).
‘dart‘: Dropouts meet Multiple Additive Regression Trees (DART).
‘goss‘: Gradient-based One-Side Sampling (GOSS).
The default is GDBT, which is the classical gradient boosting algorithm.
DART is described in the 2015 paper titled “DART: Dropouts meet Multiple Additive Regression Trees” and, as its name suggests, adds the concept of dropout from deep learning to the Multiple Additive Regression Trees (MART) algorithm, a precursor to gradient boosting decision trees.
This algorithm is known by many names, including Gradient TreeBoost, boosted trees, and Multiple Additive Regression Trees (MART). We use the latter to refer to this algorithm.
GOSS was introduced with the LightGBM paper and library. The approach seeks to only use instances that result in a large error gradient to update the model and drop the rest.
… we exclude a significant proportion of data instances with small gradients, and only use the rest to estimate the information gain.
Running the example first reports the mean accuracy for each configured boosting type.
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
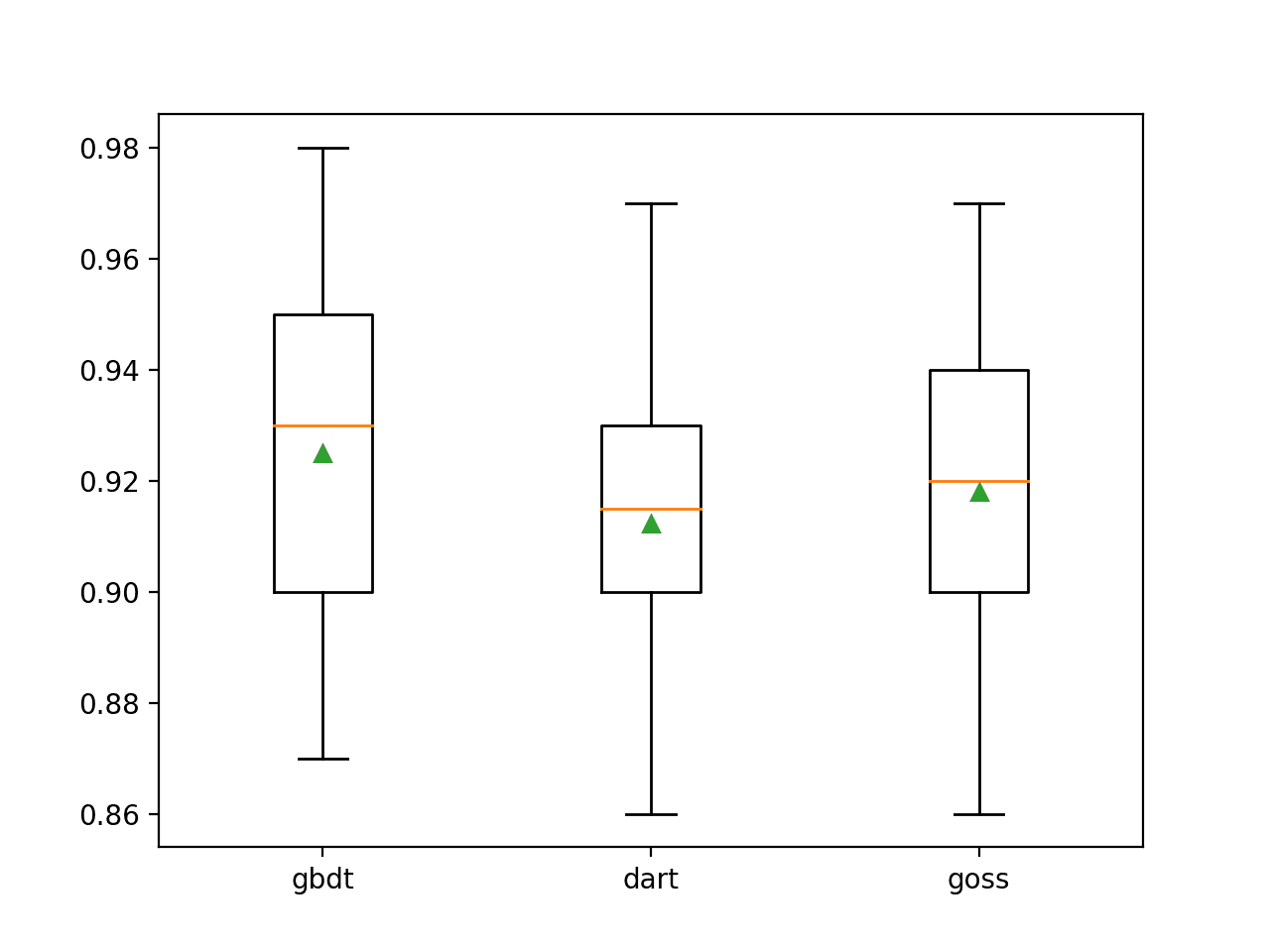
In this case, we can see that the default boosting method performed better than the other two techniques that were evaluated.
1
2
3
>gbdt 0.925 (0.031)
>dart 0.912 (0.028)
>goss 0.918 (0.027)
A box and whisker plot is created for the distribution of accuracy scores for each configured boosting method, allowing the techniques to be compared directly.
Box Plots of LightGBM Boosting Type vs. Classification Accuracy
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Hi Jason,
Thanks for the wonderful paper.
One question regarding max_depth vs num_leaves
MaxDepth = [2,3,4,5,6,7,8,9,10]
NumLeaves = [2 ** i for i in MaxDepth]
NumLeaves = [4, 8, 16, 32, 64, 128, 256, 512, 1024]
num_leaves higher values may cause overfitting right,
also getting warning as
No further splits with positive gain, best gain: -inf
may i know how to set num_leaves optimally for smaller and larger datasets?
Thanks
Hi dear.. i want to know the above mentioned algorithm we achieved accuracy.. but how we get values using confusion matrix…
I dnt know how i can do.
Model.fit(X) if i used whatever model name in above case lightgbm etc.
After that
Ypred = model.predict (X)
Confusionmatrix (y, Pred)
It provides me total reuslt like no error in values..
So kindly tell me how can i make confusion matrix using cross validation technique instead of test train split and with only X dependent and y outcome variable etc.
Sir, I want to know the difference between light GBM and Histogram Gradient Boosting With LightGBM, because I have read in many places that light gbm uses histogram based approach. So, I am confused, if light GBM automatically uses the concept of binning in its training process then what is the difference between histogram baed light GBM?
Hi,
Thanks for this article, but there is something I can’t understand, you already explained the different boosting types of LGBM and you said that ‘The default is GBDT, which is the classical gradient boosting algorithm.’
So is using LGBM with ‘gbdt’ the same as using the ‘Gradient Boosting’ class of sklearn, or is it interesting to compare their results? (Because I wanna implement both : LGBM and GBM but I’m not sure if it’s a good idea if I just keep the default parameter for lgbm)
Also, the power of LGBM is related to GOSS and EFB, but since those two are not used in the default parameter, then we are not really using LGBM right?
Hi Sir, Thank you for the amazing explanation of every aspect of Light GBM, while explaining GOSS you said that samples giving small gradient are excluded as they result small info gain. Can you pls let me know the meaning of small gradient and large gradient with some example. In little laymen language it would be easy to understand.
Gradient is another name for slope. You use it to measure how much change you can achieve in the objective function if you change the input. A large gradient means the objective function changed a lot, or your input can drive the function a lot. Input with a small gradient, on contrary, possibly can’t make any impact to the function. Therefore if everything goes with a cost, we want to focus on those with a large gradient because it is the most cost effective.
Hi Jason, Many thanks for this article. Can you clear something up about LightGBM and predict_proba. My understanding (correct me if wrong) is that with Light you only get back raw scores and not probabilities as you would with say GBM or XGboost. If this is the case what would be the route to turn them into prob’s









Hi Jason,
Thanks for the wonderful paper.
One question regarding max_depth vs num_leaves
MaxDepth = [2,3,4,5,6,7,8,9,10]
NumLeaves = [2 ** i for i in MaxDepth]
NumLeaves = [4, 8, 16, 32, 64, 128, 256, 512, 1024]
num_leaves higher values may cause overfitting right,
also getting warning as
No further splits with positive gain, best gain: -inf
may i know how to set num_leaves optimally for smaller and larger datasets?
Thanks
Perhaps leave it at the default of 31.
Hi Jason, nice article as always!
Is there any article on catboost?
Can’t seem to find one.
Thanks.
I have a short example of catboost here:
https://machinelearningmastery.com/gradient-boosting-with-scikit-learn-xgboost-lightgbm-and-catboost/
Hi dear.. i want to know the above mentioned algorithm we achieved accuracy.. but how we get values using confusion matrix…
I dnt know how i can do.
Model.fit(X) if i used whatever model name in above case lightgbm etc.
After that
Ypred = model.predict (X)
Confusionmatrix (y, Pred)
It provides me total reuslt like no error in values..
So kindly tell me how can i make confusion matrix using cross validation technique instead of test train split and with only X dependent and y outcome variable etc.
This will help you to calculate a confusion matrix:
https://machinelearningmastery.com/confusion-matrix-machine-learning/
Hi Jason,
Thanks for the post. What I’m wondering is there any resources for the “Light Gradient” term, especially from Microsoft?
Sorry, I don’t understand. What do you mean by “Light Gradient term”?
Hi Jason, great document.
Can you tell me the difference between a max_depth positive or negative?
By default is -1
I believe -1 means no limit – stop when you run out of data.
Sir, I want to know the difference between light GBM and Histogram Gradient Boosting With LightGBM, because I have read in many places that light gbm uses histogram based approach. So, I am confused, if light GBM automatically uses the concept of binning in its training process then what is the difference between histogram baed light GBM?
Light GBM is a way of implementing the GBM algorithm.
You can read the specific differences in the section “Light Gradient Boosted Machine Algorithm” in the above tutorial.
Hi,
Thanks for this article, but there is something I can’t understand, you already explained the different boosting types of LGBM and you said that ‘The default is GBDT, which is the classical gradient boosting algorithm.’
So is using LGBM with ‘gbdt’ the same as using the ‘Gradient Boosting’ class of sklearn, or is it interesting to compare their results? (Because I wanna implement both : LGBM and GBM but I’m not sure if it’s a good idea if I just keep the default parameter for lgbm)
Also, the power of LGBM is related to GOSS and EFB, but since those two are not used in the default parameter, then we are not really using LGBM right?
It may be the same “algorithm” although an alternate and perhaps more efficient and/or effective implementation.
Hi Sir, Thank you for the amazing explanation of every aspect of Light GBM, while explaining GOSS you said that samples giving small gradient are excluded as they result small info gain. Can you pls let me know the meaning of small gradient and large gradient with some example. In little laymen language it would be easy to understand.
Gradient is another name for slope. You use it to measure how much change you can achieve in the objective function if you change the input. A large gradient means the objective function changed a lot, or your input can drive the function a lot. Input with a small gradient, on contrary, possibly can’t make any impact to the function. Therefore if everything goes with a cost, we want to focus on those with a large gradient because it is the most cost effective.
Hi Jason, Many thanks for this article. Can you clear something up about LightGBM and predict_proba. My understanding (correct me if wrong) is that with Light you only get back raw scores and not probabilities as you would with say GBM or XGboost. If this is the case what would be the route to turn them into prob’s