Regression is a modeling task that involves predicting a numerical value given an input.
Algorithms used for regression tasks are also referred to as “regression” algorithms, with the most widely known and perhaps most successful being linear regression.
Linear regression fits a line or hyperplane that best describes the linear relationship between inputs and the target numeric value. If the data contains outlier values, the line can become biased, resulting in worse predictive performance. Robust regression refers to a suite of algorithms that are robust in the presence of outliers in training data.
In this tutorial, you will discover robust regression algorithms for machine learning.
After completing this tutorial, you will know:
Robust regression algorithms can be used for data with outliers in the input or target values.
How to evaluate robust regression algorithms for a regression predictive modeling task.
How to compare robust regression algorithms using their line of best fit on the dataset.
Let’s get started.
Robust Regression for Machine Learning in Python Photo by Lenny K Photography, some rights reserved.
Tutorial Overview
This tutorial is divided into four parts; they are:
Regression With Outliers
Regression Dataset With Outliers
Robust Regression Algorithms
Compare Robust Regression Algorithms
Regression With Outliers
Regression predictive modeling involves predicting a numeric variable given some input, often numerical input.
Machine learning algorithms used for regression predictive modeling tasks are also referred to as “regression” or “regression algorithms.” The most common method is linear regression.
Many regression algorithms are linear in that they assume that the relationship between the input variable or variables and the target variable is linear, such as a line in two-dimensions, a plane in three dimensions, and a hyperplane in higher dimensions. This is a reasonable assumption for many prediction tasks.
Linear regression assumes that the probability distribution of each variable is well behaved, such as has a Gaussian distribution. The less well behaved the probability distribution for a feature is in a dataset, the less likely that linear regression will find a good fit.
A specific problem with the probability distribution of variables when using linear regression is outliers. These are observations that are far outside the expected distribution. For example, if a variable has a Gaussian distribution, then an observation that is 3 or 4 (or more) standard deviations from the mean is considered an outlier.
A dataset may have outliers on either the input variables or the target variable, and both can cause problems for a linear regression algorithm.
Outliers in a dataset can skew summary statistics calculated for the variable, such as the mean and standard deviation, which in turn can skew the model towards the outlier values, away from the central mass of observations. This results in models that try to balance performing well on outliers and normal data, and performing worse on both overall.
The solution instead is to use modified versions of linear regression that specifically address the expectation of outliers in the dataset. These methods are referred to as robust regression algorithms.
In this case, we want a dataset that we can plot and understand easily. This can be achieved by using a single input variable and a single output variable. We don’t want the task to be too easy, so we will add a large amount of statistical noise.
Once we have the dataset, we can augment it by adding outliers. Specifically, we will add outliers to the input variables.
This can be done by changing some of the input variables to have a value that is a factor of the number of standard deviations away from the mean, such as 2-to-4. We will add 10 outliers to the dataset.
1
2
3
4
5
6
7
8
# add some artificial outliers
seed(1)
foriinrange(10):
factor=randint(2,4)
ifrandom()>0.5:
X[i]+=factor *X.std()
else:
X[i]-=factor *X.std()
We can tie this together into a function that will prepare the dataset. This function can then be called and we can plot the dataset with the input values on the x-axis and the target or outcome on the y-axis.
The complete example of preparing and plotting the dataset is listed below.
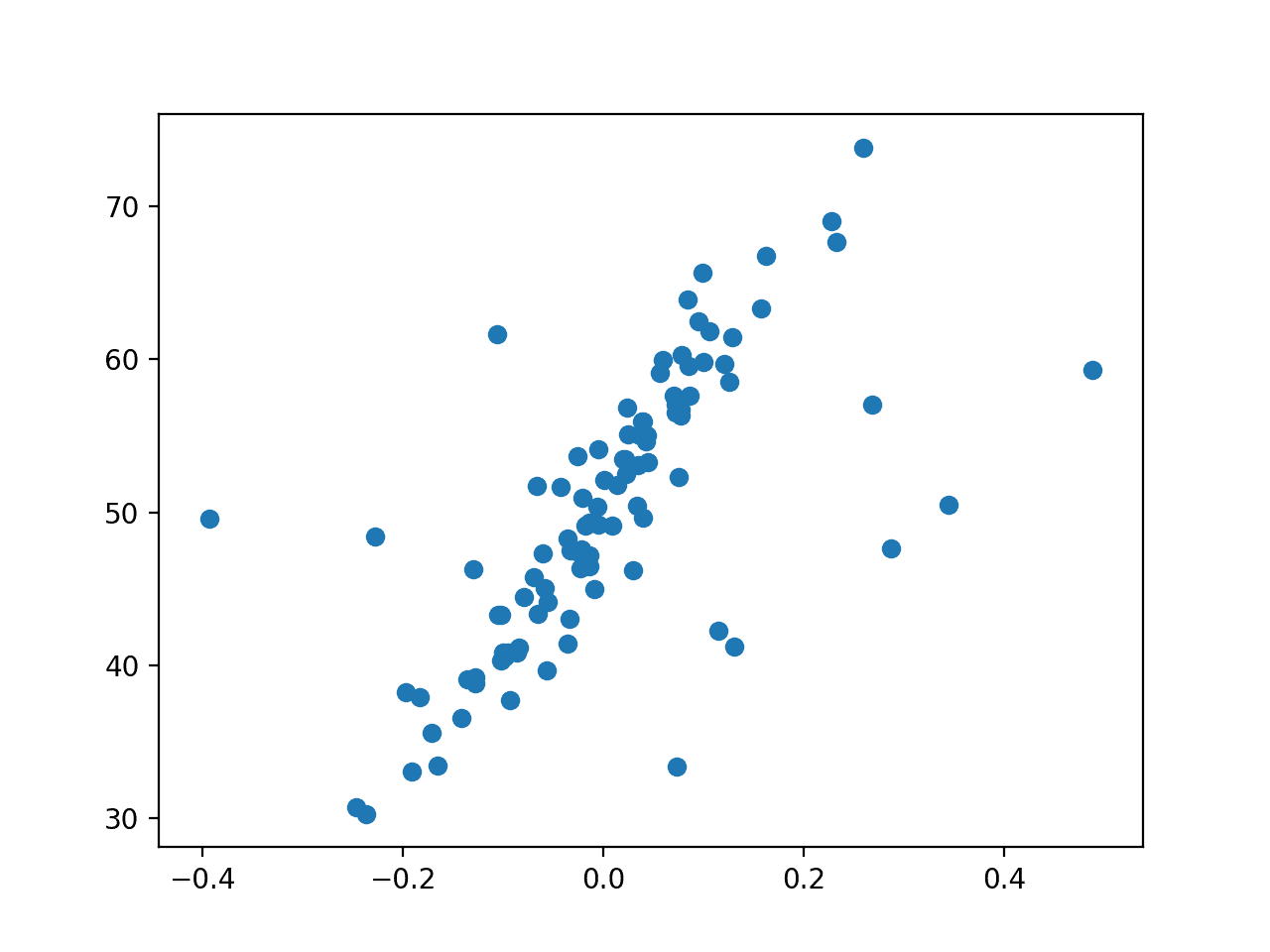
Running the example creates the synthetic regression dataset and adds outlier values.
The dataset is then plotted, and we can clearly see the linear relationship in the data, with statistical noise, and a modest number of outliers as points far from the main mass of data.
Scatter Plot of Regression Dataset With Outliers
Now that we have a dataset, let’s fit different regression models on it.
Robust Regression Algorithms
In this section, we will consider different robust regression algorithms for the dataset.
Linear Regression (not robust)
Before diving into robust regression algorithms, let’s start with linear regression.
We can evaluate linear regression using repeated k-fold cross-validation on the regression dataset with outliers. We will measure mean absolute error and this will provide a lower bound on model performance on this task that we might expect some robust regression algorithms to out-perform.
We can also plot the model’s line of best fit on the dataset. To do this, we first fit the model on the entire training dataset, then create an input dataset that is a grid across the entire input domain, make a prediction for each, then draw a line for the inputs and predicted outputs.
This plot shows how the model “sees” the problem, specifically the relationship between the input and output variables. The idea is that the line will be skewed by the outliers when using linear regression.
1
2
3
4
5
6
7
8
9
10
11
12
13
# plot the dataset and the model's line of best fit
Running the example first reports the mean MAE for the model on the dataset.
We can see that linear regression achieves a MAE of about 5.2 on this dataset, providing an upper-bound in error.
1
Mean MAE: 5.260 (1.149)
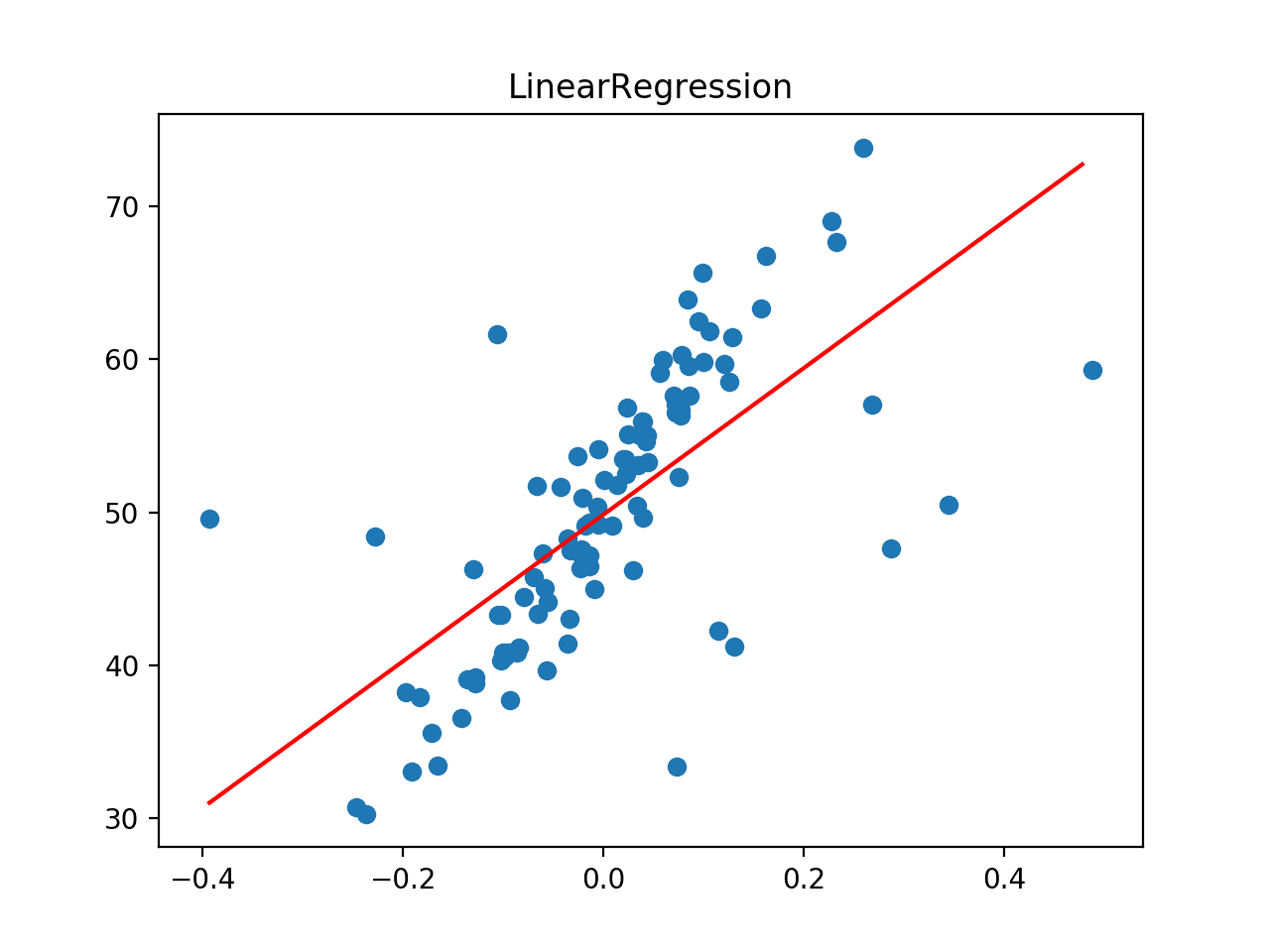
Next, the dataset is plotted as a scatter plot showing the outliers and this is overlaid with the line of best fit from the linear regression algorithm.
In this case, we can see that the line of best fit is not aligning with the data and it has been skewed by the outliers. In turn, we expect this has caused the model to have a worse-than-expected performance on the dataset.
Line of Best Fit for Linear Regression on a Dataset with Outliers
Huber Regression
Huber regression is a type of robust regression that is aware of the possibility of outliers in a dataset and assigns them less weight than other examples in the dataset.
We can use Huber regression via the HuberRegressor class in scikit-learn. The “epsilon” argument controls what is considered an outlier, where smaller values consider more of the data outliers, and in turn, make the model more robust to outliers. The default is 1.35.
The example below evaluates Huber regression on the regression dataset with outliers, first evaluating the model with repeated cross-validation and then plotting the line of best fit.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
# huber regression on a dataset with outliers
from random import random
from random import randint
from random import seed
from numpy import arange
from numpy import mean
from numpy import std
from numpy import absolute
from sklearn.datasets import make_regression
from sklearn.linear_model import HuberRegressor
from sklearn.model_selection import cross_val_score
Running the example first reports the mean MAE for the model on the dataset.
We can see that Huber regression achieves a MAE of about 4.435 on this dataset, outperforming the linear regression model in the previous section.
1
Mean MAE: 4.435 (1.868)
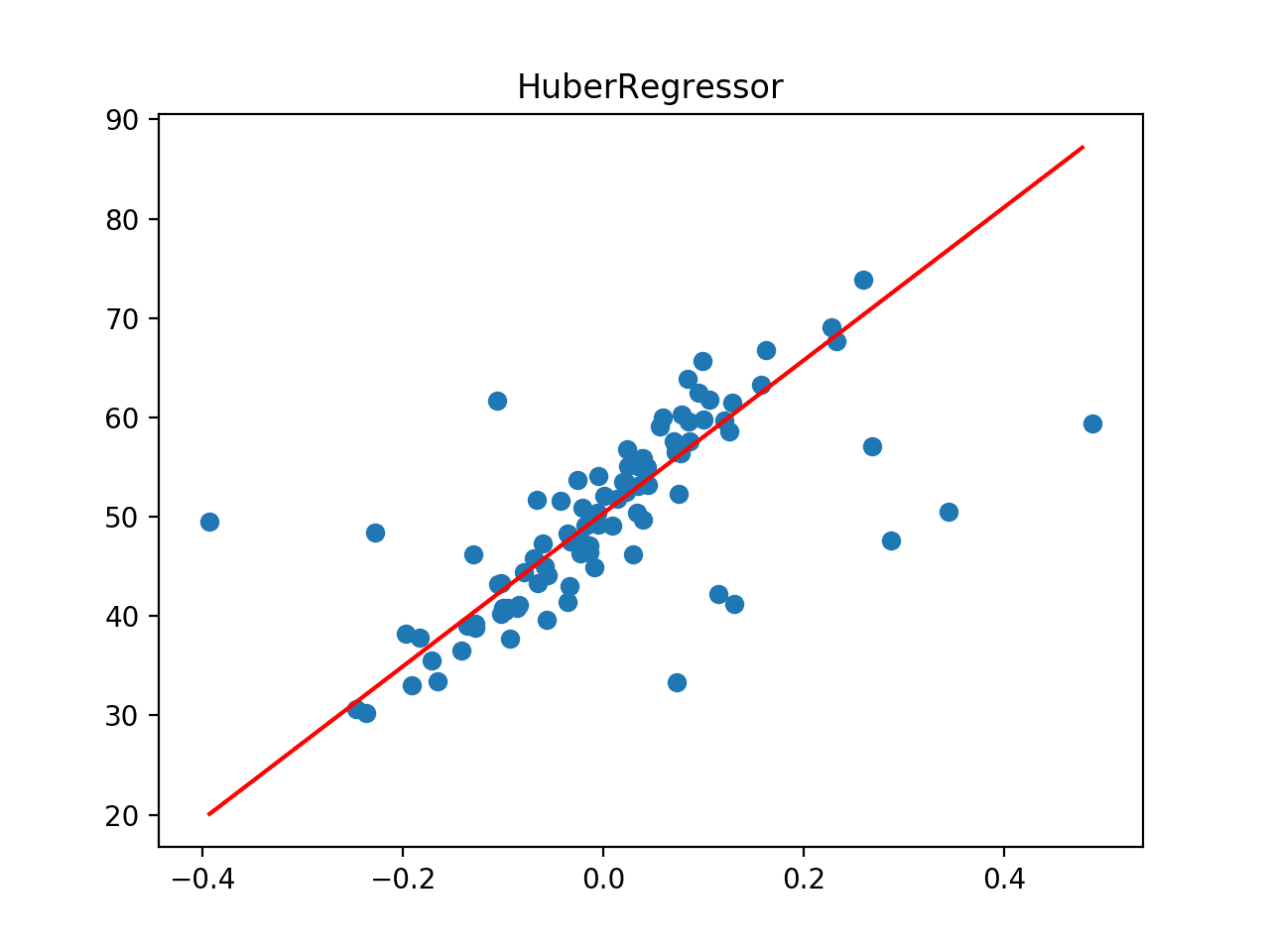
Next, the dataset is plotted as a scatter plot showing the outliers and this is overlaid with the line of best fit from the algorithm.
In this case, we can see that the line of best fit is better aligned with the main body of the data, and does not appear to be obviously influenced by the outliers that are present.
Line of Best Fit for Huber Regression on a Dataset with Outliers
RANSAC tries to separate data into outliers and inliers and fits the model on the inliers.
The scikit-learn library provides an implementation via the RANSACRegressor class.
The example below evaluates RANSAC regression on the regression dataset with outliers, first evaluating the model with repeated cross-validation and then plotting the line of best fit.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
# ransac regression on a dataset with outliers
from random import random
from random import randint
from random import seed
from numpy import arange
from numpy import mean
from numpy import std
from numpy import absolute
from sklearn.datasets import make_regression
from sklearn.linear_model import RANSACRegressor
from sklearn.model_selection import cross_val_score
Running the example first reports the mean MAE for the model on the dataset.
We can see that RANSAC regression achieves a MAE of about 4.454 on this dataset, outperforming the linear regression model but perhaps not Huber regression.
1
Mean MAE: 4.454 (2.165)
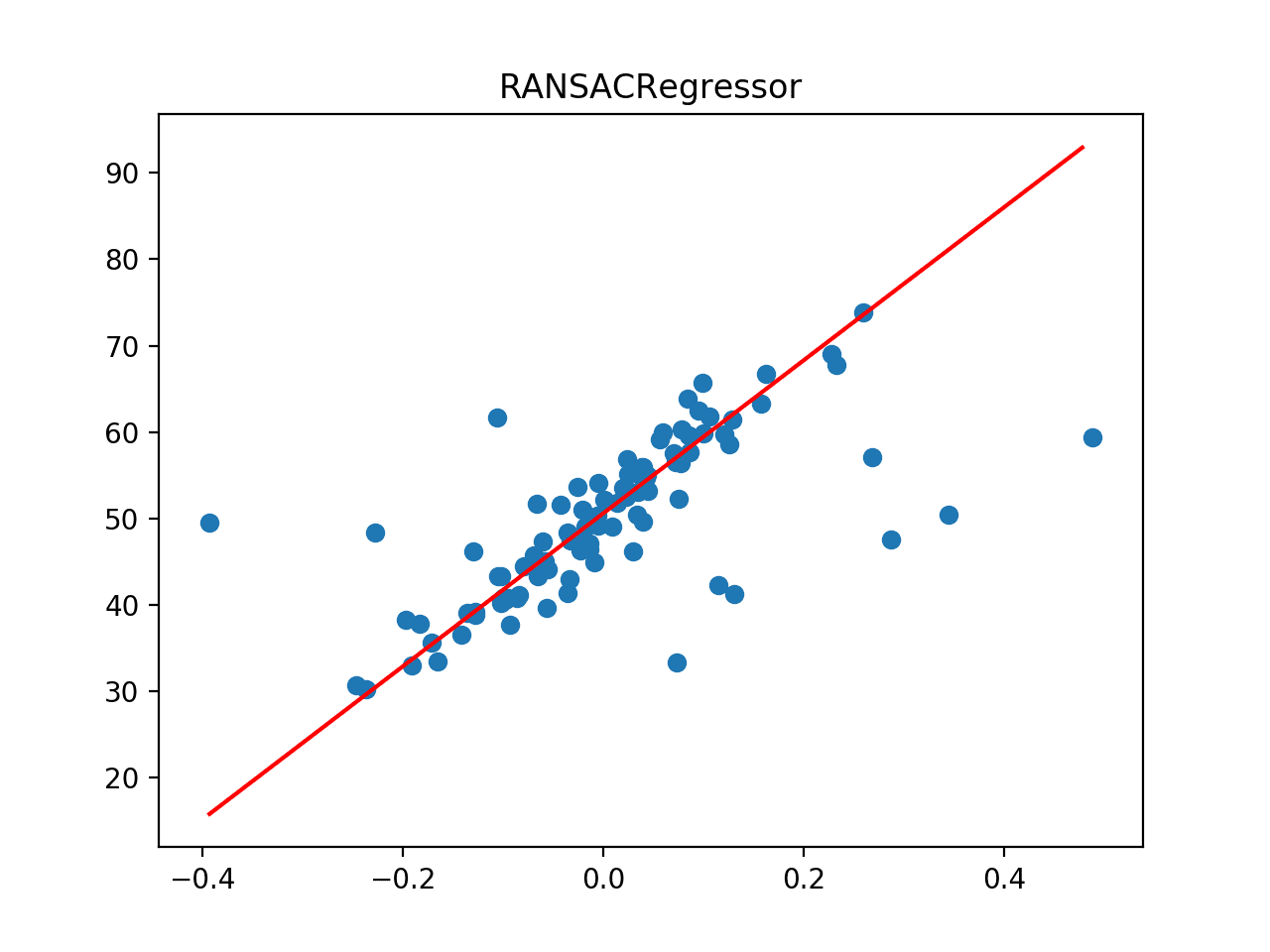
Next, the dataset is plotted as a scatter plot showing the outliers, and this is overlaid with the line of best fit from the algorithm.
In this case, we can see that the line of best fit is aligned with the main body of the data, perhaps even better than the plot for Huber regression.
Line of Best Fit for RANSAC Regression on a Dataset with Outliers
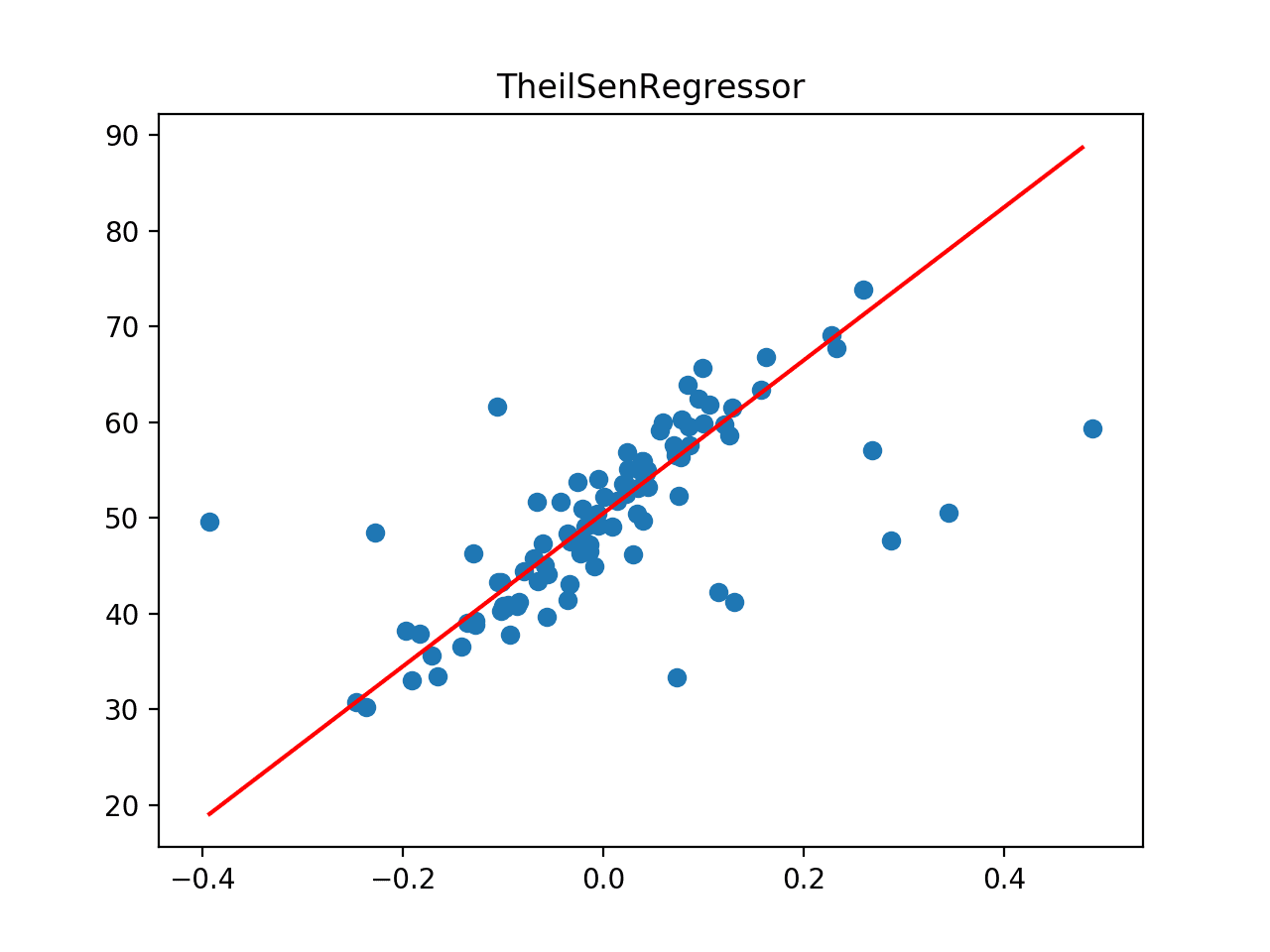
Theil Sen Regression
Theil Sen regression involves fitting multiple regression models on subsets of the training data and combining the coefficients together in the end.
The scikit-learn provides an implementation via the TheilSenRegressor class.
The example below evaluates Theil Sen regression on the regression dataset with outliers, first evaluating the model with repeated cross-validation and then plotting the line of best fit.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
# theilsen regression on a dataset with outliers
from random import random
from random import randint
from random import seed
from numpy import arange
from numpy import mean
from numpy import std
from numpy import absolute
from sklearn.datasets import make_regression
from sklearn.linear_model import TheilSenRegressor
from sklearn.model_selection import cross_val_score
Running the example first reports the mean MAE for the model on the dataset.
We can see that Theil Sen regression achieves a MAE of about 4.371 on this dataset, outperforming the linear regression model as well as RANSAC and Huber regression.
1
Mean MAE: 4.371 (1.961)
Next, the dataset is plotted as a scatter plot showing the outliers, and this is overlaid with the line of best fit from the algorithm.
In this case, we can see that the line of best fit is aligned with the main body of the data.
Line of Best Fit for Theil Sen Regression on a Dataset with Outliers
Compare Robust Regression Algorithms
Now that we are familiar with some popular robust regression algorithms and how to use them, we can look at how we might compare them directly.
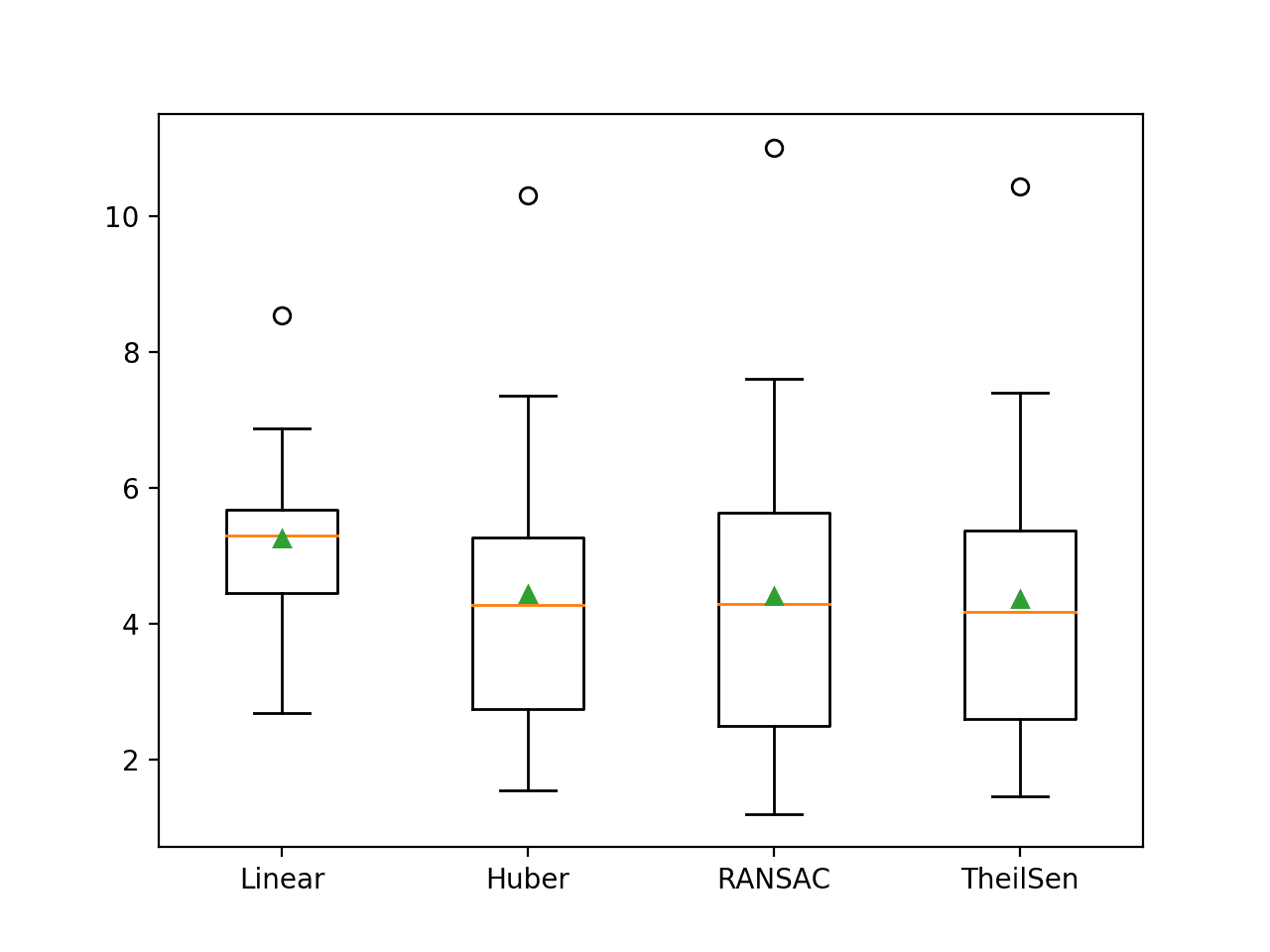
It can be useful to run an experiment to directly compare the robust regression algorithms on the same dataset. We can compare the mean performance of each method, and more usefully, use tools like a box and whisker plot to compare the distribution of scores across the repeated cross-validation folds.
The complete example is listed below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
# compare robust regression algorithms on a regression dataset with outliers
from random import random
from random import randint
from random import seed
from numpy import mean
from numpy import std
from numpy import absolute
from sklearn.datasets import make_regression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedKFold
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import HuberRegressor
from sklearn.linear_model import RANSACRegressor
from sklearn.linear_model import TheilSenRegressor
Running the example evaluates each model in turn, reporting the mean and standard deviation MAE scores of reach.
Note: your specific results will differ given the stochastic nature of the learning algorithms and evaluation procedure. Try running the example a few times.
We can see some minor differences between these scores and those reported in the previous section, although the differences may or may not be statistically significant. The general pattern of the robust regression methods performing better than linear regression holds, TheilSen achieving better performance than the other methods.
1
2
3
4
>Linear 5.260 (1.149)
>Huber 4.435 (1.868)
>RANSAC 4.405 (2.206)
>TheilSen 4.371 (1.961)
A plot is created showing a box and whisker plot summarizing the distribution of results for each evaluated algorithm.
We can clearly see the distributions for the robust regression algorithms sitting and extending lower than the linear regression algorithm.
Box and Whisker Plot of MAE Scores for Robust Regression Algorithms
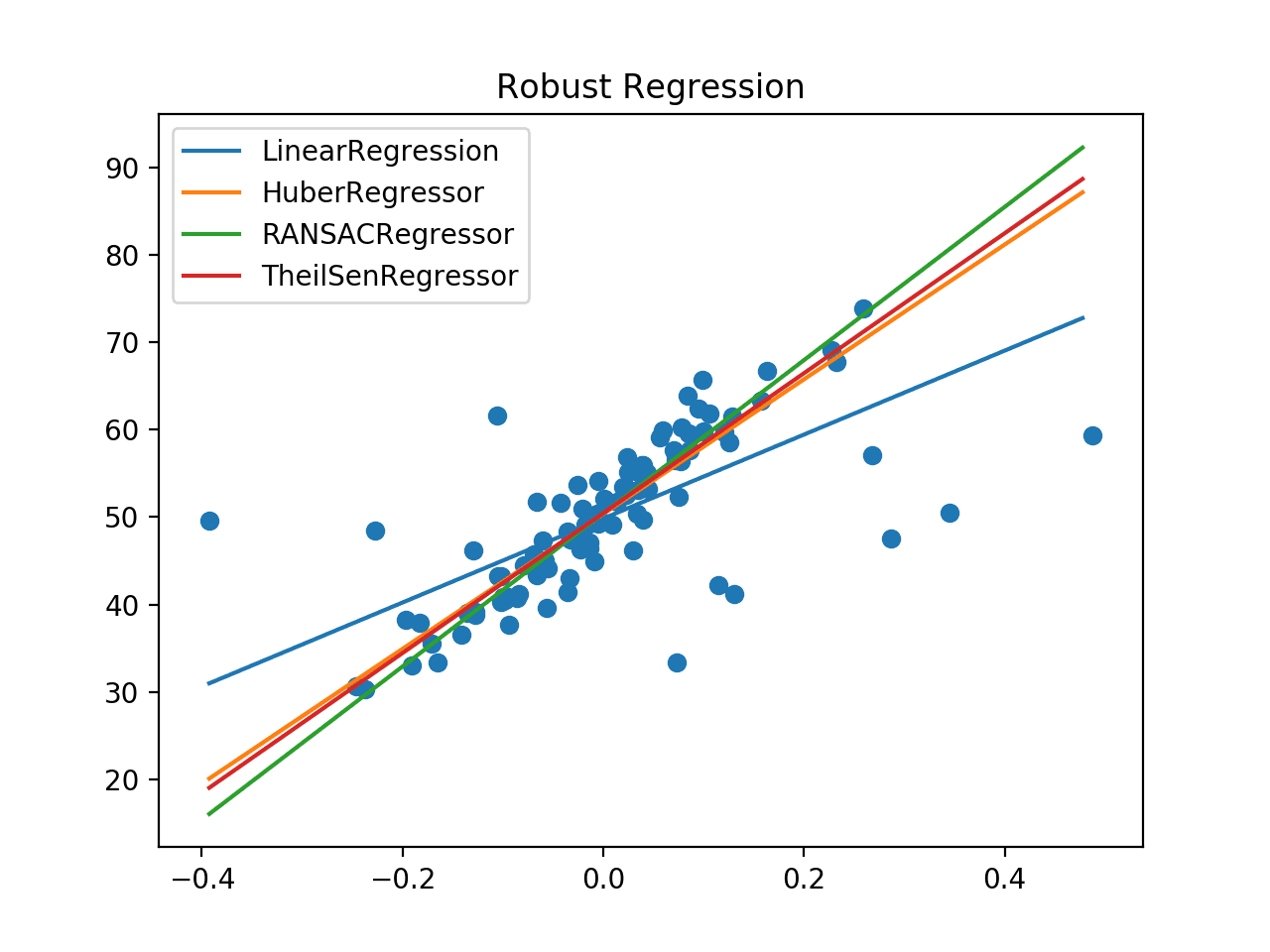
It may also be interesting to compare robust regression algorithms based on a plot of their line of best fit.
The example below fits each robust regression algorithm and plots their line of best fit on the same plot in the context of a scatter plot of the entire training dataset.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
# plot line of best for multiple robust regression algorithms
from random import random
from random import randint
from random import seed
from numpy import arange
from sklearn.datasets import make_regression
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import HuberRegressor
from sklearn.linear_model import RANSACRegressor
from sklearn.linear_model import TheilSenRegressor
Running the example creates a plot showing the dataset as a scatter plot and the line of best fit for each algorithm.
We can clearly see the off-axis line for the linear regression algorithm and the much better lines for the robust regression algorithms that follow the main body of the data.
Comparison of Robust Regression Algorithms Line of Best Fit
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Great article I learnt a lot! I was wondering – what should be done if we also want to give different weights for the observations? For example in a time series of 3-4 years we want to give more weight for closer observations. Can you guide to further reading of this? Thanks!!
What I meant was if you want to compare between 12 months slope this month vs. 12 months slope last month. In this case you want the slope to be less affected by earlier observations.
First of all thank you for your job, posting these interesting methods. I was wondering: is it possible to insert robust regression in a clustering algorithm? That is, placing a condition that makes a cluster of points belong to a regression estimator, or calculating a cluster based on a regressor and then go on with other clusters (which would have other regressors). This, maybe, by placing a tolerance angle for each cluster. It would be very interesting to have such a feature.
I too cannot figure out how to do it. I guess it would may be possible to do such a process by iterating the operation of linear estimation n times on a 2d/3d array, being n = number of clusters, for example, in a k-mean type clustering. But I don’t really understand at which place of the clustering algorithm code I have to change what to place the regression condition.
Great tutorial, thank you for it and for the others that you have published on the site. I was wondering if it is possible to do a linear regression estimation on 3d data sets with these methods. Will much appreciate any advice. Thanks
Great post Jason. I had a related question. How do I approach a regression problem where the data is not noisy but target variable is noisy. Which regression algorithms can I use? How do I denoise a noisy target variable in regression?
It was an excellent read. Great tutorial and very clear explanation of robust regression and all the different algorithms.
I was wondering if there are any limitations to robust regression? Why not use robust regression all the time instead of using the OLS regression model?
(1) the algorithm is more complex (2) introducing stochastic element, e.g., in RANSAC, may not be what you want (3) the model has different assumption than OLS
Thank you for creating this summary! I am a psychology student new to python and statistical analysis, and am trying to understand whether I can do a robust version of multiple linear regression in python. Do you have any thoughts on the matter?
am getting error at ValueError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_18720/1163480024.py in
45 X, y = get_dataset()
46 # define a uniform grid across the input domain
—> 47 xaxis = arange(X.min(), X.max(), 0.01)
48 for model in get_models():
49 # plot the line of best fit
~\Anaconda3\lib\site-packages\pandas\core\generic.py in __nonzero__(self)
1535 @final
1536 def __nonzero__(self):
-> 1537 raise ValueError(
1538 f”The truth value of a {type(self).__name__} is ambiguous. ”
1539 “Use a.empty, a.bool(), a.item(), a.any() or a.all().”
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
ValueError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_18720/1163480024.py in
45 X, y = get_dataset()
46 # define a uniform grid across the input domain
—> 47 xaxis = arange(X.min(), X.max(), 0.01)
48 for model in get_models():
49 # plot the line of best fit
~\Anaconda3\lib\site-packages\pandas\core\generic.py in __nonzero__(self)
1535 @final
1536 def __nonzero__(self):
-> 1537 raise ValueError(
1538 f”The truth value of a {type(self).__name__} is ambiguous. ”
1539 “Use a.empty, a.bool(), a.item(), a.any() or a.all().”
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
Hi Juji…I’m eager to help, but I just don’t have the capacity to help you setup or debug work workstation.
Also, I am not an expert in debugging workstations and development environments.
My material is generally intended for those that know their way around their own workstation and know how to install software.
Check these tutorials for setting up your environment:
How to Setup a Python Environment for Machine Learning and Deep Learning with Anaconda
How to Install a Python 3 Environment on Mac OS X for Machine Learning and Deep Learning
How to Create a Linux Virtual Machine For Machine Learning Development With Python 3
If you continue to have problems, consider posting your question and issue to StackOverflow.
Such an interesting topic, just like all your posts. How would a real world ML use case be with these RobReg models look like? How do we leverage these on a dataset? Can any of these RobReg’s be used in a NN? cheers!
Dear James,
Thanks for this excellent tutorial. OLS regression gives an r-squared which I think of as a generalised “estimate” of the accuracy of the regression. Can you get an r-squared for robust models or is this not possible/conceptually flawed?
If r-squared is not the right measure for robust models, is there a useful equivalent?
Thanks,
Stu
Thanks for the Post!
For the independent variables or the features, what is the recommended way to scale?
Is it reasonable to scale using mean and std dev. or does it make more sense to use median and interquartile range?








It is a quite nice and fun tutorial for linear regression tools. However is there any link with Machine Learning ?
Thanks.
Machine learning borrows predictive models from statistics. Therefore a linear regression can be referred to as machine learning.
More here:
https://machinelearningmastery.com/faq/single-faq/how-are-statistics-and-machine-learning-related
Thanks for introducing last two robust models
You’re welcome.
Great post Jason! I learned a lot. Thank you.
Thanks!
Dear Dr Jason,
thank you for these tutorials.
In the third last example:
Why do you prefer the TheiSen model 4.371 (1.961) which is > Huber 4.435 (1.868)?
Thank you,
Anthony of Sydney
TheilSen has lower error 4.371 vs 4.435.
Dear Dr Jason,
Thank you, and apologies.
Anthony of Sydney
Dear Dr Jason,
thank you for these tutorials. It is very nicely written and explained.
You’re welcome!
I never tire of learning with you. Thanks for your post.
Thanks!
Great article I learnt a lot! I was wondering – what should be done if we also want to give different weights for the observations? For example in a time series of 3-4 years we want to give more weight for closer observations. Can you guide to further reading of this? Thanks!!
The model will learn these weights for you in away that results in the minimum error. This is the whole idea of machine learning.
What I meant was if you want to compare between 12 months slope this month vs. 12 months slope last month. In this case you want the slope to be less affected by earlier observations.
Linear models will learn a separate weight for each lag observation – if the weighting as you described is optimal, the model will find it.
First of all thank you for your job, posting these interesting methods. I was wondering: is it possible to insert robust regression in a clustering algorithm? That is, placing a condition that makes a cluster of points belong to a regression estimator, or calculating a cluster based on a regressor and then go on with other clusters (which would have other regressors). This, maybe, by placing a tolerance angle for each cluster. It would be very interesting to have such a feature.
You’re welcome.
I don’t see how. But if you have some ideas, perhaps try them out with a prototype.
I too cannot figure out how to do it. I guess it would may be possible to do such a process by iterating the operation of linear estimation n times on a 2d/3d array, being n = number of clusters, for example, in a k-mean type clustering. But I don’t really understand at which place of the clustering algorithm code I have to change what to place the regression condition.
Perhaps explore your idea with small code prototypes to see if it is viable.
Great tutorial
Thanks!
Great tutorial, thank you for it and for the others that you have published on the site. I was wondering if it is possible to do a linear regression estimation on 3d data sets with these methods. Will much appreciate any advice. Thanks
I don’t see why not. Try it and see.
Any advice on how to plot 3d results? how to plot the plane of best fit? thanks
Yes, matplotlib supports 3d surface plots. Check the API docs.
Great article!
My only observation is that HuberRegressor appears to be significantly faster than TheilSenRegressor.
Thanks!
It sure is.
Fantastic tutorial. The world becomes a little better with your knowledge and kindness. 🙂
Do you know is there a python library that can do Lasso with a Huber loss function. Thanks!
Thanks!
Not off hand, sorry.
Great post Jason. I had a related question. How do I approach a regression problem where the data is not noisy but target variable is noisy. Which regression algorithms can I use? How do I denoise a noisy target variable in regression?
I recommend testing a suite of different algorithms and discover what works well or best with your dataset.
How do you get the coefficients from the models?
Call the get_params() function on the model.
Can you apply Robust algorithms such as Ransac / Thiel sen to time series data which have outliers and also are not stationary?
Theoretically should work but I don’t see any existing library implementing this.
Hello,
It was an excellent read. Great tutorial and very clear explanation of robust regression and all the different algorithms.
I was wondering if there are any limitations to robust regression? Why not use robust regression all the time instead of using the OLS regression model?
Thanks!
(1) the algorithm is more complex (2) introducing stochastic element, e.g., in RANSAC, may not be what you want (3) the model has different assumption than OLS
Hi Jason,
Thank you for creating this summary! I am a psychology student new to python and statistical analysis, and am trying to understand whether I can do a robust version of multiple linear regression in python. Do you have any thoughts on the matter?
Thank you!
Hi Maria…the following may be of interest to you:
https://machinelearningmastery.com/multivariate-adaptive-regression-splines-mars-in-python/
Thank you so much James. I think this might be beyond me (my needs) at this stage but genuinely appreciate it 🙂
am getting error at ValueError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_18720/1163480024.py in
45 X, y = get_dataset()
46 # define a uniform grid across the input domain
—> 47 xaxis = arange(X.min(), X.max(), 0.01)
48 for model in get_models():
49 # plot the line of best fit
~\Anaconda3\lib\site-packages\pandas\core\generic.py in __nonzero__(self)
1535 @final
1536 def __nonzero__(self):
-> 1537 raise ValueError(
1538 f”The truth value of a {type(self).__name__} is ambiguous. ”
1539 “Use a.empty, a.bool(), a.item(), a.any() or a.all().”
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
ValueError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_18720/1163480024.py in
45 X, y = get_dataset()
46 # define a uniform grid across the input domain
—> 47 xaxis = arange(X.min(), X.max(), 0.01)
48 for model in get_models():
49 # plot the line of best fit
~\Anaconda3\lib\site-packages\pandas\core\generic.py in __nonzero__(self)
1535 @final
1536 def __nonzero__(self):
-> 1537 raise ValueError(
1538 f”The truth value of a {type(self).__name__} is ambiguous. ”
1539 “Use a.empty, a.bool(), a.item(), a.any() or a.all().”
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
Hi Juji…I’m eager to help, but I just don’t have the capacity to help you setup or debug work workstation.
Also, I am not an expert in debugging workstations and development environments.
My material is generally intended for those that know their way around their own workstation and know how to install software.
Check these tutorials for setting up your environment:
How to Setup a Python Environment for Machine Learning and Deep Learning with Anaconda
How to Install a Python 3 Environment on Mac OS X for Machine Learning and Deep Learning
How to Create a Linux Virtual Machine For Machine Learning Development With Python 3
If you continue to have problems, consider posting your question and issue to StackOverflow.
Great post thanks ! Does it exist some equivalents or ways to use these robustness technics in logistic regression please ?
Thank you !
Hi Thb…the following may help add clarity:
https://www.scirp.org/journal/paperinformation.aspx?paperid=98625
Such an interesting topic, just like all your posts. How would a real world ML use case be with these RobReg models look like? How do we leverage these on a dataset? Can any of these RobReg’s be used in a NN? cheers!
Hi FabianB…Please describe the “real world ML use” you are considering so that we may better assist you.
Dear James,
Thanks for this excellent tutorial. OLS regression gives an r-squared which I think of as a generalised “estimate” of the accuracy of the regression. Can you get an r-squared for robust models or is this not possible/conceptually flawed?
If r-squared is not the right measure for robust models, is there a useful equivalent?
Thanks,
Stu
Hi Stu…You are very welcome! The following is an excellent discussion addressing this topic:
https://stackoverflow.com/questions/60073531/is-it-appropriate-to-calculate-r-squared-of-robust-regression-using-rlm#:~:text=Now%20coming%20to%20the%20appropriateness,the%20formula%20for%20r%2Dsquared.
Thanks James, that’s v useful indeed.
Thanks for the Post!
For the independent variables or the features, what is the recommended way to scale?
Is it reasonable to scale using mean and std dev. or does it make more sense to use median and interquartile range?
Hi A Singh…You may find the following of interest:
https://machinelearningmastery.com/how-to-improve-neural-network-stability-and-modeling-performance-with-data-scaling/