The XGBoost library for gradient boosting uses is designed for efficient multi-core parallel processing.
This allows it to efficiently use all of the CPU cores in your system when training.
In this post you will discover the parallel processing capabilities of the XGBoost in Python.
After reading this post you will know:
- How to confirm that XGBoost multi-threading support is working on your system.
- How to evaluate the effect of increasing the number of threads on XGBoost.
- How to get the most out of multithreaded XGBoost when using cross validation and grid search.
Kick-start your project with my new book XGBoost With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
- Update Jan/2017: Updated to reflect changes in scikit-learn API version 0.18.1.

How to Best Tune Multithreading Support for XGBoost in Python
Photo by Nicholas A. Tonelli, some rights reserved.
Need help with XGBoost in Python?
Take my free 7-day email course and discover xgboost (with sample code).
Click to sign-up now and also get a free PDF Ebook version of the course.
Problem Description: Otto Dataset
In this tutorial we will use the Otto Group Product Classification Challenge dataset.
This dataset is available from Kaggle (you will need to sign-up to Kaggle to be able to download this dataset). You can download the training dataset train.zip from the Data page and place the unzipped trian.csv file into your working directory.
This dataset describes the 93 obfuscated details of more than 61,000 products grouped into 10 product categories (e.g. fashion, electrons, etc.). Input attributes are counts of different events of some kind.
The goal is to make predictions for new products as an array of probabilities for each of the 10 categories and models are evaluated using multiclass logarithmic loss (also called cross entropy).
This competition completed in May 2015 and this dataset is a good challenge for XGBoost because of the nontrivial number of examples and the difficulty of the problem and the fact that little data preparation is required (other than encoding the string class variables as integers).
Impact of the Number of Threads
XGBoost is implemented in C++ to explicitly make use of the OpenMP API for parallel processing.
The parallelism in gradient boosting can be implemented in the construction of individual trees, rather than in creating trees in parallel like random forest. This is because in boosting, trees are added to the model sequentially. The speed of XGBoost is both in adding parallelism in the construction of individual trees, and in the efficient preparation of the input data to aid in the speed up in the construction of trees.
Depending on your platform, you may need to compile XGBoost specifically to support multithreading. See the XGBoost installation instructions for more details.
The XGBClassifier and XGBRegressor wrapper classes for XGBoost for use in scikit-learn provide the nthread parameter to specify the number of threads that XGBoost can use during training.
By default this parameter is set to -1 to make use of all of the cores in your system.
|
1 |
model = XGBClassifier(nthread=-1) |
Generally, you should get multithreading support for your XGBoost installation without any extra work.
Depending on your Python environment (e.g. Python 3) you may need to explicitly enable multithreading support for XGBoost. The XGBoost library provides an example if you need help.
You can confirm that XGBoost multi-threading support is working by building a number of different XGBoost models, specifying the number of threads and timing how long it takes to build each model. The trend will both show you that multi-threading support is enabled and give you an indication of the effect it has when building models.
For example, if your system has 4 cores, you can train 8 different models and time how long in seconds it takes to create each, then compare the times.
|
1 2 3 4 5 6 7 8 9 10 |
# evaluate the effect of the number of threads results = [] num_threads = [1, 2, 3, 4] for n in num_threads: start = time.time() model = XGBClassifier(nthread=n) model.fit(X_train, y_train) elapsed = time.time() - start print(n, elapsed) results.append(elapsed) |
We can use this approach on the Otto dataset. The full example is provided below for completeness.
You can change the num_threads array to meet the number of cores on your system.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# Otto, tune number of threads from pandas import read_csv from xgboost import XGBClassifier from sklearn.preprocessing import LabelEncoder import time from matplotlib import pyplot # load data data = read_csv('train.csv') dataset = data.values # split data into X and y X = dataset[:,0:94] y = dataset[:,94] # encode string class values as integers label_encoded_y = LabelEncoder().fit_transform(y) # evaluate the effect of the number of threads results = [] num_threads = [1, 2, 3, 4] for n in num_threads: start = time.time() model = XGBClassifier(nthread=n) model.fit(X, label_encoded_y) elapsed = time.time() - start print(n, elapsed) results.append(elapsed) # plot results pyplot.plot(num_threads, results) pyplot.ylabel('Speed (seconds)') pyplot.xlabel('Number of Threads') pyplot.title('XGBoost Training Speed vs Number of Threads') pyplot.show() |
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running this example summarizes the execution time in seconds for each configuration.
|
1 2 3 4 |
(1, 115.51652717590332) (2, 62.7727689743042) (3, 46.042901039123535) (4, 40.55334496498108) |
A plot of these timings is provided below.
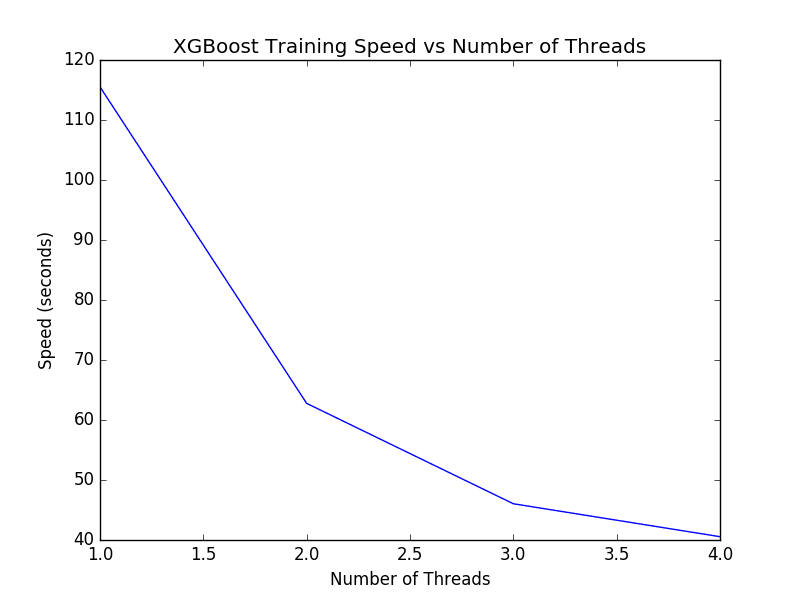
XGBoost Tune Number of Threads for Single Model
We can see a nice trend in the decrease in execution time as the number of threads is increased.
If you do not see an improvement in running time for each new thread, you may want to investigate how to enable multithreading support in XGBoost as part of your install or at runtime.
We can run the same code on a machine with a lot more cores. The large Amazon Web Services EC2 instance is reported to have 32 cores. We can adapt the above code to time how long it takes to train the model with 1 to 32 cores. The results are plotted below.
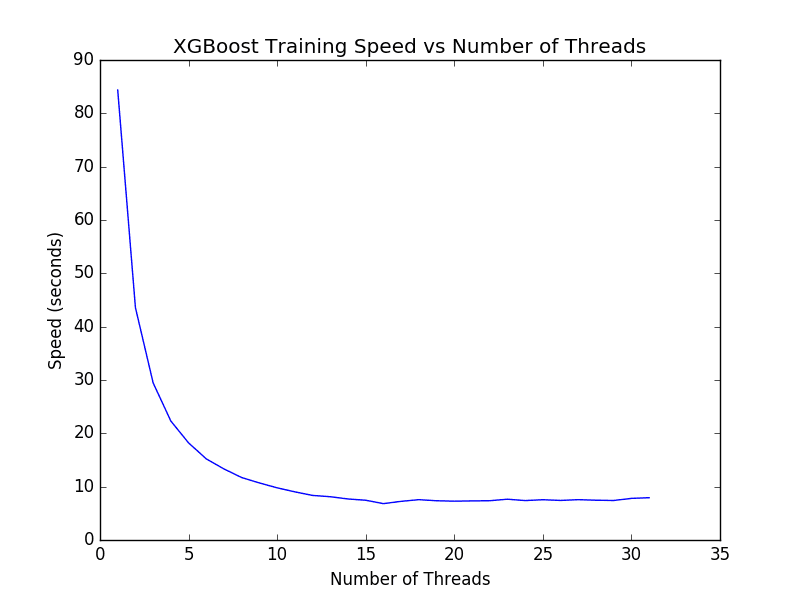
XGBoost Time to Train Model on 1 to 32 Cores
It is interesting to note that we do not see much improvement beyond 16 threads (at about 7 seconds). I expect the reason for this is that the Amazon instance only provides 16 cores in hardware and the additional 16 cores are available by hyperthreading. The results suggest that if you have a machine with hyperthreading, you may want to set num_threads to equal the number of physical CPU cores in your machine.
The low-level optimized implementation of XGBoost with OpenMP squeezes every last cycle out of a large machine like this.
Parallelism When Cross Validating XGBoost Models
The k-fold cross validation support in scikit-learn also supports multithreading.
For example, the n_jobs argument on the cross_val_score() function used to evaluate a model on a dataset using k-fold cross validation allows you to specify the number of parallel jobs to run.
By default, this is set to 1, but can be set to -1 to use all of the CPU cores on your system, which is good practice. For example:
|
1 |
results = cross_val_score(model, X, label_encoded_y, cv=kfold, scoring='log_loss', n_jobs=-1, verbose=1) |
This raises the question as to how cross validation should be configured:
- Disable multi-threading support in XGBoost and allow cross validation to run on all cores.
- Disable multi-threading support in cross validation and allow XGBoost to run on all cores.
- Enable multi-threading support for both XGBoost and Cross validation.
We can get an answer to this question by simply timing how long it takes to evaluate the model in each circumstance.
In the example below we use 10 fold cross validation to evaluate the default XGBoost model on the Otto training dataset. Each of the above scenarios is evaluated and the time taken to evaluate the model is reported.
The full code example is provided below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# Otto, parallel cross validation from pandas import read_csv from xgboost import XGBClassifier from sklearn.model_selection import StratifiedKFold from sklearn.model_selection import cross_val_score from sklearn.preprocessing import LabelEncoder import time # load data data = read_csv('train.csv') dataset = data.values # split data into X and y X = dataset[:,0:94] y = dataset[:,94] # encode string class values as integers label_encoded_y = LabelEncoder().fit_transform(y) # prepare cross validation kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7) # Single Thread XGBoost, Parallel Thread CV start = time.time() model = XGBClassifier(nthread=1) results = cross_val_score(model, X, label_encoded_y, cv=kfold, scoring='neg_log_loss', n_jobs=-1) elapsed = time.time() - start print("Single Thread XGBoost, Parallel Thread CV: %f" % (elapsed)) # Parallel Thread XGBoost, Single Thread CV start = time.time() model = XGBClassifier(nthread=-1) results = cross_val_score(model, X, label_encoded_y, cv=kfold, scoring='neg_log_loss', n_jobs=1) elapsed = time.time() - start print("Parallel Thread XGBoost, Single Thread CV: %f" % (elapsed)) # Parallel Thread XGBoost and CV start = time.time() model = XGBClassifier(nthread=-1) results = cross_val_score(model, X, label_encoded_y, cv=kfold, scoring='neg_log_loss', n_jobs=-1) elapsed = time.time() - start print("Parallel Thread XGBoost and CV: %f" % (elapsed)) |
Note: Your results may vary given the stochastic nature of the algorithm or evaluation procedure, or differences in numerical precision. Consider running the example a few times and compare the average outcome.
Running the example prints the following results.
|
1 2 3 |
Single Thread XGBoost, Parallel Thread CV: 359.854589 Parallel Thread XGBoost, Single Thread CV: 330.498101 Parallel Thread XGBoost and CV: 313.382301 |
We can see that there is a benefit from parallelizing XGBoost over the cross validation folds. This makes sense as 10 sequential fast tasks is better than (10 divided by num_cores) slow tasks.
Interestingly we can see that the best result is achieved by enabling both multi-threading within XGBoost and in cross validation. This is surprising because it means that num_cores number of parallel XGBoost models are competing for the same num_cores in the construction of their models. Nevertheless, this achieves the fastest results and is the suggested usage of XGBoost for cross validation.
Because grid search uses the same underlying approach to parallelism, we expect the same finding to hold for optimizing the hyperparameters for XGBoost.
Summary
In this post you discovered the multi-threading capability of XGBoost.
You learned:
- How to check that the multi-threading support in XGBoost is enabled on your system.
- How increasing the number of threads affects the performance of training XGBoost models.
- How to best configure XGBoost and Cross Validation in Python for minimum running time.
Do you have any questions about multithreading support for XGBoost or about this post? Ask your questions in the comments and I will do my best to answer.
Discover The Algorithm Winning Competitions!

Develop Your Own XGBoost Models in Minutes
...with just a few lines of Python
Discover how in my new Ebook:
XGBoost With Python
It covers self-study tutorials like:
Algorithm Fundamentals, Scaling, Hyperparameters, and much more...
Bring The Power of XGBoost To Your Own Projects
Skip the Academics. Just Results.



")


Good one, thanks, really interesting!
Thanks Mate, I’m glad you found it interesting.
Hi Jason, am running this code, the first batch on n umber of threads using the XGB book. It hangs up on model.fit(X, label_encoded_y) … am running in Jupyter Notebook using Python 3+ …. has anyone come across this issue before?
Thanks
Hi David, perhaps try on the command line outside of a notebook?
Hi Jason, are nthread = -1 and nthread = 4 the same for a computer with 4 cores? With regard to the parallelism in cross validation, it took forever to run for paralleling both XGBoost and CV on my laptop, while the first two scenarios completed within reasonable time. Any idea? Thanks!
That is correct Ruiye.
The scenarios are aggressive in ram and cpu. It might have just clobbered your hardware – sorry.
Hi,
From some reasoh XGboost doesn’t parallel on mac os on Python 3 for me.
I installed xgboost like this:
git clone –recursive https://github.com/dmlc/xgboost cd xgboost; cp make/minimum.mk ./config.mk; make -j4 workon riskvenv cd python-package sudo python setup.py install
But the xgboost doesn’t use all the 4 cores when running even when I specify the number of threads and when I don’t.
Do any one have a clue how to solve this issue?
Perhaps it’s a Python 3 issue?
I can confirm that I can all 4 cores with Python 2.7 with xgboost.
I honestly think this article misleading since the default procedure is to use all threads, so tuning on this parameter will not give you any gain if you want to use all threads which is by far the most common.
I only think there is a reason to tune this if you know you have 4 different models and want only to use one thread for each otherwise I not think this article have en purpose.
Thnaks Peter.
I wanted to show the speed-up offered by using more cores – e.g. jumping on big AWS instances can help speed up your model.
FWIW, in my config (conda, python 3.6.5, xgboost 0.71), the default does not seem to multithread if nthread is not specified. See results below. I would specify nthread=-1 or test as described in this post to determine which nthread value works best.
-1 3.9046308994293213
not set 6.836001396179199
1 6.832951545715332
2 5.142981767654419
3 4.339038848876953
4 3.99072265625
5 3.7604596614837646
6 3.6778457164764404
7 3.56015944480896
8 3.5151889324188232
Helli sir,
You are doing a good job. I have tuned XGBoost Hyper parameter like Gamma, Learning_rate, reg_lambda, max_depth, min_child_weight, subsample etc. I now used the values I got from the tuning to see if the accuracy will change, but it stays the same as the untuned accuracy. What can I do to increase the accuracy sir? Kind regards.
It may be related to the stochastic nature of the algorithm. Consider using repeated k-fold cross validation.
More on the stochastic nature of ML algorithms here:
https://machinelearningmastery.com/randomness-in-machine-learning/
Thanks Jason for the post.
So, in training time the code runs in parallel. I am trying to figure out does the parallelism happens at run time too?
If I have 50 trees does the output of each tree is done in parallel or sequentially?
It is not that clean as there is a dependence between the trees.
I believe the construction of the trees themselves is parallelized.
Hi Jason,
Really appreciate this post. I’m still quite confused about the last scenario. If you use, nthreads=-1 and njobs=-1, is it using all cores to run XGBoost fitting and all cores in parallel for CV? So, let’s say I have 32 cores, then 32 cores are being used for XGBoost, and then 32 XGBoost jobs are being launched for CV? I have no idea how those 2 parameters are competing for compute time. Have you gotten more insight on that? I imagine if you have a total of 32 cores, then n_threads x n_jobs would have to equal 32?
Thanks!
Perhaps you could run CV with 1 thread and run xgboost with the remaining 31?
Perhaps try 16/16 spit? experiment and see what works best.
HI Jason, I dont know what happens but i got this result:
Single Thread XGBoost, Parallel Thread CV: 15.321717
Parallel Thread XGBoost, Single Thread CV: 12.168671
Parallel Thread XGBoost and CV: 16.646298
I’m using Python 3.6
Thanks
Your installation of xgboost might not be setup to use multiple threads.
Michael’s result is the expected slow down. If you run N (n_threads=-1) instances of multithreaded XGB, each using N threads, you have N^2 threads for N execution units. If N EUs means hyperthreads, then you have 2N threads per per core. If N EUs means cores, then you have N threads per core. Either way, over subscription. XGB tends to be CPU bound. It might be interesting if this article was updated to show something like K threads for CV with N/K threads for XGB.
Further considerations for XGB performance, look at the “xgboost Exact speed” chart here. Beyond the physical core count (36), the performance gets worse. https://github.com/dmlc/xgboost/issues/3810
Thanks.
XGBClassifier deprecated
nthread, now it isn_jobsand the default is1.Source: https://xgboost.readthedocs.io/en/latest/python/python_api.html
To check if
XGBoostis working, I would also recommend simply checking the CPUs % usinghtop, you should see all of them well around 100%Thanks for the note.
I am learning an ensemble model using XGBoost algorithm
When I printed base_learners, it seems to be stored as a dictionary type. like this :
{‘dnn’: , ‘random forest’: RandomForestClassifier(bootstrap=True, class_weight=None, criterion=’gini’,
max_depth=4, max_features=’sqrt’, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=2, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=-1,
oob_score=False, random_state=42, verbose=0, warm_start=False), ‘extra trees’: ExtraTreesClassifier(bootstrap=False, class_weight=None, criterion=’gini’,
max_depth=4, max_features=’auto’, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=2, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100, n_jobs=-1,
oob_score=False, random_state=42, verbose=0, warm_start=False)}
To use ‘base_learner’ in another file, How can I save that? I can’t use save_model(). because that is not model
And, also I can’t using pickle module. I don’t know why.
But I think multithreaded error problems.
When I using pickle module, I got the following error message:
pickle.dump(base_learners, open(‘./models/base_learners.pkl’, ‘wb’))
TypeError: can’t pickle _thread.RLock objects
Do you know the solution?
I don’t have an example of changing the base learner in xgboost.
Sorry, I have not seen that error, perhaps try posting to stackoverflow?
Hi Jason,
I have a problem with the multithreading of scikit wrapper XGBClassifier. I was using n_jobs=4 for XGBClassifier in a 4 cored machine and the CPU usage shows only ~100%. However, I expected a usage of ~400% which was in the case of XGBoost alone. Could you have any clue why this is happening?
I don’t know, sorry.
Sorry about this question. I didn’t install xgboost with multithreading
I machine learning more computation extensive or data intensive? should we use parallel programming like cuda or big data frameworks like hadoop for machine learning?
Yes and no. It depends on the project.