The residual errors from forecasts on a time series provide another source of information that we can model.
Residual errors themselves form a time series that can have temporal structure. A simple autoregression model of this structure can be used to predict the forecast error, which in turn can be used to correct forecasts. This type of model is called a moving average model, the same name but very different from moving average smoothing.
In this tutorial, you will discover how to model a residual error time series and use it to correct predictions with Python.
After completing this tutorial, you will know:
About how to model residual error time series using an autoregressive model.
How to develop and evaluate a model of residual error time series.
How to use a model of residual error to correct predictions and improve forecast skill.
Kick-start your project with my new book Time Series Forecasting With Python, including step-by-step tutorials and the Python source code files for all examples.
Let’s get started.
Updated Jan/2017: Improved some of the code examples to be more complete.
Updated Apr/2019: Updated the link to dataset.
Updated Aug/2019: Updated data loading to use new API.
Updated Apr/2020: Changed AR to AutoReg due to API change.
Model of Residual Errors
The difference between what was expected and what was predicted is called the residual error.
It is calculated as:
1
residual error = expected - predicted
Just like the input observations themselves, the residual errors from a time series can have temporal structure like trends, bias, and seasonality.
Any temporal structure in the time series of residual forecast errors is useful as a diagnostic as it suggests information that could be incorporated into the predictive model. An ideal model would leave no structure in the residual error, just random fluctuations that cannot be modeled.
Structure in the residual error can also be modeled directly. There may be complex signals in the residual error that are difficult to directly incorporate into the model. Instead, you can create a model of the residual error time series and predict the expected error for your model.
The predicted error can then be subtracted from the model prediction and in turn provide an additional lift in performance.
A simple and effective model of residual error is an autoregression. This is where some number of lagged error values are used to predict the error at the next time step. These lag errors are combined in a linear regression model, much like an autoregression model of the direct time series observations.
An autoregression of the residual error time series is called a Moving Average (MA) model. This is confusing because it has nothing to do with the moving average smoothing process. Think of it as the sibling to the autoregressive (AR) process, except on lagged residual error rather than lagged raw observations.
In this tutorial, we will develop an autoregression model of the residual error time series.
Before we dive in, let’s look at a univariate dataset for which we will develop a model.
Stop learning Time Series Forecasting the slow way!
Take my free 7-day email course and discover how to get started (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
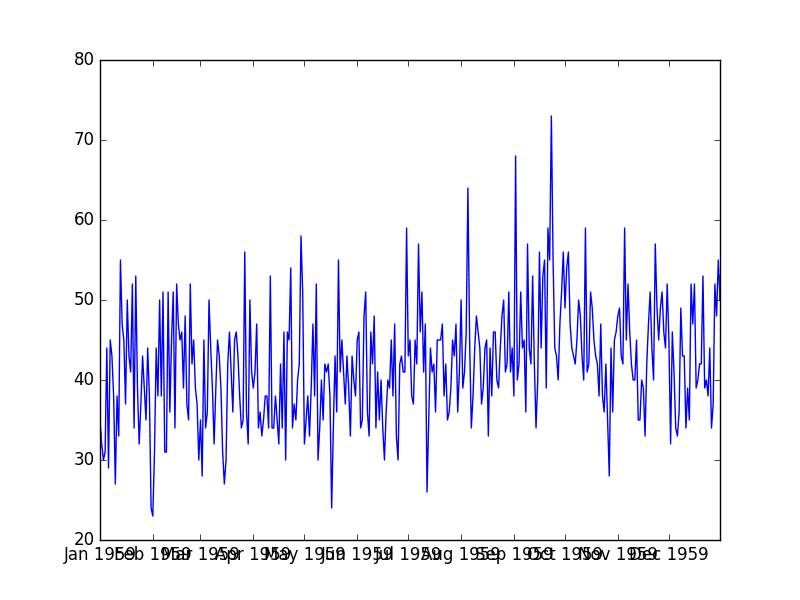
Daily Female Births Dataset
This dataset describes the number of daily female births in California in 1959.
The units are a count and there are 365 observations. The source of the dataset is credited to Newton (1988).
Running the example prints the first 5 rows of the loaded file.
1
2
3
4
5
6
7
Date
1959-01-01 35
1959-01-02 32
1959-01-03 30
1959-01-04 31
1959-01-05 44
Name: Births, dtype: int64
The dataset is also shown in a line plot of observations over time.
Daily Total Female Births Plot
We can see that there is no obvious trend or seasonality. The dataset looks stationary, which is an expectation of using an autoregression model.
Persistence Forecast Model
The simplest forecast that we can make is to forecast that what happened in the previous time step will be the same as what will happen in the next time step.
This is called the “naive forecast” or the persistence forecast model. This model will provide the predictions from which we can calculate the residual error time series. Alternately, we could develop an autoregression model of the time series and use that as our model. We will not develop an autoregression model in this case for brevity and to focus on the model of residual error.
We can implement the persistence model in Python.
After the dataset is loaded, it is phrased as a supervised learning problem. A lagged version of the dataset is created where the prior time step (t-1) is used as the input variable and the next time step (t+1) is taken as the output variable.
1
2
3
4
# create lagged dataset
values=DataFrame(series.values)
dataframe=concat([values.shift(1),values],axis=1)
dataframe.columns=['t-1','t+1']
Next, the dataset is split into training and test sets. A total of 66% of the data is kept for training and the remaining 34% is held for the test set. No training is required for the persistence model; this is just a standard test harness approach.
Once split, the train and test sets are separated into their input and output components.
1
2
3
4
5
6
# split into train and test sets
X=dataframe.values
train_size=int(len(X)*0.66)
train,test=X[1:train_size],X[train_size:]
train_X,train_y=train[:,0],train[:,1]
test_X,test_y=test[:,0],test[:,1]
The persistence model is applied by predicting the output value (y) as a copy of the input value (x).
1
2
# persistence model
predictions=[xforxintest_X]
The residual errors are then calculated as the difference between the expected outcome (test_y) and the prediction (predictions).
We can use the autoregression model (AR) provided by the statsmodels library.
Building on the persistence model in the previous section, we can first train the model on the residual errors calculated on the training dataset. This requires that we make persistence predictions for each observation in the training dataset, then create the AR model, as follows.
Next, we can step through the test dataset and for each time step we must:
Calculate the persistence prediction (t+1 = t-1).
Predict the residual error using the autoregression model.
The autoregression model requires the residual error of the 15 previous time steps. Therefore, we must keep these values handy.
As we step through the test dataset timestep by timestep making predictions and estimating error, we can then calculate the actual residual error and update the residual error time series lag values (history) so that we can calculate the error at the next time step.
This is a walk forward forecast, or a rolling forecast, model.
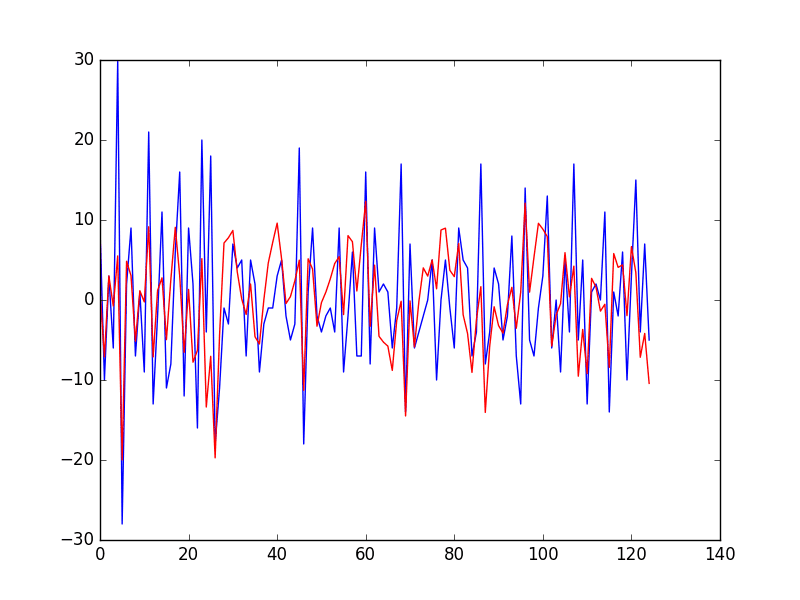
We end up with a time series of the residual forecast error from the train dataset and a predicted residual error on the test dataset.
We can plot these and get a quick idea of how skillful the model is at predicting residual error. The complete example is listed below.
Running the example prints the predictions and the expected outcome for each time step in the test dataset.
The RMSE of the corrected forecasts is calculated to be 7.499, which is much better than the score of 9.151 for the persistence model alone.
1
2
3
4
5
6
7
...
predicted=40.675538, expected=37.000000
predicted=40.419129, expected=52.000000
predicted=44.839954, expected=48.000000
predicted=43.820997, expected=55.000000
predicted=44.574876, expected=50.000000
Test RMSE: 7.499
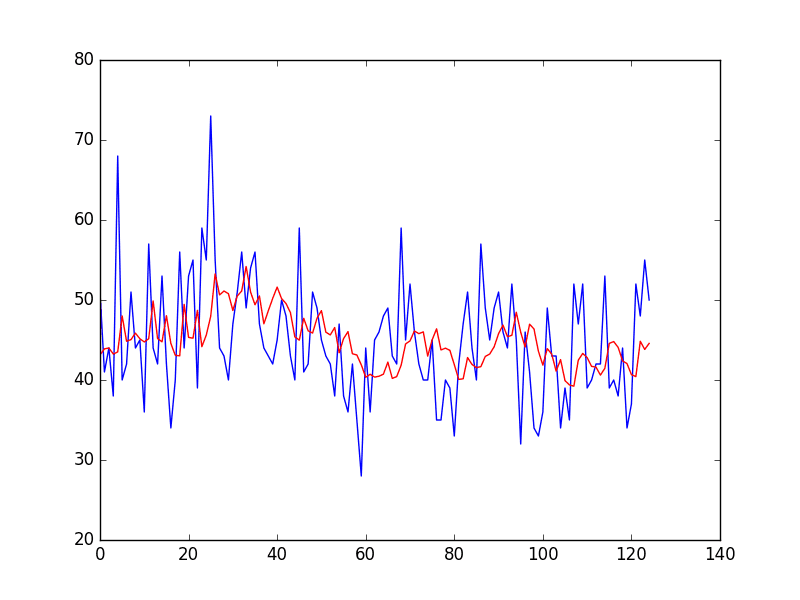
Finally, the expected values for the test dataset are plotted (blue) compared to the corrected forecast (red).
We can see that the persistence model has been aggressively corrected back to a time series that looks something like a moving average.
Corrected Persistence Forecast for Daily Female Births
Summary
In this tutorial, you discovered how to model residual error time series and use it to correct predictions with Python.
Specifically, you learned:
About the Moving Average (MA) approach to developing an autoregressive model to residual error.
How to develop and evaluate a model of residual error to predict forecast error.
How to use the predictions of forecast error to correct predictions and improve model skill.
Do you have any questions about Moving Average models, or about this tutorial?
Ask your questions in the comments below and I will do my best to answer.
Want to Develop Time Series Forecasts with Python?
Sir Actually he is taking about Hybride ARIMA-ANN model G. Peter Zhang model in which residuals are modeled by ANN ..
Problem is that how such small set of residuals are modeled by ANN…
Thanks in advance
Hello Jason,
I used an SARIMAX model for my time series data and when calculating residual error for the test and train set, I observed a seasonality in the residual error. Do you think should I re-correct the SARIMAX model somehow or I can implement the above method you explained to the residual error?
Thank you Jason!
Have a good day.
PS: It will be useful to receive email from you whenever you reply to our messages.
Hello Jason, I wanted to ask the same question as Fatima.
In my case, the dataset is actually multivariate, and I want to model the residual error on this multivariate dataset, and I assume the AR model won’t work in my case. Can I use the classical ML models for the same purpose ?
Hello Jason,
Thanks again for all your helpful tutorials!
I was reading about regression with ARMA errors on Rob Hyndman’s blog (https://robjhyndman.com/hyndsight/arimax/). Is it similar to what you have here except yours used a persistance model instead of ARMA / ARIMA?
Row
thank you for posting this example.
In your example you are forecasting 1 step into the future, but what if you had to forecast lets say 10 steps ahead using this a persistence model combined with this error correction model?
Would you simply forecast the errors by changing the code to:
model_fit.forecast()[10] ?
In general, I think it would be useful if you would show an example of multiple steps ahead out of sample forecasts.
Thanks for your reply. I made an ARIMA forecast for my dataset, for which I would like to forecast the errors too. Should I make a training set, fit the ARIMA model, forecast for the length of the test set and then get the errors from the test set? Or does it differ when using the ARIMA approach?
So I collected the errors step by step, and then checked for stationarity using the ADF and KPSS tests, which tell me that the errors are stationary. Then I fit an ARIMA(0, 0, 0) model on the errors after taking a look at the autocorrelation and partial autocorrelation plots. This model kind of averages out and is not very flexible, in the sense that it doesn’t capture spikes in the data, i.e., where the errors deviate a lot from the mean. Is there a way to fit a more flexible model or use a different one perhaps? Please let me know. Thanks!
Thanks a lot for your work! Is it safe to assume that the process that you laid out in this blog is exactly what happens behind-the-scenes if I include an MA term in the ARIMA model?
Contrasting the described 2-step approach of separately estimating models (first for response then for residuals) and subsequently combining them in the forecast step with estimation in the likes of GLMM or Transfer Functions Models where we (can) impose some correlation structure on the errors directly: are there any pitfalls if the practical objective is only a “good” forecast as measured here by RMSE (instead of say hypothesis testing on parameters)?
Thanks for your great work, I really appreciate it.
In the article you say:
“Structure in the residual error can also be modeled directly. There may be complex signals in the residual error that are difficult to directly incorporate into the model. Instead, you can create a model of the residual error time series and predict the expected error for your model.”
Now the question is: in which cases is direct modelling of error structure preferred over the proposed 2-step method?
I guess standard errors of parameters are affected, but is there any practical difference regarding forecast performance alone?
I was wondering if ARMARESULT.resid gives the actual residuals .I want to use those residuals in a different model .but the size of the array it return is 55 and the dataset I am fitting is 57 .
If q is the reason why I am getting those results ,how would I align the residuals along with the time series data to feed them into another model like LSTM?
If you can answer me and give me an example or any referrence I will be grateful .
Good post. Have a question on 1 point.
Initially blog mentions this point
“There may be complex signals in the residual error that are difficult to directly incorporate into the model. ”
Regarding this, question is, can you share some ideas or techniques through which we can detect such structure in residual series. This will help to determine, if we need to do residual modelling or not, in first place.
Hi Jason.. on the explanation about White noise… You mentioned that the only error after we extracted the signal from any time series should be White Noise. But that is the ideal model which we try to achieve…But there is always some Residual errors which we calculate from the Error measures like RSME… So basically any model would have both Residual errors which are reducible and White noise that are irreducible?
As George Box said “All models are wrong but some are useful”.
Hi Jason, thank you for your great explanation ! Some questions i got:
– Are these kind of methods working better for ‘dynamic environment’ (ie when possible cause of observed time serie change can change (new causes, …)) ? I mean if the environment is ‘stable’, should we not expect some white noise in the model ?
– Does this make sense to apply this method many times ? I mean checking to forecast the error of ‘second degree’ : ie error after adding the error forecast, and so on… I guess yes in theory if the second error is still not white noise, but does this really happen in practice ?
Hi Jason,
I am getting negative values for my sales prediction,can you plz suggest something to fix that especially in terms of tuning the hyperparameters.Just FYI, I am using azure automl to generate the model.
Perhaps try an alternate model?
Perhaps try an alternate configuration of your model?
Perhaps try data preparation prior to modeling?
Perhaps try post-processing of the predictions?
I think this method doesn’t work. Main reason being using the expected error(ground truth) in the “history” list to predict the same thing. Multiplying the AutoReg coefs with pred_error, which remains prediction error only in the first loop. From next loop on-wards you’re using cheating.
yes That’s true. after reading the comments I got to know that we can add prediction errors into history by actually predicting from AR model which trained on residual errors.
Is this how we get residual terms in arima equation . Suppose ARIMA(2,0,4) model we can get the coefficients but model_fit.summary() I have the coefficient of 4 q terms but how are e(t-1) ,e(t-2) ,e(t-3) and e(t-4) is calculated . Will be very grateful if you can give relevant link
Error/residual terms are assumed to be random but following normal distribution. If you know the true value of x(t-1), x(t-2), etc. and compare too the prediction, then the difference is the error term. Otherwise, the error terms are unknown.







Is anyone else finding that these tutorials just don’t work?
Sorry to hear that, what problem are you getting exactly?
Update: I updated the first two code examples to be more complete/easier to run directly.
Hai jason, Is there any way to forecast auto correlated residual without having test data residuals
Perhaps. You have complete freedom over how the problem is framed, e.g. the inputs and outputs.
Be sure to choose inputs that you have available at prediction time.
hi,how to know lag numer?
can I conclude above process as how arima(p,d,q) process works in background?
Sorry, I don’t follow. Perhaps you can restate your question with more context?
i’m trying to model residual from arima using ann,it’s called hybrid arima. do you have any clue?
What is the problem you are having exactly?
Sir Actually he is taking about Hybride ARIMA-ANN model G. Peter Zhang model in which residuals are modeled by ANN ..
Problem is that how such small set of residuals are modeled by ANN…
Thanks in advance
Thank you for the tutorial. Would you please explain this tutorial with matlab?
Sorry, I don’t have matlab tutorials, it is a platform that is only used in school – not on business projects.
Hello Jason,
I used an SARIMAX model for my time series data and when calculating residual error for the test and train set, I observed a seasonality in the residual error. Do you think should I re-correct the SARIMAX model somehow or I can implement the above method you explained to the residual error?
Thank you Jason!
Have a good day.
PS: It will be useful to receive email from you whenever you reply to our messages.
Yes, if there is a signal in the residual errors then the model should be updated to also cover that signal if possible.
Hello Jason,
“We can model the residual error time series using an autoregression model”
Would it be perhaps possible ( and more accurate) to model the residual error using a machine learning model?
Why?
Hello Jason, I wanted to ask the same question as Fatima.
In my case, the dataset is actually multivariate, and I want to model the residual error on this multivariate dataset, and I assume the AR model won’t work in my case. Can I use the classical ML models for the same purpose ?
Know that, I do have the lags included in my dataset
Perhaps try a range of models including linear and machine learning and discover what works best for your specific dataset.
Hi Jason,
I do not quite understand how you got
‘next time step (t+1) is taken as the output variable’
It seems you used the values at time t as the values at time t+1.
Should it be ” values.shift(-1) ” ?
Thank you very much!
Yes, I use t+1 for t. It was not a good choice of terminology.
Hello Jason,
Thanks again for all your helpful tutorials!
I was reading about regression with ARMA errors on Rob Hyndman’s blog (https://robjhyndman.com/hyndsight/arimax/). Is it similar to what you have here except yours used a persistance model instead of ARMA / ARIMA?
Row
Yes, ARIMA is ARMA wit the added differencing step.
Thank you, Jason.
You’re welcome.
Hi Jason,
thank you for posting this example.
In your example you are forecasting 1 step into the future, but what if you had to forecast lets say 10 steps ahead using this a persistence model combined with this error correction model?
Would you simply forecast the errors by changing the code to:
model_fit.forecast()[10] ?
In general, I think it would be useful if you would show an example of multiple steps ahead out of sample forecasts.
Cheers!
Call model.forecsat(10)
history = train_resid[len(train_resid)-window:]
history = [history[i] for i in range(len(history))]
The first line outputs the same result as the second one. Could you explain why you have included them both? Thank you.
Typo, I expect.
Thanks for your reply. I made an ARIMA forecast for my dataset, for which I would like to forecast the errors too. Should I make a training set, fit the ARIMA model, forecast for the length of the test set and then get the errors from the test set? Or does it differ when using the ARIMA approach?
Yes, that sounds reasonable. Be sure to collect errors in the same way as obs, e.g. step-by-step or sequence by sequence.
So I collected the errors step by step, and then checked for stationarity using the ADF and KPSS tests, which tell me that the errors are stationary. Then I fit an ARIMA(0, 0, 0) model on the errors after taking a look at the autocorrelation and partial autocorrelation plots. This model kind of averages out and is not very flexible, in the sense that it doesn’t capture spikes in the data, i.e., where the errors deviate a lot from the mean. Is there a way to fit a more flexible model or use a different one perhaps? Please let me know. Thanks!
Well done!
Perhaps try a suite of models and model configurations and discover what works best for your dataset.
Hi Jason,
is it possible to mix LSTM with a residual architecture?
thank you in advance.
Yes, residual errors can be provided as input to the model.
Hi Jason,
Thanks a lot for your work! Is it safe to assume that the process that you laid out in this blog is exactly what happens behind-the-scenes if I include an MA term in the ARIMA model?
Very close.
Hi Jason,
Contrasting the described 2-step approach of separately estimating models (first for response then for residuals) and subsequently combining them in the forecast step with estimation in the likes of GLMM or Transfer Functions Models where we (can) impose some correlation structure on the errors directly: are there any pitfalls if the practical objective is only a “good” forecast as measured here by RMSE (instead of say hypothesis testing on parameters)?
Thanks for your great work, I really appreciate it.
Sorry, not sure I follow your question. Perhaps you can restate it?
In the article you say:
“Structure in the residual error can also be modeled directly. There may be complex signals in the residual error that are difficult to directly incorporate into the model. Instead, you can create a model of the residual error time series and predict the expected error for your model.”
Now the question is: in which cases is direct modelling of error structure preferred over the proposed 2-step method?
I guess standard errors of parameters are affected, but is there any practical difference regarding forecast performance alone?
Thanks
No, use results/data to guide model selection.
Perhaps try both approaches and use the model that has better skill/less error.
I was wondering if ARMARESULT.resid gives the actual residuals .I want to use those residuals in a different model .but the size of the array it return is 55 and the dataset I am fitting is 57 .
Perhaps the model had a difference of 2 to account for the number of residuals?
you mean the q value is 2 ?
If q is the reason why I am getting those results ,how would I align the residuals along with the time series data to feed them into another model like LSTM?
If you can answer me and give me an example or any referrence I will be grateful .
I don’t have an example, you will have to experiment.
Yes.
Good post. Have a question on 1 point.
Initially blog mentions this point
“There may be complex signals in the residual error that are difficult to directly incorporate into the model. ”
Regarding this, question is, can you share some ideas or techniques through which we can detect such structure in residual series. This will help to determine, if we need to do residual modelling or not, in first place.
Sometimes, simply fitting a model on the residuals can lift performance.
Hi Jason.. on the explanation about White noise… You mentioned that the only error after we extracted the signal from any time series should be White Noise. But that is the ideal model which we try to achieve…But there is always some Residual errors which we calculate from the Error measures like RSME… So basically any model would have both Residual errors which are reducible and White noise that are irreducible?
As George Box said “All models are wrong but some are useful”.
Ideally we would get to the point where the residual error is comprise of white noise only.
This is an ideal, not possible or very hard to achieve in practice.
Hi Jason, thank you for your great explanation ! Some questions i got:
– Are these kind of methods working better for ‘dynamic environment’ (ie when possible cause of observed time serie change can change (new causes, …)) ? I mean if the environment is ‘stable’, should we not expect some white noise in the model ?
– Does this make sense to apply this method many times ? I mean checking to forecast the error of ‘second degree’ : ie error after adding the error forecast, and so on… I guess yes in theory if the second error is still not white noise, but does this really happen in practice ?
It really depends on the specific of the dataset.
Perhaps. Some experiemtantion may be required.
Hi Jason,
I am getting negative values for my sales prediction,can you plz suggest something to fix that especially in terms of tuning the hyperparameters.Just FYI, I am using azure automl to generate the model.
Perhaps try an alternate model?
Perhaps try an alternate configuration of your model?
Perhaps try data preparation prior to modeling?
Perhaps try post-processing of the predictions?
Can you please add an option to sort the comments based on date pls. It really saves time.
Comment threads are listed in date-time order ascending (oldest to newest).
I think this method doesn’t work. Main reason being using the expected error(ground truth) in the “history” list to predict the same thing. Multiplying the AutoReg coefs with pred_error, which remains prediction error only in the first loop. From next loop on-wards you’re using cheating.
yes That’s true. after reading the comments I got to know that we can add prediction errors into history by actually predicting from AR model which trained on residual errors.
Is this how we get residual terms in arima equation . Suppose ARIMA(2,0,4) model we can get the coefficients but model_fit.summary() I have the coefficient of 4 q terms but how are e(t-1) ,e(t-2) ,e(t-3) and e(t-4) is calculated . Will be very grateful if you can give relevant link
Error/residual terms are assumed to be random but following normal distribution. If you know the true value of x(t-1), x(t-2), etc. and compare too the prediction, then the difference is the error term. Otherwise, the error terms are unknown.