A Top-Down Strategy for Beginners to Start and Practice Machine Learning.
Getting started is much easier than you think.
In this post I show you the top-down approach for getting started in applied machine learning. You will discover the four steps to this approach. They should feel familiar because it’s probably the same top-down approach that you used to learn how to program. Namely, get the basics, practice a lot and dive into the details later after you’re hooked.
At the end of the post, I link to my mini-course that can shortcut the path and give you step-by-step instructions to follow to start and practice applied machine learning.
Beginners are Different
Beginners have an interest in machine learning but are not sure how to take that first step. They are confused because the material on blogs and in courses is almost always pitched at an intermediate level.
Machine Learning Photo by Erik Charlton, some rights reserved.
Typical books and university-level courses are bottom-up. They teach or require the mathematics before grinding through a few key algorithms and theories before finishing up. This can be a good approach if you have the time, patience and appropriate background. Not everyone has so much free time or the desire to move through so much low-level material before getting to the meat and potatoes of applied machine learning.
I get a lot of emails from beginners asking for advice on how to get started in machine learning. It’s a tough problem, because there are so many possibilities and so many things I could recommend. I tell them not to dive into the math and not to go straight back to school.
The students and professionals I advise are almost always programmers or have an engineering background, and I tell them that there is a much more efficient path into machine learning for them.
Solution is Top-Down
My advice for beginners in machine learning is to take a top-down approach.
Beginners are Different Photo by mikebaird, some rights reserved.
I advise beginners to take a faster route to discover what applied machine learning is all about before dedicating huge time resources into studying the theory. It makes sense and it is familiar because it’s the way you get excited about programming first, before diving in and making it a focus of study and career.
The top down approach is to quickly learn the high-level step-by-step process of working through a machine learning problem end-to-end using a software tool. With modern platforms, it is possible to work through small problems in minutes to hours using complex state-of-the-art algorithms and rigorous validation and statistical hypothesis testing, all performed automatically within the tools.
It is after you are familiar and confident with the process that I advise you start looking deeper into the algorithms and theory side of machine learning. How first, why later.
We can summarize this top-down approach as follows:
Learn the high-level process of applied machine learning.
Learn how to use a tool enough to be able to work through problems.
Practice on datasets, a lot.
Transition into the details and theory of machine learning algorithms.
Applied Machine Learning Process
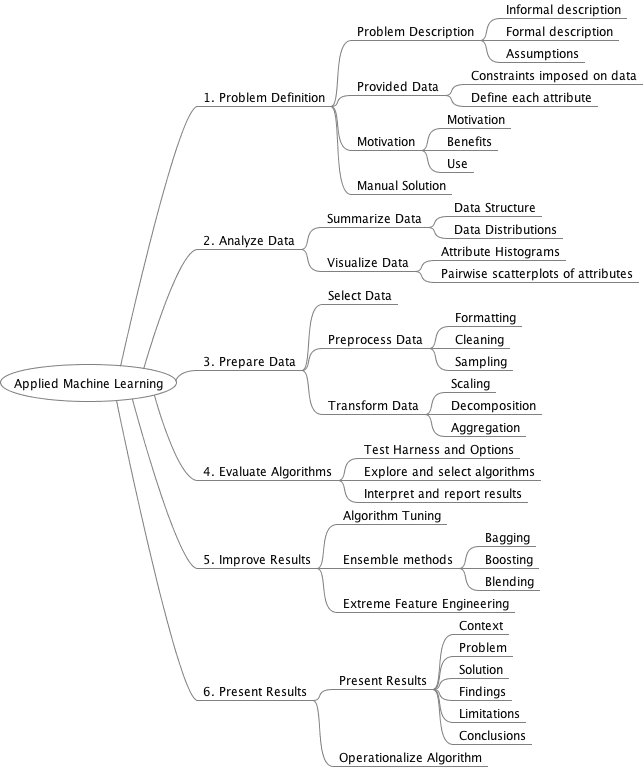
I have written a lot about the process of applied machine learning. I advocate a 6-step process for classification and regression type problems, the common problem types at the heart of most machine learning problems. The process is as follows:
Problem Definition: Understand and clearly describe the problem that is being solved.
Analyze Data: Understand the information available that will be used to develop a model.
Prepare Data: Discover and expose the structure in the dataset.
Improve Results: Leverage results to develop more accurate models.
Present Results: Describe the problem and solution so that it can be understood by third parties.
Applied Machine Learning Process Overview
By following this structured process on each problem you work through, you enforce a minimum level of rigour and dramatically increase the likelihood of getting good (or more likely excellent) results.
Use the Weka Machine Learning Workbench
The software platform for beginners to learn when getting started is the Weka Machine Learning Workbench.
I think the decision to use Weka when getting started is a complete no-brainer because:
It provides a simple graphical user interface that encapsulates the process of applied machine learning outlined above.
It facilitates algorithm and dataset exploration as well as rigours experiment design and analysis.
It is free and open source, licensed under the GNU GPL.
It is cross-platform and runs on Windows, Mac OS X and Linux (requires a Java virtual machine).
It contains state-of-the-art algorithms with an impressive abundance of Decision Trees, Rule Based Algorithms and Ensemble methods, as well as others.
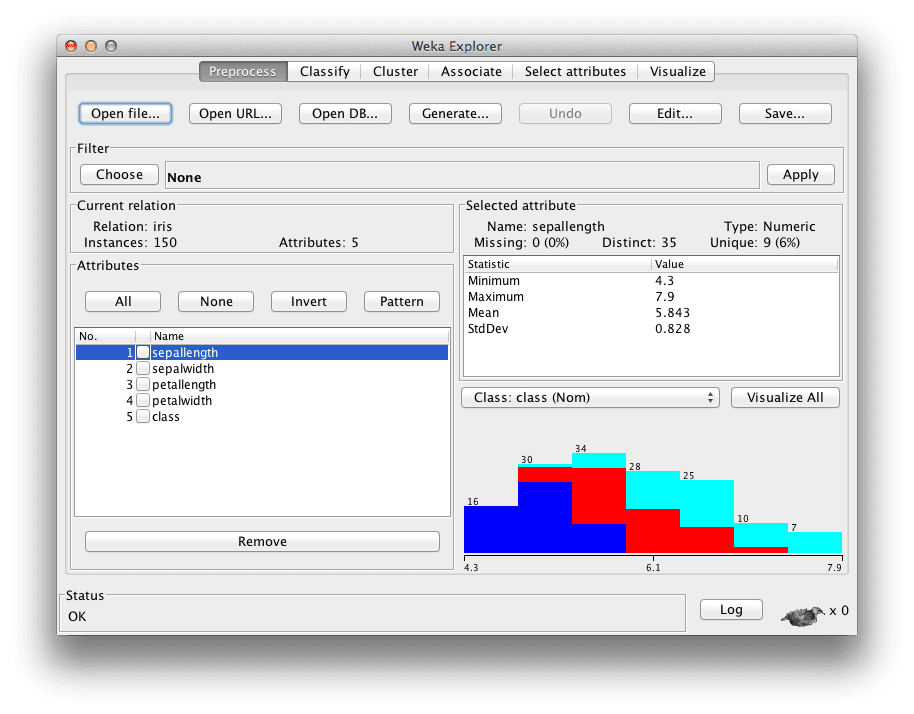
Weka Explorer Interface with the Iris dataset loaded
You can see for yourself how easy the platform is to use, I have written a number of 5-minute Weka tutorials, such as:
Additionally, if you get right into Weka, you can run algorithms from the command line and integrate algorithms into your application via the application programming interface. It is an extensible platform and you can quickly and easily implement your own algorithms to the interface and use them in the GUI.
Practice, Practice, Practice, on Datasets
Once you are up and running with Weka, you need to practice the 6-step process of applied machine learning.
The Weka installation includes a data directory with many standard machine learning datasets, most taken from actual scientific problem domains. There is also a wealth of excellent datasets to trial and learn from on the UCI Machine Learning Repository. These datasets are an excellent place for you to get started learning and practicing.
The datasets are small and easily fit into memory.
The small size of the datasets also means that algorithms and experiments are quick to run.
The problems and data are real, including noise, biases in sampling and data collection that you need to consider.
The data is well understood so that you can leverage what is known and openly discuss the data with peers.
There are known “good results” for you to compare to and recreate.
You can choose your own level of detail on each step of the structured process. I recommend spending no more than one-hour on each step when getting started. You can do and learn a lot about a problem in one hour with Weka, especially when designing and running experiments. This will keep your motivation and project velocity high.
Lots of Data Photo attributed to cibomahto, some rights reserved
The structured process encourages you to make observations and record results and findings as you work through a given problem. It is wise to keep these observations and findings together, perhaps in a project directory or Github project.
I recommend blogging about each of your projects, even each step of a project as you complete it. You can do this on your own blog (if you have one) or as Facebook or Google+ updates (that now support images and text formatting). I like the honesty that publicly blogging projects encourages. It also provides an indicator to your peers and colleagues that you are interested, serious about and developing some chops in applied machine learning.
Transitioning Deeper
Because the projects are small and the process is structured, you can quickly learn a lot about a problem and move through a number of projects. You can also collect data on problems of your own and use the same process to deliver useful and meaningful results on projects at work or for your own benefit.
The next step is to dive deeper into the algorithms and learn why they work and how to get more out of them. I recommend transitioning deeper into the subject by picking up the book Data Mining: Practical Machine Learning Tools and Techniques. It is written by the original authors of the Weka platform and provides a treatment of how and why the algorithms used in Weka work and other deeper concerns of machine learning.
The deeper knowledge will allow you to get more from the platform on your own custom problems. It will also allow you to better appreciate the methods in Weka and you will start to build an intuition as to the mapping between problem and algorithm types
Summary
In this post you discovered the top-down approach to getting started in machine learning that advocates learning the specific structured process, a powerful tool that supports this process and to practice applied machine learning in a series of focused projects.
You learned that this is the exact opposite of the traditional bottom-up approach that expects you to perform the heavy lifting in the field first, (before you even know if the field is right for you) and leaves you to figure out how to apply algorithms in practice all by yourself.
Hey Jason, I’m interested in the course. I’m very familiar with Python, and as I was looking to practice ML, I figured using scikit-learn would be the natural path for me. So I was turning a blind eye to your Weka posts. However, reading the section in this post “Use the Weka Machine Learning Workbench”, with the image of the GUI, really sparked my interest. The fact that it comes with datasets and has a focus on visual output are compelling features for me. It invites playfulness and exploration.
I’ve found in other areas of programming that it’s important for me to stop being snobbish about the tools I use, and just dive and work with whatever tool allows me to get things done. I’m looking forward to loading up Weka and playing with the data and algorithms.
Thanks Steven, I have sent you an email with the coupon to get 20% off.
I reckon you’ll get a lot out of the course. It’s very hands on and the “applied machine learning” skills are very transferable to other platforms like scikit-learn, after you’ve picked them up.
The tools are the easy part, getting process down pat is key. And Weka is a total joy to use.
Hey Jason, i am the emerging candidate for the machine learning. The content which you shared is very useful and interesting. I request you to send me the link to access WEKA ML workbench.
Hi – have just been exposed to machine learning in an informatics course. Instructor used Weka as part of the introduction and now I am trying to learn more. I’m particularly interested in the application to medicine (e.g. diabetes and breast cancer examples). I look forward to trying out your guide.
Thanks for making an introductory resource that isn’t intimidating.
Hey Jason, I am very interested in the course. I was looking through some machine learning books on amazon talking about Sci-kit before I stumbled onto your post that described Weka and its GUI – I was instantly hooked!
I just took the initial tumble down the rabbit hole of programming – read a few things and watched some videos so very familiar with terminology and concept – the bits and pieces are all there just now need to get a ton of practice. I have a deep background in statistics and regression, etc. – the majority of my background is financial services but I have begun some consulting work where one of my biggest projects is a client who is very successful in machine learning – so your blog is nothing less than a godsend!
Very excited to dive into the course and begin this journey of machine learning!
I am a new starter in machine learning, going through your introductory message I know definately I will get something better out of your modules. I have not known how much it cost yet but I will definately participate. I am into text classification ( filtering of offensive langiage in online social networks using natural language processing). I know it would be of a great assistance to me. Hope to mail you as am going on through the modulels.
Thank you.
i am a java developer looking to transition into the field of analytics. How would this course help in my goal ? I really liked your approach on machine learning.
Would you recommend this course to (senior) high school students who have some knowledge of algorithms and have moved beyond the basics of a programming language such as Python?
Hi Jason , Thanks for a good article .I am a practicing surgeon at a charitable hospital in South India ( Hyderabad ) . I have an intense desire to develop a device which can assess, tabulate and analyse several vitals and other important parameters of an individual ,which could prevent several debilitating chronic disorders . I have started a portal called healthisall.in earlier and have failed in implementing it properly but the blog is been a huge hit .I have moved on and now I am planning on starting an integrated application with a device useful for every individual in a family aiming at prevention . I am looking for a course which can educate me with the basics of healthcare related IOT( Real basics ) .Kindly let me know how to proceed further .I am willing to approach any teams who could be interested in working in the same field or related stuff. Thank you so much .
I am just getting started in machine learning. Although I am not a programmer I do work in a network carrier (voip, data, iptv) field and use a lot of scripting languages to get the job done. ML is being mentioned more and more in my field for various project manager, customer service, and performance analytics needs so I need to be at least familiar with it. I look forward to your course and thank you for putting within my reach to comprehend.
Hi Jason,
I have extensive experience in database management systems and HLL programming. I would like to switch to ML and I do not know where to start from. I need your help to move forward in ML. What are basic prerequisites to opt for this course.
I really liked this article! I couldn’t agree more on the benefit of posting our projects, results, and findings in a blog. It serves many purposes, but the most important to me is that shows you know what you’re talking about! Also, it works as a personal brand advertisement that’ll ease your way into the industry!



")




Hey Jason, I’m interested in the course. I’m very familiar with Python, and as I was looking to practice ML, I figured using scikit-learn would be the natural path for me. So I was turning a blind eye to your Weka posts. However, reading the section in this post “Use the Weka Machine Learning Workbench”, with the image of the GUI, really sparked my interest. The fact that it comes with datasets and has a focus on visual output are compelling features for me. It invites playfulness and exploration.
I’ve found in other areas of programming that it’s important for me to stop being snobbish about the tools I use, and just dive and work with whatever tool allows me to get things done. I’m looking forward to loading up Weka and playing with the data and algorithms.
Thanks Steven, I have sent you an email with the coupon to get 20% off.
I reckon you’ll get a lot out of the course. It’s very hands on and the “applied machine learning” skills are very transferable to other platforms like scikit-learn, after you’ve picked them up.
The tools are the easy part, getting process down pat is key. And Weka is a total joy to use.
Hey Jason, i am the emerging candidate for the machine learning. The content which you shared is very useful and interesting. I request you to send me the link to access WEKA ML workbench.
Thanks,
Shiva R
The Weka software is free and open source and can be downloaded from here:
https://www.cs.waikato.ac.nz/ml/weka/
the link u shared 🙁 not working
http://www.cs.waikato.ac.nz’s server IP address could not be found.
Weka:
https://www.cs.waikato.ac.nz/ml/weka/
Hi – have just been exposed to machine learning in an informatics course. Instructor used Weka as part of the introduction and now I am trying to learn more. I’m particularly interested in the application to medicine (e.g. diabetes and breast cancer examples). I look forward to trying out your guide.
Thanks for making an introductory resource that isn’t intimidating.
Hey Jason, I am very interested in the course. I was looking through some machine learning books on amazon talking about Sci-kit before I stumbled onto your post that described Weka and its GUI – I was instantly hooked!
I just took the initial tumble down the rabbit hole of programming – read a few things and watched some videos so very familiar with terminology and concept – the bits and pieces are all there just now need to get a ton of practice. I have a deep background in statistics and regression, etc. – the majority of my background is financial services but I have begun some consulting work where one of my biggest projects is a client who is very successful in machine learning – so your blog is nothing less than a godsend!
Very excited to dive into the course and begin this journey of machine learning!
Thanks Kris!
Just what I was looking for, thank you
Glad to hear that Kurren!
This is what i looking for, thanks for sharing
I am a new starter in machine learning, going through your introductory message I know definately I will get something better out of your modules. I have not known how much it cost yet but I will definately participate. I am into text classification ( filtering of offensive langiage in online social networks using natural language processing). I know it would be of a great assistance to me. Hope to mail you as am going on through the modulels.
Thank you.
Hi Jason
i am a java developer looking to transition into the field of analytics. How would this course help in my goal ? I really liked your approach on machine learning.
HI Jason,
Would you recommend this course to (senior) high school students who have some knowledge of algorithms and have moved beyond the basics of a programming language such as Python?
Hi Jason,
I would like to start with your course. Do you have any current discount offers?
Regards,
Joga
Hi Jason , Thanks for a good article .I am a practicing surgeon at a charitable hospital in South India ( Hyderabad ) . I have an intense desire to develop a device which can assess, tabulate and analyse several vitals and other important parameters of an individual ,which could prevent several debilitating chronic disorders . I have started a portal called healthisall.in earlier and have failed in implementing it properly but the blog is been a huge hit .I have moved on and now I am planning on starting an integrated application with a device useful for every individual in a family aiming at prevention . I am looking for a course which can educate me with the basics of healthcare related IOT( Real basics ) .Kindly let me know how to proceed further .I am willing to approach any teams who could be interested in working in the same field or related stuff. Thank you so much .
I am just getting started in machine learning. Although I am not a programmer I do work in a network carrier (voip, data, iptv) field and use a lot of scripting languages to get the job done. ML is being mentioned more and more in my field for various project manager, customer service, and performance analytics needs so I need to be at least familiar with it. I look forward to your course and thank you for putting within my reach to comprehend.
Thanks Frank, it’s great to have you here.
Hi Jason,
I have extensive experience in database management systems and HLL programming. I would like to switch to ML and I do not know where to start from. I need your help to move forward in ML. What are basic prerequisites to opt for this course.
Regards
S Ahmad
Hi, my best advice for getting started is here:
https://machinelearningmastery.com/start-here/#getstarted
By Far Best Tutorial I found online for Beginners. I would love to read most of articles on this site and join your course.
Thanks.
Hi Jason… Inspired by your posts and want to learn. But, want to ask a little more. Is there some concessions to students for the courses?
Yes, send me an email or message and I will send you a student discount.
Hi Jason, looking forward to join you course. My email id is – namsaxena95@gmail.com.
You can join here:
https://machinelearningmastery.leadpages.co/machine-learning-resource-guide/
Thanks for valuable information . I am a Java Developer and interested in ML . Should i learn python first before starting learning ML ?
I don’t think language matters, I expect there are many good java libraries for ML.
I do see great demand for skills in Python for ML:
https://machinelearningmastery.com/python-growing-platform-applied-machine-learning/
Hey Jason! I would like to start with machine learning but i am completely novice, so how and where should i start with?? Thanks in advance
Here is a good place to start:
https://machinelearningmastery.com/start-here/#getstarted
I really liked this article! I couldn’t agree more on the benefit of posting our projects, results, and findings in a blog. It serves many purposes, but the most important to me is that shows you know what you’re talking about! Also, it works as a personal brand advertisement that’ll ease your way into the industry!
Yes, especially if you specialize on a specific sub-field of machine learning.
Hi Jason,Currently I am working in Angular 6 and I want to learn ML, is there any perquisites or language which I should learn first.
No, I recommend diving in:
https://machinelearningmastery.com/start-here/#getstarted