The rise in popularity and use of deep learning neural network techniques can be traced back to the innovations in the application of convolutional neural networks to image classification tasks.
Some of the most important innovations have sprung from submissions by academics and industry leaders to the ImageNet Large Scale Visual Recognition Challenge, or ILSVRC. The ILSVRC is an annual computer vision competition developed upon a subset of a publicly available computer vision dataset called ImageNet. As such, the tasks and even the challenge itself is often referred to as the ImageNet Competition.
In this post, you will discover the ImageNet dataset, the ILSVRC, and the key milestones in image classification that have resulted from the competitions.
After reading this post, you will know:
- The ImageNet dataset is a very large collection of human annotated photographs designed by academics for developing computer vision algorithms.
- The ImageNet Large Scale Visual Recognition Challenge, or ILSVRC, is an annual competition that uses subsets from the ImageNet dataset and is designed to foster the development and benchmarking of state-of-the-art algorithms.
- The ILSVRC tasks have led to milestone model architectures and techniques in the intersection of computer vision and deep learning.
Kick-start your project with my new book Deep Learning for Computer Vision, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.

A Gentle Introduction to ImageNet and the Large Scale Visual Recognition Challenge (ILSVRC)
Photo by Tom Hall, some rights reserved.
Overview
This tutorial is divided into three parts; they are:
- ImageNet Dataset
- ImageNet Large Scale Visual Recognition Challenge
- Deep Learning Milestones From ILSVRC
ImageNet Dataset
ImageNet is a large dataset of annotated photographs intended for computer vision research.
The goal of developing the dataset was to provide a resource to promote the research and development of improved methods for computer vision.
We believe that a large-scale ontology of images is a critical resource for developing advanced, large-scale content-based image search and image understanding algorithms, as well as for providing critical training and benchmarking data for such algorithms.
— ImageNet: A Large-Scale Hierarchical Image Database, 2009.
Based on statistics about the dataset recorded on the ImageNet homepage, there are a little more than 14 million images in the dataset, a little more than 21 thousand groups or classes (synsets), and a little more than 1 million images that have bounding box annotations (e.g. boxes around identified objects in the images).
The photographs were annotated by humans using crowdsourcing platforms such as Amazon’s Mechanical Turk.
The project to develop and maintain the dataset was organized and executed by a collocation between academics at Princeton, Stanford, and other American universities.
The project does not own the photographs that make up the images; instead, they are owned by the copyright holders. As such, the dataset is not distributed directly; URLs are provided to the images included in the dataset.
Want Results with Deep Learning for Computer Vision?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
ImageNet Large Scale Visual Recognition Challenge (ILSVRC)
The ImageNet Large Scale Visual Recognition Challenge or ILSVRC for short is an annual competition helped between 2010 and 2017 in which challenge tasks use subsets of the ImageNet dataset.
The goal of the challenge was to both promote the development of better computer vision techniques and to benchmark the state of the art.
The annual challenge focuses on multiple tasks for “image classification” that includes both assigning a class label to an image based on the main object in the photograph and “object detection” that involves localizing objects within the photograph.
ILSVRC annotations fall into one of two categories: (1) image-level annotation of a binary label for the presence or absence of an object class in the image, […] and (2) object-level annotation of a tight bounding box and class label around an object instance in the image
— ImageNet Large Scale Visual Recognition Challenge, 2015.
The general challenge tasks for most years are as follows:
- Image classification: Predict the classes of objects present in an image.
- Single-object localization: Image classification + draw a bounding box around one example of each object present.
- Object detection: Image classification + draw a bounding box around each object present.
More recently, and given the great success in the development of techniques for still photographs, the challenge tasks are changing to more difficult tasks such as labeling videos.
The datasets comprised approximately 1 million images and 1,000 object classes. The datasets used in challenge tasks are sometimes varied (depending on the task) and were released publicly to promote widespread participation from academia and industry.
For each annual challenge, an annotated training dataset was released, along with an unannotated test dataset for which annotations had to be made and submitted to a server for evaluation. Typically, the training dataset was comprised of 1 million images, with 50,000 for a validation dataset and 150,000 for a test set.
The publically released dataset contains a set of manually annotated training images. A set of test images is also released, with the manual annotations withheld. Participants train their algorithms using the training images and then automatically annotate the test images. These predicted annotations are submitted to the evaluation server. Results of the evaluation are revealed at the end of the competition period
— ImageNet Large Scale Visual Recognition Challenge, 2015.
Results were presented at an annual workshop at a computer vision conference to promote the sharing and distribution of successful techniques.
The datasets are still available for each annual challenge, although you must register.
Deep Learning Milestones From ILSVRC
Researchers working on ILSVRC tasks have pushed back the frontier of computer vision research and the methods and papers that describe them are milestones in the fields of computer vision, deep learning, and more broadly in artificial intelligence.
The pace of improvement in the first five years of the ILSVRC was dramatic, perhaps even shocking to the field of computer vision. Success has primarily been achieved by large (deep) convolutional neural networks (CNNs) on graphical processing unit (GPU) hardware, which sparked an interest in deep learning that extended beyond the field out into the mainstream.
State-of-the-art accuracy has improved significantly from ILSVRC2010 to ILSVRC2014, showcasing the massive progress that has been made in large-scale object recognition over the past five years
— ImageNet Large Scale Visual Recognition Challenge, 2015.
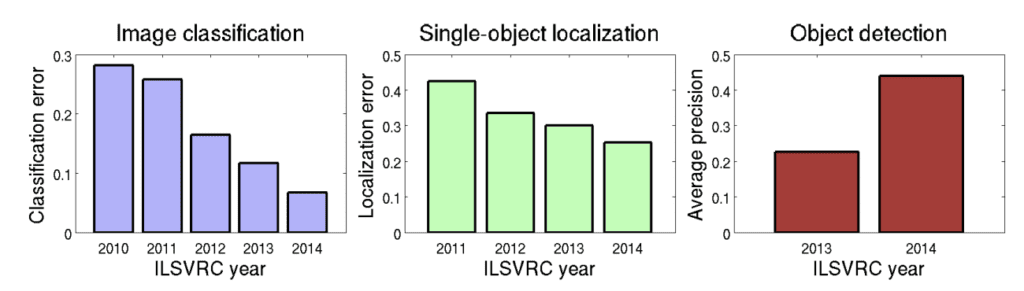
Summary of the Improvement on ILSVRC Tasks Over the First Five Years of the Competition.
Taken from ImageNet Large Scale Visual Recognition Challenge, 2015.
There has been widespread participation in the ILSVRC over the years with many important developments and an enormous number of academic publications. Picking out milestones from so much work is a challenge in an of itself.
Nevertheless, there are techniques, often named for their parent university, research group, or company that stand out and have become staples in the intersecting fields of deep learning and computer vision. The papers that describe the methods have become required reading and the techniques used by the models have become heuristics when using the general techniques in practice.
In this section, we will highlight some of these milestone techniques proposed as part of ILSVRC in which they were introduced and the papers that describe them. The focus will be on image classification tasks.
ILSVRC-2012
AlexNet (SuperVision)
Alex Krizhevsky, et al. from the University of Toronto in their 2012 paper titled “ImageNet Classification with Deep Convolutional Neural Networks” developed a convolutional neural network that achieved top results on the ILSVRC-2010 and ILSVRC-2012 image classification tasks.
These results sparked interest in deep learning in computer vision.
… we trained one of the largest convolutional neural networks to date on the subsets of ImageNet used in the ILSVRC-2010 and ILSVRC-2012 competitions and achieved by far the best results ever reported on these datasets.
— ImageNet Classification with Deep Convolutional Neural Networks, 2012.
ILSVRC-2013
ZFNet (Clarifai)
Matthew Zeiler and Rob Fergus propose a variation of AlexNet generally referred to as ZFNet in their 2013 paper titled “Visualizing and Understanding Convolutional Networks,” a variation of which won the ILSVRC-2013 image classification task.
ILSVRC-2014
Inception (GoogLeNet)
Christian Szegedy, et al. from Google achieved top results for object detection with their GoogLeNet model that made use of the inception module and architecture. This approach was described in their 2014 paper titled “Going Deeper with Convolutions.”
We propose a deep convolutional neural network architecture codenamed Inception, which was responsible for setting the new state of the art for classification and detection in the ImageNet Large-Scale Visual Recognition Challenge 2014 (ILSVRC14).
— Going Deeper with Convolutions, 2014.
VGG
Karen Simonyan and Andrew Zisserman from the Oxford Vision Geometry Group (VGG) achieved top results for image classification and localization with their VGG model. Their approach is described in their 2015 paper titled “Very Deep Convolutional Networks for Large-Scale Image Recognition.”
… we come up with significantly more accurate ConvNet architectures, which not only achieve the state-of-the-art accuracy on ILSVRC classification and localisation tasks, but are also applicable to other image recognition datasets, where they achieve excellent performance even when used as a part of a relatively simple pipelines
— Very Deep Convolutional Networks for Large-Scale Image Recognition, 2015.
ILSVRC-2015
ResNet (MSRA)
Kaiming He, et al. from Microsoft Research achieved top results for object detection and object detection with localization tasks with their Residual Network or ResNet described in their 2015 paper titled “Deep Residual Learning for Image Recognition.”
An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task.
— Deep Residual Learning for Image Recognition, 2015.
Did I miss an important milestone?
Let me know in the comments below.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Papers
- ImageNet: A Large-Scale Hierarchical Image Database, 2009.
- ImageNet Large Scale Visual Recognition Challenge, 2015.
- ImageNet Classification with Deep Convolutional Neural Networks, 2012.
- Visualizing and Understanding Convolutional Networks, 2013.
- Going Deeper with Convolutions, 2014.
- Very Deep Convolutional Networks for Large-Scale Image Recognition, 2015.
- Deep Residual Learning for Image Recognition, 2015.
Articles
- ImageNet, Wikipedia.
- ImageNet Homepage
- Large Scale Visual Recognition Challenge (ILSVRC) Homepage
- Stanford Vision Lab
Summary
In this post, you discovered the ImageNet dataset, the ILSVRC competitions, and the key milestones in image classification that have resulted from the competitions.
Specifically, you learned:
- The ImageNet dataset is a very large collection of human annotated photographs designed by academics for developing computer vision algorithms.
- The ImageNet Large Scale Visual Recognition Challenge, or ILSVRC, is an annual competition that uses subsets from the ImageNet dataset and is designed to foster the development and benchmarking of state-of-the-art algorithms.
- The ILSVRC tasks have led to milestone model architectures and techniques in the intersection of computer vision and deep learning.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
Develop Deep Learning Models for Vision Today!

Develop Your Own Vision Models in Minutes
...with just a few lines of python code
Discover how in my new Ebook:
Deep Learning for Computer Vision
It provides self-study tutorials on topics like:
classification, object detection (yolo and rcnn), face recognition (vggface and facenet), data preparation and much more...
Finally Bring Deep Learning to your Vision Projects
Skip the Academics. Just Results.






Thank you Jason for that amazing tutorial.
I am asking if there are a challenges made for speech recognition, speech enhancement or any other field that apply deep neural networks for speech?
An other question is, are these arcitectures for CNN successfull also for speech enhancement?
Thank you.
Sorry, I don’t have expertise in speech recognition, I hope to cover it in the future.
Yes the CNN is good on speech recognition, because you can represent the sounds in optimal way such as Fast Fourier Transform and collect data from an image, like the CNN normally do.
Thanks for the nice tutorial.
I’m curious about how they split the data between training, test, and validation?
Thanks again.
Typically a random sample.
Great Tutorial, as always, Jason! Do you know by any chance that why the organizers have stopped holding the challenge and how we can now assess which of new models coming out after 2017 are the best?
Good question, you can see why they stopped/moved on here:
http://image-net.org/challenges/beyond_ilsvrc
And more here:
http://image-net.org/update-sep-17-2019
Can you please post details of who won the ILSVRC in next years?
Those competitions were discontinued and new tasks took their place.
I have heard that the competition was taking place from 2010 to 2017.In your article,some of these years are not mentioned.Can you please give me information about,who won in those years and please let me know if some other similar competitions are taking place(like ILSVRC).ImageNet generally conduct competition in 3 Category(Classification,Detection and Localisation),So could you please make it clear like who won in each category…
Yes, you can access this form the links in the “further reading” section.