At the very start of your machine learning journey, publicly available datasets alleviate the worry of creating the datasets yourself and let you focus on learning to use the machine learning algorithms. It also helps if the datasets are moderately sized and do not require too much pre-processing to get you to practice using the algorithms quicker before moving on to more challenging problems.
Two datasets we will be looking at are the simpler digits dataset provided with OpenCV and the more challenging but widely used CIFAR-10 dataset. We will use any of these two datasets during our journey through OpenCV’s machine learning algorithms.
In this tutorial, you will learn how to download and extract the OpenCV digits and CIFAR-10 datasets for practicing machine learning in OpenCV.
After completing this tutorial, you will know:
How to download and extract the OpenCV digits dataset.
How to download and extract the CIFAR-10 dataset without necessarily relying on other Python packages (such as TensorFlow).
Kick-start your project with my book Machine Learning in OpenCV. It provides self-study tutorials with working code.
Let’s get started.
Image Datasets for Practicing Machine Learning in OpenCV Photo by OC Gonzalez, some rights reserved.
Tutorial Overview
This tutorial is divided into three parts; they are:
The Digits Dataset
The CIFAR-10 Dataset
Loading the Datasets
The Digits Dataset
OpenCV provides the image, digits.png, composed of a ‘collage’ of 20$\times$20 pixel sub-images, where each sub-image features a digit from 0 to 9 and may be split up to create a dataset. In total, the digits image contains 5,000 handwritten digits.
The digits dataset provided by OpenCV does not necessarily represent the real-life challenges that come with more complex datasets, primarily because its image content features very limited variation. However, its simplicity and ease of use will allow us to quickly test several machine learning algorithms at a low pre-processing and computational cost.
To be able to extract the dataset from the full digits image, our first step is to split it into the many sub-images that make it up. For this purpose, let’s create the following split_images function:
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
fromcv2 importimread,IMREAD_GRAYSCALE
fromnumpy importhsplit,vsplit,array
defsplit_images(img_name,img_size):
# Load the full image from the specified file
img=imread(img_name,IMREAD_GRAYSCALE)
# Find the number of sub-images on each row and column according to their size
num_rows=img.shape[0]/img_size
num_cols=img.shape[1]/img_size
# Split the full image horizontally and vertically into sub-images
The split_images function takes as input the path to the full image, together with the pixel size of the sub-images. Since we are working with square sub-images, we shall be denoting their size by a single dimension, which is equal to 20.
The function subsequently applies the OpenCV imread method to load a grayscale version of the image into a NumPy array. The hsplit and vsplit methods are then used to split the NumPy array horizontally and vertically, respectively.
The array of sub-images the split_images function returns is of size (50, 100, 20, 20).
Once we have extracted the array of sub-images, we shall partition it into training and testing sets. We will also need to create the ground truth labels for both splits of data to be used during the training process and to evaluate the test results.
The followingsplit_data function serves these purposes:
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
fromnumpy importfloat32,arange,repeat,newaxis
defsplit_data(img_size,sub_imgs,ratio):
# Compute the partition between the training and testing data
partition=int(sub_imgs.shape[1]*ratio)
# Split dataset into training and testing sets
train=sub_imgs[:,:partition,:,:]
test=sub_imgs[:,partition:sub_imgs.shape[1],:,:]
# Flatten each image into a one-dimensional vector
The split_data function takes the array of sub-images as input and the split ratio for the training portion of the dataset. The function then proceeds to compute the partition value that divides the array of sub-images along its columns into training and testing sets. This partition value is then used to allocate the first set of columns to the training data and the remaining set of columns to the testing data.
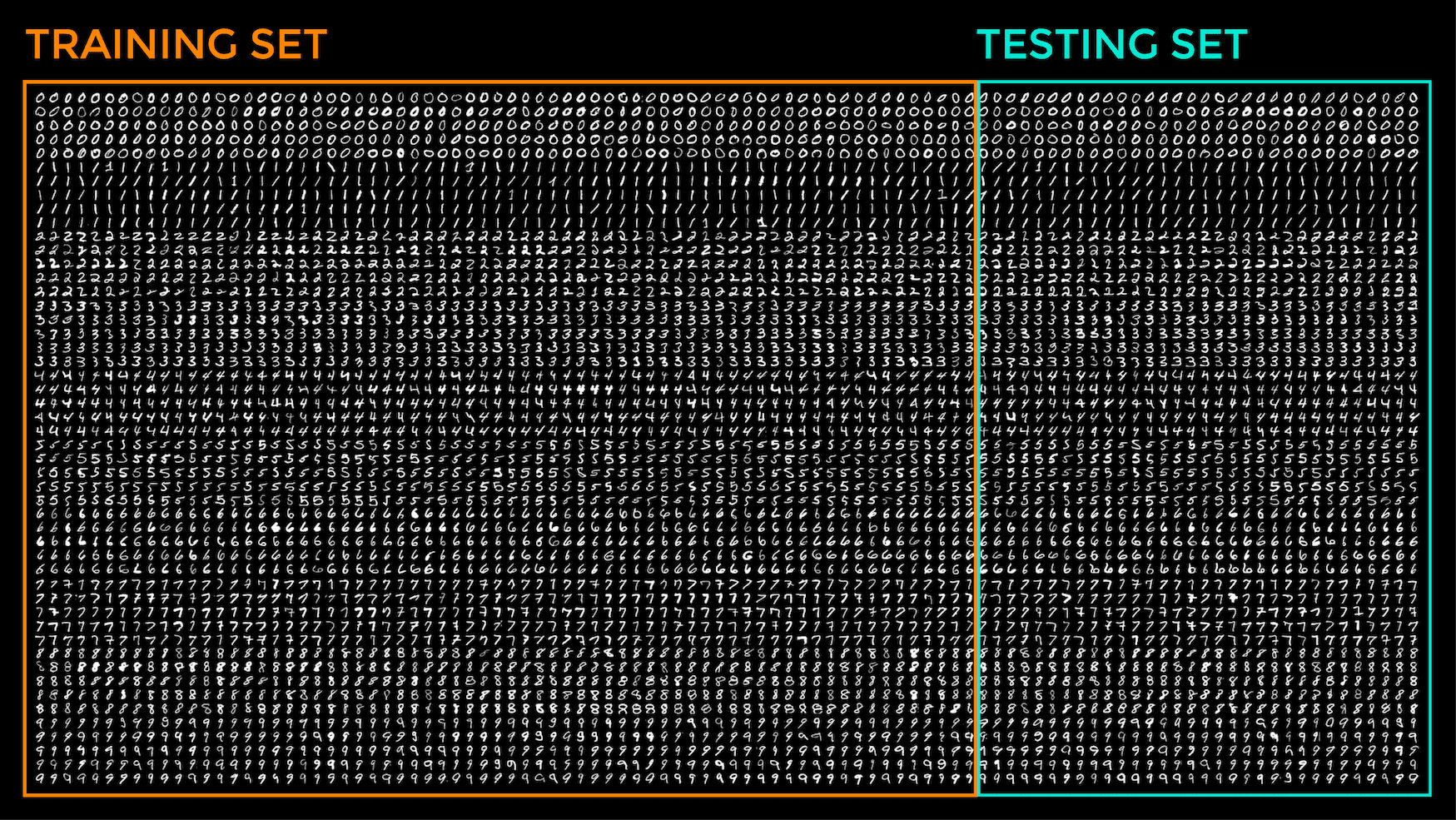
To visualize this partitioning on the digits.png image, this would appear as follows:
Partitioning the sub-images into a training dataset and a testing dataset
You may also note that we are flattening out every 20$\times$20 sub-image into a one-dimensional vector of length 400 pixels such that, in the arrays containing the training and testing images, every row now stores a flattened out version of a 20$/times$20 pixel image.
The final part of the split_data function creates ground truth labels with values between 0 and 9 and repeats these values according to how many training and testing images we have available.
The CIFAR-10 Dataset
The CIFAR-10 dataset is not provided with OpenCV, but we shall consider it because it represents real-world challenges better than OpenCV’s digits dataset.
The CIFAR-10 dataset consists of a total of 60,000, 32$\times$32 RGB images. It features a variety of images belonging to 10 different classes, such as airplanes, cats, and ships. The dataset files are readily split into 5 pickle files containing 1,000 training images and labels, plus an additional one with 1,000 testing images and labels.
Let’s go ahead and download the CIFAR-10 dataset for Python from this link (note: the reason for not using TensorFlow/Keras to do so is to show how we can work without relying on additional Python packages if need be). Take note of the path on your hard disk to which you have saved and extracted the dataset.
The following code loads the dataset files and returns the training and testing, images, and labels:
Python
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
frompickleimportload
fromnumpy importarray,newaxis
defload_images(path):
# Create empty lists to store the images and labels
imgs=[]
labels=[]
# Iterate over the dataset's files
forbatch inrange(5):
# Specify the path to the training data
train_path_batch=path+'data_batch_'+str(batch+1)
# Extract the training images and labels from the dataset files
It is important to remember that the compromise of testing out different models using a larger and more varied dataset, such as the CIFAR-10, over a simpler one, such as the digits dataset, is that training on the former might be more time-consuming.
Loading the Datasets
Let’s try calling the functions that we have created above.
I have separated the code belonging to the digits dataset from the code belonging to the CIFAR-10 dataset into two different Python scripts that I named digits_dataset.py and cifar_dataset.py, respectively:
Python
1
2
3
4
5
6
7
8
9
10
11
fromdigits_dataset importsplit_images,split_data
fromcifar_dataset importload_images
# Load the digits image
img,sub_imgs=split_images('Images/digits.png',20)
# Obtain training and testing datasets from the digits image
Note: Do not forget to change the paths in the code above to where you have saved your data files.
In the subsequent tutorials, we shall see how to use these datasets with different machine learning techniques, first seeing how to convert the dataset images into feature vectors as one of the pre-processing steps before using them for machine learning.
Want to Get Started With Machine Learning with OpenCV?
Take my free email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Further Reading
This section provides more resources on the topic if you want to go deeper.
It provides self-study tutorials with all working code in Python to turn you from a novice to expert. It equips you with logistic regression, random forest, SVM, k-means clustering, neural networks,
and much more...all using the machine learning module in OpenCV
Kick-start your deep learning journey with hands-on exercises



")




No comments yet.